

Master scaled dot-product attention with queries, keys, and values. Learn why scaling by √d_k prevents softmax saturation and enables stable transformer training.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Scaled Dot-Product Attention
In the previous chapter, we explored the fundamental pattern of self-attention: compute similarity scores, normalize with softmax, and aggregate values. We used raw embeddings directly, measuring similarity through dot products between embedding vectors. This simplified approach captures the essence of attention, but real transformer models use a more powerful formulation called scaled dot-product attention.
This refinement introduces two key modifications. First, instead of using embeddings directly, we project them into three separate representations: queries, keys, and values. Second, we scale the dot products before applying softmax to prevent numerical instability. These changes might seem minor, but they're essential for training deep attention-based models effectively.
The Query-Key-Value Framework
The insight behind queries, keys, and values comes from information retrieval. Think of a database lookup: you have a query (what you're searching for), a set of keys (labels for stored items), and values (the actual stored content). The lookup process finds keys that match the query and returns the corresponding values.
Self-attention works similarly. For each position in the sequence:
- The query represents what this position is "looking for"
- The keys represent what each position "offers" to be matched against
- The values represent the information each position will contribute to the output
In attention mechanisms, queries, keys, and values are learned linear projections of the input embeddings. The query at position is matched against all keys to determine how much each value contributes to position 's output.
Why not just use the embeddings directly, as we did in the simplified version? The separate projections give the model more flexibility. The query projection can learn to emphasize features that are useful for finding relevant context. The key projection can learn to emphasize features that are useful for being found. And the value projection can learn what information is actually useful to contribute to the output. These are different roles, and separating them allows the model to specialize each representation.
Linear Projections
Given an input sequence of tokens with -dimensional embeddings, we create queries, keys, and values through learned linear transformations:
where:
- is the input embedding matrix (rows are token embeddings)
- projects inputs to queries
- projects inputs to keys
- projects inputs to values
- is the query matrix
- is the key matrix
- is the value matrix
The dimensions (key/query dimension) and (value dimension) are hyperparameters. Often , but they can differ. The critical requirement is that queries and keys must have the same dimension since we'll compute their dot products.
Each token's embedding gets transformed into three distinct vectors. Position produces query , key , and value . The query will be used to find relevant positions; the key will be used to be found; the value will be used to contribute information.
The Dot Product for Similarity
With queries and keys in hand, we need a way to measure how relevant each key is to each query. The dot product provides exactly this: it quantifies how much two vectors point in the same direction. For query and key , the similarity score is:
where:
- : the similarity score between position 's query and position 's key
- : the query vector for position , a -dimensional vector
- : the key vector for position , also -dimensional
- : the -th component of query
- : the -th component of key
- : the dimension of query and key vectors
The dot product measures alignment: if the query and key point in similar directions, the score is high and positive. If they're orthogonal (perpendicular in the -dimensional space), the score is zero. If they point in opposite directions, the score is negative.
