

Learn how layer normalization enables stable transformer training by normalizing across features rather than batches, with implementations and gradient analysis.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Layer Normalization
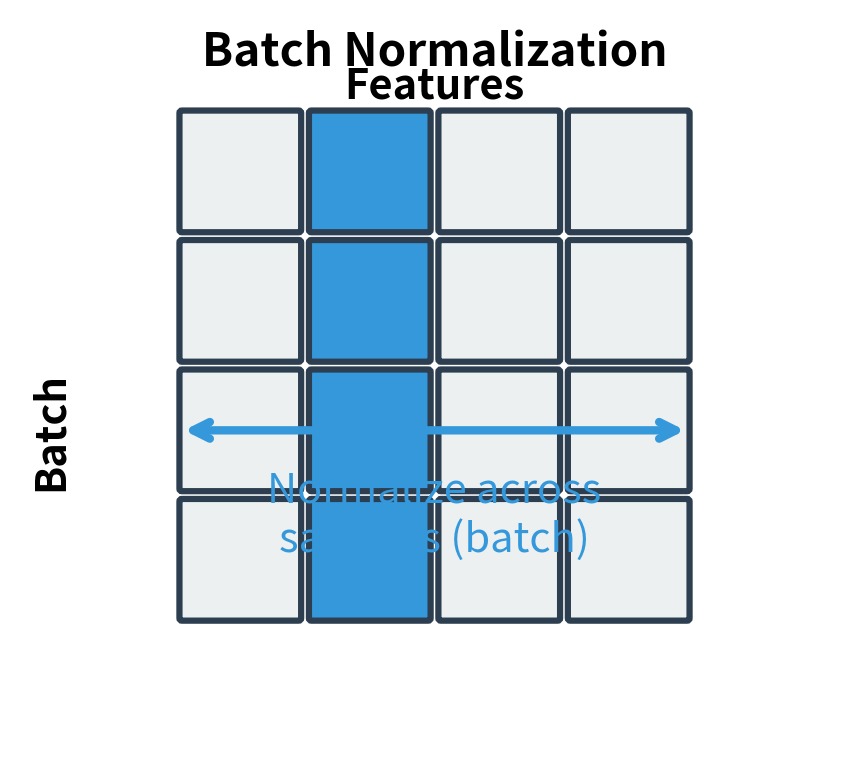
Batch normalization transformed how we train deep feedforward networks, but it stumbles when applied to transformers. The batch dimension becomes problematic: batch sizes vary, sequences have different lengths, and the statistics computed across a batch of diverse sentences lack semantic coherence. Layer normalization, introduced by Ba, Kiros, and Hinton in 2016, sidesteps these issues entirely by normalizing across features rather than across the batch. This seemingly simple change made layer normalization the default normalization technique for transformers, from the original "Attention is All You Need" architecture to modern large language models.
In this chapter, we'll explore why layer normalization works so well for transformers, how it differs from batch normalization in both computation and behavior, and the subtle implementation details that affect training stability. We'll also examine how the placement of layer normalization within transformer blocks affects learning dynamics, a design choice that has evolved significantly since the original transformer architecture.
Why Batch Normalization Fails for Transformers
Before diving into layer normalization, it's worth understanding exactly why batch normalization doesn't work well for sequence models. The core issue is that batch normalization computes statistics across the batch dimension, assuming that each position in a layer sees similar data across samples.
In a transformer processing sentences of varying lengths, each position in the sequence represents something different. Position 0 might be "The" in one sentence and "Scientists" in another. Position 50 might be a verb in one sentence, a noun in another, and padding in a third. Computing a mean and variance across these semantically unrelated positions produces statistics that don't reflect any meaningful property of the data.
The batch statistics are dominated by the extreme sequences, and these statistics change dramatically between positions. Layer normalization avoids this problem entirely by computing statistics within each sample independently, treating each token's representation as a self-contained unit to normalize.
The Layer Normalization Formula
To understand layer normalization, let's start with a fundamental question: what does it mean for a neural network layer to have "unstable" activations, and how can we fix it?
The Problem: Activation Scale Drift
Imagine a token's hidden representation as a vector of 768 numbers (a typical transformer dimension). During training, these numbers can drift: some become very large, others very small, and their collective distribution shifts unpredictably. This creates two problems. First, downstream layers must constantly adapt to changing input statistics, making learning inefficient. Second, when values grow too large or too small, gradients either explode or vanish, destabilizing training entirely.
