

Master BPTT for training recurrent neural networks. Learn unrolling, gradient accumulation, truncated BPTT, and understand the vanishing gradient problem.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Backpropagation Through Time
In the previous chapter, we introduced RNN architecture: how recurrent connections create a hidden state that flows across timesteps, enabling the network to process sequences of arbitrary length. We saw the elegant parameter sharing that makes RNNs practical. But we left a critical question unanswered: how do we actually train these networks?
Standard backpropagation, which you learned in the neural network foundations, assumes a feedforward structure where information flows in one direction. RNNs break this assumption. The same weights are used at every timestep, and the hidden state at time depends on the hidden state at time , which depends on , and so on. This creates a temporal dependency chain that standard backpropagation cannot directly handle.
Backpropagation Through Time (BPTT) solves this problem by conceptually "unrolling" the RNN across time, transforming the recurrent network into a deep feedforward network with shared weights. Once unrolled, we can apply the chain rule just as we did for feedforward networks, but now the gradients flow backward through time as well as through layers.
This chapter derives BPTT from first principles, traces gradient flow through the unrolled computation graph, and implements the algorithm from scratch. You'll see exactly how gradients accumulate across timesteps and why this creates both computational challenges and the infamous vanishing gradient problem that we'll tackle in the next chapter.
From Feedforward to Recurrent: The Training Challenge
Let's first recall how we train feedforward networks, then see why RNNs require a different approach.
In a feedforward network, each layer transforms its input exactly once. The loss depends on the final output, and backpropagation traces gradients backward through each layer. Each weight appears in exactly one place in the computation graph, so its gradient is computed once.
RNNs are fundamentally different. Consider a sequence of length . At each timestep , the RNN computes:
where:
- : the hidden state at timestep
- : the hidden state from the previous timestep
- : the input at timestep
- : the hidden-to-hidden weight matrix (recurrent weights)
- : the input-to-hidden weight matrix
- : the bias vector
The key observation is that , , and are the same parameters at every timestep. This parameter sharing is what gives RNNs their power, but it also means each parameter affects the loss through multiple computational paths, one for each timestep.
Unlike feedforward networks where each weight appears once in the computation graph, RNN weights are reused at every timestep. When computing gradients, we must account for how each weight influences the loss through all timesteps, not just one.
Unrolling the RNN
The conceptual trick that makes BPTT work is unrolling: we create a copy of the RNN for each timestep, treating the recurrent network as a very deep feedforward network where each "layer" corresponds to a timestep.
Consider a sequence of length 4. The unrolled computation graph looks like this:
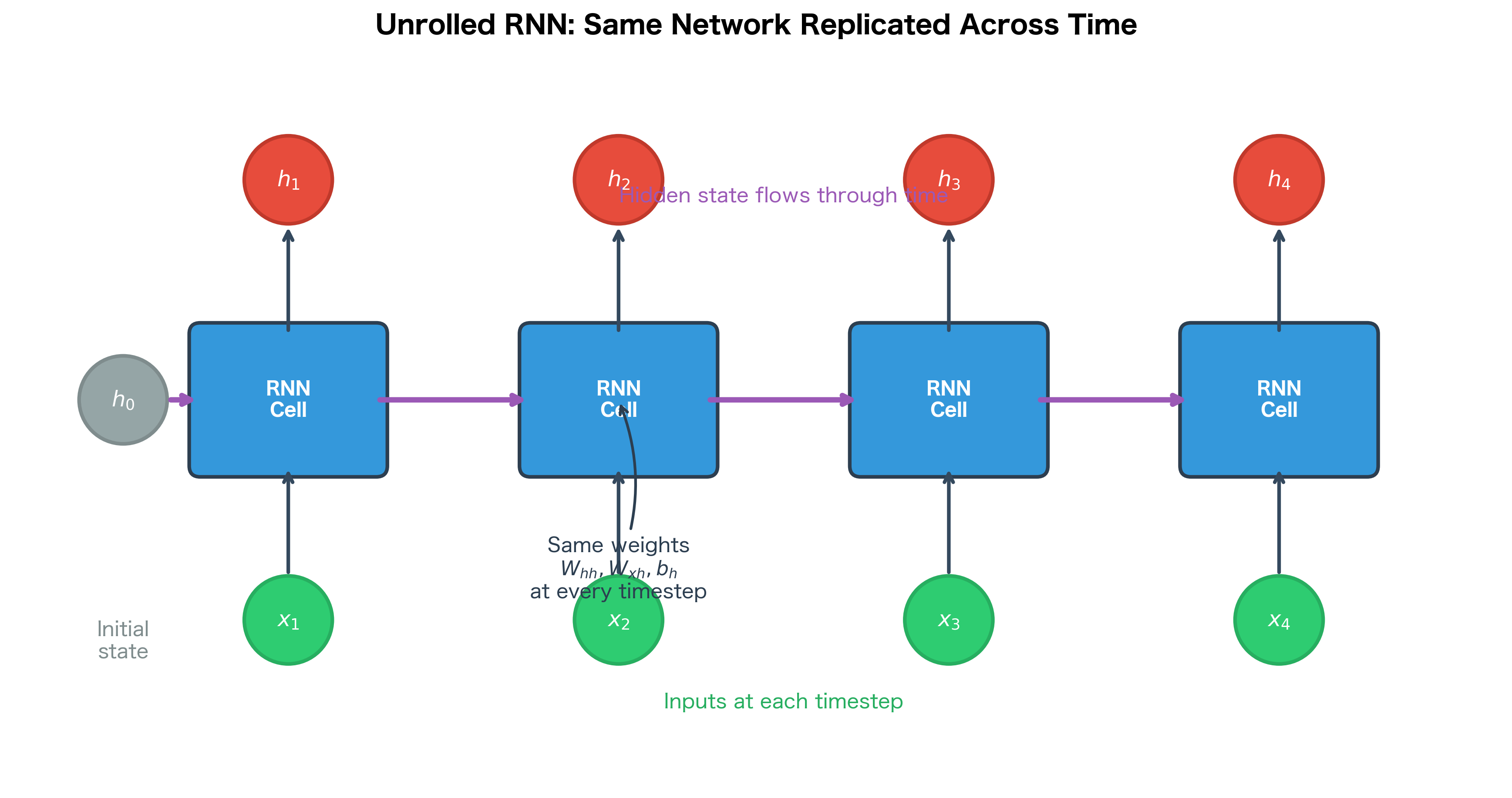
In the unrolled view, we see that:
- Each timestep has its own copy of the RNN cell, but they all share the same weights
- The hidden state flows horizontally, carrying information from past to future
- Inputs enter from below at each timestep
- The network is now a deep feedforward network with "layers"
This unrolling is purely conceptual. We don't actually create copies of the weights in memory. But thinking about the RNN this way allows us to apply the chain rule systematically.
The BPTT Derivation
With the unrolled view in mind, we can now derive the BPTT algorithm systematically. The key challenge is this: how do we compute the gradient of the loss with respect to weights that are used repeatedly across time? The answer comes from carefully applying the chain rule while tracking how each weight influences the loss through multiple paths.
We'll build up the derivation in three stages, starting with the simplest case and progressively tackling more complex dependencies:
- Output weights (straightforward: no temporal dependencies)
- Hidden state gradients (the recursive heart of BPTT)
- Recurrent weights (combining recursion with gradient accumulation)
Throughout, we'll consider a sequence-to-sequence task where we compute a loss at each timestep and sum them. The total loss over the entire sequence is:
where:
- : the total loss over all timesteps, which we want to minimize
- : the sequence length (total number of timesteps)
- : the loss at timestep , typically computed from the hidden state through an output layer (e.g., cross-entropy for classification)
Gradient with Respect to Output Weights
We begin with the simplest case: the output weights that transform hidden states into predictions. This serves as a warm-up because these weights don't create temporal dependencies. Each use of at timestep affects only the loss at that timestep, not any future losses.
