Complete guide to Mixed Integer Linear Programming (MILP) for factory optimization, covering mathematical foundations, constraint modeling, branch-and-bound algorithms, and practical implementation with Google OR-Tools. Learn how to optimize production planning with discrete setup decisions and continuous quantities.

This article is part of the free-to-read Machine Learning from Scratch
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Mixed Integer Linear Programming (MILP) for Factory Optimization
Mixed Integer Linear Programming (MILP) is a powerful optimization technique that combines the flexibility of linear programming with the discrete decision-making capabilities of integer programming. In factory optimization, MILP allows us to model complex production scenarios where we need to make discrete choices (like which machines to use, which products to produce) while optimizing continuous variables (like production quantities, resource allocation). This makes MILP particularly valuable for real-world manufacturing problems where decisions are inherently discrete but quantities are continuous.
Unlike pure linear programming, which assumes all variables can take any fractional value, MILP recognizes that many real-world decisions are binary (yes/no) or integer-valued (whole numbers of items). For example, we can't produce 2.3 machines or hire half a worker. This discrete nature makes MILP more realistic for factory optimization while maintaining the computational advantages of linear programming for the continuous aspects of the problem.
The key advantage of MILP in factory settings is its ability to handle both tactical decisions (what to produce) and strategic decisions (capacity investments, technology choices) in a single optimization framework. This integrated approach allows factory managers to optimize not just production schedules but also long-term capacity planning and resource allocation decisions.
Advantages
MILP provides several significant advantages for factory optimization. First, it offers mathematical rigor and guarantees optimal solutions (within computational limits), which is important for high-stakes manufacturing decisions where suboptimal choices can cost millions. The linear programming foundation ensures that the continuous aspects of production (quantities, resource usage) are optimized efficiently, while the integer constraints handle the discrete nature of real-world manufacturing decisions.
Second, MILP models are highly flexible and can incorporate a wide range of constraints and objectives. We can model complex relationships between products, machines, and resources, including setup costs, capacity constraints, demand requirements, and even multi-period planning horizons. This flexibility makes MILP suitable for diverse manufacturing scenarios, from simple production scheduling to complex supply chain optimization.
Third, MILP provides clear sensitivity analysis capabilities, allowing managers to understand how changes in parameters (demand, costs, capacities) affect optimal solutions. This insight is invaluable for scenario planning and risk management in manufacturing environments where conditions frequently change.
Disadvantages
Despite its power, MILP has several limitations that factory managers should consider. The most significant disadvantage is computational complexity. As the number of integer variables increases, the problem becomes exponentially harder to solve. This means that large-scale factory optimization problems may require significant computational resources and time, potentially making real-time optimization impractical for very complex scenarios.
Second, MILP requires precise mathematical modeling, which can be challenging for complex manufacturing systems. Translating real-world factory constraints into mathematical formulations requires deep understanding of both the manufacturing process and optimization theory. Poor modeling can lead to solutions that are mathematically optimal but practically infeasible.
Third, MILP assumes linear relationships between variables, which may not always reflect real-world manufacturing dynamics. While many factory optimization problems can be approximated linearly, some relationships (like economies of scale or learning curves) are inherently nonlinear and may require more complex modeling approaches or approximations.
Formula
Imagine you're managing a factory floor. Your job is to decide what to produce and how much, all while keeping costs low and staying within machine capacities. But here's the catch: some of your decisions are straightforward quantities (produce 5 units, use 12 hours), while others are all-or-nothing choices (set up the machine or don't, produce this product line or skip it). This fundamental difference between continuous quantities and discrete yes/no decisions is what makes factory optimization both challenging and interesting.
The mathematical challenge emerges because these two types of decisions interact in complex ways. You can't produce anything without first setting up the machine, but setup costs money regardless of how much you produce. Machine capacity limits how much you can make, but the capacity itself depends on which machines you've decided to set up. To solve this problem mathematically, we need a framework that can handle both continuous optimization (finding the best quantities) and discrete decision-making (choosing which setups to perform) simultaneously.
This is exactly what Mixed Integer Linear Programming provides. The "mixed" part means we combine continuous variables (for quantities) with integer or binary variables (for discrete choices). The "linear" part means all relationships are linear, making the problem computationally tractable. The "programming" part refers to optimization, finding the best solution among all possibilities.
Let's build this formulation step by step, starting with what we're trying to optimize.
Building the Objective Function: What Are We Optimizing?
Every optimization problem starts with a clear goal. In factory optimization, that goal is typically to minimize total cost. But here's where it gets interesting: manufacturing costs don't all behave the same way.
Think about what happens when you produce more units. Some costs increase proportionally: raw materials, direct labor, energy consumption. If you produce 10 units instead of 5, these costs roughly double. These are variable costs, which vary directly with production quantity.
But other costs don't change at all with quantity. Setting up a machine costs the same whether you produce 1 unit or 1000 units. Deciding to produce a product line requires the same initial investment regardless of volume. These are fixed costs, which are incurred once when you make a decision, then remain constant.
This creates a fundamental economic trade-off. If setup costs are high, you want to minimize setups, which might mean producing larger batches of fewer products. If variable costs dominate, you want to produce exactly what's needed. The optimizer needs to balance these competing forces.
