

Learn how MLPs stack neurons into layers to solve complex problems. Covers hidden layers, weight matrices, batch processing, and classification/regression tasks.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Multilayer Perceptrons
In the previous chapters, we explored linear classifiers and activation functions as separate building blocks. Linear classifiers can find decision boundaries, but only straight ones. Activation functions introduce non-linearity, but a single neuron with an activation still has limited representational power. The breakthrough comes when we stack these components together into layers, creating what we call a multilayer perceptron (MLP).
MLPs are the workhorses of deep learning. They can approximate virtually any function given enough neurons and proper training. From sentiment analysis to language modeling, understanding MLPs is essential because they form the building blocks of more complex architectures like transformers. This chapter shows you how to construct, understand, and implement MLPs from the ground up.
From Single Neurons to Hidden Layers
A single neuron computes a weighted sum of its inputs, adds a bias, and passes the result through an activation function. Given an input vector with features, the neuron computes:
where:
- : the input vector containing features
- : the weight vector, where each controls how much input influences the output
- : the dot product , computing a weighted sum of inputs
- : the bias term, which shifts the decision boundary
- : the activation function (e.g., ReLU, sigmoid), which introduces non-linearity
- : the scalar output of the neuron
This single neuron can learn a linear decision boundary (made non-linear by ), but it cannot solve problems requiring more complex boundaries.
A hidden layer is a collection of neurons that sits between the input and output of a neural network. Each neuron in a hidden layer receives the full input (or the output of the previous layer), applies its own weights and bias, and produces one scalar output. The term "hidden" reflects that these intermediate computations are not directly observed, only the final output layer is.
