

A comprehensive guide covering statistical modeling fundamentals, including measuring model fit with R-squared and RMSE, understanding the bias-variance tradeoff between overfitting and underfitting, and implementing cross-validation for robust model evaluation.

This article is part of the free-to-read Machine Learning from Scratch
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Statistical Modeling: Building and Evaluating Predictive Models
Statistical modeling forms the bridge between data and insight, providing a formal framework for understanding relationships between variables and making predictions. At its core, statistical modeling involves constructing mathematical representations of real-world phenomena, evaluating how well these models capture underlying patterns, and ensuring they generalize effectively to new data.
Introduction
The journey from raw data to actionable predictions requires careful attention to model quality. While building a model might seem straightforward (fit a line to data points, train a classifier on labeled examples), the true challenge lies in creating models that are neither too simple to capture meaningful patterns nor so complex that they memorize noise instead of learning genuine relationships.
This chapter explores three fundamental concepts that data scientists should understand when building statistical models. First, we examine how to measure model fit using quantitative metrics that assess prediction accuracy. Second, we investigate the balance between underfitting and overfitting, two failure modes that represent opposite extremes of model complexity. Finally, we introduce cross-validation, a robust technique for evaluating model performance that helps ensure our models will perform well on unseen data.
Understanding these concepts provides the foundation for all machine learning and statistical modeling work. Whether you're fitting a simple linear regression or training a deep neural network, the principles of measuring fit, avoiding overfitting, and validating performance remain constant. These skills enable practitioners to build models that not only perform well on training data but also deliver reliable predictions in production environments.
Model Fit: Quantifying Prediction Quality
When we build a statistical model, our primary goal is to create a function that accurately predicts outcomes for new observations. Model fit refers to how well our model's predictions align with actual observed values. Quantifying this fit allows us to compare different models, diagnose problems, and communicate model quality to stakeholders.
Measuring Fit with R-squared
For regression tasks where we predict continuous outcomes, R-squared (the coefficient of determination) provides an intuitive measure of model fit. R-squared quantifies the proportion of variance in the dependent variable that our model successfully explains. The formula captures this relationship through the ratio of explained variance to total variance:
Where:
- : Actual observed value for observation
- : Model's predicted value for observation
- : Mean of all actual values
- : Number of observations
R-squared typically ranges from 0 to 1 for models that include an intercept, with values closer to 1 indicating better fit. Values can be negative when a model performs worse than simply predicting the mean. An R-squared of 0.85, for instance, tells us that our model explains 85% of the variance in the outcome variable, leaving only 15% unexplained. However, R-squared has important limitations. It increases when we add more predictors, even if those predictors add no real explanatory power. Additionally, a high R-squared doesn't guarantee that our model assumptions are met or that we've captured causal relationships rather than spurious correlations.
Root Mean Squared Error
While R-squared provides a proportional measure of fit, Root Mean Squared Error (RMSE) offers an absolute measure in the same units as our target variable. RMSE calculates the standard deviation of prediction errors, giving us a concrete sense of how far off our predictions typically are:
The appeal of RMSE lies in its interpretability. If we're predicting house prices in dollars and obtain an RMSE of 25,000. RMSE penalizes large errors more heavily than small ones due to the squaring operation, making it particularly sensitive to outliers. This sensitivity can be advantageous when large errors are especially costly, but it also means that a few extreme mispredictions can dominate the metric.
When comparing models, lower RMSE values indicate better fit. Unlike R-squared, RMSE doesn't have an upper bound and depends on the scale of the target variable, so it's most useful for comparing models predicting the same outcome rather than for assessing model quality in isolation.
Example: Comparing Model Fit Metrics
The following visualization demonstrates how different levels of model fit manifest in both R-squared and RMSE metrics. We'll examine three scenarios representing excellent, moderate, and poor model fit.