The solution is elegant: before each token's representation moves to the next layer, we transform it to have a predictable, standardized distribution. Specifically, we want the 768 features to have zero mean and unit variance. This "resets" the scale at every layer, preventing drift from accumulating.
Step 1: Finding the Center
The first step is computing where the current distribution is centered. Given a hidden state vector representing one token, we calculate its mean:
where:
- : the arithmetic mean of all features in this token's representation
- : the hidden dimension (e.g., 768 for BERT-base, 4096 for LLaMA-7B)
- : the value of the -th feature
This tells us the "center of mass" of the representation. If , the features are shifted toward positive values; if , they lean negative. The goal is to shift this center to zero.
Step 2: Measuring the Spread
Next, we need to know how spread out the values are. A representation where all values cluster tightly around the mean is very different from one where values are scattered widely. We capture this with variance:
where:
- : the variance, measuring how much the features deviate from their mean
- : the squared deviation of each feature from the mean
Squaring ensures that positive and negative deviations don't cancel out. If is large, the features are spread out; if small, they're tightly clustered. We'll use the standard deviation to rescale the values to unit variance.
Step 3: The Normalization Transform
With mean and variance in hand, we can now standardize each feature:
where:
- : the normalized value of the -th feature
- : a tiny constant (typically ) added to prevent division by zero if variance is extremely small
This two-part transformation is exactly what you'd do to standardize any dataset: subtract the mean (centering at zero), then divide by the standard deviation (scaling to unit variance). The result has zero mean and approximately unit variance across the features.
Step 4: Restoring Flexibility with Learnable Parameters
Here's where layer normalization becomes clever rather than restrictive. Forcing every representation to have exactly zero mean and unit variance might seem limiting: what if the optimal representation for some layer actually needs a different distribution?
The solution is to add learnable parameters that can undo the normalization if needed:
where:
- : the final output for the -th feature
- : a learned scale parameter for feature (initialized to 1)
- : a learned shift parameter for feature (initialized to 0)
These parameters are learned during training, just like weights and biases. If the network discovers that feature should have mean 3.5 and standard deviation 2.0, it can learn and to recover that distribution. This means layer normalization never reduces the network's representational power: it starts from a stable baseline but can learn any distribution it needs.
The Complete Formula
Putting all the pieces together, layer normalization transforms a hidden state vector of dimension into:
where:
- : the input vector representing one token's hidden state
- : the mean across all features
- : the variance across all features
- : a small stability constant (typically or )
- : learned scale parameters, initialized to ones
- : learned shift parameters, initialized to zeros
- : element-wise multiplication
The formula reads naturally: subtract the mean, divide by the standard deviation (with a safety epsilon), then apply a learned scale and shift.
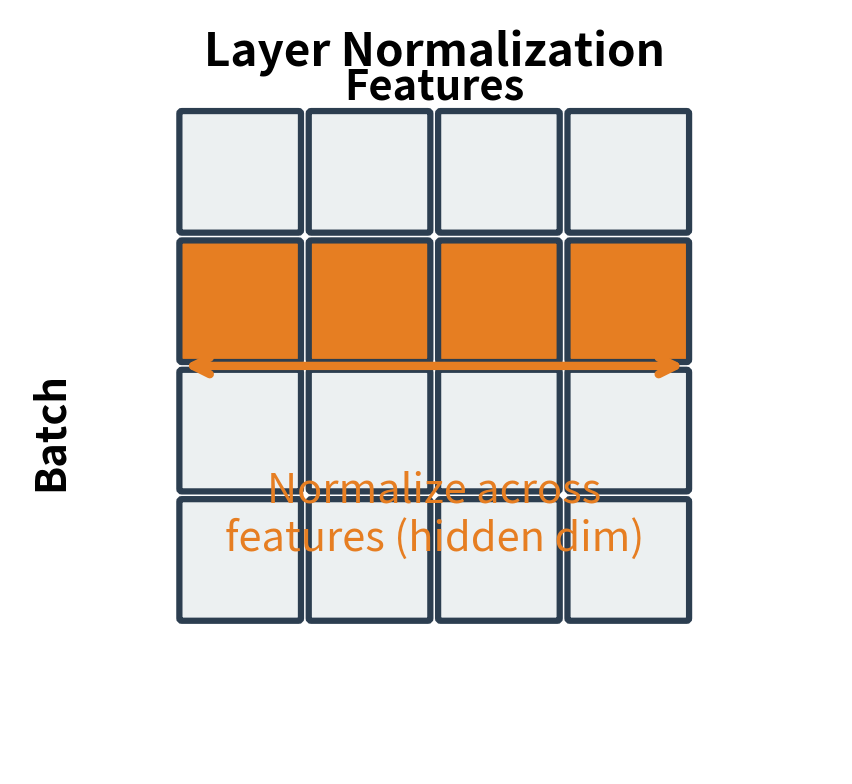
Why Features, Not Samples?
