

A comprehensive guide to foundational data visualization techniques including histograms, box plots, and scatter plots. Learn how to understand distributions, identify outliers, reveal relationships, and build intuition before statistical analysis.

This article is part of the free-to-read Machine Learning from Scratch
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Visualization & Intuition: Seeing Data Before Computing
Data visualization is a foundational step in understanding any dataset, providing immediate intuitive insights that raw numbers alone cannot convey. Before calculating summary statistics or fitting complex models, visualizations reveal patterns, outliers, distributions, and relationships that guide subsequent analysis and help prevent analytical mistakes.
Introduction
The human visual system excels at pattern recognition, making visualization one of the most powerful tools in the data scientist's arsenal. A well-crafted histogram can instantly reveal whether data follows a normal distribution or exhibits skewness. A scatter plot can expose non-linear relationships that correlation coefficients might obscure. Box plots highlight outliers that could derail a regression model if left unaddressed.
Exploratory data analysis through visualization has been championed by statisticians like John Tukey, who emphasized the importance of "looking at the data" before applying formal statistical procedures. This philosophy recognizes that computational tools are most effective when guided by human intuition and domain knowledge, both of which are enhanced through visual exploration.
This chapter introduces three fundamental visualization techniques (histograms, box plots, and scatter plots) that form the foundation of exploratory data analysis. These tools provide complementary perspectives on data, revealing distributional properties, summary characteristics, and relationships that inform every subsequent analytical decision. By mastering these visualizations, practitioners develop intuition about their data that transforms them from mechanical calculators into thoughtful analysts capable of asking the right questions and interpreting results in meaningful ways.
Histograms: Understanding Distributions
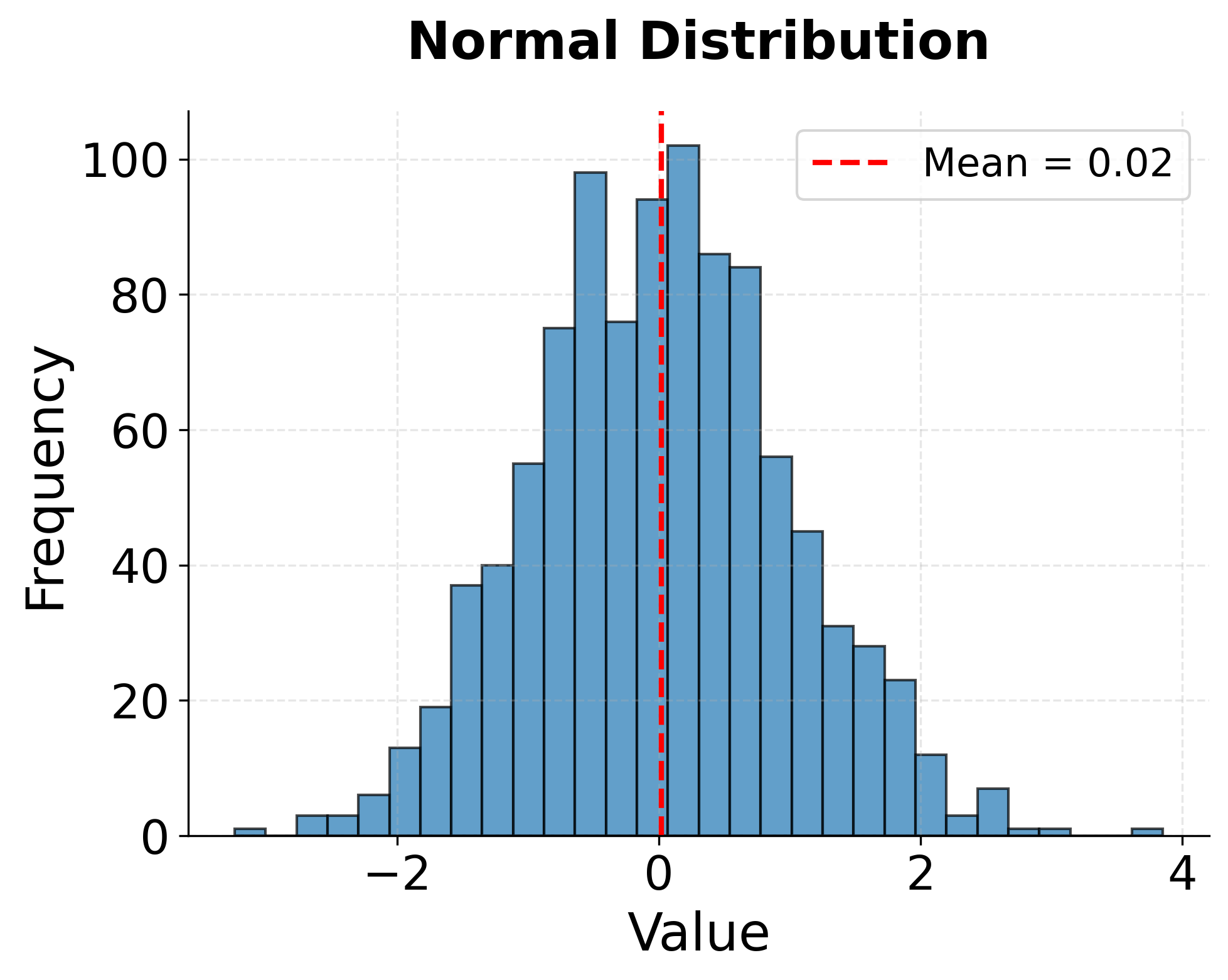
Histograms display the distribution of a continuous variable by dividing the range of values into bins and counting how many observations fall into each bin. The resulting bar chart provides an immediate visual sense of where data is concentrated, how spread out it is, and whether it exhibits unusual patterns like multiple peaks or long tails.
