

Master sinusoidal position encoding, the deterministic method that gives transformers positional awareness. Learn the mathematics behind sine/cosine waves and the elegant relative position property.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Sinusoidal Position Encoding
The transformer's self-attention mechanism is permutation invariant: it produces the same output regardless of token order. To capture sequential structure, we need to inject position information. The original "Attention Is All You Need" paper introduced sinusoidal position encoding, an elegant solution that encodes each position as a unique pattern of sine and cosine waves at different frequencies.
This approach offers several compelling properties. Each position receives a deterministic, unique encoding without any learned parameters. The encoding can represent positions the model has never seen during training. And remarkably, relative positions can be computed through simple linear transformations of absolute positions. Let's understand how this works.
The Position Encoding Formula
Before diving into the mathematics, let's consider what properties we want from a position encoding. We need a function that takes a position index and produces a vector, and this function must satisfy several constraints:
-
Uniqueness: Each position must map to a distinct vector. If positions 5 and 17 produce the same encoding, the model cannot distinguish them.
-
Bounded values: The encoding should not grow unboundedly with position. If position 1000 produces values 1000 times larger than position 1, the position signal would overwhelm the semantic content of the embeddings.
-
Smooth progression: Nearby positions should have similar encodings. Position 50 should be more similar to position 51 than to position 500, giving the model useful gradient information.
-
Deterministic: The same position should always produce the same encoding, without requiring any learned parameters.
Sinusoidal functions satisfy all these requirements elegantly. Sine and cosine oscillate smoothly between -1 and 1, ensuring bounded values. Different frequencies distinguish positions at different scales. And the encoding is purely deterministic, computed from a fixed formula.
Building the Encoding Step by Step
The core idea is to assign each position a unique "fingerprint" using waves of different frequencies. Think of how you might describe your location in a building: you could give the floor number (coarse scale), the room number (medium scale), and your position within the room (fine scale). Together, these scales uniquely identify any location.
For position encoding, we use sine and cosine waves at different frequencies to achieve the same multi-scale identification. Each position in the sequence receives a -dimensional vector, where consecutive pairs of dimensions use sine and cosine at the same frequency:
where:
- : the position index in the sequence (0, 1, 2, ...)
- : the dimension index pair (0, 1, 2, ..., )
- : the total embedding dimension
- : the encoding value at position , even dimension
- : the encoding value at position , odd dimension
- : a base constant that controls the frequency range
Understanding the Frequency Term
The key to the formula is the denominator . This term controls how fast each dimension pair oscillates as position increases. Let's unpack what happens at different dimension indices:
-
When (the first dimension pair): The denominator is , so we compute and . This oscillates rapidly: moving from position 0 to position 6 covers roughly one full cycle.
-
When (the last dimension pair): The denominator is approximately , so we compute and . This oscillates extremely slowly: you need 62,832 positions to complete one full cycle.
The exponent creates a geometric progression of frequencies. As increases from 0 to , the exponent increases from 0 to approximately 1, and the denominator grows from 1 to 10000. This exponential scaling ensures that each dimension pair captures position information at a different resolution.
Why Pair Sine and Cosine?
Each dimension pair uses both sine and cosine at the same frequency. This pairing is not arbitrary; it serves two purposes:
-
Unique identification within a cycle: Sine alone cannot distinguish positions that differ by multiples of . But the (sine, cosine) pair at any frequency uniquely identifies a phase angle. Geometrically, as position increases, the (sin, cos) pair traces a circle in 2D space, and every point on that circle corresponds to a unique position within one cycle.
-
Enabling relative position computation: The sine/cosine pairing allows relative positions to be computed through rotation matrices, a property we'll explore in detail later. This mathematical structure means the model can potentially learn to attend to relative positions using simple linear operations.
A deterministic method for representing token positions using sine and cosine functions at geometrically increasing wavelengths. Each position maps to a unique point in a -dimensional space without requiring any learned parameters.
Wavelength Intuition
Now that we have the formula, let's build deeper intuition for why this multi-frequency approach works so well. The key insight is that different dimensions encode position at different scales, much like how we represent time using multiple units.
Consider a clock with both a second hand and an hour hand. The second hand rotates rapidly, completing one cycle per minute. If you only had the second hand, you could tell the difference between 3:00:15 and 3:00:45, but you couldn't distinguish 3:00:15 from 4:00:15, since both would show the second hand at the same position. The hour hand solves this problem: it moves slowly, completing one cycle every 12 hours, so it can distinguish times that the second hand cannot.
Sinusoidal position encoding applies the same principle. The first dimension pairs oscillate rapidly (like the second hand), distinguishing nearby positions with high precision. The later dimension pairs oscillate slowly (like the hour hand), distinguishing distant positions that the fast oscillators cannot. Together, they create a multi-resolution representation where any two positions, no matter how close or far apart, can be distinguished by at least one dimension pair.
The wavelength formula makes this precise. For dimension pair , the wavelength (the number of positions needed for one complete oscillation cycle) is:
where:
- : the wavelength for dimension pair (measured in positions per cycle)
- : the frequency denominator that grows geometrically with
- : the angular measure of one complete cycle (in radians)
This formula reveals the geometric progression at the heart of sinusoidal encoding:
-
First dimension pair (): Wavelength is positions. Positions 0 through 6 span roughly one full cycle. This fast oscillation distinguishes positions that differ by just 1 or 2.
-
Middle dimension pairs: Wavelengths grow exponentially. By the time we reach the middle dimensions, wavelengths might be in the hundreds, suitable for distinguishing positions that differ by tens or hundreds.
-
Last dimension pair (): Wavelength is approximately positions. You'd need over 10,000 positions to complete one cycle. This slow oscillation can distinguish positions separated by thousands.
The geometric progression is deliberate and essential. If wavelengths grew linearly, nearby dimension pairs would be redundant, both distinguishing roughly the same positional differences. The exponential growth ensures each dimension pair contributes unique positional information at its own characteristic scale, creating a compact representation that efficiently covers all possible position differences.
