

Master financial data handling with pandas, NumPy, and Numba. Learn time series operations, return calculations, and visualization for quant finance.
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Data Handling and Visualization
Quantitative finance is fundamentally a data-driven discipline. Building sophisticated models and executing trading strategies requires efficient loading, cleaning, manipulation, and exploration of financial data. This chapter introduces the Python ecosystem for quantitative finance. You will work with time series data using pandas and NumPy, learning how to load and manipulate data efficiently. You'll explore performance optimization when standard tools become bottlenecks and create visualizations that reveal patterns in price and return data.
The skills in this chapter form the foundation for everything that follows. You will repeatedly draw on these patterns when calculating portfolio returns, backtesting trading strategies, or training machine learning models.
Loading Financial Data
Financial data comes in many formats: CSV files from data vendors, Excel spreadsheets from analysts, SQL databases at institutions, and API responses from market data providers. Pandas provides a unified interface for all these formats. By abstracting away the underlying storage details, pandas lets you focus on analysis rather than file handling. Understanding how to efficiently load and structure this data is the first step in any quantitative workflow.
Reading CSV Files
The most common starting point is a CSV file containing historical price data. Comma-separated value files remain the universal exchange format. They are human-readable, easily edited, and supported by virtually every tool. Let's load a sample dataset to illustrate basic loading patterns:
Use pd.read_csv() to load data. Three parameters matter for financial data:
- parse_dates: Converts date columns to datetime objects automatically
- index_col: Sets a column as the DataFrame index (typically the date)
- dtype: Specifies column data types to prevent incorrect type inference, for example forcing numeric columns to float64.
This displays the first five rows of price data with OHLC (open, high, low, close) values and volume. The index is now a DatetimeIndex, which is confirmed by the type output. The shape shows 252 rows (one year of business days) and 5 columns of data. This DatetimeIndex structure unlocks powerful time series operations we will explore shortly. The conversion from string dates to proper datetime objects is essential because it allows pandas to understand the temporal relationships between observations, enabling operations like date-range slicing and frequency-based resampling that would be impossible with plain text dates.
Handling Multiple Securities
Real-world analysis typically involves multiple securities. A portfolio manager might track dozens or hundreds of positions, while a factor model might require returns for thousands of stocks. Organize this data in two ways: wide format with one column per security, or long format with a single column for security identifier. Each format has advantages for different analyses.
Three columns appear (AAPL, GOOGL, MSFT), each with price data for one security. Each row is a date, enabling easy cross-security price comparison. This format aligns values for cross-security calculations in the same row. Computing a correlation matrix or portfolio returns becomes straightforward.
Long format works better for filtering and grouping operations: especially when applying the same analysis across multiple securities or including additional attributes like sector or fundamentals.
Each price observation is a separate row with columns for date, ticker, and price. The first three rows show the same date with different tickers. Long format enables easy filtering and grouping, though cross-security calculations require pivoting to wide format. Understanding when to use each format saves effort as analyses grow more complex.
Time Series Fundamentals
Financial analysis revolves around time series: sequences of observations indexed by time. Unlike cross-sectional data where observations are independent, time series data has an inherent ordering that encodes crucial information. Prices depend on prior values, volatility clusters, and patterns repeat across periods. Pandas provides specialized tools for temporal data that simplify complex time-based logic into concise, readable code.
The DatetimeIndex
A pandas index type for timestamps enabling time-based slicing, resampling, and alignment, essential for financial data analysis.
DatetimeIndex: The DatetimeIndex is one of pandas' most powerful features for financial applications. When your DataFrame has a DatetimeIndex, you gain access to intuitive time-based selection that understands calendar concepts like months, quarters, and years. This enables simple string-based slicing instead of complex boolean logic.
January contains approximately 21 business days of data, while Q1 contains about 63 days. The specific day selection returns a Series with one price value for each security. This demonstrates how DatetimeIndex enables intuitive slicing without complex boolean logic. Partial string indexing is far more readable than filtering with boolean masks, especially when working with dates. Without DatetimeIndex, you'd need complex boolean conditions to compare dates and handle month boundaries. The DatetimeIndex handles all of this automatically, expressing your intent directly.