If we have an output layer that produces predictions from the hidden state:
where:
- : the output (logits) at timestep
- : the hidden-to-output weight matrix
- : the hidden state at timestep
- : the output bias vector
The gradient with respect to is straightforward because only affects the loss through the outputs at each timestep. Applying the chain rule:
where:
- : the total gradient of the loss with respect to the output weights
- : the gradient of the loss at timestep with respect to the output, which depends on your loss function (e.g., softmax cross-entropy)
- : the transpose of the hidden state, needed for the outer product that produces a matrix gradient
This is just standard backpropagation applied independently at each timestep, then summed. The output weights are straightforward because they don't create temporal dependencies: changing at timestep 3 doesn't affect the hidden state at timestep 4.
Gradient with Respect to Hidden State
Now we tackle the heart of BPTT: computing gradients for the hidden states. This is where temporal dependencies make things interesting, and where the "through time" in BPTT becomes essential.
Consider the hidden state at some timestep . In a feedforward network, each activation affects the loss through exactly one path. But in an RNN, influences the loss through two distinct channels:
- Direct effect: produces output , which contributes to loss
- Indirect effect: flows into , which affects , and then into , affecting , and so on through all future timesteps
This dual influence is the fundamental difference from feedforward networks. The total gradient must account for both channels, which leads us to a recursive formulation.
For the final timestep , the gradient is simple because there are no future timesteps to consider:
For earlier timesteps, we must account for both the direct contribution to and the indirect contribution through future hidden states. The multivariate chain rule gives us:
where:
- : the total gradient of the loss with respect to hidden state , accounting for all paths to the loss
- : the direct gradient from the loss at timestep (through the output layer)
- : the total gradient at the next timestep (already computed when working backward)
- : how much changes when we perturb (the Jacobian of the RNN transition)
This recursive formula is the heart of BPTT. To make the recursion explicit, let's define as the "error signal" at timestep . This gives us:
The term is the Jacobian of the hidden state transition. To derive it, recall that . Applying the chain rule:
where:
- : a diagonal matrix of size , where the -th diagonal entry is , the derivative of tanh at the -th hidden unit
- : the recurrent weight matrix, which determines how the previous hidden state influences the current one
The tanh derivative ranges from 0 (when , the saturation regions) to 1 (when ). This bounded derivative will become critically important when we discuss vanishing gradients: if the hidden units saturate (approach ), the gradient signal gets attenuated at each timestep.
