
Learn how to build agentic workflows with LangChain and LangGraph.
Toggle tooltip visibility. Hover over underlined terms for instant definitions.
Introduction
This is the second article in our series on building intelligent agents with LangChain and LangGraph. In Part 1, we explored the fundamental concepts of connecting language models to tools. Now we'll take the next step: building sophisticated agentic workflows that can orchestrate multiple tools, maintain conversation state, and handle complex multi-step tasks.
While Part 1 focused on simple tool calling, real-world applications require systems that can:
- Plan and reason through multi-step problems
- Maintain context across conversations and tool interactions
- Handle interruptions and human feedback loops
- Orchestrate workflows with conditional logic and branching
In the following, we'll build an agen that feels truly intelligent - systems that don't just execute single commands, but can engage in meaningful dialogues while taking actions in the real world.
Let's dive into the world of agentic workflows and see how LangGraph makes building these sophisticated systems both intuitive and powerful.
Setting Up Our Environment
We'll build on the foundation from Part 1 while introducing new concepts for workflow orchestration:
StateGraph: The core abstraction for building multi-step workflowsMessagesState: LangGraph's built-in state for conversation handlingInMemorySaver: For maintaining conversation history and checkpointsCommand&interrupt: For human-in-the-loop interactionscreate_react_agent: A pre-built agent pattern for common use cases
These tools will allow us to create sophisticated agents that can handle complex, multi-turn conversations while maintaining context and state.
Recap: Building Blocks from Part 1
Let's quickly set up the foundational components we established in Part 1 - our language model and reply tool. These will serve as the building blocks for our more sophisticated workflows.
Introduction to Agentic Workflows
Now we move beyond simple tool calling to create agentic workflows - systems that can orchestrate multiple steps, maintain state, and make decisions about what to do next.
The key difference is structure and orchestration:
- Part 1: Direct tool calling (human → model → tool → response)
- Part 2: Workflow orchestration (human → workflow → multiple steps → response)
Defining Workflow State
LangGraph's StateGraph is the foundation that makes this possible, allowing us to define how data flows between different processing steps.
Every agentic workflow needs a way to pass data between steps. LangGraph uses TypedDict schemas to define what information flows through your system.
Our simple schema captures:
request: A user requestreply: The final result from our tool
This state acts as the "memory" of our workflow, ensuring each step has access to the information it needs.
Creating Workflow Nodes
Nodes are the processing units of your workflow. Each node is a function that:
- Receives the current state
- Performs some computation or action
- Returns updates to merge back into the state
Our reply_tool_node demonstrates the pattern: it takes the user's request, uses our model to generate a tool call, executes the tool, and returns the result.
Building the Workflow Graph
Now we assemble our workflow by defining the flow between nodes:
- Initialize the StateGraph with our schema
- Add nodes that process the data
- Add edges that define the execution flow
- Compile into an executable application
This creates a clear, visual representation of how our agent processes requests - from start to finish.
Testing Our First Agentic Workflow
Let's see our workflow in action. Notice how the request flows through our defined structure, and the state accumulates information as it progresses through each step.
Visualizing the Workflow
LangGraph automatically generates visual representations of your workflows. This helps you understand and debug complex agent behaviors by seeing exactly how data flows through your system.
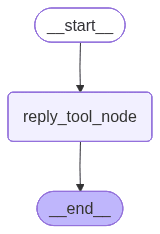
Advanced Workflow Patterns
While our first example was linear, real agentic systems need conditional logic, loops, and decision points. Let's build a more sophisticated workflow that can handle different types of responses from the language model.
Building a Conversational Agent
This workflow introduces several sophisticated concepts:
MessagesState: LangGraph's built-in state for handling conversations- Conditional edges: Logic that determines which node to execute next
- Tool message handling: Proper formatting of tool responses for the model
- Conversation loops: The ability to continue dialogues naturally
The should_continue function demonstrates conditional routing - a key pattern in agentic systems where the workflow's next step depends on the current state.
Visualizing Complex Workflows
This graph shows the conditional logic in action. Notice how call_llm can either end the conversation or route to run_tool, depending on whether tool calls are present in the response.
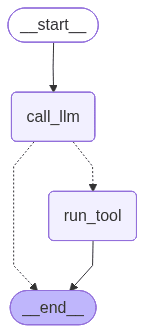
Testing the Conversational Agent
Watch how our agent processes the request:
- Receives the human message
- Generates a tool call with appropriate parameters
- Executes the tool
- Returns the formatted result
This demonstrates the complete agent lifecycle in a production-ready pattern.
Memory and Conversation Threads
One of the most powerful features of agentic workflows is the ability to maintain context across multiple interactions. This is where memory and conversation threads become essential.
Real applications need agents that can:
- Remember previous interactions
- Build context over time
- Handle interruptions and human feedback loops
- Maintain separate conversation contexts for different users
Understanding Memory and Threads
Memory (Checkpointer): Stores the complete state history of your workflow, allowing agents to "remember" previous interactions and build context over time.