To model this mathematically, we need two separate terms in our objective function:
Let's break down what each part means:
The Variable Cost Term:
- : number of products or continuous activities we can produce
- : index running through all products
- : how many units of product to produce (a continuous variable, )
- : variable cost per unit of product (e.g., cost of materials and labor per unit)
This summation captures all costs that scale with production. If c_1 = \5x_1 = 10$5 \times 10 = $50$. The more we produce, the higher this cost becomes.
The Fixed Cost Term:
- : number of discrete setup decisions we can make
- : index running through all setup decisions
- : binary variable indicating whether we make setup decision ( if yes, if no)
- : fixed cost incurred when we make decision (setup cost)
This summation captures all costs that are triggered by discrete decisions. If d_1 = \30y_1 = 1$30y_1 = 0$), we pay nothing.
Why This Structure Works
The optimizer can now make two types of decisions simultaneously:
- Continuous decisions ( values): How much of each product to produce
- Discrete decisions ( values): Which setups to perform
The objective function automatically balances these decisions. If a product has high variable costs but low setup costs, the optimizer might produce small quantities. If setup costs are high but variable costs are low, it might produce large batches to amortize the setup cost. The mathematical formulation captures this economic logic naturally.
Capturing Resource Constraints: What Limits Can We Work With?
Minimizing cost is only half the story. In the real world, we face physical and operational limits that constrain what we can actually do. Machines have finite capacity. Materials are available in limited quantities. We may have contractual obligations to meet certain demand levels. These constraints define the feasible region, the set of all production plans that are physically possible given our resources.
The mathematical challenge is that resource consumption comes from two different sources, and we need to model both:
- Variable resource consumption from production quantities: The more we produce, the more resources we use.
- Fixed resource consumption from setup decisions: Setting up a machine consumes resources regardless of production volume.
Modeling Variable Consumption
When we produce units of product , we consume resources proportionally. If each unit of Product A requires 2 hours on Machine 1, then producing 5 units requires hours. This is straightforward linear scaling.
Modeling Fixed Consumption
But discrete decisions also consume resources. Setting up Machine 1 might require 1 hour of technician time, whether we produce 1 unit or 100 units. Switching production lines might consume a fixed amount of cleaning material. These fixed consumptions happen once when we make the decision, then don't scale with production.
Combining Both Types of Consumption
For each resource (machine, material, etc.), we need to ensure that total consumption doesn't exceed available capacity . The consumption comes from both sources, so we write:
Let's understand each component:
- : index for each resource (Machine 1, Machine 2, Material A, etc.)
- : amount of resource consumed per unit of product (e.g., hours per unit)
- : production quantity of product (from our objective function)
- : fixed amount of resource consumed when we make setup decision
- : binary variable for setup decision (1 if we set up, 0 if we don't)
- : total capacity or availability of resource
- : this constraint should hold for every resource
Why We Need Both Terms: A Concrete Example
Consider Machine 1 with 20 hours of capacity. Product A requires 2 hours per unit, and setting up for Product A requires 1 hour.
In this example:
- : number of units of Product A to produce (continuous variable, )
- : binary variable indicating whether to set up for Product A ( if we set up, if we don't)
- : hours of Machine 1 required per unit of Product A
- : fixed hours of Machine 1 required when setting up for Product A
- : total capacity of Machine 1 in hours
The constraint for Machine 1 becomes:
Substituting the values:
Example calculation: If we decide to set up () and produce units:
- Variable consumption: hours
- Fixed consumption: hour
- Total consumption: hours
Since , this violates the capacity constraint. The optimizer should either reduce production (e.g., produce 9 units: ) or skip the setup (produce 10 units without setup: ).
This dual structure, combining variable consumption from production with fixed consumption from setups, is what makes MILP constraints powerful. They capture the reality that both "how much" and "whether to" decisions consume resources.
Notational Note
You might notice that binary variables are indexed differently in the objective () versus constraints (). This is a common convention: in the objective refers to setup decisions, while in constraints refers to resources. When the number of setup decisions equals the number of resources, and refer to the same variables in different contexts.
Defining Variable Types: Why Two Types Matter
The mathematical power of MILP comes from its ability to handle two fundamentally different types of variables in a single optimization problem. Understanding why we need both types, and how they differ, is crucial for grasping how MILP works.
Continuous Variables:
Continuous variables can take any non-negative real value. They represent quantities that can be measured with arbitrary precision: production volumes (3.7 units), resource allocations (12.5 hours), time durations (45.2% of capacity).
We require because negative production doesn't make physical sense. You can't produce -5 units of a product. The non-negativity constraint ensures all solutions are physically meaningful.
Binary Variables:
Binary variables are much more restrictive: they can only be 0 or 1. There's no middle ground. When , we make decision (set up the machine, produce the product line, invest in the technology). When , we don't make that decision.
This binary nature is what makes the problem "mixed integer." We're mixing continuous optimization (finding optimal quantities) with discrete decision-making (choosing which setups to perform).
Why This Constraint Is Profound
The constraint might look simple, but it has important implications. It prevents fractional setups: you cannot set up a machine "halfway" or produce a product line "75% of the way." Either you do it completely () or you don't do it at all ().