To compute all pairwise similarity scores at once, we use matrix multiplication:
where:
- : the score matrix containing all pairwise similarities
- : the query matrix (rows are query vectors)
- : the transposed key matrix (columns are key vectors)
Entry in the resulting matrix tells us how much position 's query matches position 's key. This single matrix multiplication replaces individual dot products.
The score matrix shows the raw dot products between all query-key pairs. Some values are positive (similar directions), others negative (opposite directions). Before we can use these as attention weights, we need to apply softmax. But there's a problem we need to address first.
The Scaling Problem
Consider what happens as the dimension grows. Each dot product is a sum of terms:
where:
- : a query vector of dimension
- : a key vector of dimension
- : the -th component of the query vector
- : the -th component of the key vector
- : the number of dimensions in the query/key space
If the individual components and have unit variance (which is typical after proper initialization), then each product has variance around 1. The sum of independent terms with variance 1 has variance . This means the dot product's magnitude scales with .
Let's verify this empirically:
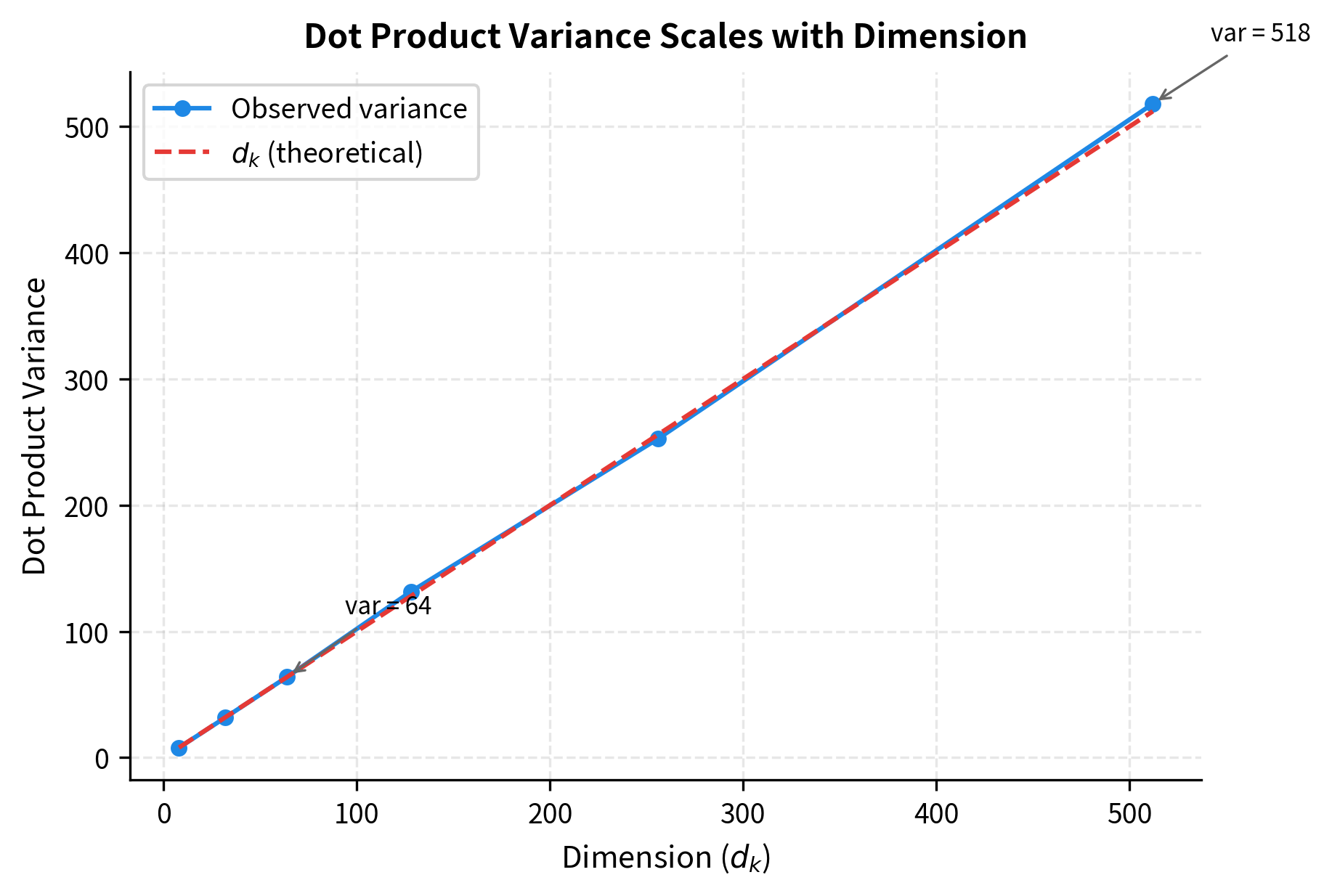
The variance grows exactly as predicted: for , the variance is approximately 512. This means dot products can easily reach magnitudes of 30 or more (since ).
Why does this matter? The softmax function converts scores to probabilities:
where:
- : the attention weight from position to position (how much position attends to position )
- : the raw similarity score between position 's query and position 's key
- : the exponential of the score, ensuring positivity
- : the sum over all positions, normalizing so weights sum to 1
Large input values push softmax into its saturated regime. If one score is significantly larger than the others, the exponential blows up that difference. Consider scores [10, 1, 1, 1]: after softmax, the weights become approximately [0.9999, 0.0001, 0.0001, 0.0001]. The attention becomes nearly one-hot, attending almost exclusively to a single position.
This extreme behavior causes two problems during training. First, gradients become vanishingly small in the saturated regions of softmax, slowing learning. Second, the model loses the ability to express soft, distributed attention patterns. It can only focus sharply on one thing.
With small scores, attention distributes across positions with the highest weight around 0.41 and entropy around 1.26 (fairly distributed). With large scores, attention collapses: the maximum weight approaches 1.0 and entropy drops to nearly 0 (extremely peaked). The model can no longer express nuanced attention patterns.
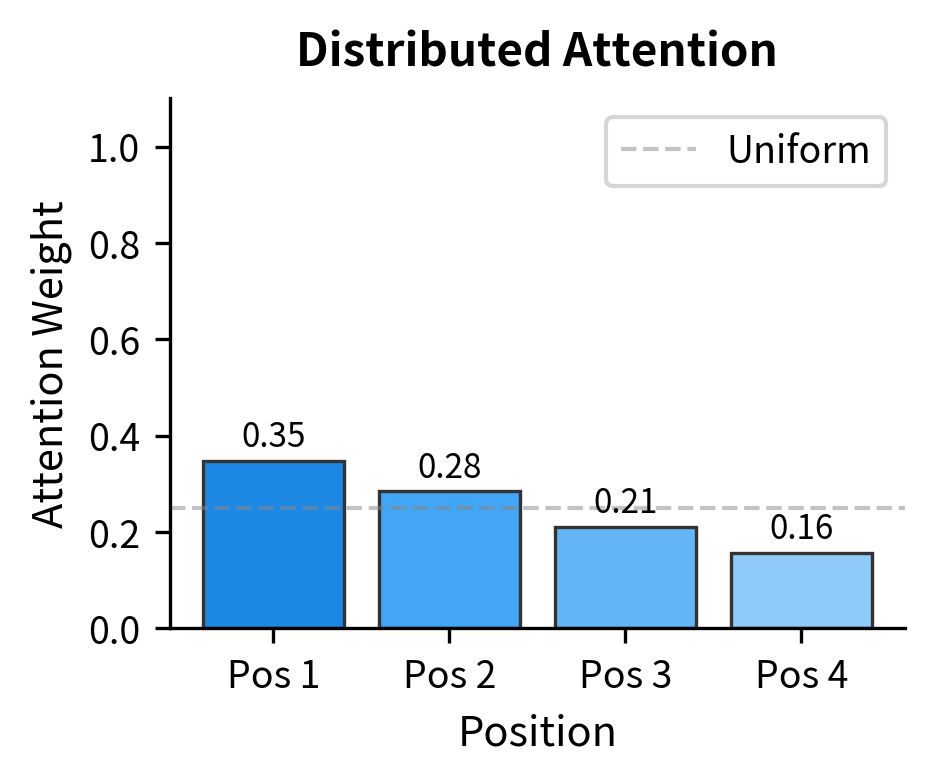
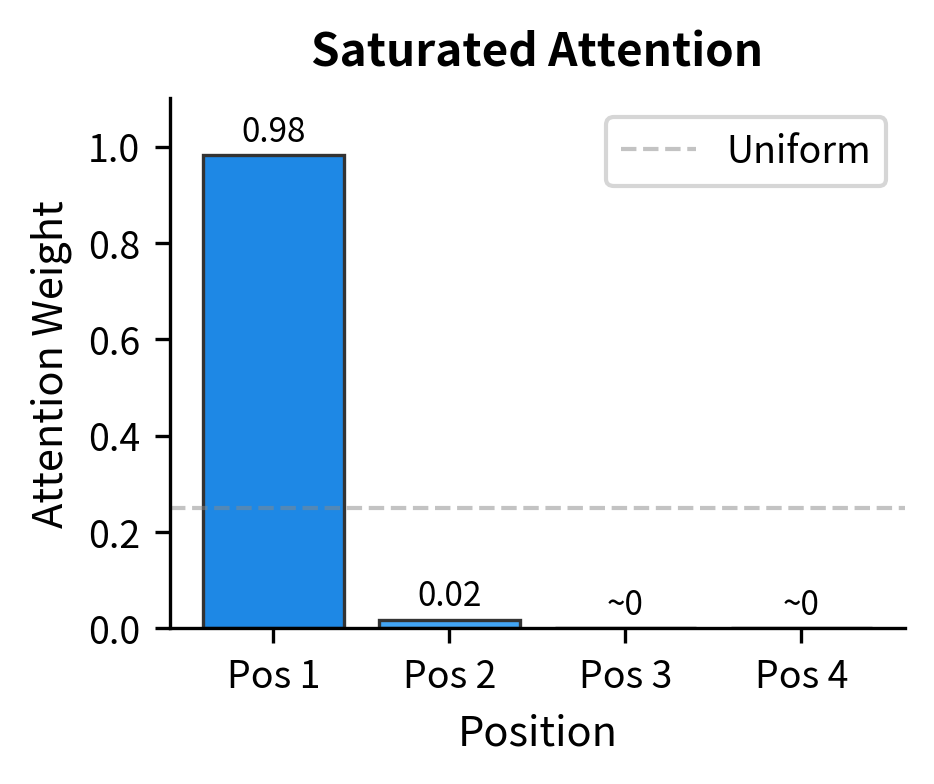
The visualization makes the contrast stark. With small scores, attention is roughly distributed across all four positions. With large scores (20x larger), almost all attention flows to position 1, with the other positions receiving essentially zero weight. This is why scaling is essential: without it, high-dimensional embeddings produce scores so large that softmax always saturates.
The Scaling Factor:
The solution is straightforward: divide the dot products by before applying softmax. Since the dot product variance is , dividing by brings the variance back to 1:
where:
- : the variance operator
- : the dot product between a query and key vector
- : the dimension of query and key vectors
- : the scaling factor applied to the dot product
The key property used here is that when you divide a random variable by a constant , its variance is divided by . Since we divide by , the variance is divided by .
With unit-variance scores, softmax operates in its sensitive region where small changes in scores produce meaningful changes in weights. The model can learn both sharp and soft attention patterns.