The key insight that distinguishes layer normalization from batch normalization is the dimension over which we compute statistics. Batch normalization asks: "What's the typical value of feature across all samples in this batch?" Layer normalization asks: "What's the typical value across all features for this particular token?"
For transformers, the layer normalization approach is far more natural. Each token is processed independently, and we want stable statistics regardless of what other tokens or samples happen to be in the batch. This independence also means layer normalization works identically during training and inference, with no need for running statistics or batch size considerations.
Implementing Layer Normalization from Scratch
Now that we understand the formula conceptually, let's translate it into code. Building layer normalization from scratch will solidify our understanding and reveal the implementation details that matter in practice.
The Forward Pass
Our implementation follows the mathematical steps exactly: compute mean, compute variance, normalize, then apply the learnable transformation.
The dim=-1 argument tells PyTorch to compute statistics across the last dimension (features), which is exactly what layer normalization requires. The keepdim=True preserves the dimension for broadcasting during subtraction and division.
A Worked Example
Let's trace through layer normalization with concrete numbers to see exactly what happens at each step.
The input tokens have varying means (around 2-3) and standard deviations (around 2-4), reflecting the non-standard distribution we created. After layer normalization, each token has mean essentially zero and standard deviation essentially one. The tiny deviations from exactly 0 and 1 are floating-point precision artifacts, not algorithmic issues.
Let's visualize this transformation to see exactly how layer normalization reshapes the feature distribution.
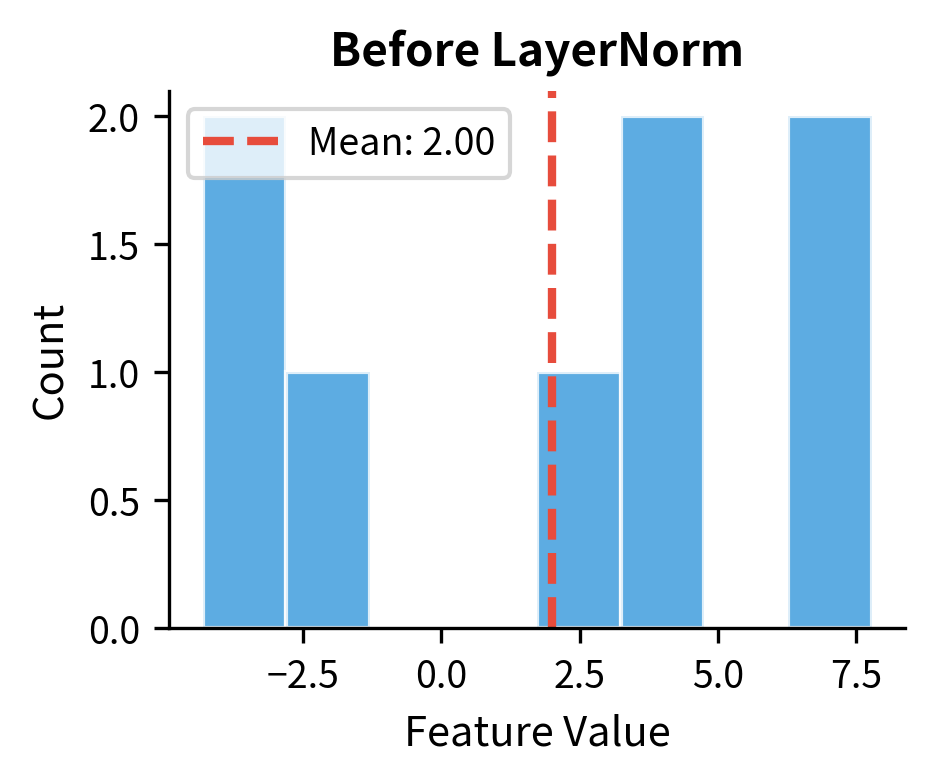
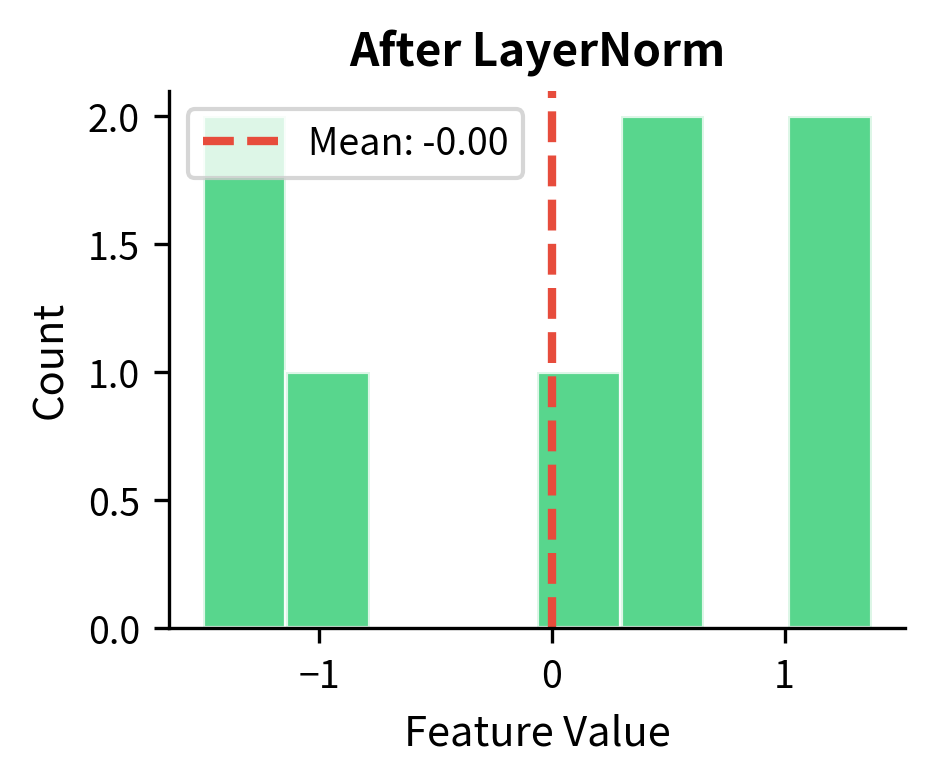