This discrete constraint fundamentally changes the geometry of the feasible region. In pure linear programming, the feasible region is a convex polyhedron, a smooth continuous shape. But when we add integer constraints, the feasible region becomes the intersection of that polyhedron with discrete lattice points. This creates a non-convex feasible region, which is why MILP problems are computationally challenging but mathematically precise for real-world factory decisions.
The "mixed" nature means we get the best of both worlds: the efficiency of continuous optimization for quantities, combined with the precision of discrete decision-making for yes/no choices.
The Complete Formulation: Bringing It All Together
Now we can assemble the complete MILP formulation by combining the objective function with all constraints:
What This Formulation Captures
This mathematical structure captures the essence of factory optimization:
-
The objective function minimizes total cost by balancing variable costs (that scale with production) and fixed costs (that are triggered by discrete decisions).
-
The resource constraints ensure that for each resource, the total consumption from both production activities and setup decisions doesn't exceed available capacity.
-
The variable constraints ensure all solutions are physically meaningful: production quantities are non-negative, and setup decisions are binary (yes or no).
-
The optimizer's task is to find values for all (production quantities) and (setup decisions) that satisfy all constraints while achieving the minimum possible cost.
This formulation is powerful because it models the real-world interaction between continuous and discrete decisions in a mathematically precise way. The optimizer doesn't just find the best production quantities. It simultaneously determines which setups to perform, recognizing that these decisions are interdependent.
Matrix Notation: The Computational Perspective
While summation notation clearly shows the structure of the problem, computational solvers work more efficiently with matrix notation. This compact representation groups all variables and constraints into vectors and matrices, enabling efficient linear algebra operations:
Understanding the Matrix Components
- : vector of continuous variables (production quantities for all products), where is the quantity of product
- : vector of binary variables (setup decisions for all choices), where indicates whether setup decision is made
- : vector of variable cost coefficients (cost per unit for each product), where is the cost per unit of product
- : vector of fixed cost coefficients (setup cost for each decision), where is the fixed cost when setup decision is made
- : constraint matrix mapping continuous variables to resources, where row corresponds to resource and column corresponds to product . Element represents the amount of resource consumed per unit of product
- : constraint matrix mapping binary variables to resources, where row corresponds to resource and column corresponds to setup decision . Element represents the fixed amount of resource consumed when setup decision is made
- : vector of resource capacities (upper bounds for all resources), where is the capacity of resource
Why Matrix Notation Matters
The matrix form is computationally efficient because solvers can use optimized linear algebra libraries to explore the feasible region and identify optimal solutions. Matrix-vector operations are highly optimized in modern computing environments, making this representation much faster than working with individual summations.
This notation also makes problem scaling transparent: adding more products increases the size of and the number of columns in , while adding more setup decisions increases the size of and the number of columns in . Understanding this structure helps you anticipate how problem complexity grows with scale.
Let's visualize the structure of a MILP problem to understand how the mathematical components map to factory decisions:
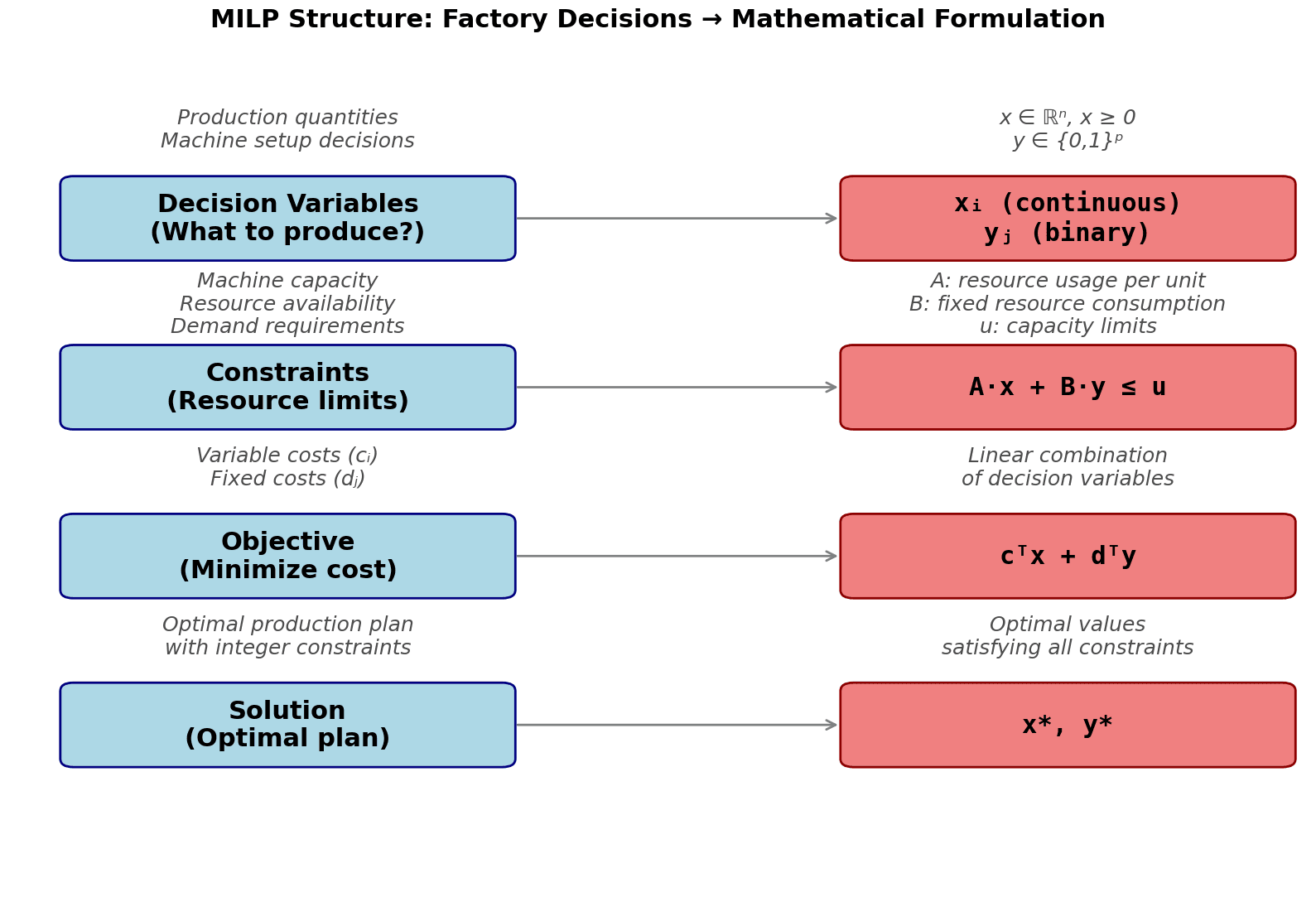