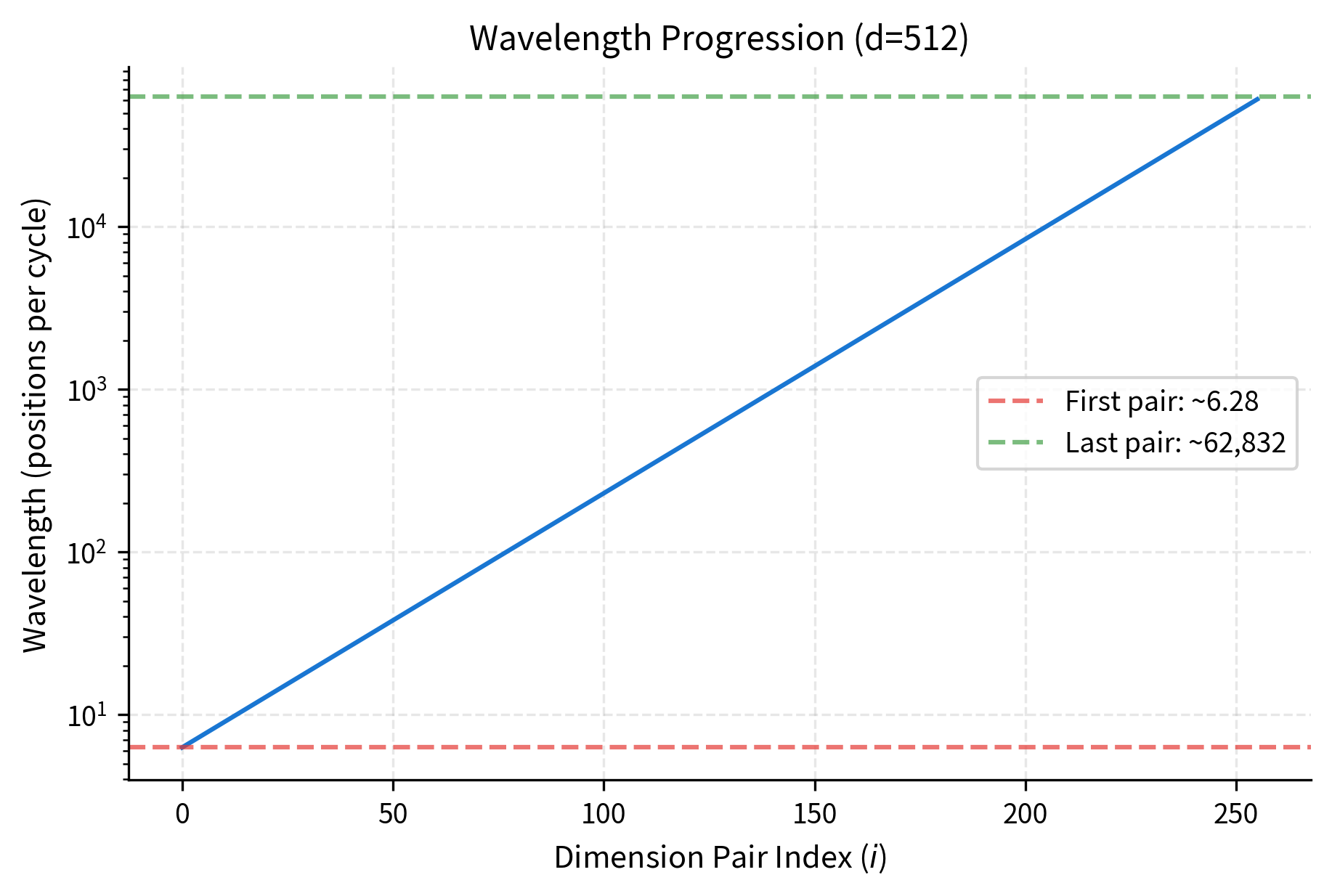
The geometric spacing is deliberate. If wavelengths grew linearly, nearby dimension pairs would be redundant. The exponential growth ensures each dimension pair contributes unique positional information.
Visualizing Position Encodings
With the formula and wavelength intuition in place, let's see what sinusoidal position encodings actually look like. We'll implement the encoding from scratch and visualize the resulting patterns to verify that our intuitions match reality.
Position 0 always has sine values of 0 and cosine values of 1 in the first few dimensions. As position increases, the high-frequency dimensions (small indices) change rapidly while low-frequency dimensions (large indices) change slowly.
Let's visualize the encoding as a heatmap to see the wave patterns:
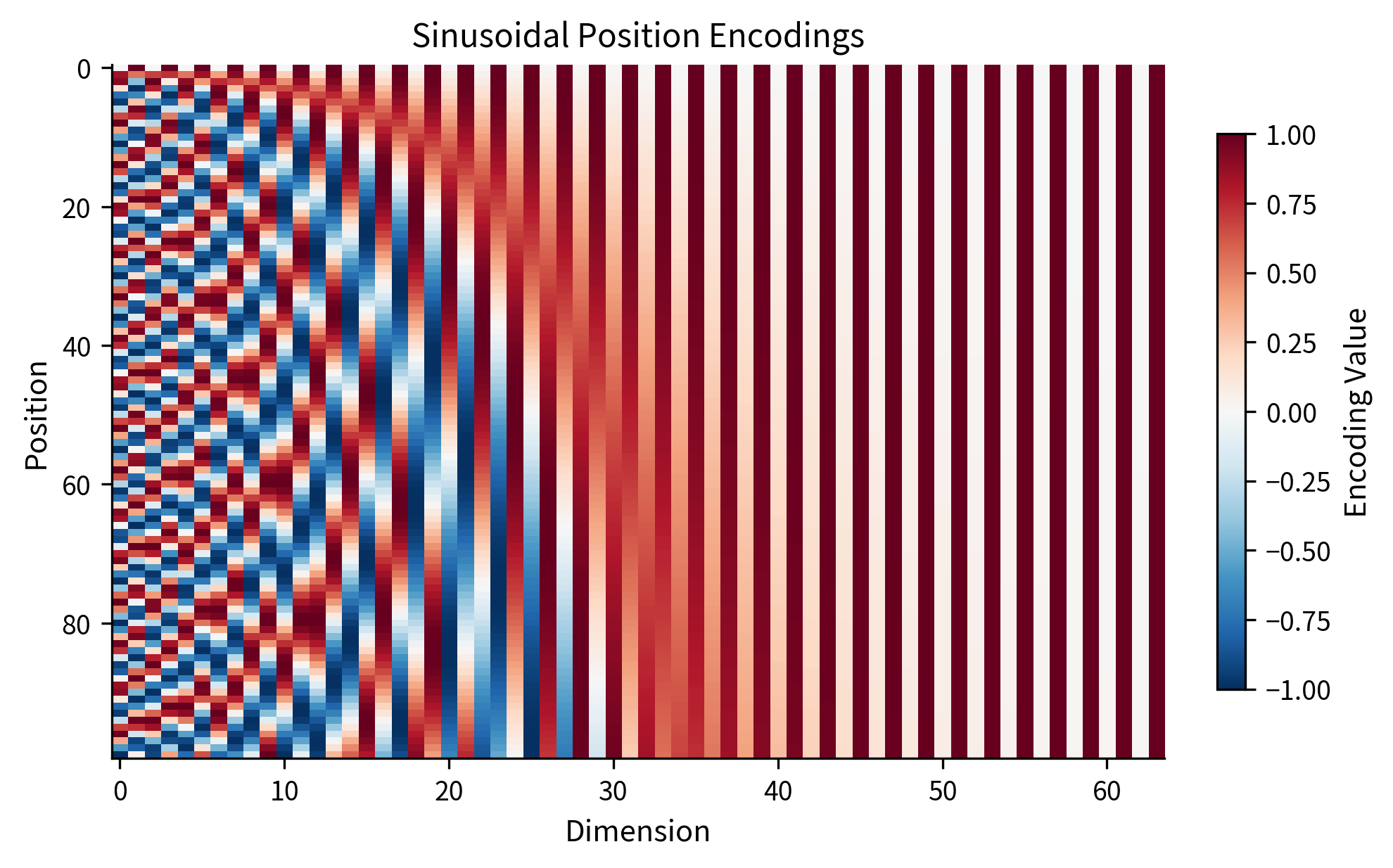
The heatmap reveals the core structure. On the left side (low dimension indices), we see rapid oscillations: positions 0 and 3 might look similar here, but positions 0 and 1 are clearly different. On the right side (high dimension indices), the oscillations are so slow that the entire 100-position range barely covers a fraction of one cycle. The combination ensures every position has a unique encoding.