The scaling factor normalizes dot product scores to have unit variance regardless of dimension. This prevents softmax saturation and maintains healthy gradients during training.
Derivation of Dot Product Variance
Let's derive why the dot product has variance . Assume and are independent random variables with zero mean and unit variance (typical after proper weight initialization).
Step 1: Variance of a single product term
For a single component product :
- Mean: (by independence)
- Variance:
Each product term has zero mean and unit variance.
Step 2: Variance of the sum (the dot product)
The dot product sums independent terms. When summing independent random variables, variances add:
Step 3: Effect of scaling
Dividing by scales the variance by :
This is why the "Attention Is All You Need" paper prescribes exactly this scaling factor: it ensures unit-variance scores regardless of the embedding dimension.
The Complete Attention Formula
We've now assembled all the pieces: queries that search for relevant context, keys that advertise what each position offers, values that carry the actual information, dot products that measure relevance, scaling that keeps softmax well-behaved, and softmax that converts scores to weights. The complete mechanism chains these operations together into a single formula.
From Components to Formula
Consider what we need to accomplish for each position in the sequence:
- Find relevant positions: Compare this position's query against all keys
- Determine importance: Convert raw similarities into attention weights
- Gather information: Blend all values according to those weights
The formula that captures this entire process is:
where:
- : the query matrix, with one row per position
- : the key matrix, with one row per position
- : the value matrix, containing information to aggregate
- : the dimension of queries and keys (must match for dot product)
- : the dimension of values (can differ from )
- : the sequence length (number of tokens)
- : applied row-wise to convert scores to probability distributions
This formula is read from the inside out, following the order of operations. Let's trace through each stage to understand how the pieces fit together.
Stage-by-Stage Computation
Stage 1: Compute pairwise similarities with
The matrix multiplication computes all query-key dot products simultaneously. When we multiply a query matrix of shape by a transposed key matrix of shape , we get a score matrix of shape . Entry contains the dot product , measuring how much position should attend to position .
Stage 2: Normalize variance with
Before applying softmax, we divide all scores by . As we derived earlier, this keeps the score variance at 1 regardless of dimension, preventing softmax from saturating. Without this scaling, high-dimensional queries and keys would produce scores so large that softmax collapses to near-one-hot distributions.
Stage 3: Convert to probabilities with
Softmax is applied row-wise, so each row of the score matrix becomes an independent probability distribution. Row tells us how position distributes its attention across all positions. The weights are positive and sum to 1, making them valid for computing weighted averages.
Stage 4: Aggregate values with
Finally, we multiply the attention weight matrix by the value matrix. This computes, for each position, a weighted sum of all value vectors. The result is an matrix where row is position 's new representation, enriched with information gathered from across the sequence.
The output is a matrix where each row is the contextual representation for one position, computed as a weighted average of all value vectors according to the attention weights.
Implementation
Translating this formula into code reveals its simplicity. Three matrix operations capture the entire attention mechanism:
The implementation is concise. One matrix multiplication computes all pairwise scores, scalar division handles scaling, softmax normalizes each row, and a final matrix multiplication aggregates the values. This composability is what makes attention so powerful: complex contextual reasoning emerges from simple, differentiable operations.