Mathematical Properties: Why MILP Is Both Powerful and Challenging
Understanding the mathematical structure of MILP problems helps explain both their power and their computational challenges. The geometry of the feasible region reveals why MILP is fundamentally different from pure linear programming.
The Geometry of Feasible Regions
The feasible region of a MILP problem has a distinctive geometric structure. Imagine first the continuous relaxation, what happens if we ignore the integer constraints and allow fractional values. This creates a polyhedron: a geometric shape with flat faces, straight edges, and sharp corners. This is the feasible region of the underlying linear program.
Now impose the integer constraints. We're no longer allowed to use any point in the polyhedron, only the integer lattice points (points with integer coordinates) that lie within it. The feasible region becomes the intersection of the polyhedron with these discrete points.
This intersection creates a non-convex feasible region, which fundamentally distinguishes MILP from pure linear programming.
Why Non-Convexity Matters
In linear programming, the feasible region is convex, which guarantees that any local optimum is also a global optimum. This property enables efficient algorithms like the simplex method that can quickly find optimal solutions by moving along edges of the polyhedron.
In MILP, the non-convexity means we cannot simply follow a gradient or use simplex-like methods. We need to explore discrete points in the feasible region, which is why MILP problems are NP-hard in general. As the number of binary variables grows, the number of potential solutions grows exponentially. With binary variables, there are possible combinations of setup decisions to consider. This exponential growth makes exact solution increasingly difficult as problems scale.
The Silver Lining: Extreme Point Property
Despite this complexity, MILP problems have an important property that makes them solvable: if an optimal solution exists, there exists an optimal solution at an extreme point of the continuous relaxation. Extreme points are the "corners" of the polyhedron, points that can't be expressed as a convex combination of other feasible points.
This means we don't need to search through all possible integer combinations. We can focus our search on the corners of the feasible polyhedron where integer solutions are most likely to be found. This property is what makes branch-and-bound algorithms effective.
How Branch-and-Bound Exploits This Structure
Branch-and-bound algorithms exploit the extreme point property by solving a series of linear programming relaxations. They systematically explore extreme points while using bounds to prune away regions that cannot contain optimal solutions. The algorithm:
- Starts with the continuous relaxation (ignoring integer constraints)
- If the solution has fractional values, branches by fixing variables to integer values
- Uses bounds from the LP relaxation to eliminate subproblems that can't be optimal
- Continues until an integer solution is found and proven optimal
The Role of Duality and Bounds
Duality theory from linear programming extends to MILP through Lagrangian relaxation, where we relax some constraints and incorporate them into the objective function with penalty terms. This approach provides bounds on the optimal solution value, which helps branch-and-bound algorithms determine when they've found a solution that's close enough to optimal.
These bounds enable more efficient solution algorithms by allowing early termination when the gap between the best known solution and the best possible solution becomes sufficiently small. For large problems where exact solution is computationally infeasible, this allows us to find high-quality solutions within acceptable time limits.
Visualizing Mixed Integer Linear Programming
Let's create visualizations to understand how MILP works in practice. We'll examine a simple factory optimization problem with two products and capacity constraints.