Let's examine specific dimension pairs to see the sine/cosine relationship:
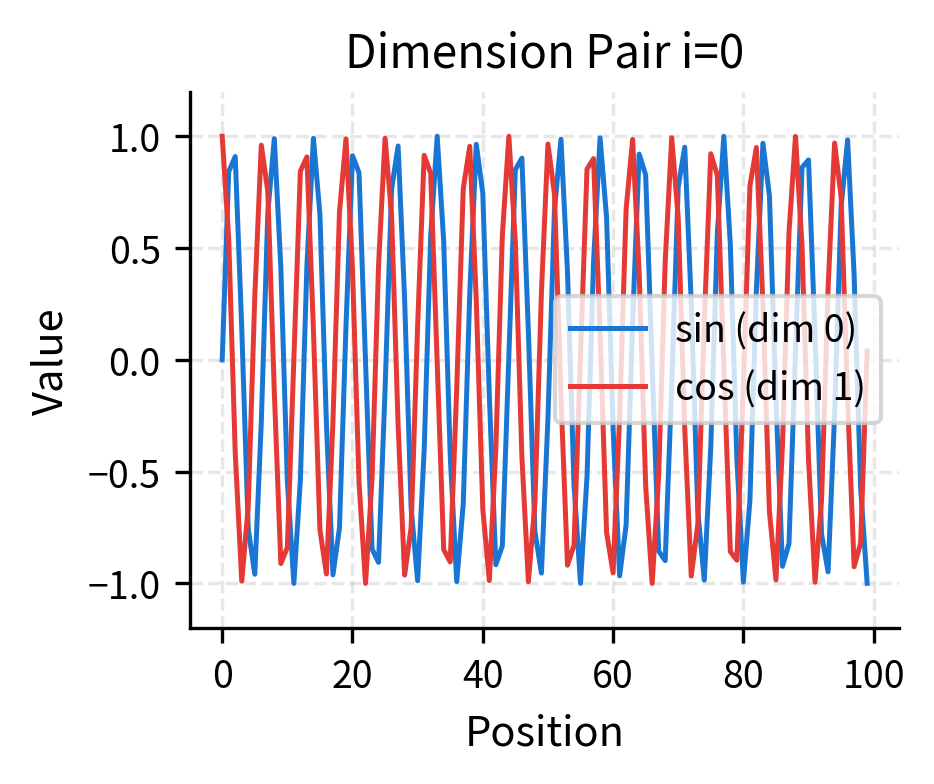
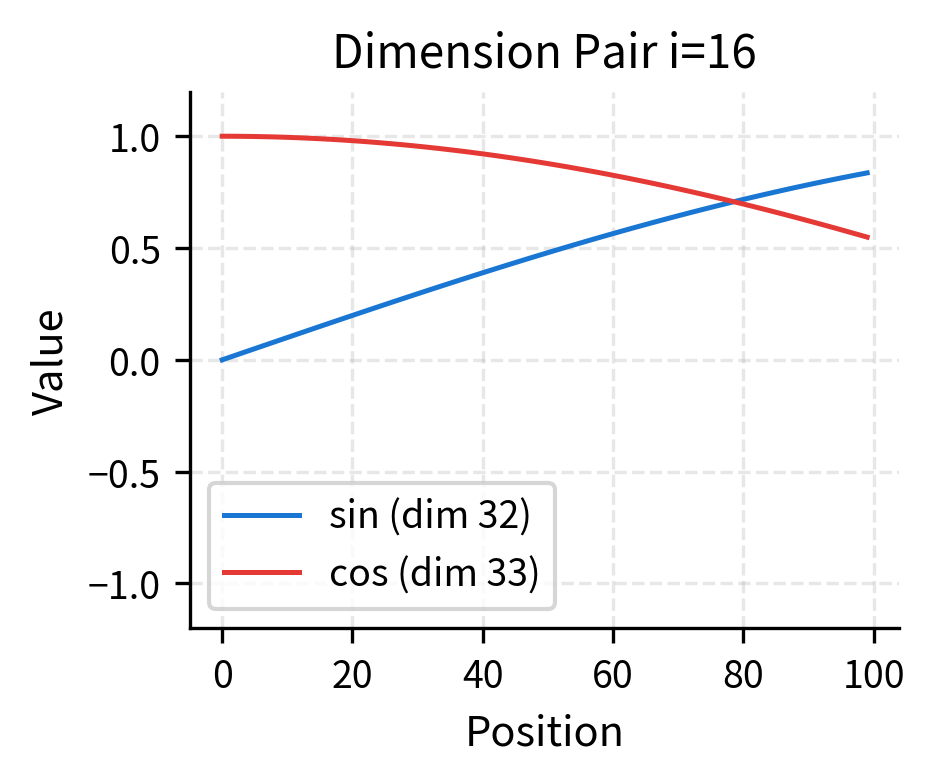
Each dimension pair contributes a (sine, cosine) tuple that traces a circle in 2D space as position increases. The sine and cosine are 90° out of phase, ensuring that every position has a unique combination even within a single dimension pair.
