

A comprehensive guide to CatBoost (Categorical Boosting), including categorical feature handling, target statistics, symmetric trees, ordered boosting, regularization techniques, and practical implementation with mixed data types.

This article is part of the free-to-read Machine Learning from Scratch
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
CatBoost
CatBoost (Categorical Boosting) is a gradient boosting framework developed by Yandex that addresses several limitations found in traditional gradient boosting implementations like XGBoost and LightGBM. While we've explored the fundamental concepts of boosted trees, CatBoost introduces features that make it effective for handling categorical features and achieving robust performance with minimal hyperparameter tuning.
The framework's name reflects its primary strength: handling of categorical variables without requiring extensive preprocessing. Unlike other gradient boosting libraries that require categorical features to be encoded (one-hot encoding, label encoding, etc.), CatBoost can work directly with categorical data, automatically learning optimal encoding strategies during training. This capability, combined with its regularization techniques and symmetric tree structure, makes CatBoost well-suited for datasets with mixed data types and when you need reliable performance with minimal manual intervention.
CatBoost addresses overfitting issues through its "oblivious trees" (symmetric trees) and regularization methods. The framework's design philosophy emphasizes robustness and ease of use, making it valuable for practitioners who want strong performance without extensive hyperparameter optimization.
Advantages
CatBoost's main advantage lies in its native handling of categorical features. Traditional gradient boosting frameworks often require categorical variables to be preprocessed through encoding schemes like one-hot encoding or label encoding, which can lead to high-dimensional sparse matrices and potential overfitting. CatBoost eliminates this preprocessing step by implementing categorical feature processing algorithms that learn optimal encodings during training, often resulting in better performance and reduced computational overhead.
The framework's symmetric tree structure (oblivious trees) provides another advantage by reducing overfitting and improving generalization. Unlike traditional decision trees where each node can have different splitting criteria, oblivious trees use the same feature for splitting at each level of the tree. This constraint helps prevent overfitting and creates more robust models that generalize better to unseen data. Additionally, CatBoost's built-in regularization techniques, including gradient-based regularization and feature combinations, provide protection against overfitting without requiring extensive hyperparameter tuning.
CatBoost performs well in scenarios requiring minimal manual intervention. The framework includes default parameters that work well across a range of datasets, reducing the need for extensive hyperparameter optimization. This makes it valuable for practitioners who need reliable performance quickly or for automated machine learning pipelines where manual tuning isn't feasible.
Disadvantages
CatBoost has several limitations that practitioners should consider. The main drawback is its computational efficiency compared to other gradient boosting frameworks. CatBoost's categorical feature processing and symmetric tree structure, while beneficial for model quality, result in slower training times compared to XGBoost and LightGBM. This performance gap becomes more pronounced with large datasets, making CatBoost less suitable for scenarios where training speed is critical.
The framework's memory usage can be substantial, particularly when dealing with high-cardinality categorical features. While CatBoost's automatic categorical processing is convenient, it can consume more memory than preprocessed alternatives, potentially limiting its applicability on memory-constrained systems or very large datasets. Additionally, the symmetric tree structure, while beneficial for generalization, can be less flexible than traditional decision trees, potentially limiting the model's ability to capture complex interactions in some datasets.
Another consideration is CatBoost's smaller ecosystem compared to XGBoost. While the framework is well-documented and actively maintained, it has fewer third-party integrations, community resources, and specialized tools compared to the more established XGBoost ecosystem. This can make it more challenging to find solutions to specific problems or integrate CatBoost into existing machine learning pipelines.
Formula
CatBoost builds upon the fundamental gradient boosting framework we've already explored, but introduces several key modifications to the standard gradient boosting formula. Let's examine how CatBoost's approach differs from traditional gradient boosting implementations.
The core gradient boosting formula remains the same foundation:
where:
- : The ensemble model at iteration (cumulative prediction after adding trees)
- : The ensemble model from the previous iteration (cumulative prediction after trees)
- : The learning rate at iteration (controls the contribution of each new tree)
- : The new tree added at iteration (trained on residuals or gradients)
- : Input feature vector for a given observation
However, CatBoost modifies how we compute the gradients and how we build the trees.
