

Learn POS tagging from tag sets to statistical taggers. Covers Penn Treebank, Universal Dependencies, emission and transition probabilities, and practical implementation with NLTK and spaCy.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Part-of-Speech Tagging
Every word in a sentence plays a role. Nouns name things, verbs describe actions, adjectives modify nouns, and adverbs modify verbs. Part-of-speech tagging is the task of automatically labeling each word with its grammatical category. Given the sentence "The quick brown fox jumps over the lazy dog," a POS tagger produces labels like DET, ADJ, ADJ, NOUN, VERB, ADP, DET, ADJ, NOUN.
Why does this matter? Part-of-speech information forms the backbone of deeper linguistic analysis. Syntactic parsers use POS tags to constrain the possible parse trees. Named entity recognizers rely on POS patterns to identify entity boundaries. Information extraction systems use verb-noun sequences to find relations. Even modern neural systems, despite learning representations end-to-end, often benefit from POS features as auxiliary inputs.
This chapter introduces the fundamental concepts of POS tagging. You'll learn the major tag sets used in NLP, understand why context matters for disambiguation, implement taggers using both rules and statistical methods, and evaluate their performance on real text.
What Is a Part of Speech?
Parts of speech, also called lexical categories or word classes, group words by their grammatical function and syntactic behavior. Linguists have debated these categories for millennia, dating back to Pāṇini's grammar of Sanskrit around 500 BCE.
A part of speech (POS) is a category of words that share similar grammatical properties and syntactic roles. Examples include nouns, verbs, adjectives, adverbs, prepositions, and conjunctions.
Traditional grammar identifies eight parts of speech in English: noun, verb, adjective, adverb, pronoun, preposition, conjunction, and interjection. Computational linguistics uses finer distinctions. Instead of just "verb," we might distinguish between base verbs (VB), third-person singular present verbs (VBZ), past tense verbs (VBD), and past participles (VBN).
Consider how the word "run" behaves differently in these sentences:
- "I run every morning." (base verb, VB)
- "She runs every morning." (third-person singular, VBZ)
- "He ran yesterday." (past tense, VBD)
- "I have run marathons before." (past participle, VBN)
- "That was a good run." (noun, NN)
The same word form can have different tags depending on context. This ambiguity is what makes POS tagging challenging and interesting.
Tag Sets
A tag set defines the inventory of labels a tagger can assign. Different tag sets make different distinctions, trading off between granularity and simplicity.
The Penn Treebank Tag Set
The Penn Treebank tag set, developed at the University of Pennsylvania in the 1990s, became the de facto standard for English POS tagging. It contains 36 POS tags plus 12 punctuation and symbol tags.
The fine-grained distinctions serve specific purposes. Distinguishing singular nouns (NN) from plural nouns (NNS) helps identify subject-verb agreement errors. Separating proper nouns (NNP) from common nouns (NN) aids named entity recognition. The six verb tags capture tense and aspect, crucial for temporal reasoning.
The Universal POS Tag Set
The Penn Treebank tag set works well for English but doesn't transfer to other languages. German has different case markings, Chinese lacks inflectional morphology, and Arabic has complex verb forms. The Universal Dependencies project introduced a cross-linguistic tag set with 17 tags designed to work across languages.
The Universal tag set collapses fine-grained distinctions. All Penn Treebank verb tags (VB, VBD, VBG, VBN, VBP, VBZ) map to VERB. The tradeoff is reduced expressiveness for increased cross-linguistic compatibility.
Mapping Between Tag Sets
Converting between tag sets is common when combining resources annotated with different conventions:
The mapping loses information. Both "quick" (JJ) and "quicker" (JJR) become ADJ, erasing the comparative distinction. This loss may or may not matter depending on your application.
The Challenge of Ambiguity
Many words can function as multiple parts of speech. The word "light" can be an adjective ("a light meal"), noun ("the light is bright"), or verb ("please light the candle"). Determining the correct tag requires examining context.
Studies of the Penn Treebank show that about 40% of word tokens are ambiguous, having multiple possible tags. However, context usually resolves the ambiguity. After seeing "the," we expect a noun or adjective, not a verb. After seeing "can," if the next word is a verb, then "can" is likely a modal.