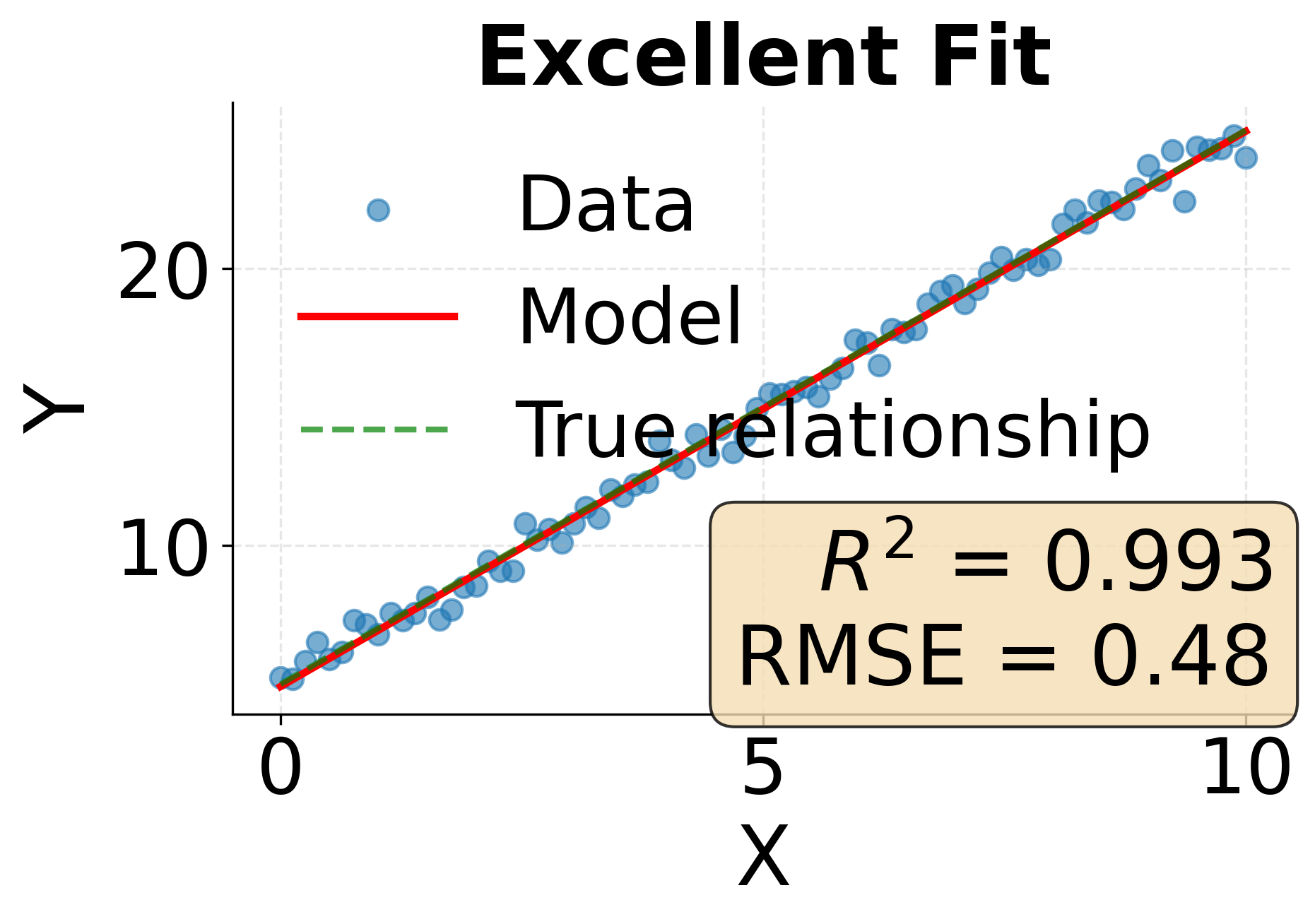
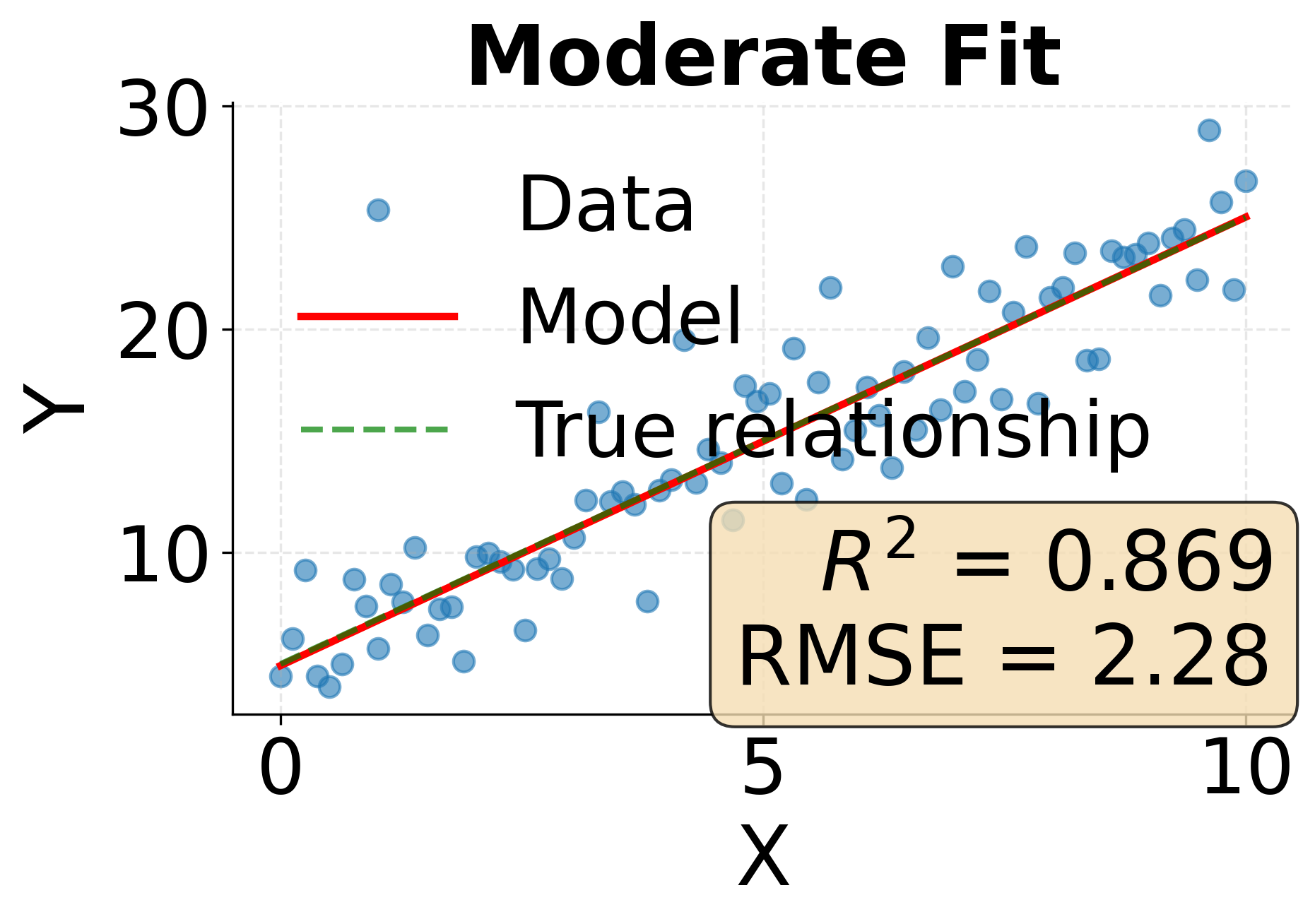
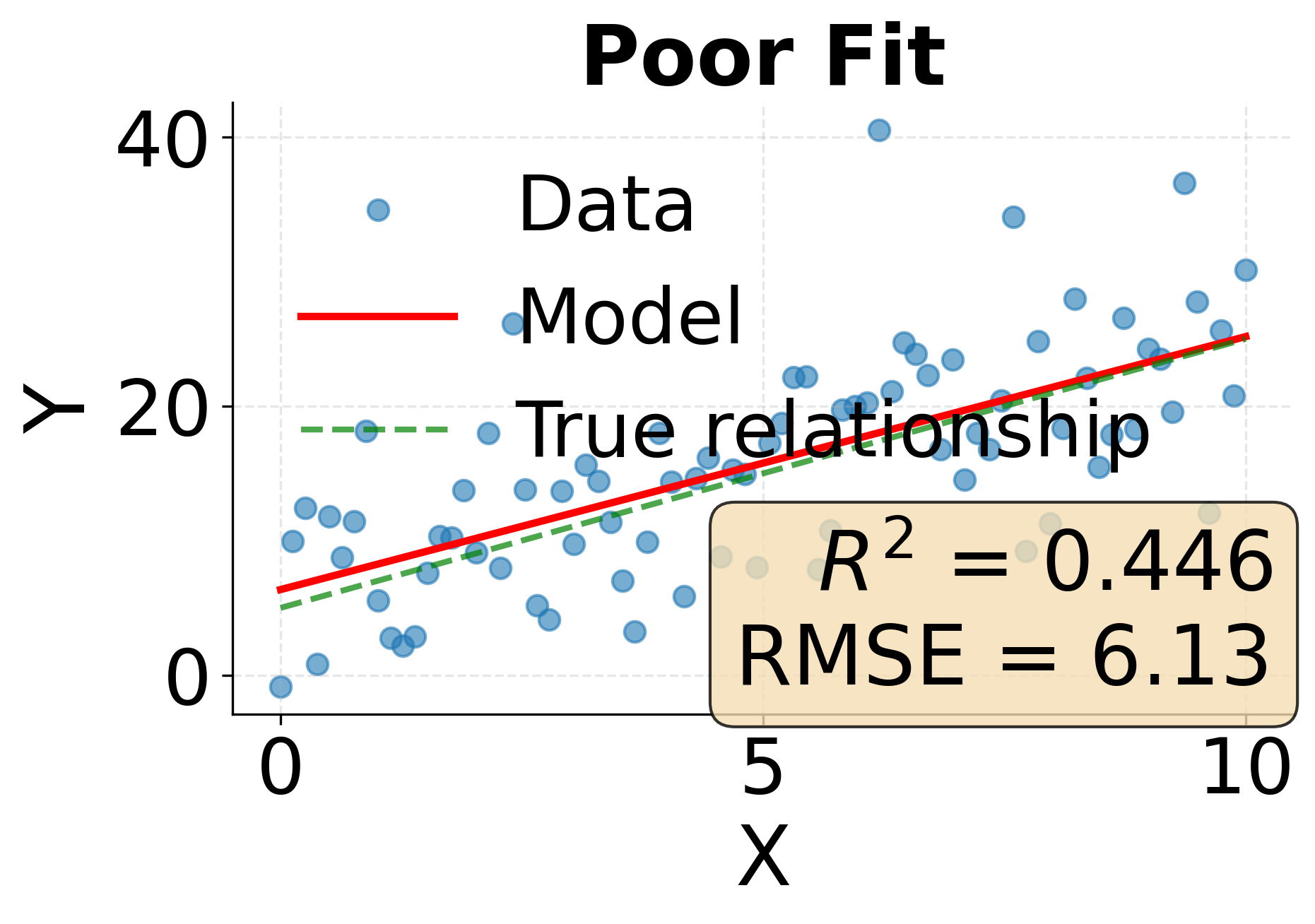
One of the most fundamental challenges in statistical modeling is finding the right level of model complexity. Too simple a model fails to capture important patterns in the data, while too complex a model learns noise and spurious relationships that don't generalize. This tension between simplicity and complexity manifests as the bias-variance tradeoff, and understanding it is important for building models that perform well on new data.