Categorical Feature Processing:
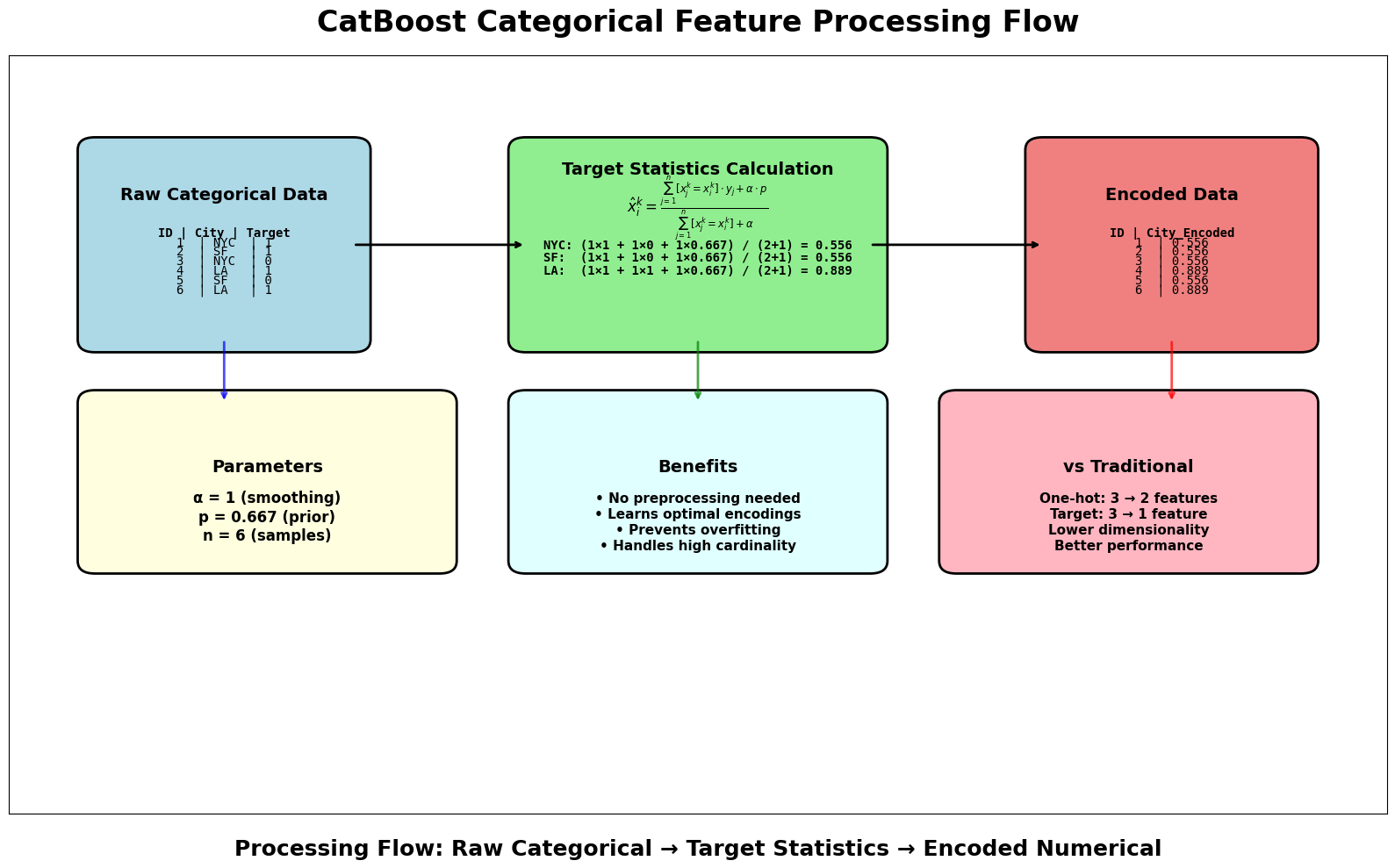
CatBoost's most distinctive feature is its handling of categorical variables. Instead of preprocessing categorical features, CatBoost computes target statistics during training. For a categorical feature with categories , CatBoost computes an encoded value for each observation as follows:
where:
- : The encoded numerical value for the -th observation's category in feature
- : The categorical value of feature for observation
- : Indicator function that equals 1 if observation has the same category as observation , and 0 otherwise
- : The target value for observation
- : Total number of observations in the dataset
- : Smoothing parameter that controls regularization (typically set to 1)
- : Prior probability of the target (usually the mean of the target variable across the entire dataset)
Numerator:
adds up the target values for all observations that share the same category as the -th observation. The term is added to introduce smoothing, pulling the encoding towards the global mean when there are few samples for a category.
Denominator:
counts how many times the category appears in the dataset. Adding to the denominator ensures the encoding is well-defined even for rare categories and further smooths the result.
This formula computes a smoothed mean target value for each category. For each observation, the encoded value is the average target for its category, but "shrunk" towards the overall mean according to the smoothing parameter . This helps prevent overfitting, especially for categories that appear infrequently.
CatBoost uses this dynamic, smoothed target encoding for categorical features during training. By combining the mean target value for each category with the global mean, CatBoost creates robust numerical representations of categorical variables that capture their relationship with the target variable, while reducing the risk of overfitting.