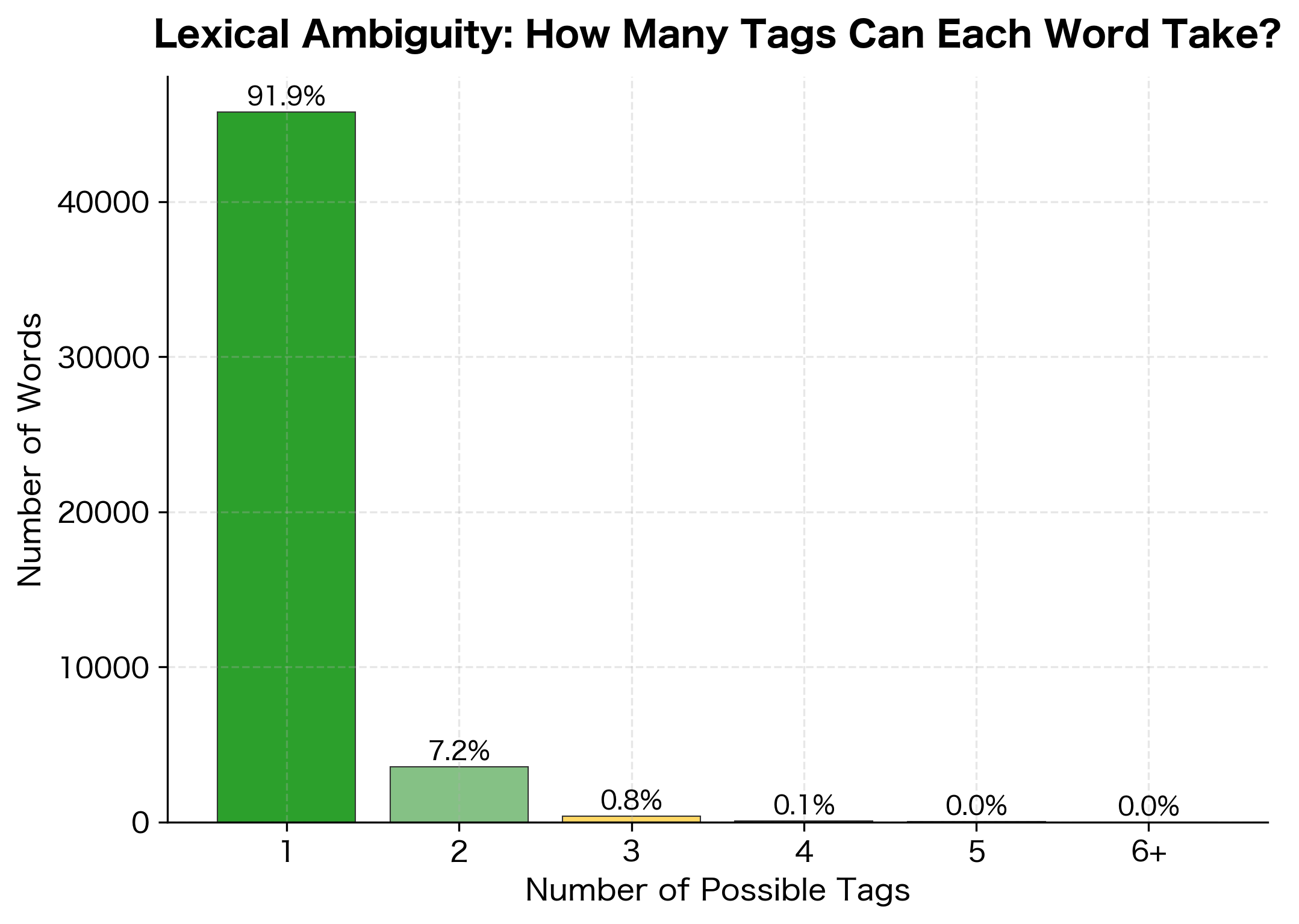
Quantifying Ambiguity
Let's measure how much ambiguity exists in English text using the Brown corpus:
The analysis reveals that a significant portion of words can take multiple tags. However, frequency matters. Common words like "the" are unambiguous (always DT), while rarer words show more variation. The most ambiguous words often include function words and common verbs that double as nouns.
Rule-Based POS Tagging
Before statistical methods dominated, researchers built rule-based taggers using hand-crafted patterns. While largely superseded, understanding these approaches provides intuition for what makes tagging difficult.
A Simple Pattern-Based Tagger
The simplest approach assigns tags based on word endings and patterns:
The PatternTagger applies rules in order: first checking a lexicon of common words with known tags, then matching suffix patterns, and finally falling back to defaults. This approach captures obvious cases but ignores context entirely.
The pattern tagger handles clear cases well: "quickly" gets RB due to the "-ly" suffix, "running" gets VBG due to "-ing", and "beautiful" gets JJ due to "-ful". However, it fails on ambiguous words where context matters.
Limitations of Patterns
Pattern-based taggers break down on contextual ambiguity:
The pattern tagger assigns "can" as MD (modal) in all cases because that's in its lexicon, but "can" should be NN when it's a container. Similarly, "fish" gets tagged as NN by default, but it's a verb in "I can fish." Resolving these cases requires examining surrounding words.
Using NLTK's Taggers
NLTK provides several pre-trained taggers that handle context and ambiguity:
NLTK's default tagger is an averaged perceptron model trained on the Penn Treebank. It uses features from the current word, surrounding words, and previously predicted tags to make contextually informed decisions. Notice how it correctly handles "can" as both a modal verb and a noun depending on context.
Tagset Conversion with NLTK
NLTK can also convert to Universal tags:
Using spaCy's Tagger
spaCy provides fast, accurate tagging with both fine-grained and coarse tags:
spaCy provides both fine-grained tags (like Penn Treebank's VBZ) and coarse Universal tags. The token.tag_ attribute gives fine-grained tags while token.pos_ gives Universal tags. This dual annotation is convenient when you need different levels of granularity.