Let's apply this function to our running example and examine the outputs:
The attention weight matrix has shape : one row for each of our 4 tokens, one column for each potential attention target. Each row sums to exactly 1.0, confirming that softmax produces valid probability distributions. The output has shape , matching our sequence length and value dimension. Each position now carries a contextual representation that blends information from all positions, with the blending proportions determined by the attention weights.
Visualizing the Attention Computation
Let's trace through the complete attention computation visually. We'll use a small example with interpretable tokens to see how each step transforms the data.
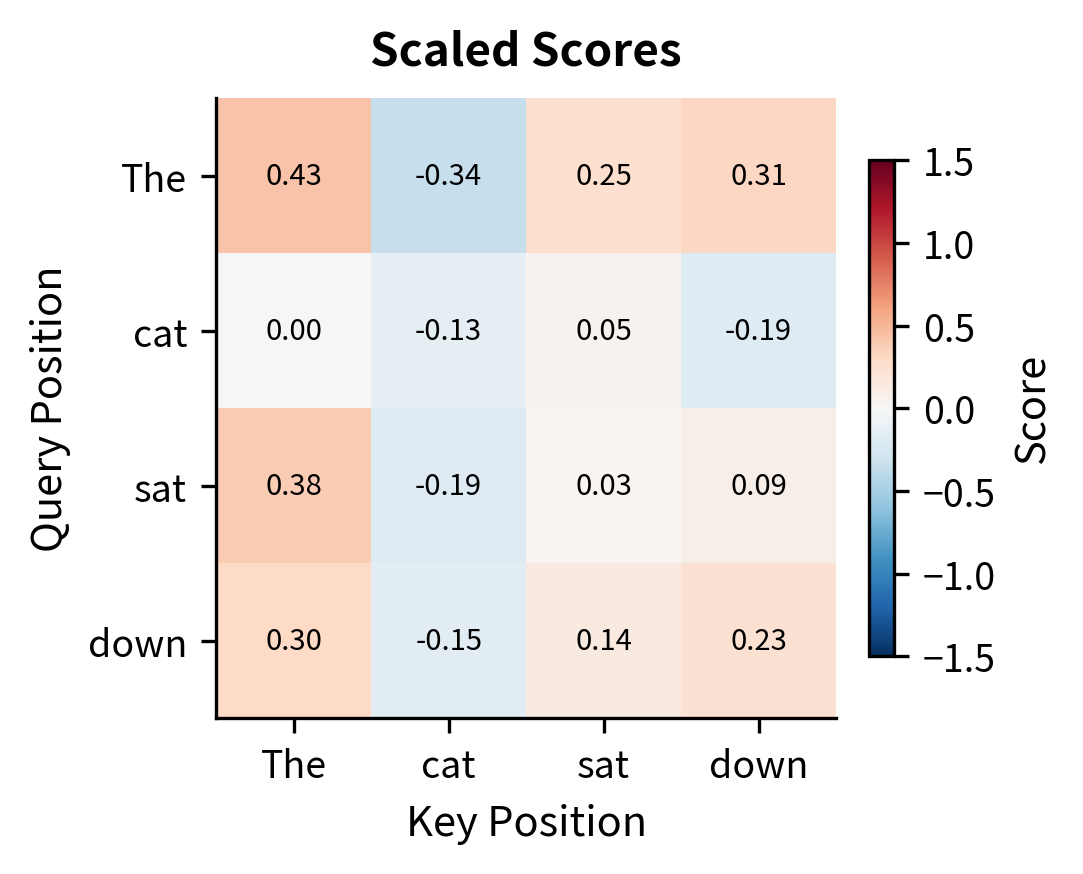
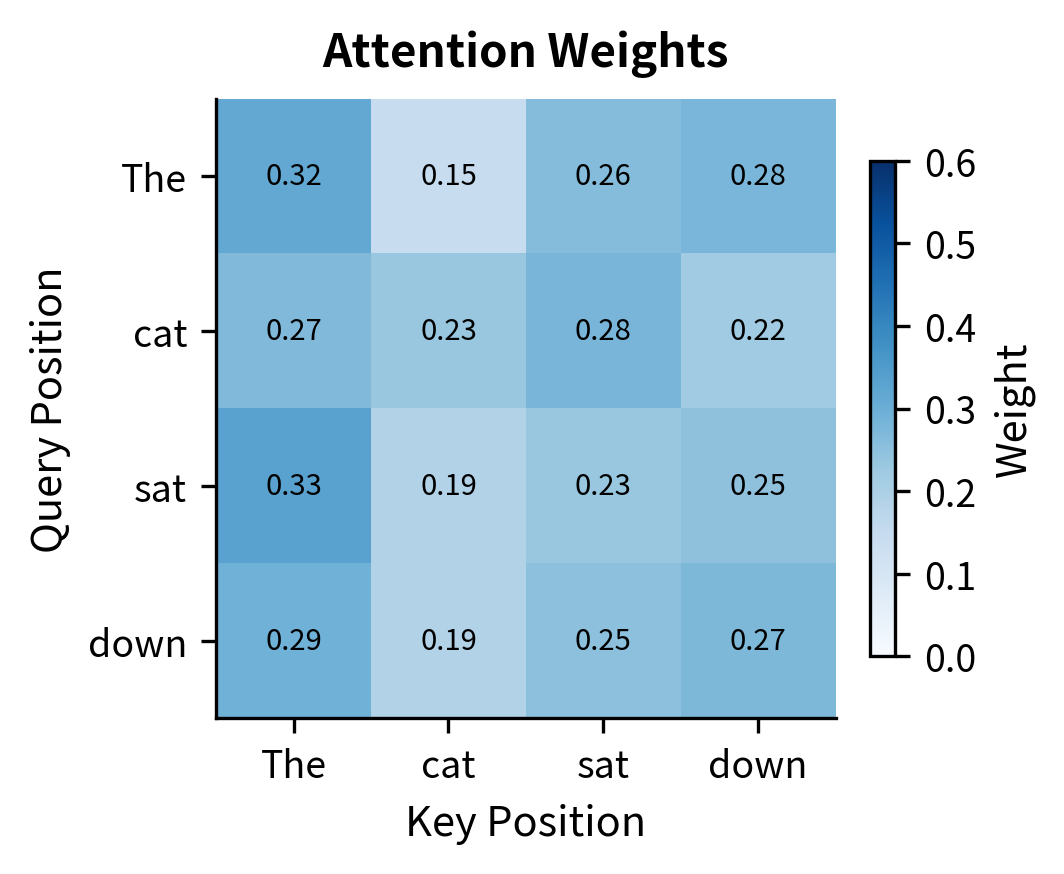
The left panel shows scaled similarity scores ranging roughly from -1 to +1. This moderate range keeps softmax well-behaved. The right panel shows attention weights after softmax, where each row forms a probability distribution. Some positions focus attention sharply (one dominant weight), while others distribute attention more broadly.
