

Learn how global tokens solve the information bottleneck in sparse attention by creating communication hubs that reduce path length from O(n/w) to just 2 hops.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Global Tokens
Sparse attention patterns like sliding windows solve the quadratic complexity problem but introduce a new challenge: how does information travel across the full sequence? If each token only attends to nearby neighbors, a token at position 0 cannot directly communicate with a token at position 1000. Information must hop through many intermediate windows, risking degradation along the way. Global tokens solve this by designating certain positions as communication hubs that can attend to and be attended by every position in the sequence.
The Information Bottleneck in Local Attention
Sliding window attention limits each token to a local neighborhood. While efficient, this creates a path length problem reminiscent of RNNs. To transfer information from the start of a document to the end, data must flow through overlapping windows one hop at a time.
Consider a sequence of 4096 tokens with a window size of 512. A token at position 0 can directly see tokens up to position 256 (half the window). To reach position 4000, information must traverse roughly 16 hops through successive windows. Each hop introduces potential for information loss or distortion.
Path length measures the number of attention operations needed for one position to influence another. Standard self-attention has path length 1 (direct connection). Sliding window attention has path length proportional to sequence length divided by window size.
Global tokens restore direct connections by serving as intermediaries. Any token can communicate with any other token by passing through a global token, reducing the maximum path length to 2.
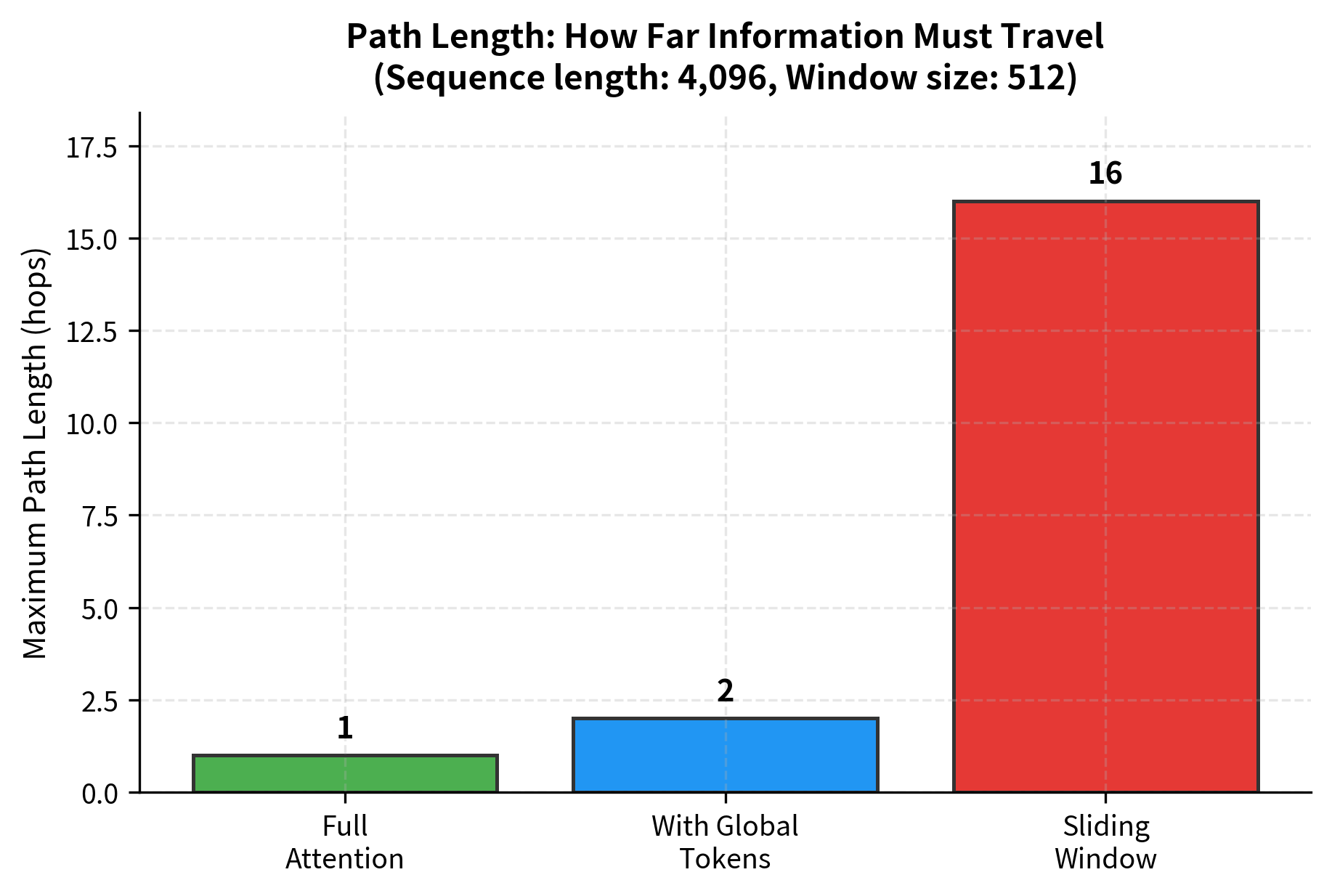
The difference is clear. Sliding window attention requires 16 hops to connect distant positions, while adding just one global token reduces this to 2. This improvement in connectivity comes with minimal computational overhead since only a few tokens become global.