Explaining Tags
spaCy includes explanations for each tag:
Building a Statistical Tagger
The pattern-based tagger we built earlier fails on ambiguous words because it ignores context. To do better, we need a tagger that learns from data which tags are likely for each word and, crucially, which tags tend to follow other tags. This section walks through building such a tagger from scratch, developing the mathematical intuition step by step.
The Core Insight: Words and Sequences Both Matter
Imagine you encounter the word "can" in a sentence. How do you decide if it's a modal verb ("She can swim") or a noun ("Open the can")? You use two types of evidence:
-
Word-level evidence: Some words strongly prefer certain tags. "Quickly" is almost always an adverb. "The" is always a determiner. But "can" is genuinely ambiguous.
-
Sequence-level evidence: Tags follow patterns. After "the," you expect a noun or adjective. After a modal verb like "can," you expect another verb. These grammatical regularities help disambiguate.
A statistical tagger captures both types of evidence as probability distributions learned from annotated training data.
Emission Probabilities: Linking Words to Tags
The first distribution answers: "Given that I know the tag, how likely is this particular word?" This is called the emission probability because we think of the tag as "emitting" or generating the word we observe.
The emission probability measures how likely a specific word is to appear with a given part-of-speech tag. High emission probability means the word is typical for that tag.
Consider the tag NOUN. Words like "cat," "dog," "table," and "government" frequently appear as nouns, so they have high emission probability given the NOUN tag. The word "quickly," by contrast, almost never appears as a noun, so is nearly zero.
We estimate emission probabilities by counting how often each word appears with each tag in our training corpus, then normalizing:
where:
- : the count of times this word appeared with this tag in training
- : the total count of this tag across all words
For example, if "dog" appears 50 times with the NN tag in training, and NN appears 10,000 times total, then .
Transition Probabilities: Capturing Grammar
The second distribution captures sequential patterns: "Given the previous tag, how likely is the current tag?" This is called the transition probability because it describes how we transition from one tag to the next.
The transition probability measures how likely a tag is to follow another tag. High transition probability indicates a common grammatical pattern.
where:
- : the tag at position in the sentence
- : the tag at the previous position
Some transitions are very common: determiners (DT) almost always precede nouns (NN) or adjectives (JJ). Other transitions are rare: you rarely see two determiners in a row. By learning these patterns from data, the tagger can use context to disambiguate.
We estimate transition probabilities similarly to emissions:
where:
- : the count of times immediately followed
- : the total count of in the corpus
Combining Evidence: The Scoring Function
Now we can score candidate tags by combining both types of evidence. For a word at position with previous tag , we want to find the tag that maximizes:
This product captures both how well the tag explains the word (emission) and how well it fits the grammatical context (transition). The tag with the highest combined score wins.
In practice, we work in log space to avoid numerical underflow when multiplying many small probabilities:
where logarithms convert the multiplication to addition, making computation more stable.
Implementation
Let's implement this statistical tagger step by step:
The train method iterates through tagged sentences, building four data structures:
- word_tag_counts: For each tag, counts how often each word appeared with that tag
- tag_counts: Total occurrences of each tag (for normalizing emission probabilities)
- transition_counts: For each previous tag, counts how often each current tag followed
- prev_tag_counts: Total occurrences of each tag as a predecessor (for normalizing transitions)
We also track the vocabulary and tag set, which we'll need during inference.
Handling Unseen Events: Smoothing
There's a critical problem with the raw probability estimates: any word-tag combination not seen in training gets probability zero. If the test data contains the word "smartphone" but our 1990s training data doesn't include it, the model can't assign any tag to it.
We solve this with add-k smoothing (also called Laplace smoothing), which adds a small constant to all counts:
where:
- : the raw count of times this word appeared with this tag
- : the total count of this tag across all words
- : the smoothing constant (we use 0.001), which adds a small probability mass to unseen events
- : the vocabulary size, used to ensure probabilities sum to 1
The intuition is simple: instead of saying "I've never seen 'smartphone' as a noun, so probability is zero," we say "I've never seen it, but it's possible, so here's a tiny probability." The denominator adjustment ensures all probabilities still sum to 1.
Smaller values trust the training data more, while larger values spread probability more evenly across possibilities. A value of 0.001 works well in practice, keeping probabilities close to the empirical estimates while preventing zeros.
Greedy Decoding: Choosing Tags
With our probability estimates in hand, we need a strategy for choosing tags. The simplest approach is greedy decoding: at each position, pick the tag that maximizes the score, then move on:
The greedy decoder loops through each word, computing a score for every possible tag by combining emission and transition probabilities. The implementation uses log probabilities for numerical stability, converting the multiplication in our scoring formula to addition:
where:
- : the emission probability, measuring how likely this word is given the proposed tag
- : the transition probability, measuring how likely this tag is given what came before
The tag with the highest combined score wins. We add a tiny constant (1e-10) before taking logarithms to avoid taking the log of zero.
Greedy decoding has an important limitation: it makes locally optimal choices that may be globally suboptimal. Consider the sentence "I can fish." When processing "can," the tagger doesn't yet know that "fish" follows. If the training data strongly associates "can" with the modal verb tag, greedy decoding picks that, even though the full context suggests "can" might be a verb in "I can [verb] fish" (meaning "I am able to fish").
