

A comprehensive guide to choosing the right approach for your LLM project: using pre-trained models as-is, enhancing them with context injection and RAG, or specializing them through fine-tuning. Learn the trade-offs, costs, and when each method works best.
There are four main approaches to adapting Large Language Models:
-
Off-the-Shelf: Use pre-trained model as-is.
- Zero setup
- Generic answers, no custom knowledge
-
Prompt Engineering: Customize behavior with smart prompts.
-
Off-the-Shelf: Use pre-trained model as-is.
- Zero setup
- Generic answers, no custom knowledge
-
Prompt Engineering: Customize behavior with smart prompts.
- Fast iteration, no training needed
- Limited control, context length caps, inconsistent results
-
RAG (Retrieval-Augmented Generation): Inject real-time data into prompts.
- Up-to-date, accurate, privacy-friendly, grounded outputs
- Needs vector DB infra, slower response, context limits
-
Fine-Tuning: Train the model on your own data.
- Highest task performance, consistency, offline capable
- Expensive, static knowledge, re-training needed for updates
Decision Flow:
- Start Off-the-Shelf to explore.
- Add Prompt Engineering for simple control/customization.
- Use RAG when accuracy, freshness, and scale matter.
- Choose Fine-Tuning for high-volume, static, specialized tasks.
Often, combining methods (e.g., fine-tune + RAG) works best.
Introduction
Large Language Models (LLMs) have become incredibly powerful and accessible, but using them 'off-the-shelf' is just the beginning. To truly unlock their potential for specific tasks, you need to choose the right strategy for embedding specialized knowledge or behavior.
This guide explores the three primary approaches:
- Using off-the-shelf models as-is - leveraging pre-trained capabilities without modification
- Context injection - enhancing responses with runtime information via prompt engineering and RAG
- Fine-tuning - fundamentally altering model weights through specialized training
Note: Pre-training is not covered here, as it is neither practical for most organizations nor necessary for the vast majority of use cases.
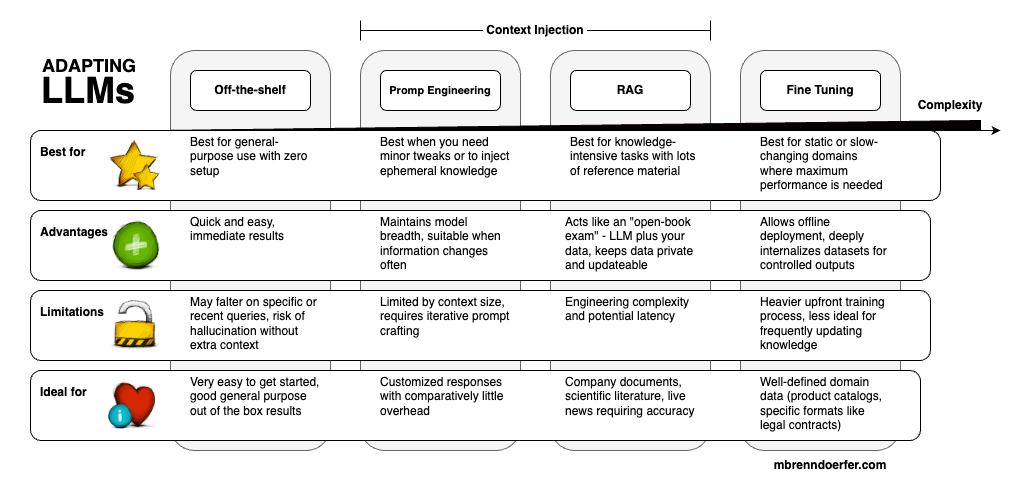
We'll dive into the when, why, and how of each method, comparing their trade-offs in performance, cost, and complexity to help you decide which path is right for your project. Below you see an initial overview of the four main approaches to adapting Large Language Models.
Off-the-Shelf Usage
Using a pre-trained model (like OpenAI, Antrophic, or Google) "Off-the-Shelf" means you feed it a prompt and get an answer with no modifications to the model.
This is the quickest way to leverage an LLM's general knowledge and abilities. This is what most people refer to when they say "using an LLM".
When to Use Off-the-Shelf Models
- General Knowledge Suffices: The model's existing training data covers your needs (casual Q&A, general writing)
- No Domain-Specific Data: You don't have custom data or strict requirements for style/accuracy
- Fast Prototyping: You want immediate results without any training or setup
Limitations
Off-the-shelf models can be inaccurate for niche or up-to-date queries, since they only know what was in their training set. They might hallucinate (make up facts) if asked about information not in their knowledge base.