To make this geometric interpretation concrete, let's plot the trajectory of (sin, cos) pairs as position increases:
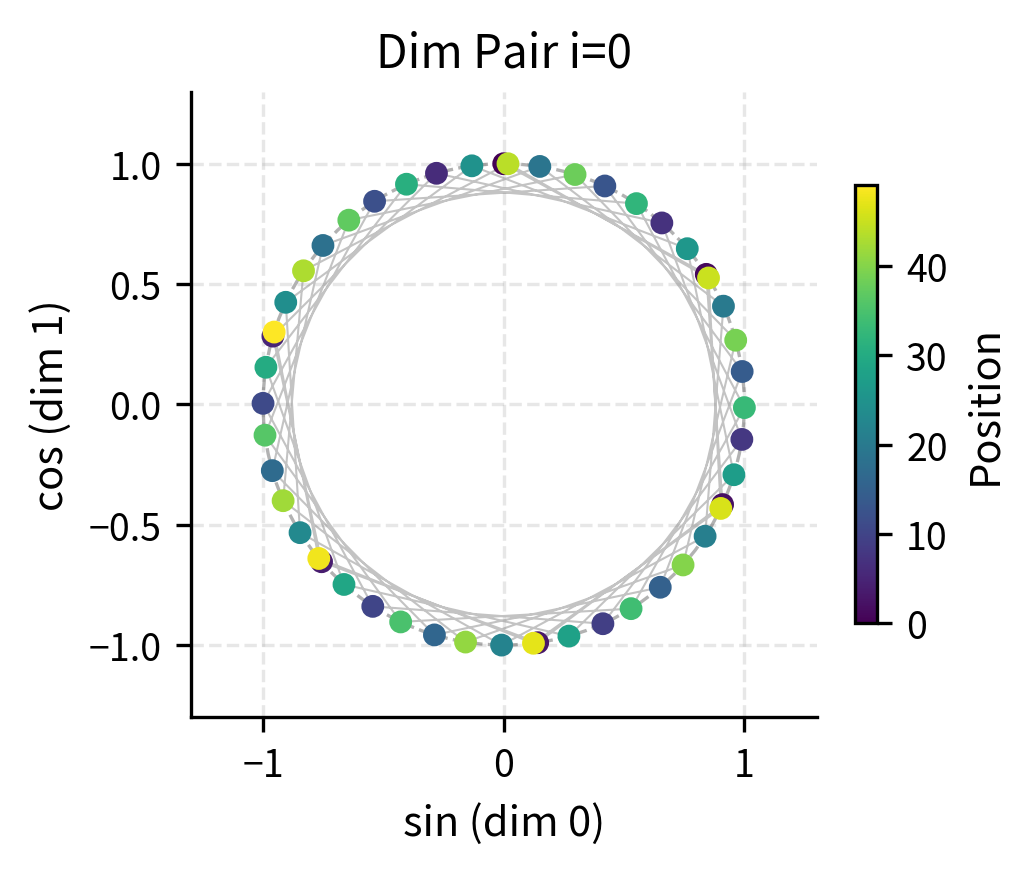
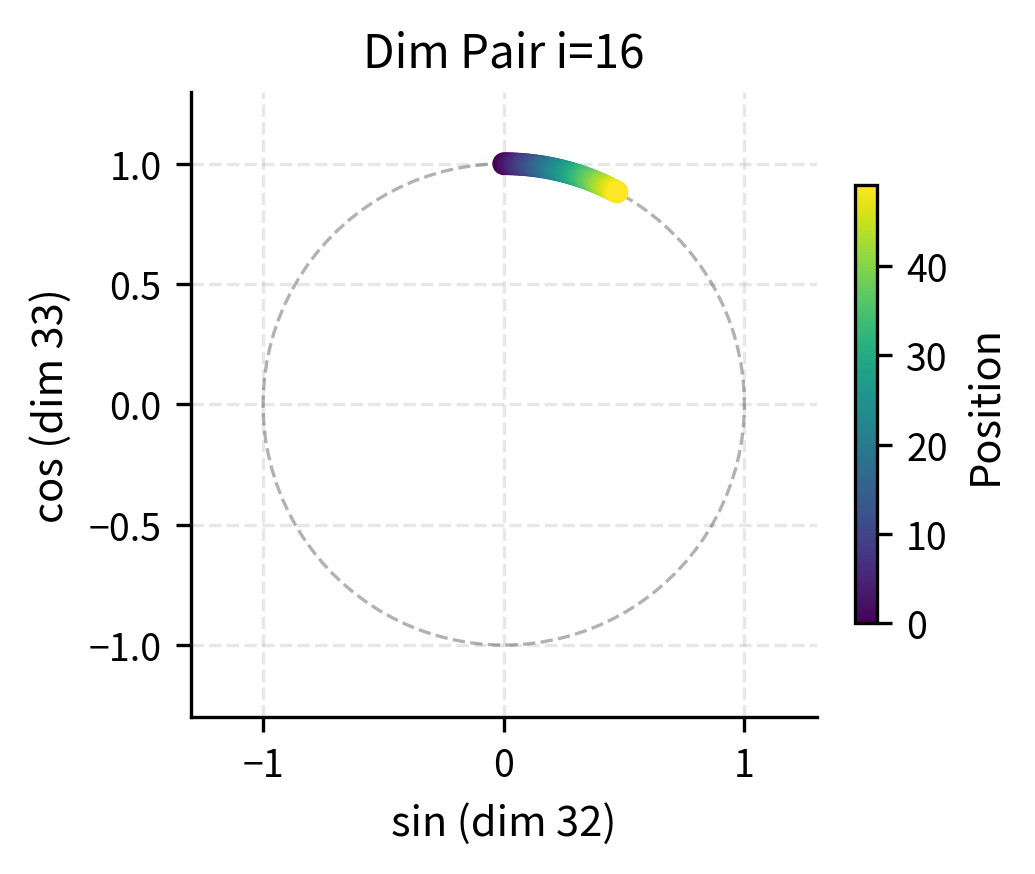
The circular trajectories reveal why sine/cosine pairing works so well. In the first dimension pair (left), the fast oscillation means positions loop around the circle multiple times. Even if two positions land at similar angles on the circle, they'll be distinguished by other dimension pairs with different frequencies. In the middle dimension pair (right), positions are spread across a smaller arc, providing coarse-grained discrimination.
