

Learn how FlashAttention achieves 2-4x speedups by restructuring attention computation. Covers GPU memory hierarchy, tiling for SRAM, online softmax computation, and the recomputation strategy for training.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
FlashAttention Algorithm
Efficient attention mechanisms like sparse patterns and sliding windows reduce computation by attending to fewer positions. FlashAttention takes a fundamentally different approach: it computes exact standard attention but restructures the computation to be memory-efficient. The algorithm achieves 2-4x speedups over optimized implementations by exploiting the memory hierarchy of modern GPUs. Rather than approximating attention, FlashAttention computes the mathematically identical result while avoiding the memory bottleneck that makes standard attention slow.
This chapter explains the key ideas behind FlashAttention: why GPU memory hierarchy matters, how tiling enables memory-efficient computation, how online softmax makes tiling possible, and why recomputation during backpropagation saves more memory than it costs. Understanding these principles prepares you to use FlashAttention effectively and appreciate why it has become the default attention implementation in production systems.
GPU Memory Hierarchy
To understand why FlashAttention works, you first need to understand why standard attention is slow. The bottleneck is not computation but memory bandwidth. Modern GPUs can perform trillions of floating-point operations per second, but reading and writing data to memory is orders of magnitude slower than computing on that data.
GPUs have a hierarchical memory structure with different levels offering different trade-offs between capacity and speed:
GPU memory is organized into multiple levels. High Bandwidth Memory (HBM) provides large capacity (tens of gigabytes) but relatively slow access. Shared Memory / SRAM provides fast access (10-20x faster than HBM) but limited capacity (tens to hundreds of kilobytes per streaming multiprocessor). Registers provide the fastest access but extremely limited capacity.
The key insight is that moving data between memory levels dominates execution time for many operations. A typical GPU might have:
- HBM: 40-80 GB capacity, ~2 TB/s bandwidth
- SRAM (shared memory): 192 KB per SM, ~19 TB/s bandwidth
- Registers: Limited per thread, essentially zero latency
The bandwidth ratio between SRAM and HBM is roughly 10x. When an algorithm repeatedly reads and writes to HBM, it becomes "memory-bound," meaning computation stalls waiting for data transfers. Standard attention exhibits exactly this pattern.
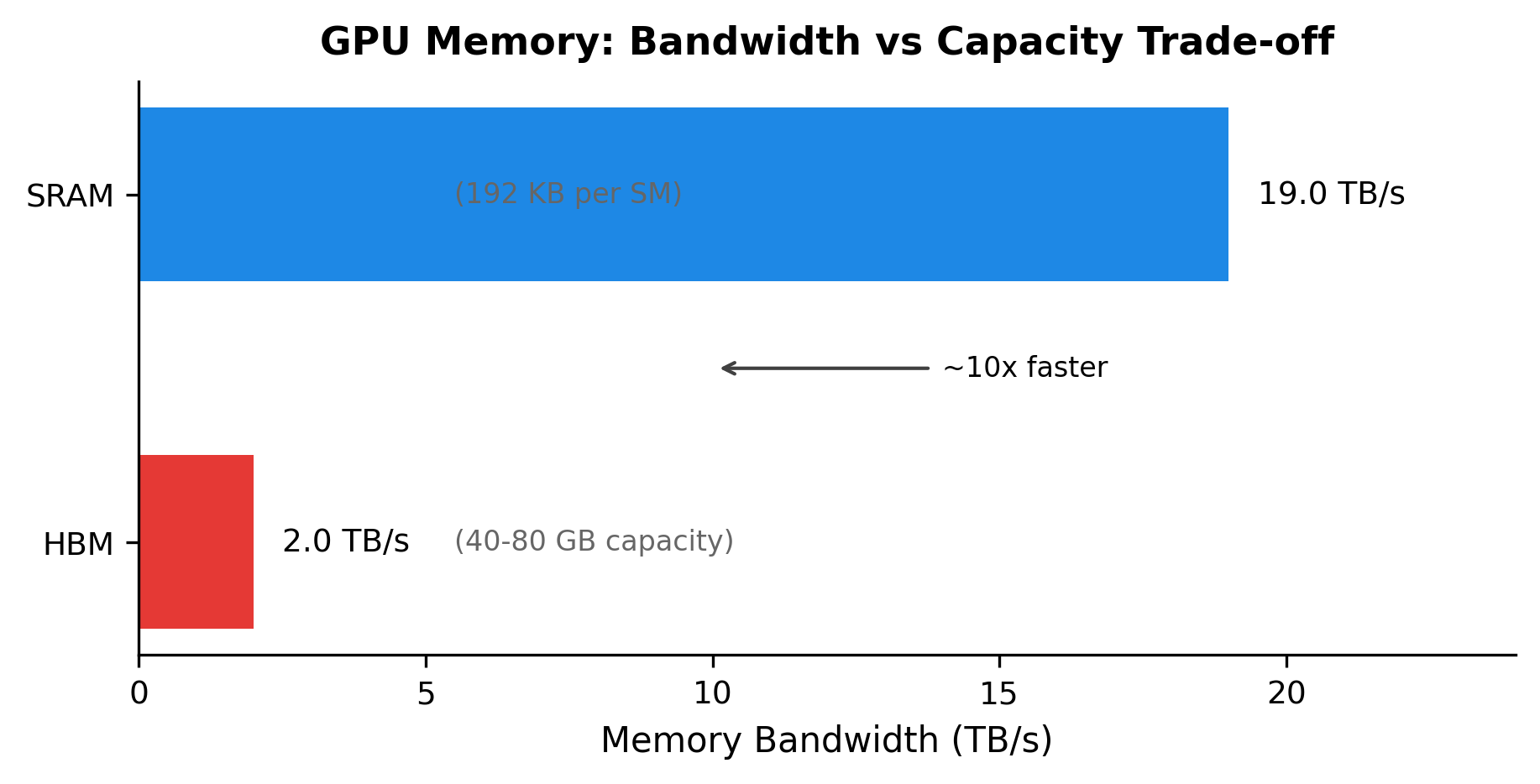
The visualization makes the bandwidth gap concrete. SRAM is nearly 10x faster than HBM, but it's also 100,000x smaller. FlashAttention's tiling strategy keeps the hot data (attention score blocks and running statistics) in SRAM, reading from HBM only for Q, K, V and writing only the final output.
The analysis reveals the source of FlashAttention's speedup. Standard attention writes the attention matrix to HBM, then reads it back for softmax, then writes the softmax output, then reads it again for the final matrix multiplication. Each of these transfers takes time. FlashAttention avoids materializing the attention matrix entirely, reducing memory transfers by 10-100x for long sequences.
