

Explore GPT-2's architecture, model sizes, WebText training, and zero-shot capabilities that transformed language modeling through scale.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
GPT-2
In February 2019, OpenAI announced GPT-2 with an unusual strategy: they would not release the full model. The 1.5 billion parameter language model was, they claimed, too dangerous. It could generate text so convincingly human-like that they feared widespread misuse for fake news, spam, and impersonation. The decision sparked fierce debate about responsible AI release, but it also underscored a more fundamental shift. GPT-2 demonstrated that scale, applied to a simple autoregressive language modeling objective, could produce emergent capabilities that no one had explicitly trained for.
This chapter examines GPT-2's contributions to language modeling. We'll explore how OpenAI scaled up from GPT-1's 117 million parameters across four model sizes, understand the architectural refinements that enabled stable training at scale, analyze the WebText dataset that taught the model from high-quality internet text, and investigate the zero-shot learning phenomenon that made GPT-2 far more than just a text generator. By the end, you'll understand why GPT-2 marked the transition from fine-tuned specialists to general-purpose language models.
Model Sizes: A Family of Models
GPT-2 wasn't a single model but a family of four. OpenAI trained models ranging from 117 million to 1.5 billion parameters, enabling systematic study of how capabilities scale with size. This approach would become standard practice for subsequent large language models.
GPT-2 Small matches GPT-1's size at 117M parameters with 12 layers. GPT-2 Medium doubles this to 345M parameters with 24 layers. GPT-2 Large reaches 762M with 36 layers. GPT-2 XL, the full model, contains 1.5B parameters across 48 layers.
The architectural specifications for each variant are:
| Parameter | GPT-2 Small | GPT-2 Medium | GPT-2 Large | GPT-2 XL |
|---|---|---|---|---|
| Layers () | 12 | 24 | 36 | 48 |
| Hidden size () | 768 | 1024 | 1280 | 1600 |
| Attention heads () | 12 | 16 | 20 | 25 |
| Head dimension () | 64 | 64 | 64 | 64 |
| Feed-forward size | 3072 | 4096 | 5120 | 6400 |
| Vocabulary size | 50,257 | 50,257 | 50,257 | 50,257 |
| Context length | 1024 | 1024 | 1024 | 1024 |
| Parameters | ~117M | ~345M | ~762M | ~1.5B |
The key architectural parameters are:
- : number of transformer layers (blocks stacked sequentially)
- : hidden dimension, the size of token representations flowing through the network
- : number of attention heads operating in parallel within each layer
- : dimension per attention head, determining how much information each head can capture
The head dimension stays fixed at 64 across all variants, following a pattern that would persist through GPT-3 and beyond. Scaling happens through more attention heads and more layers, not larger heads. The 4x feed-forward expansion ratio (hidden size 4 = feed-forward size) also remains constant. Context length doubled from GPT-1's 512 to 1024 tokens, allowing the model to condition on longer passages.
Let's compute the parameter distribution to understand where model capacity resides:
The parameter breakdown reveals where model capacity resides. For GPT-2 Small, embeddings constitute about 31% of parameters, but this fraction shrinks dramatically as models scale. GPT-2 XL dedicates over 90% of its parameters to transformer layers, meaning the vast majority of learned knowledge resides in attention and feed-forward weights rather than the vocabulary embeddings.
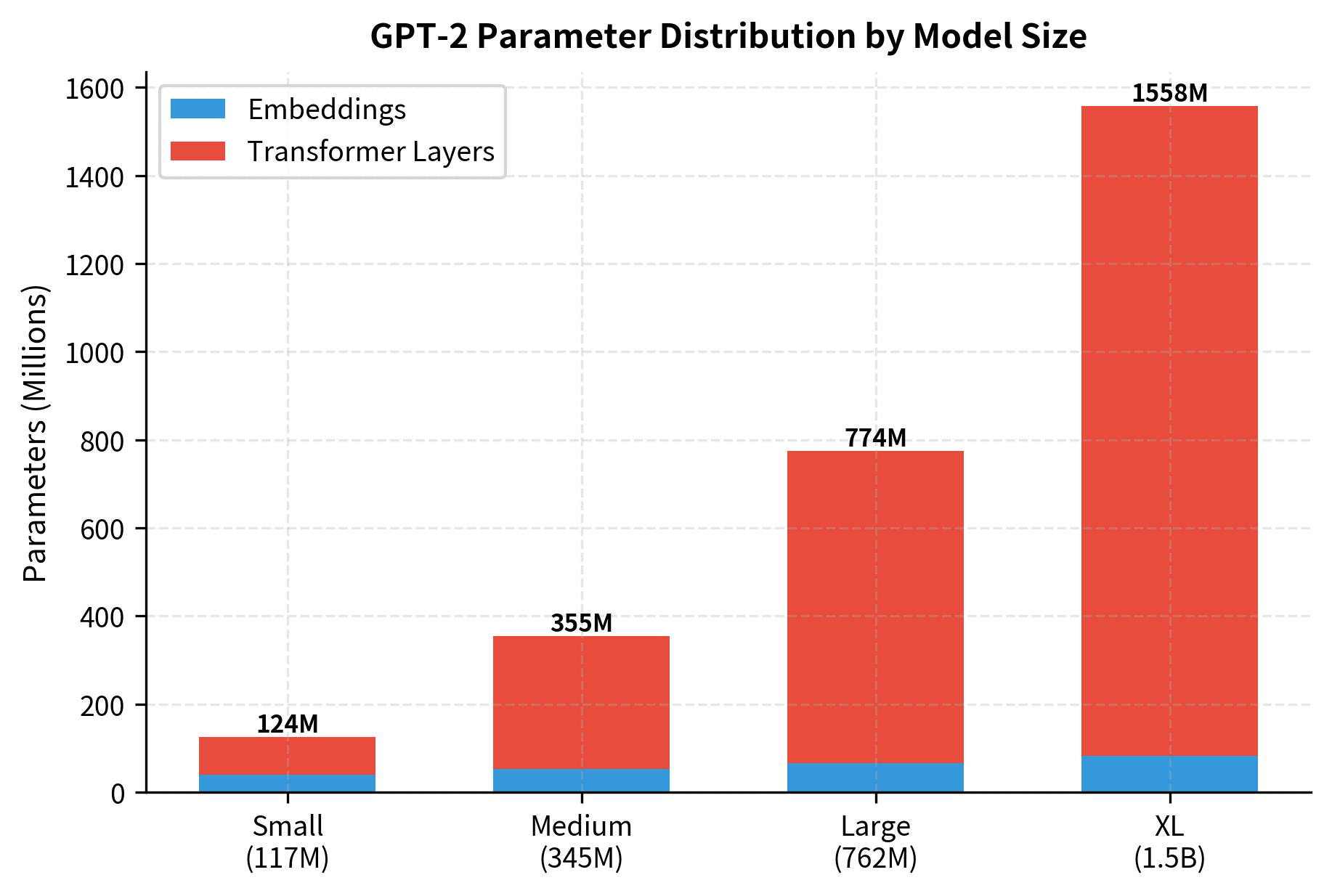
The embedding layer represents a decreasing fraction of total parameters as models grow. In GPT-2 Small, embeddings account for roughly 31% of parameters, but in GPT-2 XL this drops to about 6%. This pattern reflects a fundamental principle: vocabulary embeddings scale with vocabulary size, while transformer layers scale quadratically with hidden dimension and linearly with depth. For large models, knowledge increasingly resides in the transformer layers themselves.