CLS Token as Global Attention
The idea of global tokens predates efficient transformers. BERT's [CLS] token, placed at the start of every sequence, was designed to aggregate sentence-level information. During fine-tuning, the [CLS] representation feeds into classification heads because it has learned to summarize the entire input.
Longformer and BigBird formalized this intuition by giving the [CLS] token bidirectional global attention. In standard BERT, [CLS] only receives information through the normal attention mechanism. In Longformer, [CLS] can attend to every token and every token can attend to [CLS].
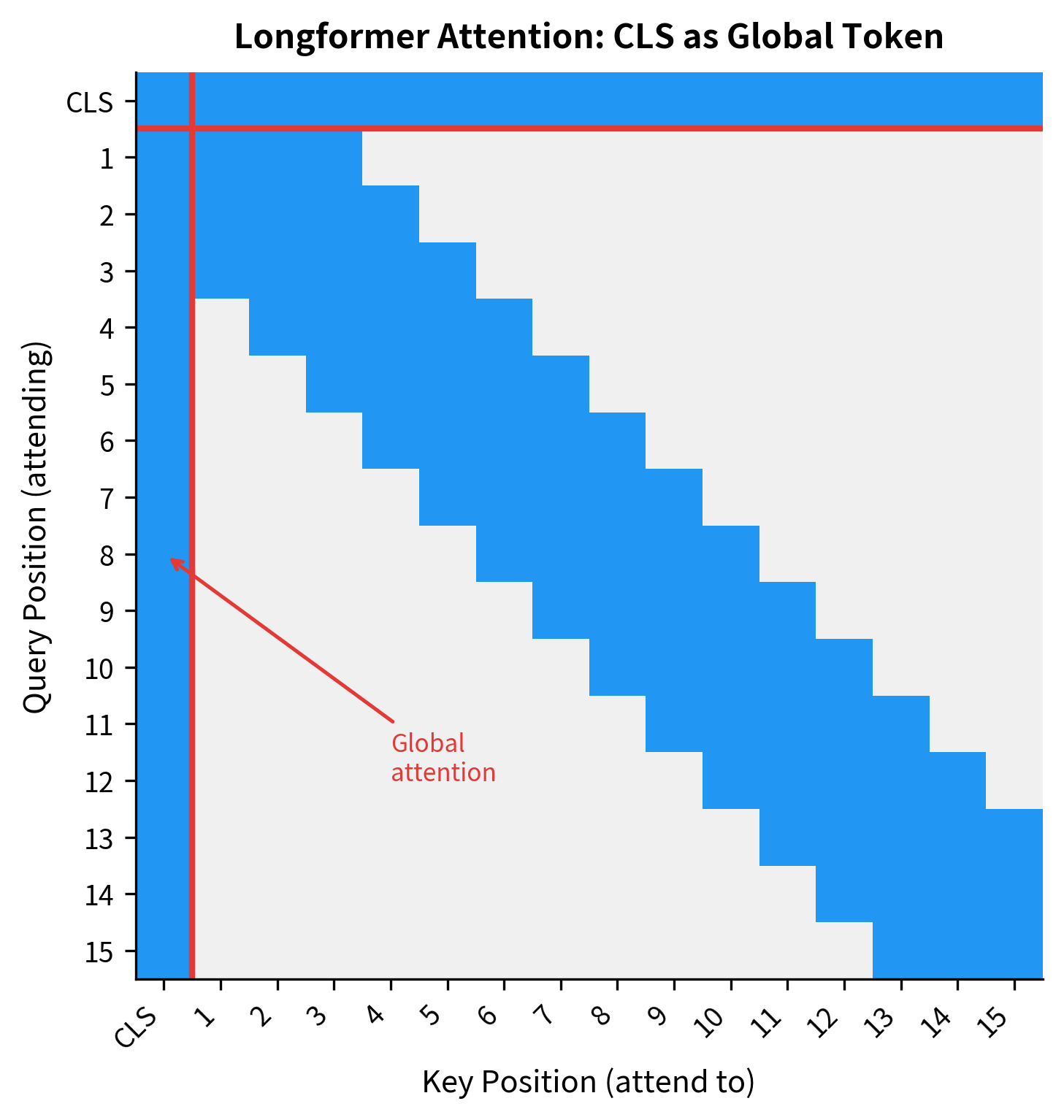
The attention mask reveals the structure. The cross pattern emanating from position 0 shows the CLS token's global connectivity. The diagonal band represents local window attention for all other positions. This combination ensures that every token is at most 2 hops from any other token: local token → CLS → distant local token.