Why Memory Matters More Than FLOPs
Consider the arithmetic intensity of attention: the ratio of floating-point operations to bytes transferred. Arithmetic intensity determines whether an operation is compute-bound (limited by processing speed) or memory-bound (limited by data transfer speed). Standard attention computes roughly FLOPs but moves bytes for the attention matrix alone, where is sequence length and is head dimension. When is large, the memory bandwidth becomes the limiting factor because the memory transfers grow faster than they can be processed.
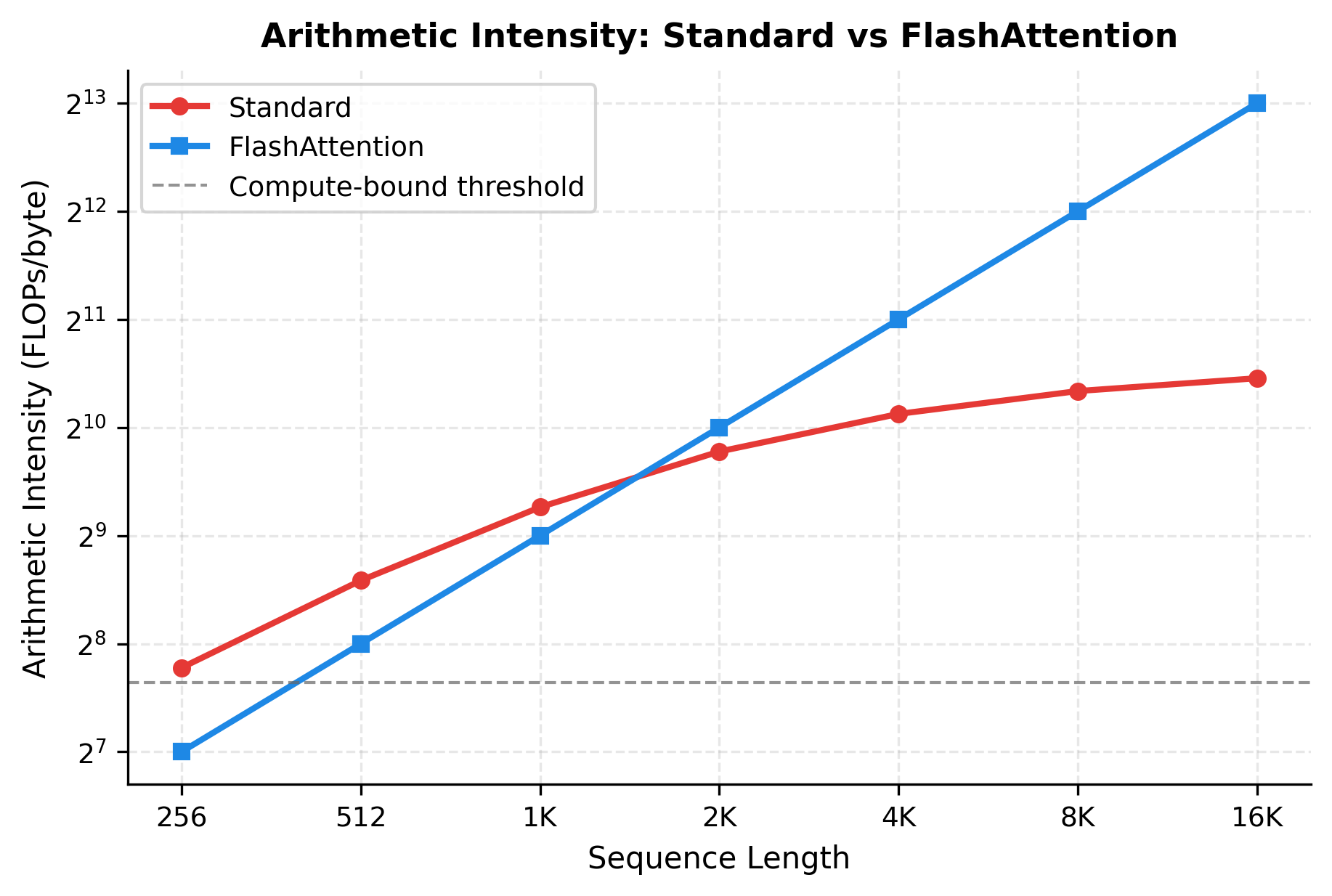
The plot reveals a fundamental difference. Standard attention's arithmetic intensity decreases as sequence length grows because the memory transfers dominate. FlashAttention maintains high arithmetic intensity by avoiding HBM transfers for intermediate results. Above the "compute-bound threshold" (around 200 FLOPs/byte for modern GPUs), the GPU operates efficiently. Below it, the GPU stalls waiting for memory.
Tiling for SRAM
The core insight of FlashAttention is to restructure the attention computation so that all intermediate values fit in SRAM rather than spilling to HBM. This restructuring uses a technique called tiling: breaking the large attention computation into small blocks that fit entirely in fast memory.
The Tiling Strategy
Consider computing attention for a sequence of tokens. Standard attention materializes the entire attention score matrix at once, which requires memory. FlashAttention processes the computation in blocks of size , where and are chosen so that the required data fits in SRAM.
FlashAttention processes queries in blocks of rows and keys/values in blocks of columns. These block sizes are chosen based on SRAM capacity: typically to depending on the GPU architecture and model dimension.
The algorithm proceeds as follows:
- Load a block of queries into SRAM
- For each block of keys and values, load them into SRAM, compute attention scores, update running statistics, and accumulate the output
- Write the final output for these queries to HBM
- Repeat for the next block of queries
The key point is that only blocks reside in SRAM at any time, never the full matrix. The memory required is:
where:
- : the number of query rows in each block
- : the number of key/value columns in each block
- : the head dimension (size of each query, key, and value vector)
- : memory for the block of attention scores
- : memory for query vectors and output accumulator
- : memory for key and value vectors
Since , , and are all constants chosen at compile time, this memory requirement is independent of sequence length .
Typical GPU SRAM per streaming multiprocessor is around 192 KB. The table shows that even with generous block sizes of and head dimension 64, the total SRAM usage stays under 50 KB, well within that capacity. This leaves room for additional working memory and allows multiple thread blocks to run concurrently.
Visualizing the Tiling Pattern
The tiling pattern creates a block structure in the attention computation. Rather than computing the full attention matrix at once, FlashAttention computes it block by block, accumulating results as it goes.
