

Master probabilistic tokenization with unigram language models. Learn how SentencePiece uses EM algorithms and Viterbi decoding to create linguistically meaningful subword units, outperforming deterministic methods like BPE.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Unigram Language Model Tokenization
Introduction
Subword tokenization methods like Byte Pair Encoding (BPE) work by greedily merging the most frequent character pairs. But what if we could make smarter decisions about which merges to perform? The Unigram Language Model approach treats tokenization as a probabilistic optimization problem, asking: "What's the most likely way to segment this text into tokens?"
At its core, unigram LM tokenization trains a language model on subword units and uses it to find the tokenization that maximizes the probability of the text. This approach, popularized by the SentencePiece library, offers several advantages over deterministic methods like BPE.
Rather than applying fixed merge rules, unigram tokenization learns a vocabulary of subword units where each unit has an associated probability. During tokenization, the algorithm searches for the segmentation that gives the highest total probability under this model.
Technical Deep Dive
This section covers the mathematical foundations of unigram tokenization, including the probabilistic model formulation, the EM algorithm for training, and the Viterbi algorithm for finding optimal segmentations.
Unigram Language Model Formulation
A unigram language model assigns probabilities to individual tokens independently. The probability of one token doesn't depend on what tokens came before or after it. This independence assumption makes the model computationally tractable while still capturing which subword units are common in the language.
For tokenization, we want to segment text into a sequence of subword tokens that maximizes the joint probability. Because tokens are treated as independent under the unigram assumption, the joint probability of a segmentation is simply the product of the individual token probabilities:
where:
- : the probability of the entire text under this particular segmentation
- : the number of tokens in the segmentation (different segmentations may have different values of )
- : the -th subword token in the sequence
- : the probability of the -th token, learned from the training corpus
- : the product operator, multiplying together all token probabilities
The key insight is that we have a vocabulary of learned subword units, each with an associated probability. We can represent any word as a sequence of subword tokens from . For example, the word "tokenization" might be segmented as ["token", "ization"] or ["tok", "en", "ization"], and we want to choose the segmentation with the highest probability.
Why does this product formula make sense? Intuitively, if we segment a word into common, frequently-occurring subwords, each will be relatively high, giving a high overall probability. If we use rare or arbitrary character sequences, those tokens will have low probabilities, dragging down the product.