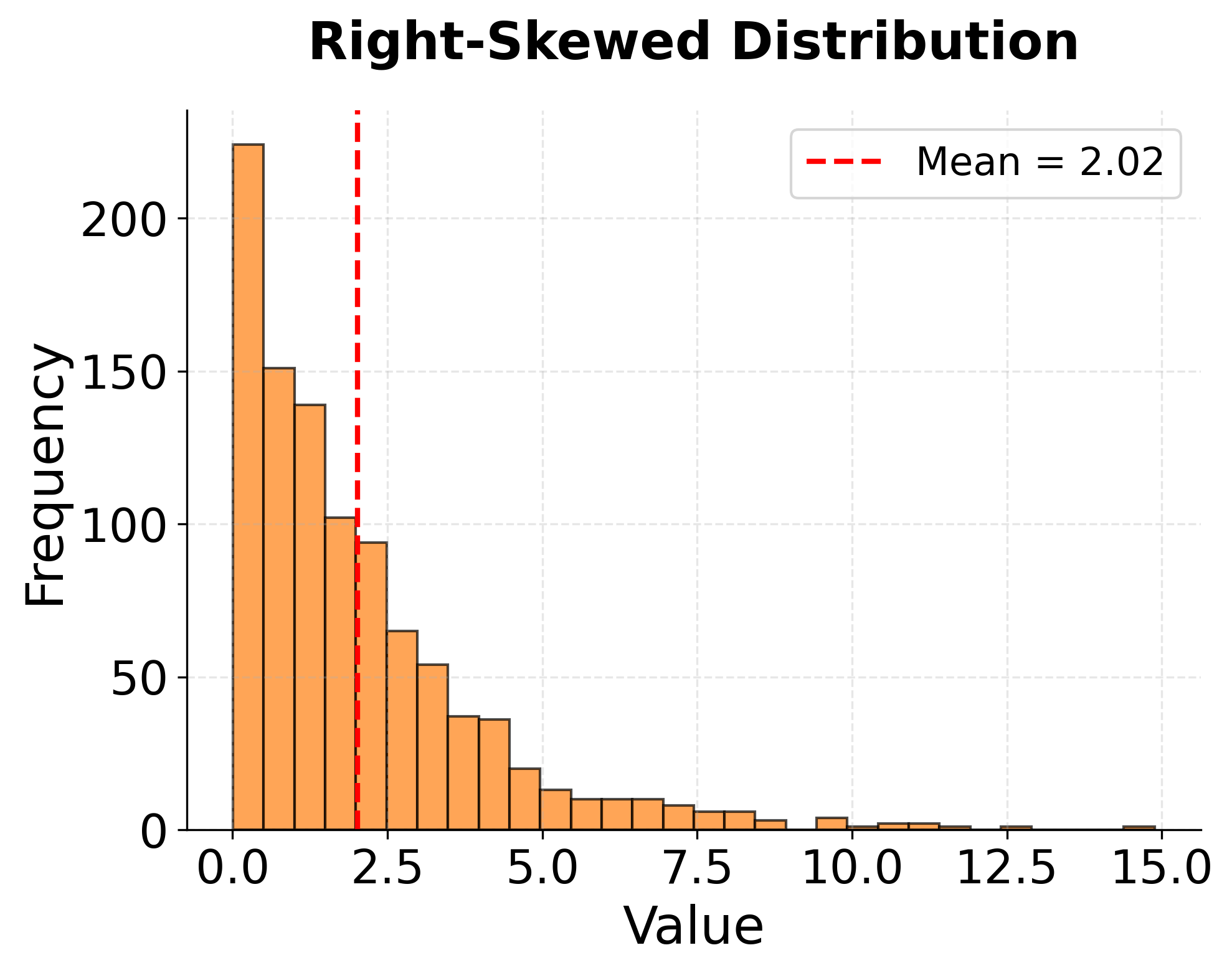
The shape of a histogram reveals important information about the underlying data generation process. A symmetric, bell-shaped distribution centered around a single peak suggests data that might follow a normal distribution, which justifies many classical statistical procedures. Skewed distributions, with long tails extending to the right or left, indicate that extreme values occur more frequently than a normal distribution would predict. Such skewness might suggest the need for data transformation or the use of robust statistical methods that don't assume normality.
Histograms also expose potential data quality issues. Unexpected gaps in the distribution might indicate missing categories or measurement problems. Sharp cutoffs at round numbers could reveal data entry practices rather than true properties of the measured phenomenon. Multiple distinct peaks (bimodal or multimodal distributions) often suggest that the data combines multiple subpopulations that should be analyzed separately.
The choice of bin width significantly affects histogram appearance and interpretation. Too few bins obscure detail and make the distribution appear overly smooth. Too many bins create a jagged appearance dominated by random noise rather than meaningful signal. Most visualization libraries provide reasonable default binning strategies, but practitioners should experiment with different bin widths to ensure they're not missing important features or being misled by arbitrary binning choices.