The histograms make the transformation crystal clear. Before normalization, the feature values are scattered around a positive mean with varied spread. After normalization, they're centered at zero with approximately unit variance. This happens independently for every token in the sequence.
Notice that each token is normalized independently: the first token's statistics don't affect the second token's normalization. This independence is precisely what makes layer normalization suitable for transformers, where tokens must be processed in parallel and sequences have variable lengths.
The Role of Learnable Parameters
After normalizing activations to zero mean and unit variance, we've effectively forced all features into a standardized distribution. But what if the network actually needs some features to have a larger spread, or to be centered around a non-zero value? The learnable parameters (scale) and (shift) solve this problem.
For each feature dimension , the final output is:
where:
- : the final output for the -th feature
- : the normalized value (zero mean, unit variance)
- : the learned scale for feature , which controls the spread of values
- : the learned shift for feature , which controls the center of the distribution
Here's the key insight: if the network learns and , it can completely undo the normalization and recover the original distribution. This means layer normalization can never hurt the network's representational capacity; in the worst case, it learns to bypass itself entirely. In practice, the network finds an intermediate setting that benefits from stable optimization while still representing the patterns it needs.
The output distribution for each feature is controlled by its corresponding and values. Features with larger values have wider distributions, while shifts the center. This per-feature control allows different dimensions of the representation to operate at different scales, which is crucial for transformers where different attention heads and feature dimensions may need different dynamic ranges.