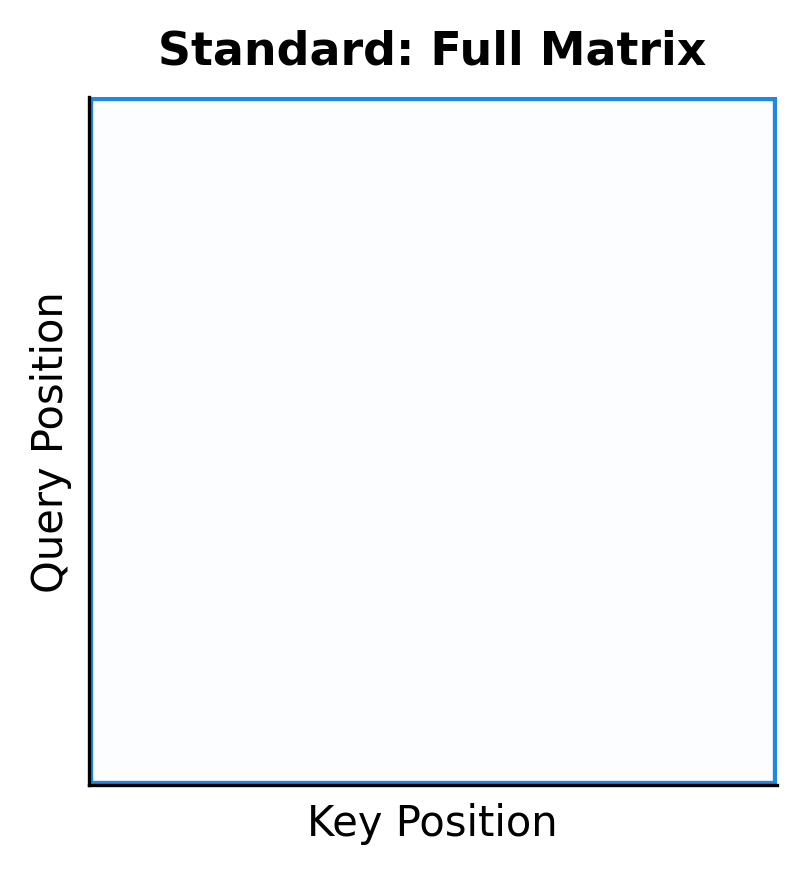
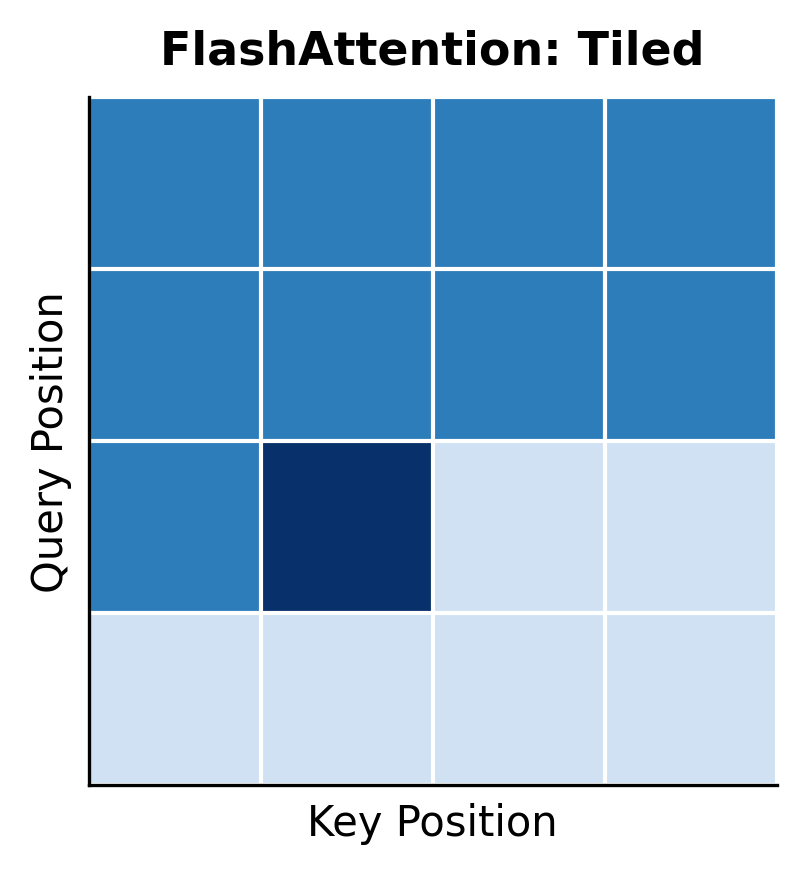
The visualization shows the fundamental difference. Standard attention fills the entire matrix (left), storing all values in HBM. FlashAttention processes one block at a time (right, with the current block highlighted), keeping only that block in fast SRAM. Completed blocks are not stored; instead, their contribution to the output is accumulated incrementally.
Online Softmax Computation
Tiling creates an elegant solution for memory but introduces a subtle mathematical challenge. Softmax requires global information: to normalize any single attention score, you must know the sum of exponentials across the entire row. How can we compute softmax incrementally when we only see one block of keys at a time?
The Challenge: Softmax Needs Global Information
Consider the standard softmax formula:
where:
- : the -th attention score in a row (the score we want to normalize)
- : the exponential of that score, ensuring a positive value
- : the sum of exponentials over all scores in the row, serving as the normalizing constant
- : the total number of positions in the sequence
The denominator presents our problem: we need to sum over all positions, but we're processing keys in blocks. After seeing only the first block, we don't know what scores the remaining blocks will contribute. How can we produce a valid softmax output without waiting until all blocks are processed?
The answer lies in a clever reformulation: rather than computing softmax in one pass, we maintain running statistics that allow us to incrementally update our computation as new blocks arrive. This technique, called online softmax, is the mathematical heart of FlashAttention.
Building Intuition: What Statistics Do We Need?
Before diving into formulas, let's think about what information we need to maintain across blocks. Softmax has two key properties we must preserve:
-
Numerical stability: Exponentiating large values causes overflow. The standard trick is to subtract the maximum value before exponentiating: instead of .
-
Normalization: The outputs must sum to 1, which requires knowing the total sum of exponentials.
This suggests we need to track two running statistics:
- The maximum score seen so far (for numerical stability)
- The running sum of exponentials (for normalization)
But here's the subtlety: when we see a new block with a larger maximum, we need to retroactively adjust our previous contributions. The exponentials we computed earlier were relative to the old maximum, and now they need to be relative to the new maximum.
The Online Softmax Algorithm
After processing block , we maintain two statistics:
- : the maximum value seen so far (over all blocks 1 through )
- : the sum of exponentials , where each exponential is computed relative to the current maximum
When block arrives with new attention scores , we update both statistics in sequence. First, we update the running maximum:
where:
- : the updated maximum after seeing block
- : the previous maximum (from blocks 1 through )
- : the largest score in the new block
This simply takes the larger of the old maximum and the new block's maximum. The maximum can only increase or stay the same, never decrease.
Now comes the crucial step. The running sum was computed relative to , but we need all exponentials relative to . We must rescale the previous sum:
where:
- : the updated sum of exponentials after block
- : the previous sum (computed with respect to )
- : the rescaling factor that adjusts the old sum for the new maximum
- : the contribution from the new block, computed relative to the new maximum
Why the Rescaling Factor Works
The rescaling factor deserves careful attention. It's the key that makes online softmax mathematically exact.