Now let's visualize the branch-and-bound process that MILP solvers use:

Example
Let's work through a concrete factory optimization example step by step. Consider a factory that produces two products using two machines with the following specifications:
Problem Setup:
- Product 1: requires 2 hours on Machine A, 4 hours on Machine B, profit of $3 per unit
- Product 2: requires 3 hours on Machine A, 2 hours on Machine B, profit of $2 per unit
- Machine A: 12 hours available
- Machine B: 16 hours available
- Additional constraint: We can only produce products in whole units (integer constraint)
Step 1: Define Variables
Let = number of units of Product 1 to produce Let = number of units of Product 2 to produce
Step 2: Formulate the Problem
Our objective is to maximize profit:
Subject to constraints:
- Machine A capacity:
- Machine B capacity:
- Non-negativity:
- Integer constraint:
Step 3: Solve the LP Relaxation First
If we ignore the integer constraint, we can solve this as a linear program. We need to find where the constraint boundaries intersect, which gives us the optimal solution.
From Machine A constraint: , we can express as:
From Machine B constraint: , we can express as:
To find the intersection point where both constraints are binding (satisfied with equality), we set the two expressions equal:
Multiplying both sides by 3 to eliminate the denominator:
Expanding the right side:
Rearranging terms to collect on one side:
Simplifying:
Solving for :
Substituting back into the Machine A constraint (with equality) to find :
Simplifying:
Solving for :
Verification: Let's verify this solution satisfies both constraints:
- Machine A: ✓
- Machine B: ✓
So the LP relaxation gives us with profit:
The optimal profit is \13$.
Step 4: Apply Branch-and-Bound
Since we need integer solutions, we use branch-and-bound:
Branch 1:
- New constraint:
- With fixed, from Machine A: , so , giving
- From Machine B: , so , giving
- The binding constraint is , so the solution is (this is already an integer solution)
- Profit =
Branch 2:
- New constraint:
- From Machine B: , with :
- Simplifying: , so , giving
- Since (non-negativity), we have
- Solution: (integer solution)
- Profit =
Branch 1.1: and
- With and :
- Verification: Machine A: ✓
- Verification: Machine B: ✓
- Solution: (integer solution)
- Profit =
Branch 1.2: and
- With and :
- Verification: Machine A: ✓
- Verification: Machine B: ✓
- Solution: (integer solution)
- Profit =
Step 5: Compare Integer Solutions
We have found three feasible integer solutions:
- Solution 1: , Profit =
- Solution 2: , Profit =
- Solution 3: , Profit =
Since we're maximizing profit, the optimal integer solution is Solution 3: with a profit of \13$.
Note: In this example, the LP relaxation solution happens to be an integer solution, so the integer constraint doesn't reduce the optimal value. This is not always the case. Often, integer constraints force us to accept a lower objective value than the LP relaxation.
Let's visualize this example to see the LP relaxation solution compared to the integer solutions:


Note: In this case, the LP relaxation happens to give an integer solution. However, the integer constraint ensures we only consider feasible integer points
Implementation in Google OR-Tools
Google OR-Tools provides an excellent framework for solving MILP problems with its CP-SAT solver, which is specifically designed for constraint programming and mixed integer problems. OR-Tools offers both a Python API and C++ implementation, making it accessible for data scientists while maintaining high performance.
Basic Factory Optimization
Let's start with a simple factory optimization problem that demonstrates the core MILP concepts. We'll solve the two-product problem from our earlier example using OR-Tools.
First, we set up the problem by creating a solver, defining variables, and specifying constraints:
Now let's display the results:
The solver found an optimal solution. The production quantities and profit values shown above match our earlier manual calculation. The constraint verification confirms that both machines are fully utilized, with Machine A using exactly its full capacity of 12 hours and Machine B using its full capacity of 16 hours. This full utilization indicates that the solution is efficient and that the capacity constraints are binding, meaning we cannot increase production without violating constraints. When both constraints are binding at the optimal solution, it suggests that the problem is well-formulated and that the solver has found the true optimal point where no further improvement is possible.
Advanced Factory Optimization with Setup Costs
Now let's tackle a more realistic factory optimization problem that includes setup costs and multiple products. This demonstrates how binary variables model discrete setup decisions alongside continuous production quantities.
We'll optimize production of three products across three machines, where each product requires a setup (incurring a fixed cost) before production can begin:
Let's examine the optimization results:
The optimization results demonstrate how the solver balances production quantities against setup costs. Products with higher profit margins and lower setup costs are prioritized in the optimal solution, while products that don't contribute enough to cover their setup costs may be excluded entirely. For example, if a product has a setup cost of $50 but only generates $40 in profit, the solver will set its production to zero rather than incurring a net loss.
The machine utilization percentages indicate how efficiently each machine is being used. Values near 100% suggest that machine capacity is a binding constraint, meaning that increasing capacity would allow for higher production and potentially greater profit. Lower utilization (e.g., below 80%) might indicate that other constraints, such as demand limits, setup cost trade-offs, or resource availability on other machines, are preventing full machine usage. In such cases, the bottleneck is not the machine capacity itself but rather other factors in the optimization problem.