Task-Specific Global Tokens
While CLS provides classification-focused global attention, different tasks benefit from different global token configurations. Question answering, for instance, naturally has two distinct segments: the question and the context passage. Making all question tokens global ensures that every context token can directly attend to the question.
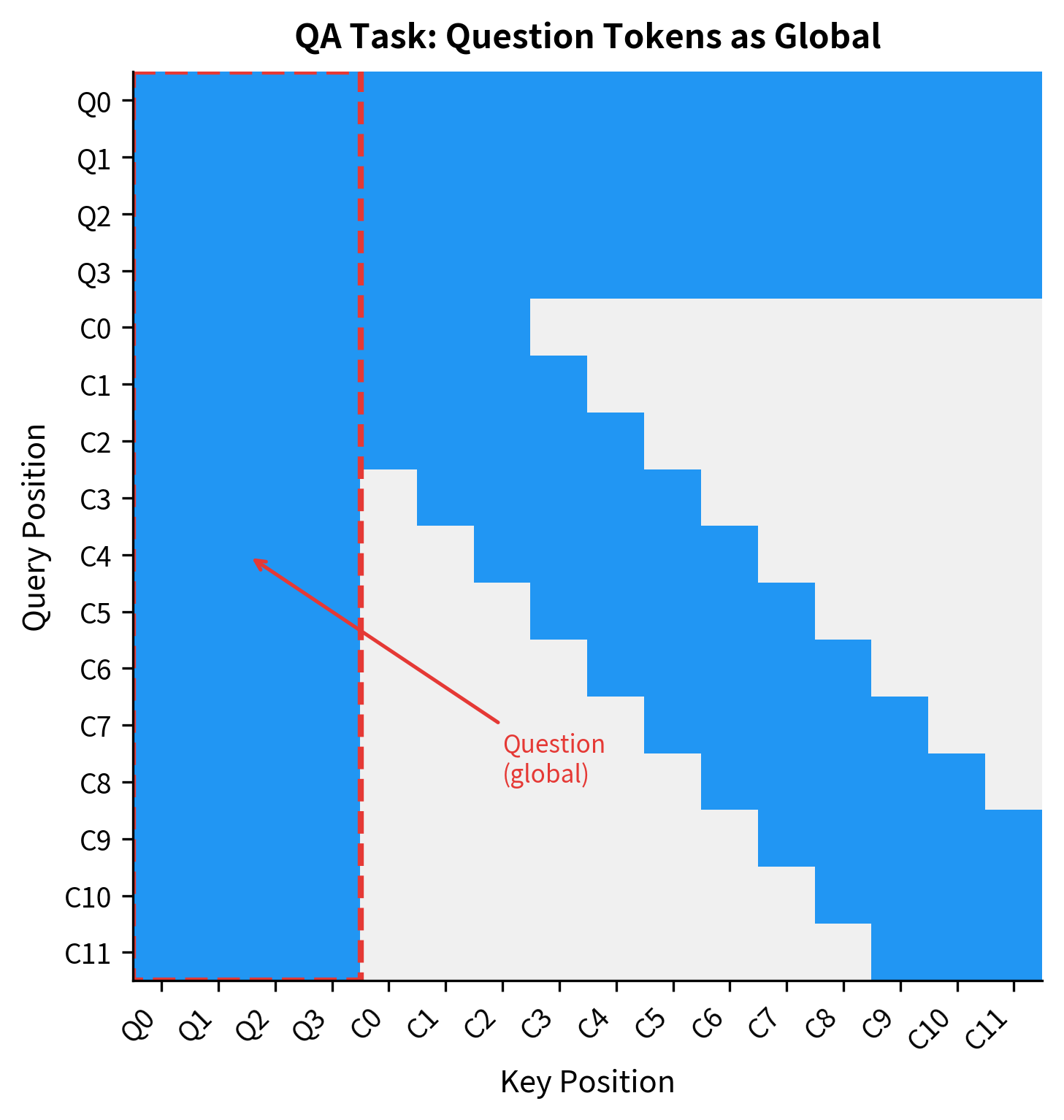
The mask shows a block pattern. The upper-left quadrant is fully connected (question tokens attending to each other). The left columns and top rows extend this connectivity to context tokens. The lower-right shows the sliding window pattern among context tokens.