Uniqueness of Position Encodings
Why does this encoding give each position a unique vector? Consider two positions and . For them to have identical encodings, they would need to be indistinguishable across all dimension pairs. But with the geometric progression of wavelengths, this is virtually impossible.
If two positions differ by 1, the first dimension pair (wavelength ~6) will clearly distinguish them. If they differ by 100, middle dimension pairs will distinguish them. If they differ by 10,000, the later dimension pairs will distinguish them. The multi-scale representation captures position differences at any granularity.
Let's verify this by computing distances between position encodings:
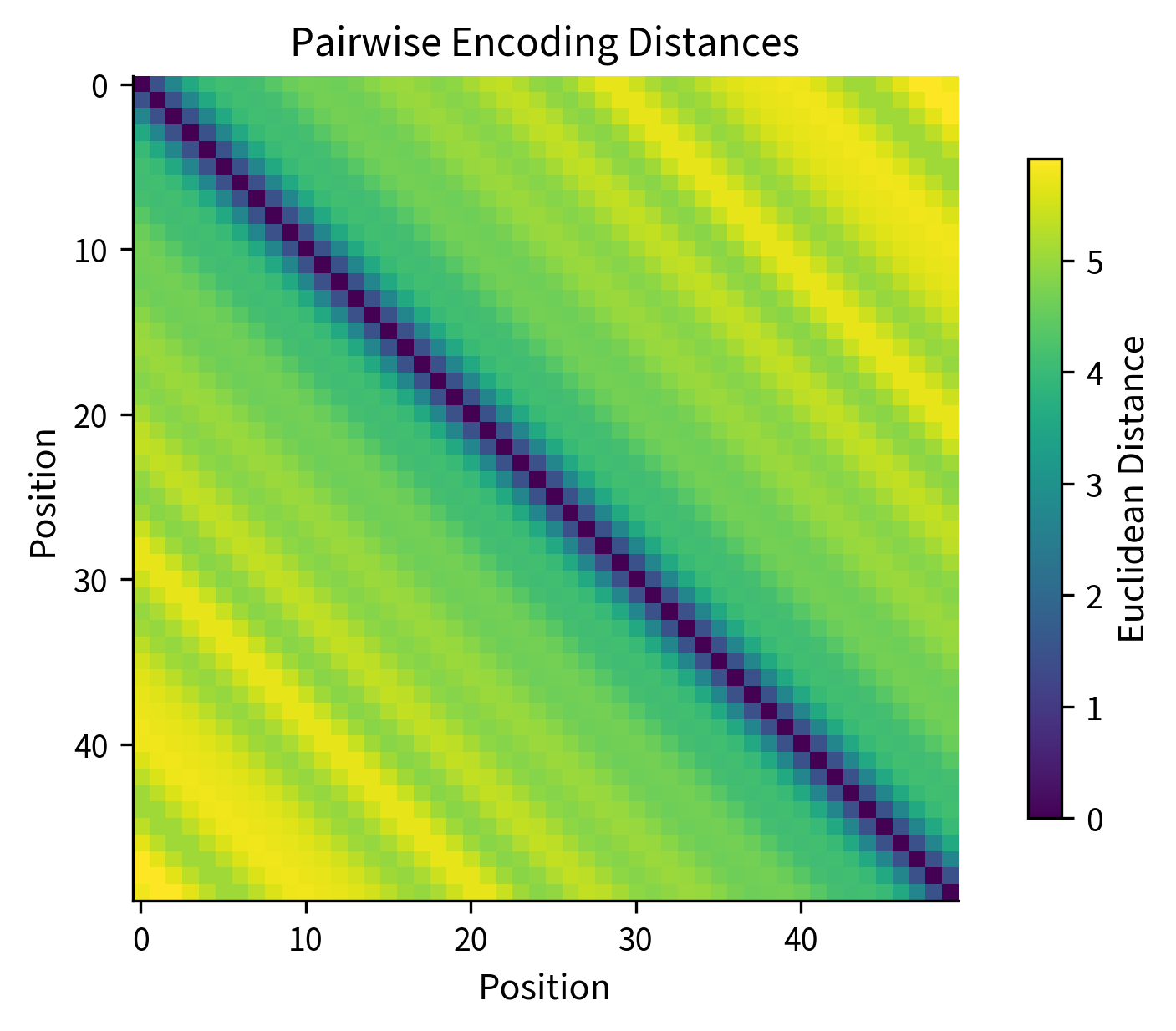
The distance matrix confirms that no two positions have identical encodings (no zeros off the diagonal). The banded structure shows that nearby positions have smaller distances, while distant positions have larger distances. This smooth distance gradient helps the model learn position-dependent patterns.