Architectural Changes from GPT-1
GPT-2 maintained the decoder-only transformer architecture from GPT-1 but introduced several modifications that proved crucial for stable training at larger scales. These changes became standard practice for subsequent language models.
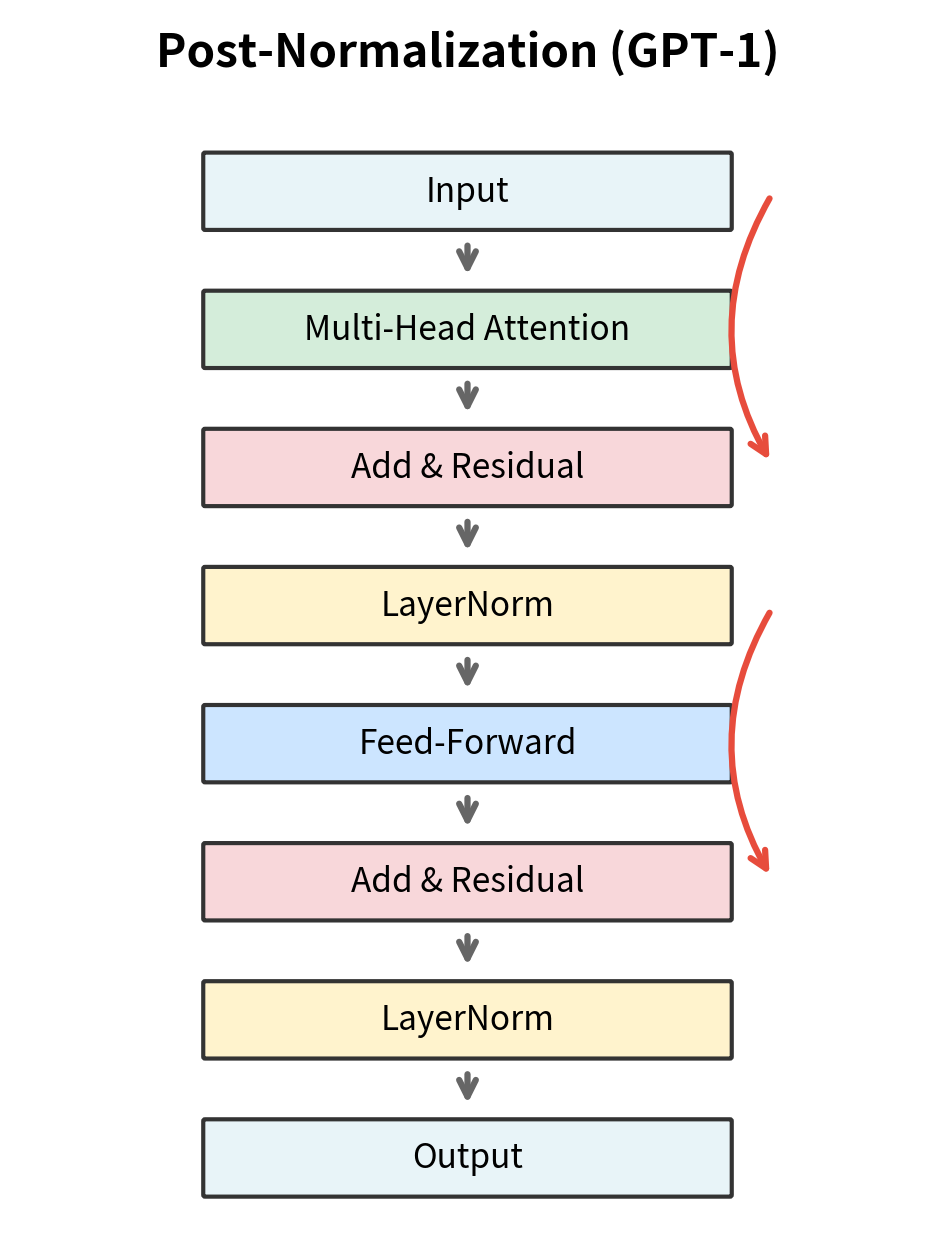
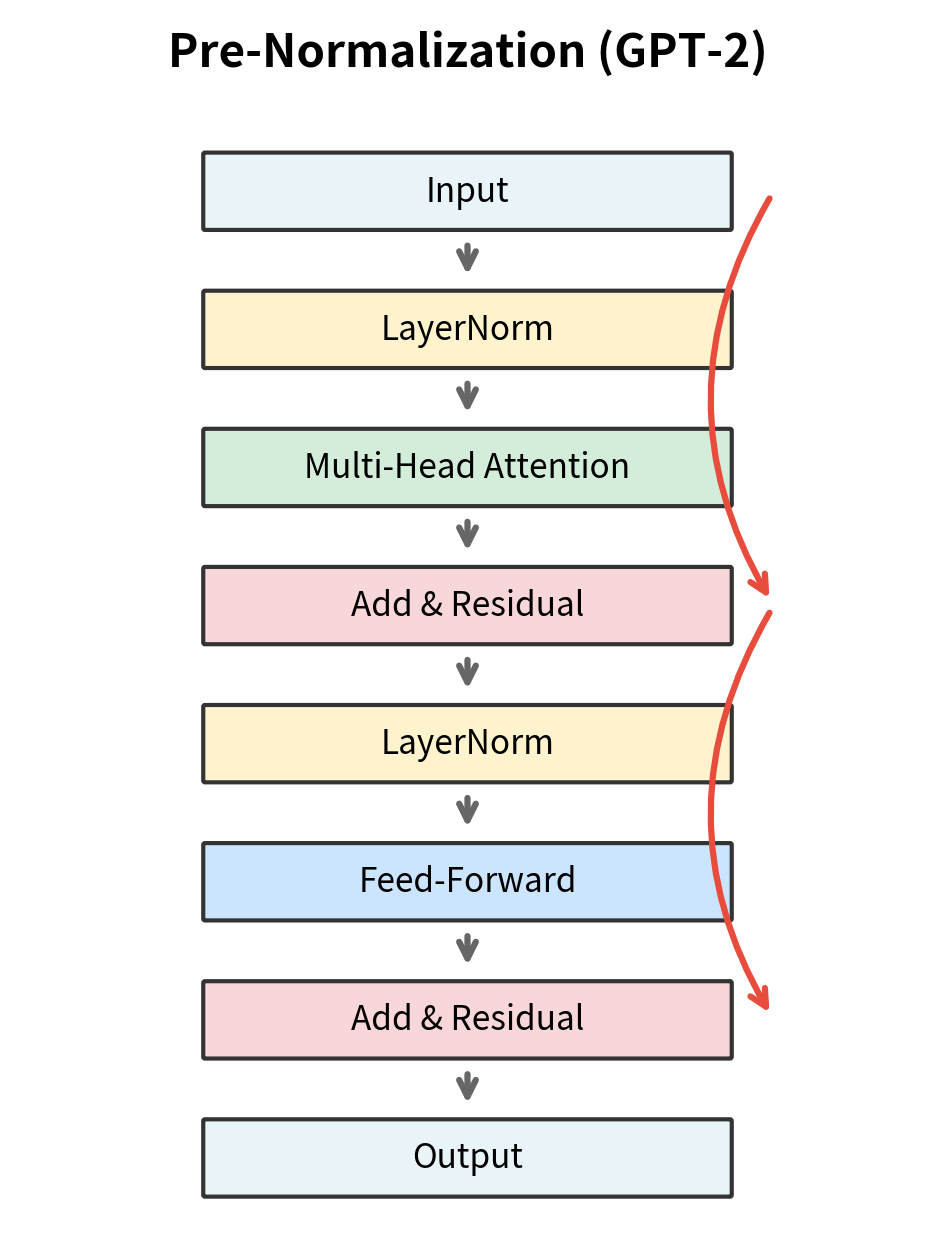
Pre-Normalization
The most significant architectural change was moving layer normalization before each sub-block rather than after. GPT-1 and the original transformer used post-normalization, applying LayerNorm after the residual connection. GPT-2 switched to pre-normalization, applying LayerNorm before the attention and feed-forward operations.
