

Learn how to use Monte Carlo simulation to model and analyze stock market returns, estimate future performance, and understand the impact of randomness in financial forecasting. This tutorial covers the fundamentals, practical implementation, and interpretation of simulation results.
Toggle tooltip visibility. Hover over underlined terms for instant definitions.
A Simple Yet Complete Tutorial on Estimating Long-Term Investment Returns
Learning Objectives
By the end of this tutorial, you will be able to:
- Understand the fundamentals of Monte Carlo simulation for financial modeling
- Implement a complete investment return simulation using Python
- Interpret probability distributions and risk metrics for investment decisions
- Create meaningful visualizations to communicate financial uncertainty
- Apply these techniques to your own investment analysis
What We'll Build
We'll create a Monte Carlo simulation that estimates the future value of a $100 investment over 10 years, accounting for market volatility and uncertainty. This approach is widely used by financial advisors, portfolio managers, and individual investors to understand potential outcomes and make informed decisions.
Key Concepts Covered
- Monte Carlo Method: Using random sampling to model complex systems
- Investment Returns: How compound growth works with volatility
- Risk Assessment: Understanding percentiles and confidence intervals
- Data Visualization: Creating meaningful charts for financial analysis
1. Setting Up The Environment
First, let's import the essential libraries we'll need for our simulation and visualization:
2. Defining The Simulation Parameters
Understanding the Financial Model
Before diving into the code, let's understand what we're modeling:
- Expected Return (): The average annual return expected from the investment (8%)
- Volatility (): How much the returns vary from year to year (15% standard deviation)
- Time Horizon: How long the investment will be held (10 years)
- Simulation Paths: How many different scenarios will be tested (10,000 iterations)
Why These Numbers?
- 8% expected return: Roughly matches historical stock market averages
- 15% volatility: Typical for a diversified stock portfolio
- 10,000 simulations: Provides statistical confidence in the results
The parameters are defined below:
3. Generating Random Returns
The Heart of Monte Carlo Simulation
Thousands of possible future scenarios will be generated by randomly sampling investment returns from a normal distribution. This is the core of Monte Carlo simulation:
Key Insight: Annual returns are assumed to follow a normal distribution with:
- Mean = 8% (the expected return)
- Standard deviation = 15% (market volatility)
Understanding the Output Structure
- Rows: Each row represents one possible future scenario (simulation path)
- Columns: Each column represents a year in the 10-year horizon
- Values: Each value is a randomly sampled annual return for that year and scenario
4. Computing Final Portfolio Values