Matrix Form and Computational Efficiency
The formula computes everything through matrix multiplications, which are highly optimized on modern hardware.
Let's trace the shapes through the computation:
The attention weight matrix is , which is the source of the quadratic complexity we discussed in the previous chapter. For sequence length , this is a element matrix. For (a moderately long document), it becomes 100 million elements.
However, note that the computations are batch-able. In practice, we process multiple sequences simultaneously:
Batched operations leverage GPU parallelism effectively. All three sequences are processed simultaneously through the same matrix multiplications.
A Complete Worked Example
The formula becomes concrete when we trace through it with actual numbers. Let's work through a minimal example: three tokens with 2-dimensional queries, keys, and values. By keeping the dimensions tiny, we can follow every calculation by hand and build intuition for what the attention mechanism actually computes.
Setting Up the Example
We'll work with three abstract tokens, "A," "B," and "C." In a real model, these would come from learned projections of input embeddings. Here, we'll define them directly with carefully chosen values that have geometric meaning.
The queries have an intuitive geometric interpretation: "A" points due east (along dimension 1), "C" points due north (along dimension 2), and "B" points northeast (equally between both dimensions). The keys are distributed similarly but with different magnitudes. The values are orthogonal basis vectors plus a midpoint, making it easy to see how blending works.
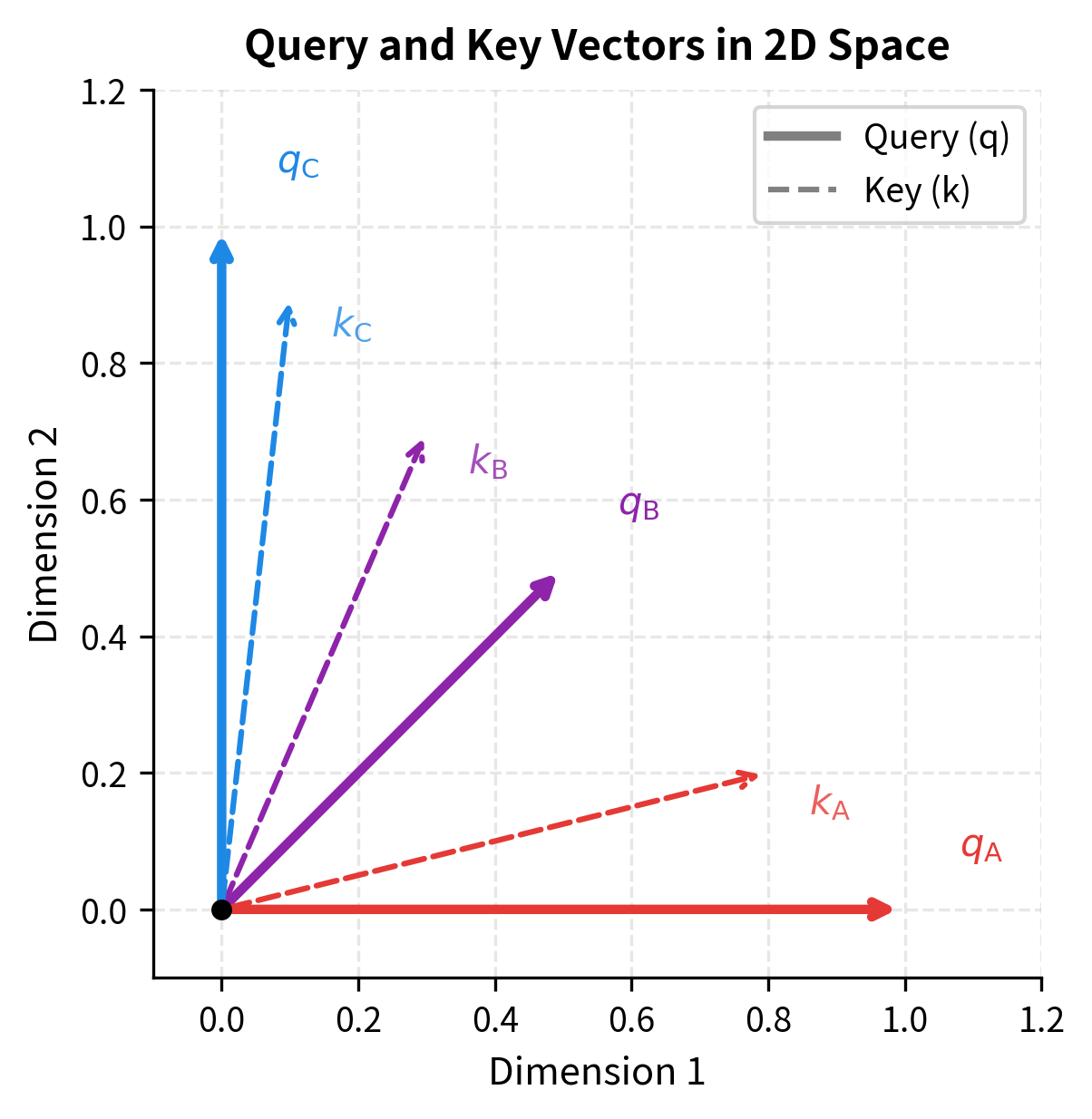
The visualization reveals why certain query-key pairs have high dot products. Query points east and aligns well with key (which also has a strong eastward component), producing a high similarity score. Query points north and aligns best with key (which points mostly north). Query lies between the axes and has moderate similarity with all keys.