To illustrate this concept, let's visualize different possible segmentations of the word "tokenization" with their associated probabilities. The unigram model learns that certain subword units like "token" and "ization" are more probable than arbitrary splits.
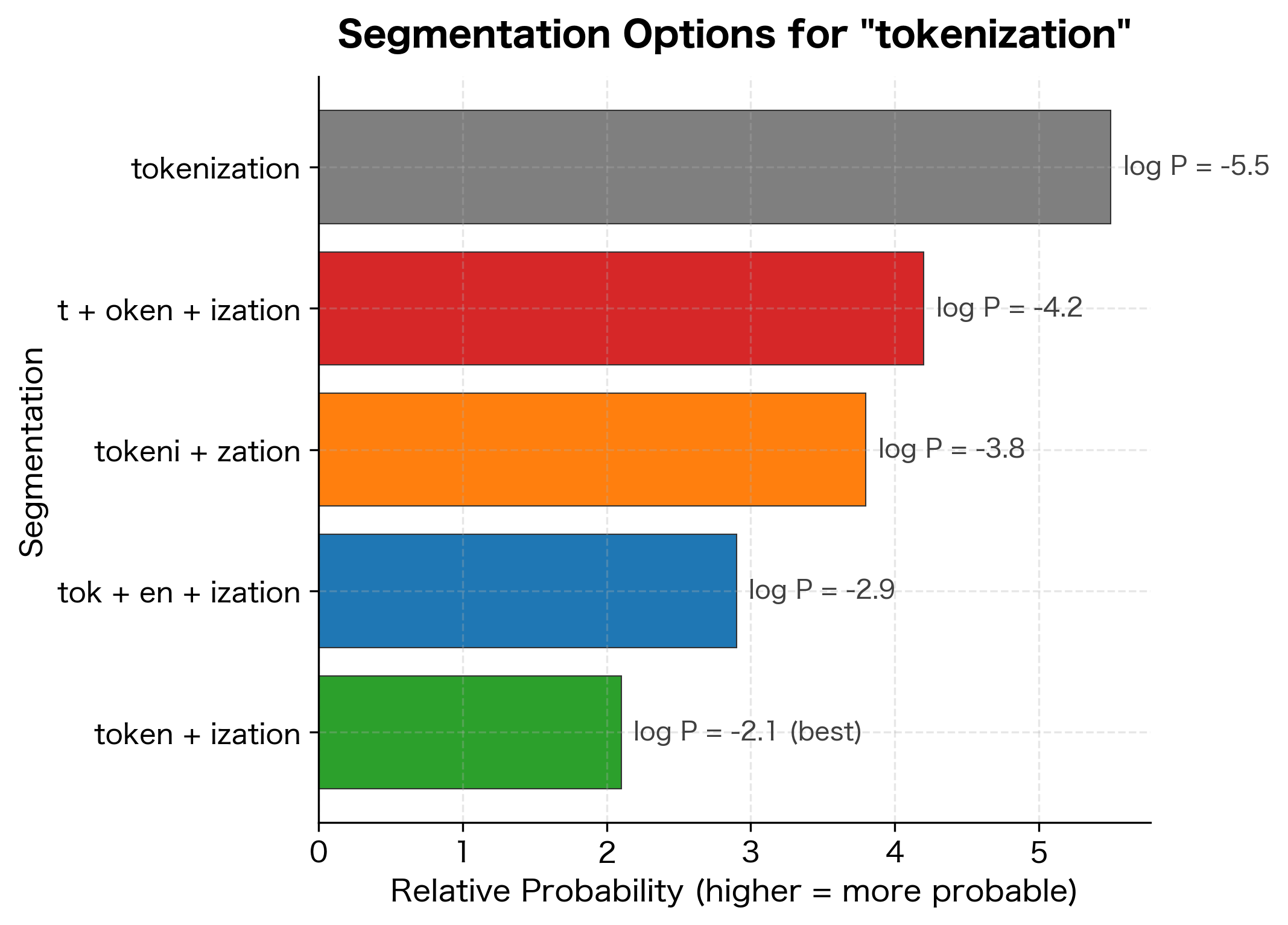
This visualization shows how the unigram model evaluates different ways to split a word. The most probable segmentation combines meaningful subword units ("token" + "ization") that frequently appear in the training corpus. Less natural splits receive lower probabilities, guiding the model toward linguistically sensible token boundaries.
The EM Algorithm for Training
Training a unigram language model for tokenization uses an Expectation-Maximization (EM) algorithm, adapted specifically for the tokenization task. Unlike standard language model training, the EM algorithm here must consider all possible ways to segment each word in the corpus. We start with a large initial vocabulary (typically all possible substrings up to a maximum length) and iteratively refine both the vocabulary and the token probabilities.
E-Step: Compute Tokenization Probabilities
For each word in our training corpus, we compute the probability of all possible ways to segment it using the current vocabulary. This gives us the expected count of each subword token across all possible segmentations.
M-Step: Update Probabilities
Once we have the expected counts from the E-step, we update the probability of each token to be proportional to how often it's expected to appear. This is the standard maximum likelihood estimate for a unigram model:
where:
- : the updated probability for a specific token in the vocabulary
- : the expected frequency of this token, computed by summing its contribution across all possible segmentations of all words in the training corpus (weighted by each segmentation's probability)
- : the current vocabulary of subword units
- : a dummy variable iterating over all tokens in the vocabulary
- : the sum of expected counts across the entire vocabulary, which serves as a normalizing constant to ensure all probabilities sum to 1
This formula is essentially a frequency-based probability estimate: tokens that appear more frequently (across all likely segmentations) receive higher probabilities. The denominator ensures that the probabilities form a valid distribution.
The algorithm also includes a vocabulary pruning step that removes low-probability tokens to keep the vocabulary size manageable. Tokens whose probability falls below a threshold are removed, focusing the model on the most useful subword units.
To illustrate the EM algorithm's learning process, let's visualize how token probabilities evolve over iterations. The algorithm starts with uniform probabilities and gradually learns which subword units are more frequent in the corpus.