More sophisticated approaches like the Viterbi algorithm (covered in a later chapter) consider all possible tag sequences simultaneously, finding the globally optimal path. But greedy decoding is fast and works reasonably well when transitions provide strong guidance.
Putting It Together: Training and Evaluation
Now let's train our statistical tagger on real data and see how it performs:
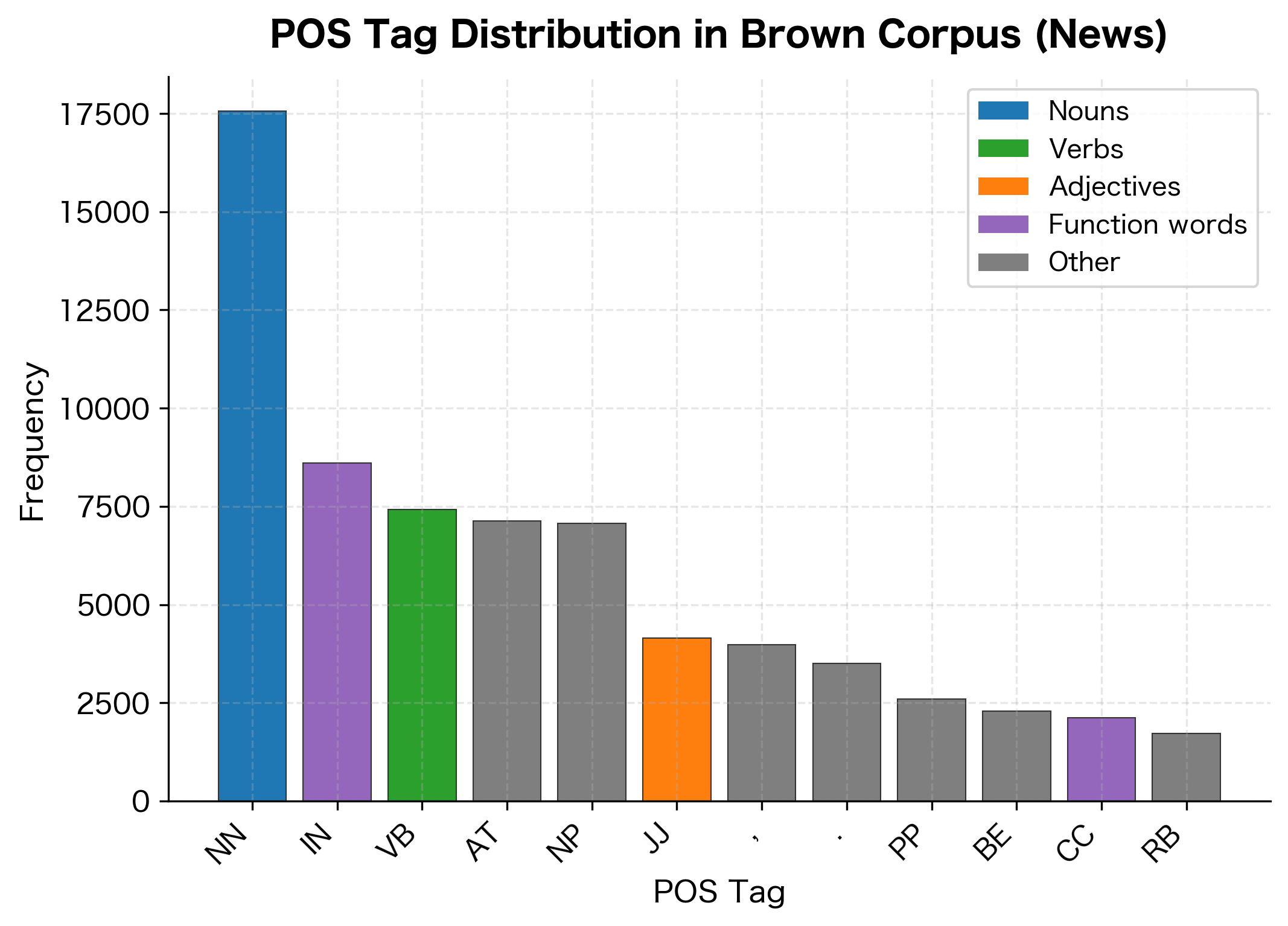
We'll use the Brown corpus, a classic collection of American English text from the 1960s, which includes POS annotations. We simplify the tags to their first two characters (e.g., "NN" and "NNS" both become "NN") to reduce the tag set size and make patterns easier to see:
The training data contains several thousand sentences with a vocabulary of thousands of unique words. The tag distribution is heavily skewed: nouns (NN) and prepositions (IN) dominate, reflecting their prevalence in news text. Less common tags like modal verbs (MD) and conjunctions (CC) appear far less frequently but are important for grammatical structure.
This skewed distribution has implications for our tagger. Tags with more training examples will have more reliable probability estimates, while rare tags may suffer from sparse data.
