

Explore Microsoft's Phi model family and how textbook-quality training data enables small models to match larger competitors. Learn RoPE, attention implementation, and efficient deployment strategies.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Phi Models
What if smaller models could match larger ones? The Phi series from Microsoft Research challenged the prevailing "scale is all you need" paradigm by demonstrating that carefully curated training data matters as much as, or more than, model size. A 1.3 billion parameter model matching GPT-3.5 on certain benchmarks seemed implausible until Phi proved otherwise.
The Phi models represent a philosophical shift in language model development. Rather than training on all available web text and hoping scale will overcome noise, the Phi team focused obsessively on data quality. They synthesized "textbook-quality" training data using larger models, creating datasets specifically designed to teach reasoning, coding, and world knowledge. This approach treats model training as curriculum design rather than data accumulation.
This chapter explores the Phi model family from Phi-1 through Phi-3. You'll learn about the textbook-quality data hypothesis, understand the architectural choices that complement high-quality training, and see how small language models can achieve surprising capabilities when trained thoughtfully.
The Small Model Challenge
Before Phi, the path to better language models seemed clear: make them bigger. GPT-2 (1.5B parameters) improved on GPT (117M). GPT-3 (175B) improved on GPT-2. Each generation scaled up by roughly 10x, and performance followed. This pattern suggested that capability and size were fundamentally linked.
Scaling laws describe the predictable relationship between model size, training data, and compute on one hand, and model performance on the other. Research by Kaplan et al. (2020) and Hoffmann et al. (2022) showed that loss decreases as a power law:
where:
- : the model's loss (lower is better)
- : the number of model parameters
- : the number of training tokens
- : empirically determined exponents (typically around 0.05-0.1)
This relationship suggests that larger models are reliably better given sufficient data and compute.
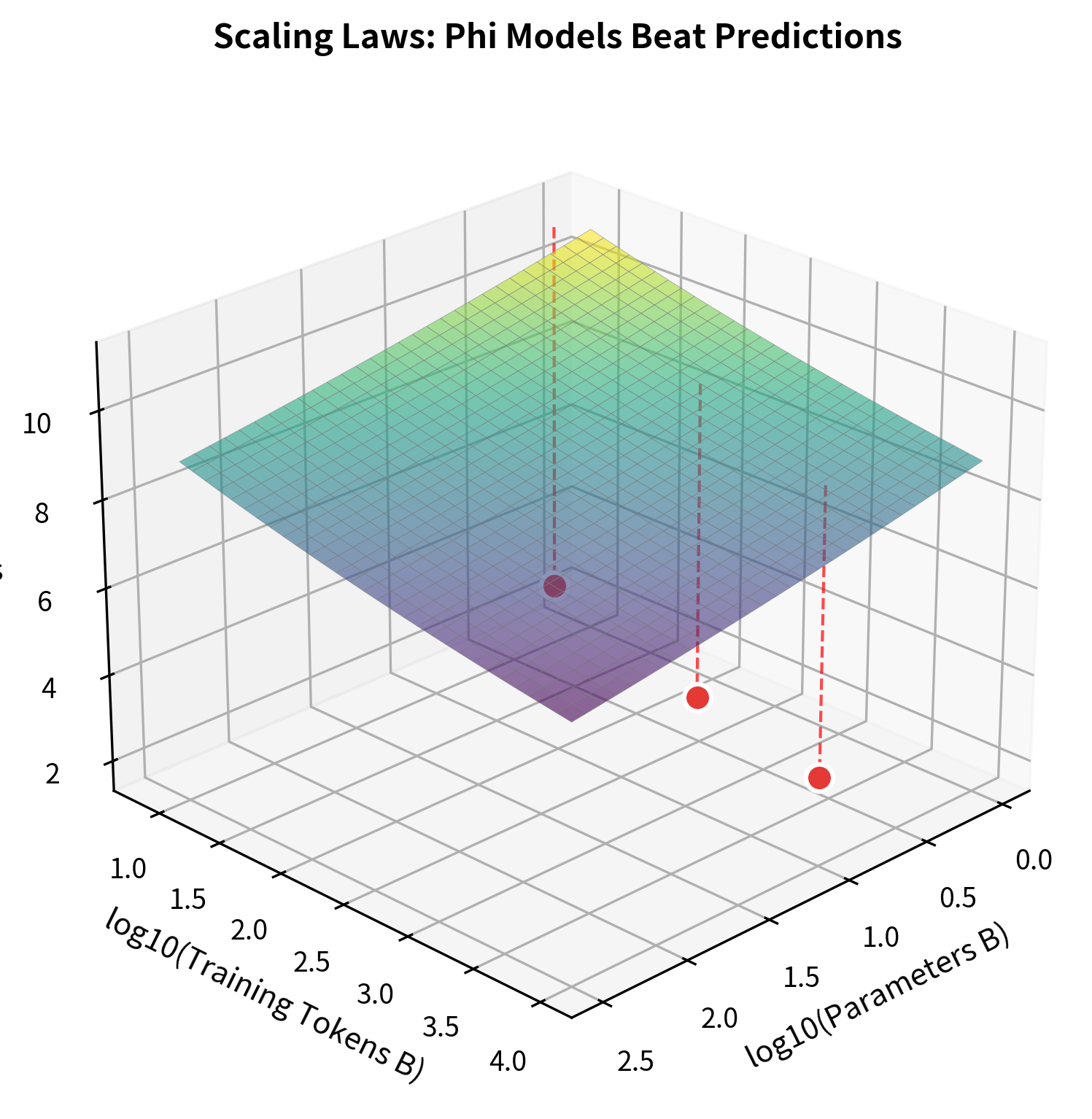
The Phi models consistently achieve lower loss than standard scaling laws predict, demonstrating that data quality can substitute for model size.