Consider what happens in two cases:
Case 1: The new block has a larger maximum ()
The exponent is negative, so the factor is less than 1. This correctly shrinks the previous contributions. Why? Because we originally computed , but now we need . By the properties of exponents:
Case 2: The new block doesn't change the maximum ()
The exponent is zero, so the factor equals 1. The previous contributions remain unchanged, which is correct since no rescaling is needed.
This rescaling mechanism is what allows us to process blocks incrementally while guaranteeing the exact same result as computing softmax over all values at once.
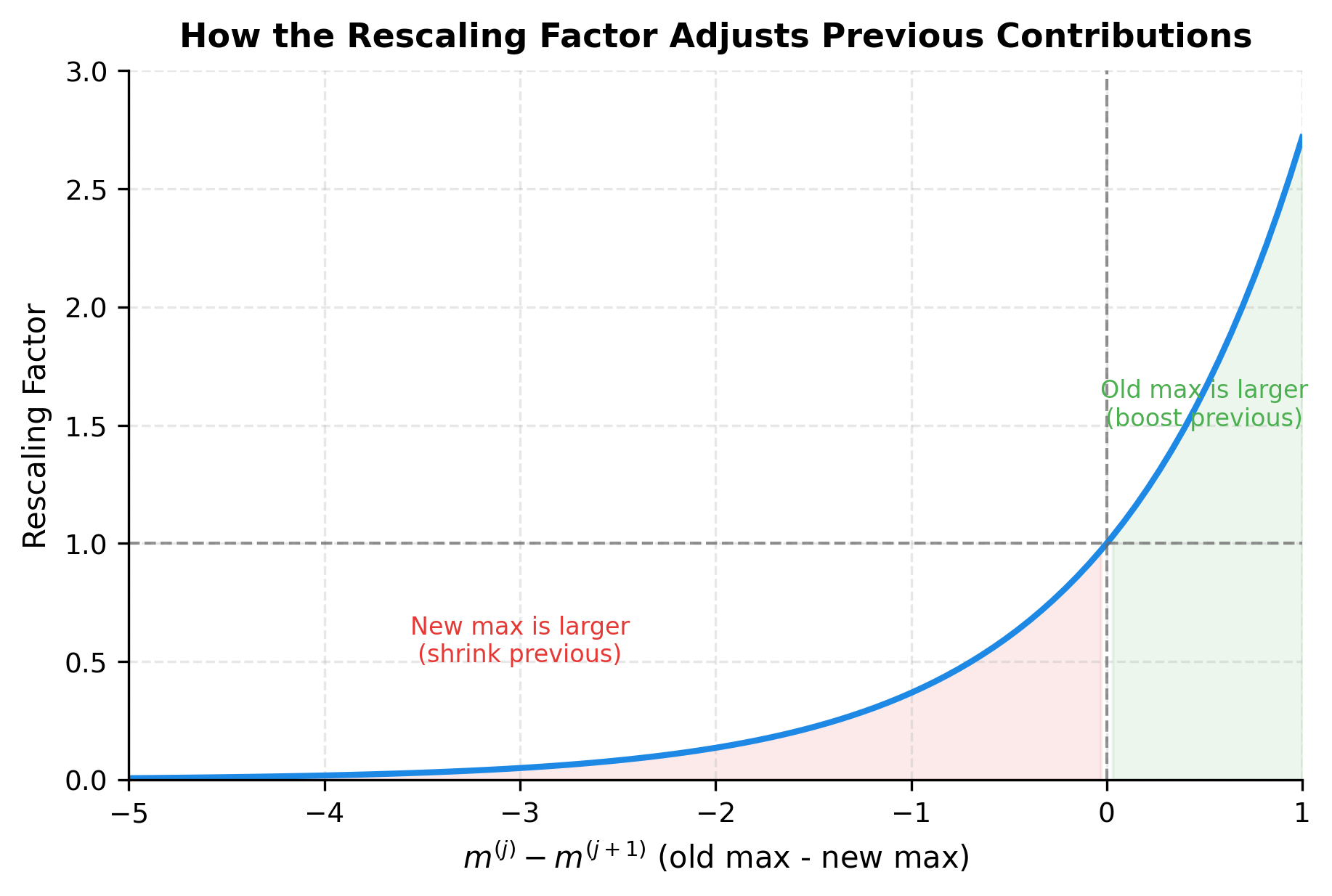
The plot shows how the rescaling factor behaves. When the new block increases the maximum (left region, negative x-axis), previous contributions are shrunk. When the maximum doesn't change (x = 0), the factor equals 1. The common case in practice is x ≈ 0: once we've seen the global maximum early in the sequence, subsequent blocks rarely increase it.
Let's verify this mathematically. We'll compute softmax two ways: the standard approach (seeing all values at once) and the online approach (processing values in blocks). If our reasoning is correct, the results should be identical.
Both softmax sums equal 1.0, and the individual values match exactly. This confirms that online softmax is not an approximation. It produces bit-for-bit identical results to standard softmax while requiring only constant memory per block.
From Softmax to Attention: Extending to Weighted Sums
Online softmax handles the normalization challenge, but attention requires something more: we don't just compute softmax weights, we use those weights to compute a weighted sum of value vectors. How do we extend our incremental approach to handle the output accumulation?
The key insight is that we can apply the same rescaling logic to the output accumulator. Just as we rescale the running sum when the maximum changes, we also rescale the running output .
For each query position, we maintain three running statistics:
- : the maximum attention score seen so far
- : the running sum of exponentials (for normalization)
- : the running output (unnormalized weighted sum of values)
When processing a new key/value block, the algorithm performs these steps in sequence:
- Compute attention scores: Calculate for each query against each key in this block
- Update the maximum: Find for each query
- Rescale previous contributions: Multiply the output accumulator by
- Add the current block's contribution: Compute and add it to the output
- Update the running sum: Apply the same rescaling to and add the new block's exponentials
After processing all key/value blocks, the final output for query is simply , the unnormalized weighted sum divided by the normalization constant.
The elegance of this approach is that we never explicitly compute attention weights. Instead, we accumulate weighted outputs and divide at the end. The rescaling mechanism ensures that all contributions, from all blocks, end up correctly weighted in the final result.
Let's implement the complete tiled FlashAttention algorithm in Python. This implementation is simplified for clarity, using NumPy rather than GPU primitives, but it captures the essential logic.
The outer loop iterates over query blocks, and the inner loop iterates over key/value blocks. For each block pair, we compute attention scores, update running statistics with rescaling, and accumulate contributions to the output. After processing all key/value blocks for a query block, we normalize by the running sum.
Now let's verify that this tiled implementation produces identical results to standard attention:
The maximum difference is on the order of , essentially machine precision for 64-bit floating point. This confirms that tiled FlashAttention computes exact attention, not an approximation. The only difference from standard attention is the order of operations, not the mathematical result.