Measuring Performance
To evaluate our tagger, we compare its predictions against the gold-standard annotations in our test set. We compute overall accuracy (percentage of tokens tagged correctly) and per-tag accuracy to identify which categories are harder:
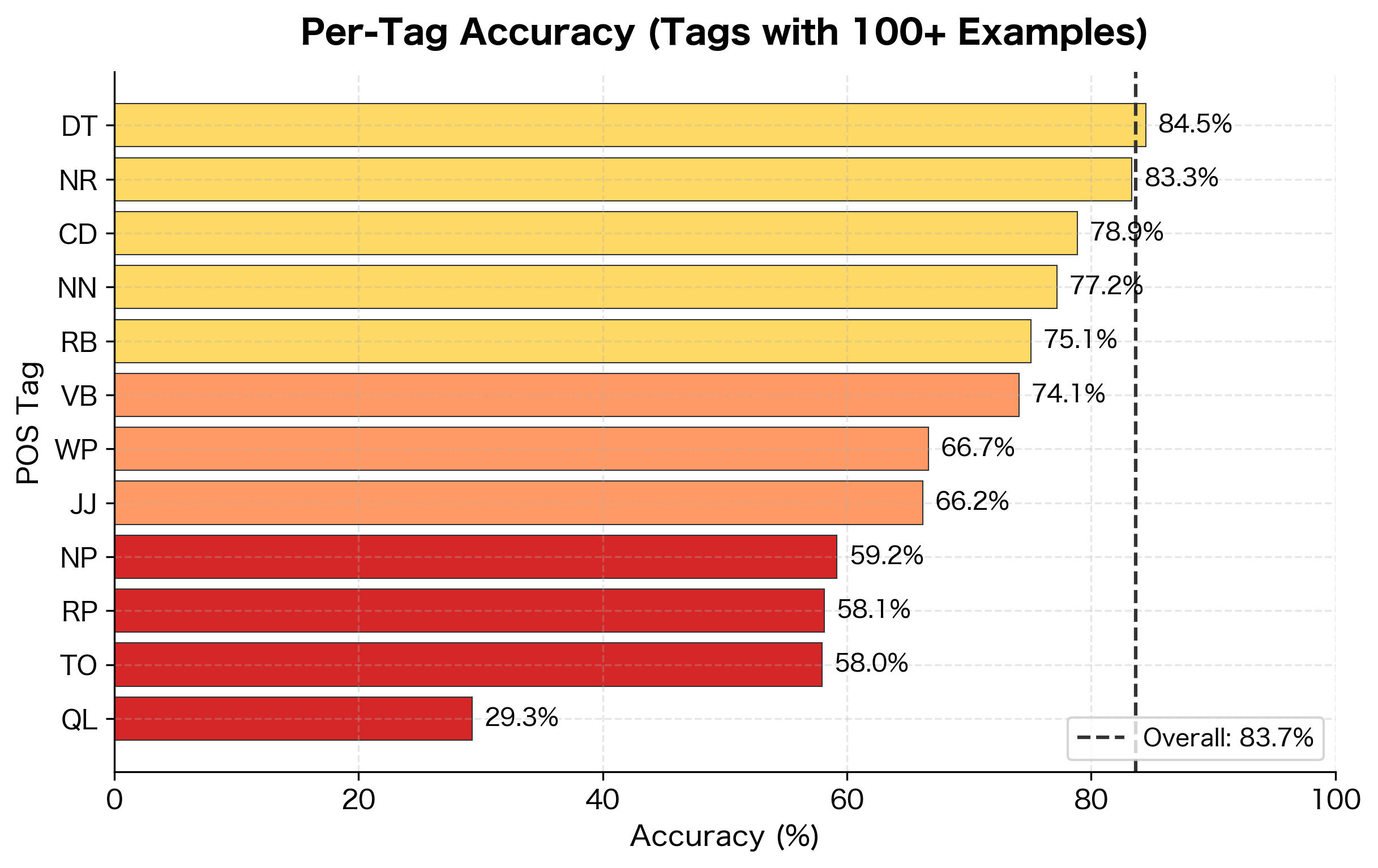
Our simple statistical tagger achieves reasonable accuracy, demonstrating that even a straightforward probabilistic approach outperforms pattern-based rules. The per-tag breakdown reveals an interesting pattern: closed-class words like determiners (DT) and prepositions (IN) achieve high accuracy because they have limited, predictable behavior. Open-class words like nouns (NN) and verbs (VB) are harder because they include many ambiguous words and the categories are more diverse.
The accuracy is respectable but falls short of state-of-the-art systems (97%+). The gap comes from several sources: our greedy decoding misses some context, our simplified tag set loses information, and we don't use morphological features beyond the word itself.