Consider the classic XOR problem: given two binary inputs, output 1 if exactly one input is 1, and 0 otherwise. No single linear boundary can separate the positive from negative examples. But with a hidden layer, we can first transform the inputs into a new representation where the classes become linearly separable.
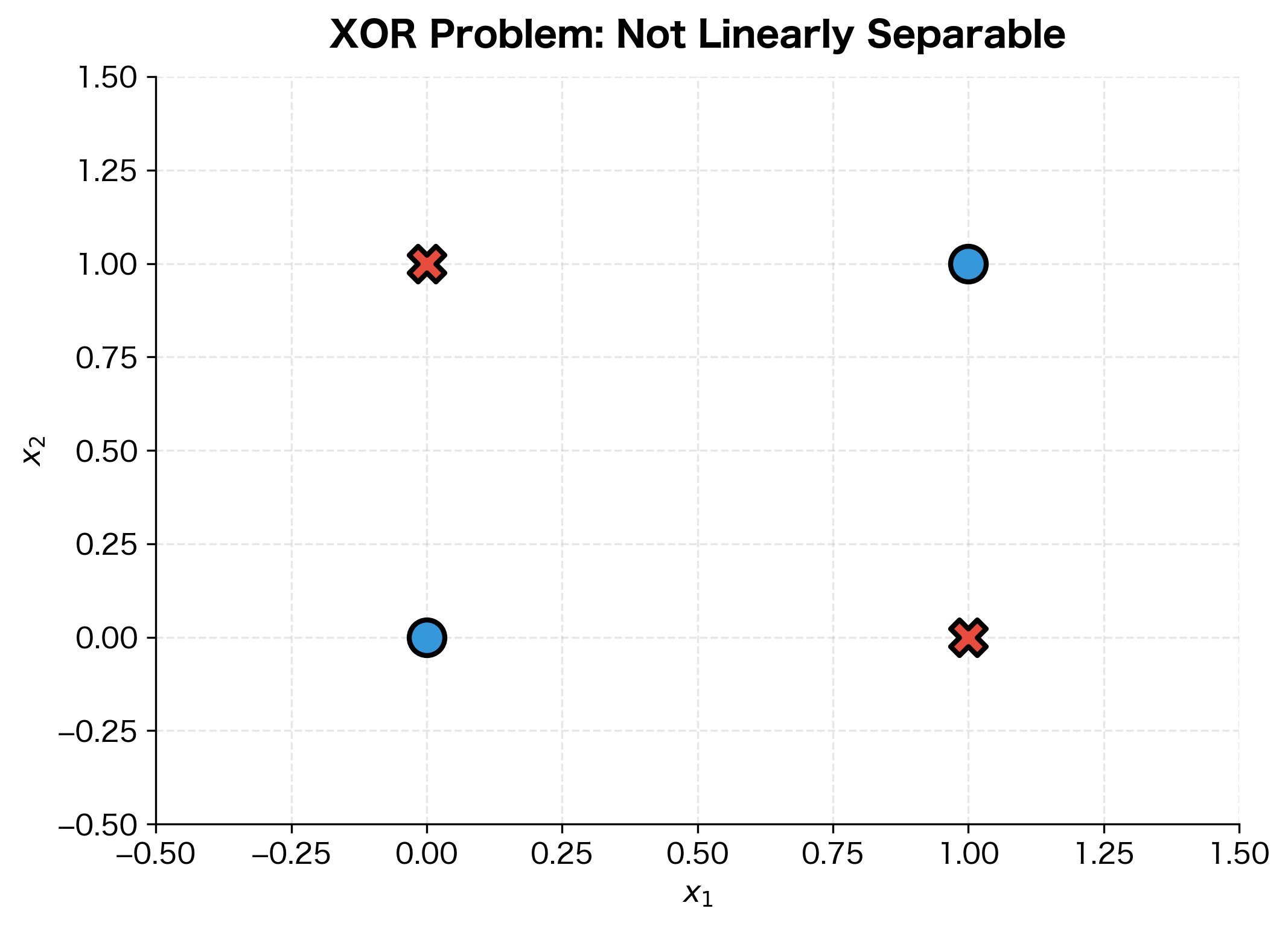
The magic happens when we add a hidden layer. Each hidden neuron learns to detect a different feature or pattern in the input. The output layer then combines these learned features to make the final prediction.
To see this in action, let's manually construct a hidden layer that solves XOR and visualize how it transforms the input space:
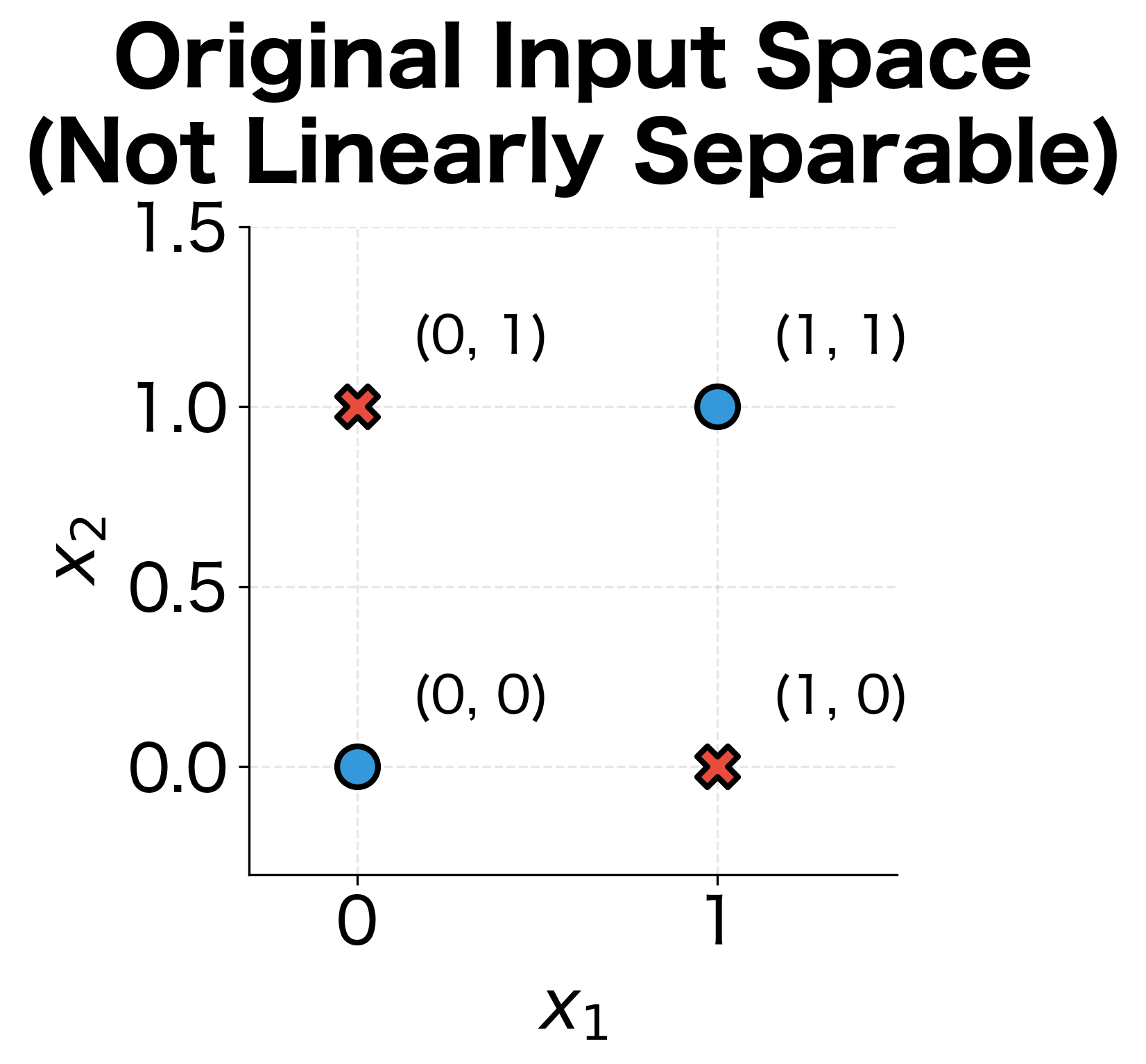
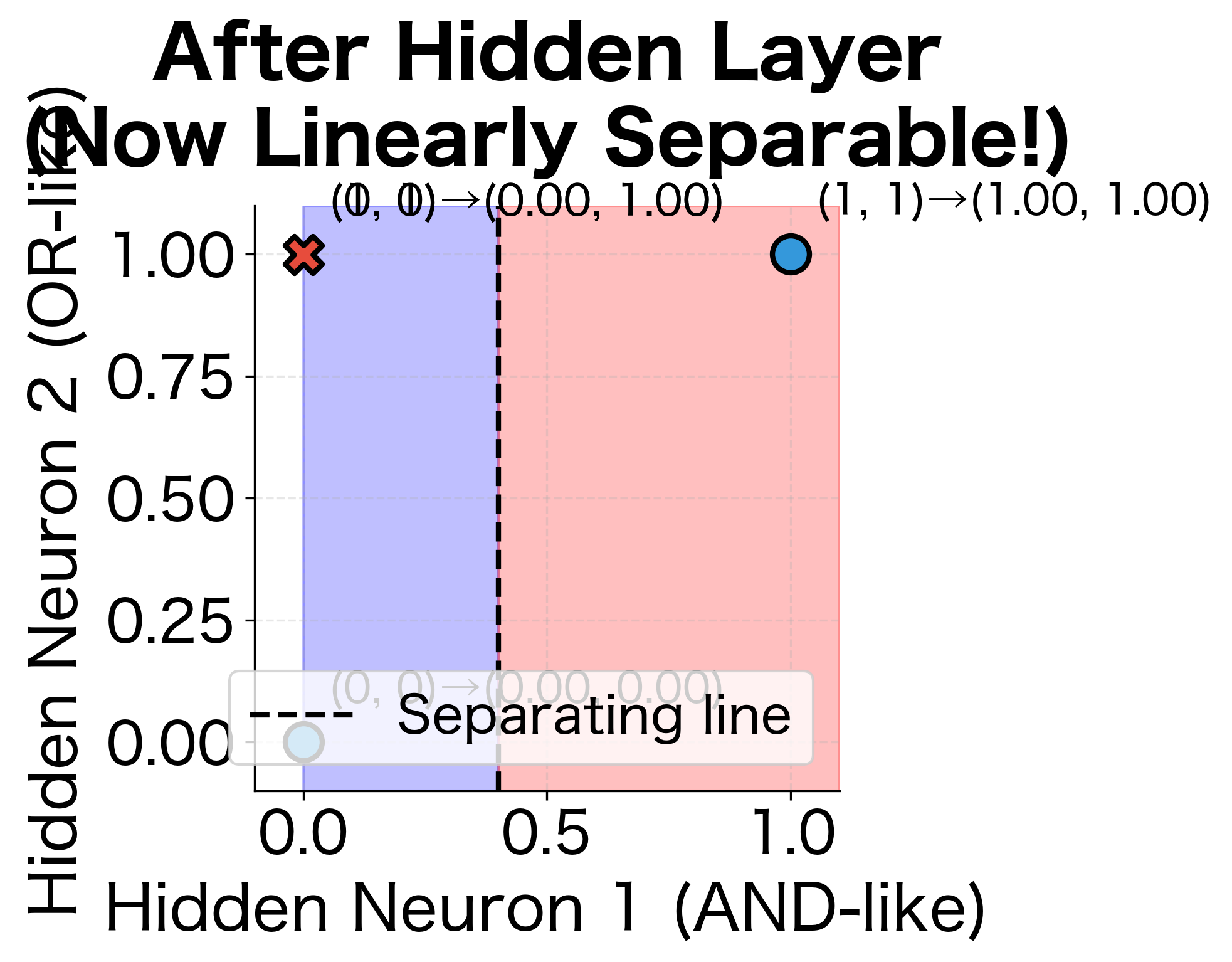
The hidden layer has transformed the input space so that a simple linear classifier can now separate the classes. The first hidden neuron activates only when both inputs are high (AND-like behavior), while the second activates when either input is high (OR-like behavior). In this new coordinate system, the XOR pattern becomes trivially separable.
Network Architecture and Notation
An MLP consists of an input layer, one or more hidden layers, and an output layer. We describe the architecture by the number of units in each layer. For example, a network with 4 inputs, two hidden layers of 8 and 4 units, and 2 outputs would be written as 4-8-4-2.
Let's establish notation that will serve us throughout this chapter and beyond:
- : Total number of layers (excluding input)
- : Number of neurons in layer
- : Weight matrix for layer , with shape
- : Bias vector for layer , with shape
- : Pre-activation values at layer
- : Activations (post-activation values) at layer
- : The input is treated as the activation of layer 0
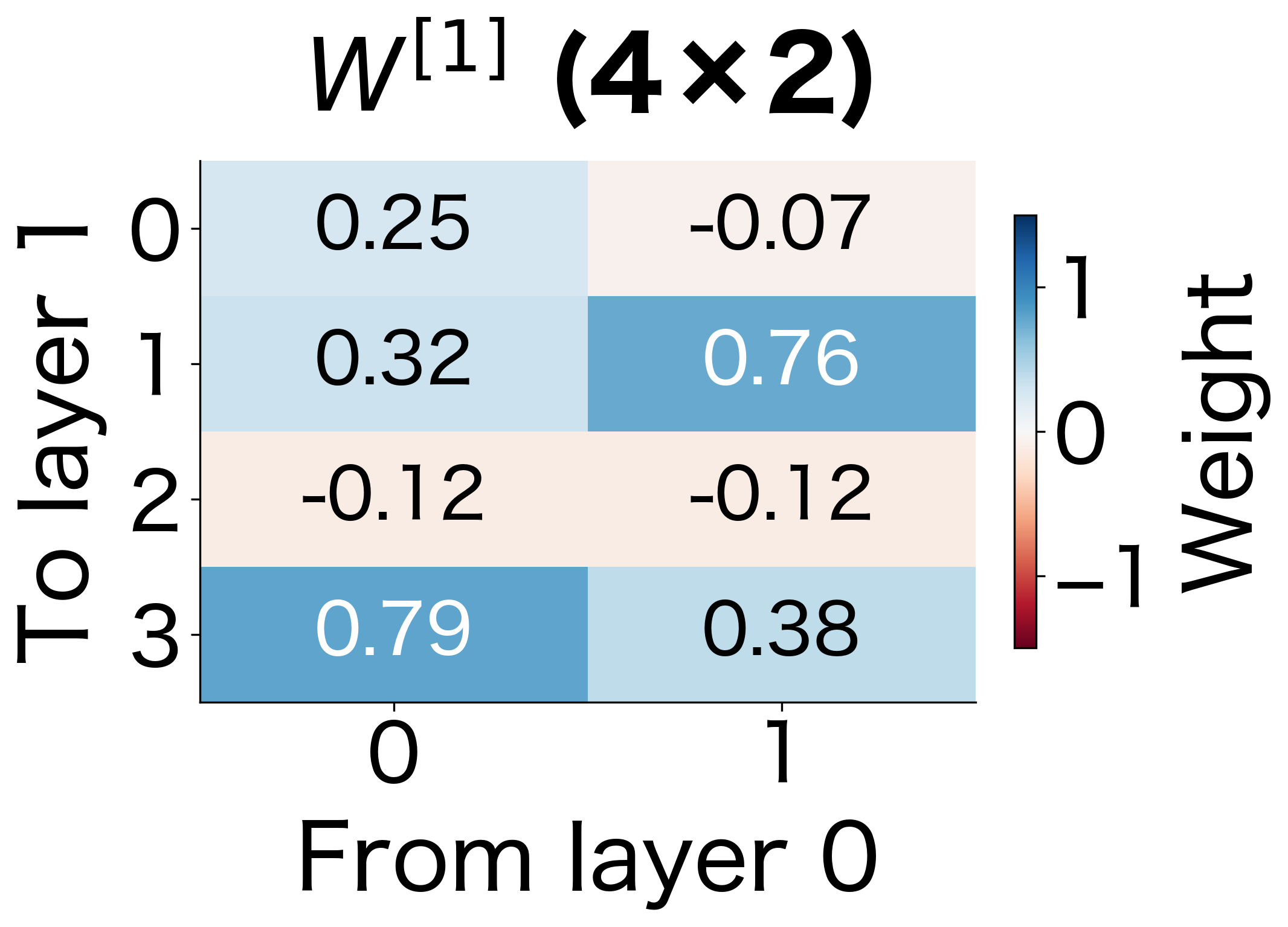
The weight matrix connects layer to layer . Each row of contains the weights for one neuron in layer . The element represents the weight connecting neuron in layer to neuron in layer .