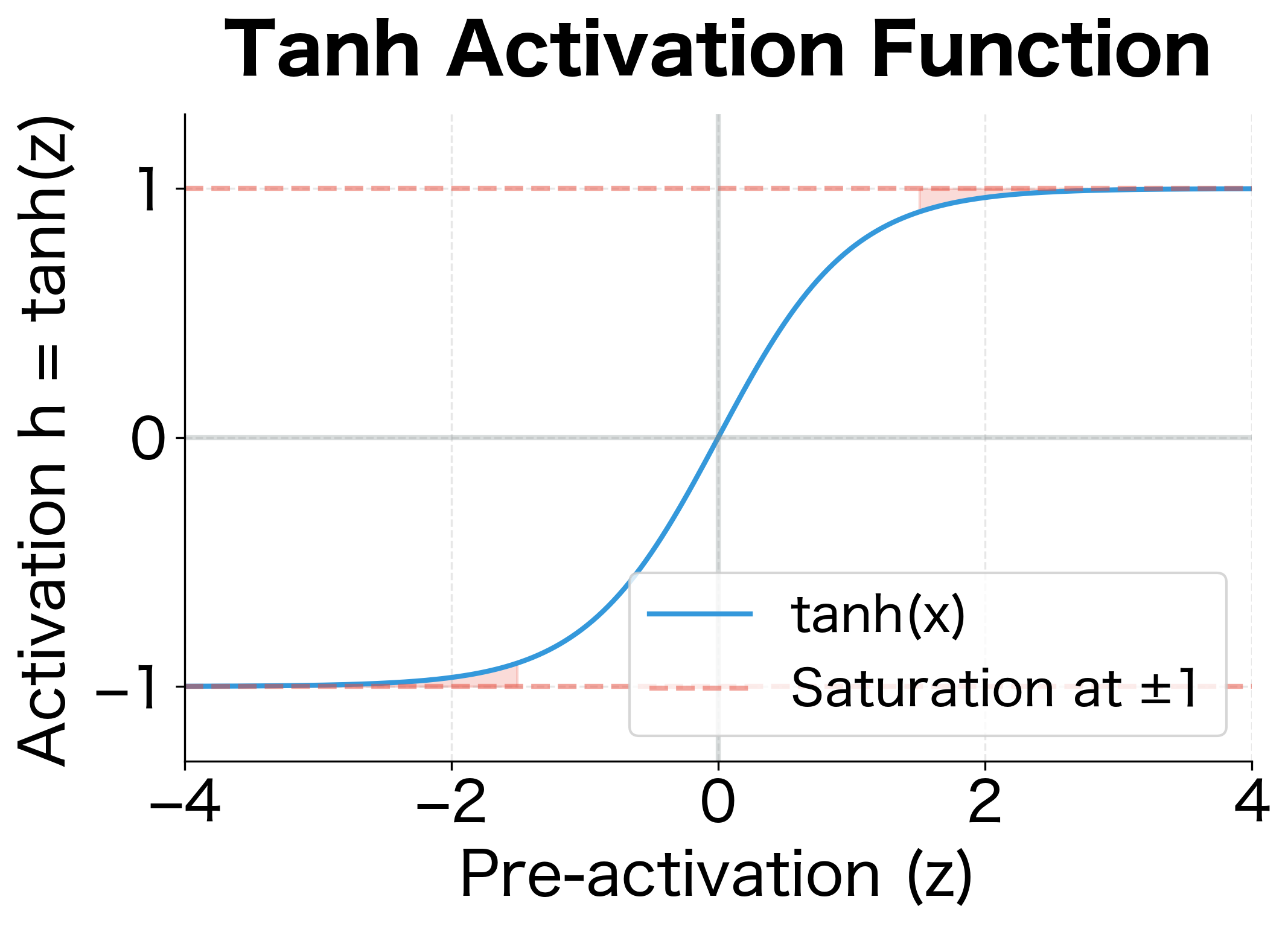
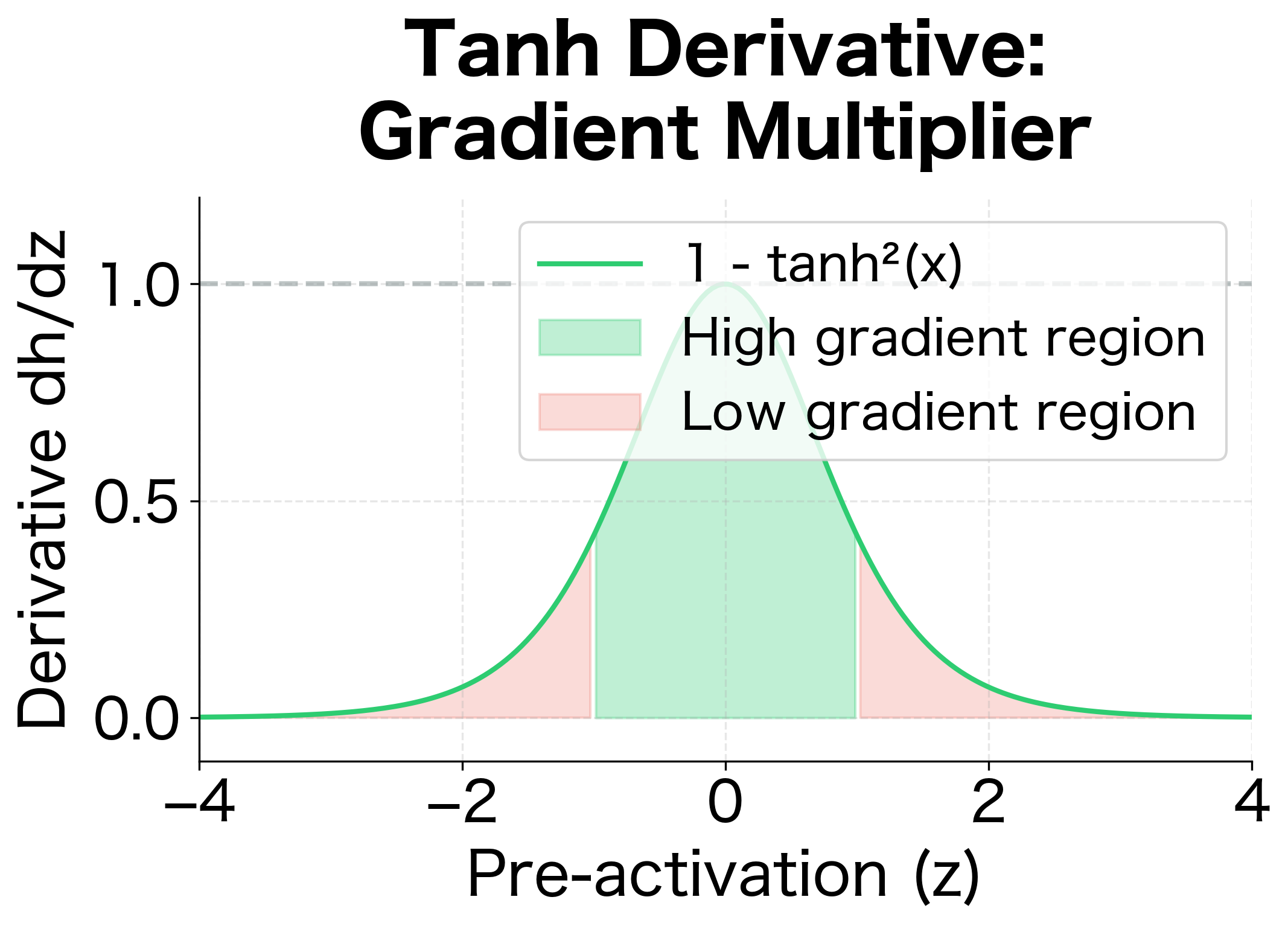
The plot reveals why tanh can cause gradient problems. In the green region (|z| < 1), the derivative is close to 1, allowing gradients to flow relatively unimpeded. But in the red saturation regions (|z| > 1), the derivative drops rapidly toward zero. If hidden units frequently saturate, each timestep multiplies the gradient by a small number, causing exponential decay.
Gradient with Respect to Recurrent Weights
With the hidden state gradients in hand, we can finally tackle the recurrent weights . This is where gradient accumulation becomes essential.
The challenge is that appears at every timestep in the unrolled computation graph. When we change , we change the computation at timestep 1, timestep 2, timestep 3, and so on. Each of these changes affects the loss. The total gradient must sum all these contributions:
More formally, since is used at every timestep, its gradient is the sum of contributions from all timesteps:
where:
- : the total gradient of the loss with respect to the recurrent weights
- : the error signal at timestep (computed in the backward pass)
- : how the hidden state at timestep changes with respect to the weights (the local gradient)
At each timestep , the local gradient comes from differentiating with respect to :
where appears because the gradient of a matrix-vector product with respect to involves the vector .
Combining the error signal with the local gradient at each timestep:
where:
- : the error signal multiplied element-wise by the tanh derivative, giving the gradient at the pre-activation
- : the hidden state from the previous timestep, transposed for the outer product
- : element-wise (Hadamard) multiplication
The sum over all timesteps reflects the fact that the same weight matrix is used at every step. Each use contributes to the total gradient.
The key insight of BPTT is gradient accumulation: each weight's gradient is the sum of its contributions from all timesteps. This is why we must store all hidden states during the forward pass, as we need them when computing the backward pass.
Visualizing Gradient Flow
To understand BPTT intuitively, let's visualize how gradients flow backward through the unrolled network.
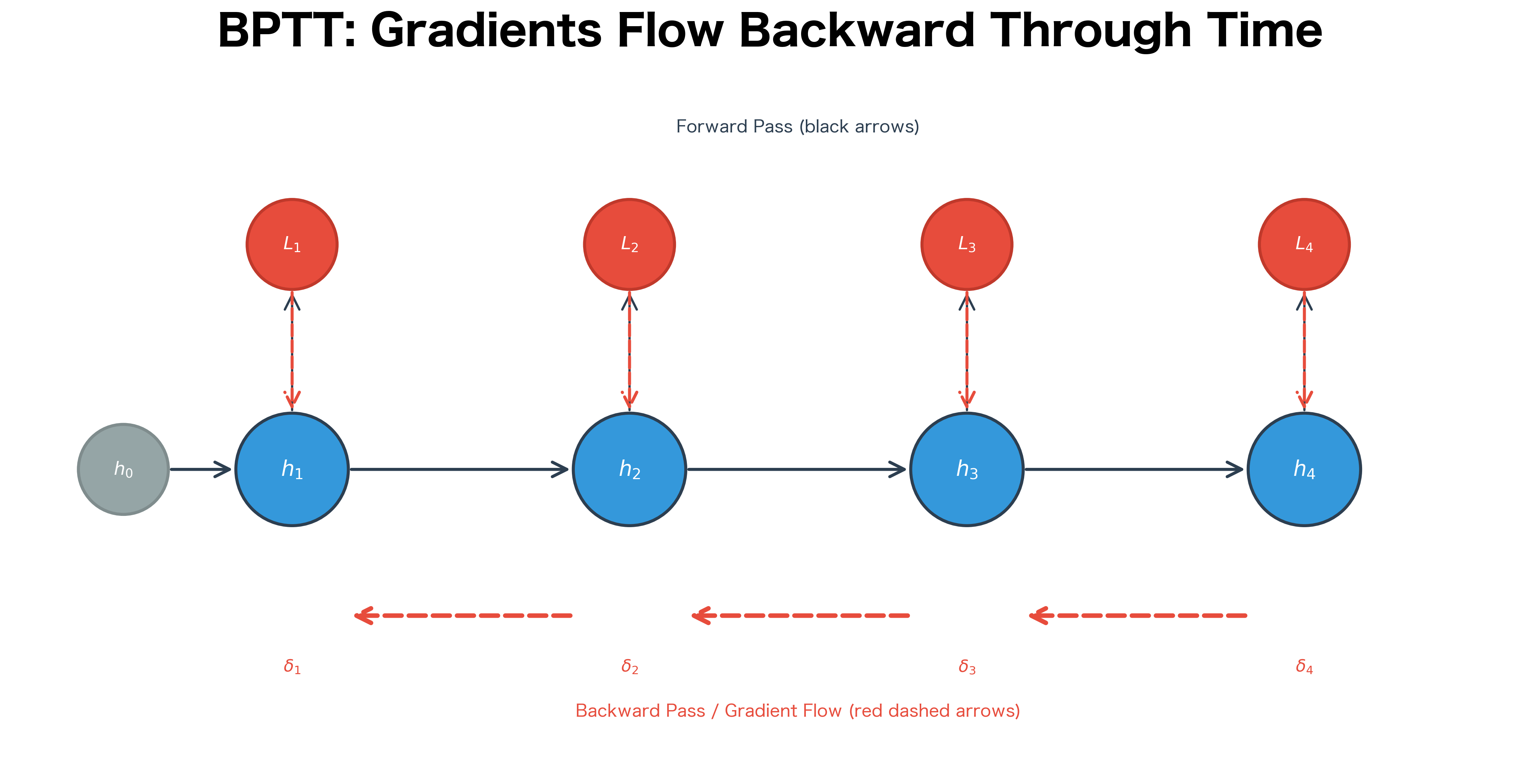
The diagram reveals a crucial insight: the gradient at early timesteps accumulates contributions from all future losses. The gradient at the first hidden state includes:
- The direct gradient from
- The gradient from flowing back through
- The gradient from flowing back through and
- The gradient from flowing back through , , and
This accumulation is what allows RNNs to learn long-range dependencies, but it's also the source of the vanishing gradient problem we'll explore in the next chapter.