But scaling has costs. Training GPT-4 reportedly cost over $100 million. Running inference on 175B parameter models requires specialized hardware. The environmental footprint of training and deploying such models is substantial. If smaller models could achieve similar capabilities, the practical benefits would be enormous.
The Phi project asked a contrarian question: what if the training data, not just the quantity but the quality, is the primary bottleneck? Web-scraped datasets contain enormous amounts of low-quality content: SEO spam, machine-generated text, forum noise, and redundant information. What if we replaced this with carefully crafted educational content?
The table reveals the dramatic size difference between Phi models and their competitors. Phi-1 uses only 7B training tokens compared to LLaMA-2's 2,000B, yet achieves competitive performance. This 280x difference in training data volume underscores the impact of data quality.
The parameter counts tell a striking story. Phi-1 with 1.3B parameters competed with models 10-100x larger on coding tasks. Phi-2 at 2.7B matched LLaMA-2-7B and approached LLaMA-2-70B on reasoning benchmarks. How is this possible?
Phi-1: Textbooks Are All You Need
The first Phi model focused on code generation. The team hypothesized that the quality of training data for coding tasks could be dramatically improved by generating synthetic "textbook" content rather than relying on scraped code from GitHub.
The Textbook-Quality Data Hypothesis
Real-world code has problems as training data:
- Noise: Comments may be wrong, outdated, or missing entirely
- Inconsistency: Different projects use different styles and patterns
- Complexity: Production code often handles edge cases that obscure core concepts
- Lack of explanation: Code exists without pedagogical context
A programming textbook, by contrast, introduces concepts systematically, provides clear explanations, uses consistent style, and builds complexity gradually. The Phi team used GPT-3.5 to generate synthetic textbook content covering Python programming concepts.
The textbook-style code is longer, but every line serves an educational purpose. Variable names are descriptive. Comments explain the "why," not just the "what." The docstring includes a concrete example. This is the kind of content that teaches programming concepts effectively.