Understanding Underfitting
Underfitting occurs when our model is too simple to capture the underlying structure in the data. An underfit model has high bias, meaning it makes strong assumptions that don't align with reality. For example, trying to fit a straight line to data that follows a curved pattern results in underfitting. The model consistently misses the mark because it lacks the flexibility to represent the true relationship.
The symptoms of underfitting are straightforward to diagnose. The model performs poorly on both training data and test data, suggesting it hasn't learned the fundamental patterns. Predictions systematically deviate from actual values in ways that reveal the model's inadequacy. In practice, underfitting often stems from using overly simple model architectures, insufficient features, or excessive regularization that constrains the model too severely.
Understanding Overfitting
Overfitting represents the opposite problem. An overfit model is so complex that it learns not just the underlying patterns but also the random noise present in the training data. This model has high variance, meaning small changes in the training data lead to large changes in the fitted model. While an overfit model achieves excellent performance on training data, it fails when confronted with new observations because the patterns it learned were specific to the training set rather than general truths.
Detecting overfitting requires comparing training and test performance. The hallmark sign is a large gap between the two: near-perfect training accuracy but poor test accuracy. The model has essentially memorized the training examples rather than learning transferable patterns. Common causes of overfitting include using models with too many parameters relative to the amount of training data, training for too many iterations, or failing to apply appropriate regularization.
Finding the Sweet Spot
The goal of model building is to find the sweet spot between underfitting and overfitting where the model captures real patterns without learning noise. This optimal complexity level minimizes total error, balancing the bias from oversimplification against the variance from excessive complexity. Achieving this balance requires careful attention to model selection, regularization strategies, and validation procedures.
Practical strategies for managing this tradeoff include starting with simple models and gradually increasing complexity while monitoring validation performance. Regularization techniques like L1 and L2 penalties add constraints that prevent overfitting without requiring us to manually limit model complexity. Feature selection helps by removing irrelevant predictors that add noise. Most importantly, proper validation using held-out test data ensures we detect overfitting before deploying models to production.
Example: The Spectrum from Underfitting to Overfitting
This visualization demonstrates how model complexity affects fit quality. We'll fit polynomial models of increasing degree to the same data, showing how insufficient complexity leads to underfitting while excessive complexity produces overfitting.