A Worked Example
The formulas above can feel abstract until you trace through them with concrete numbers. Let's work through BPTT step by step on a tiny example, computing every intermediate value by hand. This will solidify your understanding of how gradients flow backward through time and accumulate across timesteps.
We'll use a sequence of length 3 with scalar hidden states (dimension 1) to keep the arithmetic tractable. In practice, hidden states are vectors with hundreds or thousands of dimensions, but the same principles apply.
Setup:
- Sequence length:
- Hidden dimension: (scalar for simplicity)
- Input dimension:
- Inputs: , ,
- Initial hidden state:
- Weights: , ,
- Target outputs: , ,
- Loss: Mean squared error at each timestep
Forward Pass:
Now we compute gradients flowing backward from to :
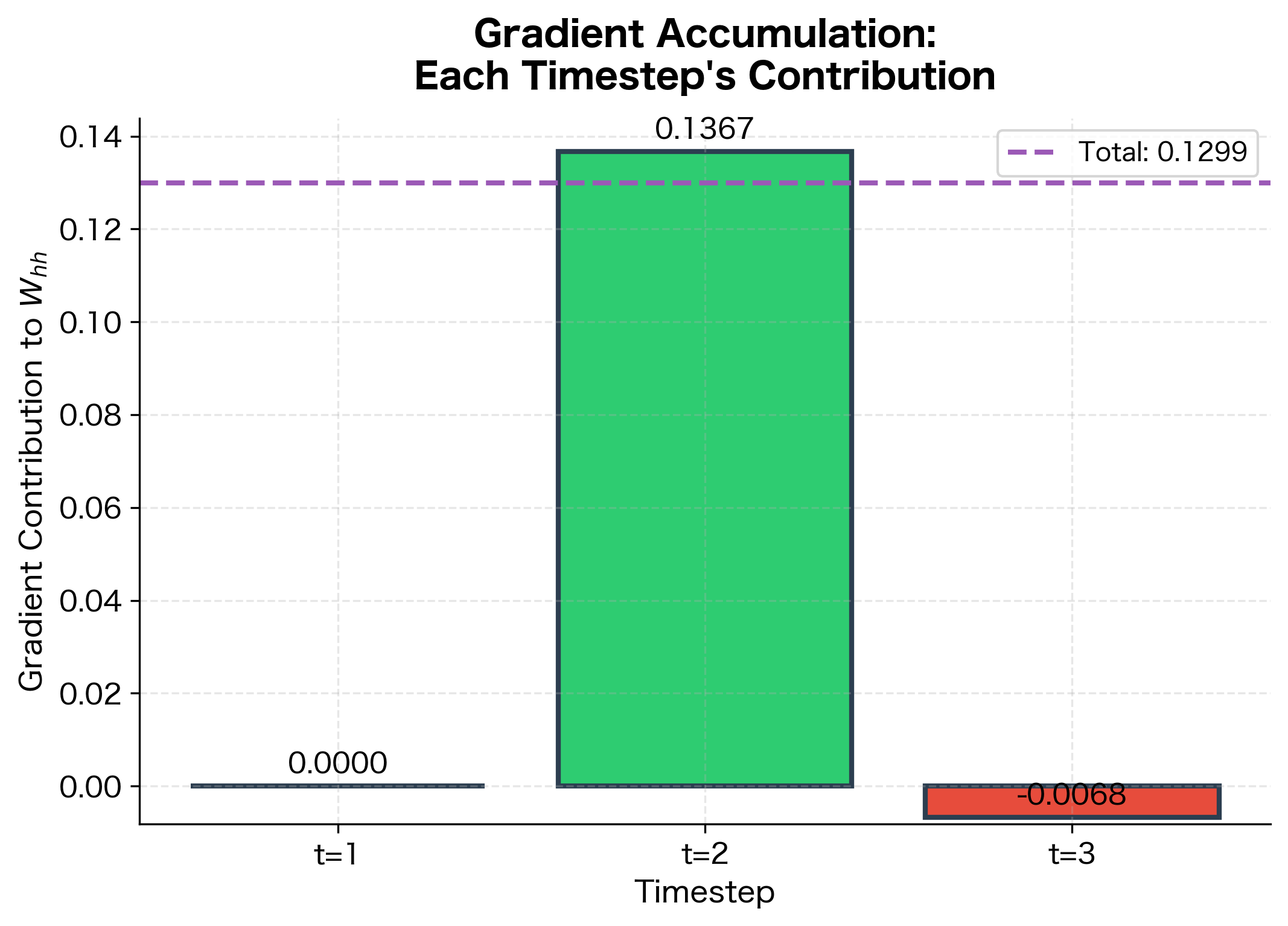
This worked example illustrates the two key aspects of BPTT:
-
Recursive gradient computation: Notice how at the first timestep includes contributions from all three losses. The gradient from flows backward through and before reaching , getting multiplied by the tanh derivative and at each step. This is the "through time" in Backpropagation Through Time.
-
Gradient accumulation for shared weights: The gradient for is the sum of contributions from all timesteps. At timestep 1, the contribution is zero because , but timesteps 2 and 3 both contribute. In a longer sequence, this sum would have many more terms, all computed in a single backward pass.
The small numbers in this example hint at a deeper issue: the gradient contributions shrink as we go further back in time. The tanh derivative (around 0.78-0.92 in our example) multiplied by gives a factor less than 1 at each step. Over many timesteps, this shrinking compounds exponentially, leading to the vanishing gradient problem we'll explore in the next chapter.