Thread: A unique identifier that groups related conversations together. Different threads maintain separate conversation histories, enabling multi-user applications.
The combination enables sophisticated behaviors:
- Contextual responses based on conversation history
- Resuming interrupted conversations
- Personalization across multiple interactions
Using Pre-Built Agent Patterns
The create_react_agent function is a utility provided by LangGraph for building conversational agents that can reason and act using tools. It implements the ReAct (Reasoning + Acting) pattern, allowing your agent to alternate between thinking and taking actions (like calling tools) until the task is complete.
With create_react_agent, you can:
- Define which tools your agent can use
- Provide a language model for reasoning
- Supply a prompt to guide the agent's behavior
- Optionally add memory (via a checkpointer) to enable multi-turn conversations
This function abstracts away much of the boilerplate, letting you focus on your agent's logic and capabilities.
The ReAct (Reasoning + Acting) pattern alternates between reasoning about what to do and taking actions until the task is complete.
I intentionally sent a nonsensical request to showcase how the agent handles unexpected or unclear inputs.
Accessing Conversation History
The get_state() method allows you to inspect the complete conversation history for any thread. This is invaluable for debugging, analytics, and understanding how your agent behaves over time.
Continuing Conversations
By using the same thread ID, our agent maintains context from previous interactions. Notice how it remembers the earlier question and can reference it in subsequent responses.
Watch how the conversation builds naturally. Each exchange adds to the shared context, enabling more sophisticated interactions that feel human-like in their continuity and understanding.
The impressive part is that the LLM understands "him" refers to Jon, thanks to the maintained conversational context.
Human-in-the-Loop: Interrupts and Feedback
The most sophisticated agentic systems know when to pause and ask for human guidance. Interrupts enable human-in-the-loop workflows where agents can:
- Request clarification on ambiguous tasks
- Ask for approval before taking critical actions
- Gather additional input to complete complex requests
- Handle scenarios outside their training or capabilities
This creates truly collaborative AI systems that combine automated efficiency with human judgment.
Building an Interrupt-Enabled Workflow
This example demonstrates the interrupt pattern:
- Normal processing: Nodes execute automatically in sequence
- Interrupt point: The workflow pauses and waits for human input
- Resume with feedback: The workflow continues with the provided information
- Completion: Normal processing resumes to finish the task
The interrupt() function is the key - it suspends execution and requests human input.
Visualizing Interrupt Workflows
The workflow graph shows the human feedback node as a regular step in the process. LangGraph handles the complexity of pausing execution and resuming when input arrives.
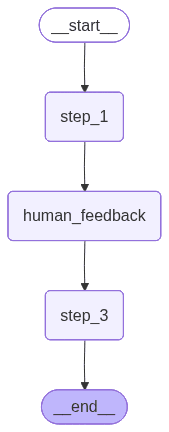
Running the Interrupt Workflow
Notice how the workflow executes until it hits the interrupt point, then waits. The __interrupt__ event indicates the system is paused and waiting for human input.
Resuming with Human Feedback
Using the Command(resume=...) function, we provide the requested feedback and continue execution. The workflow seamlessly incorporates the human input and proceeds to completion.
This pattern enables sophisticated collaborative workflows where AI handles routine tasks while humans provide guidance on complex decisions.
Reply Agent Implementation
Let's combine everything we've learned into a simple reply agent that demonstrates all the key concepts:
- Workflow orchestration with conditional logic
- Tool integration with proper error handling
- Clean architecture for maintainability
- Extensible design for adding more tools and capabilities
This serves as a template for building real-world agentic systems.
Running Your Production Agent
To deploy this agent, save the code above as reply_agent.py and run it from your terminal:
The agent will process your request through the complete workflow, demonstrating how all the concepts work together in a real application.
Example Usage and Output
Here's what happens when you run the agent:
Input: "Inform Jeremy about his delivery status being in-progres"
Processing:
- LLM analyzes the request
- Determines appropriate tool and parameters
- Executes the reply tool
- Returns formatted result
Output: Complete reply with correct classification
Key Takeaways and Next Steps
You've now mastered the essential concepts for building sophisticated agentic workflows:
Core Concepts Mastered:
- StateGraph orchestration: Managing complex multi-step workflows
- Conditional routing: Making decisions about workflow execution
- Memory and threads: Maintaining context across conversations
- Human-in-the-loop: Incorporating human feedback and oversight
- Production patterns: Building maintainable, extensible agent systems
Architectural Patterns Learned:
- State management with
TypedDictschemas - Node-based workflow design
- Tool integration and error handling
- Conversation state persistence
- Interrupt-driven human collaboration
The patterns you've learned form the foundation for any intelligent agent system. Whether you're building customer service bots, data analysis tools, or autonomous workflow systems, these concepts will serve as your building blocks.


Comments