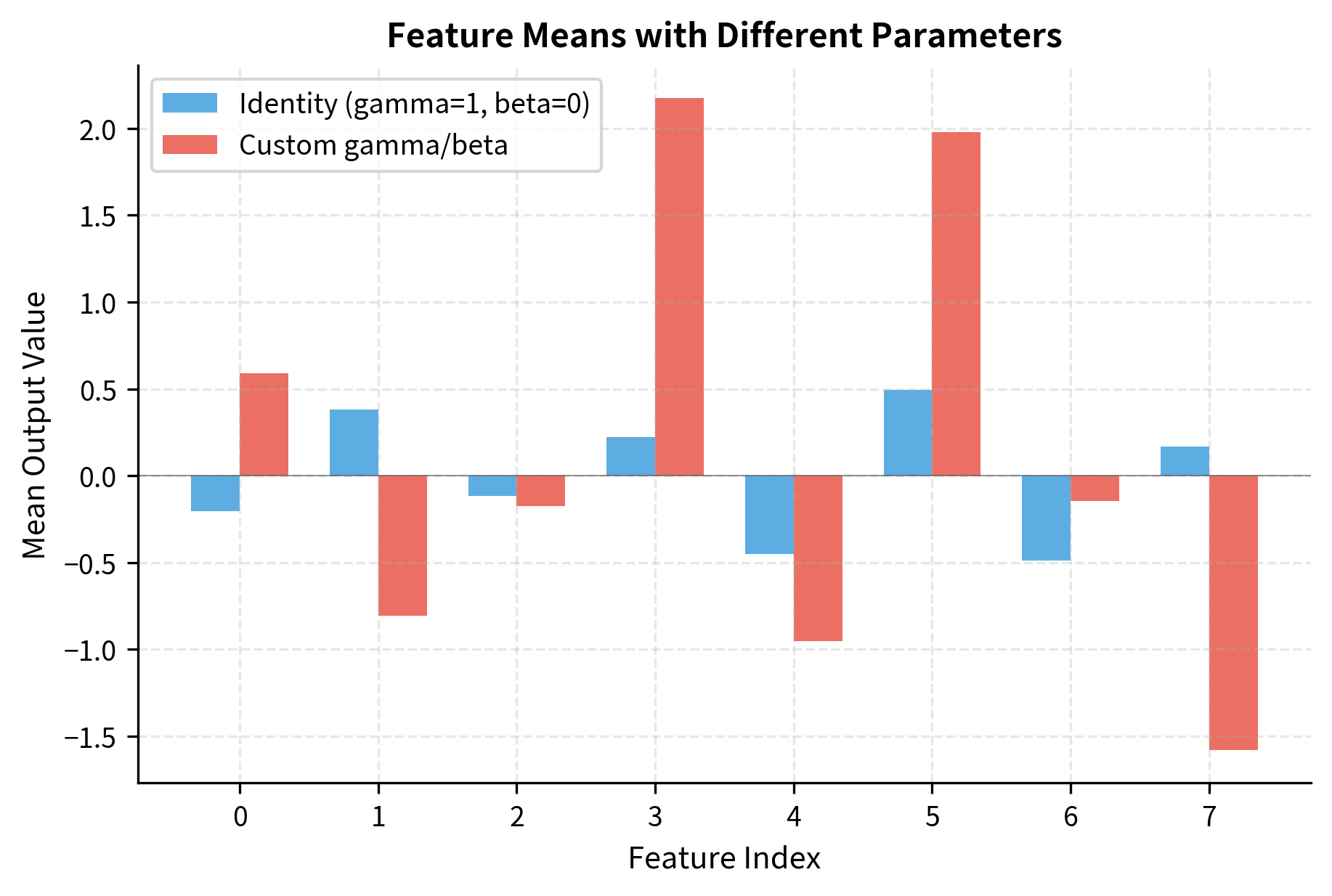
With identity parameters (gamma=1, beta=0), all feature means are near zero as expected. With custom parameters, each feature shifts to its corresponding beta value, demonstrating how the learnable parameters give each dimension independent control over its output distribution.
PyTorch's LayerNorm
PyTorch provides a built-in nn.LayerNorm that handles all these details efficiently. Let's verify our implementation matches PyTorch's behavior.