Example: An unmodified model might not know about a policy your company introduced this month and could "guess" an answer incorrectly.
Control Issues: You have limited control over style or behavior beyond what prompt wording can influence.
Context Injection (Prompt Engineering & RAG)
Instead of altering the model, you provide additional context in the prompt to guide its response. This can range from simple prompt engineering to full Retrieval-Augmented Generation (RAG) pipelines.
Prompt Engineering
You include instructions or background info directly in the prompt.
Examples:
- Prepending "You are an expert financial advisor..." (role setting)
- Supplying a few Q&A examples to shape the model's style and behavior (few-shot learning)
Benefits:
- Requires no training - you're essentially programming the model with natural language
- Easy to adjust and iterate
Limitations:
- Prompt tweaks can yield different results
- The model may ignore or misinterpret instructions if they conflict with its training
Retrieval-Augmented Generation (RAG)
This is a more advanced form of context injection where the model is coupled with an external knowledge base.
How it Works: When a query comes in, you retrieve relevant documents (e.g. from your proprietary data or latest information) and prepend them to the model's prompt as context. The model then generates an answer using both its built-in knowledge and the provided text.
Why it's Powerful: RAG "plugs" the LLM into fresh or private data that it otherwise wouldn't have. Importantly, the base model itself isn't changed - you're just feeding it helpful data each time.
Advantages of Context Injection
- Preserved Capabilities: Maintains the model's broad abilities (since you don't alter its weights)
- Current Knowledge: Ensures up-to-date, specific knowledge is available when needed
- Reduced Hallucinations: RAG provides grounded answers from real documents
- Privacy-Friendly: Keeps private data out of model weights - documents remain in a separate database
- Easy Updates: If your knowledge changes, just update documents without retraining
Disadvantages of Context Injection
- Context Limits: You can only feed so much text before hitting the prompt length limit (context size is becoming less of a problem, but long context show deteroation in performance)
- Engineering Complexity: Requires embedding index, vector search, and retrieval infrastructure
- Latency Issues: Each query requires re-supplying context, which can increase response time and cost
- Inconsistency: Prompt engineering may not work for very specialized tasks or yield inconsistent results
Fine-Tuning
Fine-tuning means actually training the model further on your own data so it internalizes new knowledge or behaviors. This adjusts the model's weights to specialize it for a task or domain.
When to Use Fine-Tuning
Specialized Performance is Required
- You have a specific task or domain where you need the model to excel consistently
- Example: A medical chatbot that must use correct medical terminology and reliably follow clinical guidelines
- Example: A customer service bot that uses your company's tone and product info
- A fine-tuned model can "learn" the style, terminology, and facts from your data
Frequent Reuse of the Same Task
- You will be asking the model to do the same type of task repeatedly
- Example: Always summarizing legal documents in a certain format
- Fine-tuning embeds that capability so you don't have to provide lengthy instructions every time
- The model becomes an expert in that specific task
When Prompting or RAG Falls Short
- Your task requires reasoning or formatting that the base model struggles with even when given context
- Example: Teaching the model to follow a specific output template
- Example: Injecting a large set of Q&A pairs that cover edge cases
Advantages of Fine-Tuning
- Maximum Performance: Tailor-made model often outperforms the base model on your specific task
- Efficiency: A smaller fine-tuned model might match a much larger one on that narrow task
- Consistency: The model handles your use-case predictably without needing complex prompts
- Cost Optimization: A fine-tuned smaller model might be faster and cheaper than using a giant model with prompts
Disadvantages of Fine-Tuning
- High Setup Costs: Requires obtaining a high-quality training dataset (labor-intensive) and computational resources
- Time Investment: Can be expensive and time-consuming, often needing GPUs/TPUs and careful training
- Catastrophic Forgetting: The model might become too specialized and lose general abilities
- Example: A model fine-tuned heavily on legal text might get better at legal Q&A but worse at casual conversation
- Static Knowledge: Once fine-tuned, the model's knowledge is fixed to the training data
- No Source Attribution: Unlike RAG, doesn't provide source citations - just generates from "memorized" knowledge
- Privacy Considerations: All fine-tuned knowledge is baked into the model weights
Adapting LLMs: Summary of Methods