This task-specific design makes semantic sense. When answering a question, every context word should be able to consider the question directly. Without global question tokens, a context word might need to hop through multiple windows before accessing question information.
Learned Global Tokens
CLS and task-specific tokens are fixed by design. An alternative approach introduces learnable global tokens that the model discovers during training. These tokens don't correspond to any input words but serve purely as memory and communication buffers.
Perceiver and Perceiver IO use this idea extensively. They introduce a small set of latent tokens (often 256-512) that cross-attend to a much longer input sequence. The latent tokens then self-attend among themselves efficiently, and finally cross-attend back to produce outputs.
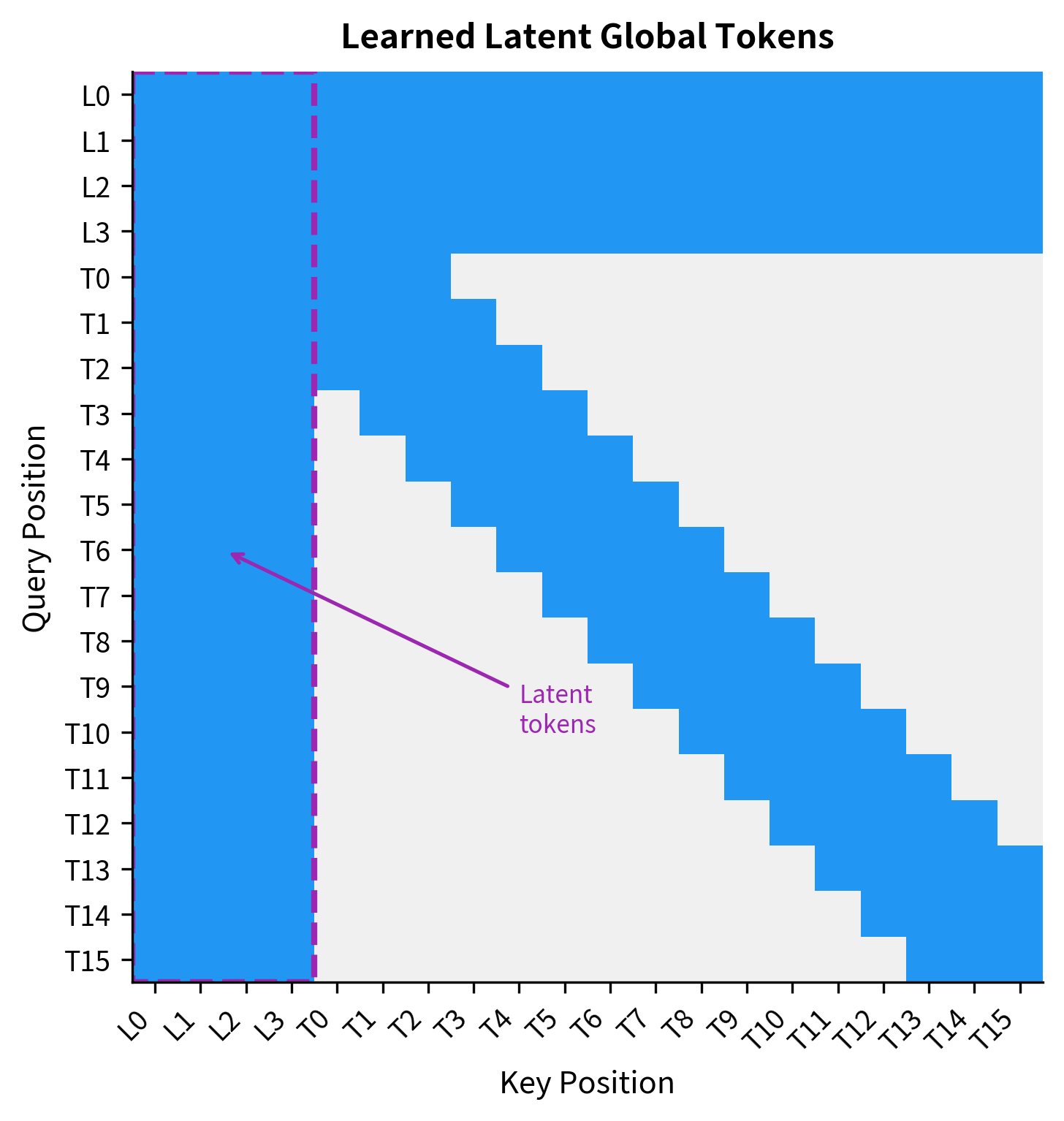
The advantage of learned latents is flexibility. The model can discover what information to store in global memory rather than being constrained to predefined positions. The latent tokens act as a compressed representation of the full sequence, enabling efficient long-range communication.