Let's visualize how gradient magnitude decays as it flows backward through time:
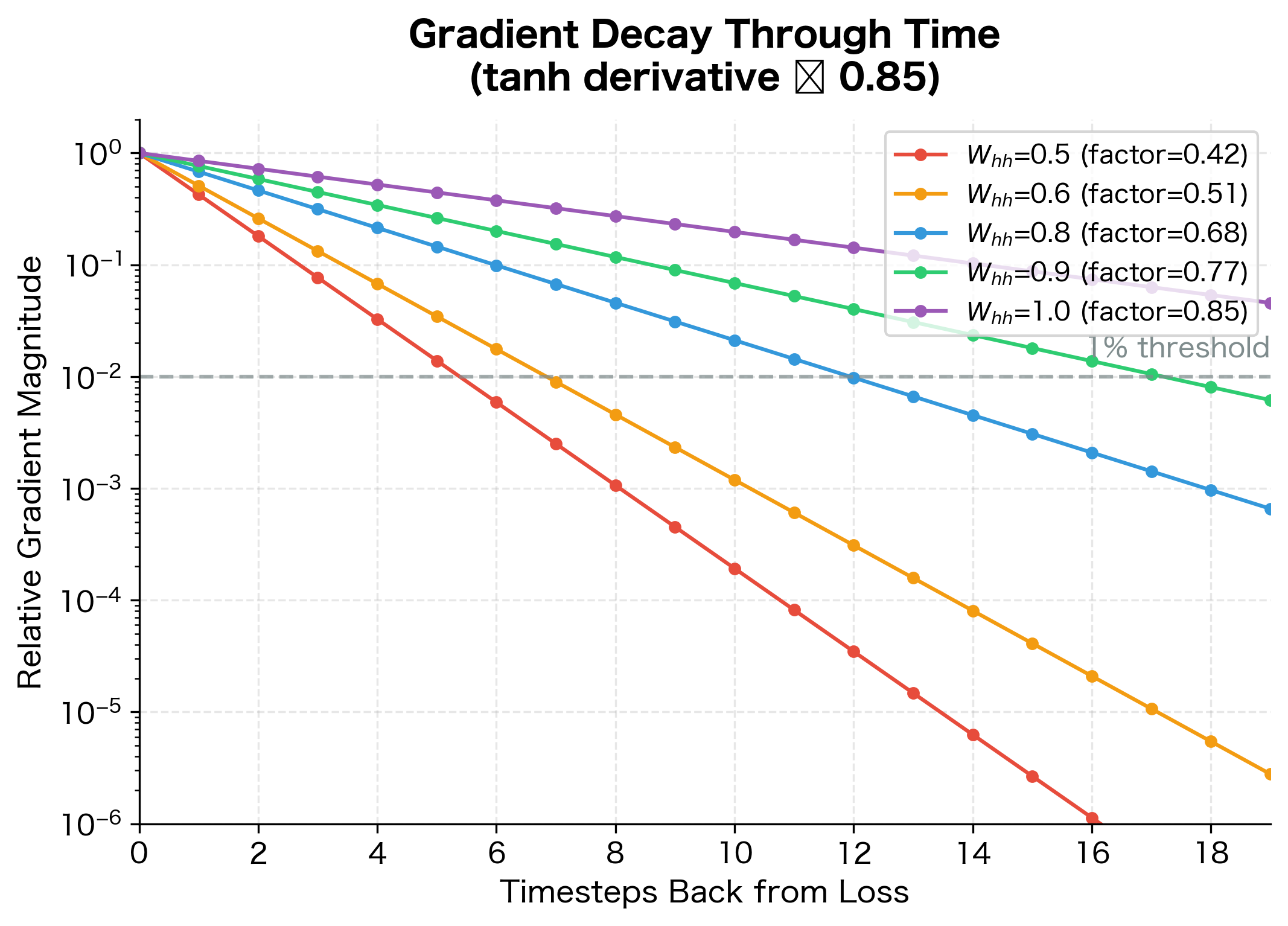
The logarithmic scale reveals the exponential nature of gradient decay. With (our worked example), gradients fall below 1% of their original magnitude after just 8 timesteps. Even with , gradients still decay significantly over 20 steps. Only when the effective decay factor approaches 1.0 do gradients maintain their magnitude, but this requires careful initialization and is difficult to maintain during training.
Implementing BPTT from Scratch
Having derived BPTT mathematically and traced through a worked example, we're ready to implement the algorithm in code. This implementation will handle the general case: vector-valued hidden states, multiple weight matrices, and cross-entropy loss for classification.
We'll build a simple character-level language model, a classic application of RNNs that predicts the next character given the previous characters. This task is simple enough to train quickly but complex enough to demonstrate all aspects of BPTT.
RNN Forward Pass
The forward pass computes hidden states and outputs while storing everything needed for backpropagation. The key insight is that we must save all intermediate values: the hidden states at every timestep (for computing weight gradients) and the pre-activation values (for computing tanh derivatives).
The forward pass stores three critical pieces of information:
- inputs: The input vectors at each timestep
- hidden_states: All hidden states including , needed for computing weight gradients
- pre_activations: The values before tanh, needed for computing tanh derivatives
BPTT Backward Pass
The backward pass is where BPTT comes to life. We iterate through timesteps in reverse order, computing the error signal at each step and accumulating gradients for all weight matrices. The code directly implements the formulas we derived earlier:
The backward pass implements the BPTT algorithm:
-
Compute output gradients: For each timestep, compute the gradient of the cross-entropy loss with respect to the output logits.
-
Backward through time: Starting from the last timestep, propagate gradients backward. At each step:
- Add the gradient from the output layer and the gradient from future timesteps
- Backpropagate through the tanh activation
- Accumulate gradients for all weight matrices
- Pass the gradient to the previous timestep through
-
Gradient accumulation: Each weight matrix accumulates contributions from all timesteps.
Verifying with Numerical Gradients
Let's verify our implementation by comparing analytical gradients to numerical approximations:
The analytical and numerical gradients match to within relative error, well within floating-point precision. This level of agreement confirms our BPTT implementation is mathematically correct. Gradient checking is an essential debugging technique: if the relative error exceeds , there's likely a bug in the backward pass.
Training on Character Sequences
Let's train our RNN on a simple character prediction task:
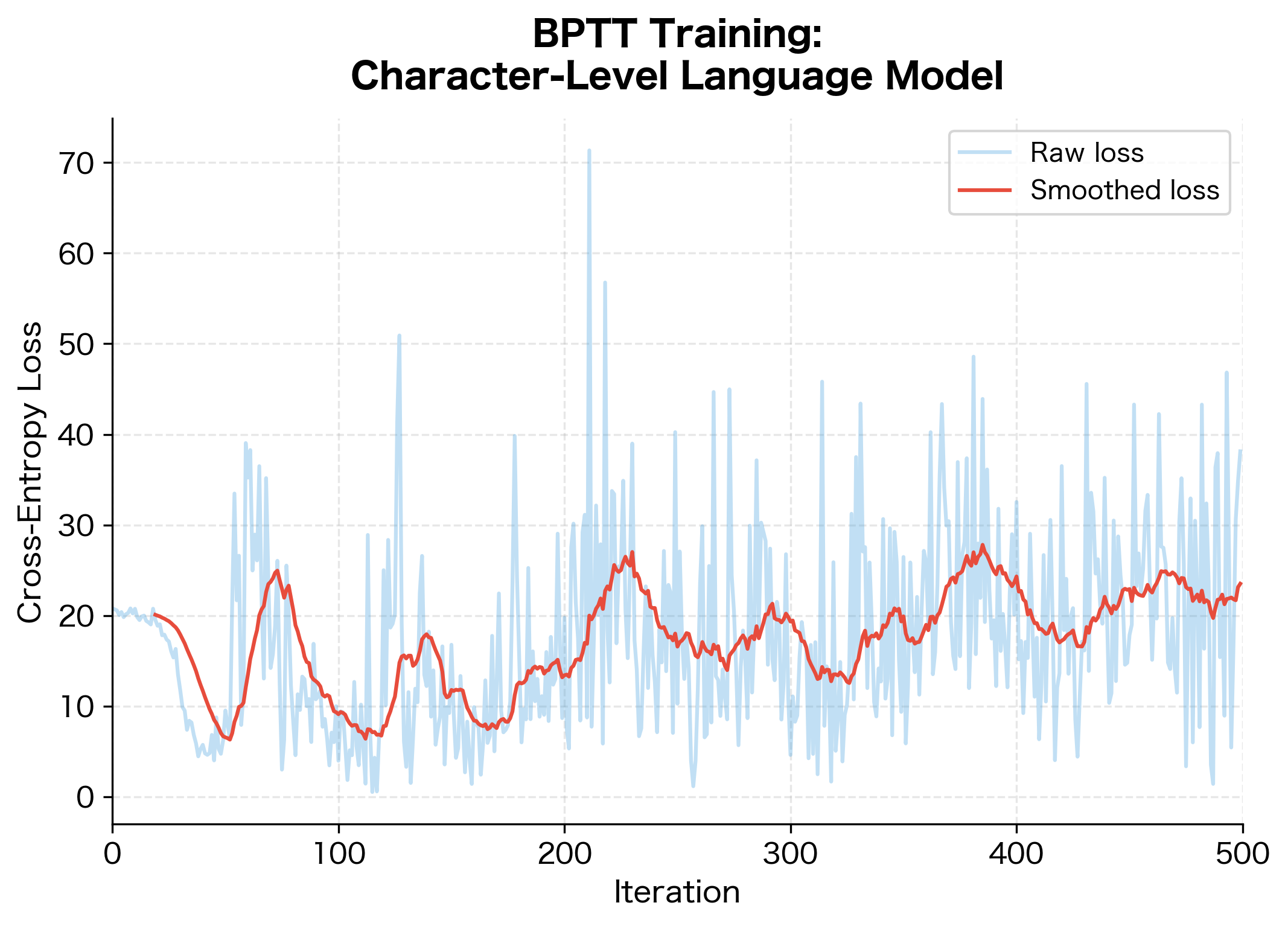
The loss decreases steadily, showing that BPTT successfully trains the RNN. Let's sample from the trained model:
The generated text shows the RNN has learned the basic structure of the training data. While not perfect (the simple model and limited training produce some errors), the output demonstrates that BPTT successfully trained the network to capture character-level patterns. The model learned common bigrams like "he", "ll", "wo", and "ld" from the repeating "hello world" sequence.