The causal mask is crucial for autoregressive generation. It ensures each position can only attend to previous positions (and itself), preventing information leakage from future tokens. Let's visualize what this mask looks like:
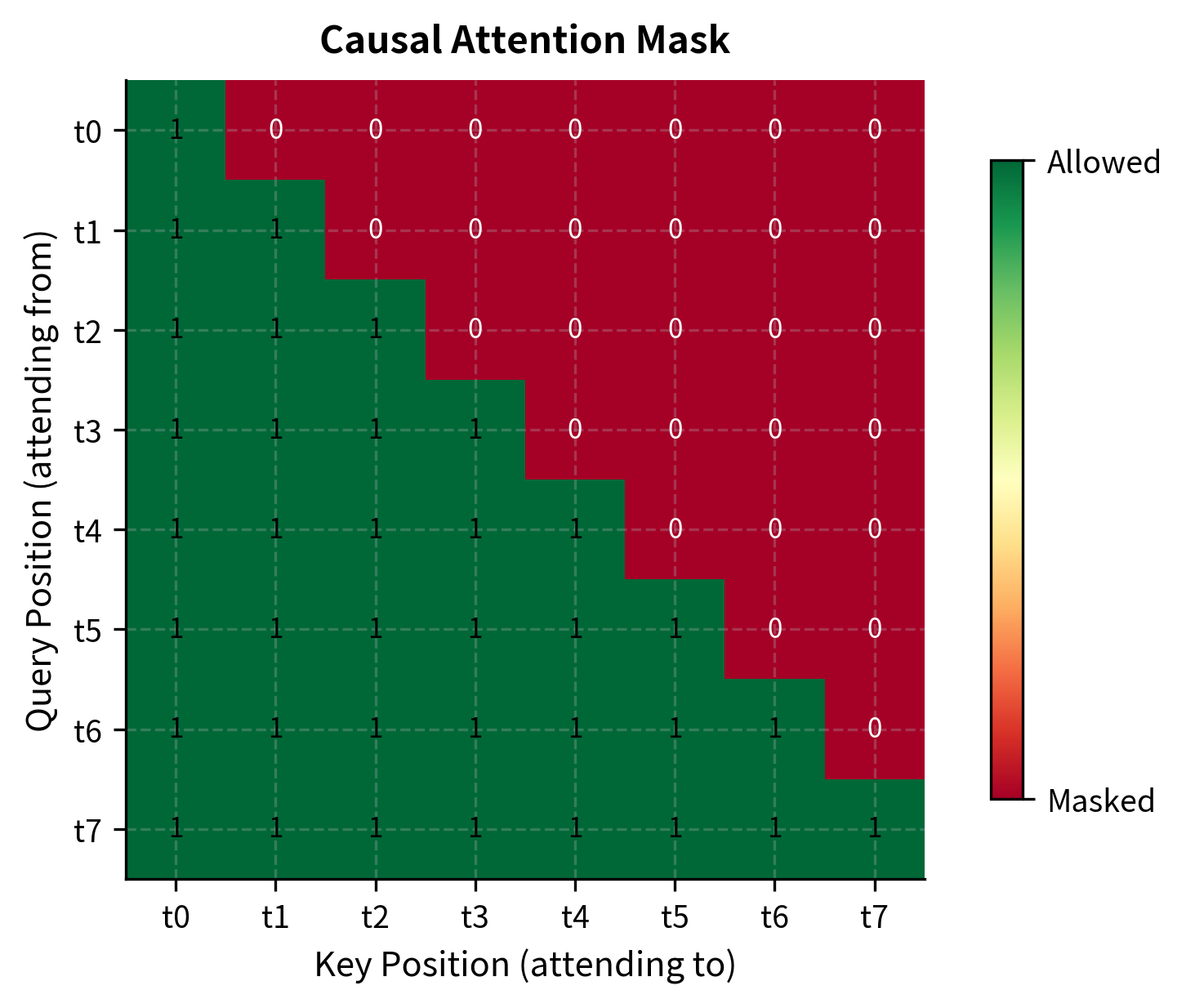
The lower triangular pattern means token can only attend to tokens . This is what makes GPT-2 autoregressive: when predicting the next token, the model cannot "peek" at future tokens. During training, this enables efficient parallel computation since the entire sequence can be processed in one forward pass with masking.
Why does this matter? Pre-normalization provides more stable gradients during training. In post-normalization, the residual branch adds unnormalized activations, which can have high variance. The subsequent LayerNorm must handle this variance, but gradients flowing back through the normalization can become unstable at scale. With pre-normalization, the residual connection adds already-normalized values, keeping the residual stream's magnitude more controlled.
GELU Activation
GPT-2 replaced the ReLU activation function with GELU (Gaussian Error Linear Unit). While ReLU simply zeros out negative values, GELU applies a smooth, non-monotonic transformation that weights inputs by their probability under a Gaussian distribution.
The GELU function multiplies each input by its probability of being greater than other inputs from a Gaussian distribution. This creates a smooth gating mechanism where positive values pass through almost unchanged, while negative values are attenuated based on how negative they are.
The exact formulation is:
where:
- : the input value to the activation function
- : the cumulative distribution function (CDF) of the standard normal distribution, representing the probability that a random variable is less than or equal to
- : the error function, a special function that arises in probability and statistics
The intuition is elegant: we multiply each input by the probability that exceeds values drawn from a Gaussian. Large positive values have , so they pass through unchanged. Large negative values have , so they're zeroed out. Values near zero get partially attenuated.
In practice, computing the error function is expensive. GPT-2 and most implementations use this polynomial approximation:
where is the hyperbolic tangent function and the constants and were chosen to minimize approximation error. This formulation is differentiable everywhere and computationally efficient.