Global Token Count
How many global tokens do you need? This depends on the task and sequence length. Too few global tokens create an information bottleneck. Too many defeat the purpose of sparse attention by reintroducing quadratic interactions.
For classification tasks with a single CLS token, one global token often suffices. The CLS token aggregates a summary representation, and the classification head only needs this single vector.
For tasks requiring fine-grained outputs (like question answering or named entity recognition), more global tokens help. Making all question tokens global in QA provides richer context for every answer span candidate.
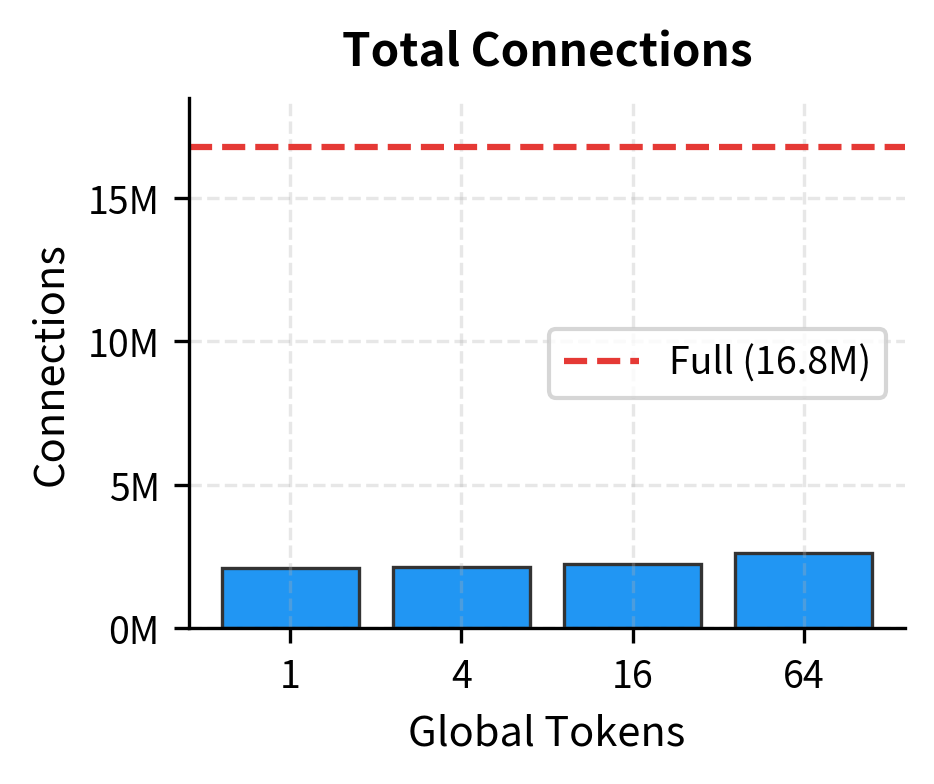
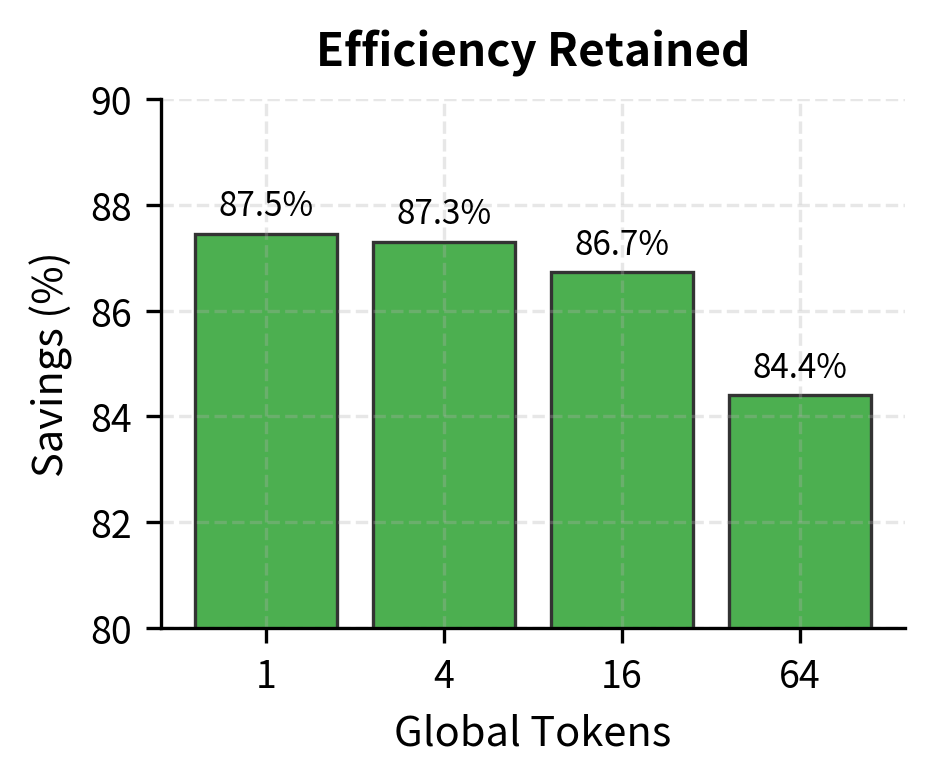
Even with 64 global tokens, we maintain over 84% savings compared to full attention. The marginal cost of additional global tokens is linear in sequence length, not quadratic. This means you can afford to be generous with global tokens for complex tasks without sacrificing efficiency.
Global-Local Attention Mixing