Let's visualize the results from the advanced factory optimization:




Sensitivity Analysis
Understanding how changes in problem parameters affect optimal solutions is crucial for decision-making. Let's perform sensitivity analysis by solving the optimization problem under different scenarios:
Now let's display the sensitivity analysis results:
The sensitivity analysis reveals how parameter changes affect optimal decisions. Comparing the scenarios shown above, higher product profits generally lead to increased production and higher net profits, as the additional revenue more than compensates for setup costs. When product profits increase by 25-40% (as in the "Higher Product Profit" scenario), the solver can justify additional setups and higher production volumes.
Lower setup costs make it economically viable to produce more products, potentially increasing total production volume. When setup costs are reduced by 50% (as in the "Lower Setup Costs" scenario), products that were previously unprofitable due to high setup costs may now be included in the optimal solution. Conversely, high setup costs (doubled in the "High Setup Costs" scenario) may cause the optimizer to reduce the number of products produced, focusing only on those with the best profit-to-setup-cost ratios. This analysis helps factory managers understand which parameters have the most impact on profitability and where to focus improvement efforts, such as negotiating lower setup costs or improving production efficiency to increase profit margins.
Let's visualize the sensitivity analysis results to compare how different scenarios affect the optimal solution:


Key Parameters
Below are some of the main parameters and methods that affect how MILP solvers work and perform in Google OR-Tools:
Key Solver Parameters
-
Solver.CreateSolver(solver_name): Creates a solver instance. Common options include'SCIP'(recommended for MILP),'CBC'(open-source alternative), and'GLOP'(for linear programming only). SCIP typically provides the best performance for mixed integer problems but requires a license for commercial use. -
SetTimeLimit(seconds): Sets the maximum time in milliseconds for the solver to run (default: no limit). Use this to prevent the solver from running indefinitely on difficult problems. Typical values range from 1000-10000 milliseconds depending on problem complexity. -
SetNumThreads(n): Sets the number of threads for parallel solving (default: uses all available cores). For large problems, increasing threads can speed up solution time, but may not always improve performance due to overhead.
Key Variable Creation Methods
-
IntVar(lower_bound, upper_bound, name): Creates an integer variable with specified bounds. Usesolver.infinity()for unbounded variables. Integer variables are important for modeling discrete decisions like production quantities that should be whole numbers. -
BoolVar(name): Creates a binary variable (equivalent toIntVar(0, 1, name)). Binary variables model yes/no decisions like setup choices or machine selection. More efficient than integer variables for binary decisions. -
NumVar(lower_bound, upper_bound, name): Creates a continuous variable for quantities that can take fractional values. Use when integer constraints are not required, as continuous variables solve faster.
Key Constraint Methods
-
Constraint(lower_bound, upper_bound): Creates a linear constraint with specified bounds. Use-solver.infinity()for unbounded lower bounds andsolver.infinity()for unbounded upper bounds. The constraint is enforced as: lower_bound ≤ expression ≤ upper_bound. -
SetCoefficient(variable, coefficient): Sets the coefficient for a variable in a constraint. Call this method for each variable in the constraint expression. Coefficients can be positive or negative to model resource consumption or production.
Key Objective Methods
-
SetMaximization(): Sets the objective to maximize (default is minimization). Use for profit maximization problems. The objective function is built by setting coefficients for each variable. -
SetMinimization(): Sets the objective to minimize. Use for cost minimization problems. This is the default behavior if neither method is called. -
SetCoefficient(variable, coefficient): Sets the coefficient for a variable in the objective function. Positive coefficients for maximization problems, negative for minimization (or vice versa depending on whether you're maximizing profit or minimizing cost).
Key Solution Methods
-
Solve(): Solves the optimization problem and returns a status code. ReturnsSolver.OPTIMALif an optimal solution was found,Solver.FEASIBLEif a feasible but not necessarily optimal solution was found, or other status codes for infeasible or unbounded problems. -
solution_value(): Returns the value of a variable in the optimal solution. Call this method on each variable after a successful solve to extract the solution values. -
Objective().Value(): Returns the value of the objective function at the optimal solution. Use this to get the total profit or cost after solving.
Practical Applications
Practical Implications
MILP is particularly valuable in production planning and scheduling scenarios where factories need to make discrete decisions about which products to produce while optimizing continuous production quantities. This dual nature makes MILP well-suited for make-to-order manufacturing environments where demand varies significantly and setup costs are substantial. The ability to model both binary setup decisions and continuous production quantities in a single optimization framework allows factory managers to balance the trade-off between setup costs and production efficiency. For example, in job shop manufacturing where each order requires machine setup, MILP can determine which orders to accept and in what sequence to maximize profit while respecting capacity constraints.
The method is also effective for capacity planning and resource allocation problems where factories need to decide whether to invest in additional machines or production lines. MILP can model these strategic decisions alongside tactical production scheduling, enabling integrated optimization of both short-term operations and long-term investments. This integrated approach is particularly valuable in industries with high capital costs and complex production interdependencies, such as automotive manufacturing, semiconductor production, and chemical processing. In these contexts, the ability to simultaneously optimize production schedules and capacity investments can lead to significant cost savings compared to sequential decision-making approaches.
MILP becomes less appropriate when problems scale beyond several hundred integer variables, as computational time grows exponentially with the number of discrete decisions. For very large-scale problems with thousands of products and machines, decomposition methods or heuristic approaches may be more practical. Additionally, if the relationships between variables are highly nonlinear, MILP's linearity assumption may require significant approximation that compromises solution quality. In such cases, nonlinear programming or specialized algorithms designed for the specific problem structure may provide better results.