Truncated BPTT
Full BPTT requires storing all hidden states for the entire sequence, which becomes prohibitive for long sequences. For a sequence of length with hidden dimension , we need memory just for hidden states.
Truncated Backpropagation Through Time is a practical approximation to full BPTT that limits gradient flow to a fixed number of timesteps . This reduces memory requirements from to , at the cost of not learning dependencies longer than steps.
Truncated BPTT addresses this by limiting how far back gradients flow. Instead of backpropagating through the entire sequence, we:
- Divide the sequence into chunks of length
- Run forward through the entire sequence, but only backpropagate through the last timesteps
- Carry the hidden state forward between chunks, but not the gradients
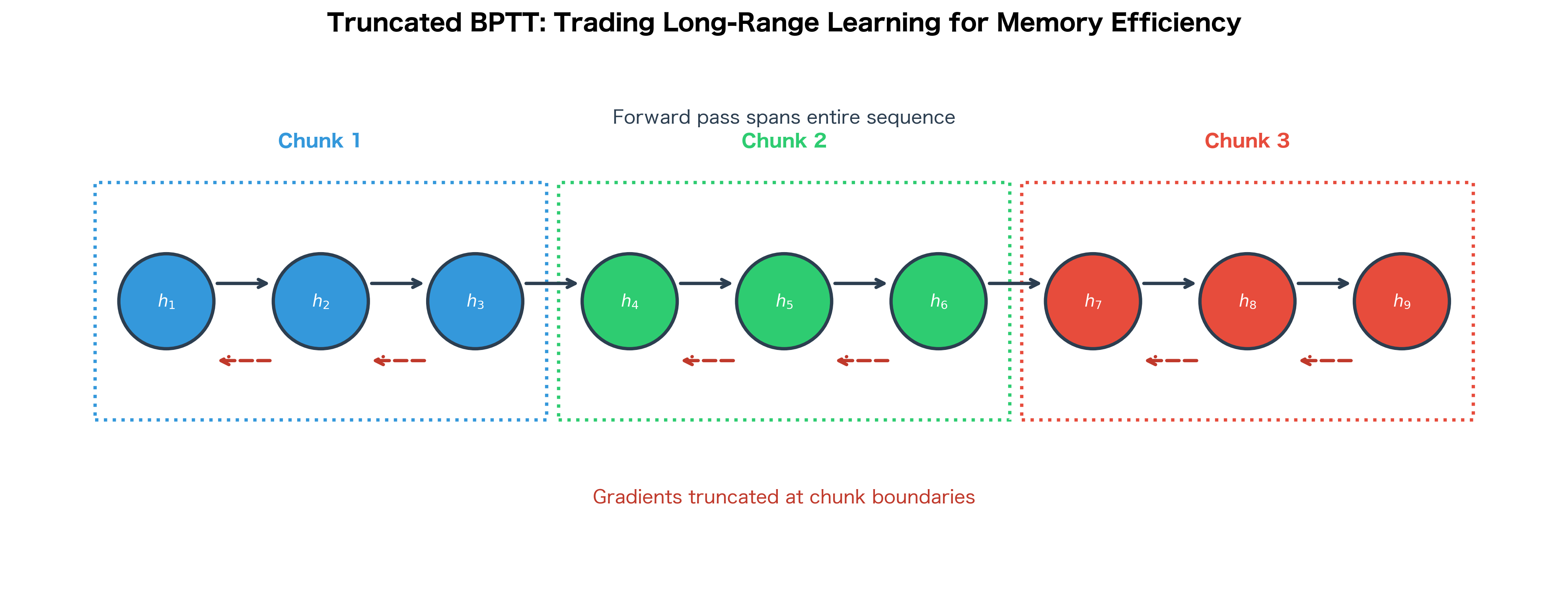
The trade-off is clear: truncated BPTT uses less memory but cannot learn dependencies longer than timesteps. In practice, is often set to 20-50 timesteps, which works well for many tasks but fundamentally limits what the RNN can learn.
Memory Requirements
Understanding BPTT's memory requirements is crucial for practical deep learning. Let's analyze what we need to store during training.
Forward Pass Storage:
- Hidden states: values (one hidden state vector per timestep)
- Pre-activation values: values (needed to compute tanh derivatives during backprop)
- Inputs: values (already stored as part of the input data)
Backward Pass Computation:
- Gradient for each weight matrix: same size as the weight (e.g., for )
- Temporary gradient signals: values for (reused at each timestep)
The dominant cost is storing hidden states: memory. For a sequence of length 1000 with hidden dimension 512, this is about 2 million floating-point numbers, or 8 MB in float32. With batch processing (multiple sequences simultaneously), multiply by the batch size.