Resampling Time Series
Financial data often needs to be converted between frequencies. Daily prices might need weekly or monthly conversion for longer-term analysis, risk reporting, or comparison with lower-frequency economic data. Alternatively, you might aggregate intraday tick data into daily bars for overnight processing. The resample() method handles this transformation elegantly, treating time series frequency conversion as a specialized form of grouping.
Prices appear at the end of each month, reducing 252 daily observations to approximately 12 monthly observations. Each row represents the last trading day of the month. Downsampling is useful for longer-term analysis where daily fluctuations obscure trends. Upsampling requires choosing how to fill gaps: interpolation or forward-filling introduces artificial data points. Interpolation or forward-filling introduces artificial data points. For most financial applications, downsampling to lower frequencies is more practical. Frequency codes follow a consistent pattern: 'D' for daily, 'W' for weekly, 'ME' for month end, and 'QE' for quarter end. You can also resample to higher frequencies (upsampling), though this requires specifying how to fill the gaps. The aggregation function choice matters. Using 'last' preserves the end-of-period price, while 'mean' computes the period average. For OHLC data, use 'first' for open, 'max' for high, 'min' for low, 'last' for close, and 'sum' for volume to preserve each field's meaning.

Rolling Window Calculations
Many financial metrics rely on rolling windows, including moving averages, rolling volatility, and rolling correlations. These calculations capture how a statistic evolves over time and provide insight into changing market conditions that a single summary statistic would obscure. A rolling window calculation computes a statistic over a fixed-size moving window of data. For a window of size at time , we compute the statistic using observations from to .
Imagine sliding a frame across the data. At each position, you calculate a statistic using observations inside the frame, record it, then shift the frame forward by one observation. This generates a time series showing how the statistic evolves. Smaller windows respond quickly to recent data but are noisier. Larger windows are smoother but lag behind changes.

Formally, a rolling statistic with window size is computed as:
where:
- : statistic value at time
- : the statistical function (examples include mean, standard deviation, maximum, minimum, or any aggregate function)
- : the observation at time
- : the window size (number of observations to include)
- : current time index
At each time point : you gather the most recent observations, apply your chosen function , and record the result. As advances, the window slides forward by dropping the oldest observation and incorporating the newest one. This creates a dynamic view of your statistic that reveals patterns invisible in static summaries.
Pandas makes these calculations straightforward:
The annualization formula converts daily volatility to annual volatility. This conversion is essential: risk metrics are conventionally quoted on an annual basis, allowing comparison across assets and time periods. To understand why the square root appears, consider that volatility scales with the square root of time under the assumption of independent returns (the "square root of time" rule). This relationship, known as the "square root of time" rule, shows how risk scales across investment horizons.
where:
- : annualized volatility (standard deviation of annual returns)
- : daily volatility, which is the standard deviation of daily returns
- : number of trading days per year, which is 252 for US markets
This formula arises from the statistical properties of independent returns: assuming daily returns are independent and identically distributed with variance σ_d², the variance of returns over T days aggregates additively. The variance of a sum of independent random variables equals the sum of their variances, which is a fundamental property of probability theory. Therefore, if daily returns have variance σ_d², the variance of T-day cumulative returns is:
where:
- : variance of cumulative returns from time 0 to time
- : return at time
- : variance of daily returns
- : number of days
Taking the square root to obtain standard deviation gives:
where:
- : volatility over days (standard deviation of -day returns)
- : daily volatility
- : number of days
A daily volatility of 1% does not imply annual volatility of 252% but rather approximately 16%, since . This distinction has profound implications for risk management and option pricing.
AAPL prices appear alongside their 20-day and 50-day moving averages. Notice how the moving averages smooth out daily price fluctuations, creating a cleaner representation of the underlying trend. The 20-day MA responds more quickly to price changes than the 50-day MA due to its shorter window. This responsiveness difference is why technical analysts often watch for crossovers between fast and slow moving averages as potential trading signals. The current volatility value represents the annualized standard deviation of returns over the most recent 20 trading days. Higher volatility indicates greater price uncertainty. The window parameter specifies the number of observations to include. The first n-1 values are NaN because insufficient history exists to compute the statistic, where n is the window size. Use min_periods to set the minimum number of observations required for a valid result, allowing calculations to begin earlier with less data.