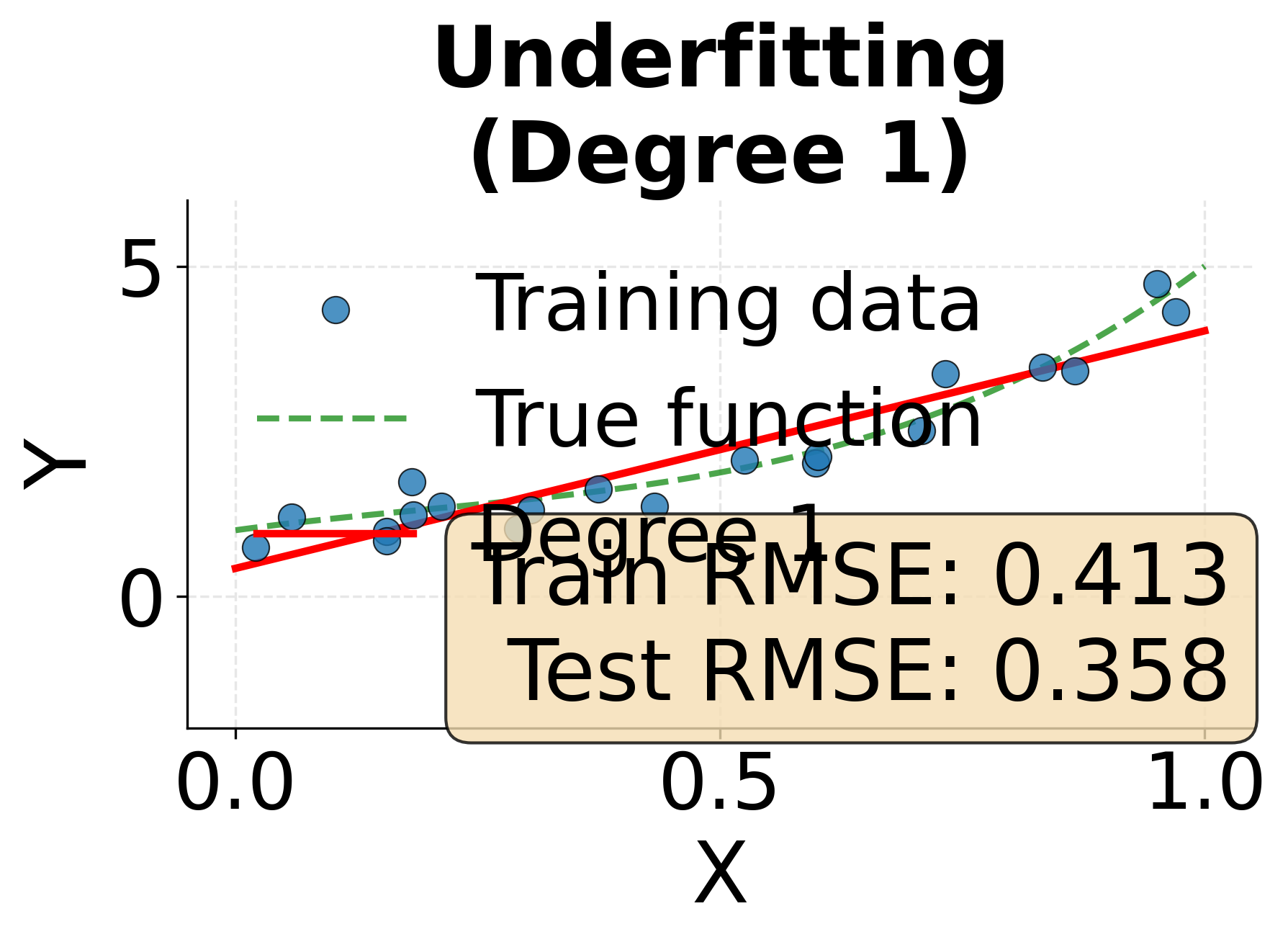
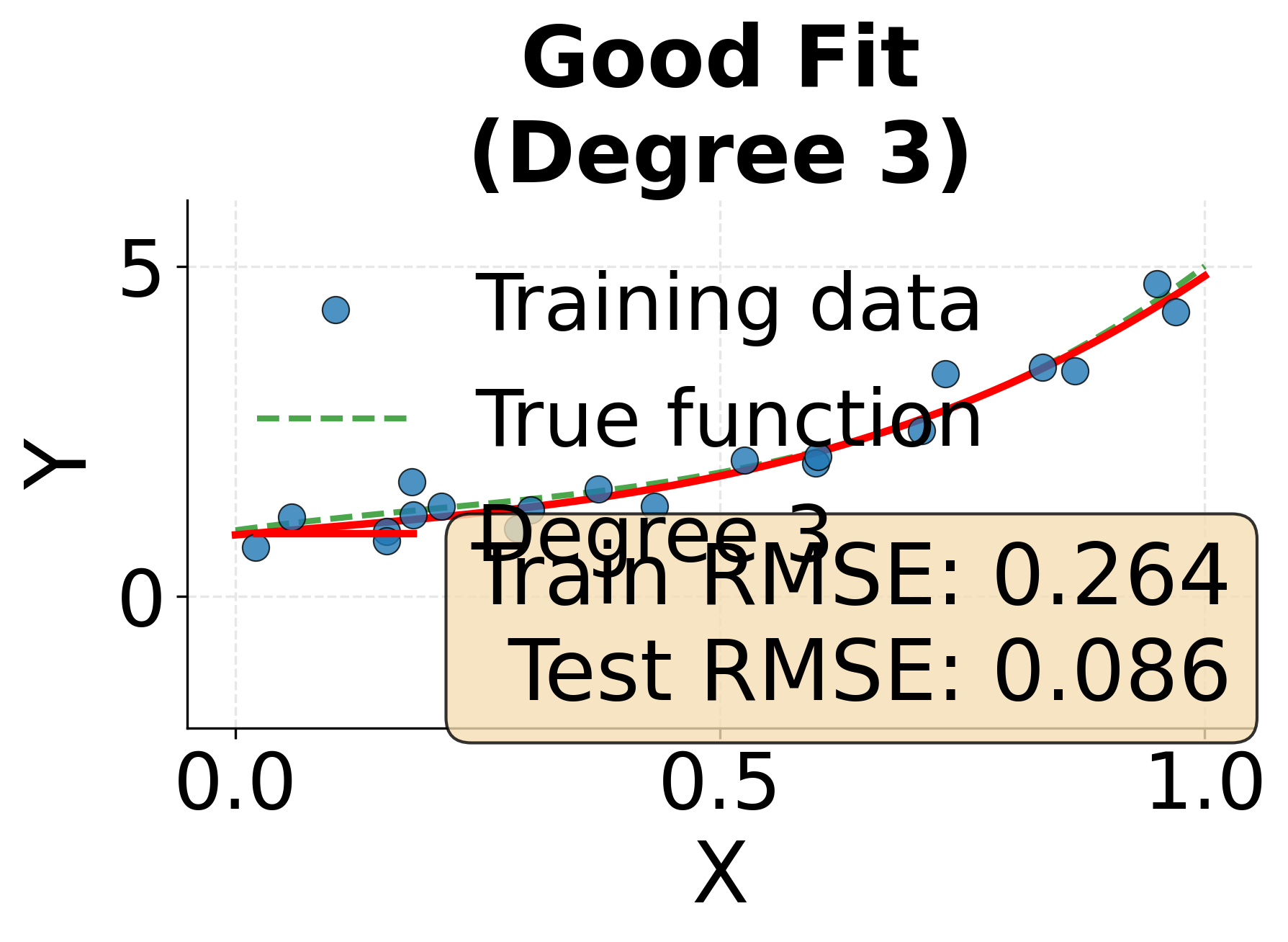
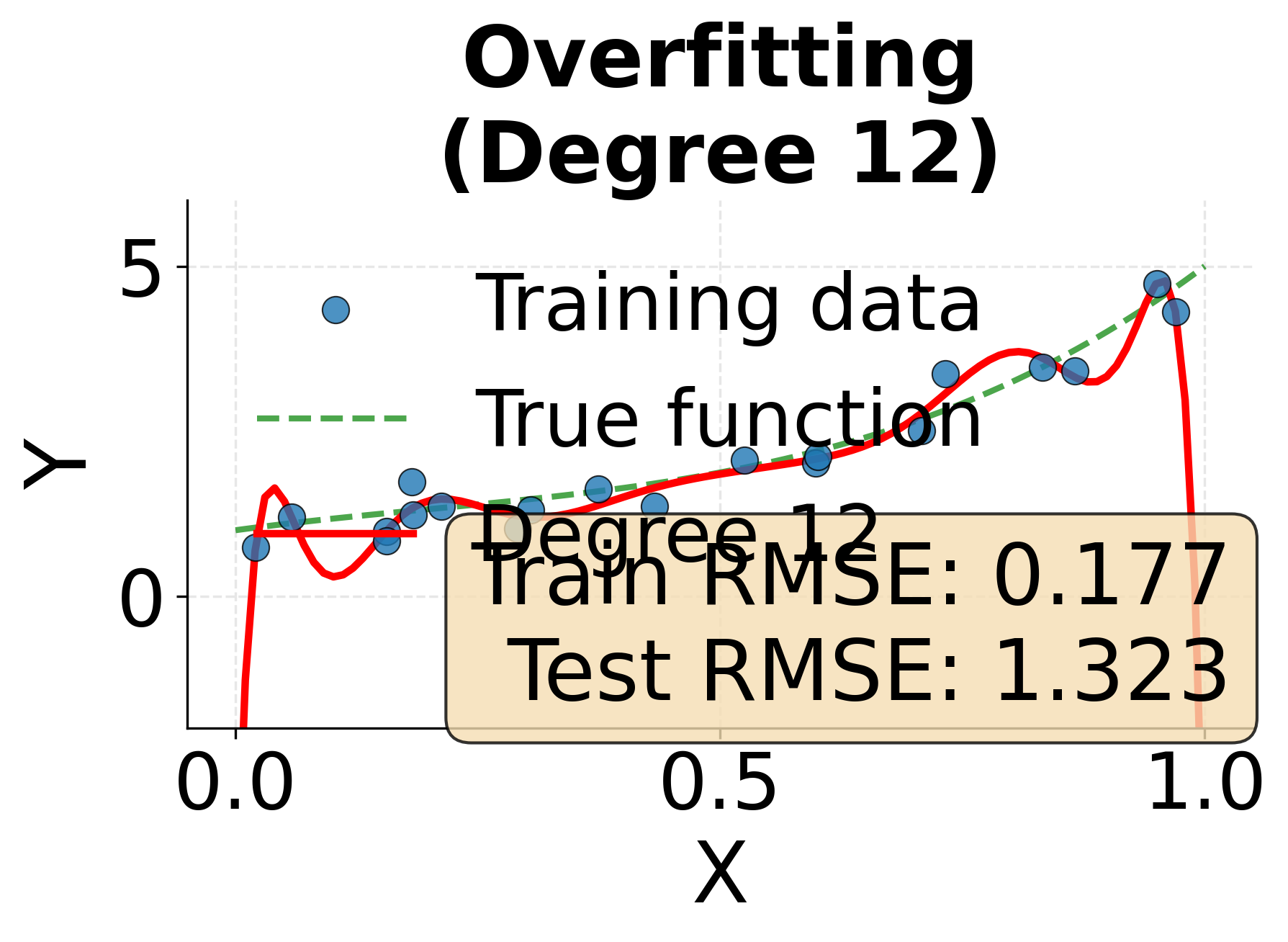
Cross-Validation: Robust Model Evaluation
Simply splitting data into training and test sets provides a basic evaluation framework, but this approach has limitations. The performance estimate depends heavily on which specific observations end up in each set, leading to high variance in our assessment. Cross-validation addresses this problem by systematically using different portions of the data for training and testing, producing more stable and reliable performance estimates.
K-Fold Cross-Validation
The most common cross-validation approach is k-fold cross-validation, which divides the dataset into k equally sized folds. The algorithm then trains k different models, each time using k-1 folds for training and the remaining fold for validation. By averaging performance across all k trials, we obtain a robust estimate that reduces the influence of any particular train-test split.
Typical choices for k range from 5 to 10, with k=5 or k=10 being most common. Larger values of k provide more training data for each model and more comprehensive evaluation but increase computational cost. The extreme case, leave-one-out cross-validation where k equals the number of observations, provides maximum data efficiency but can be prohibitively expensive for large datasets.