This 3-layer network has a modest parameter count, but the numbers grow quickly. Let's visualize what these weight matrices actually look like:
![$W^{[2]}$: Weight matrix connecting first hidden (4 neurons) to second hidden layer (3 neurons).](https://cnassets.uk/notebooks/3_multilayer_perceptrons_files/output_5.png)
![$W^{[3]}$: Weight matrix connecting second hidden (3 neurons) to output layer (1 neuron).](https://cnassets.uk/notebooks/3_multilayer_perceptrons_files/output_6.png)
The weight matrices grow with the product of consecutive layer sizes. A layer connecting 512 neurons to 256 neurons requires parameters just for the weights, plus 256 bias terms. This rapid growth in parameters is why network architecture design requires careful consideration.
Forward Pass Computation
With our notation established, we can now understand how an MLP transforms an input into an output. This process, called the forward pass, is the heart of neural network computation. Think of it as a pipeline: data flows in one direction, from input through hidden layers to output, with each layer transforming the representation along the way.
The Two-Step Layer Computation
At each layer, the network performs two distinct operations that work together to create expressive transformations:
Step 1: Linear Transformation. First, we compute a weighted combination of inputs from the previous layer. This is where the learnable parameters (weights and biases) come into play:
The weight matrix determines how strongly each input neuron influences each output neuron. The bias vector shifts the output, allowing neurons to activate even when inputs are zero. Together, they define a linear transformation that can rotate, scale, and translate the input space.
Step 2: Non-linear Activation. Next, we apply an activation function element-wise to introduce non-linearity:
This step is crucial. Without activation functions, stacking multiple linear transformations would collapse into a single linear transformation, no matter how many layers we add. The activation function bends and warps the space, allowing the network to model complex, non-linear relationships.
The Complete Forward Pass
For a network with layers, the forward pass chains these two-step computations together. Starting with the input (which we treat as ), we propagate through each layer:
where:
- : the pre-activation vector at layer , the raw output of the linear transformation before any non-linearity is applied
- : the activation vector at layer , the output after applying the activation function, which becomes input to the next layer
- : the weight matrix connecting layer to layer , containing learnable parameters
- : the bias vector for layer , containing learnable parameters
- : the activation function applied element-wise (e.g., ReLU, sigmoid, tanh)
- : the network's final output, our prediction
Why This Architecture Works
The power of this layered structure comes from composition. Each layer learns to detect increasingly abstract features:
- Early layers learn simple patterns directly from the input (edges, basic shapes, common word fragments)
- Middle layers combine these simple patterns into more complex features (textures, object parts, phrases)
- Later layers assemble these features into high-level concepts (objects, categories, meanings)
The output layer typically uses a different activation than hidden layers, chosen based on the task. For binary classification, sigmoid squashes output to for probability interpretation. For multiclass classification, softmax produces a probability distribution across classes. For regression, we often use no activation (identity function) to allow unbounded predictions.
Implementing the Forward Pass
Let's translate these mathematical concepts into code. We'll build a forward pass function from scratch using NumPy to see exactly how the computation flows.
First, we define our activation functions. ReLU (Rectified Linear Unit) is the most common choice for hidden layers because it's simple, computationally efficient, and helps avoid the vanishing gradient problem. Sigmoid is useful for the output layer in binary classification, where we need probabilities between 0 and 1.
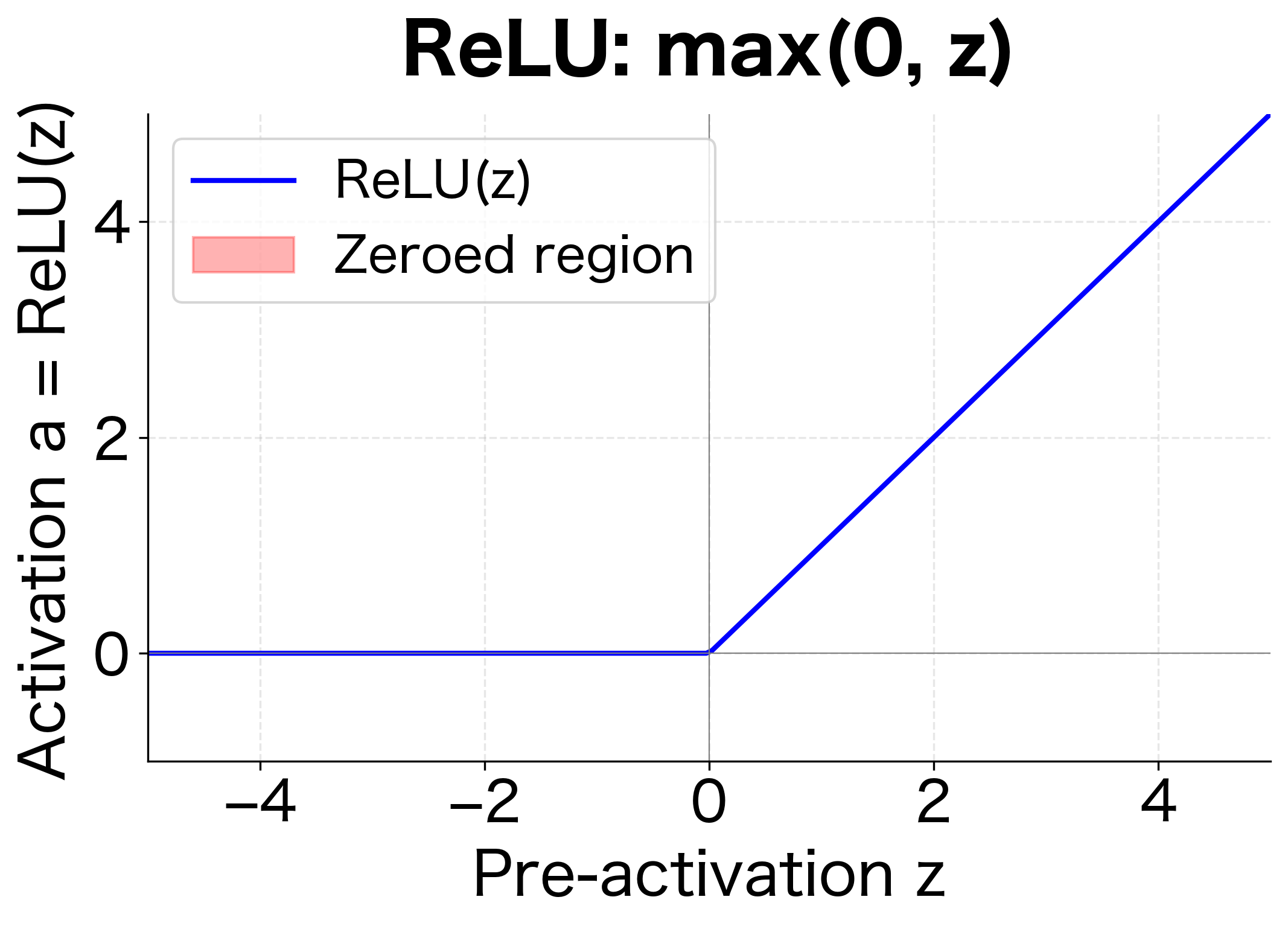
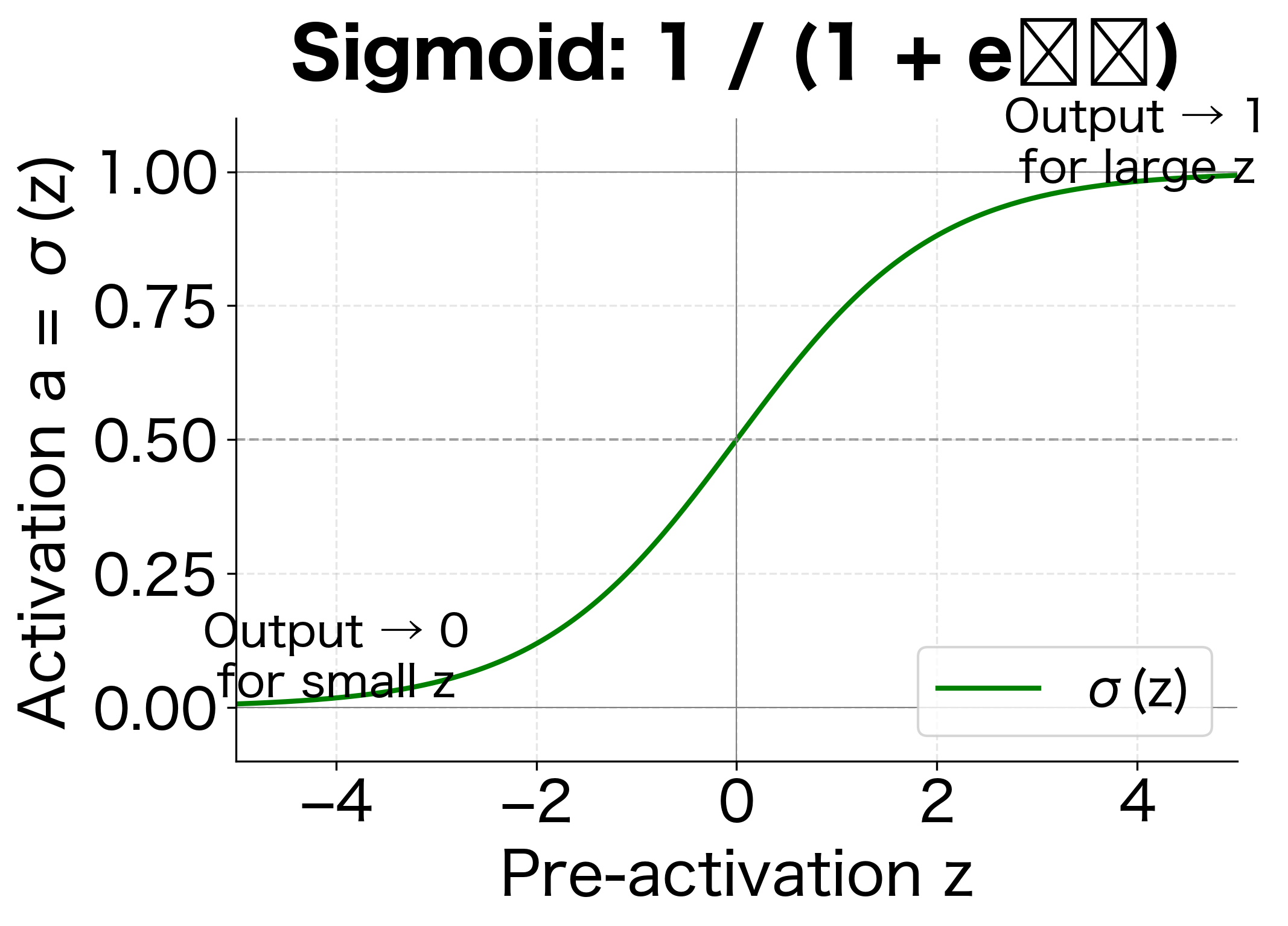
Now we implement the forward pass itself. The function iterates through each layer, applying the two-step computation we described: linear transformation followed by activation.
Tracing Through a Concrete Example
To solidify our understanding, let's trace through the forward pass with actual numbers. We'll use the 2-4-3-1 network we defined earlier and pass a single input through it.
The forward pass transforms our 2D input through three layers, ultimately producing a single scalar output. Several key observations emerge from this trace:
-
ReLU's effect on hidden layers: Notice how negative pre-activation values become zero after ReLU. This sparsity (many zeros) is actually beneficial, making the network more computationally efficient and helping prevent overfitting.