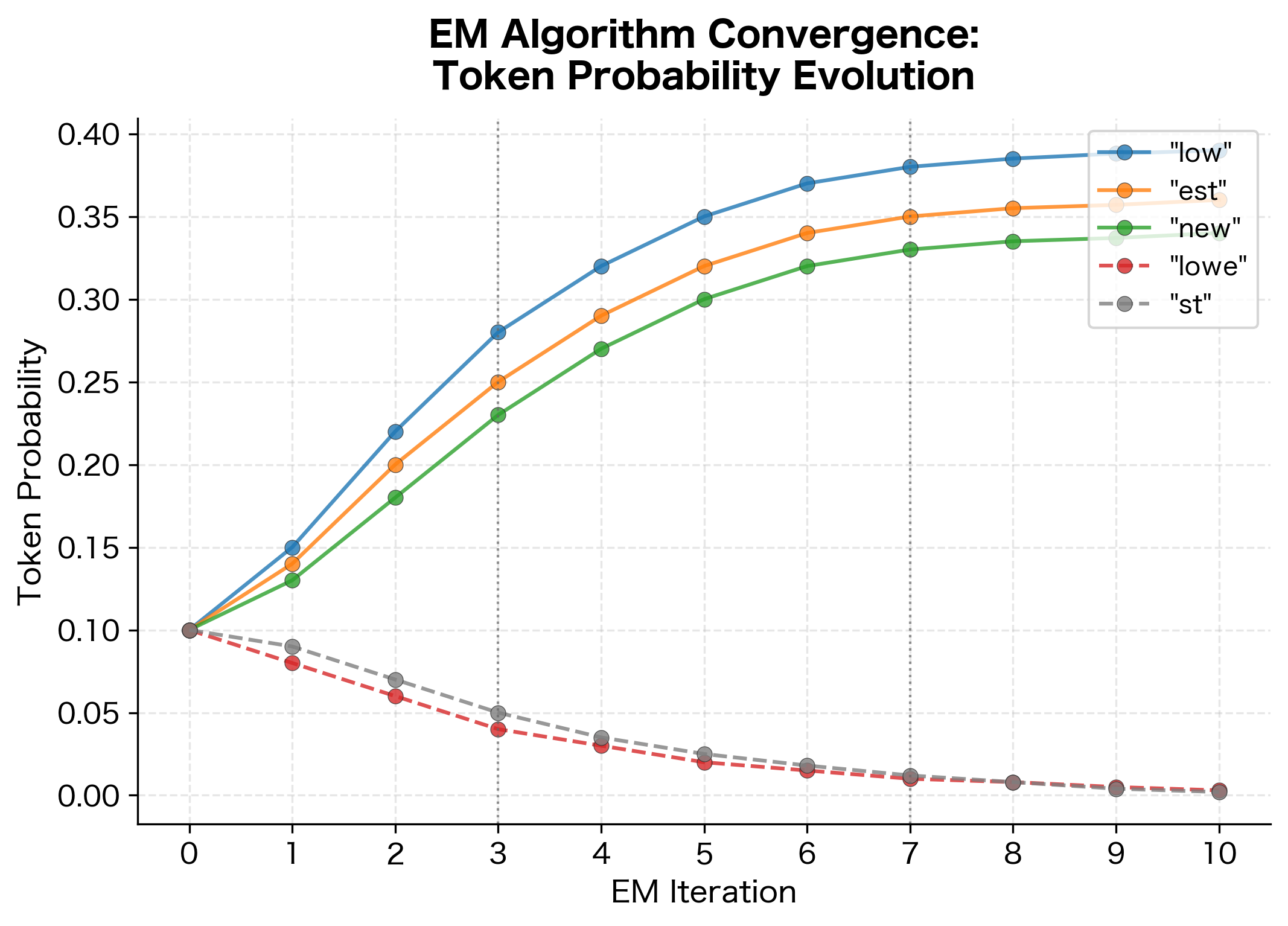
This visualization demonstrates the EM algorithm's learning dynamics. Initially, all tokens have equal probability. Over iterations, meaningful subword units that frequently appear in the corpus ("low", "est", "new") gain probability, while less useful or nonexistent tokens are gradually pruned away. The algorithm converges when the token probabilities stabilize, resulting in a vocabulary optimized for the corpus's subword patterns.
Unigram models treat tokens as independent, while n-gram models consider dependencies between consecutive tokens. For tokenization, the unigram assumption works well because we're primarily concerned with which subword units are meaningful, not their sequential dependencies within a word.
Viterbi Decoding for Tokenization
Once we have our trained unigram model, tokenization becomes a search problem: find the segmentation of the input text that gives the highest probability. A naive approach would enumerate all possible ways to split the word into tokens, but this grows exponentially with word length. Instead, we use the Viterbi algorithm, a dynamic programming approach that efficiently finds the optimal segmentation.
The key insight of Viterbi is that the best segmentation ending at any position can be computed from the best segmentations ending at earlier positions. We only need to track the single best path to each position, not all possible paths.