Step 1: Compute Raw Similarity Scores
First, we compute the dot product between every query and every key. This measures how well each query-key pair aligns.
Token "A" (with its eastward query) has the highest similarity with key "A" (which also points mostly east) and lowest similarity with key "C" (which points mostly north). This makes geometric sense: parallel vectors have high dot products, perpendicular vectors have low dot products.
Step 2: Apply the Scaling Factor
Next, we divide all scores by . With only 2 dimensions, this scaling is modest, but it becomes crucial in high-dimensional settings.
The scaled scores are smaller in magnitude, keeping them in a range where softmax will produce meaningful gradients. In our 2D example, scores that were around 0.8 become around 0.57. The relative ordering is preserved, but the absolute differences are compressed.
Step 3: Convert to Attention Weights
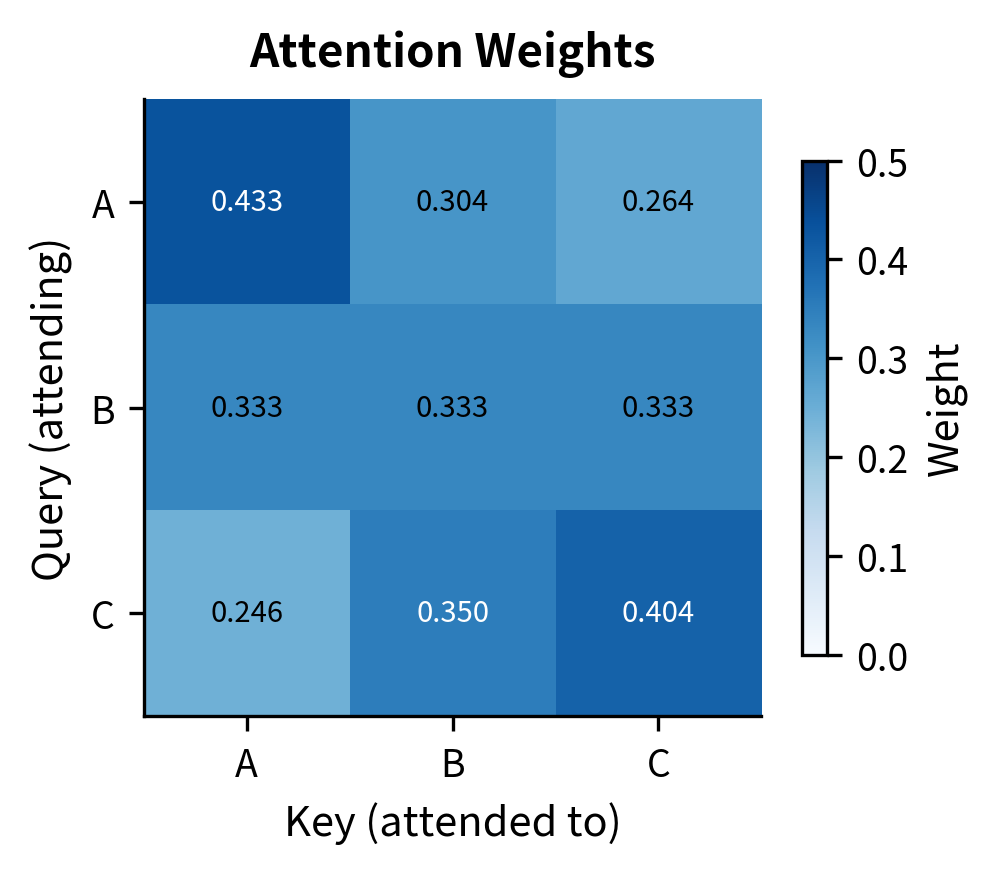
Softmax transforms each row of scaled scores into a probability distribution. Let's trace through the calculation for token "A" in detail.
Each row now sums to 1.0, forming a valid probability distribution. Token "A" attends most strongly to itself (because its query aligned best with its own key), but it also gathers some information from "B" and "C." The attention isn't one-hot; it's a soft distribution that blends information from multiple sources.
Step 4: Aggregate Values
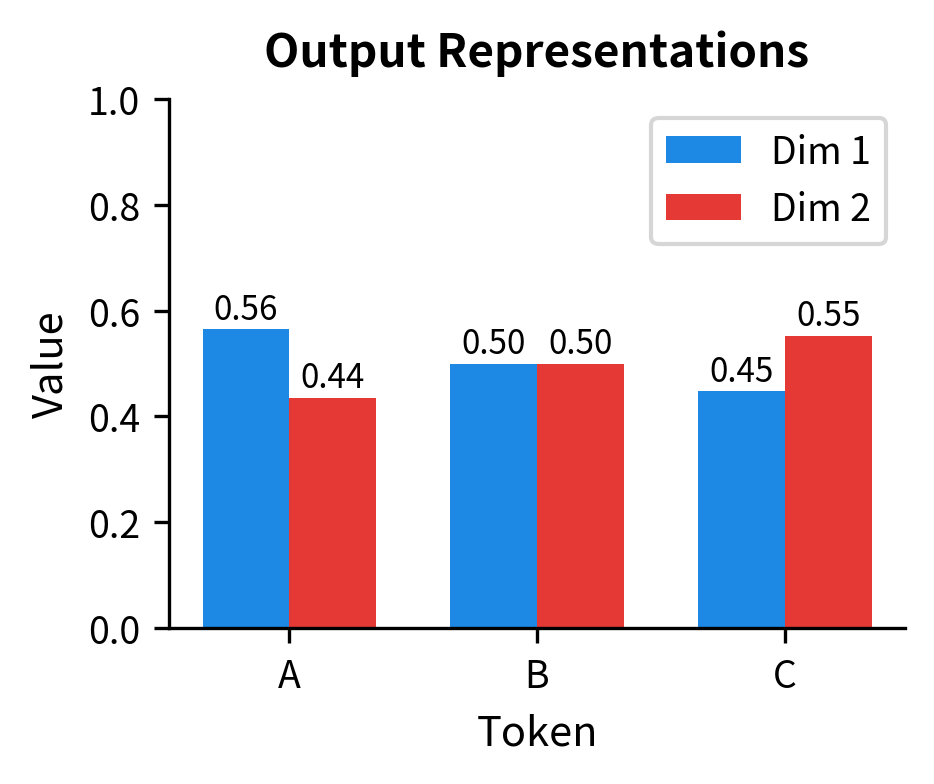
Finally, we use the attention weights to compute a weighted average of all value vectors for each position.