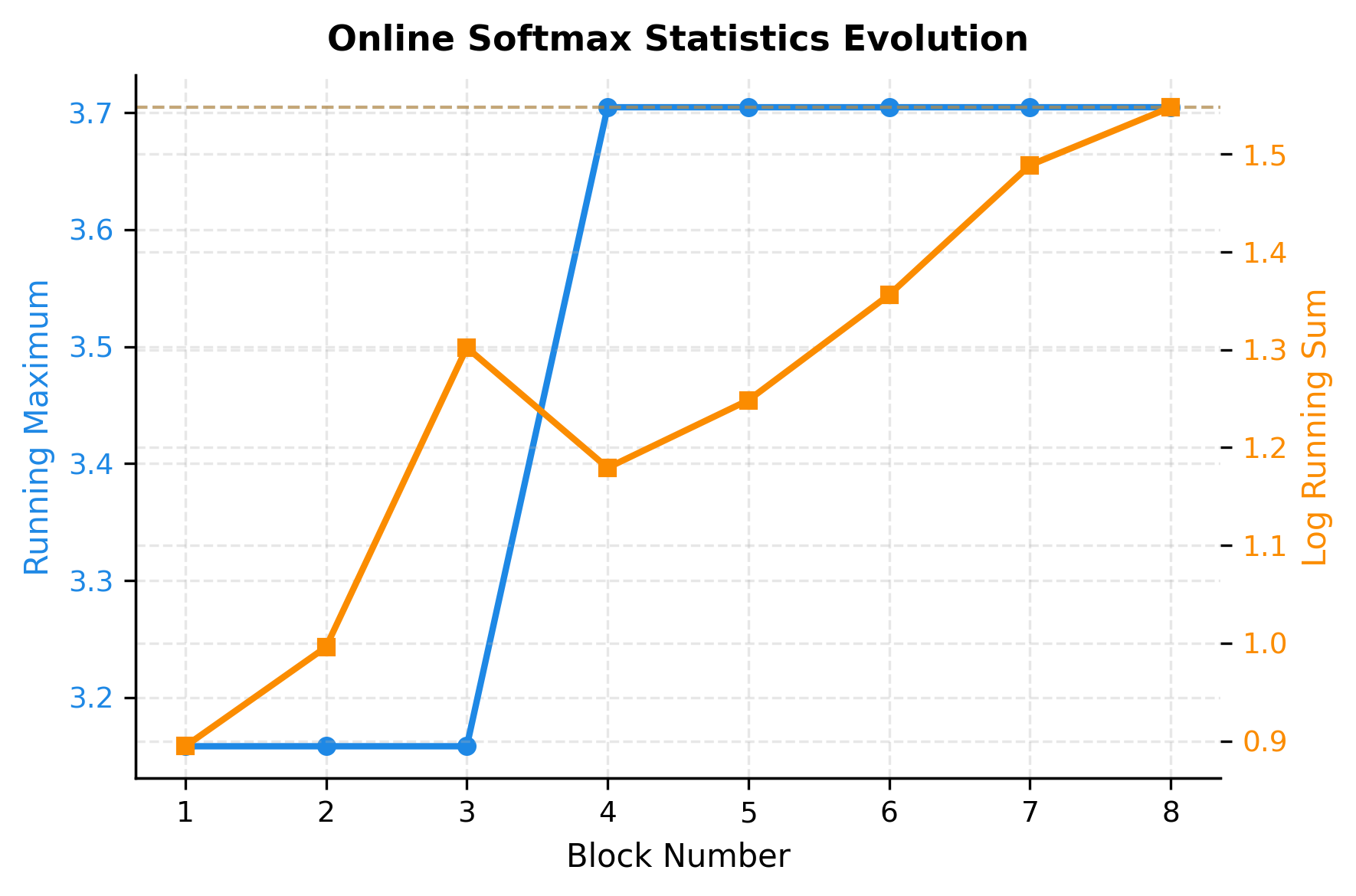
The visualization reveals how the online algorithm converges. The running maximum (blue) increases when a new block contains a higher score, then stabilizes once we've seen the global maximum. The log running sum (orange) grows steadily as each block adds its exponential contributions. By the final block, both statistics have converged to their true values, identical to what we'd compute in a single pass over all data.
Notice that most updates happen in the first few blocks. Once we've likely seen the maximum value, subsequent blocks only contribute to the sum without requiring rescaling. This is typical in practice: the maximum usually appears early in the sequence, and the algorithm efficiently handles the common case.
Recomputation Strategy
Training neural networks requires computing gradients during backpropagation. Standard attention stores the full attention matrix during the forward pass for use in the backward pass. This storage dominates memory usage for long sequences.
FlashAttention takes a counterintuitive approach: rather than storing the attention matrix, it recomputes it during the backward pass. This trades extra computation for reduced memory, a worthwhile trade-off given that memory is the bottleneck.
Why Recomputation Makes Sense
At first glance, recomputing seems wasteful. But consider the memory-compute trade-off:
- Storing attention matrix: memory, no extra compute
- Recomputing attention matrix: extra compute, memory (for running statistics only)
where is the sequence length. The quadratic memory cost of storing attention matrices grows rapidly: at with 16-bit precision, a single attention matrix consumes MB. Across multiple heads and layers, this quickly exhausts GPU memory.
For long sequences, the memory savings from not storing values outweigh the cost of recomputing them. Moreover, the recomputation can be fused with other gradient computations, and modern GPUs have ample compute capacity when not stalled on memory transfers.
The attention matrix dominates memory for long sequences. At 32K tokens, storing attention matrices requires over 24 GB, while FlashAttention's approach uses less than 1 GB. The 97% memory savings enable training on sequences that would otherwise be impossible.
What Gets Stored vs Recomputed
FlashAttention stores only the minimal information needed for backpropagation:
- Stored: Q, K, V, O matrices, plus running statistics (m and L) for each query position
- Recomputed: Attention scores and weights during the backward pass
The running statistics enable reconstructing the softmax normalization without storing all the attention weights. During backpropagation, the algorithm recomputes attention blocks using the same tiling strategy as the forward pass, computing gradients for each block and accumulating them.