For a word of length , we want to find positions that define the token boundaries. These positions split the word into tokens, and we want the split that maximizes the product of token probabilities:
where:
- : the input word to tokenize (a string of characters)
- : the length of the word in characters
- : the number of tokens in this particular segmentation (unknown in advance, so we search over all valid values)
- : token boundary positions, where (start of word) and (end of word)
- : the substring of from character position (inclusive) to (exclusive), representing the -th token
- : the probability of this substring as a token, looked up from our trained vocabulary
- : the product of all token probabilities
The Viterbi algorithm efficiently finds the most probable segmentation by using dynamic programming: for each position in the word, it computes the highest-probability segmentation of the substring . This is done by considering all possible last tokens ending at position and taking the one that gives the best total probability. Because we only need to track the single best path to each position (not all paths), the algorithm runs in time rather than exponential time.
Sampling Multiple Segmentations
While Viterbi gives us the single best segmentation, we might want to sample from the distribution of possible segmentations. This is useful for data augmentation and creating more robust models.
The sampling algorithm works by:
- Computing all possible token boundaries at each position
- Sampling tokens according to their probabilities
- Building a complete segmentation by sampling sequentially
This approach can generate multiple valid tokenizations for the same text, which helps models learn more robust representations.
Subword Regularization
Subword regularization is a technique that randomly samples different tokenizations during training. Instead of always using the same segmentation, we sometimes use alternative segmentations that have lower but still reasonable probabilities.
This regularization helps models become more robust to different tokenization choices and improves generalization, especially for morphologically rich languages.
A Worked Example
Let's work through a detailed example to understand how unigram tokenization processes text. This will show how the algorithm learns from data and makes tokenization decisions.
Suppose we have a small training corpus:
low lower lowest new newest newest
This corpus contains morphological patterns we want the model to learn: "low" appears in "low", "lower", and "lowest"; "est" appears in "lowest" and "newest"; "new" appears in "new" and "newest".
Step 1: Initial Vocabulary Construction
We start with all possible substrings up to a maximum length (typically 4-6 characters for efficiency). For our corpus, this includes:
- Character-level tokens: "l", "o", "w", "e", "s", "t", "n", "r"
- Bigram tokens: "lo", "ow", "we", "es", "st", "ne", "ew", "er"
- Trigram tokens: "low", "owe", "wer", "est", "new", "wes"
- Longer tokens: "lower", "lowest", "newest"
Step 2: EM Training Process
The EM algorithm iteratively refines token probabilities:
E-Step: For each word, compute the probability of all possible segmentations using current token probabilities. For "lowest":
- ["low", "est"]: P(low) × P(est) = high probability
- ["lowe", "st"]: P(lowe) × P(st) = medium probability
- ["l", "o", "w", "e", "s", "t"]: product of 6 character probabilities = low probability
M-Step: Update token probabilities based on expected frequencies across all segmentations in the corpus.
After several iterations, tokens that appear frequently get higher probabilities:
- "low": appears in "low", "lower", "lowest" → high probability
- "est": appears in "lowest", "newest" → high probability
- "new": appears in "new", "newest" → high probability
- Rare tokens like "lowest" (appears only once) → lower probability
Step 3: Tokenization of New Text
When tokenizing "lowest" using the trained model, the Viterbi algorithm evaluates possible segmentations:
| Segmentation | Token Sequence | Probability | Calculation |
|---|---|---|---|
| Best | ["low", "est"] | High | P(low) × P(est) |
| Alternative | ["lowe", "st"] | Medium | P(lowe) × P(st) |
| Worst | ["l", "o", "w", "e", "s", "t"] | Low | P(l) × P(o) × P(w) × P(e) × P(s) × P(t) |
The algorithm chooses ["low", "est"] because it maximizes the joint probability while using the fewest, most meaningful tokens.
This example demonstrates the core principles: unigram tokenization learns which subword units are most probable from the training data, then uses dynamic programming to find optimal segmentations. The probabilistic approach allows for more linguistically sensible token boundaries compared to rule-based methods.
Code Implementation
Now let's see these concepts in action using SentencePiece, a practical implementation of unigram tokenization. The following code demonstrates the complete pipeline from corpus preparation to tokenization.
Training a Unigram Model
First, we'll create a small training corpus and train an unigram tokenizer using SentencePiece. The corpus contains words with shared morphological patterns that the model should learn to recognize.
Examining the Learned Vocabulary
After training, we can inspect the vocabulary to see what subword units the model learned and their associated log probabilities. Higher values (less negative) indicate more frequent tokens.