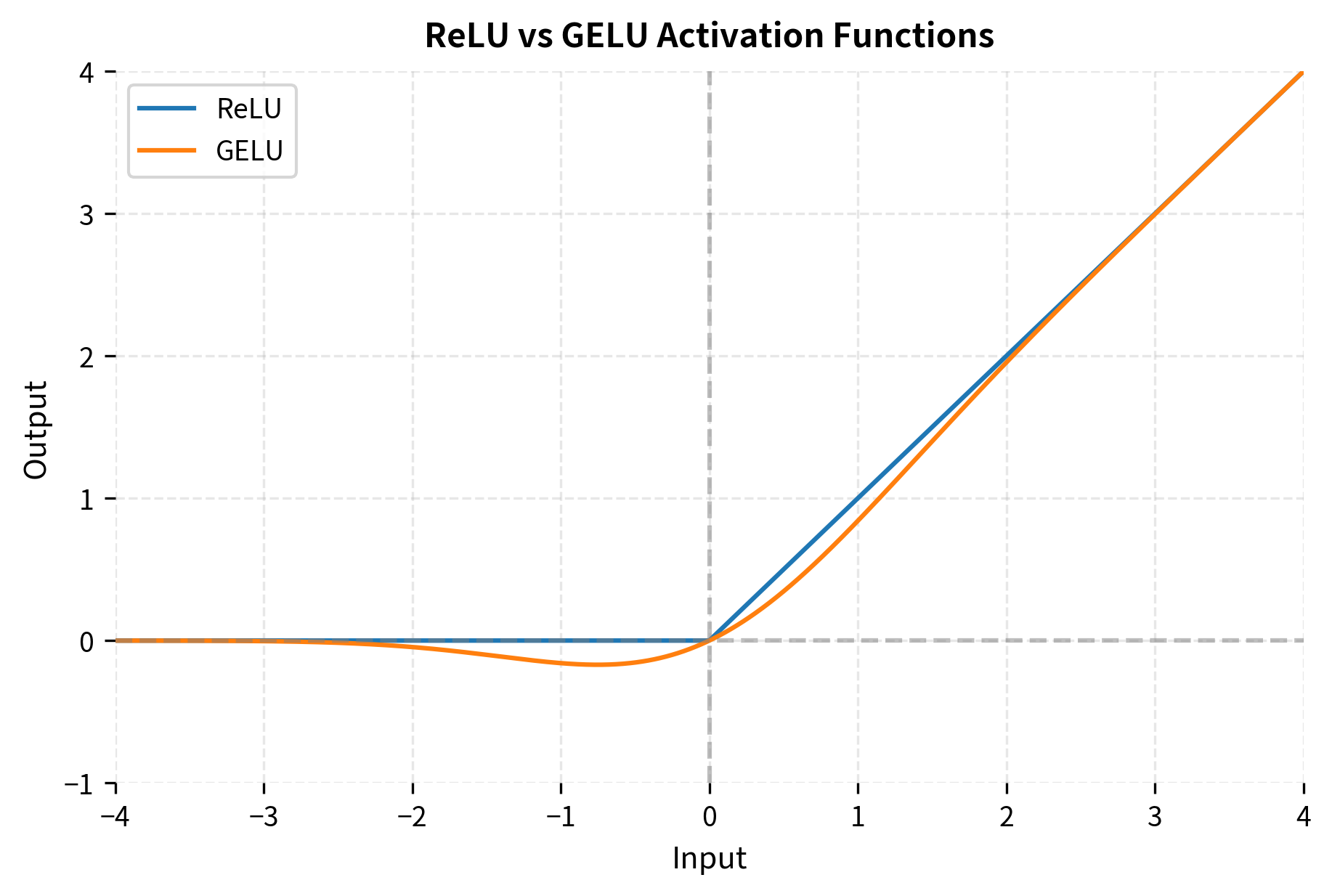
GELU's smoothness provides better gradient flow compared to ReLU's hard cutoff. To understand why this matters for training, let's compare the derivatives:
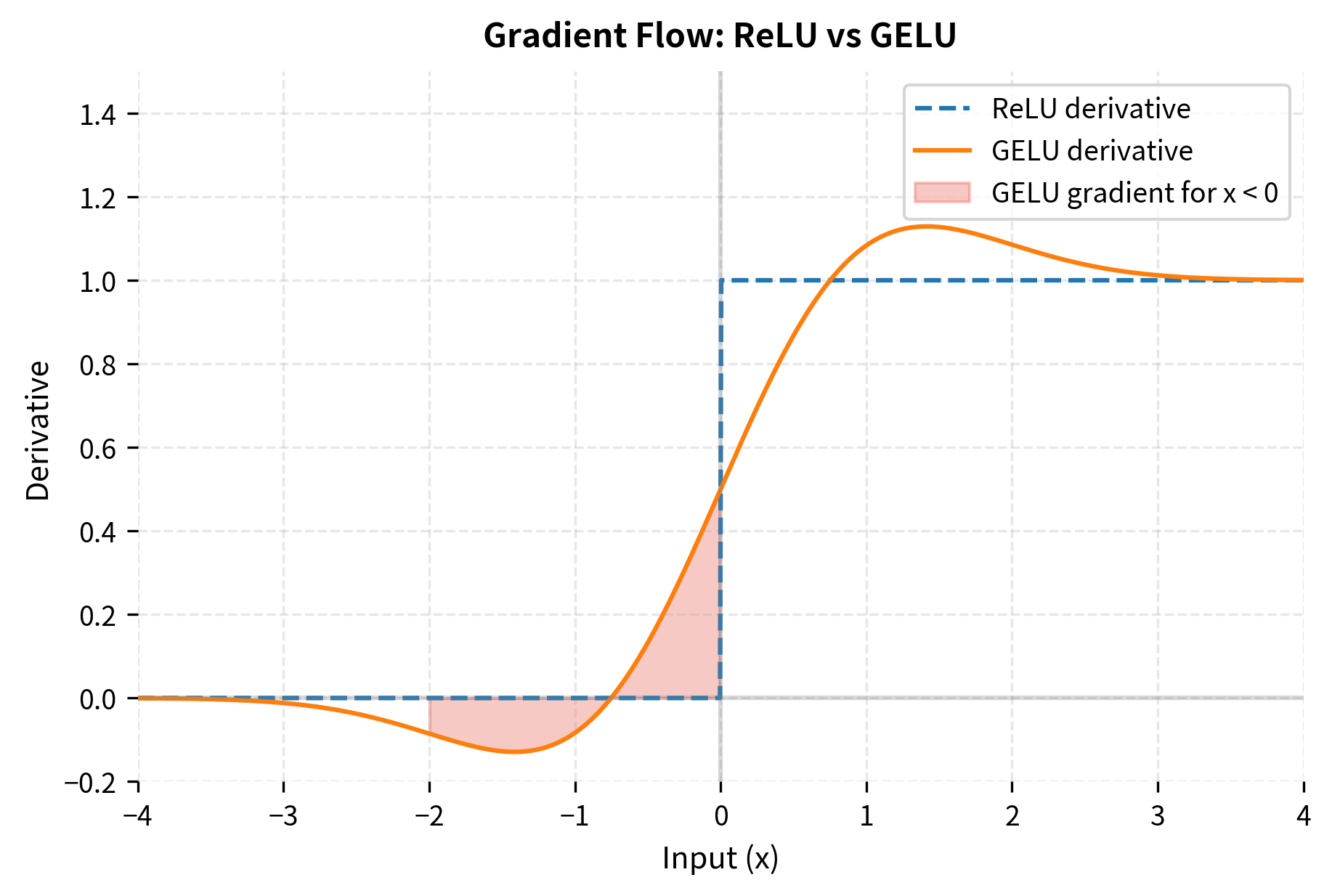
The shaded region shows where GELU outperforms ReLU: for slightly negative inputs, ReLU has zero gradient (the "dying ReLU" problem), while GELU allows some gradient to flow. This small difference compounds across billions of training steps and millions of neurons, potentially making the difference between successful and failed optimization at large scales.