The Compound Growth Formula
The fundamental principle of compound growth is applied to calculate how the investment grows over time. The mathematical formula is:
Where:
- (capital Pi) means "product of" - multiply all terms together
- is the return in year
- converts a return percentage to a growth factor
Why This Works
- A 10% return means money grows by a factor of 1.10
- A -5% loss means money is multiplied by 0.95
- Over multiple years, all these factors are multiplied together
Example Calculation
If returns of [8%, -2%, 15%] occur over 3 years:
- Growth factors: [1.08, 0.98, 1.15]
- Total growth: 1.08 × 0.98 × 1.15 = 1.217
- 100 × 1.217 = $121.70
5. Statistical Analysis and Risk Assessment
Understanding Percentiles and Risk Metrics
The beauty of Monte Carlo simulation lies in its ability to quantify uncertainty. Instead of a single "expected" outcome, a full distribution of possibilities is obtained. The key statistics can be analyzed as follows:
Key Percentiles Explained:
- 5th percentile: Only 5% of scenarios do worse than this (downside risk)
- 25th percentile: First quartile - represents poor but not catastrophic outcomes
- 50th percentile (median): Half of scenarios do better, half do worse
- 75th percentile: Third quartile - represents good outcomes
- 95th percentile: Only 5% of scenarios do better than this (upside potential)
These risk metrics are calculated below:
Understanding Median vs Expected Return
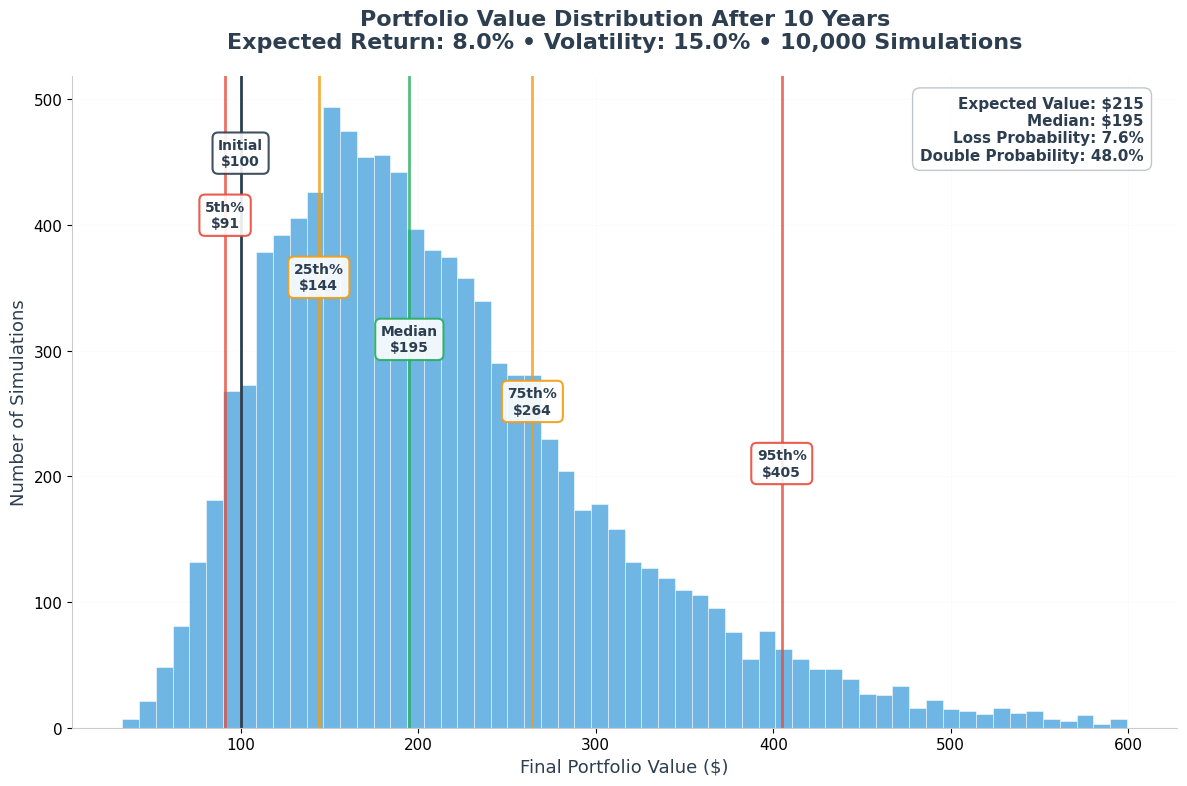
Key Insight: Notice that the median ($195) is lower than the expected value ($215). This is not an error - it's a fundamental characteristic of investment returns.
Why This Happens:
-
Skewed Distribution: Investment returns exhibit positive skewness - there are occasional very large gains that pull the average upward, but losses are bounded (you can't lose more than 100%).
-
Arithmetic vs Geometric: The expected value uses arithmetic averaging of outcomes, while actual compound growth follows geometric progression. A few extremely successful scenarios significantly raise the arithmetic mean.
-
Practical Implication: The median represents the "typical" outcome - half of all scenarios do better, half do worse. The expected value is mathematically correct but influenced by extreme positive outcomes.
Real-World Meaning: If you ran this investment 100 times, you'd be more likely to end up near the median ($195) than the expected value ($215). The expected value includes the impact of those rare scenarios where your portfolio might grow to $500+ or even $1000+.
6. Creating Meaningful Visualizations
We'll create a series of focused visualizations to understand different aspects of our Monte Carlo simulation results. Each chart reveals different insights about the investment risk and return profile.
6.1 Portfolio Value Distribution
The histogram shows the spread of possible outcomes from our Monte Carlo simulation. This visualization helps us understand the likelihood of different portfolio values after 10 years.