Box Plots: Summarizing Key Statistics
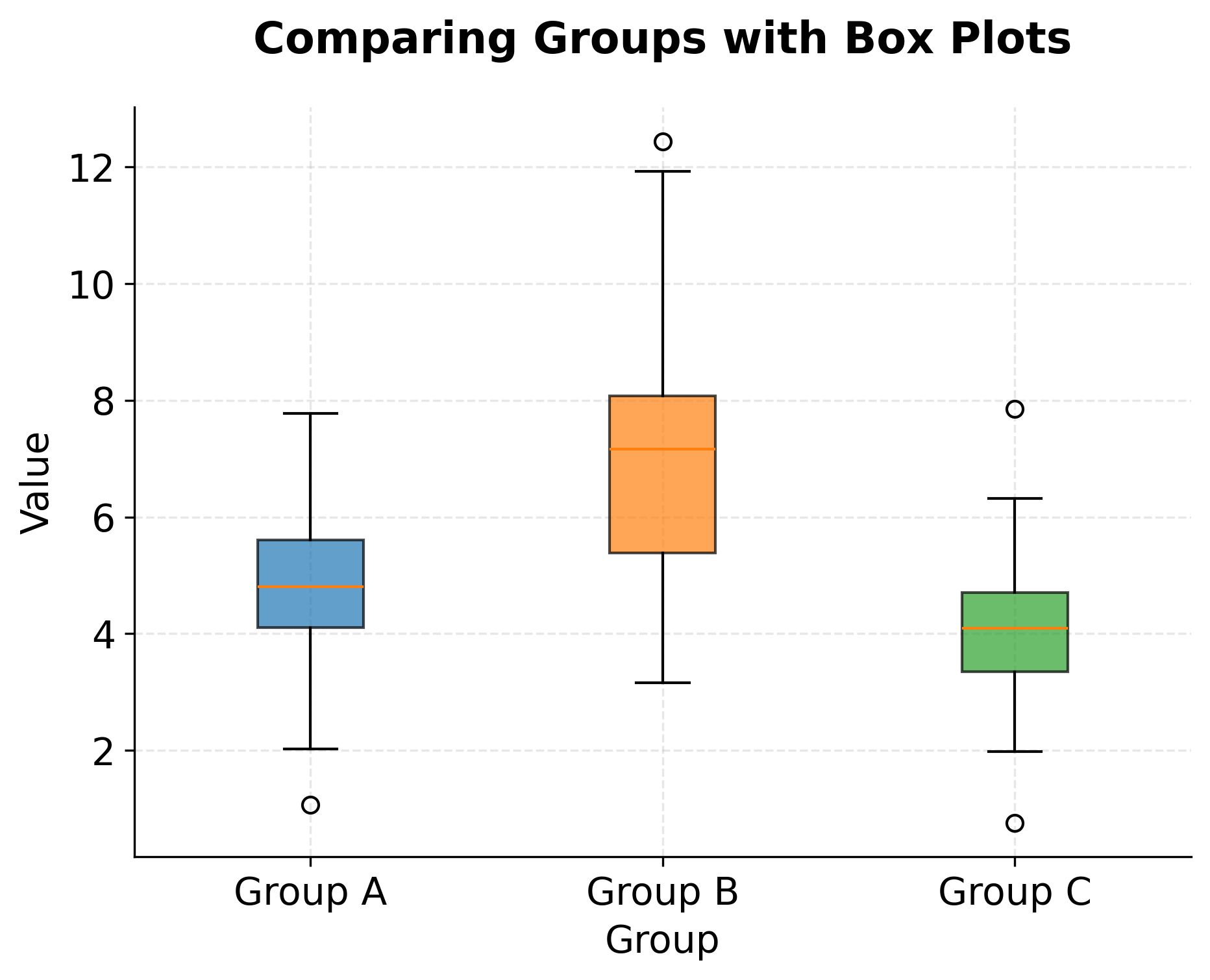
Box plots, also known as box-and-whisker plots, provide a concise visual summary of a distribution's key statistical properties. The rectangular box spans from the first quartile (25th percentile) to the third quartile (75th percentile), capturing the middle 50% of the data. A line inside the box marks the median (50th percentile). Whiskers extend from the box to show the range of typical values, while individual points beyond the whiskers flag potential outliers.
This compact representation makes box plots particularly valuable for comparing distributions across multiple groups. Arranging several box plots side by side immediately reveals differences in central tendency (median positions), spread (box heights), and outlier patterns. Such comparisons might show that one group has systematically higher values than another, or that some groups exhibit more variability, or that outliers occur predominantly in certain categories.