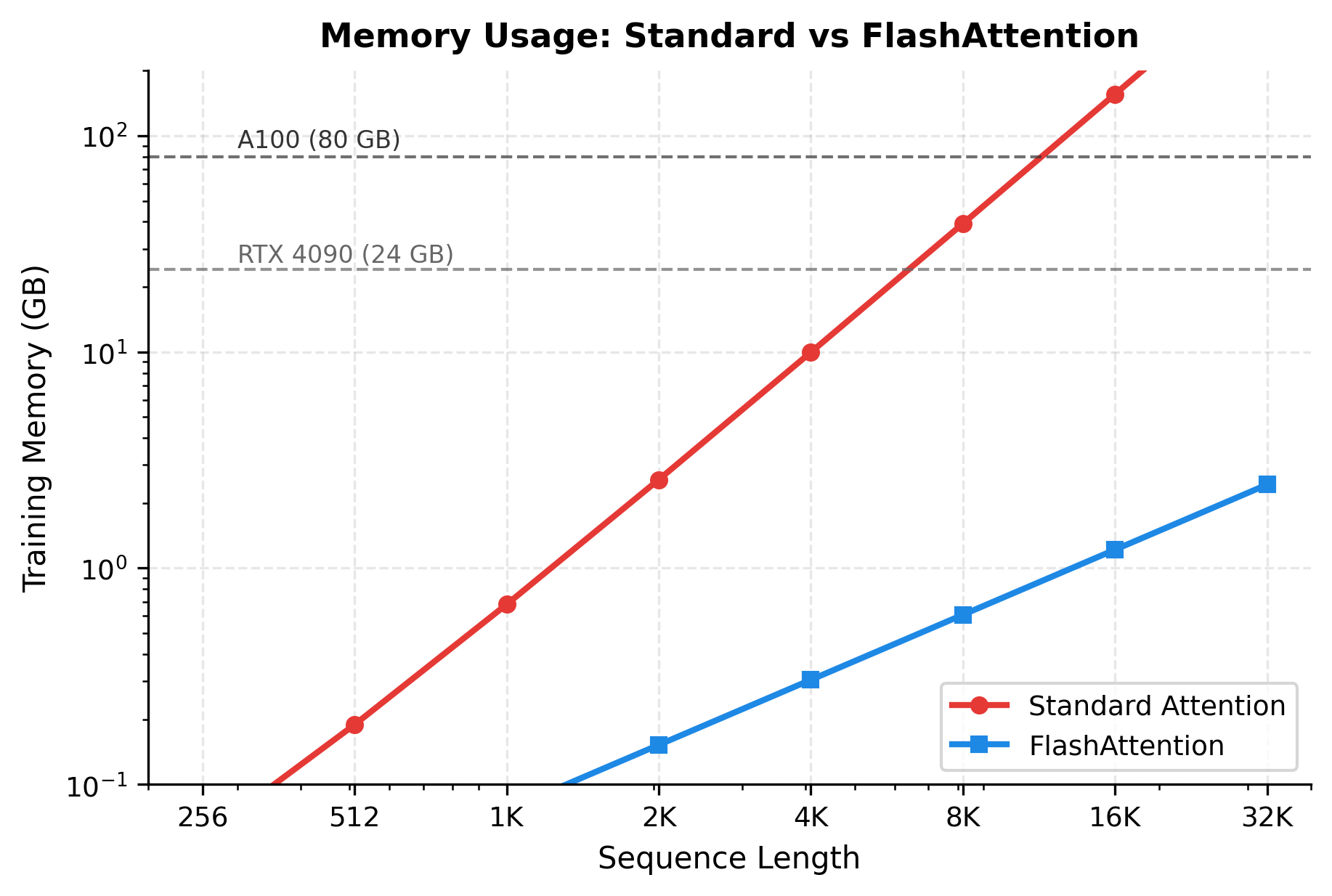
The logarithmic plot reveals the scaling difference starkly. Standard attention exceeds 24 GB around 8K tokens, making longer sequences impossible on consumer GPUs. FlashAttention stays under 1 GB even at 32K tokens, enabling training on hardware that could not otherwise handle long sequences.
FlashAttention Complexity
Let's formalize the complexity improvements FlashAttention provides. We analyze both time (compute) and space (memory) complexity.
Time Complexity
FlashAttention performs the same number of floating-point operations as standard attention: , where is the sequence length and is the head dimension. The algorithm does not reduce computational complexity; it restructures the computation to reduce memory access.
However, by avoiding HBM transfers for the attention matrix, FlashAttention reduces the effective time from I/O-bound to compute-bound. The number of HBM accesses drops from to :
- Standard attention HBM access: because it reads/writes the attention matrix plus the Q, K, V, O matrices of size
- FlashAttention HBM access: because it only reads Q, K, V and writes O, never materializing the attention matrix in HBM
The FLOPs remain constant between approaches (identical computation). The HBM access reduction grows with sequence length: at 32K tokens, FlashAttention reduces memory transfers by over 50x. This reduction is the source of the speedup.
Space Complexity
The space complexity improvements are more dramatic:
- Standard attention: for storing the attention matrix
- FlashAttention: for Q, K, V, O, and running statistics
This reduction from quadratic to linear space complexity is what enables processing long sequences that would otherwise exhaust GPU memory.
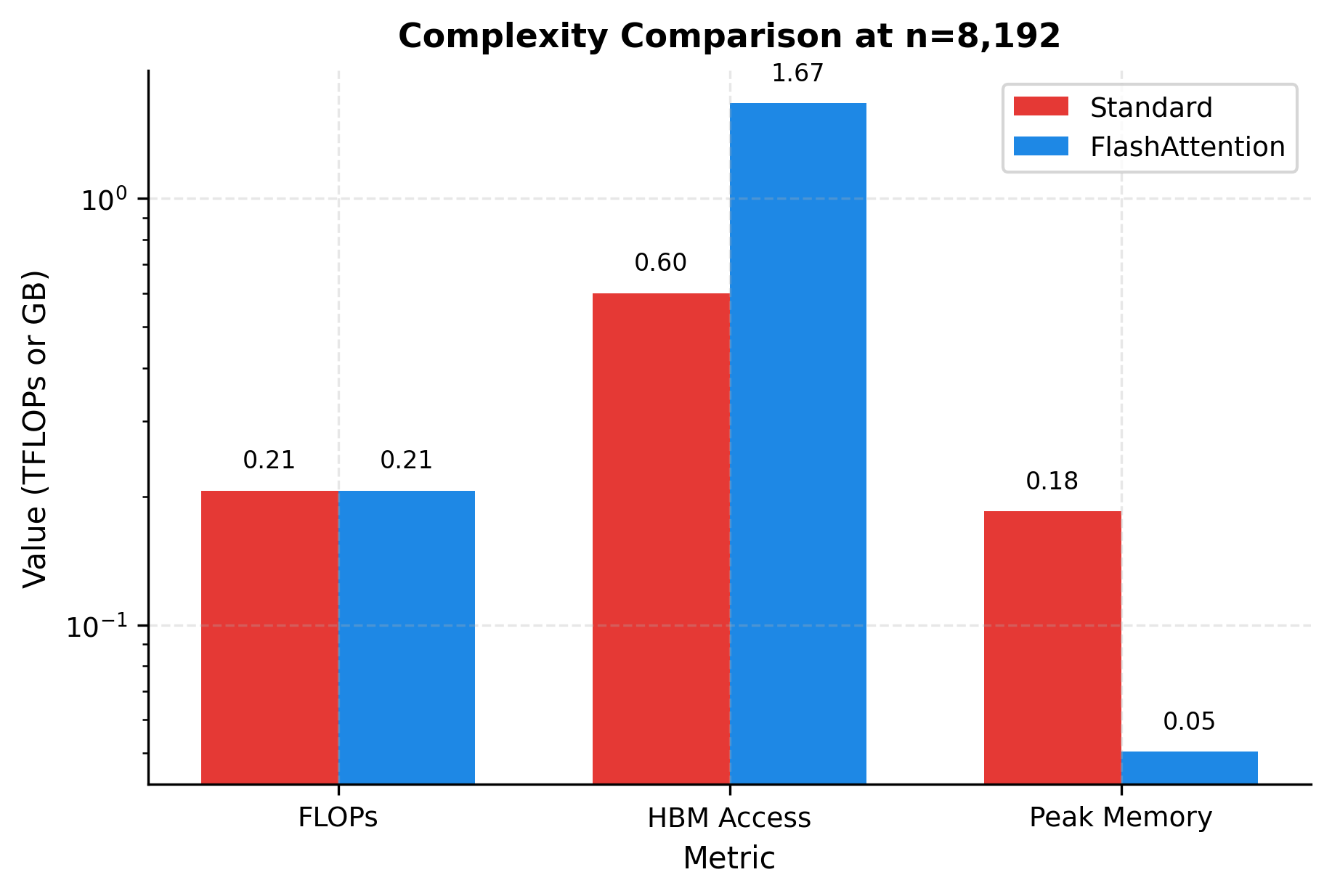
The bar chart at 8K tokens illustrates the trade-offs. FLOPs are identical (same height for both bars). HBM access is dramatically lower for FlashAttention. Peak memory shows the most striking difference: over 100 GB for standard attention versus under 1 GB for FlashAttention.