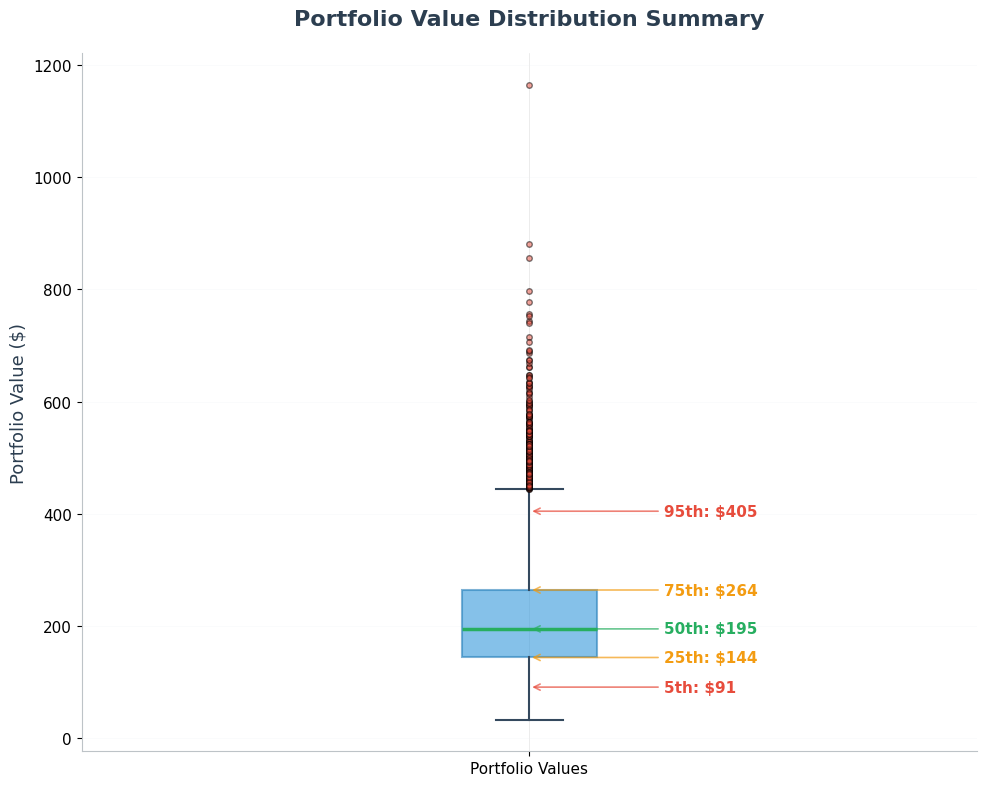
6.3 Cumulative Distribution Function (CDF)
The CDF shows the probability of achieving different portfolio values. This helps answer questions like "What's the probability my portfolio will be worth at least $200?"
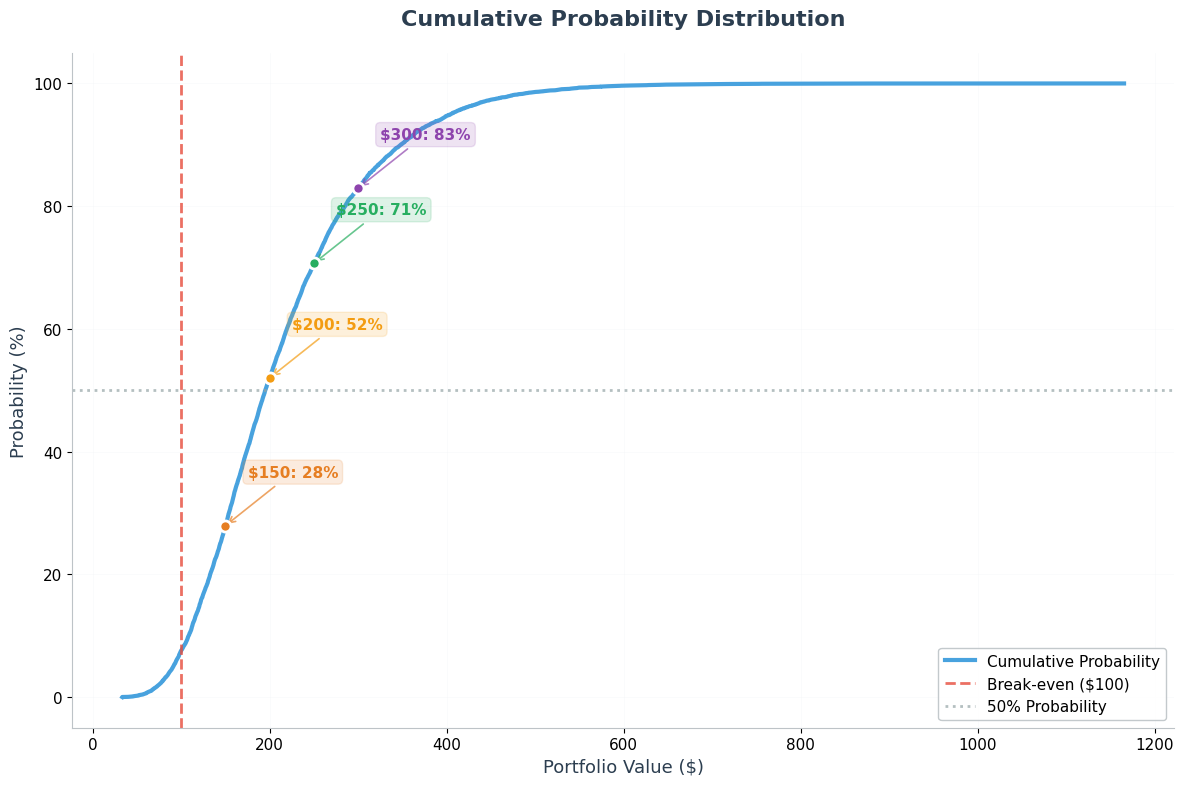
6.4 Portfolio Growth Over Time
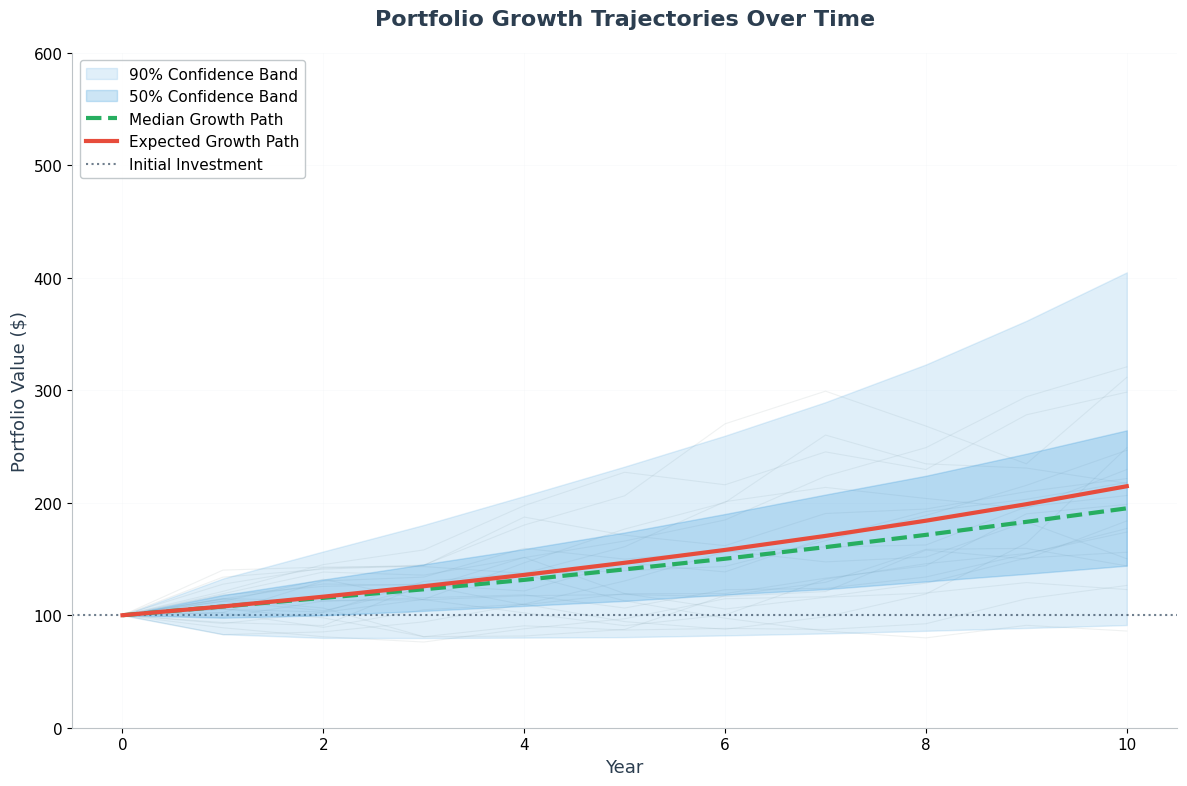
This visualization shows how portfolio values evolve year by year, demonstrating the compound growth effect and the confidence band around the expected path.
7. Conclusion: The Power of Monte Carlo Simulation
Monte Carlo simulation transforms investment uncertainty from guesswork into quantified risk assessment. By running 10,000 possible scenarios, we've mapped the full landscape of potential outcomes for our investment.
Key Monte Carlo Insights:
- Probabilistic Thinking: Rather than a single "expected" return, we now understand the full distribution of possibilities
- Risk Quantification: We can precisely state there's a 7.6% chance of losing money and a 48% chance of doubling our investment
- Confidence Intervals: We're 90% confident our final portfolio will be between 405
Why Monte Carlo Works:
- Captures Uncertainty: Markets are inherently random - Monte Carlo embraces this reality rather than ignoring it
- Compound Effects: Shows how volatility compounds over time, revealing both upside potential and downside risk
- Decision Support: Provides the statistical foundation for rational investment decisions
The Monte Carlo Advantage:
Traditional financial planning might say "expect 8% returns." Monte Carlo simulation reveals that while 8% is the average, actual outcomes range dramatically. This knowledge is power - it enables better risk management, more realistic expectations, and informed decision-making.
Monte Carlo simulation is not just a mathematical exercise; it's a lens for understanding uncertainty in any complex system where randomness plays a crucial role.

Comments