Best Practices
To achieve effective MILP solutions, start by carefully modeling the problem structure. Use binary variables for setup decisions, machine selection, and other yes/no choices, while reserving continuous variables for production quantities and resource allocations. When modeling setup costs, ensure that binary variables are properly linked to production variables using big-M constraints with appropriately sized M values. Calculate M based on problem-specific bounds rather than using arbitrarily large numbers. For example, if maximum production capacity for a product is 100 units, use M=100 rather than M=10000. This prevents numerical instability and improves solver performance by creating tighter linear relaxations.
For solver selection, commercial solvers like Gurobi or CPLEX often provide superior performance and reliability for production systems, though they require licensing fees. When using open-source solvers like SCIP or CBC, configure appropriate parameters to balance solution quality and computational time. Set time limits based on problem size: 300-600 seconds for problems with fewer than 100 integer variables, 600-1800 seconds for problems with 100-500 variables, and consider longer limits or decomposition strategies for larger problems. Set optimality gap tolerances between 0.01 and 0.05 (1-5%) depending on your solution quality requirements. For problems where near-optimal solutions are acceptable, larger gaps (0.05-0.10) can significantly reduce solve times. Validate solutions by checking constraint satisfaction and comparing against known feasible solutions or historical performance data.
When formulating constraints, avoid redundant constraints that don't tighten the feasible region, as they can slow down the solver without providing benefit. Use constraint aggregation where possible to reduce the number of constraints, but be careful not to lose important problem structure that could help the solver prune the search space. For multi-period problems, consider time-indexed formulations that explicitly model temporal relationships, as these often provide tighter linear relaxations than alternative formulations. When modeling capacity constraints, include both aggregate and detailed constraints when they provide complementary information, but remove constraints that are dominated by others.
Data Requirements and Preprocessing
MILP models require accurate data on production times, machine capacities, setup costs, and demand forecasts. Production time estimates should be standardized across all products and machines, using consistent units (typically hours) and accounting for variability through buffer times or stochastic modeling. Machine capacities should reflect actual available time rather than theoretical maximums, accounting for maintenance windows, shift schedules, and other operational constraints. For example, if a machine operates 8 hours per shift with 30 minutes of scheduled maintenance, use 7.5 hours as the capacity rather than the full 8 hours. Setup costs should include both direct costs (labor, materials) and opportunity costs (lost production time), as omitting opportunity costs can lead to suboptimal solutions that minimize direct expenses but reduce overall throughput.
Demand forecasts require careful preprocessing to ensure they represent realistic production requirements. Aggregate demand data to appropriate time buckets that match the optimization horizon, and validate forecasts against historical patterns to identify potential anomalies. For multi-product scenarios, ensure demand data includes product mix requirements and any dependencies between products. When demand uncertainty is significant, consider robust optimization approaches or scenario-based formulations rather than relying solely on point forecasts. For time-indexed problems, ensure demand data is aligned with the time period structure of the model, and handle any missing or incomplete data through appropriate imputation methods or constraint adjustments.
Data quality directly impacts solution quality, so invest in robust data collection systems that capture production times, machine utilization, and setup activities accurately. Implement data validation checks to identify outliers or inconsistencies before optimization runs. For production time data, flag values that deviate more than 20% from historical averages for manual review. Regular calibration of model parameters against actual performance data helps maintain accuracy as production conditions evolve. Compare model predictions to actual outcomes monthly or quarterly, and adjust parameters when systematic discrepancies exceed 5-10%. Standardize data collection procedures across different production lines or facilities to ensure consistency when scaling models to multiple locations.
Common Pitfalls
One frequent mistake is using overly large big-M values when linking binary and continuous variables, which creates weak linear relaxations and slows solver performance. Instead, calculate M values based on problem-specific bounds. For example, if maximum production is 100 units, use M=100 rather than M=10000. Another common issue is failing to properly model setup constraints, leading to solutions where production occurs without corresponding setup activities. Include explicit constraints that force binary setup variables to equal 1 when production quantities are positive, using constraints of the form where is production and is the setup binary variable. Additionally, ensure that setup costs are only incurred when the binary variable equals 1, not when production is positive.
Neglecting to validate that solutions are actually implementable in the factory can lead to theoretically optimal but practically infeasible plans. Solutions may violate constraints that weren't explicitly modeled, such as material handling limitations, worker availability, or quality control requirements. Review solutions with production managers and validate against physical constraints before implementation. Additionally, beware of over-optimizing on cost metrics while ignoring other important objectives like delivery reliability or quality, which may require multi-objective formulations or constraint-based approaches. A solution that minimizes cost but consistently misses delivery deadlines may be worse than a slightly more expensive but reliable alternative.