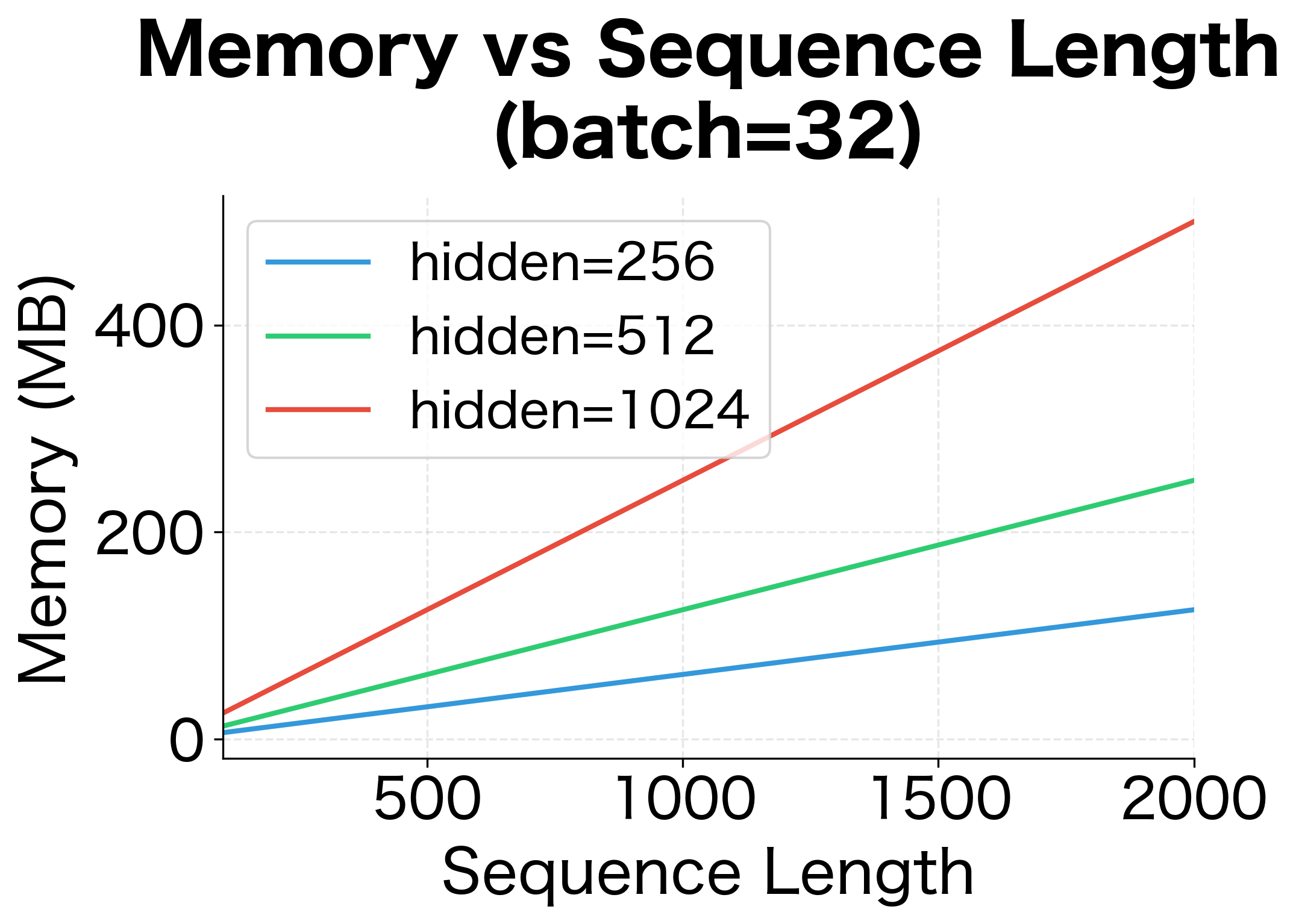
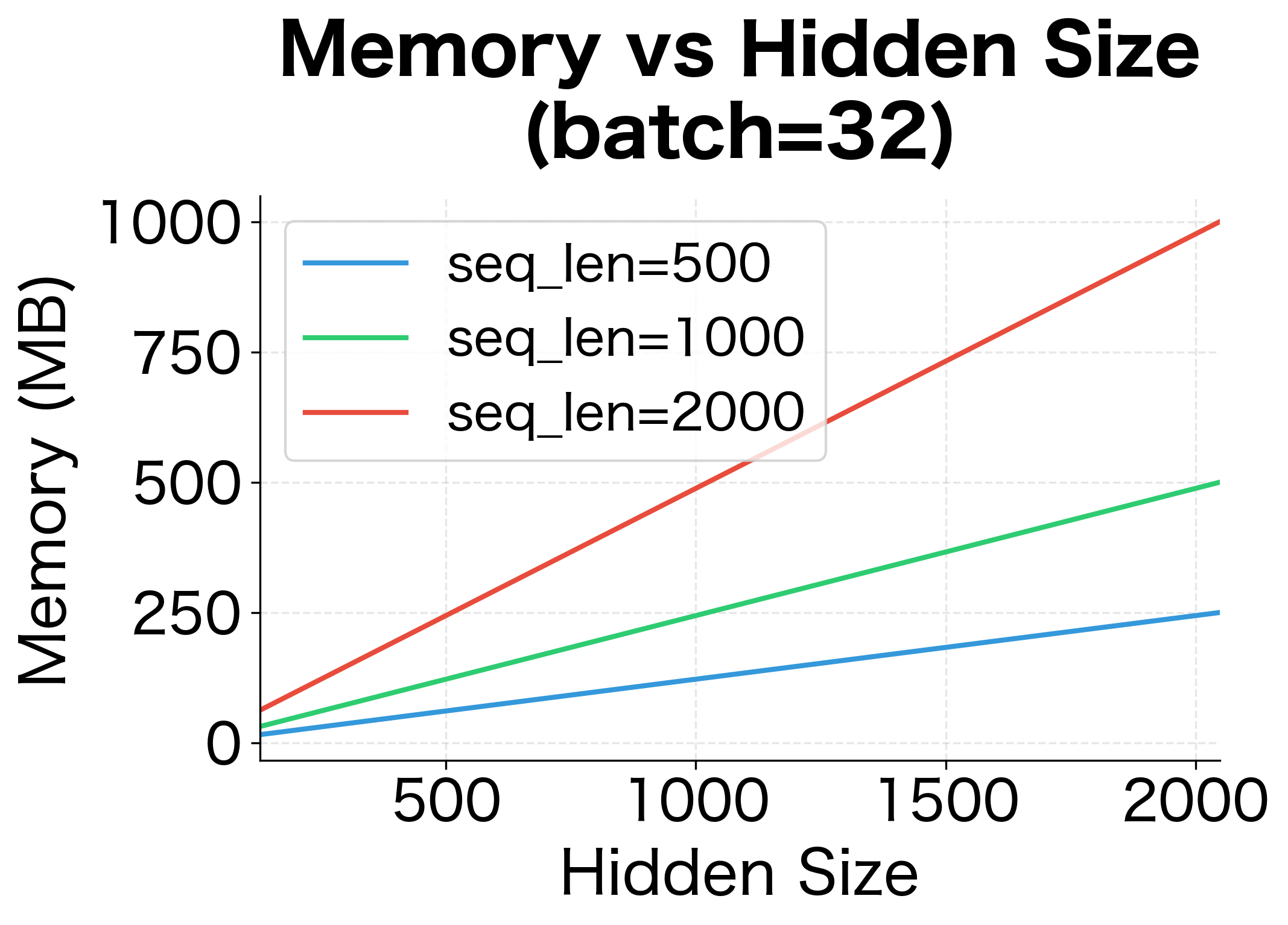
The table and plots show how memory requirements scale dramatically with sequence length, hidden size, and batch size. A modest configuration (1000 timesteps, 1024 hidden units, batch size 64) already requires over 500 MB just for activation storage, not including model parameters or optimizer state. For very long sequences, memory becomes the bottleneck. This is one motivation for truncated BPTT and later architectural innovations like transformers that can process sequences in parallel.
Limitations and Impact
BPTT is a foundational algorithm that made training recurrent neural networks practical, but it comes with significant challenges that shaped the evolution of sequence modeling.
The Vanishing Gradient Problem
The most critical limitation of BPTT is the vanishing gradient problem. When gradients flow backward through many timesteps, they pass through repeated multiplications by and the tanh derivative . If these multiplications consistently shrink the gradient (eigenvalues less than 1), the gradient signal decays exponentially.
To see this mathematically, consider how the gradient at depends on the loss at timestep . Unrolling the recursive formula, we get a product of Jacobians:
where:
- : how much the loss at the final timestep changes when we perturb the first hidden state
- : the direct gradient at the final timestep
- : the product of Jacobian matrices, each of the form
Each Jacobian has magnitude bounded by the product of the largest tanh derivative (at most 1) and the spectral norm of . If this product is less than 1, the gradient shrinks at each step. After steps, the gradient is multiplied by a factor that decays exponentially with sequence length.
For long sequences, this product approaches zero, meaning early timesteps receive essentially no learning signal from late losses. The network cannot learn long-range dependencies because the gradient information is lost before it reaches the relevant parameters.
This isn't just a theoretical concern. In practice, vanilla RNNs trained with BPTT struggle with dependencies beyond 10-20 timesteps. A language model might fail to connect a pronoun with its antecedent if they're separated by many words. A time series model might miss patterns that span long intervals.