The outputs match within floating-point precision, confirming our implementation is correct.
Layer Normalization in Transformers
In transformer architectures, layer normalization appears in two key locations: after the attention mechanism and after the feed-forward network. The original transformer used "post-norm" placement, where normalization comes after the residual connection:
Modern architectures like GPT-2, GPT-3, and LLaMA use "pre-norm" placement, where normalization comes before the sublayer:
The difference in placement has significant implications for gradient flow, which we'll explore in detail in the pre-norm vs post-norm chapter.
Gradient Flow Through Layer Normalization
Understanding how gradients flow through layer normalization is essential for debugging training issues and understanding why normalization stabilizes training.
The backward pass through layer normalization is more complex than a simple element-wise operation because each output depends on all inputs through the mean and variance computation. When we change a single input , it affects not only its own normalized output but also the mean and variance , which in turn affect every output element. This coupling makes the gradient computation more intricate.
Given the loss and the upstream gradient (the gradient flowing back from later layers), we need to compute three gradients: for backpropagation, and and for updating the learnable parameters.
Gradients for Learnable Parameters
The output of layer normalization is , where is the normalized input. Since this is a simple affine transformation, the gradients follow directly from the chain rule.
For the scale parameter :
where:
- : the gradient of the loss with respect to the -th scale parameter
- : an index over all tokens (across batch and sequence dimensions)
- : the upstream gradient for the -th feature of the -th token
- : the normalized value of the -th feature for the -th token
Intuitively, this sums up how much each token's normalized value contributed to the loss through this scale parameter.
For the shift parameter :
where:
- : the gradient of the loss with respect to the -th shift parameter
This is simply the sum of upstream gradients, since adds directly to the output.
Gradient for Input
The gradient with respect to input is more involved because depends on in three ways: directly, through the mean , and through the variance . Applying the chain rule carefully yields:
where:
- : the gradient of the loss with respect to the -th input element