The Cross-Validation Process
The process begins by randomly shuffling the data and partitioning it into k folds. In the first iteration, we train our model on folds 2 through k and evaluate it on fold 1. In the second iteration, we train on folds 1 and 3 through k while evaluating on fold 2. This continues until each fold has served as the validation set exactly once. The final performance metric averages the results across all k iterations, often reported with a standard error to capture variability.
This systematic rotation through the data ensures that every observation is used for both training and validation, maximizing the information we extract from limited data. It also provides insight into model stability. If performance varies dramatically across folds, this suggests the model is sensitive to the specific training examples it sees, which may indicate overfitting or insufficient training data.
Stratified Cross-Validation
For classification problems, particularly those with imbalanced classes, stratified cross-validation offers an important refinement. Standard k-fold cross-validation might by chance create folds where rare classes are underrepresented or missing entirely. Stratified cross-validation ensures that each fold maintains approximately the same class distribution as the complete dataset, leading to more representative performance estimates and preventing situations where the validation set contains no examples of certain classes.
Cross-Validation for Model Selection
Beyond evaluating a single model's performance, cross-validation plays an important role in comparing different models and selecting hyperparameters. When we need to choose between different model architectures or tune parameters like regularization strength, cross-validation provides an honest assessment of how each configuration will perform on new data. The key is to avoid using the test set for these decisions. Instead, we use cross-validation on the training data to select the best model, then evaluate that final model on a held-out test set that has never been seen during the model development process.
Example: Visualizing Cross-Validation Splits
This example illustrates how 5-fold cross-validation systematically rotates through the data, with each fold serving as validation data once while the remaining folds provide training data.
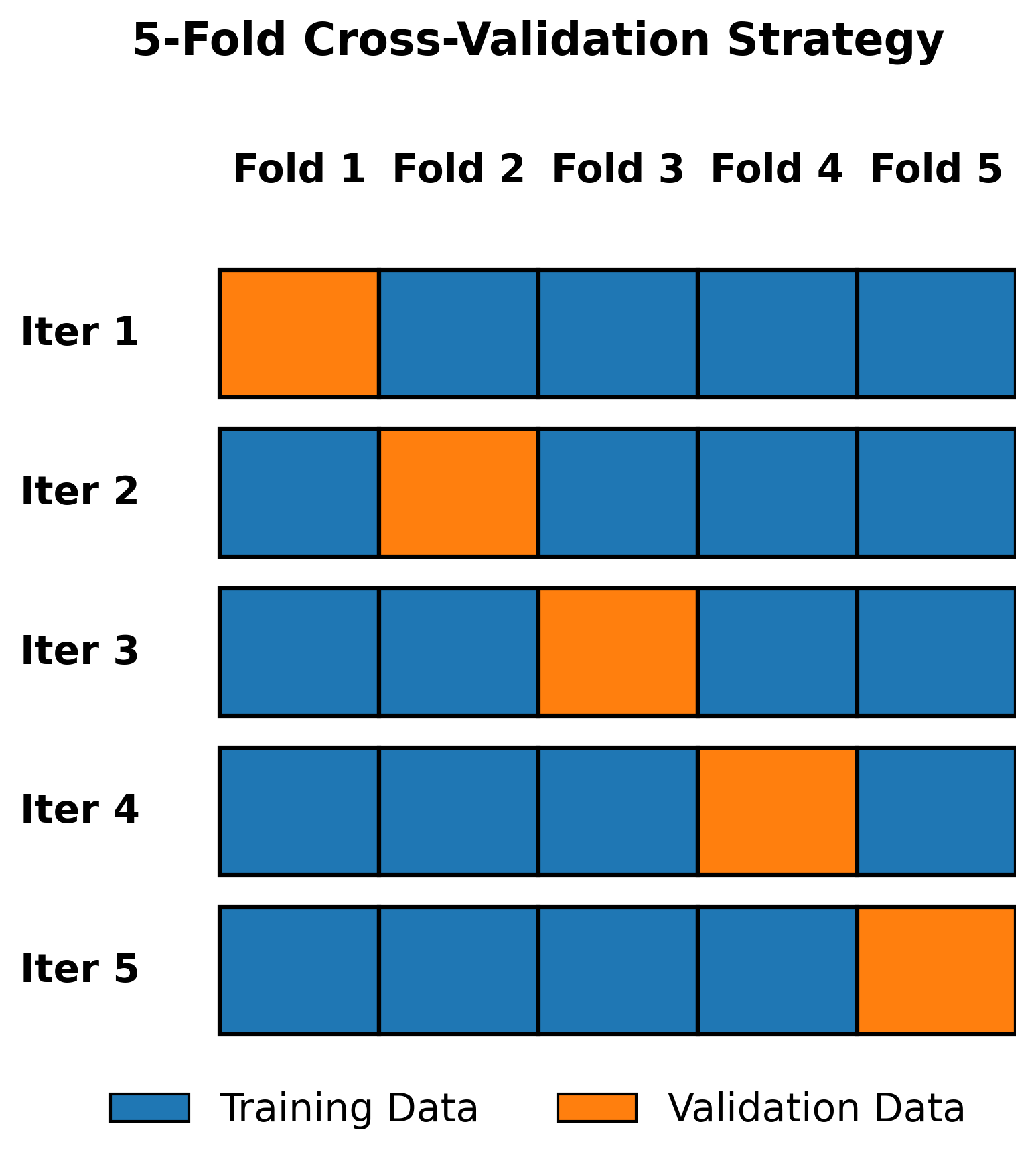
Practical Applications
Statistical modeling concepts apply across virtually every data science domain. In predictive analytics for business, companies use these principles to build models that forecast sales, predict customer churn, or estimate credit risk. The metrics discussed here help quantify prediction accuracy in dollars or percentage points, making it possible to calculate the business value of improved models. Cross-validation ensures these models perform reliably when deployed on new customers or time periods.