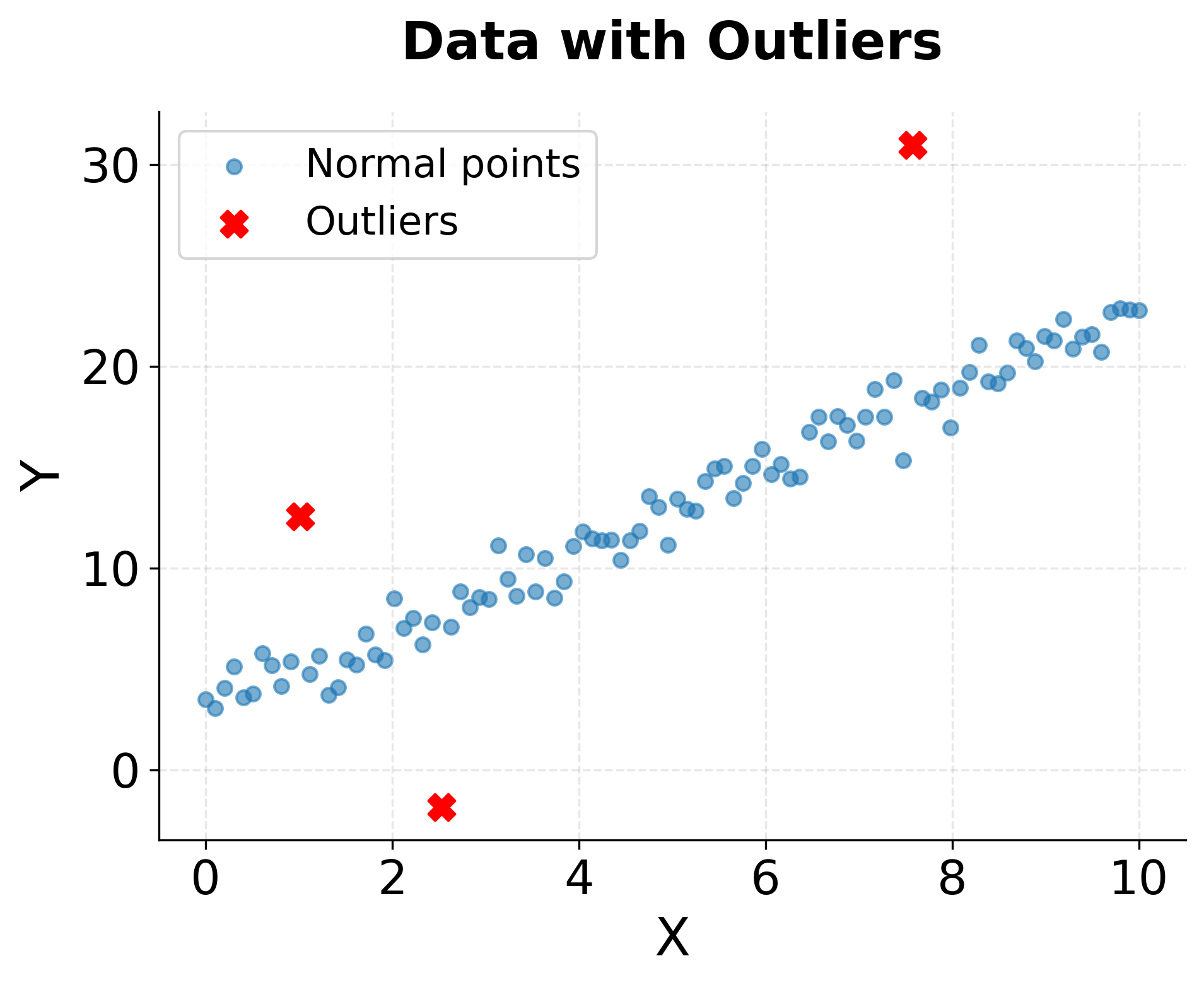
The definition of outliers in box plots typically follows the interquartile range (IQR) rule: values more than 1.5 times the IQR below the first quartile or above the third quartile are flagged as potential outliers. While this rule is somewhat arbitrary, it provides a useful starting point for identifying observations that warrant closer inspection. Some outliers represent genuine extreme values that carry important information about rare events or boundary conditions. Others indicate measurement errors, data entry mistakes, or observations from a different population that should be excluded or modeled separately.
Box plots sacrifice some information that histograms preserve, particularly about the detailed shape of the distribution between quartiles. A bimodal distribution with two distinct peaks might appear as a simple box plot with a large interquartile range. This limitation means box plots work best as complements to, rather than replacements for, histograms, with each visualization type highlighting different aspects of the data.