Off-the-Shelf Models
- Best for: General-purpose use with zero setup
- Advantages: Quick and easy, immediate results
- Limitations: May falter on specific or recent queries, risk of hallucination without extra context
Prompt Engineering
- Best for: Minor tweaks or injecting ephemeral knowledge
- Advantages: Maintains model breadth while providing guidance, suitable when information changes often
- Limitations: Limited by context size, requires iterative prompt crafting
RAG (Retrieval-Augmented Generation)
- Best for: Knowledge-intensive tasks with lots of reference material
- Advantages: Acts like an "open-book exam" - combines model capabilities with your data, keeps data private and updateable
- Limitations: Engineering complexity and potential latency
- Ideal for: Company documents, scientific literature, live news requiring accuracy
Fine-Tuning
- Best for: Static or slow-changing domains where maximum performance is needed
- Advantages: Allows offline deployment, deeply internalizes datasets for controlled outputs
- Limitations: Heavy upfront training process, less ideal for frequently updating knowledge
- Ideal for: Well-defined domain data (product catalogs, specific formats like legal contracts)
In practice, these approaches can be combined. For example, you might fine-tune a base model on general instruction-following or your brand's tone, and still use RAG to provide live data for factual quer
Fine-tuning can also be done after building a RAG pipeline: you could fine-tune the model on examples of using retrieved documents, to help it better integrate external info (though it then starts to blur into the model's weights).
Deciding which path to take depends on your specific needs in terms of accuracy, data freshness, compute budget, privacy, and development effort.
Comparison Table: Methods, Pros, Cons & Trade-offs
| Method | Setup Complexity | Performance | Maintenance | Cost | Best For | Key Pros | Key Cons |
|---|---|---|---|---|---|---|---|
| Off-the-Shelf | Minimal | Good for general tasks | None | Very Low (API calls only) | General-purpose tasks, Quick prototyping, Broad knowledge queries | Zero setup required, Immediate results, Full model capabilities, No training data needed | May hallucinate on specific topics, No domain-specific knowledge, Limited customization, Relies on training data cutoff |
| Prompt Engineering | Low | Good with right prompts | Low (prompt updates) | Low (API calls only) | Simple customization, Format control, Few-shot learning | Quick to implement, No training required, Maintains model breadth, Easy to iterate | Limited by context window, Inconsistent results, Prompt engineering skills needed, Can be prompt-sensitive |
| RAG | Moderate | Excellent for knowledge tasks | Moderate (data updates) | Moderate (infrastructure + API) | Knowledge-intensive tasks, Up-to-date information, Verifiable answers, Large document bases | Always current data, Preserves model abilities, Source attribution, Scalable knowledge base, Privacy-friendly data storage | Engineering complexity, Retrieval latency, Quality depends on retrieval, Requires embedding infrastructure, Context window limitations |
| Fine-Tuning | High | Excellent for specific tasks | High (retraining needed) | High (compute + data prep) | Specialized domains, Consistent style/format, Offline deployment, Performance-critical tasks | Maximum task performance, Consistent outputs, Smaller models possible, No runtime data fetching, Complete privacy | Expensive to train, Risk of catastrophic forgetting, Static knowledge (gets stale), Requires quality training data, Long development cycle |
Decision Framework
- Start with Off-the-Shelf if you're exploring capabilities or have general-purpose needs
- Add Prompt Engineering when you need basic customization or format control
- Implement RAG when you need current, verifiable information from large knowledge bases
- Use Fine-Tuning when you need maximum performance on a specific, well-defined task with static requirements
Cost & Complexity Spectrum
Off-the-Shelf → Prompt Engineering → RAG → Fine-Tuning
↑ ↑
Lowest cost/complexity Highest cost/complexity
Least specialized Most specialized
Practical Examples: Three Approaches Compared
To solidify the concepts, let's walk through a scenario with three approaches. Imagine you want an AI assistant to answer questions about your company's internal policies. You have a policy document that employees might ask about (e.g., parental leave policy).
Scenario: "What is the parental leave policy at our company?"
Off-the-Shelf Model
You take a base pre-trained model (no fine-tuning, no added context). The model, not having seen your company's policy in its training data, will likely respond with a generic answer or "I'm not sure".
- Response: "Companies typically offer 12 weeks of parental leave" - but that's just a guess.
- Issue: The off-the-shelf model has no knowledge of your specific company, so it either produces a generic policy or hallucinates details, which could be incorrect.