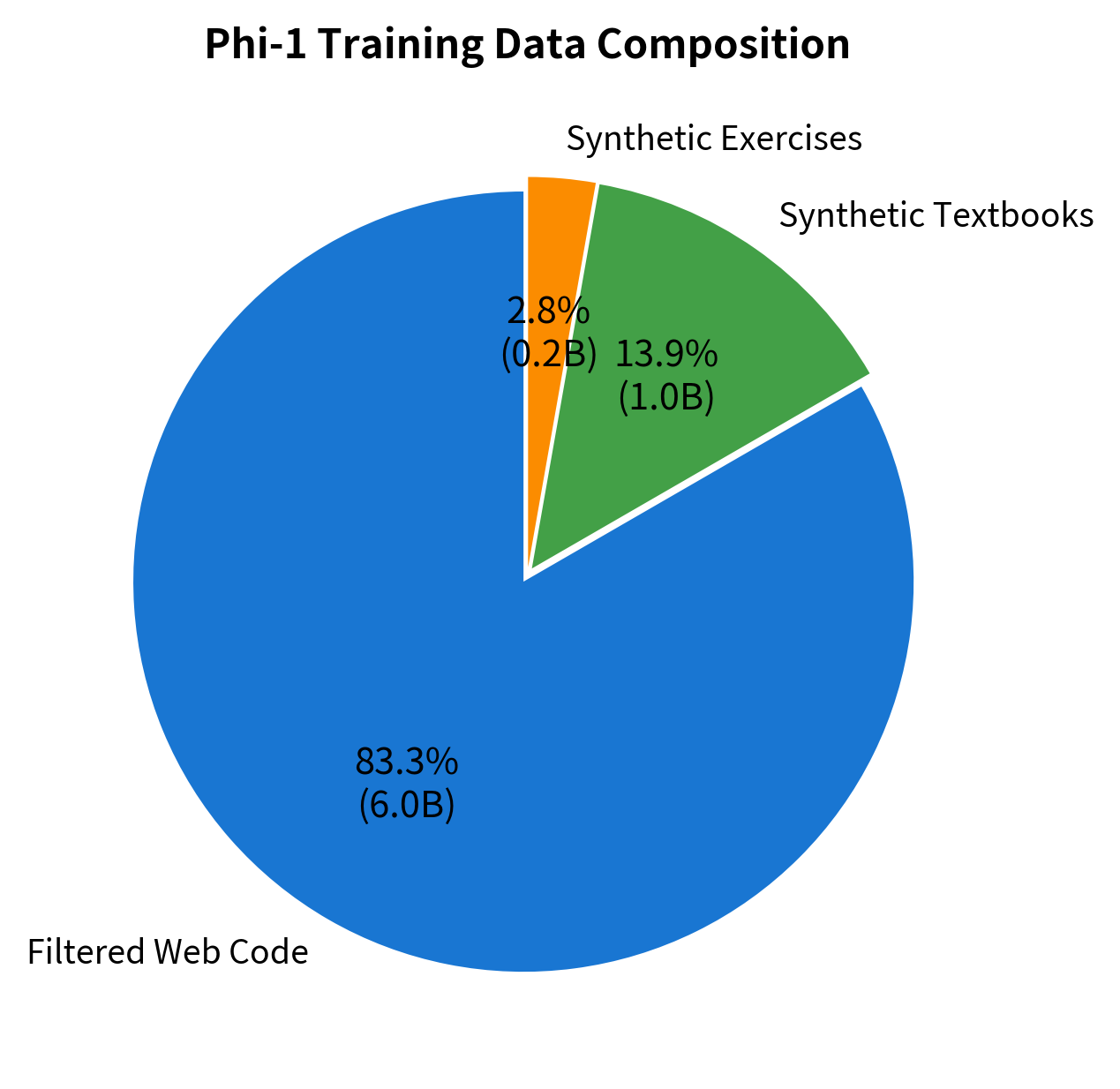
Phi-1 Training Data Composition
Phi-1's training data combined three sources:
- Filtered Code: About 6B tokens of web code filtered for quality
- Synthetic Textbooks: 1B tokens of GPT-3.5 generated educational content
- Synthetic Exercises: Code exercises with solutions, also generated
The filtering process was aggressive. From a large corpus of Python code, only about 20% passed quality filters based on educational value metrics. The synthetic data was generated with careful prompting to produce content resembling high-quality textbooks and courses.
Phi-1 Results
Phi-1's performance surprised the research community. On HumanEval, a benchmark for Python code generation, Phi-1 achieved 50.6% pass@1, comparable to models 10x its size.