Scatter Plots: Revealing Relationships
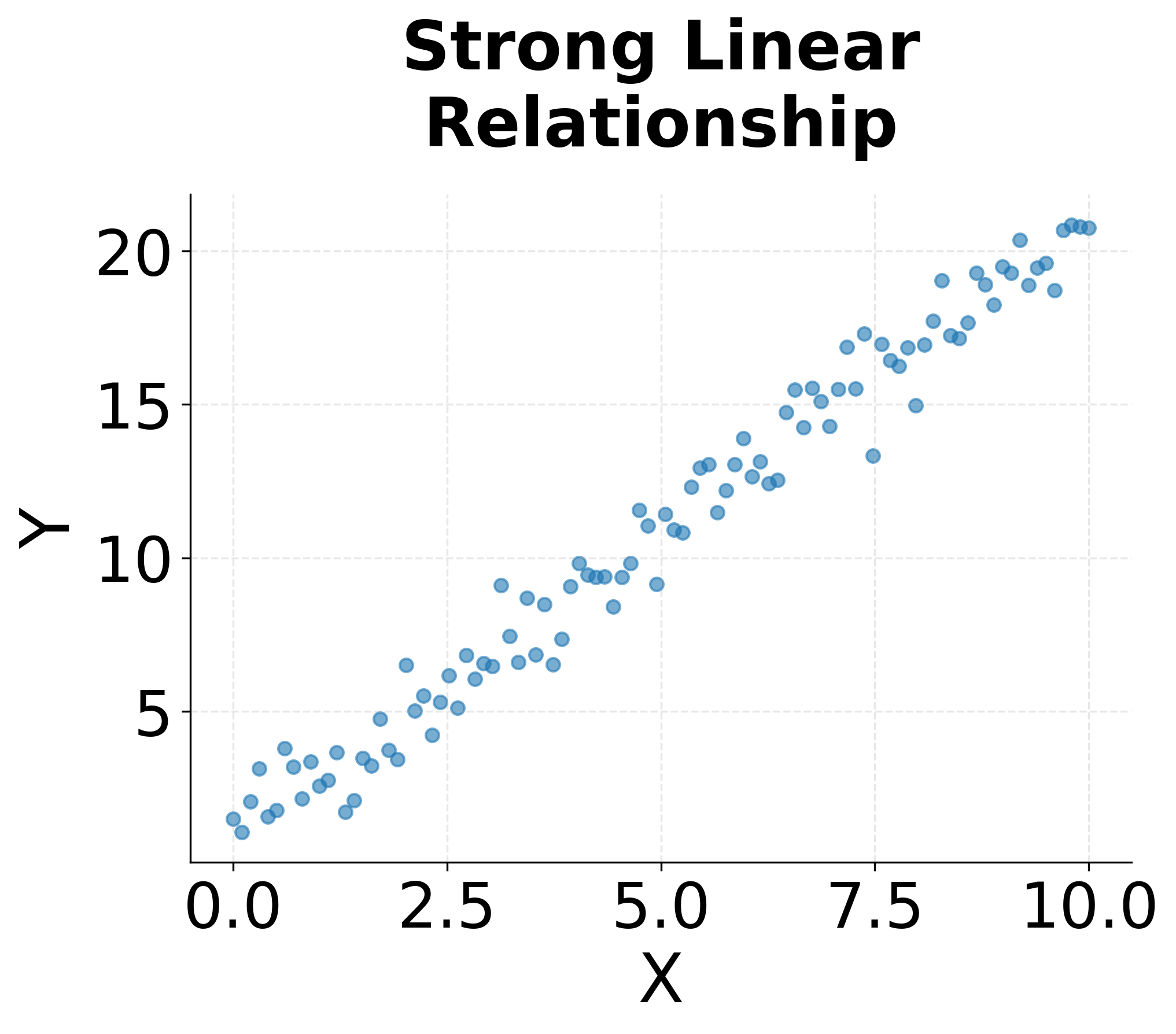
Scatter plots display the relationship between two continuous variables by plotting each observation as a point in two-dimensional space. The resulting point cloud reveals patterns of association that summary statistics like correlation coefficients capture only partially. A tight linear arrangement of points indicates a strong relationship, while a diffuse cloud suggests weak or no association. Non-linear patterns (curves, clusters, or fan shapes) expose complexities that linear models would fail to capture.
The strength of scatter plots lies in their ability to reveal the nature of relationships, not just their existence. Two variables might have identical correlation coefficients but completely different scatter plot patterns. One might show a genuinely linear relationship, while another exhibits a curved relationship, and a third displays a linear trend distorted by a few influential outliers. Only the scatter plot distinguishes between these scenarios, guiding the choice of appropriate modeling techniques.