- : the learned scale parameter for the -th feature
- : the standard deviation (with epsilon for stability)
- : the feature dimension (number of elements in the input vector)
- : the normalized input, equal to
Let's break down the three terms inside the parentheses:
-
Direct contribution : The gradient that would flow if normalization were a simple scaling operation.
-
Mean correction : Accounts for how changing affects , which affects all outputs. This term subtracts the average gradient, centering the gradient distribution.
-
Variance correction : Accounts for how changing affects , which scales all outputs. This term is proportional to the normalized value , meaning inputs far from the mean get larger corrections.
This formula reveals something important: the gradient for each input element depends on the gradients of all other elements through the mean and variance terms. This coupling helps distribute gradient information across features, which can improve training stability.
The differences are on the order of or smaller, well within floating-point precision. This confirms our manual backward pass implementation correctly computes the gradients that PyTorch's autograd produces automatically.
Visualizing Layer Normalization's Effect
Let's visualize how layer normalization transforms the activation distribution during a forward pass through multiple transformer blocks.
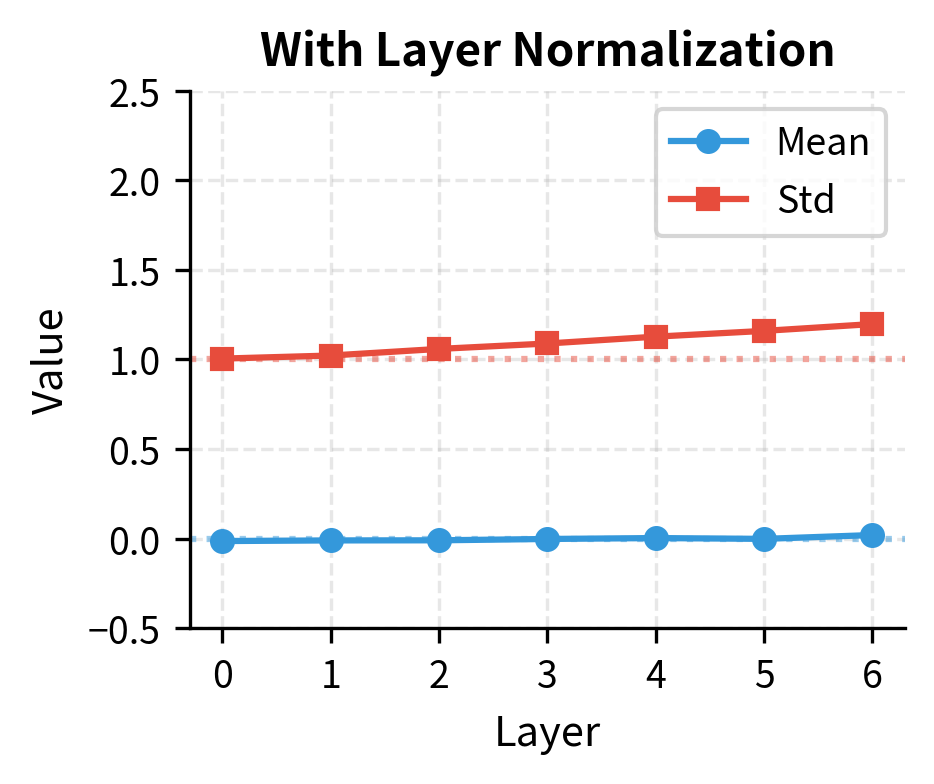
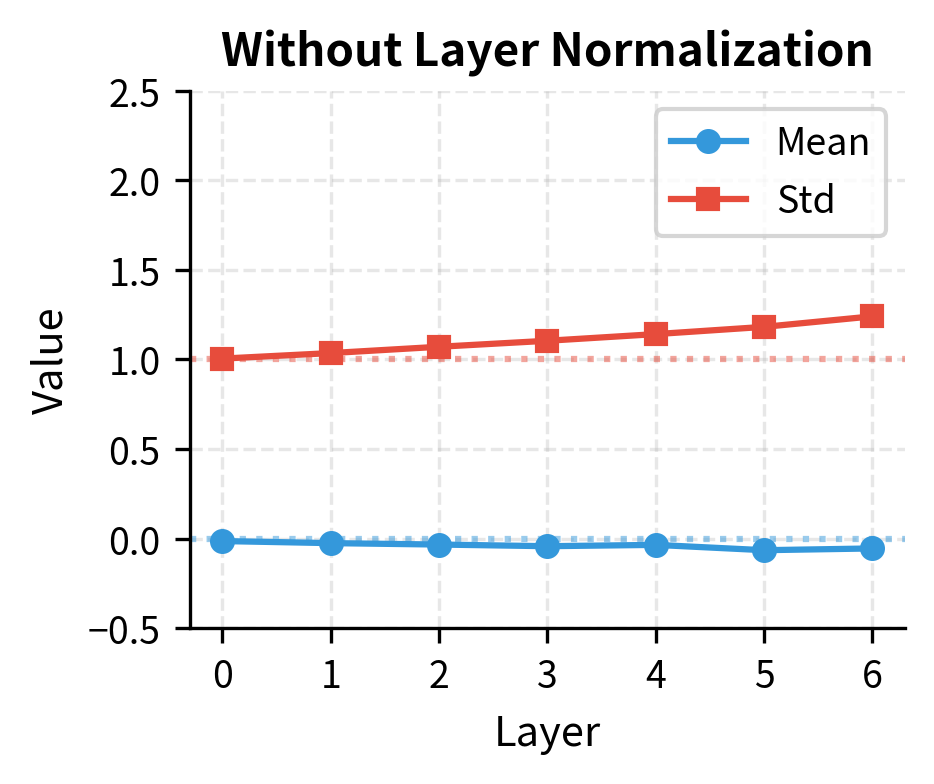
With layer normalization, activations maintain stable statistics throughout the network. Without it, activations can drift, though the effect depends heavily on initialization. In practice, this stability becomes crucial during training when weight updates can cause activation statistics to shift dramatically without normalization to anchor them.
Epsilon: A Small but Critical Detail
The epsilon parameter () appears in the denominator of the normalization formula:
where:
- : the normalized value for the -th feature
- : the original input value
- : the mean across all features
- : the variance across all features
- : a small constant added to prevent division by zero
The purpose of is to ensure numerical stability. If all input values are identical (or nearly so), the variance approaches zero. Without , we would divide by zero, producing infinity or NaN. Adding a small positive constant like ensures the denominator is always positive.
The choice of epsilon can affect numerical stability, especially with mixed-precision (FP16) training where very small values may underflow.