-
Dimensional changes: The representation changes size at each layer, from 2 dimensions (input) to 4, then 3, then finally 1 (output). The network progressively compresses information toward the final prediction.
-
Sigmoid's bounded output: The final layer's sigmoid activation squashes the output to a probability between 0 and 1, suitable for binary classification.
-
Composition creates complexity: Although each individual step is simple (matrix multiply, add bias, apply activation), the composition of many such steps creates a highly non-linear function capable of modeling complex patterns.
Batch Processing with Matrix Operations
The forward pass we implemented processes one example at a time, but this is inefficient in practice. Modern hardware, especially GPUs, is designed for parallel computation. By processing multiple examples simultaneously, we can achieve dramatic speedups.
The key insight is that we can stack multiple input vectors into a matrix, where each column represents one example. Instead of looping through examples one by one, we perform a single matrix multiplication that processes all examples at once.
For a batch of examples, the input becomes a matrix of shape , where each column represents one example. The forward pass equations generalize elegantly to matrix form:
where:
- : the activation matrix from the previous layer, with shape
- : the weight matrix with shape
- : the pre-activation matrix with shape
- : the bias vector with shape , broadcast across all columns
- : the batch size (number of examples processed simultaneously)
The matrix multiplication computes the linear transformation for all examples at once. The bias vector is broadcast (replicated) across all columns, adding the same bias to each example. The activation function is then applied element-wise to produce .
All five examples are processed in a single matrix operation, producing five outputs simultaneously. The varying output values reflect the different input features for each example. Batch processing is not just about efficiency. It also provides more stable gradient estimates during training, as we will see in the backpropagation chapter.
Representational Capacity and the Universal Approximation Theorem
One of the most remarkable properties of MLPs is their ability to approximate any continuous function. The Universal Approximation Theorem states that a feedforward network with a single hidden layer containing a finite number of neurons can approximate any continuous function on a compact subset of , given appropriate weights.
A neural network with one hidden layer of sufficient width can approximate any continuous function to arbitrary accuracy. This does not guarantee that gradient descent will find such an approximation, nor does it specify how many neurons are needed.
The theorem tells us that MLPs are expressive enough to represent complex functions. However, it says nothing about:
- How many neurons are needed (could be exponentially many)
- Whether training will find good weights
- How well the network will generalize to new data
In practice, we find that deeper networks (more layers) often work better than wider networks (more neurons per layer) for the same total number of parameters. Depth enables hierarchical feature learning, where early layers detect simple patterns and later layers combine them into complex concepts.
The shallow network actually has the most parameters despite having only one hidden layer. The deeper networks distribute their capacity across more layers with fewer neurons each. Let's visualize this trade-off:

This trade-off matters: deeper networks can represent more complex compositional functions. Think of it like building with LEGO: a few large blocks can cover area, but many small blocks arranged hierarchically can create intricate structures.
MLP for Classification
Classification is one of the most common tasks for MLPs. The network takes features as input and produces probabilities for each class. For binary classification, we use a single output neuron with sigmoid activation. For multiclass, we use multiple output neurons with softmax activation.
Binary Classification
In binary classification, the output represents the probability that the input belongs to class 1. We train the network by minimizing the binary cross-entropy loss, which measures how well the predicted probabilities match the true labels:
where:
- : the number of training examples in the batch
- : the true label for example (either 0 or 1)
- : the predicted probability that example belongs to class 1
- : the natural logarithm
This loss function has an intuitive interpretation. When the true label is , only the first term is active, which penalizes low predicted probabilities. When , only the second term is active, penalizing high predicted probabilities. The loss approaches zero when predictions are confident and correct, and grows large when predictions are wrong.