In healthcare, models predict patient outcomes, disease progression, or treatment efficacy. Here the stakes are particularly high. Overfitting could lead to models that perform well in clinical trials but fail in broader populations. Rigorous cross-validation helps identify this problem before deployment, while metrics like RMSE provide interpretable measures of prediction error in clinically meaningful units like days of hospital stay or probability of readmission.
Scientific research employs these techniques to understand relationships between variables and make predictions about natural phenomena. Climate scientists build models to predict temperature changes or extreme weather events, using cross-validation to ensure predictions hold across different time periods and geographic regions. Ecologists model species populations, where understanding the difference between model uncertainty and natural variability is important for conservation decisions.
In engineering applications, models predict system failures, optimize manufacturing processes, or control autonomous systems. The bias-variance tradeoff becomes particularly important in robotics, where underfit models may fail to navigate complex environments while overfit models might not transfer from simulation to reality. Cross-validation helps tune these models to achieve reliable real-world performance.
Limitations and Considerations
While the metrics and techniques discussed provide powerful tools for model evaluation, they come with important caveats that practitioners should understand. R-squared and RMSE only measure prediction accuracy on the specific data we have. They say nothing about whether our model will work on fundamentally different populations or whether it has captured causal relationships that remain stable under interventions. A model with excellent metrics might still fail catastrophically if deployed in a context that differs from the training environment.
Cross-validation assumes that the data points are independent and identically distributed. This assumption breaks down in many real-world scenarios. Time series data exhibits temporal dependencies that violate independence, requiring specialized cross-validation strategies that respect temporal order. Hierarchical or clustered data where observations within groups are correlated requires cluster-aware cross-validation to avoid overoptimistic performance estimates.
The choice of evaluation metric matters enormously and should align with the actual costs and benefits in the application domain. RMSE weights all errors equally after squaring, but in many applications, different types of errors have vastly different consequences. Predicting that a disease is absent when it's actually present might be far more costly than the reverse error. In such cases, specialized metrics or cost-sensitive evaluation frameworks provide more appropriate assessments.
Cross-validation provides honest performance estimates but doesn't eliminate the fundamental challenge of limited data. If we have only a small dataset, even carefully cross-validated performance estimates will have high uncertainty. No amount of clever evaluation can substitute for collecting more data when the training set is too small to support the complexity of the model we're trying to build.
Finally, all these techniques assume we've properly prepared our data and chosen appropriate model architectures. No evaluation framework can rescue a model built on the wrong features, with serious data quality issues, or using an architecture fundamentally unsuited to the problem. These tools help us evaluate and compare models, but they don't replace the need for domain knowledge, careful feature engineering, and thoughtful model design.
Summary
Statistical modeling requires careful attention to three interconnected concepts that together determine whether our models will succeed in practice. First, we should quantify model fit using appropriate metrics that capture prediction accuracy in meaningful ways. R-squared provides an intuitive proportional measure of variance explained, while RMSE offers an absolute error metric in the original units of the target variable. These metrics give us concrete numbers to compare models and track improvement, but they should be interpreted carefully in context.
Second, we need to navigate the fundamental tradeoff between underfitting and overfitting by finding the right level of model complexity. Underfit models are too simple to capture real patterns and perform poorly on both training and test data. Overfit models are so complex they memorize noise rather than learning generalizable relationships, achieving excellent training performance but failing on new data. The goal is to find the sweet spot where the model captures true patterns without learning spurious noise, balancing bias against variance.
Finally, cross-validation provides the methodological rigor necessary to honestly evaluate model performance and make sound decisions about model selection and hyperparameters. By systematically rotating through different train-validation splits, cross-validation produces stable performance estimates that are less dependent on any particular division of the data. This approach maximizes the information we extract from limited data while protecting against overfitting to a single test set.
Together, these concepts form the foundation of principled model development. They apply whether we're fitting simple linear regressions or training complex deep learning systems, providing the evaluation framework necessary to build models that deliver reliable predictions on new data. Mastering these fundamentals enables data scientists to move beyond simply fitting models to systematically developing solutions that perform well in production environments.
Quiz
Ready to test your understanding of statistical modeling concepts? Take this quiz to reinforce what you've learned about model fit, bias-variance tradeoff, and cross-validation.

Comments