The input variance is extremely small (around ), which means we're dividing by a very small number. With epsilon = 0, the output standard deviation explodes because we're essentially dividing by nearly zero. As epsilon increases, the output becomes more stable. The standard choice of strikes a balance: it's large enough to prevent numerical issues but small enough not to distort the normalization when variance is reasonably sized. A reasonable epsilon value (typically to ) provides a safety net without affecting normal computations.
Layer Normalization with Different Normalized Shapes
PyTorch's nn.LayerNorm accepts a normalized_shape parameter that controls which dimensions are normalized. For transformers, we typically normalize over the feature dimension only:
Notice the difference: with normalized_shape=(8,), each individual token has zero mean (Token 0,0 and Token 0,1 both have mean approximately 0). With normalized_shape=(4, 8), the entire sample is normalized together, so individual tokens may have non-zero means but the sample as a whole has zero mean.
Normalizing over features only is the standard choice for transformers because it treats each token independently, matching the autoregressive nature of language models and allowing the model to process variable-length sequences.
Limitations and Impact
Layer normalization has become ubiquitous in transformer architectures, but it's not without drawbacks.
The primary computational overhead comes from computing statistics for every token at every layer. For a model with hidden dimension , each layer normalization requires computing a mean (sum of elements) and variance (sum of squared differences), then normalizing all elements. While these operations are memory-bandwidth bound rather than compute-bound on modern GPUs, they still add up in models with hundreds of layers.
The learned and parameters add parameters per layer normalization, which is negligible compared to attention and FFN parameters but contributes to model complexity. More importantly, these parameters can be a source of numerical issues when they grow very large or approach zero, requiring careful initialization and sometimes explicit constraints.
Layer normalization also introduces a subtle form of coupling between features that can affect interpretability. Because each feature is normalized relative to the others, the absolute activation value of any single feature becomes less meaningful. This makes it harder to interpret individual neurons or feature dimensions in isolation.
Despite these limitations, layer normalization's impact on transformer training stability cannot be overstated. Before normalization techniques were widely adopted, training deep networks required careful learning rate tuning, extensive warmup periods, and often failed entirely for very deep models. Layer normalization enables stable training with higher learning rates, reduces sensitivity to initialization, and allows models to scale to unprecedented depths. The original transformer used layer normalization, and every major language model since has relied on some form of normalization to train successfully.
The success of layer normalization has also spurred research into alternatives. RMSNorm, which we'll cover in the next chapter, removes the mean-centering step to improve computational efficiency while maintaining most of the stability benefits.
Key Parameters
When using nn.LayerNorm in PyTorch, understanding the key parameters helps you configure it correctly for your architecture:
-
normalized_shape: The shape of the input over which to normalize. For transformers, this is typically the hidden dimension
d_model(e.g., 768, 1024). You can also pass a list like[seq_len, d_model]to normalize over multiple dimensions, though normalizing over features only is the standard choice. -
eps: The epsilon value added to the denominator for numerical stability. Default is
1e-5, which works well for most cases. For mixed-precision (FP16) training, you may need a larger value like1e-4to avoid underflow issues when variance is very small. -
elementwise_affine: Whether to include learnable and parameters. Default is
True. Setting toFalseremoves the learnable parameters, reducing model size slightly but limiting the network's ability to learn optimal feature scales.
Summary
Layer normalization is a fundamental component of transformer architectures that enables stable training of deep models. Unlike batch normalization, which computes statistics across the batch dimension, layer normalization operates on each sample independently, making it well-suited for variable-length sequences and small batch sizes.
The core operation normalizes each token's representation to zero mean and unit variance, then applies learned scale () and shift () parameters to recover representational flexibility. This simple transformation stabilizes activations throughout the network, prevents gradient issues during training, and reduces sensitivity to initialization.
Key takeaways:
- Feature-wise normalization: Layer normalization computes mean and variance across the feature dimension, treating each token independently
- Learnable parameters: and allow the network to undo normalization when beneficial, preserving representational capacity
- Placement matters: Pre-norm (normalize before sublayer) has become the modern standard, improving gradient flow in deep networks
- Epsilon for stability: A small constant prevents division by zero with near-constant inputs
- No batch dependency: Works with any batch size, including single samples during inference
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about layer normalization in transformers.

Comments