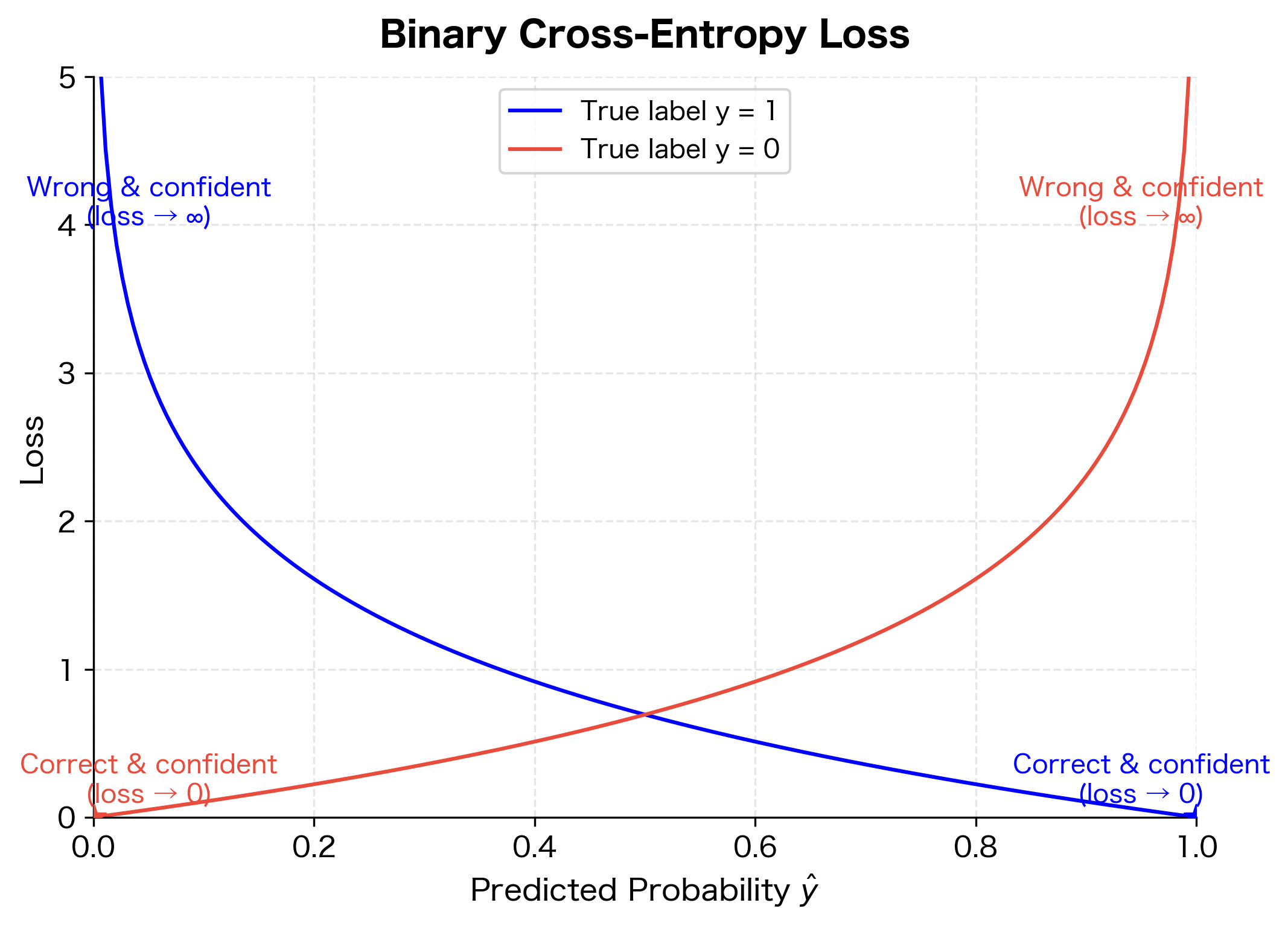
Let's build a complete binary classifier using PyTorch:
The model achieves strong test accuracy after 200 epochs of training. The significant reduction in loss from start to finish indicates successful learning. A test accuracy above 85% on the two moons dataset suggests the network has learned the non-linear decision boundary effectively.
Let's visualize the decision boundary learned by our classifier:
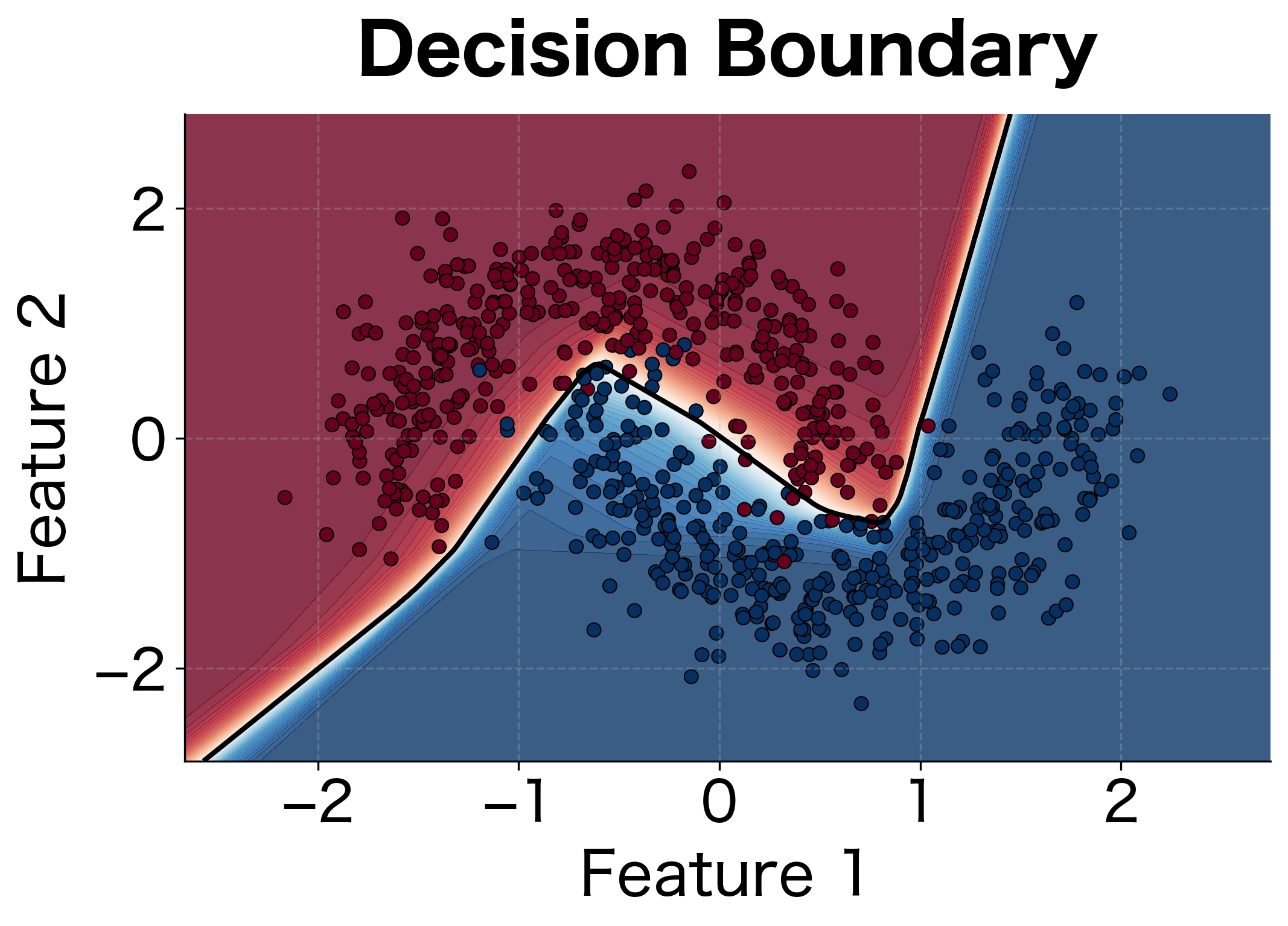
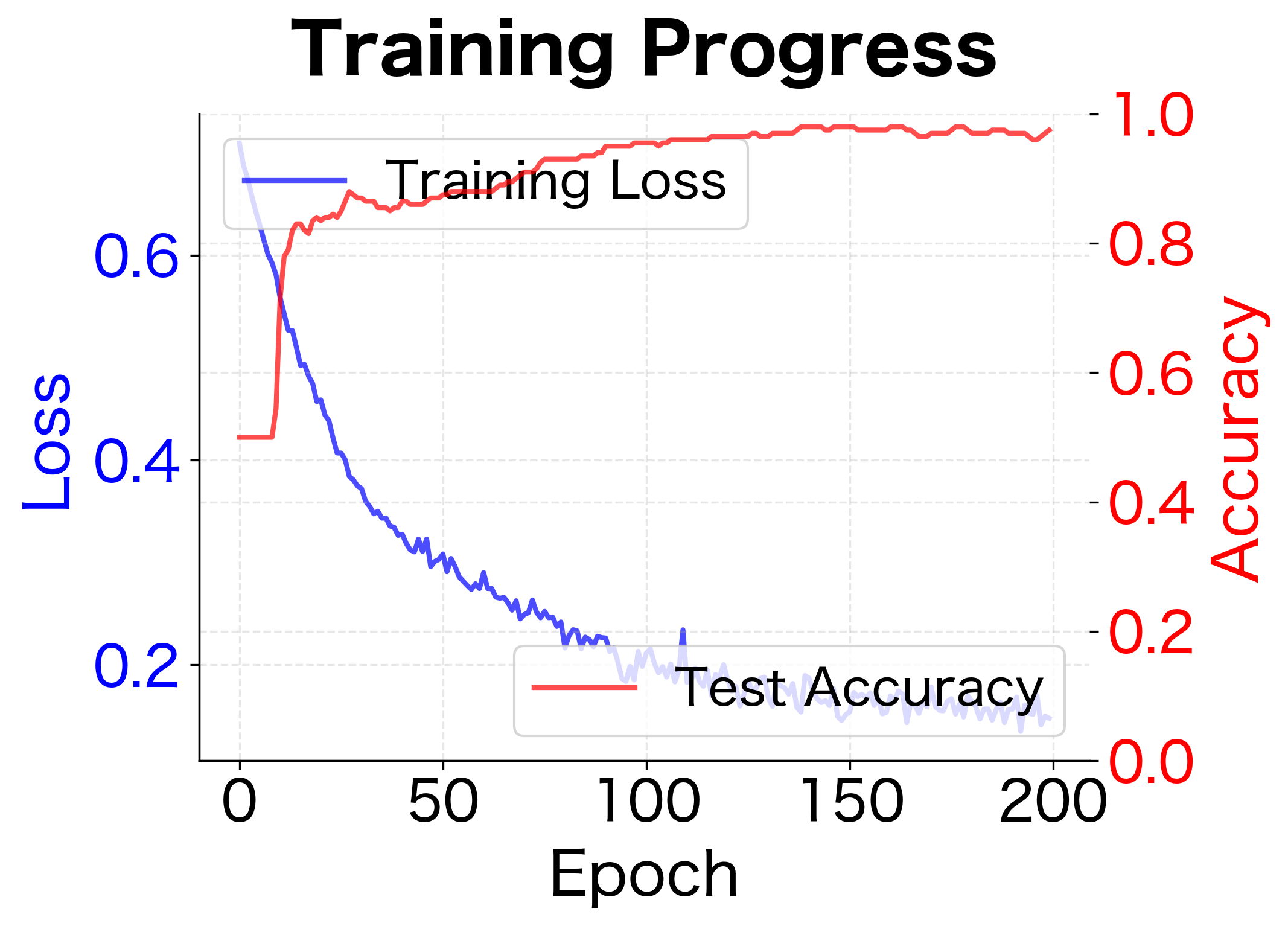
The MLP learns a curved decision boundary that cleanly separates the two moon-shaped clusters. A linear classifier would fail miserably on this task, but the hidden layer transforms the input into a representation where the classes become separable.