Let's examine how distance varies with positional separation more precisely:
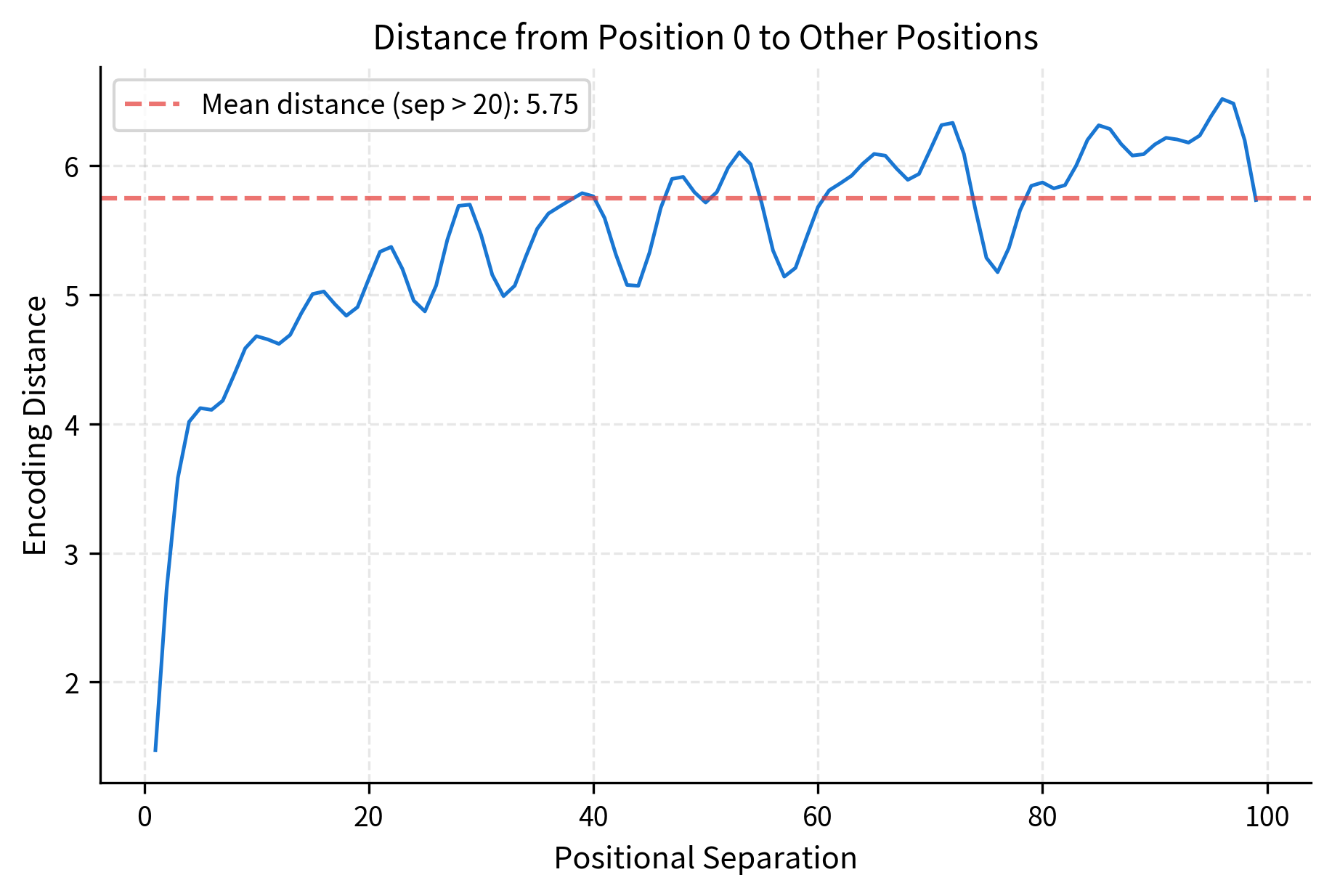
The plot reveals an important property: distance grows quickly for small separations (positions 1-10 are clearly distinguishable from position 0) but then oscillates around a plateau for larger separations. The oscillation comes from the sinusoidal structure: at certain separations, the high-frequency dimensions happen to cycle back to similar values, temporarily reducing the distance. However, the low-frequency dimensions ensure that even these "aliased" positions remain distinguishable.
The Relative Position Property
One of the most elegant properties of sinusoidal encoding is that relative positions can be expressed as linear transformations. For any fixed offset , there exists a matrix such that:
where:
- : the position encoding vector at position (a -dimensional row vector)
- : the position encoding vector at position
- : a transformation matrix that depends only on the offset , not on the absolute position
This means the model can learn to attend to relative positions (e.g., "the word 3 positions back") using simple linear operations.
To understand why this works, we need to derive the relationship step by step using trigonometric identities.
Step 1: Recall the angle addition formulas. For any angles and , trigonometry gives us:
where and are any angles (in radians). These identities let us express the sine or cosine of a sum in terms of the sines and cosines of the individual angles.
Step 2: Define the angular frequency. For dimension pair , we define the angular frequency as:
where:
- : the angular frequency for dimension pair (determines how fast this dimension oscillates)
- : the dimension pair index (0, 1, 2, ..., )
- : the total embedding dimension
- : the denominator that grows geometrically with
This means the encoding at position in dimension pair uses the argument .
Step 3: Apply the addition formulas. To find the encoding at position , we substitute and into the angle addition formulas:
where:
- : the angular frequency for dimension pair
- : the current position in the sequence
- : the position offset we want to shift by
- and : the original encoding values at position (these are and )
- and : constants that depend only on the offset , not on the absolute position
Step 4: Recognize the matrix structure. The key insight is that the right-hand sides of both equations are linear combinations of and . This is exactly what matrix multiplication does! We can write:
This is a rotation in 2D! For each dimension pair, the encoding at is the encoding at rotated by angle . The rotation matrix for offset in dimension pair is:
where:
- : the 2×2 rotation matrix for dimension pair with offset
- : the angular frequency for dimension pair
- : the position offset (how many positions to shift)
- : the rotation angle, which depends on both the offset and the dimension's frequency
Step 5: Construct the full transformation matrix. The full transformation matrix is block-diagonal, with each 2×2 block being the rotation matrix for that dimension pair:
where:
- : the full transformation matrix for offset
- : the 2×2 rotation matrix for dimension pair (defined above)
- : 2×2 zero matrices (indicating no interaction between dimension pairs)
- The matrix has blocks along the diagonal
This block-diagonal structure means relative position shifts act independently on each dimension pair, rotating the (sine, cosine) pair by an amount proportional to the offset. The independence is crucial: each dimension pair encodes position at its own frequency, and shifting by positions rotates each pair by its own characteristic angle .
Let's verify this property numerically:
The errors are at machine precision, confirming that the relative position property holds exactly. This mathematical structure is what allows transformers to potentially learn relative position relationships through their linear attention projections.