Another pitfall is assuming that the optimal solution will remain optimal as conditions change. MILP solutions are sensitive to parameter values, and small changes in costs, capacities, or demands can significantly alter optimal decisions. Perform sensitivity analysis to understand solution robustness and identify key parameters that require careful monitoring. For example, if a 5% change in setup costs causes a 20% change in the optimal solution, those setup costs are key parameters that need accurate estimation. Finally, avoid the temptation to model every detail of the production system, as overly complex models become difficult to solve and maintain. Focus on the most important constraints and decisions that drive optimization value, typically the top 20% of constraints that have the most impact on the objective function.
Computational Considerations
MILP computational complexity grows exponentially with the number of integer variables, making problem size a key consideration. For problems with fewer than 100 integer variables, most modern solvers can find optimal solutions within minutes on standard hardware. Problems with 100-500 integer variables may require several minutes to hours depending on problem structure, while problems with more than 500 integer variables often require decomposition strategies or heuristic methods. The number of continuous variables has less impact on computational time, as linear programming relaxations solve efficiently even with thousands of continuous variables. As a rule of thumb, if your problem has more than 1000 integer variables or requires more than 1 hour to solve, consider decomposition or approximation methods.
Problem structure significantly affects solver performance. Problems with tight linear relaxations (where the LP relaxation provides a good bound) solve much faster than problems with weak relaxations. To improve performance, focus on formulating constraints that create tight bounds, such as using aggregated capacity constraints alongside detailed resource constraints. Symmetry in the problem formulation can also slow down branch-and-bound algorithms, so break symmetry by adding constraints that eliminate equivalent solutions or by using specialized branching strategies. For example, if products are identical except for labels, add constraints that order them by index to eliminate symmetric solutions.
For large-scale problems, consider decomposition approaches such as Benders decomposition or Lagrangian relaxation that separate the problem into more manageable subproblems. Time-indexed formulations can be decomposed by time period, while multi-product problems can sometimes be decomposed by product family. When exact solutions are computationally infeasible, use heuristic methods like local search or genetic algorithms, or employ hybrid approaches that use MILP for strategic decisions and heuristics for detailed scheduling. Set appropriate solver parameters including time limits (300-1800 seconds for medium problems), memory limits (4-16 GB depending on problem size), and optimality gap tolerances (0.01-0.05) based on your computational resources and solution quality requirements. For problems that consistently hit time limits, consider increasing the optimality gap tolerance to 0.10 to obtain feasible solutions more quickly.
Performance and Deployment Considerations
Evaluate MILP solutions using both optimization metrics and practical performance indicators. Optimization metrics include the objective function value, optimality gap (difference between best solution and best bound, typically expressed as a percentage), and constraint satisfaction. However, these metrics alone don't guarantee practical success. Compare optimized solutions against baseline performance using key operational metrics such as on-time delivery rates, machine utilization, inventory levels, and overall equipment effectiveness (OEE). A solution with a 10% improvement in the objective function but a 5% decrease in on-time delivery may not be acceptable. Validate that theoretical improvements translate to actual performance gains through pilot implementations before full-scale deployment, typically running parallel systems for 2-4 weeks to compare outcomes.
Deploy MILP models in production environments by integrating with existing enterprise systems including ERP, MES, and supply chain management platforms. This integration ensures optimization runs use real-time data and that optimized schedules can be automatically executed in production systems. Implement automated data pipelines that extract required parameters from source systems, run optimization models on a regular schedule (typically daily or weekly depending on planning horizon), and push results back to execution systems. Include validation checks that flag solutions with unusual characteristics (e.g., production quantities more than 20% different from historical averages) or constraint violations before deployment. Set up automated alerts for cases where the solver fails to find a feasible solution or exceeds time limits.
Monitor model performance continuously to detect when updates are needed. Track the gap between predicted and actual production times, machine utilization, and setup durations to identify when model parameters require recalibration. If actual production times consistently differ from model predictions by more than 10%, recalibrate the model parameters. Establish triggers for model updates based on significant changes in production capabilities (new machines, capacity changes), introduction of new products, machine modifications, or shifts in market conditions (demand patterns, cost structures). Maintain version control for models and document changes to enable rollback if new versions perform worse than previous ones. Regular performance reviews comparing optimized plans against actual outcomes (monthly or quarterly) help identify improvement opportunities and validate that the optimization system continues to deliver value.
Summary
Mixed Integer Linear Programming provides a powerful framework for factory optimization that balances mathematical rigor with practical applicability. By combining continuous optimization for production quantities with discrete decision-making for setup and capacity choices, MILP addresses the fundamental challenges of manufacturing optimization in a unified framework.
The key strength of MILP lies in its ability to handle both tactical production decisions and strategic capacity planning within a single optimization model. This integrated approach enables factory managers to optimize not just individual production runs but also long-term resource allocation and investment decisions. The mathematical guarantees of optimality (within computational limits) provide confidence in decision-making for high-stakes manufacturing scenarios.
However, successful MILP implementation requires careful attention to data quality, model validation, and computational scalability. The exponential complexity of large-scale MILP problems means that practical applications often require problem decomposition, heuristic methods, or hybrid approaches that combine exact optimization with approximation techniques. Despite these challenges, MILP remains an important tool for factory optimization, providing the mathematical foundation for evidence-based manufacturing decisions that can significantly improve operational efficiency and profitability.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about Mixed Integer Linear Programming for factory optimization.




Comments