Multiclass Classification
For problems with more than two classes, we use softmax activation in the output layer. Softmax converts a vector of raw scores (called logits) into a probability distribution. Given an output vector from the final layer, softmax computes the probability for each class:
where:
- : the total number of classes
- : the logit (raw score) for class
- : the exponential of , which ensures all values become positive
- : the sum of exponentials across all classes, serving as a normalization constant
The exponential function amplifies differences between logits: if one class has a much higher score than others, it will dominate the probability distribution. The denominator ensures all probabilities sum to 1, creating a valid probability distribution where each output represents the predicted probability of the corresponding class.
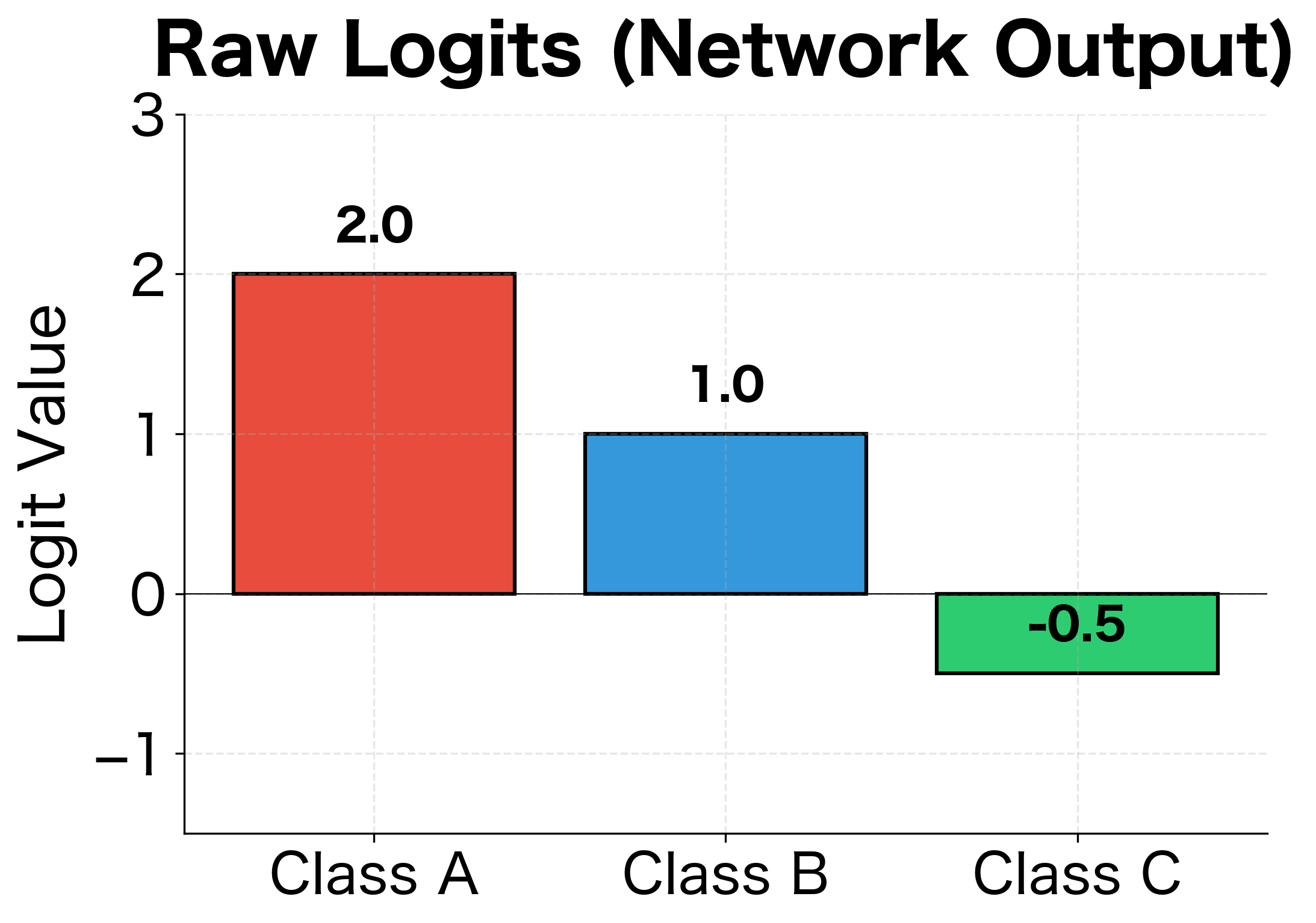
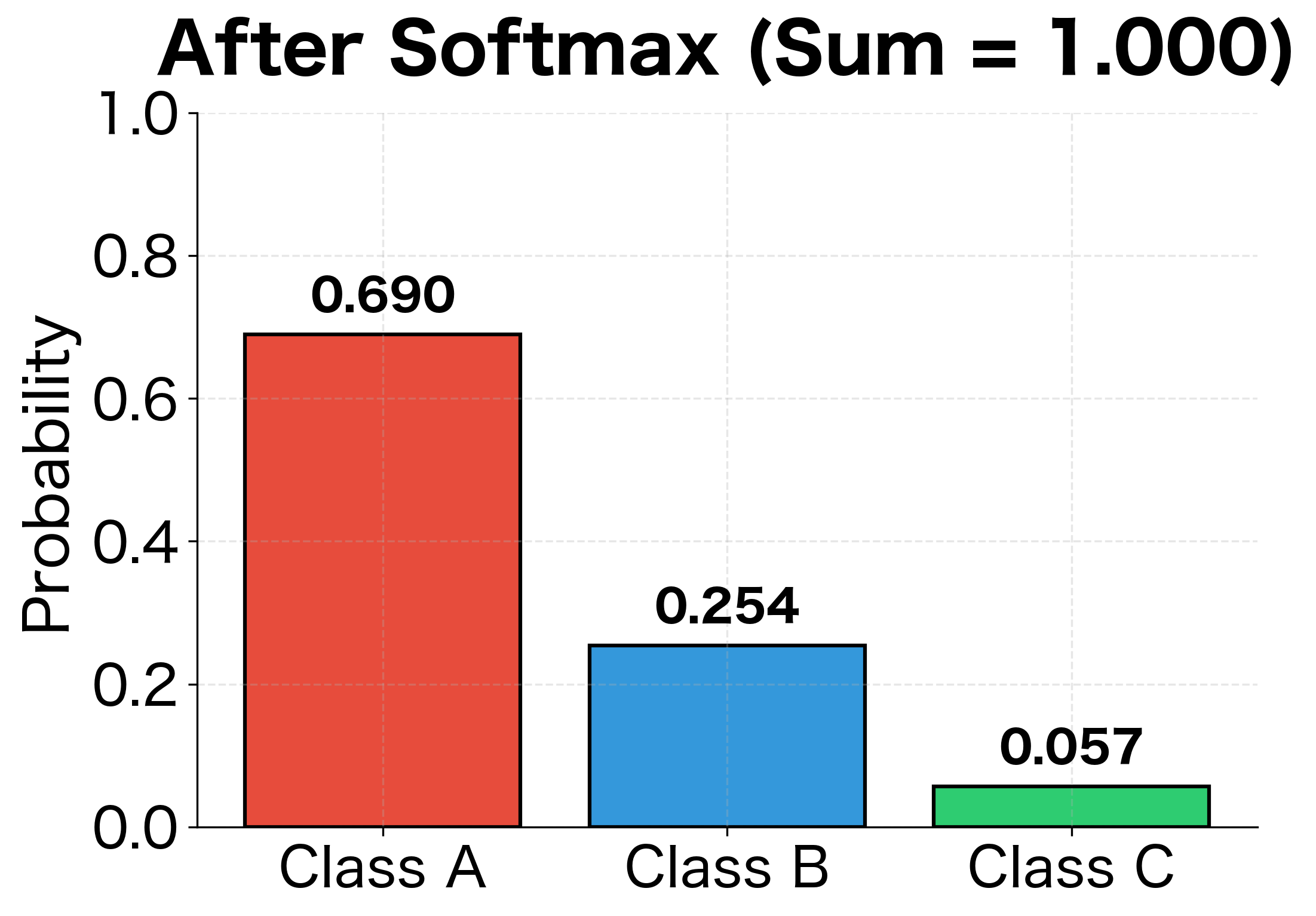
The multiclass model achieves high accuracy on the iris dataset, correctly classifying most test samples. Notice how the softmax outputs sum to 1.0 for each example, creating valid probability distributions. When the model is confident, one class dominates with probability close to 1.0 while others are near zero. The cross-entropy loss encourages this behavior by rewarding confident correct predictions and heavily penalizing confident incorrect ones.