Let's visualize this rotation property for a single dimension pair. We'll show how applying the rotation matrix to an encoding at position produces the encoding at position :
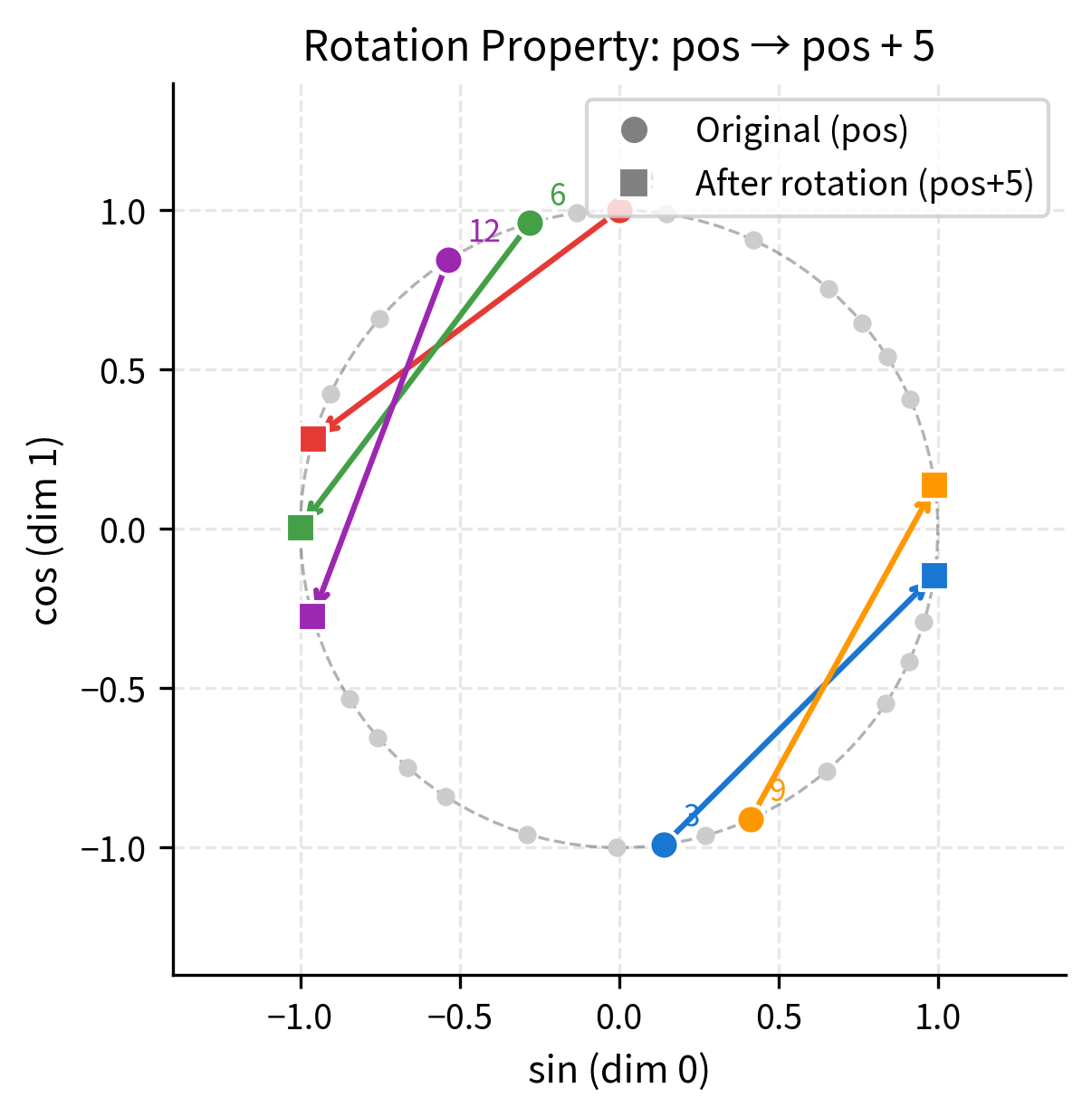
The visualization makes the rotation property tangible. Each colored arrow shows the transformation from position (circle) to position (square). Notice that all arrows rotate by the same angle, confirming that the transformation depends only on the offset , not on the starting position. This is the geometric essence of how sinusoidal encodings enable learning of relative positions.
Extrapolation Beyond Training Length
A significant advantage of sinusoidal encodings is their ability to represent positions never seen during training. Unlike learned position embeddings that require a fixed vocabulary of positions, sinusoidal encodings are computed from a deterministic formula that works for any position.
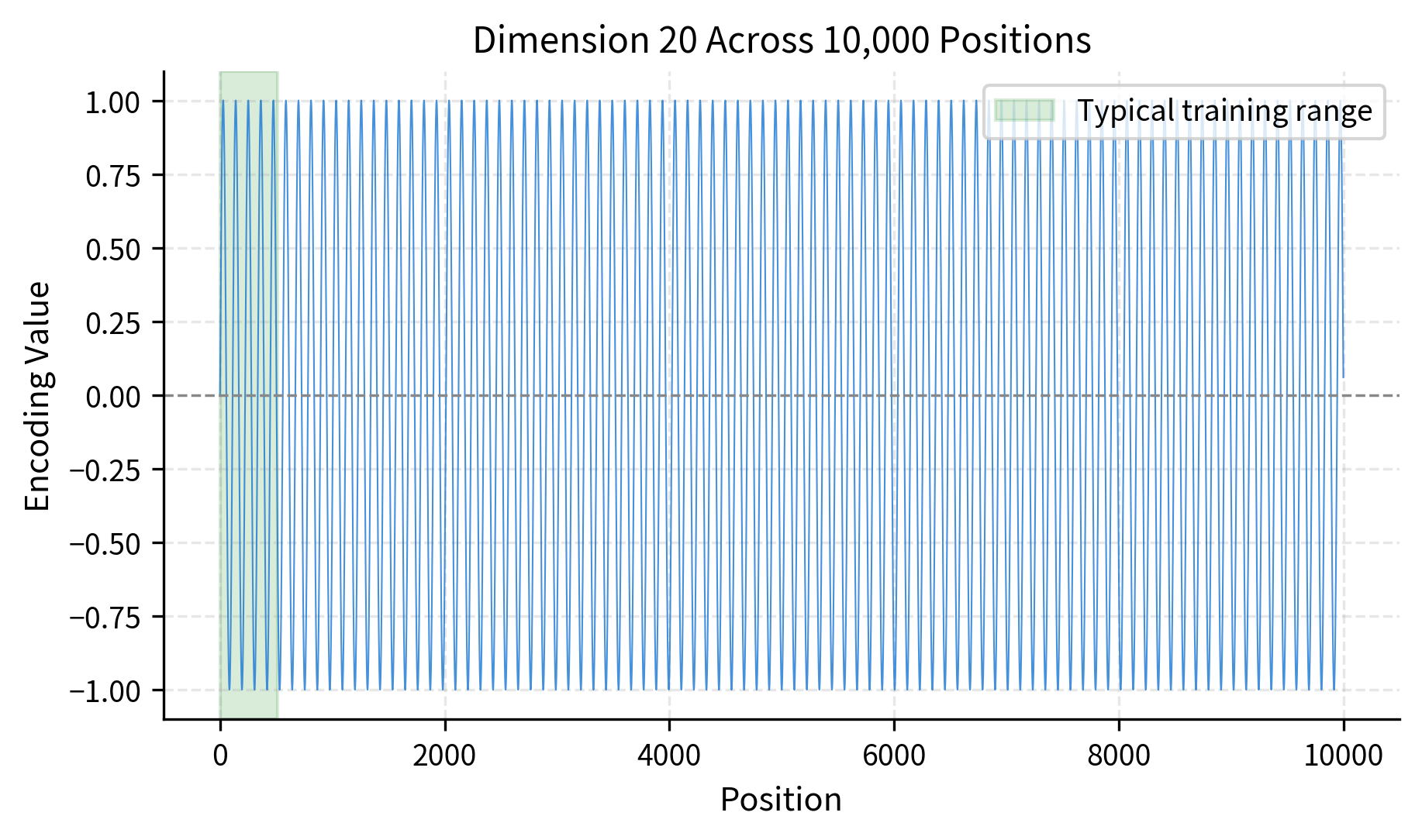
Let's examine how encodings behave beyond typical training lengths:
The encodings remain well-behaved even at position 9,999. Each dimension independently oscillates between -1 and 1, so the encoding never explodes or vanishes. This stability makes sinusoidal encodings suitable for tasks requiring longer contexts than seen during training.