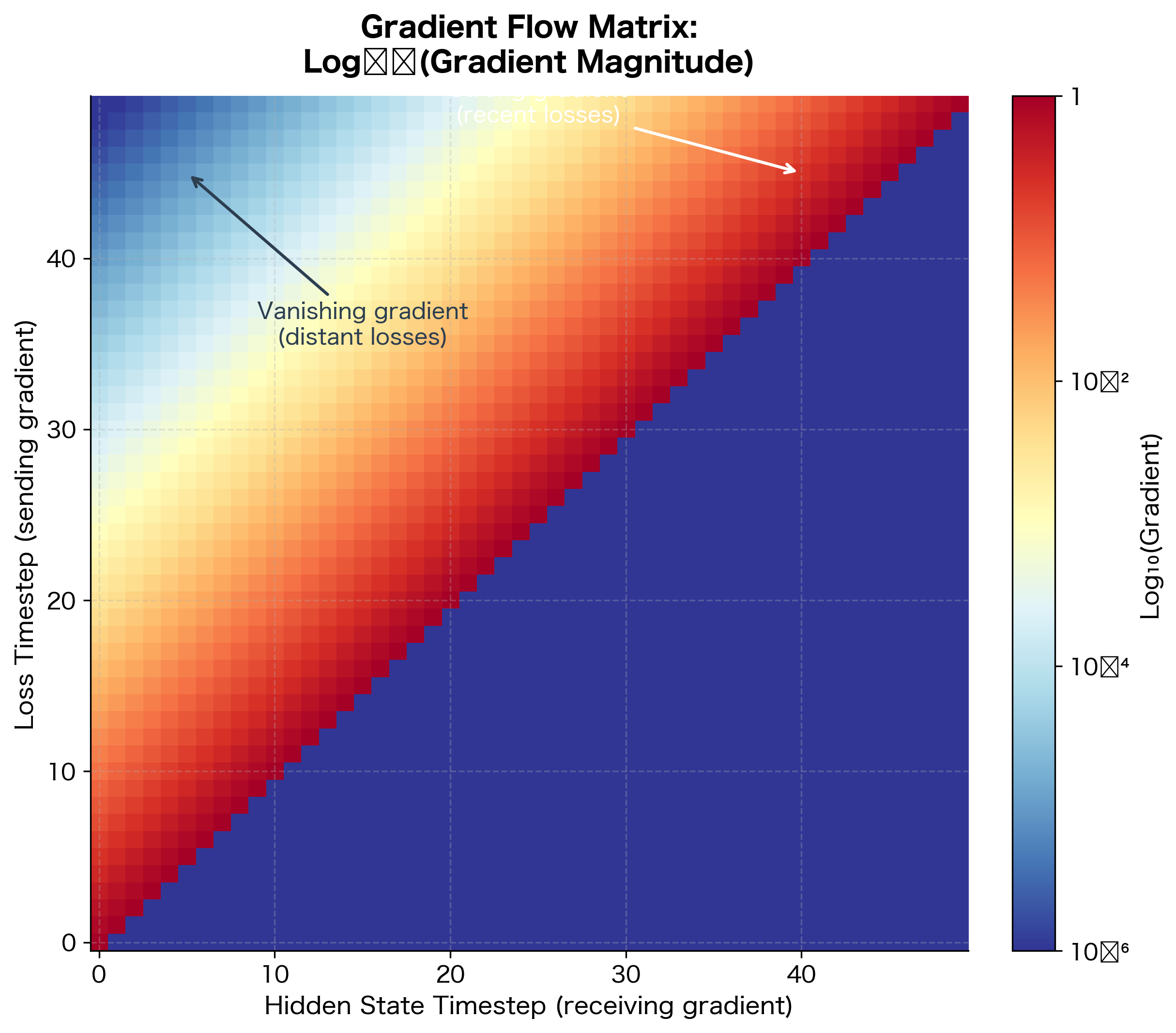
The heatmap makes the vanishing gradient problem visually stark. Each row represents a loss at a specific timestep; each column represents a hidden state that might need to be updated. The diagonal is bright (recent losses strongly affect recent hidden states), but the lower-left is dark (late losses barely affect early hidden states). If the correct prediction at timestep 50 depends on information from timestep 5, the gradient signal is attenuated by a factor of , essentially zero for practical purposes.
Exploding Gradients
The opposite problem, exploding gradients, occurs when the repeated multiplications amplify rather than shrink the gradient. The gradient grows exponentially, leading to numerical overflow and unstable training. Gradient clipping (limiting gradient magnitudes) provides a practical workaround, but it doesn't solve the underlying issue of gradient instability.
Computational Cost
BPTT is inherently sequential. We must compute the forward pass through all timesteps before starting the backward pass, and the backward pass must proceed in reverse order. This sequential dependency prevents parallelization across timesteps, making RNN training slow compared to feedforward networks of similar depth.
What BPTT Unlocked
Despite these limitations, BPTT was transformative. Before BPTT, training recurrent networks was largely impractical. BPTT made it possible to train networks that could:
- Model sequential dependencies in text, speech, and time series
- Learn from variable-length inputs without fixed-size windows
- Capture patterns that span multiple timesteps
The limitations of vanilla BPTT directly motivated architectural innovations. LSTMs and GRUs, which we'll cover in upcoming chapters, were designed specifically to address the vanishing gradient problem by creating "highways" for gradient flow. More recently, transformers abandoned recurrence entirely, using attention mechanisms that allow direct connections between any two positions in a sequence.
Understanding BPTT deeply, including its failure modes, is essential for appreciating why these newer architectures were developed and how they solve the problems that BPTT exposed.
Summary
This chapter derived and implemented Backpropagation Through Time, the algorithm that makes training recurrent neural networks possible.
The key concepts are:
-
Unrolling: Conceptually unfold the RNN across time, treating it as a deep feedforward network with shared weights. This allows us to apply the chain rule systematically.
-
Recursive gradient computation: The gradient at each hidden state combines the local loss gradient with the gradient flowing back from future timesteps:
-
Gradient accumulation: Since weights are shared across timesteps, we sum gradient contributions from all timesteps. This is the defining characteristic of BPTT compared to standard backpropagation.
-
Memory-computation trade-off: Full BPTT requires storing all hidden states, with memory scaling as . Truncated BPTT reduces memory by limiting how far back gradients flow, at the cost of not learning very long-range dependencies.
-
Gradient instability: The repeated multiplication of gradients through time leads to vanishing or exploding gradients, fundamentally limiting what vanilla RNNs can learn.
In the next chapter, we'll dive deeper into the vanishing gradient problem: why it occurs mathematically, how to visualize it, and why it motivated the development of gated architectures like LSTMs and GRUs.
Key Parameters
When implementing BPTT, several parameters significantly affect training behavior and memory usage:
-
hidden_size: The dimension of the hidden state vector. Larger values increase model capacity but also increase memory requirements quadratically (due to being ). Typical values range from 128 to 1024.
-
learning_rate: Controls the step size during gradient descent. RNNs are often sensitive to learning rate; values between 0.001 and 0.1 are common starting points. Too high causes instability; too low causes slow convergence.
-
gradient_clip_value: The maximum allowed gradient magnitude. Clipping gradients to values like 1.0 or 5.0 prevents exploding gradients from destabilizing training, though it doesn't address vanishing gradients.
-
truncation_length (k): For truncated BPTT, the number of timesteps to backpropagate through. Larger values capture longer dependencies but require more memory. Values of 20-50 are common; the optimal choice depends on the temporal structure of your data.
-
weight_scale: The standard deviation for weight initialization. Small values (0.01-0.1) prevent initial activations from saturating, which would immediately cause vanishing gradients.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about Backpropagation Through Time.

Comments