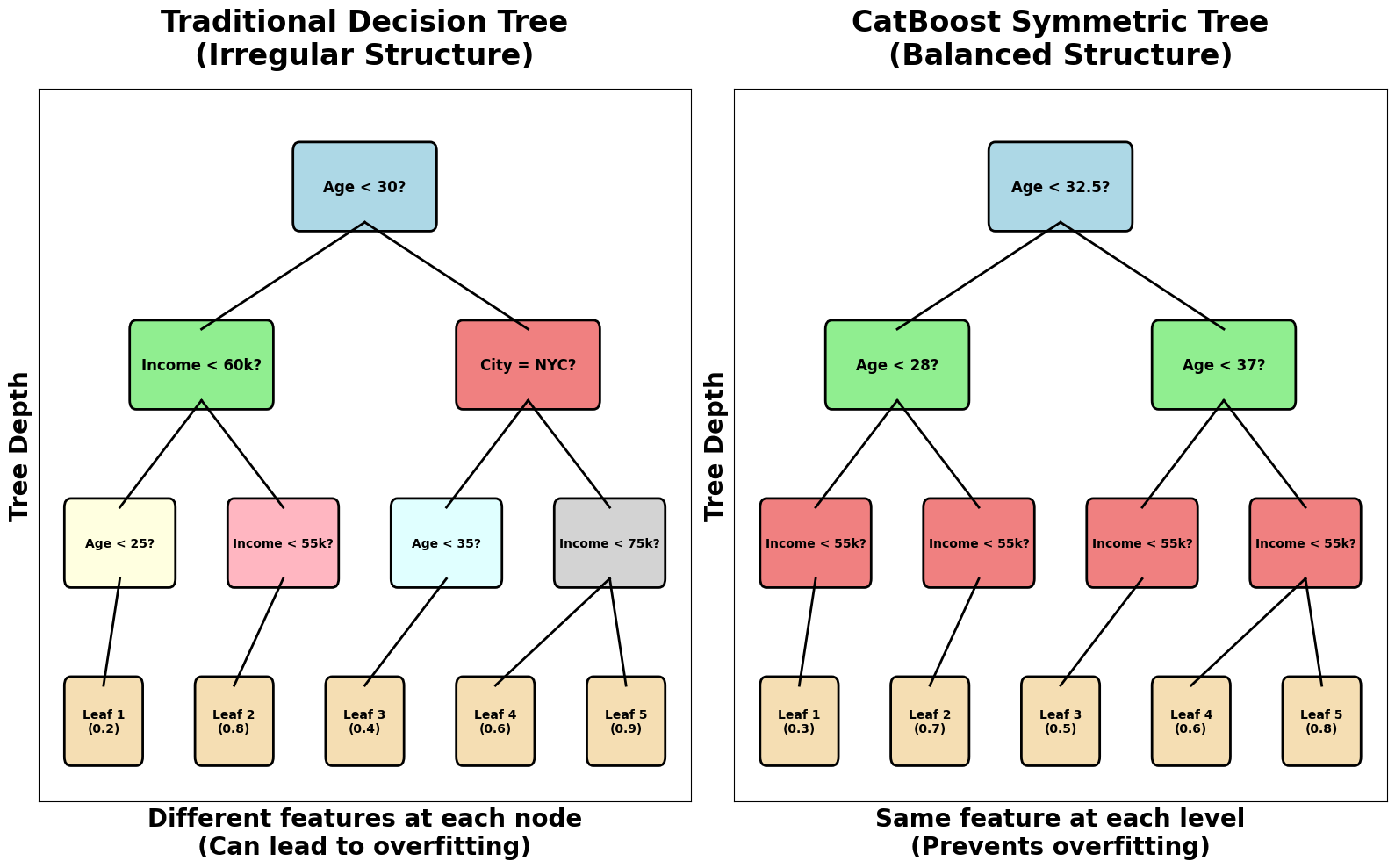
Symmetric Trees (Oblivious Trees):
CatBoost uses symmetric trees, also known as oblivious trees, where all nodes at the same depth (level) split on the same feature and threshold. This is in contrast to traditional decision trees, where each node can split on any feature independently. In a symmetric tree of depth , there are binary splits, and thus leaf nodes. The structure of the tree is fully determined by the sequence of features (and their thresholds) chosen for each level.
Let's formalize the prediction function for a symmetric tree.
Suppose the -th tree in the ensemble has depth , and at each level (), the tree splits on feature at threshold . For an input , we can define a binary decision at each level:
where:
- : Binary decision at level for input (0 for left branch, 1 for right branch)
- : Value of feature in input vector
- : Feature index used for splitting at level
- : Threshold value for the split at level
The path from the root to a leaf is determined by the vector of decisions . This vector can be interpreted as a binary number, which uniquely identifies one of the leaves. The index of the leaf node for input can be computed as:
where:
- : Index of the leaf node that input reaches (ranges from 1 to , or 0 to if zero-indexed)
- : Depth of the symmetric tree (number of levels)
- : Binary weight for the decision at level
The prediction of the -th symmetric tree for input is then:
where:
- : Prediction of the -th tree for input
- : The value (prediction) assigned to leaf in tree
- : The leaf index reached by input (computed using the formula above)
Alternatively, this can be written in indicator function notation as:
where:
-
: The region (set of all inputs ) corresponding to leaf in tree
-
: Indicator function that equals 1 if falls into region , and 0 otherwise
-
: Total number of leaves in the symmetric tree of depth
-
Each input is routed through binary splits (same feature per level for all nodes at that level).
-
The sequence of split decisions forms a binary code that selects one of leaves.
-
The output is the value assigned to that leaf.
This structure ensures that the tree is perfectly balanced and that the same features are considered at each level, which helps regularize the model and reduce overfitting.