However, extrapolation has a subtle limitation. While the encodings themselves are mathematically valid for any position, the model's attention patterns are learned on sequences of a particular length distribution. If the model trains on sequences of length 512, it has never seen the specific encoding patterns that occur at position 5000. The attention mechanism might not generalize well to these unseen patterns, even though the encodings are perfectly valid.
Complete Implementation
Here's a complete, production-ready implementation of sinusoidal position encoding that handles batched inputs:
Let's test the implementation:
The position encodings have similar magnitude to typical token embeddings (around 5-6 for 64 dimensions), which ensures that position information is meaningful but doesn't overwhelm the semantic content.
Learned vs Sinusoidal: Trade-offs
The choice between sinusoidal and learned position embeddings involves several trade-offs:
Sinusoidal advantages. No parameters to learn means faster training and no risk of overfitting position patterns. The deterministic formula works for any position, enabling extrapolation to longer sequences. The mathematical structure (relative positions as rotations) provides an inductive bias that may help the model learn position-aware patterns.
Sinusoidal disadvantages. The fixed formula may not capture task-specific positional patterns. Some tasks might benefit from non-linear position relationships that sinusoidal encoding cannot express. The extrapolation guarantee is mathematical, not practical: the model still needs to learn how to use positions, and unseen position ranges may not work well.
Learned embedding advantages. Full flexibility to represent arbitrary position patterns. Can learn task-specific positional biases directly from data. Simple to implement: just another embedding table.
Learned embedding disadvantages. Adds parameters proportional to maximum sequence length times embedding dimension. Cannot extrapolate beyond the trained position vocabulary. May overfit to position patterns in the training data.
The parameter savings are significant for long sequences. At 4096 positions with 768 dimensions, learned embeddings require over 3 million parameters just for position. Sinusoidal encoding requires none.
Interestingly, the original transformer paper found that both approaches performed similarly on machine translation. Modern practice varies: BERT uses learned embeddings, GPT-2 uses learned embeddings, but many newer architectures explore alternatives like relative position encodings (covered in later chapters) that build on the insights from sinusoidal design.
Limitations and Impact
Sinusoidal position encoding introduced key concepts that influence modern position encoding research. The insight that positions should be represented as continuous signals rather than discrete indices opened the door to smoother, more generalizable position representations. The relative position property, where positional offsets correspond to linear transformations, directly inspired later developments like Rotary Position Embedding (RoPE).
The primary limitation is the disconnect between the encoding's mathematical properties and the model's learned behavior. While sinusoidal encodings can represent arbitrary positions, the transformer must still learn to use this information. If training data only contains sequences up to length 512, the model's attention patterns are calibrated for that range. Extrapolating to length 2048 provides valid encodings but potentially invalid learned behavior.
Another limitation is the absolute nature of the encoding. Each position has a fixed representation regardless of context. The word at position 50 has the same positional encoding whether it's in a 100-token sequence or a 1000-token sequence. This can make it harder for the model to learn purely relative patterns like "attend to the previous word" without reference to absolute position.
Despite these limitations, sinusoidal encoding established foundational principles. The use of multiple frequencies to capture position at different scales, the sine/cosine pairing for unique identification, and the geometric wavelength progression all appear in various forms in modern position encoding schemes.
Key Parameters
When implementing sinusoidal position encoding, the following parameters control the encoding behavior:
-
d_model: The dimension of the position encoding vectors, which must match the token embedding dimension. Larger values provide finer-grained positional discrimination but increase computation. Common values range from 256 to 1024. -
max_len: The maximum sequence length to pre-compute encodings for. Setting this higher than your longest expected sequence avoids runtime recomputation, but increases memory usage. Typical values range from 512 to 8192 depending on the task. -
Base constant (10000): The frequency scaling constant in the denominator. This value controls the range of wavelengths from to . The original transformer paper uses 10000, but some implementations experiment with different values to adjust the frequency distribution.
Summary
Sinusoidal position encoding provides a parameter-free method for injecting positional information into transformer models. By encoding each position as a unique pattern of sine and cosine values at geometrically spaced frequencies, it creates distinguishable representations for any sequence position.
Key takeaways from this chapter:
-
Multi-scale representation: Different dimension pairs capture position at different resolutions. High-frequency pairs distinguish nearby positions, low-frequency pairs distinguish distant positions.
-
Mathematical structure: The sine/cosine pairing enables relative positions to be computed as rotations. For any fixed offset , the encoding at position is a linear transformation of the encoding at position .
-
No learned parameters: The encoding is computed from a deterministic formula, eliminating position-related parameters and enabling representation of any position.
-
Bounded values: All encoding values lie in , ensuring numerical stability regardless of position.
-
Extrapolation caveat: While encodings are valid for any position, the model's learned attention patterns may not generalize to positions unseen during training.
-
Trade-offs with learned embeddings: Sinusoidal encoding saves parameters and enables extrapolation but lacks flexibility to learn task-specific position patterns.
In the next chapter, we'll explore learned position embeddings in detail: how they're implemented, when they outperform sinusoidal encodings, and the design considerations that affect their performance.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about sinusoidal position encoding.

Comments