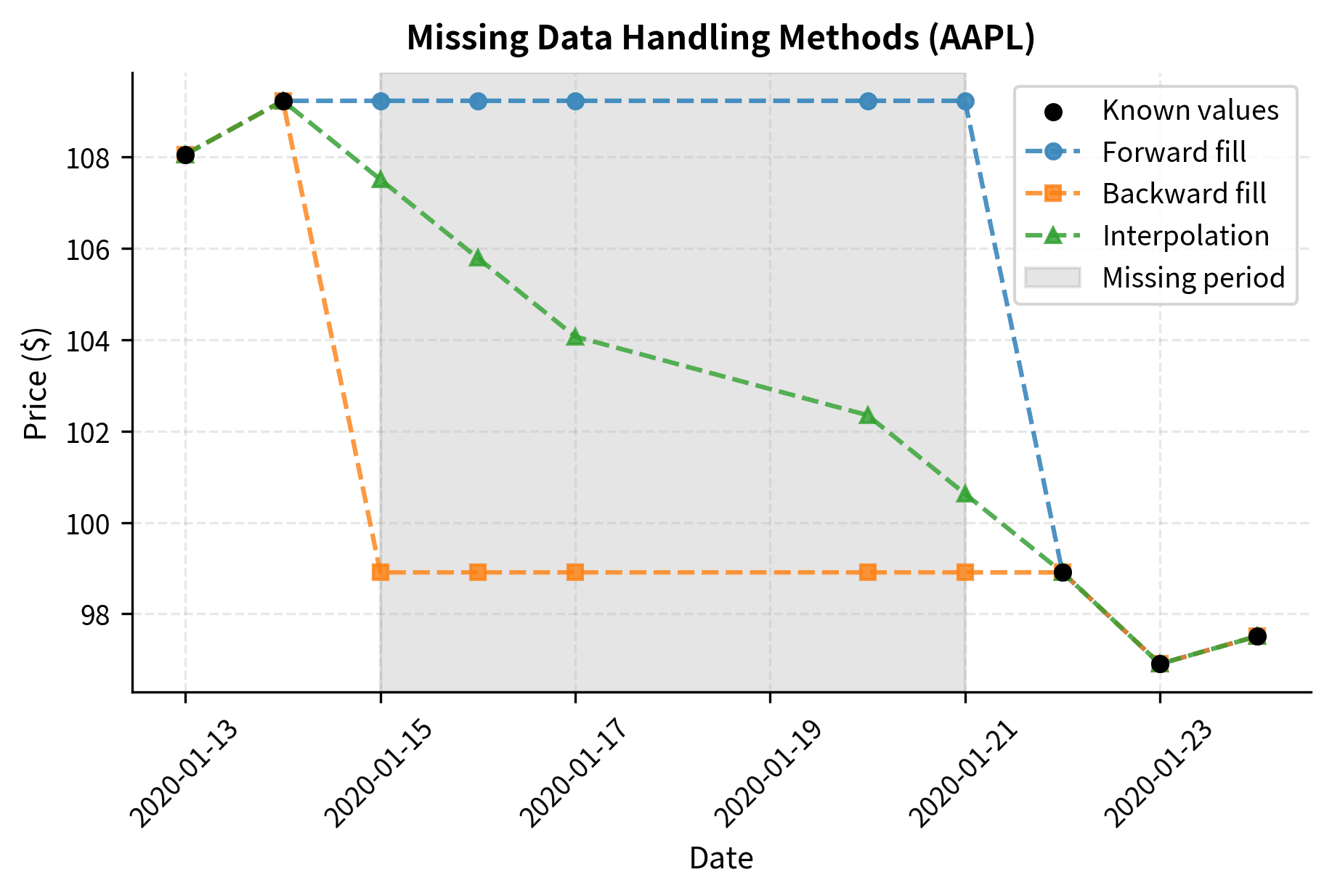
Handling Missing Data
Financial time series frequently contain missing values. Markets close for holidays, securities halt trading, and data feeds occasionally fail. Most analytical functions cannot operate on missing values: your choice of how to fill gaps significantly affects results.