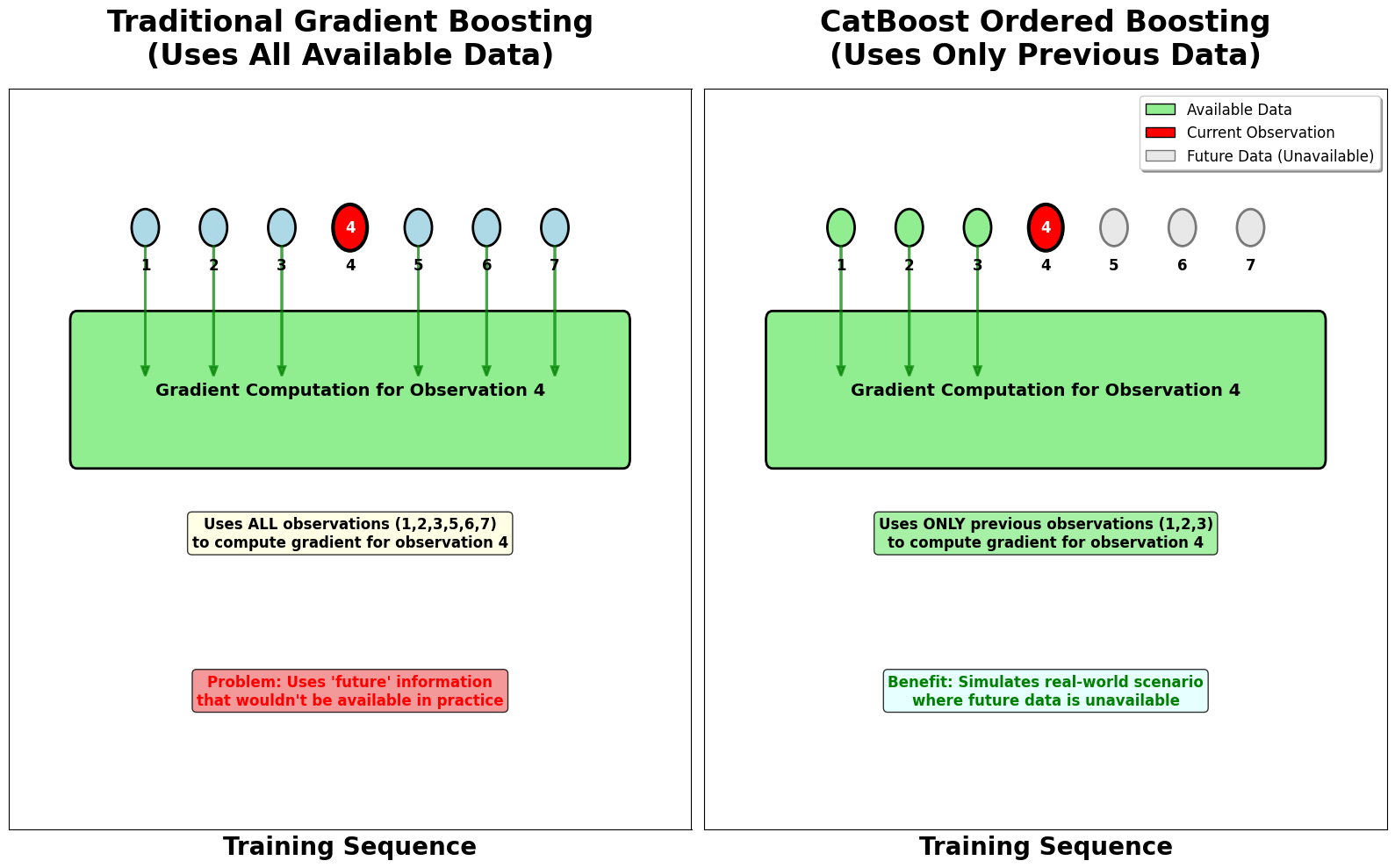
Gradient Computation with Ordered Boosting:
CatBoost implements a technique called "ordered boosting" to reduce overfitting. Instead of using all available data to compute gradients, CatBoost uses only the data that came before the current observation in the training set. This approach simulates the real-world scenario where we don't have access to future data when making predictions.
Let's expand the math behind this process.
Suppose we have a training dataset of observations, ordered as . At boosting iteration , the model so far is . For each observation , the gradient is:
where:
- : Gradient of the loss function for observation at iteration
- : Loss function (e.g., squared error for regression, log-loss for classification)
- : Actual target value for observation
- : Current model prediction for observation at iteration
- : Feature vector for observation
Traditional boosting computes the split criteria for the next tree using all gradients , i.e., all data points contribute to the statistics used for finding the best splits.
Ordered boosting in CatBoost, however, restricts the information available for each observation. When computing the split statistics for observation , only the gradients from observations with indices are used. That is, for each , the statistics for building the tree at iteration are computed using:
This can be formalized as follows. For each observation , the split statistics used to determine the best split are computed as:
where "Aggregate" denotes the sum or other relevant statistic (such as sum of gradients and Hessians) required for the split-finding algorithm.
This process ensures that, for each observation, the model and the splits are built using only information that would have been available up to that point in the data sequence, thus preventing "target leakage" from future data and reducing overfitting.
In summary:
- The gradient for observation at iteration is:
- When building the tree at iteration , CatBoost uses only the gradients from observations to compute the split criteria for observation :
This ordered approach creates a more robust training process by simulating the real-world scenario where future data is not available.
Mathematical Properties
CatBoost's symmetric tree structure provides several important mathematical properties. The constraint that all nodes at the same level use the same feature creates a more balanced tree structure, which helps prevent overfitting and improves generalization. This structure also makes the model more interpretable, as the decision path is more predictable and easier to understand.
The ordered boosting technique provides a form of regularization by preventing the model from using information that wouldn't be available in real-world scenarios. This approach helps create more robust models that perform better on unseen data, particularly in time-series or sequential data scenarios.
CatBoost's categorical feature processing creates smooth, continuous representations of categorical variables that are learned during training. This approach often results in better performance than traditional encoding methods because the encoding is optimized specifically for the task at hand, rather than using generic preprocessing techniques.
Visualizing CatBoost
Let's examine how CatBoost's symmetric tree structure compares to traditional decision trees and how its categorical feature processing works.