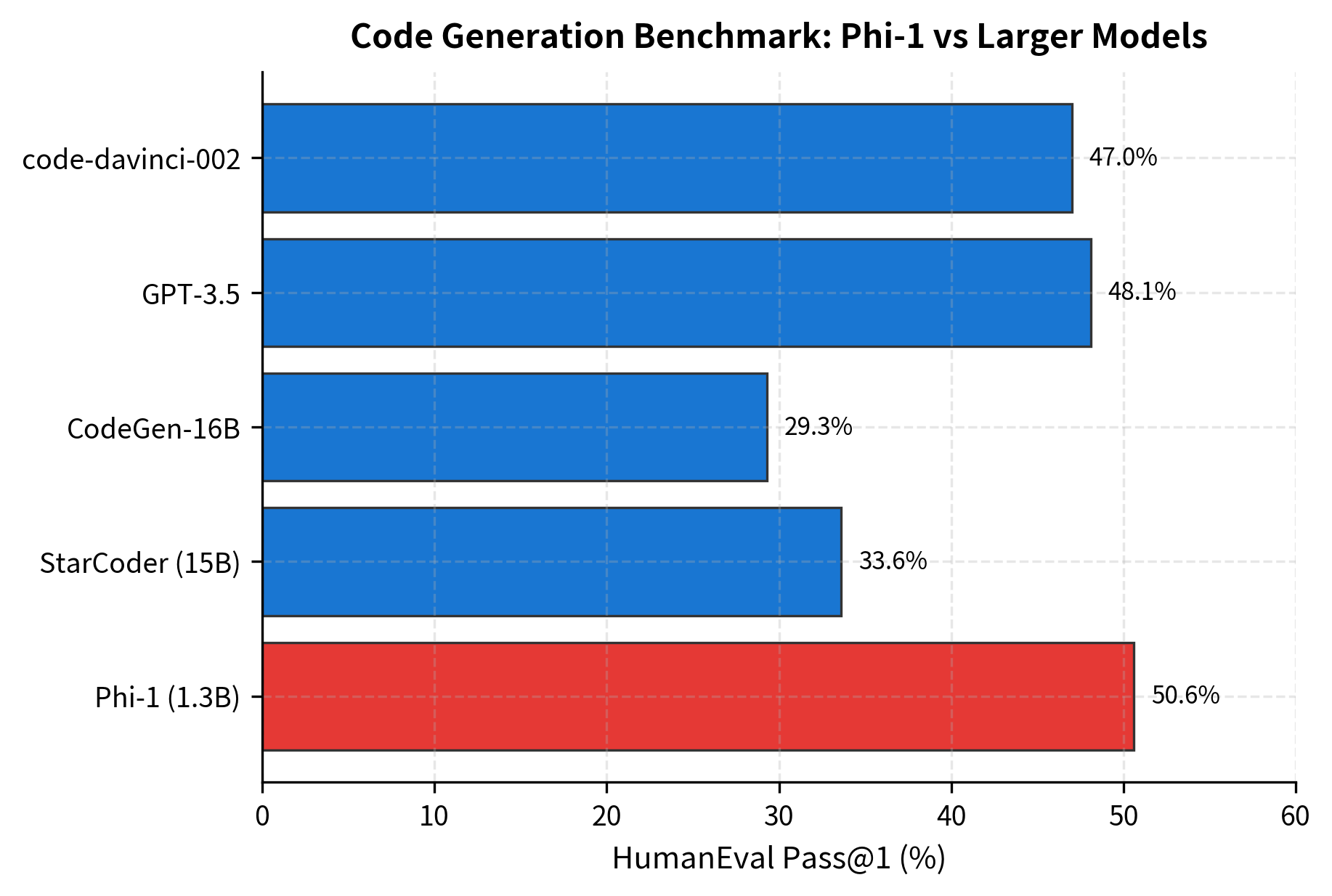
This result validated the core hypothesis: training data quality can substitute for model scale. A small model trained on carefully curated educational content matched or exceeded much larger models trained on raw web data.
Phi-1.5: Extending to Reasoning
Building on Phi-1's success, the team created Phi-1.5 to explore whether the textbook-quality approach generalized beyond coding. Phi-1.5 maintained the 1.3B parameter size but expanded the synthetic data to cover common-sense reasoning and general knowledge.
Synthetic Data for Reasoning
Generating high-quality reasoning data is more challenging than code. Code has clear correctness criteria: it either runs or it doesn't. Reasoning involves nuance, context, and sometimes subjective judgments. The Phi-1.5 team developed prompting strategies to generate textbook-like content for topics including:
- Science explanations
- Mathematical reasoning
- Common-sense scenarios
- Logical deduction
The resulting dataset contained approximately 20B tokens of synthetic textbook content covering diverse reasoning domains, plus 10B tokens of filtered web data selected for educational quality.
Phi-1.5 Architecture
Phi-1.5 used a standard transformer decoder architecture with some notable choices:
- 24 layers: Relatively deep for a 1.3B model
- 2048 hidden dimension: Standard width
- 32 attention heads: With and 32 heads, each head operates on dimensions
- Rotary positional embeddings (RoPE): Same as LLaMA for better length generalization
- Flash Attention: For efficient training
The configuration shows a relatively deep network (24 layers) for a 1.3B parameter model, with standard choices for hidden size and attention heads. The use of RoPE positional encodings matches LLaMA, enabling better length generalization than absolute positional embeddings.
The architecture itself was not novel. The innovation was entirely in the training data. This strengthens the textbook-quality hypothesis: the same architecture performs dramatically differently depending on what it's trained on.