AAPL has 5 missing values and GOOGL has 2, while MSFT has none. These gaps represent periods when we artificially removed data to demonstrate handling techniques. In real data, missing values might indicate trading halts, data feed failures, or corporate actions. Pandas provides several strategies for handling missing data: each strategy has different assumptions and use cases.
Dropping missing values reduces the dataset from 252 to approximately 245 rows, losing about 7 days of data. Forward filling eliminates all missing values (0 remaining) by carrying the last known price forward. This preserves all time periods but assumes prices remained constant during gaps. Choose based on your priorities: data completeness versus avoiding assumptions about missing periods. Forward filling is the most common approach for price data because it represents the last known price. However, use caution. It can introduce look-ahead bias if not applied carefully, and long gaps might mask important market events.
Data Manipulation
Beyond loading and time series operations, you need to filter, transform, and aggregate data for analysis. These manipulation skills form the bridge between raw data and actionable insights.
Computing Returns
The most fundamental transformation in quantitative finance is converting prices to returns. Returns have better statistical properties than prices: they are stationary, comparable across securities, and easier to aggregate. Prices drift arbitrarily over time. Returns fluctuate around a stable mean with consistent variance that statistical methods require.
Simple returns measure the percentage price change from one period to the next, representing profit or loss per dollar invested. Use simple returns when calculating actual monetary gains or losses. For an investment that moves from price to , the simple return is:
where:
- : simple return at time (fractional change, e.g., 0.05 for a 5% gain)
- : price at time
- : price at the previous time period
The numerator computes dollar profit or loss. For example, a stock moving from 105 gains P_{t-1}100 to 5 / (a 5% return). This normalization enables performance comparison across securities with different price levels, since a 100 stock versus a $500 stock.
Log returns use the natural logarithm of the price ratio and have attractive mathematical properties. Importantly, log returns sum across time periods:
where:
- : log return at time (continuous compounding rate)
- : price at time
- : price at the previous time period
- : natural logarithm (base )
The logarithm transforms multiplicative price changes to additive returns, bridging discrete and continuous-time financial theory. Since , multi-period log returns sum simply. This additive property greatly simplifies calculations involving cumulative returns over many periods.
The first five daily returns appear for each stock. The first row contains NaN values because we cannot calculate returns without a previous price: computing returns always costs one observation at the beginning of your series. The mean daily returns are small positive values, which is typical for equity returns. These represent the average daily percentage change across the sample period. Positive values indicate an upward drift in prices, though individual days show both gains and losses.


::: {.callout-note title="Simple vs. Log Returns"} Simple returns represent the actual percentage gain or loss an investor experiences and aggregate correctly across assets in a portfolio, making them essential for portfolio accounting.
where:
- : total portfolio return, which is the weighted average of individual returns
- : weight of asset in the portfolio, which is the fraction of total portfolio value where
- : simple return of asset over the period
- : sum over all assets in the portfolio, where index ranges over all holdings
This linear aggregation property is why simple returns are preferred for portfolio calculations. Each asset contributes to the portfolio return in proportion to its weight, making attribution straightforward. If you hold 60% stocks and 40% bonds, your portfolio return is simply 0.6 times the stock return plus 0.4 times the bond return.
Log returns aggregate additively across time. To find the total return over multiple periods, simply sum the individual period returns.
where:
- : cumulative log return from time 0 to time
- : log return for period , from time to time
- : final time period, which is the total number of periods
- : sum over all periods from 1 to
This additive property arises because \ln(P_T/P_0) = \ln(P_T/P_{T-1}) + \ln(P_{T-1}/P_{T-2}) + \cdots + \ln(P_1/P_0), making multi-period calculations simple. You can compute the return over any horizon by summing sub-period returns without any compounding adjustments.