Other Modifications
Several additional changes improved GPT-2's training stability:
-
Increased vocabulary size: GPT-2 uses a vocabulary of 50,257 tokens (versus GPT-1's ~40,000), built using byte-level Byte Pair Encoding. This allows the model to represent any text without unknown tokens.
-
Extended context length: The context window doubled from 512 to 1024 tokens, enabling the model to condition on longer passages.
-
Modified initialization: Weights in residual layers were scaled by , where is the number of residual layers (each transformer block has 2 residual connections, so for a 12-layer model, ). Without this scaling, each residual addition increases the variance of activations. After additions, variance would grow proportionally to . Scaling by keeps the variance of the residual stream approximately constant regardless of depth.
-
Final layer normalization: An additional LayerNorm is applied after the last transformer block, before the output projection.
Let's implement a minimal GPT-2 model to see these components together:
Our implementation produces parameter counts closely matching the official GPT-2 specifications. Small discrepancies arise from minor implementation details like bias terms and layer norm parameters, but the overall scaling matches: roughly 3x increase from Small to Medium, 2.2x from Medium to Large, and 2x from Large to XL. Weight tying between the input embeddings and output projection reduces parameter count while maintaining performance, a technique that became standard in language models.
WebText: Learning from the Internet
GPT-2's training data represented a significant departure from previous approaches. Rather than using carefully curated datasets like BooksCorpus (used for GPT-1) or Wikipedia, OpenAI created WebText by scraping outbound links from Reddit posts with at least 3 upvotes.
WebText contains approximately 40 GB of text from 8 million web pages. The filtering heuristic of requiring Reddit upvotes served as a proxy for content quality, as humans had implicitly judged these links worth sharing.
The WebText construction process involved several key decisions:
-
Source selection: Links from Reddit with karma (upvotes minus downvotes) were collected. This crowdsourced filtering biased toward content that humans found interesting, informative, or entertaining.
-
Deduplication: Near-duplicate documents were removed to prevent the model from memorizing repeated content.
-
Minimal preprocessing: Unlike many previous datasets, WebText preserved formatting, punctuation, and case. The model learned from text as it appears naturally on the web.
-
Exclusion of Wikipedia: Wikipedia was deliberately excluded to enable fair evaluation on Wikipedia-based benchmarks.
This data collection strategy reflected a key insight: the internet contains enormous diversity of text genres, styles, and topics. By learning from this diversity, GPT-2 could potentially generalize to many tasks without task-specific training.
The WebText approach had important implications. First, it scaled easily since the internet provides virtually unlimited text. Second, the diversity exposed the model to many natural "tasks" embedded in web text: answering questions, summarizing articles, translating between languages, and explaining concepts. Third, it introduced biases present in Reddit's user base and the content they share.
Zero-Shot Task Performance
GPT-2's most surprising contribution was demonstrating zero-shot task performance. Without any task-specific fine-tuning, GPT-2 could perform reading comprehension, summarization, translation, and question answering simply by framing these tasks as language modeling.