Token "A" started with value but now has an output that incorporates information from all three positions. The output is approximately , reflecting the weighted blend of "A"'s value (weighted ~0.37), "B"'s value (weighted ~0.32), and "C"'s value (weighted ~0.31). The original position-specific information has been enriched with contextual information from the entire sequence.
Comparing Scaled vs Unscaled Attention
To solidify why scaling matters, let's compare attention patterns with and without the factor at different dimensions.
Without scaling, score standard deviation grows with , reaching over 22 at . This pushes the maximum attention weight toward 1.0, meaning attention collapses to near-one-hot. With scaling, score standard deviation stays around 1.0, and maximum weights remain moderate, allowing distributed attention patterns.
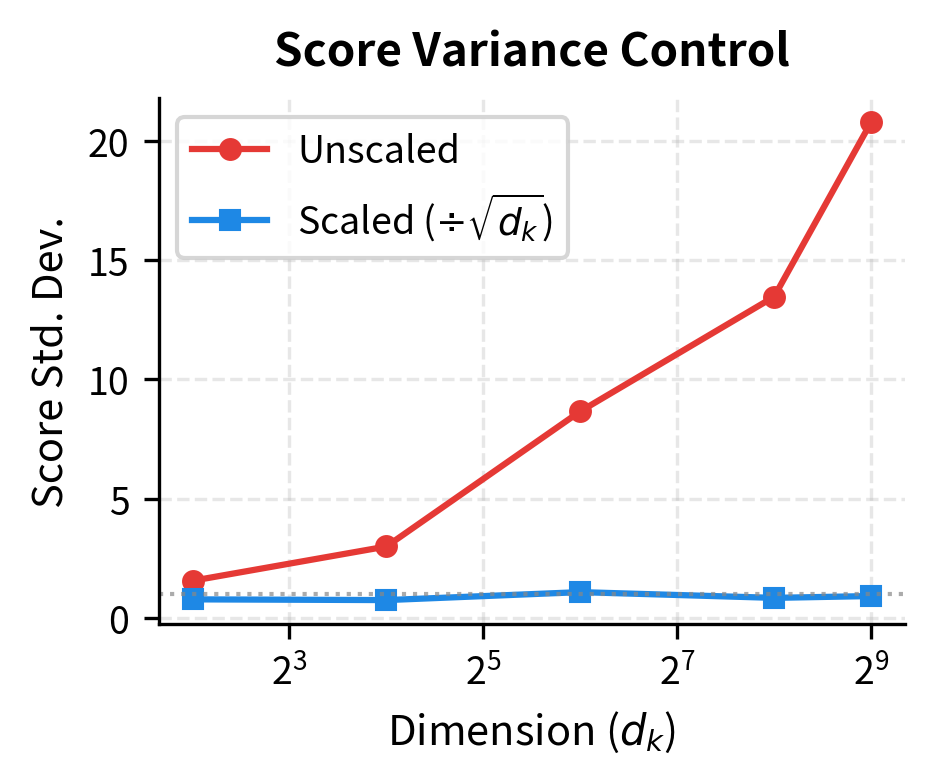
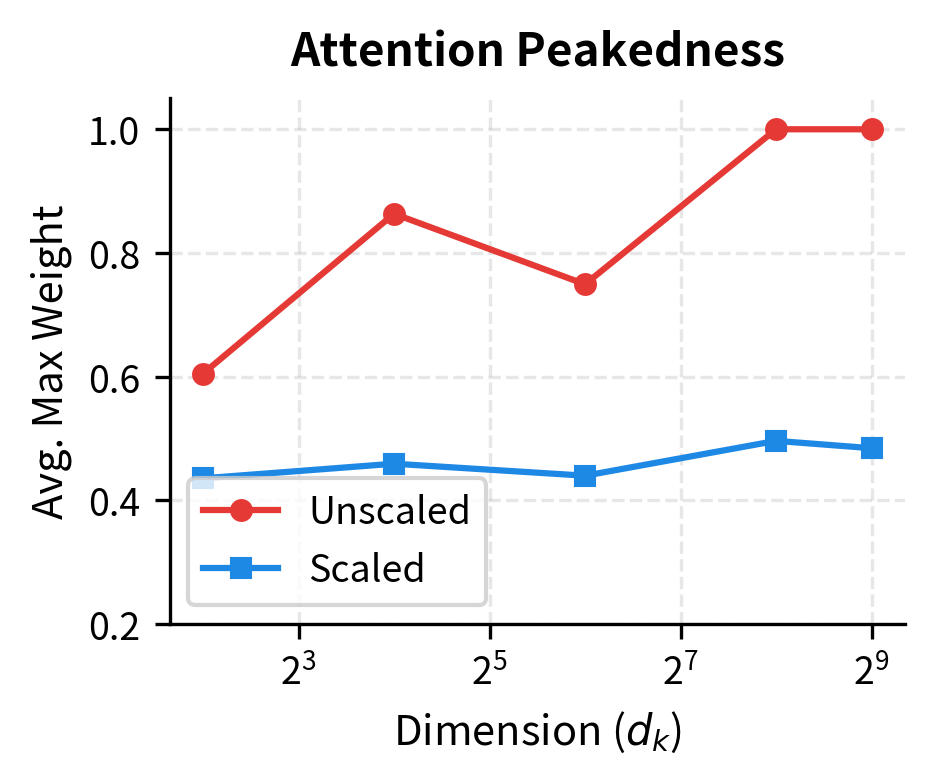
The visualization shows the benefit of scaling clearly. Without it, high-dimensional attention degenerates into hard selection. With it, the model retains the flexibility to express soft, distributed attention patterns throughout training.