Phi-2: Scaling Quality
Phi-2 doubled the parameter count to 2.7B and scaled up the synthetic data pipeline. The model demonstrated that the textbook-quality approach continues to provide benefits at larger scales, maintaining competitive performance against models 10-25x its size.
Training Data Strategy
Phi-2's training combined multiple data sources:
- Synthetic textbooks: Expanded coverage of STEM topics, coding, and reasoning
- Web data: Heavily filtered for educational content using NLP classifiers
- Code: High-quality repositories with documentation
The total training corpus was approximately 250B tokens, still modest compared to LLaMA-2's 2T tokens or GPT-3's 300B tokens, but dramatically higher quality according to Microsoft's metrics.
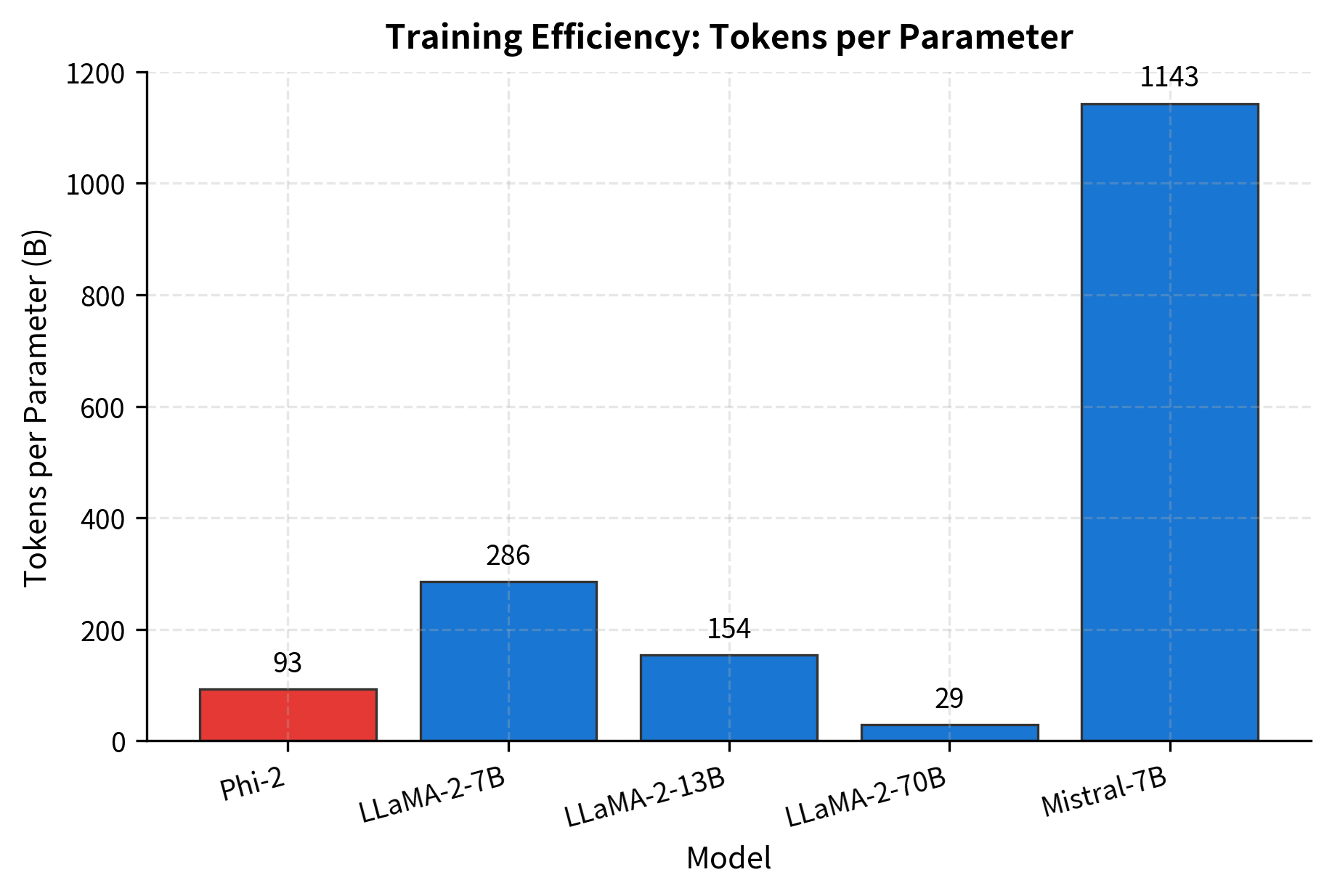
Benchmark Performance
Phi-2 achieved remarkable results across diverse benchmarks, often matching or exceeding models with 7-25x more parameters.