The vocabulary contains special tokens (<unk>, </s>, <s>) with score 0, followed by learned subword units. Tokens like "low", "est", and "new" have higher (less negative) scores because they appear frequently in the training corpus. The ▁ symbol represents a space/word boundary in SentencePiece's encoding.
Tokenizing Text
Now let's tokenize some test words to see how the model segments them. The model uses Viterbi decoding to find the highest-probability segmentation for each word.
For "lowest" and "newest", the model identifies meaningful subword units that appear frequently in the training corpus. The segmentation into ["▁low", "est"] and ["▁new", "est"] reflects the shared morphological pattern in the training data. The word "unknownword" contains no familiar patterns from training, so the model falls back to character-level tokenization, resulting in many low-probability tokens and a much lower total log-probability.
Comparing Segmentation Probabilities
Let's examine how the model compares different possible segmentations of the same word by looking at their total log probabilities.
The optimal segmentation has a substantially higher log probability than the character-level alternative. This demonstrates the core principle of unigram tokenization: by learning which subword units are common, the model prefers segmentations that use fewer, more meaningful tokens over arbitrary character sequences.
Key Parameters
The key parameters for SentencePiece unigram training are:
- vocab_size: Controls the final vocabulary size after training. Larger vocabularies capture more subword patterns but increase memory usage and may lead to overfitting on rare tokens. Typical values range from 8K-32K for modern models, with 32K being common for multilingual models.
- model_type: Specifies the tokenization algorithm. Use
'unigram'for probabilistic unigram LM tokenization or'bpe'for byte pair encoding. Unigram is generally preferred for its ability to sample multiple tokenizations. - character_coverage: Determines what fraction of characters from the training corpus to include in the vocabulary (0.0-1.0). Use 1.0 for English and other Latin-script languages. For languages with large character sets (Chinese, Japanese), values around 0.9995 are common to exclude extremely rare characters.
- unk_piece: The token used for unknown characters or subwords not in the vocabulary. Set this to a distinctive string like
'<unk>'to easily identify out-of-vocabulary inputs in downstream processing.
To illustrate the difference between Unigram LM and BPE tokenization, let's compare how they segment the same text. Unigram LM makes probabilistic decisions based on learned token frequencies, while BPE follows deterministic merge rules.
| Word | Unigram LM | BPE | Difference |
|---|---|---|---|
| tokenization | token + ization | token + ization | Same |
| is | is | is | Same |
| essential | ess + ential | ess + ential | Same |
| for | for | for | Same |
| natural | natural | nat + ural | Unigram keeps morpheme |
| language | language | lang + uage | Unigram keeps morpheme |
| processing | process + ing | proc + ess + ing | Unigram uses fewer tokens |
This comparison highlights key differences between the approaches. Unigram LM assigns probabilities to each token based on corpus statistics, enabling more nuanced decisions. BPE follows deterministic merge rules and may create less linguistically meaningful segments. The probabilistic nature of Unigram LM allows for better handling of morphological variations and out-of-vocabulary words.
Limitations & Impact
Unigram tokenization offers probabilistic segmentation but comes with trade-offs. The EM training can be computationally expensive for large vocabularies, though SentencePiece optimizes this well. The independence assumption ignores token co-occurrence patterns that could inform better segmentation.
SentencePiece's unigram mode powers tokenization in models like T5, mBART, and many multilingual systems. By learning from actual text rather than applying heuristic rules, unigram tokenization handles diverse languages and domains more robustly than BPE.
The probabilistic approach also enables advanced features like subword regularization, which has improved the robustness of large language models. While BPE remains popular for its simplicity, unigram tokenization offers a more principled approach to the tokenization problem.
Summary
Unigram language model tokenization represents a significant advancement in subword tokenization by treating segmentation as a probabilistic optimization problem. Instead of applying fixed merge rules like BPE, this approach learns a probability distribution over subword units and uses dynamic programming to find the most likely segmentation.
The method combines several sophisticated techniques: an EM algorithm adapted for tokenization that considers all possible word segmentations, Viterbi decoding for efficient segmentation finding, and optional subword regularization for improved robustness. While more computationally intensive than deterministic approaches, unigram tokenization provides superior handling of morphological variation, out-of-vocabulary words, and multilingual text.
This probabilistic framework underlies many modern tokenization systems and demonstrates how statistical learning can produce more linguistically informed text segmentation than rule-based methods.
Quiz
Ready to test your understanding of unigram language model tokenization? This quiz covers the probabilistic approach to subword segmentation, EM training, and practical implementation.

Comments