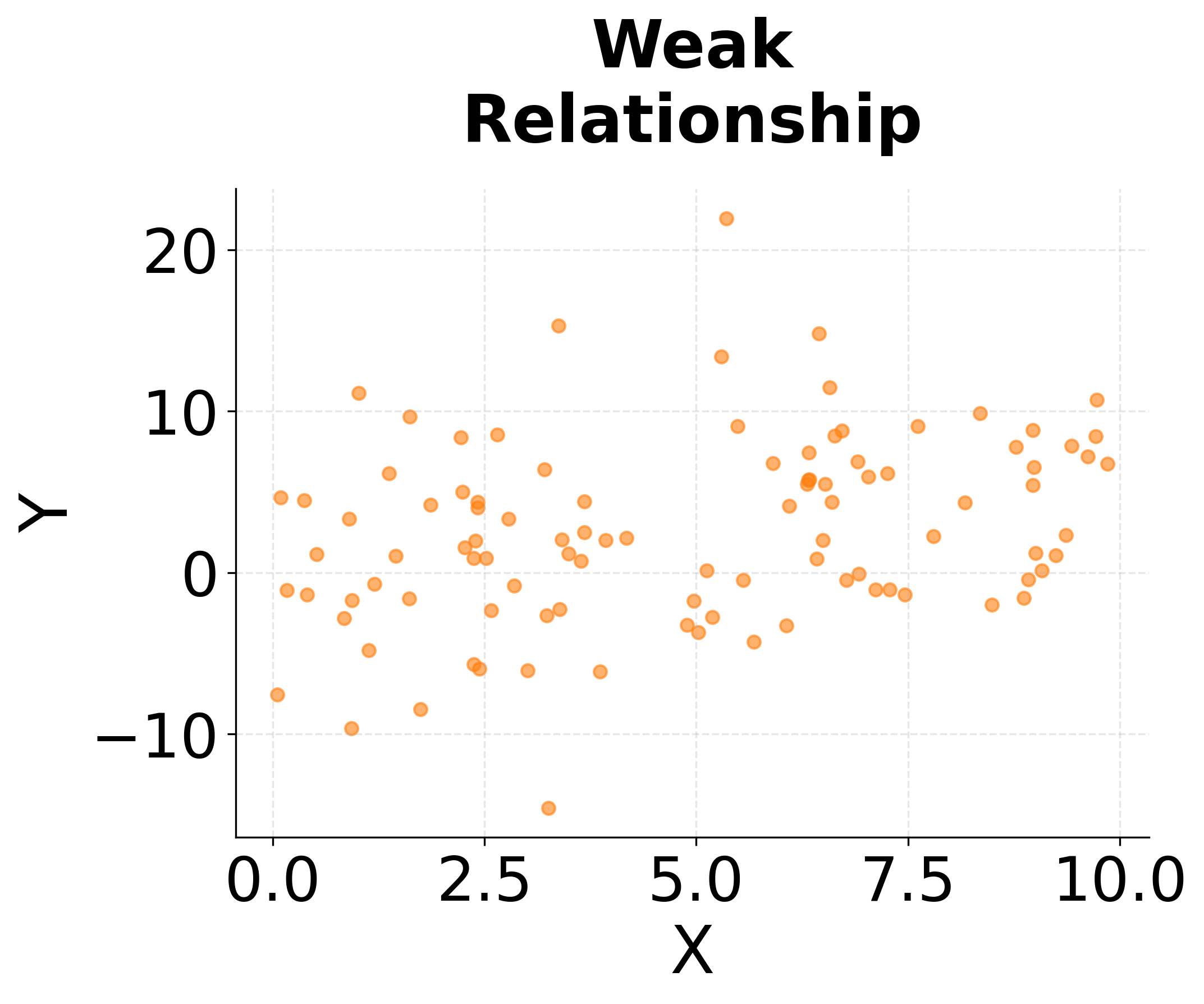
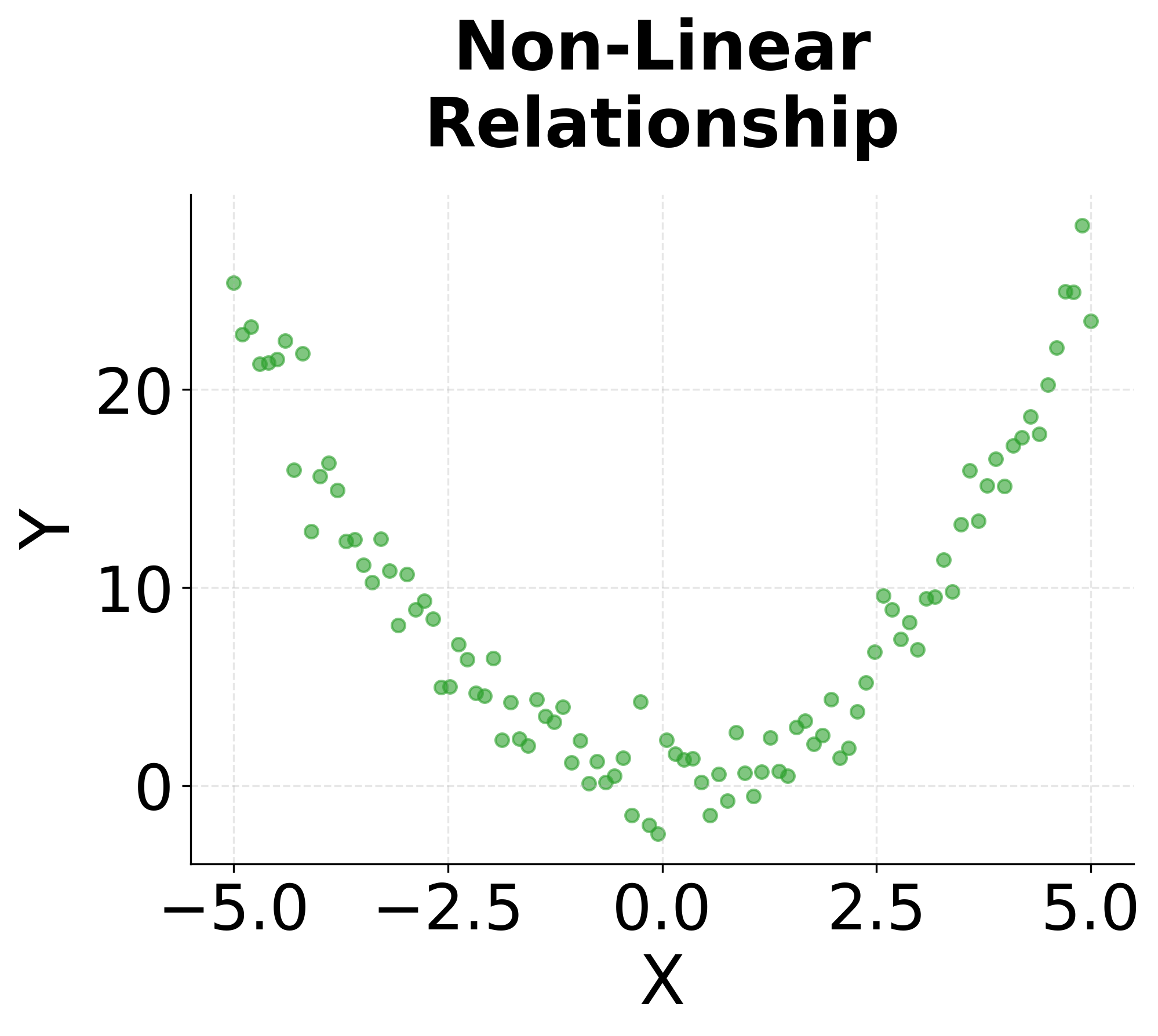
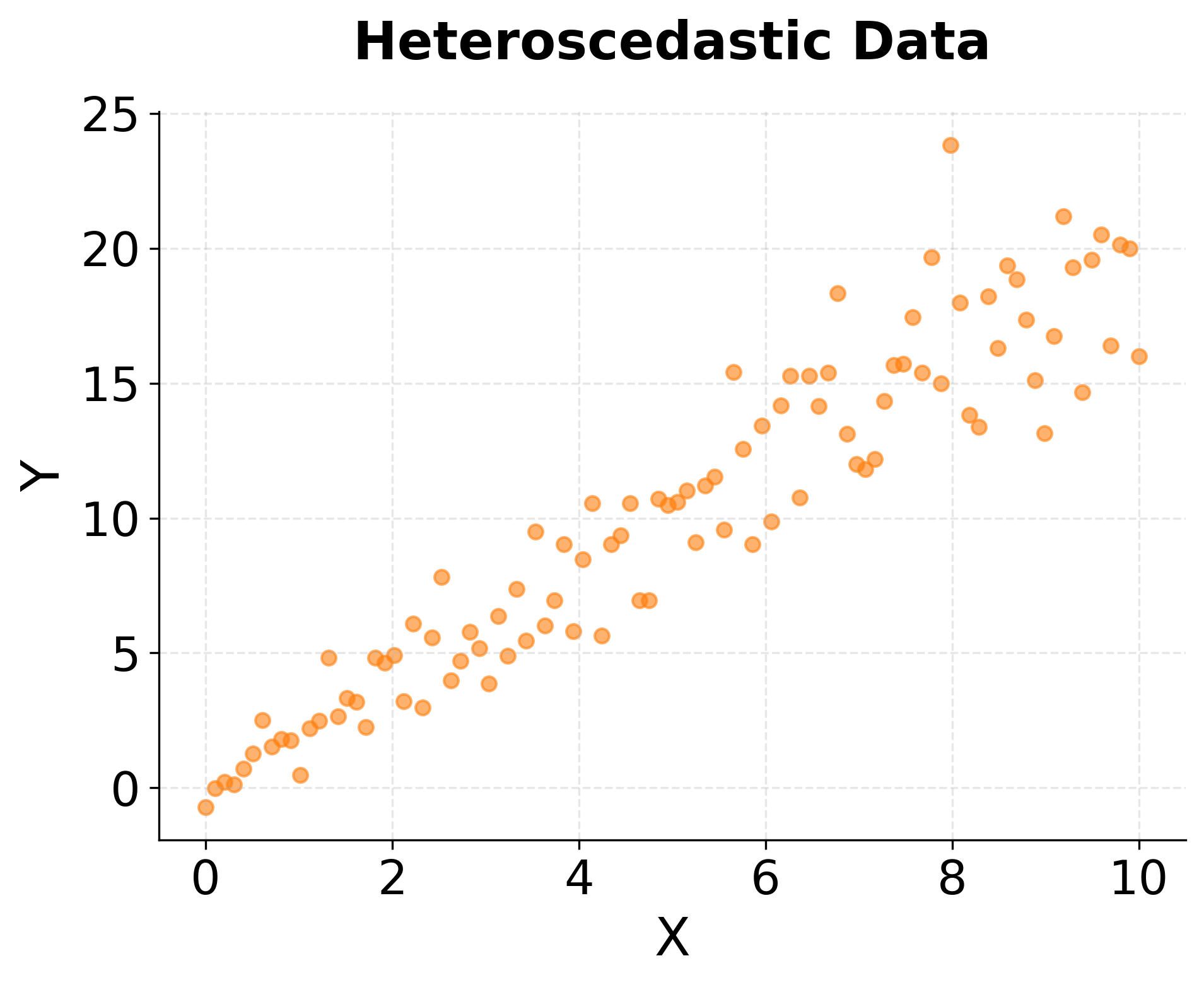
Scatter plots also expose violations of statistical assumptions that can undermine formal analyses. Heteroscedasticity, where the spread of points increases or decreases along the range of the predictor, violates an important assumption of ordinary least squares regression. A funnel-shaped scatter plot immediately reveals this problem, suggesting the need for robust regression methods or transformation of variables. Clusters of points separated by gaps might indicate distinct subgroups that should be modeled with categorical variables or mixture models rather than treating all observations as homogeneous.
For datasets with many observations, overplotting can obscure patterns as thousands of points overlap and create solid blocks of color. Transparency settings (alpha blending) partially address this by allowing dense regions to appear darker while preserving visibility of individual points in sparse areas. Hexagonal binning or contour plots provide alternative representations that summarize point density when datasets grow too large for individual points to remain distinguishable.
Choosing the Right Visualization
Selecting the appropriate visualization depends on the question being asked and the type of data available. Histograms work best for understanding the distribution of a single continuous variable, revealing shape, center, and spread. Box plots excel at comparing distributions across multiple groups, making differences in central tendency and variability immediately apparent. Scatter plots are particularly valuable for exploring relationships between two continuous variables, exposing patterns that correlation coefficients alone might miss.