The Zero-Shot Paradigm
The key insight was that many NLP tasks can be expressed as conditional text generation. Rather than training separate models for each task, you can prompt a language model with a description of the task:
- Question answering: "Q: What is the capital of France? A:"
- Summarization: "Article: [article text] TL;DR:"
- Translation: "English: Hello, how are you? French:"
The language model, having seen similar patterns in its training data, learns to complete these prompts appropriately.
Each prompt demonstrates a different task expressed as conditional text generation. The reading comprehension prompt provides context then asks a question. The summarization prompt uses "TL;DR:" as a signal the model learned from internet forums. The translation prompt establishes a pattern the model should continue. These formats work because WebText contained millions of similar patterns.
Benchmark Results
OpenAI evaluated GPT-2 on various benchmarks in zero-shot mode, comparing against supervised baselines that were explicitly trained for each task.
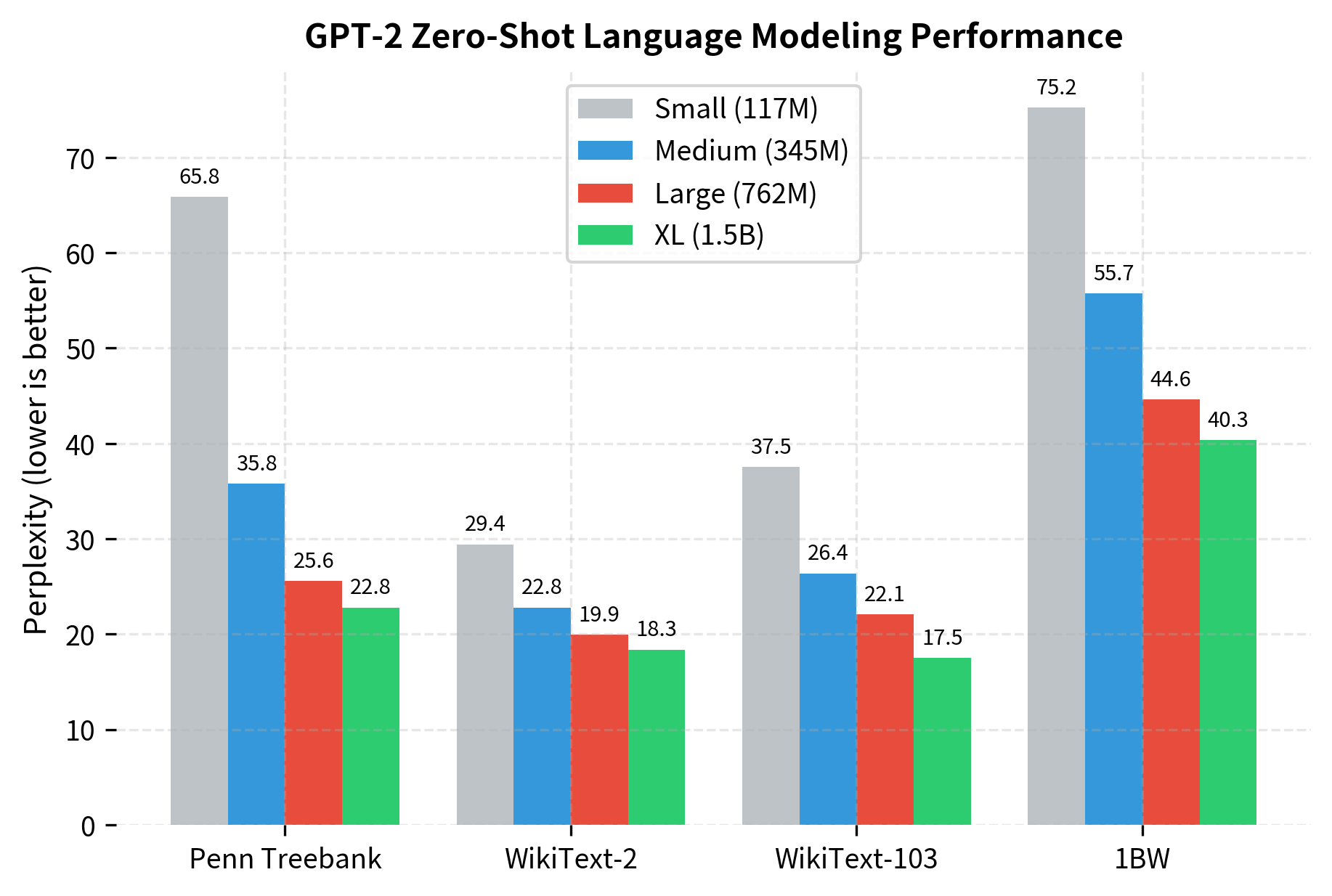
The relationship between model size and perplexity follows a consistent pattern across benchmarks. Let's examine this scaling behavior more closely:
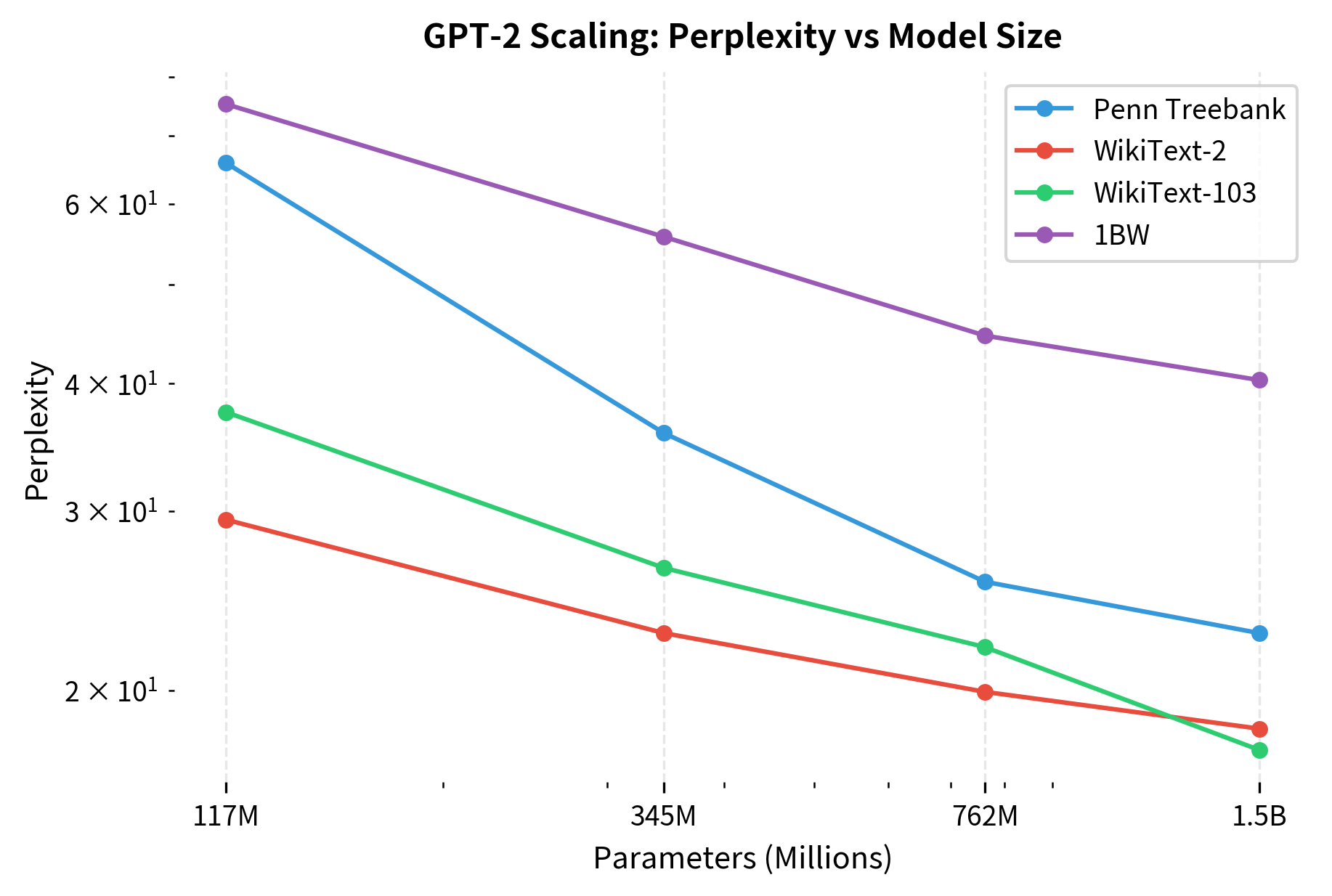
On a log-log plot, the near-linear relationship between parameters and perplexity suggests power-law scaling. This empirical observation, that performance improves predictably with scale, would later be formalized in the "Scaling Laws for Neural Language Models" paper by Kaplan et al. (2020). The consistency across diverse benchmarks indicates that scaling benefits are not dataset-specific but reflect genuine improvements in language modeling capability.
Several patterns emerged from these evaluations:
-
Consistent scaling: Larger models achieved lower perplexity across all benchmarks. GPT-2 XL achieved state-of-the-art on Penn Treebank despite never being explicitly trained on it.
-
Domain transfer: Performance on WikiText (derived from Wikipedia) was strong despite Wikipedia being excluded from training, suggesting the model learned transferable language patterns.
-
Task emergence: Capabilities like reading comprehension and translation emerged without task-specific training, purely from scale and diverse pretraining.
Limitations of Zero-Shot
Zero-shot performance, while impressive, came with clear limitations:
-
Inconsistency: The model sometimes generated plausible-sounding but incorrect answers, particularly for factual questions.
-
Sensitivity to prompting: Small changes in prompt format could significantly affect performance.
-
Task ambiguity: Without examples, the model sometimes misinterpreted what was being asked.
These limitations motivated the subsequent exploration of few-shot learning, where providing a handful of examples dramatically improved task performance.
Generation Quality
GPT-2's text generation quality captured public attention more than its benchmark scores. The model could produce coherent, contextually appropriate text that often fooled readers into thinking it was human-written.
Coherent Long-Form Generation
Unlike previous language models that quickly devolved into nonsense, GPT-2 maintained coherence over paragraphs and pages. Let's examine what enables this.
The quality of generated text depends heavily on the sampling strategy. Pure random sampling from the full distribution produces incoherent text because low-probability tokens occasionally get selected. Top-k and nucleus sampling restrict generation to high-probability tokens, dramatically improving coherence.