The interplay between global and local attention creates interesting information flow patterns. In a single attention layer, information moves in two streams. The local stream propagates through sliding windows, carrying fine-grained positional information. The global stream broadcasts through designated tokens, providing sequence-wide context.
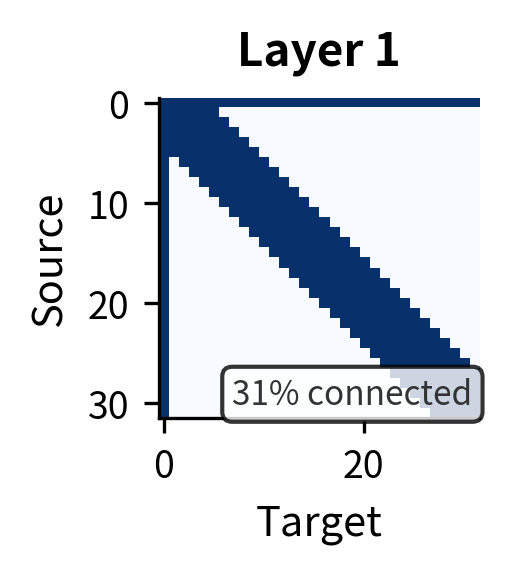
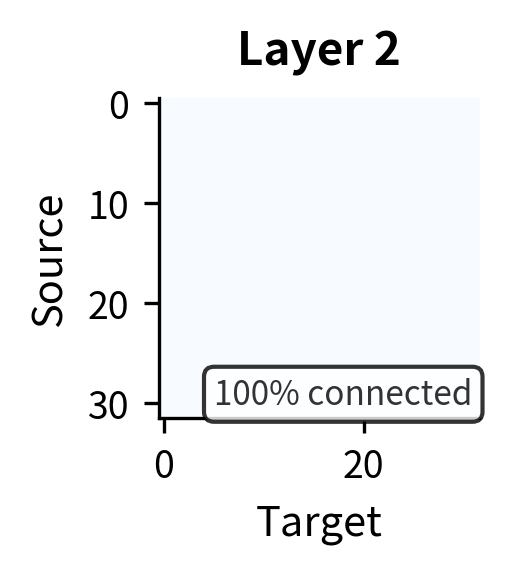
The visualization reveals how quickly information propagates. After just one layer, connectivity is limited to local neighborhoods plus the global token. By layer 2, the global token has served its purpose as a relay: nearly all positions can reach each other through the path local → global → local. By layer 3, full connectivity is achieved.
This suggests that even with aggressive sparsity, a few layers of global-local attention can match the connectivity of full attention. The key insight is that global tokens provide "shortcuts" that reduce the effective diameter of the attention graph.
Implementation Strategies
Implementing global tokens efficiently requires careful attention to the attention computation itself. The naive approach computes global and local attention separately, then merges results. A more efficient approach uses a single sparse attention kernel.