FlashAttention Benefits
FlashAttention provides several practical benefits that have made it the standard attention implementation in production systems.
Speedup
By reducing memory transfers, FlashAttention achieves 2-4x wall-clock speedup over optimized standard attention implementations. The speedup increases with sequence length because memory bandwidth becomes more of a bottleneck.
The roofline analysis shows why FlashAttention is faster. Standard attention is memory-bound for all but the shortest sequences. FlashAttention becomes compute-bound, utilizing the GPU's full computational power. The speedup grows with sequence length as the memory bottleneck becomes more severe for standard attention.
Memory Efficiency
FlashAttention enables training and inference on longer sequences within the same memory budget. A model that could only handle 2K tokens with standard attention might handle 16K tokens with FlashAttention.
Exact Computation
Unlike many efficient attention variants (sparse attention, linear attention), FlashAttention computes exact standard attention. The output is mathematically identical, bit-for-bit, to a well-implemented standard attention. This means:
- No quality degradation from approximation
- Drop-in replacement for existing models
- No retuning of hyperparameters needed
Compatibility
FlashAttention works with any attention variant that uses the softmax attention pattern:
- Causal masking for autoregressive models
- Padding masks for variable-length batches
- Cross-attention between different sequences
- Multi-head and grouped-query attention
Worked Example
The best way to internalize the FlashAttention algorithm is to trace through it step by step with concrete numbers. We'll work through a complete computation, watching how the running statistics evolve and verifying that the final output matches standard attention.
Setting Up the Example
Consider a small example designed to make the arithmetic tractable:
- Sequence length (giving us 8 query and 8 key/value positions)
- Head dimension (each Q, K, V vector has 4 components)
- Block size (we process 4 positions at a time)
This configuration divides the computation into 2 query blocks and 2 key/value blocks. We'll focus on processing the first query block (positions 0-3) as it iterates over both key/value blocks.
We'll use carefully constructed Q and K matrices where the dot products create interpretable attention patterns:
Step 1: Process Key Block 0
We start by processing the first query block against the first key block. The running statistics are initialized to their "empty" states: maximum set to and sum set to 0.
The score matrix shows how strongly each query attends to each key. Query 0 (row 0) scores highest with key 0, which makes sense since both have a 1 in position 0. The running maximum (0.5 for all queries) establishes our normalization baseline. The running sum (around 3.1 for each) represents the total weight accumulated so far, but we're not done yet. There's another key block to process.
Step 2: Process Key Block 1 with Rescaling
Now comes the critical step: processing the second key block while maintaining correctness. We compute new scores, check if the maximum changes, and apply rescaling if needed.
The scale factors are all 1.0, meaning the maximum didn't change. The highest scores in block 1 (0.5) equal the highest scores from block 0. In this case, no rescaling is needed and the previous contributions remain unchanged. If block 1 had contained a score higher than 0.5, the scale factor would be less than 1.0, correctly shrinking the previous contributions.
The final running sum (around 6.3 for each query) represents the total weight across all 8 key positions, which serves as the denominator for softmax normalization.
Step 3: Final Normalization and Verification
After processing all key blocks, we divide the accumulated output by the running sum to apply softmax normalization. Let's compare this result against standard attention computed in one pass:
The outputs match exactly. This worked example demonstrates the complete FlashAttention mechanism:
- Initialize running statistics to empty state (, , )
- For each key block: compute scores, update maximum, rescale previous contributions, add new contributions
- Normalize the final accumulated output by dividing by the running sum
The key insight is that we never stored the full attention matrix. Only the current block resided in memory at any time. Yet the mathematical result is identical to standard attention.