For small returns where , log and simple returns are approximately equal, with r ≈ R, because higher-order terms in the Taylor expansion of ln(1+R) are negligible. Most theoretical models use log returns for mathematical convenience. Portfolio calculations use simple returns for accuracy.
Filtering and Selecting
Boolean indexing extracts data subsets that meet specific criteria, enabling event studies, anomaly detection, and conditional sample construction.
AAPL had large moves exceeding 3% on several days. Synchronized trading days indicate market-wide correlation. More synchronization suggests common factors, while less suggests idiosyncratic behavior. These filtering operations identify periods worth exploring further.
Merging Datasets
Financial analysis often requires combining data from different sources such as prices with fundamentals, returns with factor exposures, or multiple time series with different starting dates.
Four columns appear (three stock returns plus market return). The shape confirms 252 rows and one new column. The inner join ensures we only keep dates present in both datasets. This prevents alignment errors. This combined view enables calculations like beta estimation or performance attribution that require comparing security returns to market returns. The join method aligns on the index, which works well for time series with the same frequency. For more complex merges, use pd.merge() with explicit key columns.
Summary Statistics
Compute comprehensive statistical summaries to understand your data's characteristics:
This view reveals key return distribution characteristics. Mean values show average daily returns, standard deviation quantifies typical volatility, and min/max values show extreme single-day moves. Skewness near zero suggests symmetric distributions, though equity returns typically show slight negative skew. Positive kurtosis indicates fat tails: extreme returns occur more frequently than normal theory predicts. This universal feature matters critically for risk management.
Performance Optimization
Pandas and NumPy are highly optimized, but certain operations become bottlenecks with large datasets or real-time systems. Knowing when and how to optimize matters.
NumPy: The Foundation
NumPy arrays underpin pandas and provide the fastest vectorized operations. Vectorization applies operations to entire arrays at once instead of looping through individual elements. For performance-critical code: working directly with NumPy arrays provides the best performance.
One fewer return observation exists per security since returns require two prices. The first few returns display as a matrix showing the initial return calculations for each security. Working with NumPy arrays directly eliminates pandas overhead for pure numerical operations, providing substantial speed improvements. Avoid Python loops over array elements. Apply operations to entire arrays at once to leverage NumPy's compiled C code.
Numba: JIT Compilation for Custom Functions
Numba compiles Python functions to machine code at runtime, achieving C-like performance while maintaining Python syntax.
When standard NumPy operations cannot express your custom logic, Numba provides high performance. Write ordinary Python code, and Numba automatically translates it to fast machine code when the function is first called.
The worst peak-to-trough decline during the period appears in the maximum drawdown. The current drawdown indicates how far the current price sits below the most recent peak. A current drawdown of 0% means we are at a new all-time high: a negative value shows we are below the peak. These metrics are critical for assessing risk and understanding the worst-case historical losses an investment experienced. The @jit(nopython=True) decorator tells Numba to compile the function without falling back to Python objects. This provides the best performance while requiring only NumPy arrays and basic Python types.


Let's compare performance between a pure Python implementation and the Numba version:
Numba demonstrates a dramatic performance advantage over pure Python. Pure Python is slower due to interpreter overhead on each iteration. Numba compiles the function to machine code and achieves near-C speeds. The speedup multiplier quantifies the performance gain. This speedup matters for tick data processing, Monte Carlo simulations, and strategy backtesting.
Cython: When You Need More Control
Cython offers another approach to performance optimization by compiling Python-like code to C. While Numba is sufficient for most needs, Cython provides more control over memory management and C library integration when required.
Start with pandas and NumPy. Use Numba when profiling reveals bottlenecks due to its simpler workflow. Reserve Cython for C library integration or extreme optimization.
When to Optimize
Follow this approach to optimization:
- Write clear code first using pandas and NumPy
- Profile to identify actual bottlenecks with tools like %timeit or cProfile
- Optimize the critical 10% consuming 90% of runtime
- Verify correctness after optimization
Avoid premature optimization: a 50ms versus 5ms backtest difference rarely matters during development. However, a live trading system unable to process market data fast enough will miss opportunities and incur losses.
Data Visualization
Visualizations reveal patterns and relationships in data that remain invisible in raw numbers.