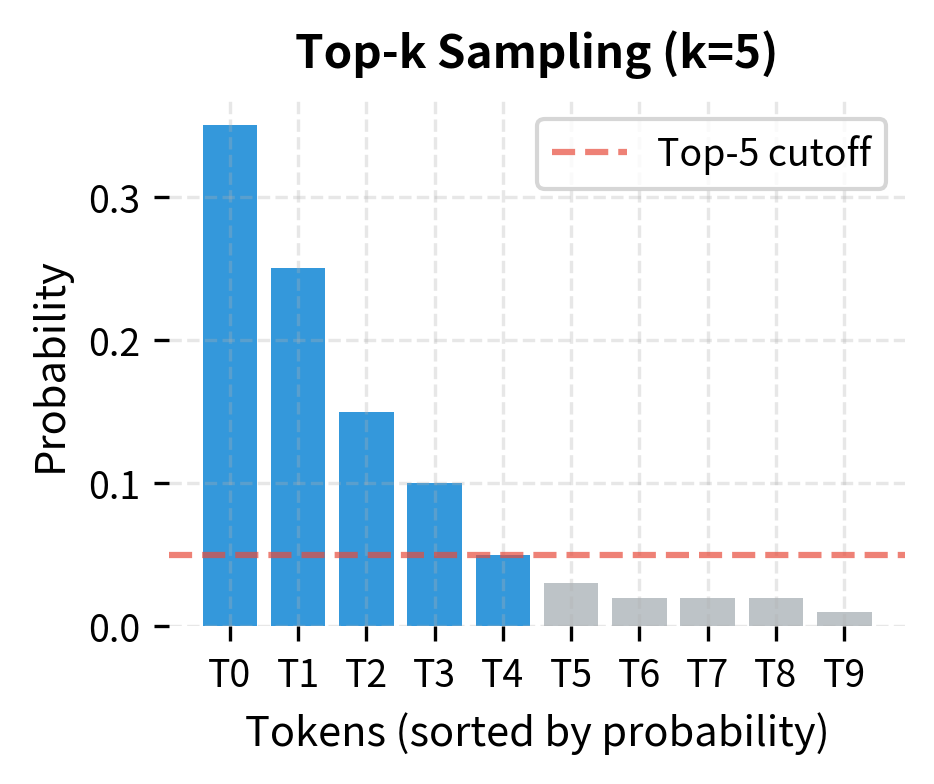
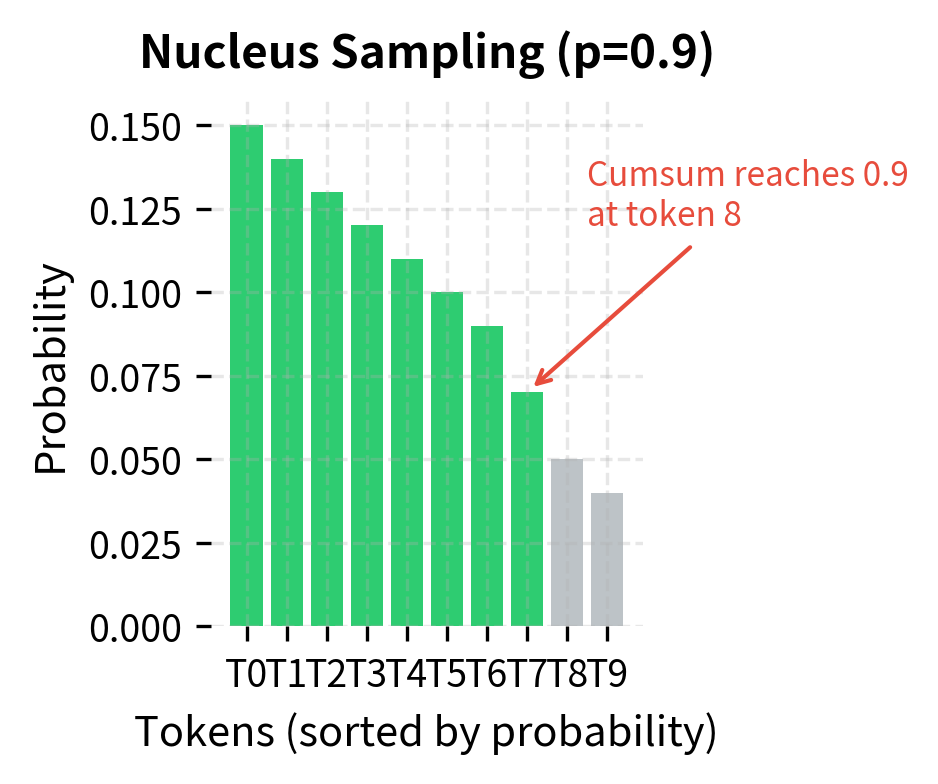
Temperature and Creativity
The temperature parameter provides a tunable tradeoff between coherence and creativity. Temperature scales the logits before applying softmax, controlling how "peaked" or "flat" the resulting probability distribution becomes.
The temperature-scaled softmax computes the probability of selecting token as:
where:
- : the probability of selecting token
- : the raw logit (unnormalized score) for token from the model's output layer
- : the temperature parameter, a positive scalar
- : the vocabulary size (total number of possible tokens)
- : the exponential function
When , this reduces to standard softmax. As , the distribution becomes increasingly peaked around the maximum logit (approaching argmax). As , the distribution approaches uniform, giving all tokens equal probability regardless of their logits. This happens because dividing by a large compresses all logit differences toward zero.