In practice, effective exploratory data analysis employs multiple visualization types in combination. A histogram might reveal that a variable is skewed, prompting investigation of a log transformation. A box plot comparison across groups might expose outliers in certain categories, leading to targeted data quality checks. A scatter plot might suggest a non-linear relationship, informing the choice of modeling approach. Each visualization provides a different lens on the data, and together they build comprehensive understanding that pure computation cannot replace.
Modern data analysis workflows often begin with automated visualization dashboards that generate standard plots for all variables and relationships in a dataset. These automated tools provide efficient first-pass exploration, though they cannot replace the thoughtful, iterative visual investigation that experienced analysts perform when guided by domain knowledge and specific hypotheses. The goal is not simply to generate plots, but to look at them critically, ask what patterns they reveal, and allow those patterns to guide subsequent analytical decisions.
Limitations and Considerations
While visualization is valuable for data exploration, it has important limitations that practitioners should recognize. Visual interpretation is inherently subjective, and different viewers may draw different conclusions from the same plot. What one analyst sees as a meaningful pattern might appear to another as random noise. This subjectivity makes visualization most powerful when combined with formal statistical tests that quantify uncertainty and provide objective criteria for decision-making.
The choice of visual encoding (colors, scales, aspect ratios, and binning strategies) significantly influences interpretation. Poorly chosen scales can exaggerate trivial differences or obscure important patterns. Misleading axis ranges, truncated axes, or inappropriate transformations can create false impressions that lead to incorrect conclusions. Best practices for visualization design, such as starting axes at zero for bar charts and using consistent scales across comparison plots, help mitigate these risks but require conscious attention and discipline.
High-dimensional data presents particular challenges, as the human visual system is limited to perceiving two or three spatial dimensions directly. While techniques like small multiples, color encoding, and interactive visualizations extend our capacity to explore high-dimensional relationships, they cannot fully overcome the fundamental constraint that we cannot simultaneously visualize all pairwise relationships in datasets with dozens or hundreds of variables. Dimension reduction techniques like PCA or t-SNE provide alternative approaches for visualizing high-dimensional structure, but these come with their own interpretational complexities.
Finally, visualization works best for small to medium-sized datasets where individual observations remain distinguishable or where binning and aggregation preserve meaningful detail. Very large datasets (millions or billions of observations) may require sophisticated visualization techniques like density plots, aggregation to hexagonal bins, or statistical sampling to remain tractable. In such cases, the goal shifts from displaying all data to creating representative summaries that capture essential distributional features while remaining interpretable.
Practical Applications
Visualization serves important functions throughout the data science lifecycle, from initial exploration through final communication of results. During exploratory data analysis, visualizations guide data cleaning by exposing outliers, missing value patterns, and implausible observations that require investigation. A histogram might reveal that age values include impossible entries like 200 or -5, while a time series plot might expose sensor failures where values suddenly flatline.
In model building, visualizations inform feature engineering and model selection decisions. Scatter plots revealing non-linear relationships suggest polynomial terms or spline transformations. Distribution histograms showing severe skewness might motivate log transformations to achieve approximate normality. Box plots comparing predictor distributions across outcome categories help identify potentially informative features while flagging concerns about class imbalance that could bias model training.
Model diagnostic plots form an important validation step after fitting statistical models or machine learning algorithms. Residual plots (residuals versus fitted values) expose heteroscedasticity, non-linearity, and other violations of modeling assumptions. Quantile-quantile (Q-Q) plots compare residual distributions to theoretical normal distributions, validating assumptions required for inference. Calibration plots for classification models reveal whether predicted probabilities align with actual frequencies, indicating whether the model is well-calibrated or exhibits systematic bias.
Finally, visualization plays an important role in communicating analytical results to diverse audiences. Decision-makers without statistical training can grasp patterns in well-designed plots that would be opaque in tables of coefficients or p-values. Effective visualization transforms analytical insights into actionable understanding, bridging the gap between technical analysis and practical business impact. Skilled data scientists combine analytical expertise with effective communication, using visualization as a tool for both discovery and persuasion.
Summary
Visualization provides intuitive understanding of data that precedes and informs all subsequent analysis. Histograms reveal distributional properties like shape, center, spread, and the presence of multiple modes or extreme skewness. Box plots concisely summarize key statistics while enabling efficient comparisons across groups and highlighting potential outliers. Scatter plots expose relationships between variables, revealing linear associations, non-linear patterns, heteroscedasticity, and influential observations that summary statistics alone would miss.
The practice of looking at data before computing statistics is not mere convention but important discipline. Visual patterns guide the selection of appropriate statistical methods, reveal violations of modeling assumptions, and expose data quality issues that could invalidate formal analyses. While visualization is inherently subjective and should be complemented by rigorous statistical testing, it remains a foundational step in transforming raw data into reliable insight. By developing strong visualization habits and cultivating visual intuition, practitioners build the foundation for all subsequent analytical work, ensuring that computational sophistication serves understanding rather than obscuring it.
Quiz
Ready to test your understanding of data visualization techniques? Take this quiz to reinforce what you've learned about histograms, box plots, and scatter plots for exploratory data analysis.

Comments