Implementation: A Complete Attention Module
Having traced through the formula by hand, we can now build a complete, reusable implementation. This module combines everything we've learned: it takes raw embeddings as input, projects them to queries, keys, and values, computes scaled dot-product attention, and returns contextualized representations.
Module Architecture
A self-contained attention module needs three components:
- Projection matrices: Learned parameters that transform input embeddings into Q, K, and V
- The attention computation: The formula we've been studying
- Proper initialization: Weight scaling that maintains signal magnitude through the network
The implementation follows patterns used in production transformer libraries like PyTorch and TensorFlow:
The __init__ method creates the three projection matrices with Xavier/Glorot initialization, which scales weights by to maintain variance through the network. The __call__ method implements the complete attention pipeline in just five lines: three projections, one scored dot product with scaling, and one value aggregation.
Testing the Module
Let's verify that our implementation works correctly on a realistic example:
The module transforms our 8-token sequence with 32-dimensional embeddings into 8 contextualized representations with 16 dimensions each. The attention weights form an matrix where each row sums to exactly 1.0, confirming that softmax produces valid probability distributions.
From Prototype to Production
This implementation captures the mathematical essence of attention, but production systems add several refinements:
- Dropout: Applied to attention weights during training for regularization
- Batch processing: Handling multiple sequences simultaneously for GPU efficiency
- Autograd integration: Enabling gradient computation for backpropagation
- Numerical precision: Using half-precision floats for memory efficiency on large models
A later chapter on multi-head attention builds directly on this single-head foundation, showing how running multiple attention heads in parallel gives the model different "perspectives" on the same input sequence.
Limitations and Impact
Scaled dot-product attention is the workhorse of modern NLP. The formula encodes both what to attend to (through query-key matching) and what information to gather (through value aggregation). The scaling factor ensures stable training across different embedding dimensions, and the matrix formulation enables efficient GPU parallelization.
The mechanism has several important limitations to keep in mind. The complexity in sequence length remains a fundamental constraint, where is the number of tokens. While the scaling factor helps with numerical stability, it doesn't reduce the quadratic memory and compute requirements. A 4,000-token sequence requires 16 million attention score computations, and an 8,000-token sequence requires 64 million. This motivates research into efficient attention variants like sparse attention, linear attention, and sliding window approaches.
Additionally, standard dot-product attention treats all positions symmetrically. Without positional encodings (covered in a later chapter), the model cannot distinguish "dog bites man" from "man bites dog." The attention mechanism itself is permutation-equivariant: shuffling input positions merely shuffles the output in the same way. External positional information must be injected to break this symmetry.
Despite these constraints, scaled dot-product attention unlocked the transformer architecture and the modern era of large language models. By enabling parallel processing of sequences and providing direct connections between any two positions, it solved the long-range dependency problems that limited recurrent models. The mechanism is simple enough to implement in a few lines of code, yet powerful enough to serve as the foundation for GPT, BERT, and their successors.
Summary
Scaled dot-product attention extends the basic attention mechanism with two key refinements: query-key-value projections and score scaling.
Key takeaways from this chapter:
-
Query-Key-Value framework: Instead of using embeddings directly, we project them into specialized representations. Queries encode "what I'm looking for," keys encode "what I offer," and values encode "what information I contribute."
-
Dot product for similarity: The similarity between query and key is their dot product . In matrix form, computes all pairwise similarities efficiently.
-
Scaling factor : Dot product variance grows with dimension , causing softmax saturation in high dimensions. Dividing by normalizes scores to unit variance, keeping softmax in its sensitive region.
-
The attention formula: combines scoring, normalization, and aggregation into a single differentiable operation.
-
Matrix efficiency: The formula translates directly to matrix multiplications, enabling efficient batch processing on GPUs.
-
Quadratic complexity: Computing requires operations for sequence length . This remains the primary computational bottleneck for long sequences.
In the next chapter, we'll explore attention masking, which allows us to control which positions can attend to which. This is essential for causal language models (where future tokens must not influence past predictions) and for handling variable-length sequences in batches.
Key Parameters
When implementing scaled dot-product attention, several hyperparameters control the model's capacity and behavior:
-
(query/key dimension): Controls the dimensionality of the query and key projections. Larger values increase model capacity but also increase computation. Common choices range from 64 to 128 per attention head. The scaling factor depends directly on this value.
-
(value dimension): Controls the dimensionality of value projections and the output. Often set equal to , but can differ. This determines the size of the contextual representations produced by attention.
-
(input embedding dimension): The dimension of the input token embeddings. The projection matrices , , and transform from to or . Typical values: 256, 512, 768, or 1024.
-
Initialization scale: The projection matrices should be initialized with appropriate variance to maintain signal magnitude. Xavier/Glorot initialization (scaling by ) is commonly used to prevent vanishing or exploding activations.
For practical implementations using PyTorch or similar frameworks, torch.nn.MultiheadAttention handles these details automatically, accepting embed_dim and num_heads as primary parameters and computing per-head dimensions internally.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about scaled dot-product attention.

Comments