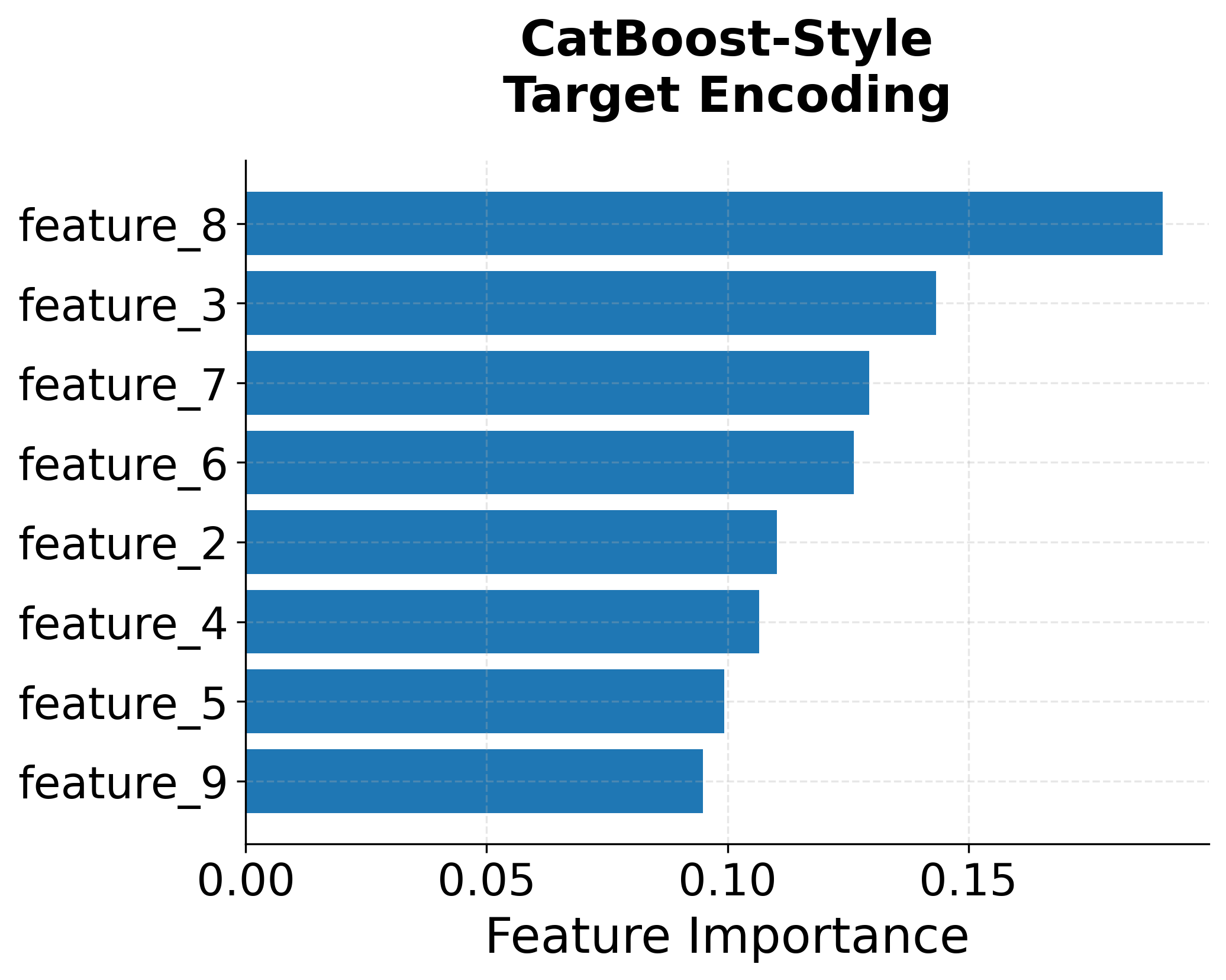
The visualization above shows the key difference between traditional categorical feature processing and CatBoost's approach. The left plot shows how one-hot encoding creates many binary features (leading to high dimensionality), while the right plot shows how CatBoost's target encoding approach maintains the original feature structure while learning optimal representations.
Example
Let's work through a concrete example to understand how CatBoost processes categorical features and builds symmetric trees. We'll use a simplified dataset to make the calculations clear and traceable.
Dataset Setup: Consider a small dataset with 6 observations, 2 numerical features, and 1 categorical feature:
| ID | Age | Income | City | Target |
|---|---|---|---|---|
| 1 | 25 | 50000 | NYC | 1 |
| 2 | 30 | 60000 | SF | 1 |
| 3 | 35 | 70000 | NYC | 0 |
| 4 | 28 | 55000 | LA | 1 |
| 5 | 40 | 80000 | SF | 0 |
| 6 | 32 | 65000 | LA | 1 |
Step 1: Categorical Feature Processing
CatBoost processes the categorical feature "City" by computing target statistics. For each category, we calculate:
With and (prior probability):
- NYC:
- SF:
- LA:
Step 2: Building a Symmetric Tree
CatBoost builds symmetric trees where all nodes at the same level use the same feature. For a tree of depth 2, we need to select 2 features for the 2 levels.
Let's say we select "Age" for level 1 and "City_encoded" for level 2. The tree structure would be:
Level 1: Age < 32.5?
├── Yes (Age < 32.5)
│ └── Level 2: City_encoded < 0.722?
│ ├── Yes → Leaf 1 (NYC: 0.556)
│ └── No → Leaf 2 (LA: 0.889)
└── No (Age ≥ 32.5)
└── Level 2: City_encoded < 0.722?