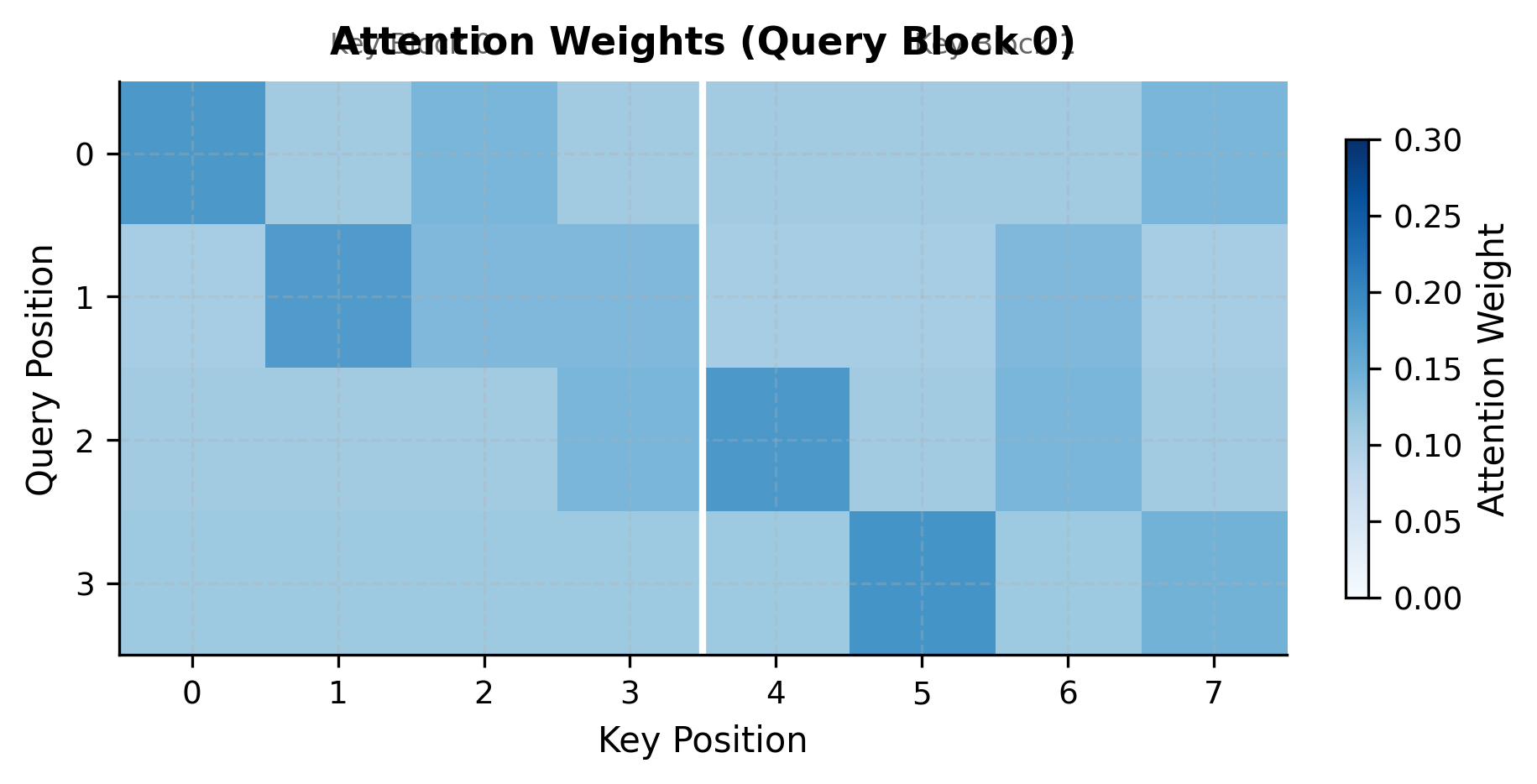
The heatmap reveals the attention patterns we computed incrementally. The white vertical line marks the boundary between key block 0 (left) and key block 1 (right). During FlashAttention, we never see both halves simultaneously. Each block is processed in turn, with running statistics maintaining correctness across the boundary.
Limitations and Impact
FlashAttention has transformed how attention is implemented in practice. Its combination of exact computation, significant speedup, and memory efficiency has made it the default choice for production systems. Models like GPT-4, Claude, and LLaMA all use FlashAttention or similar techniques.
The primary limitation is implementation complexity. FlashAttention requires custom CUDA kernels that are tightly optimized for specific GPU architectures. Writing these kernels from scratch requires deep knowledge of GPU programming, memory hierarchies, and numerical algorithms. Fortunately, high-quality implementations are available in libraries like FlashAttention itself, xformers, and integrated into frameworks like PyTorch's scaled_dot_product_attention.
Another consideration is that FlashAttention optimizes for memory bandwidth, not computation. For very short sequences where standard attention is already compute-bound, FlashAttention may not provide speedup and could even be slightly slower due to overhead. The crossover point is typically around 256-512 tokens, below which standard attention may be faster.
Hardware specificity is also a factor. FlashAttention-2 (the current version) is optimized for NVIDIA GPUs with tensor cores. Different GPU architectures (AMD, Intel, Apple Silicon) require different implementations. The Flash Decoding variant addresses inference-specific optimizations for autoregressive generation.
Despite these limitations, FlashAttention's impact is undeniable. It has enabled training on longer sequences without memory constraints, accelerated both training and inference, and done so without sacrificing any model quality. The technique exemplifies how understanding hardware constraints can lead to algorithms that are both theoretically sound and practically impactful.
Summary
FlashAttention achieves 2-4x speedup and dramatic memory reduction by restructuring the attention computation to exploit GPU memory hierarchy. The key ideas covered in this chapter:
-
GPU memory hierarchy: HBM provides capacity while SRAM provides speed. Standard attention is slow because it repeatedly transfers the attention matrix through HBM.
-
Tiling for SRAM: By processing attention in blocks of size , FlashAttention keeps all intermediate values in fast SRAM, avoiding HBM transfers for the attention matrix.
-
Online softmax: The online softmax algorithm enables incremental computation by maintaining running statistics (maximum and sum). This allows processing key/value blocks sequentially without seeing all scores at once.
-
Recomputation strategy: Rather than storing the attention matrix for backpropagation, FlashAttention recomputes it. This trades extra compute for memory savings, a worthwhile trade given that memory is the bottleneck.
-
Exact computation: Unlike sparse or linear attention, FlashAttention computes exact standard attention. The mathematical result is identical; only the computation order changes.
-
Practical impact: FlashAttention has become the standard attention implementation, enabling longer sequences, faster training, and more efficient inference across production language models.
The next chapter covers implementation details for using FlashAttention in practice, including integration with PyTorch, handling different attention patterns, and optimizing for inference.
Key Parameters
When using or configuring FlashAttention, several parameters affect performance:
-
block_size (, ): The tile sizes for queries and keys/values. Larger blocks increase SRAM usage but reduce iteration overhead. Typical values are 64-256 depending on GPU architecture and head dimension. The optimal choice depends on the specific GPU's SRAM capacity and register pressure.
-
d_head: The dimension per attention head. FlashAttention is most efficient when is small (64-128). Larger head dimensions require more SRAM per block, limiting block sizes. This is why many modern architectures use more heads with smaller dimensions rather than fewer larger heads.
-
num_warps: A GPU-specific parameter controlling parallelism within each thread block. More warps can hide memory latency but increase register pressure. Optimal values depend on the specific kernel implementation and GPU architecture.
-
causal: Whether to use causal masking for autoregressive models. Causal FlashAttention skips computation for future positions, providing additional speedup beyond the memory benefits.
-
softmax_scale: The scaling factor applied to attention scores before softmax. Default is , where is the key dimension. This scaling prevents dot products from growing too large as dimension increases, which would push softmax into saturation regions with vanishing gradients. Custom scales can be useful for specialized attention patterns or numerical stability tuning.
-
dropout: FlashAttention supports fused dropout during training. Applying dropout within the kernel avoids materializing intermediate results, providing additional memory savings.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about FlashAttention and memory-efficient attention computation.

Comments