Understanding Errors
Looking at where the tagger fails reveals systematic patterns that suggest improvements:
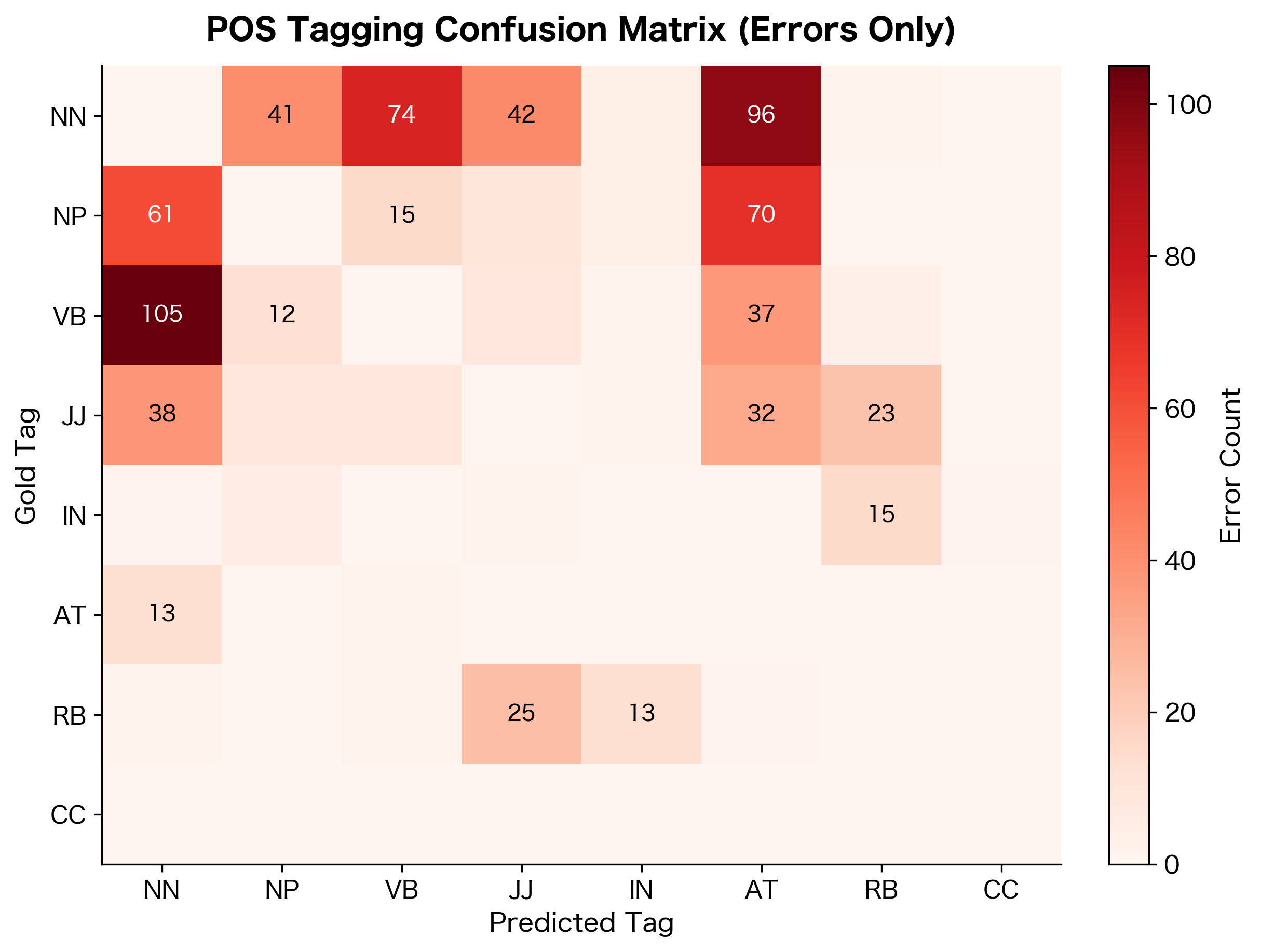
The error analysis reveals systematic confusion patterns. Nouns and proper nouns (NN vs. NP) are frequently confused because capitalization is the primary distinguishing feature, and our tagger doesn't use that signal effectively. Adjectives and nouns (JJ vs. NN) cause trouble because many English words can serve both functions ("the stone wall" vs. "throw the stone"). Verb form confusions (VB vs. VBD) often involve irregular verbs where past tense isn't marked by the "-ed" suffix.
Evaluation Metrics for POS Tagging
Accuracy, the percentage of correctly tagged tokens, is the standard metric for POS tagging. However, several nuances matter in practice.
POS tagging accuracy measures the percentage of tokens assigned the correct tag. Modern taggers achieve 97%+ accuracy on standard benchmarks, but performance varies significantly across text types and tag categories.
Known vs. Unknown Words
A critical distinction in evaluation is between known words (seen in training) and unknown words (out-of-vocabulary, OOV). Taggers typically perform much better on known words:
The gap between known and unknown word accuracy is substantial, as summarized in the table below. For unknown words, taggers must rely on morphological patterns, context, and default rules. This is why suffix-based rules (like assigning VBG to words ending in "-ing") remain useful even in statistical systems.