├── Yes → Leaf 3 (NYC: 0.556)
└── No → Leaf 4 (SF: 0.556)
Step 3: Leaf Value Calculation
For each leaf, we calculate the optimal leaf value using the gradients. The leaf values are computed to minimize the loss function, typically using the average of the gradients in each leaf.
This symmetric structure ensures that the tree is balanced and uses the same features at each level, which helps prevent overfitting and creates more interpretable models.
Implementation in CatBoost
CatBoost provides a clean, scikit-learn compatible interface that makes it easy to implement in machine learning pipelines. The framework handles categorical features automatically and provides excellent default parameters that work well across many datasets.
Let's walk through a complete example demonstrating CatBoost's key features, including automatic categorical feature handling, model training, and evaluation.
The classification report shows strong performance across both classes, with precision, recall, and F1-scores all above 0.85. The cross-validation ROC-AUC scores demonstrate model stability across different data splits, with a mean score around 0.93 and low standard deviation. This indicates that CatBoost has successfully learned meaningful patterns from the mixed categorical and numerical features without requiring extensive preprocessing.
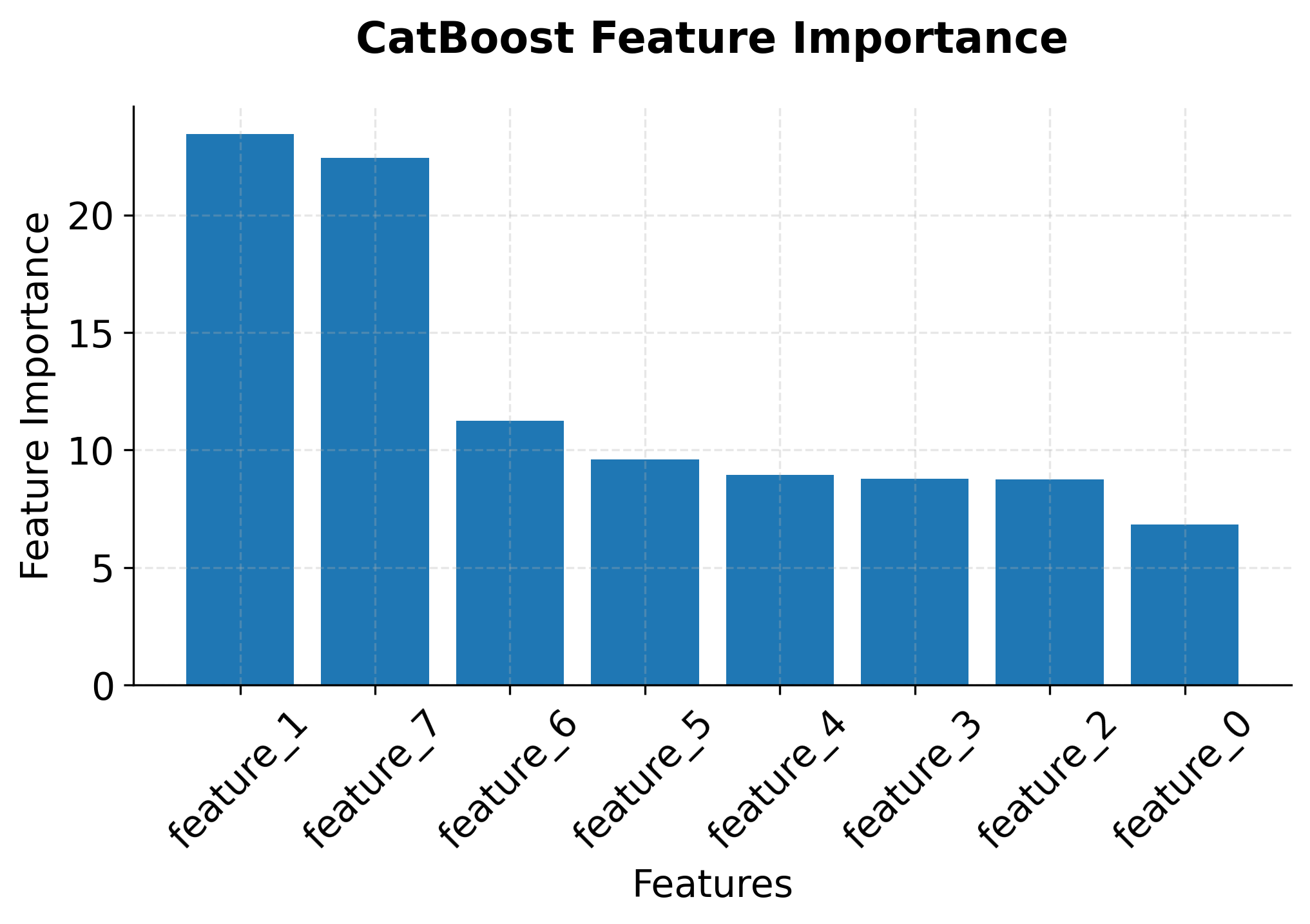
Key Implementation Notes:
-
Categorical Feature Handling: CatBoost automatically processes categorical features without requiring preprocessing. We simply specify which features are categorical using the
cat_featuresparameter. -
Pool Data Structure: CatBoost's
Poolclass provides efficient data handling and preprocessing, particularly beneficial for large datasets with mixed data types. -
Default Parameters: CatBoost's default parameters work well across many datasets, reducing the need for extensive hyperparameter tuning. The framework includes intelligent defaults for regularization and learning rate.