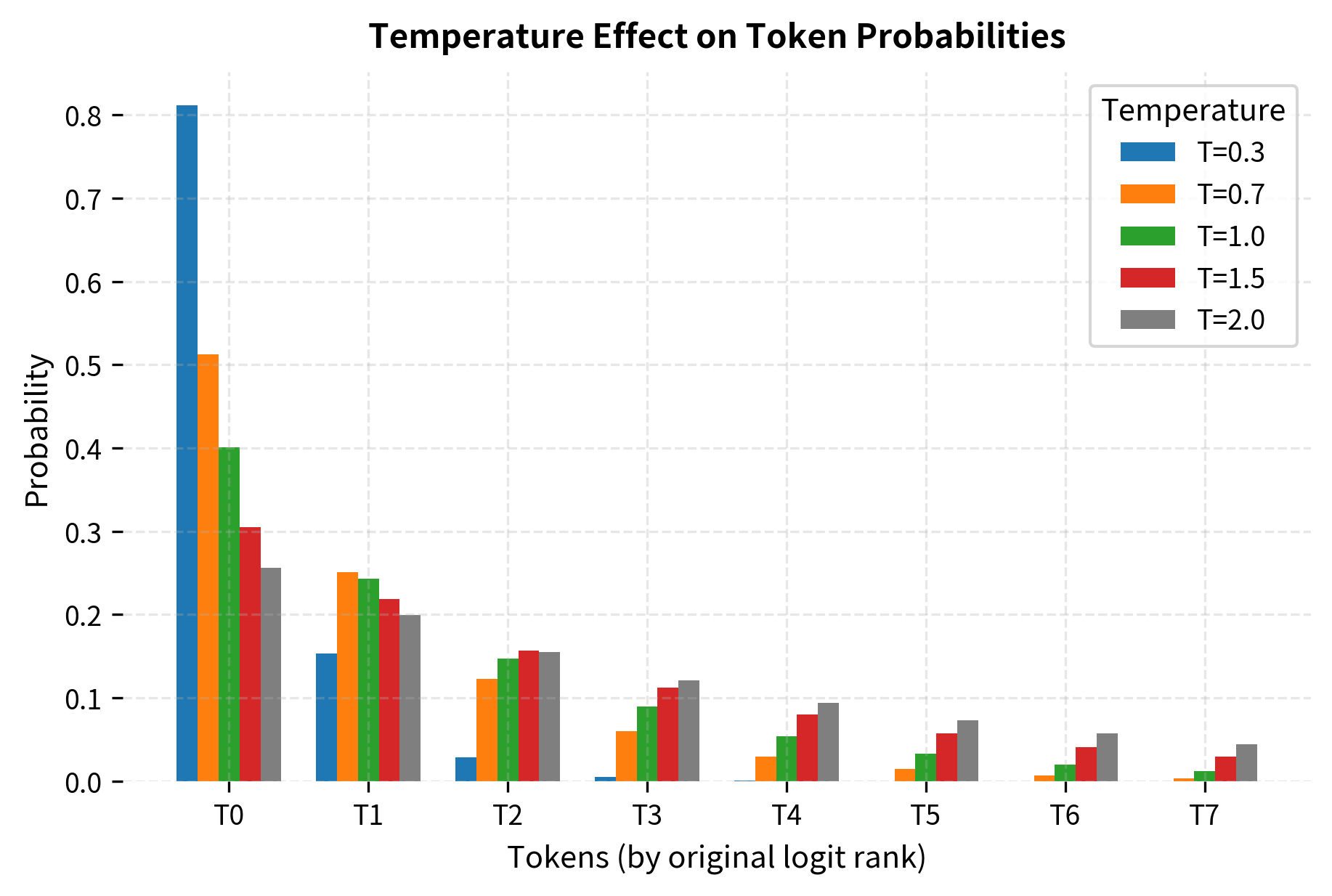
At temperature 0.3, the model almost always selects the highest-probability token, producing repetitive but grammatically correct text. At temperature 1.0 (the default), it balances variety with coherence. At temperature 2.0, even low-probability tokens have significant chance of selection, leading to creative but potentially nonsensical output.
Sample Generation
Let's demonstrate generation using a pretrained GPT-2 model from Hugging Face:
The generated text demonstrates GPT-2's ability to maintain topical coherence and grammatical correctness. It continues prompts in contextually appropriate ways, though close inspection often reveals subtle errors in logic or factual accuracy.
Limitations and Impact
GPT-2 introduced capabilities that transformed expectations for language models, but it also revealed fundamental challenges that persist in larger models today.
Factual Reliability
GPT-2 generates fluent text that can contain fabricated facts presented with confidence. The model has no mechanism to verify statements against ground truth; it simply produces statistically likely continuations. This creates a dangerous asymmetry: the text sounds authoritative but may be wrong. For knowledge-intensive tasks like medical advice or legal guidance, GPT-2's generations are unreliable without external verification. This limitation catalyzed research into retrieval-augmented generation and fact-checking systems.
Bias and Toxicity
The WebText training data, while filtered for quality through Reddit upvotes, inherited biases from its source. GPT-2 can generate text reflecting stereotypes, political biases, and offensive content present in its training distribution. OpenAI's decision to stage the model's release was partly motivated by concerns about automated generation of targeted harassment and misinformation. Subsequent work on RLHF (reinforcement learning from human feedback) and constitutional AI directly addresses these safety concerns.
What GPT-2 Enabled
Despite these limitations, GPT-2 fundamentally changed the field:
-
Scale as a strategy: GPT-2 demonstrated that simply making models larger could yield qualitatively new capabilities. This insight drove the push to GPT-3, PaLM, and other massive models.
-
Zero-shot learning: The idea that a single model could attempt many tasks without fine-tuning opened research into prompting, in-context learning, and instruction tuning.
-
Generation quality: GPT-2 set a new bar for text generation coherence, making language model outputs useful for drafting, brainstorming, and creative applications.
-
Open research: After staged release, OpenAI eventually published the full GPT-2 model. This enabled extensive research into interpretability, safety, and applications.
The transition from GPT-1 to GPT-2 established the scaling paradigm that would define the next several years of language model development: more parameters, more data, more compute. Each increment revealed new capabilities that smaller models lacked.
Summary
GPT-2 demonstrated that scaling autoregressive language models yields emergent capabilities beyond next-token prediction. The key contributions include:
-
Model family: Four sizes from 117M to 1.5B parameters, enabling systematic study of scaling behavior while keeping architecture constant
-
Architectural refinements: Pre-normalization for stable training, GELU activation for smoother gradients, and modified initialization to control variance across deep networks
-
WebText training: 40GB of text from Reddit-filtered web pages, providing diverse, naturally-occurring task demonstrations without explicit supervision
-
Zero-shot capabilities: Reading comprehension, summarization, and translation emerged from pure language modeling, achieved through clever prompting
-
Generation quality: Coherent multi-paragraph text generation that, with appropriate sampling strategies, could pass for human-written
GPT-2 marked the transition from fine-tuned specialists to general-purpose language models. Its limitations, particularly in factual reliability and bias, remain active research areas. But its core insight, that scale enables emergence, fundamentally reshaped expectations for what language models could become. The path to GPT-3 and beyond was now clear: continue scaling, and capabilities would follow.
Key Parameters
When working with GPT-2 or implementing similar architectures, these parameters most directly affect model behavior:
Architecture Parameters:
-
hidden_size (768 to 1600): The dimensionality of token representations. Larger values increase model capacity but quadratically increase attention computation. GPT-2 variants use 768, 1024, 1280, and 1600.
-
num_layers (12 to 48): The number of stacked transformer blocks. More layers enable deeper reasoning but increase memory linearly. Typical values follow powers of 12.
-
num_heads (12 to 25): The number of parallel attention heads. Must evenly divide hidden_size. More heads allow attending to different relationship types simultaneously.
-
max_position (1024): Maximum sequence length the model can process. Longer contexts enable conditioning on more information but increase memory quadratically with sequence length.
Generation Parameters:
-
temperature (0.0 to 2.0): Controls randomness in sampling. Values below 1.0 sharpen the distribution (more deterministic), values above 1.0 flatten it (more random). Common choices: 0.7 for focused text, 1.0 for balanced, 1.2+ for creative writing.
-
top_k (1 to 100): Restricts sampling to the k highest-probability tokens. Lower values increase coherence but reduce diversity. Common choices: 40-50 for general use, lower for factual tasks.
-
top_p (0.0 to 1.0): Nucleus sampling threshold. Keeps tokens until cumulative probability exceeds p. Adapts to the shape of each distribution. Common choices: 0.9-0.95 for balanced generation.
-
max_new_tokens: Number of tokens to generate. Longer generations risk coherence degradation. Consider the task: summaries need fewer tokens than stories.
Training Parameters:
-
dropout (0.0 to 0.3): Applied to attention weights and feed-forward outputs during training. GPT-2 uses 0.1. Higher values prevent overfitting on small datasets but slow convergence.
-
weight_decay (0.0 to 0.1): L2 regularization strength. GPT-2 uses 0.01. Prevents weights from growing too large, improving generalization.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about GPT-2's architecture, training, and zero-shot capabilities.

Comments