MLP for Regression
Regression tasks require predicting continuous values rather than class labels. The key differences from classification are:
- No activation function on the output layer (identity function)
- Mean squared error (MSE) or mean absolute error (MAE) as the loss function
- Output layer has one neuron per target variable
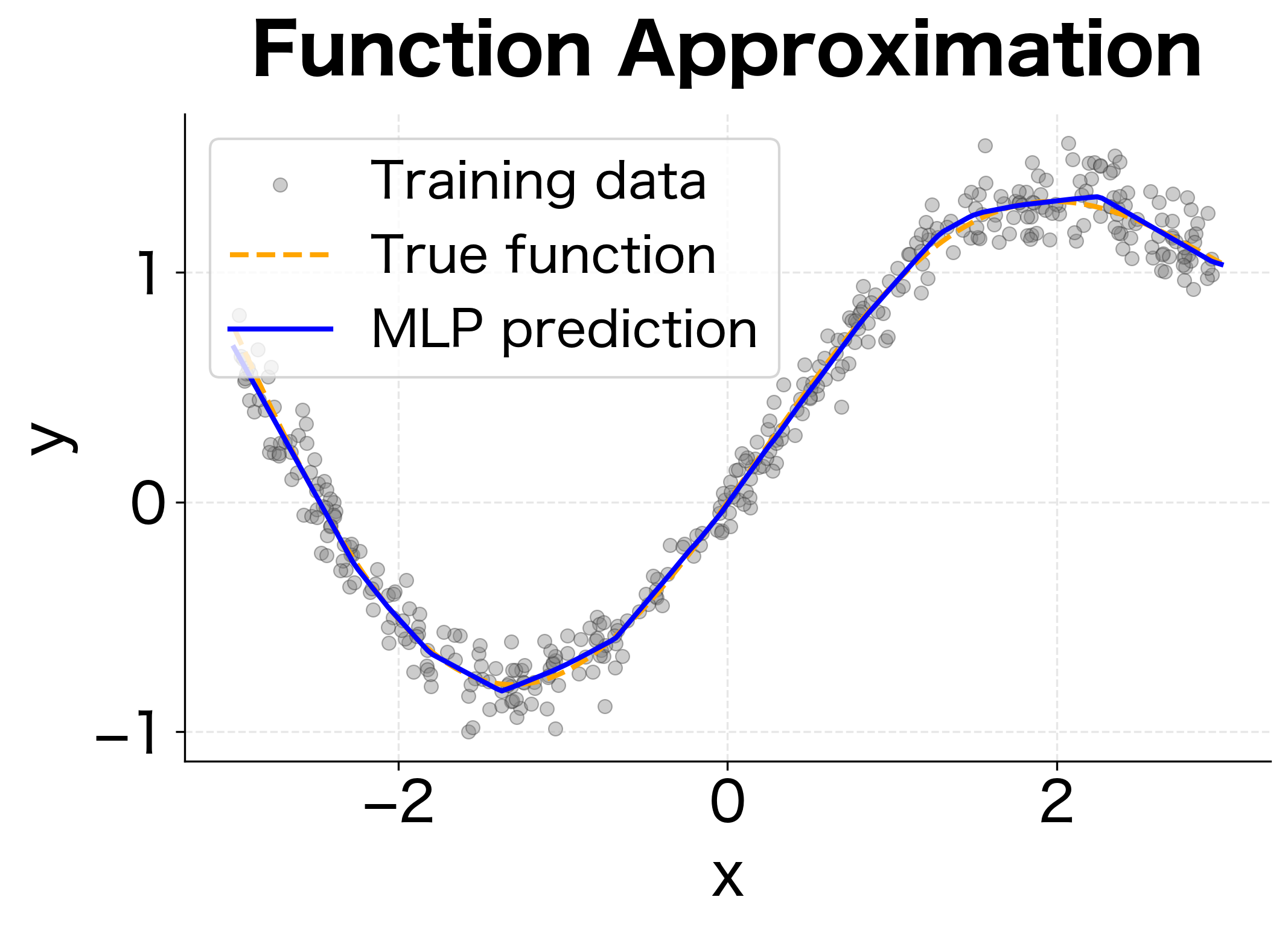
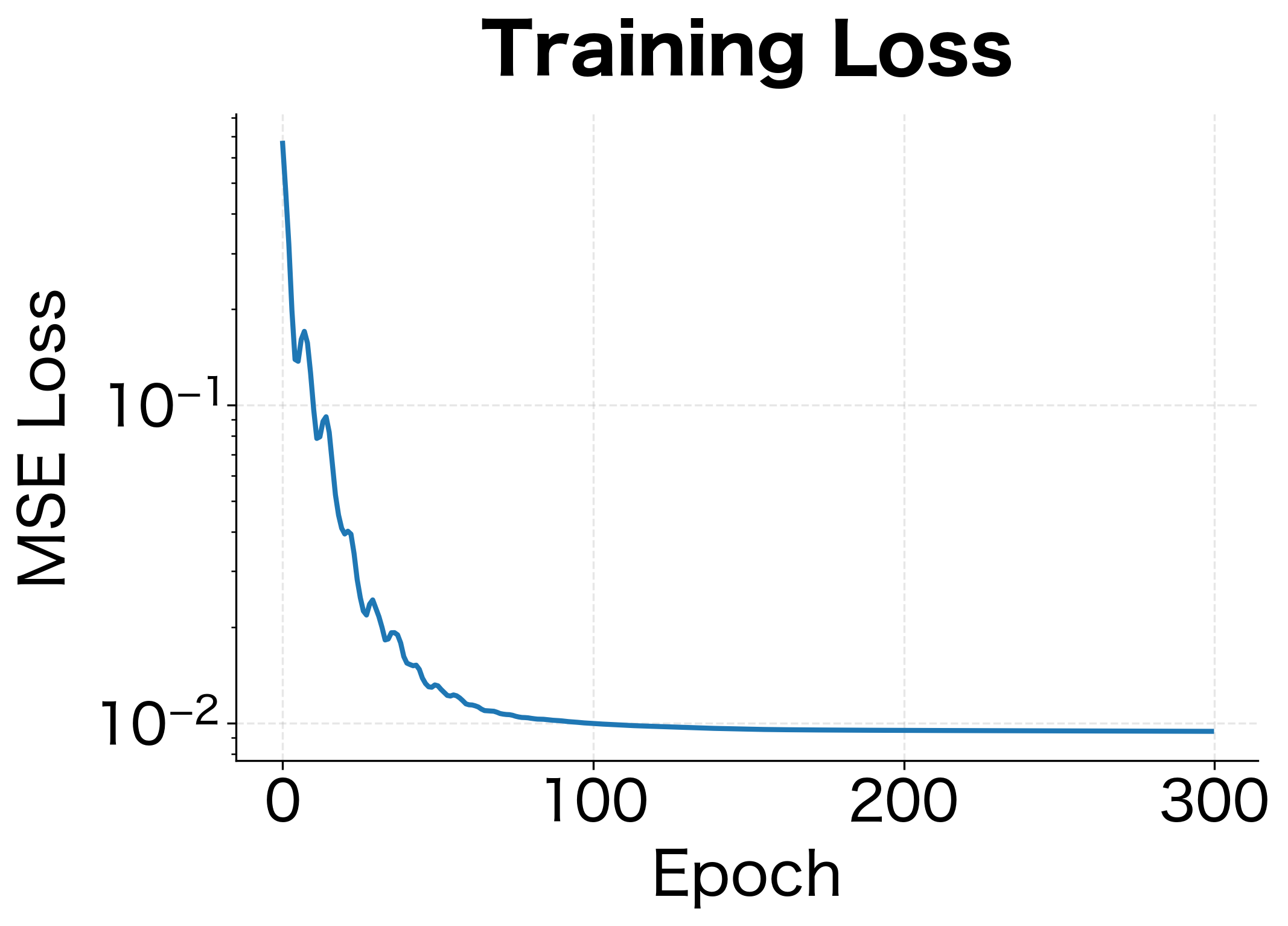
The low test MSE and RMSE indicate the model fits the underlying function well. The RMSE of around 0.1 means predictions are typically within 0.1 units of the true value on average, which matches the noise level we added to the data. The MLP learns to approximate the underlying non-linear function. Unlike polynomial regression where you must choose the degree, the MLP automatically discovers the appropriate level of complexity through its hidden representations.