The mask determines which attention scores to compute. Setting masked positions to negative infinity before softmax effectively zeros their contribution to the weighted average. The global tokens see the full sequence in their rows, while local tokens see only their windows plus global positions.
Let's verify the implementation with a small example:
Global positions connect to all 16 tokens. Local positions connect to their window (4-5 tokens) plus the 2 global tokens, totaling around 6-7 connections each.
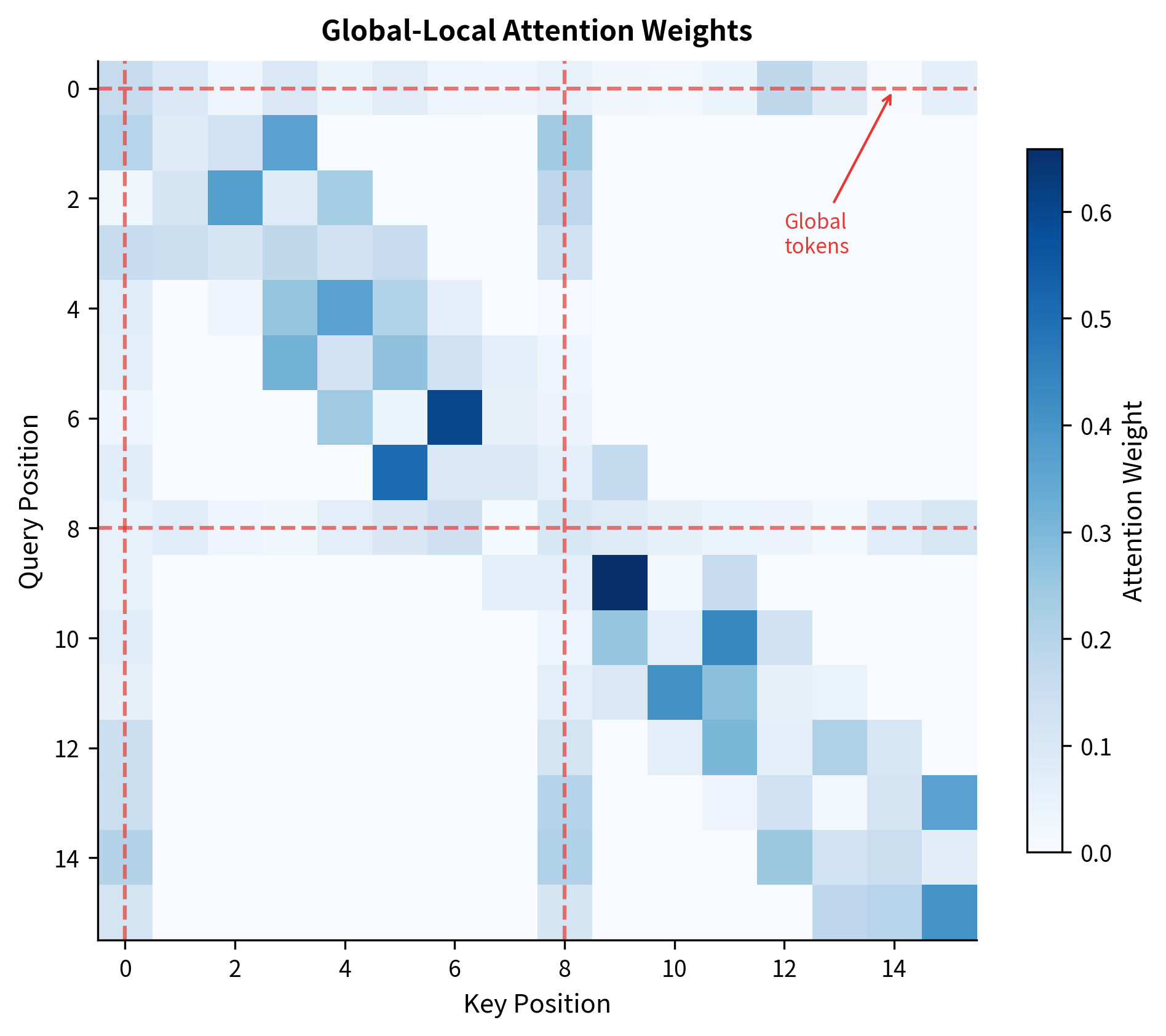
The attention weight heatmap shows the characteristic pattern. The global token rows (0 and 8) have distributed attention across all positions. The local token rows show concentrated attention within their windows, with visible bumps at columns 0 and 8 where they attend to global tokens.