: Accuracy comparison between known and unknown words. The substantial gap highlights the challenge of handling novel words. {#tbl-known-unknown-accuracy}
Sentence-Level Accuracy
Another perspective is sentence-level accuracy: the percentage of sentences where every word is tagged correctly:
Sentence-level accuracy is much lower than token accuracy because errors compound. If each token has probability of being correct and we assume independent errors, a sentence of words has probability of being entirely correct. With 95% token accuracy, a 10-word sentence has only:
where:
- : the token-level accuracy (probability of correctly tagging a single word)
- : the number of words in the sentence
This means roughly 40% of 10-word sentences contain at least one error, even with a highly accurate tagger. This matters for downstream tasks that process entire sentences, where a single tagging error can cascade into larger problems.
POS Tagging for Downstream Tasks
POS tags serve as features or preprocessing for many NLP tasks.
Information Extraction
POS patterns help identify entities and relations:
Text Simplification
POS tags help identify which words to simplify:
Technical writing tends to have higher noun density (nominalization), while simpler writing uses more verbs. POS analysis helps identify these stylistic differences.
Visualizing POS Patterns
Visualizations help reveal the structure of tagged corpora. The following figures show POS tag frequency distributions and transition patterns from our trained statistical tagger, illustrating the grammatical regularities that make statistical tagging possible.
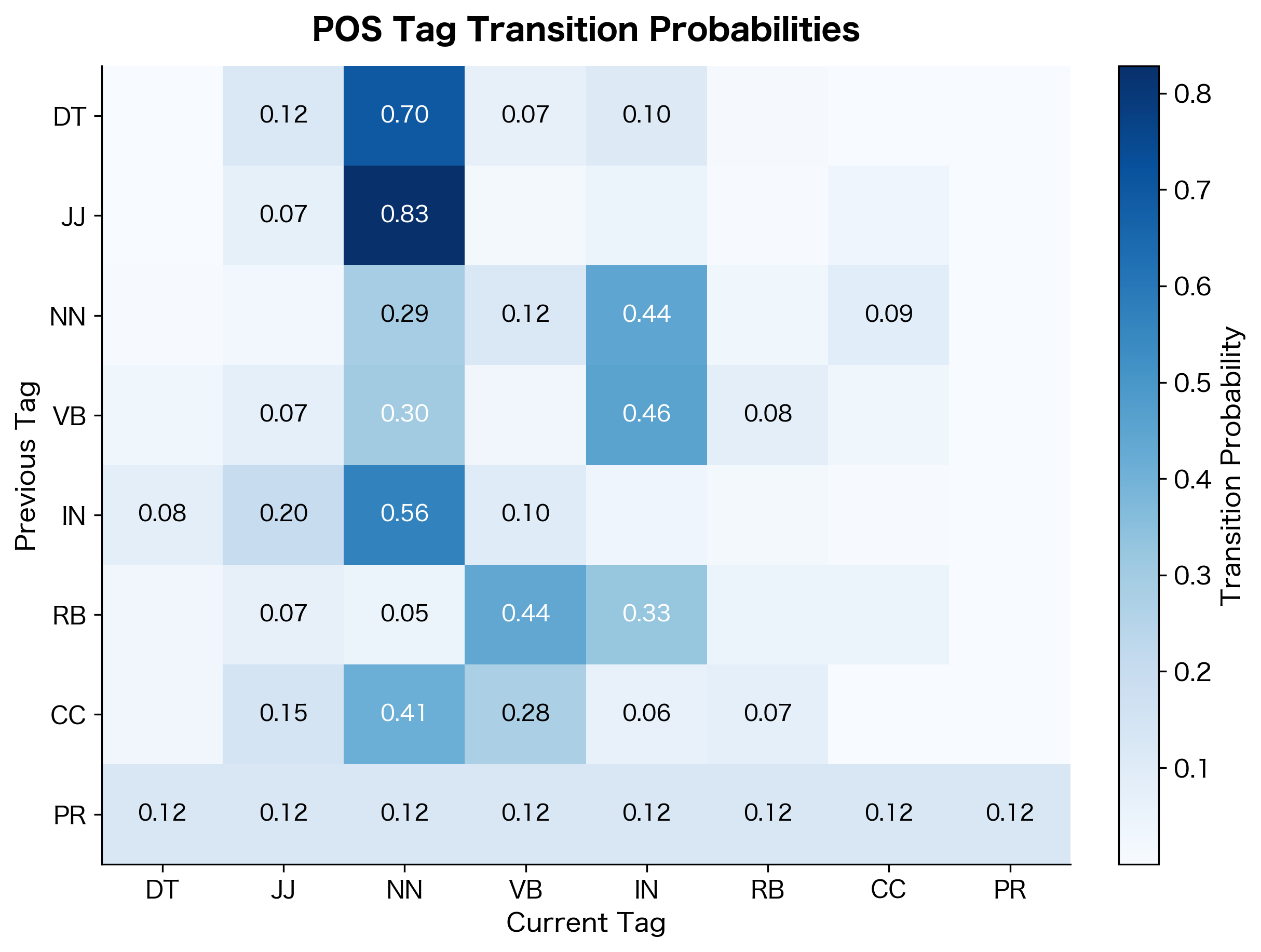
The transition matrix reveals grammatical patterns. Determiners (DT) strongly predict nouns (NN) or adjectives (JJ). Prepositions (IN) are often followed by determiners. These patterns reflect the syntactic structure of English.