Context Injection (RAG/Prompt Engineering)
You use the context injection approach. You retrieve the actual policy text from your internal knowledge base. For example, the policy document says "Acme Corp provides 16 weeks of paid parental leave for primary caregivers."
Your system prepends this to the model prompt: "[Policy Excerpt]: Acme Corp provides 16 weeks of paid parental leave for primary caregivers... [User's question]: What is our company's parental leave policy?"
- Response: "Our company offers 16 weeks of paid parental leave for primary caregivers."
- Benefits: This answer is accurate and company-specific, thanks to the retrieved context. The model is effectively reading from your data and formatting the answer in natural language. If the policy changes (say to 20 weeks next year), your RAG-based assistant will pick up the new text automatically - you just update the document in the database.
Fine-Tuned Model
You create a fine-tuning dataset with questions like "What is the parental leave policy?" paired with the correct answer from your policy docs. You fine-tune the model on hundreds of such Q&A pairs covering all your company policies.
- Response: "We offer 16 weeks paid leave for primary caregivers, and 8 weeks for secondary caregivers," with the exact phrasing it learned.
- Benefits: You don't need to provide the policy text at runtime - the info is now in the model's weights. This fine-tuned model will likely respond faster (no retrieval step) and in a style consistent with your training data.
- Limitations: If the policy changes to 20 weeks, the fine-tuned model will still say 16 weeks until you update your training data and re-train. The model won't cite a source or show how it knows the answer - it just "knows".
Example Summary
- Off-the-Shelf, our model didn't know the answer.
- With context (RAG), the model gave the right answer because we fed it the info on the fly.
- With fine-tuning, the model learned the answer and could respond on its own, but was locked to the info it was trained on (requiring re-training for updates).
Each approach has a place: if you only have a handful of well-defined queries and they rarely change, fine-tuning can be great. If you have lots of documents and need any arbitrary question answered from them, RAG is more flexible. And if you're just exploring general capabilities or don't have custom data yet, using the base model with a bit of prompt engineering is the quickest way to get started.
To illustrate the difference in outputs, consider a concrete Q&A example with a fictitious scenario:
User question: "How do I reset my VPN password in our company network?"
- Base Model (no context): "I'm sorry, I don't have information on that." (It doesn't know company-specific procedures and might apologize or give a generic suggestion that could be incorrect.)
- With RAG context: "According to our IT policy: Go to the VPN portal, click 'Forgot Password', then enter your work email. You'll receive a reset link via email to set a new password.” (Here the assistant pulled the exact steps from the internal IT document and presented them. This answer is accurate and complete, reflecting current internal procedures.)
- Fine-Tuned model: "To reset your VPN password, go to the company's VPN login page and use the 'Forgot Password' option. Follow the emailed link to set a new password. Contact IT support if you run into issues." (This answer was generated from the model's trained knowledge. It's very similar to the RAG answer because we trained the model on that IT policy. It's correct - assuming the policy hasn't changed. The style might be a bit more streamlined since the model learned how such answers typically look. But if the process changes, this answer would not automatically update.)
In practice, building a robust solution might involve a combination: you could fine-tune the model on general company Q&A and conversation style (so it knows how to answer questions politely and in-depth), and use RAG to inject specific facts that change often or weren't in the fine-tuning data. This hybrid approach is common in production systems.
Conclusion
In summary, you have a spectrum of tools for leveraging and adapting pre-trained models:
- Using an LLM as-is is fastest to get started, but you rely on its existing knowledge.
- Prompt engineering lets you coax the model's behavior or provide one-off context, which is great for experimentation and minor tweaks.
- Retrieval-Augmented Generation turns the model into a question-answering system that can draw from an external knowledge source, making it far more accurate on proprietary or updated information. It's often the choice when you need factual correctness and updatability without altering the model.
- Fine-tuning actually instills new knowledge or behaviors into the model itself, yielding a custom model for your task. It's the way to go for long-term, repeated tasks where you want the best performance and are willing to invest in training. The model can be as private as your data (since you run it locally) and as tailored as your training set.
Each approach has trade-offs in development effort, performance, and maintenance. Often, it's not either-or: you might start with prompt tweaks, move to RAG when you accumulate a lot of data, and decide to fine-tune once you have a stable dataset and need better quality or efficiency.
By understanding these options, you can choose the strategy that fits your project's needs and constraints, whether that's calling an open-source model with a clever prompt, setting up a retrieval index for it, or diving into fine-tuning workflows.

Comments