-
Feature Importance: CatBoost provides multiple types of feature importance, including prediction value change, loss function change, and feature interaction strength, helping with model interpretation.
Key Parameters
Below are some of the main parameters that affect how CatBoost works and performs.
-
iterations: Number of boosting iterations (trees to build). Default is 1000. More iterations generally improve performance but increase training time. Start with 100-500 for initial experiments, then increase if validation scores continue to improve. -
learning_rate: Step size for updating the model at each iteration. Default is 0.03. Lower values (0.01-0.1) require more iterations but often lead to better generalization. Higher values speed up training but may cause overfitting. -
depth: Maximum depth of each tree. Default is 6. Deeper trees (8-10) can capture more complex patterns but risk overfitting. Shallower trees (4-6) are more conservative and generalize better on smaller datasets. -
l2_leaf_reg: L2 regularization coefficient for leaf values. Default is 3. Higher values (5-10) provide stronger regularization and reduce overfitting. Lower values (1-3) allow the model to fit training data more closely. -
cat_features: List or array of categorical feature indices or names. CatBoost will automatically apply target encoding to these features. Can be specified as column indices (integers) or column names (strings). -
random_seed: Seed for reproducibility. Default is None. Set to an integer to ensure consistent results across runs, which is important for debugging and comparing models. -
verbose: Controls training output verbosity. Set toFalseto suppress output, or an integer to print progress every N iterations. Useful for monitoring training progress on large datasets. -
loss_function: Loss function to optimize. Default is 'Logloss' for binary classification, 'MultiClass' for multi-class, and 'RMSE' for regression. Other options include 'CrossEntropy', 'MAE', and custom loss functions. -
eval_metric: Metric used for overfitting detection and best model selection. Common choices include 'AUC', 'Accuracy', 'F1', 'Precision', 'Recall' for classification, and 'RMSE', 'MAE', 'R2' for regression. -
early_stopping_rounds: Number of iterations without improvement before stopping training. Default is None (no early stopping). Setting to 20-50 helps prevent overfitting and saves training time.
Key Methods
The following are the most commonly used methods for interacting with CatBoost models.
-
fit(X, y, cat_features=None, eval_set=None): Trains the CatBoost model on training data X and target values y. Thecat_featuresparameter specifies categorical features, andeval_setprovides validation data for monitoring. -
predict(X): Returns predicted class labels (classification) or values (regression) for input data X. For classification, returns the class with highest probability. -
predict_proba(X): Returns probability estimates for each class (classification only). Useful for setting custom decision thresholds or when you need confidence scores rather than hard predictions. -
get_feature_importance(): Returns feature importance scores showing the relative contribution of each feature to the model's predictions. Higher values indicate more influential features. -
score(X, y): Returns the mean accuracy (classification) or R² score (regression) on the given test data. Convenient for quick model evaluation.
Practical Implications
CatBoost is particularly valuable for datasets with high-cardinality categorical features such as user IDs, product categories, or geographic regions. Traditional one-hot encoding creates sparse, high-dimensional feature matrices that are computationally expensive and prone to overfitting, while CatBoost's automatic categorical processing handles these features efficiently without preprocessing. The framework's sophisticated target encoding learns optimal representations during training, often achieving better performance than manual encoding schemes.
The framework excels when you need reliable performance with minimal hyperparameter tuning. CatBoost's intelligent default parameters and built-in regularization make it well-suited for automated machine learning pipelines, rapid prototyping, or time-constrained projects. This makes it valuable for practitioners who need strong baseline models quickly or for production systems where extensive manual tuning is impractical.
When choosing between gradient boosting frameworks, consider your specific requirements. CatBoost is preferable when your dataset contains many high-cardinality categorical features, you need reliable performance without extensive tuning, or you're building automated pipelines. XGBoost is better suited when training speed is critical or you're working primarily with numerical features. LightGBM excels when you need the fastest training times or you're working with very large datasets that don't fit in memory.
Best Practices
To achieve optimal results with CatBoost, properly identify and specify categorical features using the cat_features parameter. Provide categorical features as strings or integers to allow CatBoost to apply its target encoding automatically. For datasets with mixed data types, use the Pool class for efficient memory management and preprocessing.
When tuning hyperparameters, begin with default settings and adjust only if validation performance indicates improvement. Start with 100-200 iterations and increase gradually while monitoring validation metrics. The learning rate works well at the default 0.03, but can be reduced to 0.01 for more stable convergence on complex datasets. Tree depth should generally remain between 4 and 8, with deeper trees reserved for datasets with complex interactions. Use cross-validation to assess model stability across different data splits.
For production deployments, set random_seed for reproducibility and enable early_stopping_rounds (typically 20-50) to prevent overfitting. Monitor feature importance scores to understand which features drive predictions and identify potential data quality issues. When working with time-series or sequential data, consider using ordered boosting mode to better simulate real-world prediction scenarios.
Data Requirements and Preprocessing
CatBoost works best with datasets containing a mix of categorical and numerical features. The framework handles datasets with hundreds of categorical features and thousands of categories per feature, but performance degrades with extremely high-cardinality features (millions of unique categories). Categorical features should have meaningful relationships with the target variable, as the target encoding mechanism relies on these relationships to create effective representations.