Limitations and Challenges
Despite achieving high accuracy on benchmarks, POS tagging faces several ongoing challenges.
Domain shift causes significant accuracy drops when taggers trained on news text are applied to social media, scientific articles, or historical documents. Each domain has its own vocabulary, style, and even grammatical conventions. A tagger trained on formal news articles may struggle with the informal, abbreviated language of Twitter.
Rare and novel words pose difficulties because taggers have limited information for words seen infrequently or not at all during training. Technical jargon, proper nouns, and neologisms require inference from context and morphology rather than memorized patterns.
Annotation inconsistencies in training data propagate to learned models. Even expert annotators disagree on edge cases, particularly for words that can function as multiple parts of speech. The Penn Treebank guidelines span hundreds of pages precisely because many tagging decisions are genuinely ambiguous.
Cross-linguistic challenges arise because tag sets and grammatical categories vary across languages. What constitutes a "verb" differs between English, which marks tense morphologically, and Chinese, which uses aspectual particles. Universal Dependencies aims to address this but inevitably loses language-specific distinctions.
Error propagation affects downstream tasks that rely on POS tags. A 97% accurate tagger still makes errors on roughly 3% of tokens. For a document with 1000 words, that's 30 errors that propagate to dependency parsing, named entity recognition, or information extraction. These errors compound as documents get longer.
Impact on NLP
Part-of-speech tagging was among the first NLP tasks to achieve near-human performance through machine learning, demonstrating that statistical methods could capture linguistic patterns effectively. The transition from rule-based systems to statistical taggers in the 1990s influenced the broader shift toward data-driven approaches in the field.
The task has served as a proving ground for sequence labeling techniques. Hidden Markov Models, Maximum Entropy Markov Models, Conditional Random Fields, and more recently neural architectures were all benchmarked on POS tagging before being applied to more complex tasks.
Modern pre-trained language models like BERT often include POS tagging as an auxiliary objective or evaluation task. Interestingly, these models achieve superhuman accuracy on standard benchmarks, revealing that earlier accuracy ceilings reflected annotation noise rather than true task difficulty.
POS tags remain useful features even in the age of deep learning. They provide linguistically meaningful abstractions that can improve sample efficiency, particularly for low-resource languages or specialized domains. When you have limited training data, incorporating POS information can help models generalize better.
Key Functions and Parameters
When working with POS tagging in Python, these are the essential functions and their key parameters:
NLTK POS Tagging
nltk.pos_tag(tokens, tagset=None, lang='eng') tags a list of tokens with POS labels:
tokens: List of word strings to tag (typically fromword_tokenize())tagset: Target tagset. Use'universal'for cross-linguistic Universal tags, or omit for Penn Treebank tagslang: Language code for the tagger model. Default'eng'works for English; other languages require downloading additional models
nltk.tag.map_tag(source, target, source_tag) converts between tag sets:
source: Source tagset identifier (e.g.,'en-ptb'for Penn Treebank)target: Target tagset identifier (e.g.,'universal'for Universal Dependencies)source_tag: The tag string to convert
spaCy POS Tagging
spacy.load(model_name) loads a pre-trained language model:
model_name: Model identifier like'en_core_web_sm'(small),'en_core_web_md'(medium), or'en_core_web_lg'(large). Larger models are more accurate but slower and require more memory
After processing text with nlp(text), access POS information via token attributes:
token.pos_: Coarse-grained Universal POS tag (17 tags)token.tag_: Fine-grained Penn Treebank-style tag (50+ tags)spacy.explain(tag): Returns a human-readable explanation of any tag
Statistical Tagger Parameters
When building custom taggers, key parameters include:
smoothing: Add-k smoothing constant (typically 0.001 to 0.1). Higher values assign more probability to unseen events, reducing overfitting but potentially hurting accuracy on known wordstrain/test split: Standard practice uses 80-90% for training. Larger training sets improve accuracy, especially for rare words and tag transitions
Summary
Part-of-speech tagging assigns grammatical labels to words based on their function in context. The task appears simple but requires handling widespread ambiguity, where the same word form can serve as different parts of speech.
Key takeaways:
- Tag sets define the inventory of labels. Penn Treebank uses 36 fine-grained tags while Universal Dependencies uses 17 cross-linguistic tags
- Ambiguity affects roughly 40% of word tokens in English, requiring contextual disambiguation
- Rule-based taggers use patterns and lexicons but fail on context-dependent ambiguity
- Statistical taggers learn from annotated data, combining word features with transition patterns
- NLTK and spaCy provide pre-trained taggers achieving 97%+ accuracy on standard benchmarks
- Evaluation distinguishes between known and unknown words, with OOV words being significantly harder
- Downstream applications use POS tags for noun phrase extraction, information extraction, and stylistic analysis
Part-of-speech tagging exemplifies a core NLP pattern: a task that seems trivial until you examine edge cases, where statistical methods substantially outperform hand-crafted rules, and where high but imperfect accuracy has real consequences for downstream processing.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about part-of-speech tagging.

Comments