Comparison: Different Global Token Strategies
Different architectures use global tokens in distinct ways. Understanding these variations helps when choosing or designing efficient attention mechanisms.
| Strategy | Global Tokens | Use Case | Advantages |
|---|---|---|---|
| CLS-only (Longformer) | First token | Classification | Simple, single aggregation point |
| Task-specific (QA) | Question tokens | Extractive tasks | Semantic alignment with task structure |
| Periodic (BigBird) | Every k-th token | General | Uniform coverage, no special tokens needed |
| Learned latents (Perceiver) | Separate buffer | Multimodal, long sequences | Flexible, task-agnostic |
Each strategy makes trade-offs. CLS-only is simplest but creates a single bottleneck. Task-specific requires knowing the task structure. Periodic global tokens offer even coverage but may waste capacity on uninformative positions. Learned latents are most flexible but add trainable parameters.
All strategies maintain significant savings compared to full attention. The periodic strategy with 8 global tokens has higher density (more connections) but still achieves over 80% savings. The choice depends on whether you need uniform global coverage (periodic) or task-aligned global positions (CLS, question tokens).
Limitations and Impact
Global tokens solve the long-range dependency problem in sparse attention, but they come with limitations.
The primary limitation is the potential information bottleneck. A single CLS token must compress an entire document's worth of information into one vector. For long documents with diverse content, this creates pressure on the token's representation capacity. Tasks requiring fine-grained global reasoning may need multiple global tokens, increasing complexity.
Global tokens also introduce asymmetry in the attention pattern. The CLS token sees everything, while other tokens see only windows plus global positions. This asymmetry can lead to uneven gradient flow during training, with global token parameters receiving disproportionately large updates. Careful initialization and learning rate scheduling help mitigate this issue.
Despite these limitations, global tokens work well in practice. Longformer achieved state-of-the-art results on long-document tasks like WikiHop and TriviaQA. The ability to process 4096+ tokens efficiently opened new applications in document understanding, long-form question answering, and summarization. BigBird extended this further with theoretical guarantees about universal approximation.
The conceptual impact may be even more significant. Global tokens demonstrate that carefully designed sparse patterns can match or exceed the performance of full attention while being much more efficient. This principle has influenced subsequent architectures, from Perceiver's latent arrays to modern retrieval-augmented models that retrieve relevant context rather than attending to everything.
Key Parameters
When implementing global-local attention, several parameters control the trade-off between efficiency and expressiveness:
-
window_size: The number of tokens each position can attend to locally. Larger windows capture more local context but increase computation. Typical values range from 256 to 512 for long-document models. The window should be large enough to capture phrase-level dependencies. -
global_positions: A list of token indices designated as global. Common strategies include:- First position only (CLS token) for classification
- First and last positions (CLS + SEP) for sequence-pair tasks
- All question tokens for extractive QA
- Every k-th position for uniform coverage
-
num_global: The count of global tokens. More global tokens reduce the information bottleneck but add connections where is the global count and is sequence length. Start with 1-4 global tokens and increase if task performance plateaus. -
d_k: The dimension used for scaling attention scores. Standard practice sets this equal to the model's head dimension (typically 64). Scaling by keeps attention logits in a stable range regardless of dimensionality.
Summary
Global tokens bridge efficient local attention and effective long-range modeling. By designating certain positions as communication hubs with full attention span, they reduce the maximum path length between any two positions to just 2 hops.
Key takeaways:
- The bottleneck problem: Sliding window attention limits direct communication to local neighborhoods, requiring many hops for long-range information flow.
- Global tokens as hubs: Designated positions that can attend to and be attended by all positions, serving as relay points for sequence-wide communication.
- CLS token attention: BERT's classification token naturally fits the global attention role, aggregating sequence information for downstream tasks.
- Task-specific globals: Question tokens in QA, separator tokens in sentence pairs, or any semantically meaningful positions can serve as global tokens.
- Learned latents: Trainable global tokens that discover what information to aggregate, offering flexibility at the cost of additional parameters.
- Efficient scaling: Global token count scales linearly, so even many global tokens preserve the efficiency gains of sparse attention.
- Reduced path length: With global tokens, maximum path length drops from to 2, where is the sequence length and is the window size. This matches full attention's connectivity properties.
The next chapter examines Longformer, which combines sliding window attention with global tokens into a complete architecture. We'll see how these components work together to achieve strong performance on document-level NLP tasks while maintaining linear complexity in sequence length.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about global tokens in efficient transformers.

Comments