Unlike many machine learning algorithms, CatBoost does not require standardization or normalization of numerical features, as the tree-based structure is invariant to monotonic transformations. CatBoost handles missing values in both numerical and categorical features natively, treating them as a separate category or using specialized splitting strategies. For categorical features, provide them as strings or integers rather than one-hot encoded, as CatBoost's target encoding works directly with the original categorical values.
The framework requires sufficient data to learn meaningful categorical encodings. With very small datasets (less than 1000 observations), the categorical feature processing may not have enough data to create reliable encodings, potentially leading to overfitting. In such cases, consider using simpler encoding methods or reducing the number of categorical features. For datasets with class imbalance, use the class_weights parameter or appropriate evaluation metrics like AUC or F1-score rather than accuracy.
Common Pitfalls
A frequent mistake when using CatBoost is preprocessing categorical features before passing them to the model. One-hot encoding or label encoding categorical features defeats the purpose of CatBoost's target encoding mechanism, which is designed to work with raw categorical values. Provide categorical features in their original form (as strings or integers) and let CatBoost handle the encoding automatically. This approach simplifies your preprocessing pipeline and typically results in better performance.
Another common issue is using too many iterations without early stopping, which can lead to overfitting. While CatBoost includes built-in regularization, training for thousands of iterations without monitoring validation performance can result in models that perform poorly on unseen data. Use a validation set and enable early stopping to halt training when performance stops improving. Additionally, failing to set random_seed makes results non-reproducible, which complicates debugging and model comparison.
Ignoring memory constraints is another pitfall, particularly with high-cardinality categorical features. CatBoost's categorical processing requires more memory than traditional gradient boosting implementations, and training on datasets with millions of unique categories per feature can exhaust available memory. Monitor memory usage during training and consider reducing cardinality through feature engineering or grouping rare categories if memory becomes a constraint. Using inappropriate evaluation metrics can also lead to misleading conclusions about model performance, especially with imbalanced datasets where accuracy may not reflect true predictive quality.
Computational Considerations
CatBoost's computational complexity is higher than XGBoost and LightGBM due to its categorical feature processing and symmetric tree structure. Training time is typically 1.5-3x longer than XGBoost, with the gap widening as the number and cardinality of categorical features increases. For datasets with more than 100,000 observations and multiple high-cardinality categorical features, expect training times of several minutes to hours depending on the number of iterations and tree depth.
Memory requirements are substantial, particularly for high-cardinality categorical features. Plan for 2-4x more memory usage compared to traditional gradient boosting implementations. The Pool class helps manage memory more efficiently by preprocessing data once and reusing it across iterations, but very large datasets (millions of observations with hundreds of features) may require distributed training or feature selection. Consider using GPU acceleration through the task_type='GPU' parameter for significant speedups on large datasets.
For production deployments, model inference is relatively fast and comparable to other gradient boosting frameworks. The symmetric tree structure provides computational advantages during prediction, as the same feature is evaluated at each level. However, model file size can be larger than XGBoost or LightGBM models, particularly with many iterations and deep trees. Consider model compression techniques or reducing the number of trees if deployment size is a constraint.
Performance and Deployment Considerations
Evaluating CatBoost model performance requires using appropriate metrics for your specific task. For classification, use AUC-ROC for balanced datasets and AUC-PR or F1-score for imbalanced datasets. For regression, R² and RMSE provide complementary information about model fit and prediction accuracy. Evaluate performance on a held-out test set that was not used during training or hyperparameter tuning to get an unbiased estimate of generalization performance.
When deploying CatBoost models to production, consider the tradeoff between model complexity and inference speed. Models with hundreds of trees and deep depths provide better accuracy but slower predictions. For latency-sensitive applications, reduce the number of iterations or tree depth to achieve faster inference times. The framework provides efficient prediction APIs that can be integrated into REST APIs, batch processing pipelines, and real-time streaming systems.
Monitor model performance continuously in production, as data drift can degrade prediction quality over time. Track key metrics like prediction distributions, feature importance stability, and performance on recent data compared to the training period. Implement automated retraining pipelines that periodically update the model with new data while validating that performance improvements justify deployment of updated models. Consider A/B testing new model versions against existing ones to ensure that changes improve real-world outcomes rather than just validation metrics.
Summary
CatBoost provides an advancement in gradient boosting technology through its handling of categorical features and emphasis on robustness. The framework's automatic categorical feature processing eliminates the need for extensive preprocessing while often achieving strong performance compared to traditional encoding methods. This capability, combined with its symmetric tree structure and regularization techniques, makes CatBoost well-suited for datasets with mixed data types and scenarios requiring reliable performance with minimal manual intervention.
The framework's design philosophy prioritizes model quality and stability over raw speed, making it valuable for production environments where reliability is important. While CatBoost may not be the fastest gradient boosting implementation, its intelligent defaults, built-in regularization, and categorical feature handling often result in strong out-of-the-box performance.
For practitioners working with real-world datasets that contain a mix of categorical and numerical features, CatBoost offers a useful alternative to traditional gradient boosting approaches. The framework's ability to handle categorical features natively, combined with its robust default parameters and strong performance characteristics, makes it a valuable tool for modern machine learning workflows, particularly in scenarios where data preprocessing complexity and model reliability are important concerns.
Quiz
Ready to test your understanding of CatBoost? Take this quick quiz to reinforce what you've learned about categorical boosting.

Comments