Price Charts
The price chart is the most fundamental financial visualization, showing how prices evolve over time.
Prices trended upward overall in 2020 with notable volatility. The different y-axis scales make direct comparison difficult. GOOGL trades at higher absolute prices than AAPL or MSFT, so normalization to a common starting point is needed to reveal relative performance.
AAPL and MSFT outperformed GOOGL. The common baseline of 100 reveals relative performance clearly. All three stocks dipped sharply in March 2020, followed by recovery. Normalization is essential when comparing investments with different price levels.
Return Distributions
Return distribution visualizations reveal characteristics critical for quantitative models.
AAPL returns concentrate near zero compared to the normal distribution (red). The actual distribution has a higher peak near zero and fatter tails than the normal distribution. Extreme returns occur more frequently than normal theory predicts. Fat tails represent a fundamental stylized fact of financial returns.

Scatter Plots and Correlations
Correlations between securities matter for portfolio construction and risk management. Scatter plots visualize pairwise relationships by plotting one variable against another.
AAPL and GOOGL returns show a clear positive relationship, moving together on both positive and negative days. The red regression line captures this relationship. Moderate correlation indicates synchronized movement with some independent variation. Perfect correlation (1.0) shows points on the line, while zero correlation shows a random cloud. Lower correlation provides better diversification than highly correlated assets. For multiple securities, A correlation matrix summarizes all pairwise relationships.
The diagonal shows perfect correlation, 1.0, while off-diagonal values reveal relationships between securities. All pairs show positive correlations, indicated by warm colors, with varying strength across pairs. Market-wide correlation reduces diversification benefits when constructing portfolios from similar sectors.
Rolling Statistics
Financial relationships are not static: rolling correlations reveal how relationships evolve over time.
The relationship between AAPL and GOOGL fluctuates from weak to strong positive correlation, indicating varying degrees of synchronized movement. The rolling volatility plot shows AAPL's risk profile varies significantly throughout the year and spikes in March 2020 during COVID-19 volatility. Time-varying metrics demonstrate that constant-parameter models fail to capture reality. Static models can break down dramatically when market conditions shift.
Limitations and Practical Considerations
Pandas prioritizes convenience, but row-wise iteration and complex conditional logic can be orders of magnitude slower than necessary. Performance optimization techniques using Numba address many of these bottlenecks. Optimization requires careful attention to data types: unexpected inputs can introduce subtle bugs.
Data quality issues pervade financial datasets: missing values from trading halts, stock splits that distort price series, survivorship bias in historical databases, and timestamp inconsistencies across data sources. The fillna() and interpolate() methods address these issues: the right approach depends on the data's context. Forward-filling works for portfolio calculations but risks look-ahead bias in backtests.
Effective financial visualization balances art and science and requires customization for specific audiences and purposes. A chart for internal research can prioritize information density, while a client presentation might emphasize clarity and visual appeal. Matplotlib offers extensive customization, though mastering it takes practice.
These patterns assume datasets that fit in memory. Production systems handling tick data or large security universes require different architectures with databases, chunked processing, and distributed computing. Subsequent chapters will build on these foundations while introducing more sophisticated analytical techniques.
Summary
This chapter covered essential data handling and visualization skills for quantitative finance.
Data loading and management: Pandas provides a unified interface for financial data from multiple sources. A DatetimeIndex enables time-based slicing, resampling, and rolling calculations.
Time series operations: Resampling converts between frequencies, rolling windows compute statistics, and proper missing data handling prevents errors.
Data manipulation: Convert prices to returns, then filter, merge, and summarize data for analysis.
Performance optimization: Use Numba's JIT compilation when pandas becomes a bottleneck, achieving dramatic speedups while maintaining Python syntax. Start with clear code, profile to find bottlenecks, and optimize only where needed.
Visualization: Charts reveal patterns invisible in summary statistics. Use price charts, distributions, correlations, and rolling metrics to explore data.
You will repeatedly use these data handling patterns when calculating risk, building factor models, or training machine learning models.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about data handling and visualization in quantitative finance.

Comments