Architecture Design Guidelines
Designing an MLP architecture involves choosing the number of layers, neurons per layer, activation functions, and regularization techniques. While there is no universal formula, several principles guide these decisions.
Depth vs. Width
Deeper networks can represent more complex hierarchical features. However, they are harder to train due to vanishing or exploding gradients. Wider networks have more parameters per layer but may struggle to learn compositional patterns.
As a starting point:
- For simple problems, 1-2 hidden layers often suffice
- For complex patterns, 3-5 hidden layers may be needed
- Very deep networks (10+ layers) typically require residual connections
Layer Sizes
Common patterns for hidden layer sizes include:
- Funnel: Decreasing sizes (e.g., 256-128-64) that progressively compress information
- Constant: Same size throughout (e.g., 128-128-128) for uniform capacity
- Bottleneck: Narrow middle layer (e.g., 256-32-256) to force compressed representations
The input and output sizes are determined by your problem. Hidden sizes are hyperparameters to tune.
Activation Functions
ReLU is the default choice for hidden layers due to its simplicity and effectiveness. Alternatives like Leaky ReLU or GELU can help in specific situations:
- ReLU: Fast, simple, works well in most cases
- Leaky ReLU/PReLU: Addresses dying ReLU problem
- GELU: Smooth approximation, popular in transformers
- Tanh/Sigmoid: Rarely used in hidden layers now due to saturation
For output layers:
- Sigmoid: Binary classification (outputs probability)
- Softmax: Multiclass classification (outputs probability distribution)
- Identity (none): Regression (outputs unbounded values)
Regularization
To prevent overfitting, we use regularization techniques:
- Dropout: Randomly zeros neurons during training (typical rates: 0.2-0.5)
- Weight decay: L2 penalty on weights (typical values: 1e-4 to 1e-2)
- Batch normalization: Normalizes layer inputs, also acts as regularizer
This architecture applies batch normalization after each linear layer, followed by ReLU activation and dropout. The pattern Linear BatchNorm ReLU Dropout repeats for each hidden layer, providing a consistent structure that's easy to extend. The funnel shape (256 128 64) progressively compresses the representation, forcing the network to distill the most important features as information flows toward the output.
Limitations and Impact
Despite their power, MLPs have significant limitations that motivated the development of more specialized architectures.
The most fundamental limitation is their treatment of input as a flat vector. When processing images, MLPs ignore spatial structure, treating each pixel as an independent feature. A small shift in the image produces a completely different input vector, yet the semantic content remains the same. This lack of translation invariance means MLPs need to learn the same pattern multiple times for different positions. Convolutional neural networks address this by sharing weights across spatial locations.
Similarly, for sequential data like text, MLPs treat each position independently. The sentence "The cat sat on the mat" becomes a fixed-size vector where position 1 and position 5 have no structural relationship. This makes learning long-range dependencies extremely difficult. The meaning of "it" in "The trophy doesn't fit in the suitcase because it is too big" depends on understanding the full context, something MLPs struggle with. Recurrent networks and transformers were developed specifically to handle sequential dependencies.
MLPs also struggle with variable-length inputs. Every MLP has a fixed input size determined at architecture design time. Processing sentences of different lengths requires padding to a maximum length or using techniques like bag-of-words that lose positional information entirely. This rigidity limits their applicability to many real-world problems.
Despite these limitations, MLPs remain foundational. The feed-forward layers within transformers are MLPs. The classification heads on top of pre-trained language models are MLPs. Understanding how information flows through layers, how weights connect neurons, and how activations transform representations is essential knowledge for working with any modern neural architecture.
The representational power of MLPs demonstrated that neural networks could, in principle, learn complex functions. The universal approximation theorem provided theoretical justification. The practical challenge became not representation but optimization: finding the right weights among billions of possibilities. The techniques developed to train MLPs (gradient descent, backpropagation, and regularization) form the foundation of all deep learning.
Summary
Multilayer perceptrons extend single neurons into networks capable of learning complex, non-linear functions. By stacking layers with non-linear activations, MLPs can approximate virtually any function, a property formalized in the universal approximation theorem.
Key takeaways from this chapter:
- Hidden layers transform inputs into new representations where patterns become easier to detect
- Weight matrices connect layers, with shape for the matrix connecting layer to layer
- Forward pass propagates information through linear transformations and activations:
- Batch processing uses matrix operations for efficiency, stacking examples as columns
- Classification uses sigmoid (binary) or softmax (multiclass) output activations with cross-entropy loss
- Regression uses identity (no) output activation with MSE loss
- Architecture design involves balancing depth, width, activation functions, and regularization
The next chapter explores loss functions in detail, examining how different choices affect learning and what happens when we optimize various objectives. Understanding loss functions is crucial because they define what "good" means for our network.
Key Parameters
When building MLPs in PyTorch, several parameters significantly impact model performance:
Architecture Parameters:
hidden_sizes: List of neurons per hidden layer (e.g.,[256, 128, 64]). Larger sizes increase capacity but also parameter count and risk of overfitting. Start with powers of 2 for computational efficiency.input_size: Number of input features, determined by your data.num_classes/output_size: Number of output neurons. Use 1 for binary classification or regression, for -class classification.
Regularization Parameters:
dropout_rate: Probability of zeroing neurons during training (typically 0.1-0.5). Higher values provide stronger regularization but may slow convergence. Use 0.2-0.3 as a starting point.weight_decay: L2 regularization strength in the optimizer (typically 1e-4 to 1e-2). Penalizes large weights to reduce overfitting.
Training Parameters:
lr(learning rate): Step size for gradient updates (typically 1e-4 to 1e-1). Too high causes instability; too low causes slow convergence. Adam optimizer often works well with lr=0.001.epochs: Number of complete passes through the training data. Monitor validation loss to avoid overfitting.batch_size: Number of examples per gradient update (typically 32-256). Larger batches provide more stable gradients but require more memory.
Activation Choices:
- Hidden layers: ReLU is the default choice. Consider Leaky ReLU if many neurons "die" (output constant zero).
- Output layer: Sigmoid for binary classification, Softmax (via CrossEntropyLoss) for multiclass, Identity (none) for regression.
Loss Functions:
nn.BCELoss(): Binary cross-entropy for binary classification with sigmoid output.nn.CrossEntropyLoss(): Combines softmax and negative log-likelihood for multiclass classification. Expects raw logits, not probabilities.nn.MSELoss(): Mean squared error for regression tasks.
Quiz
Ready to test your understanding of multilayer perceptrons? Take this quick quiz to reinforce what you've learned about hidden layers, forward pass computation, and network architecture.

Comments