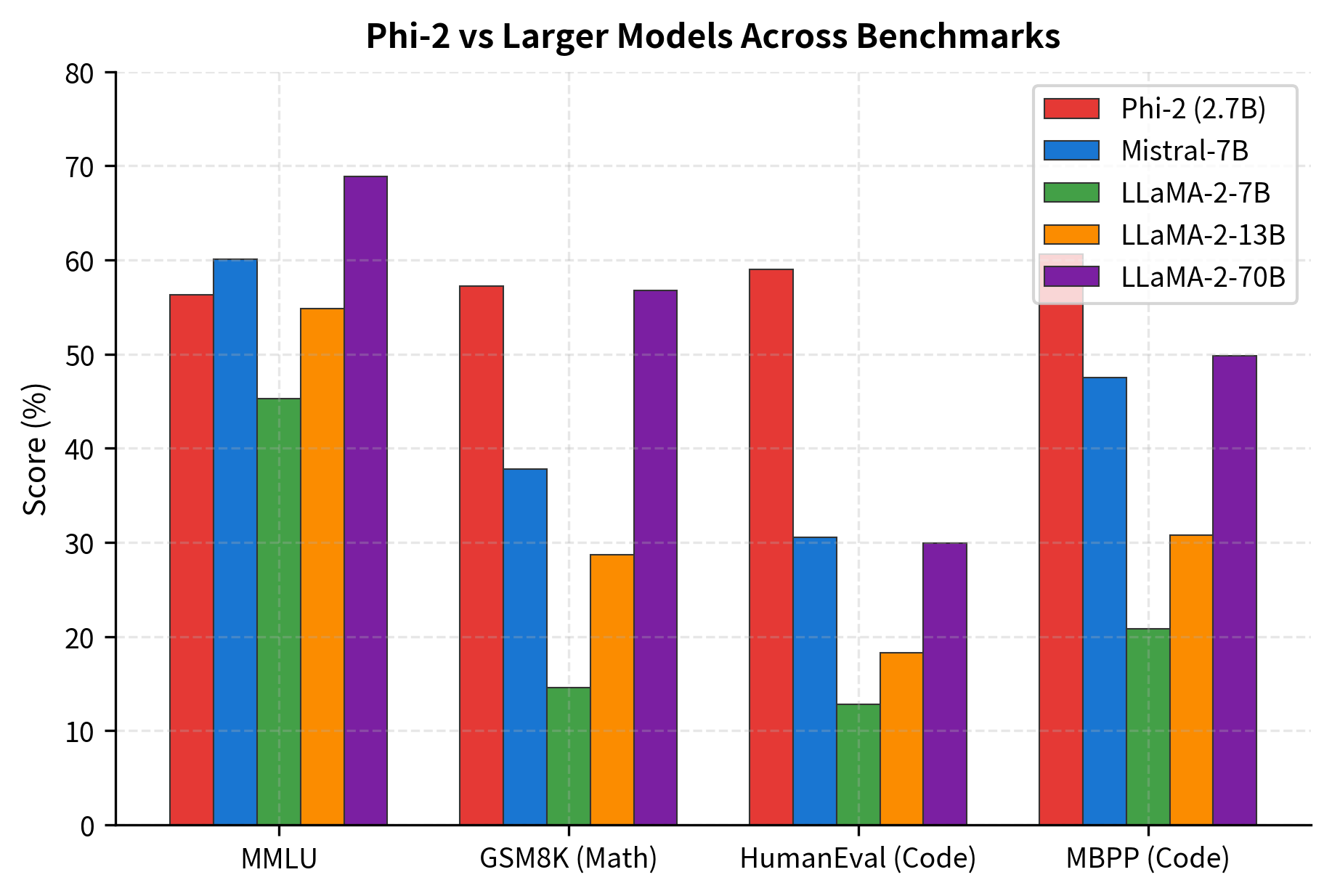
The results reveal an interesting pattern. Phi-2 excels particularly on GSM8K (mathematical reasoning) and code generation, precisely the domains where textbook-quality data provides the clearest advantage. On MMLU (general knowledge), larger models maintain an edge, suggesting that some types of knowledge benefit more from scale than from data quality.
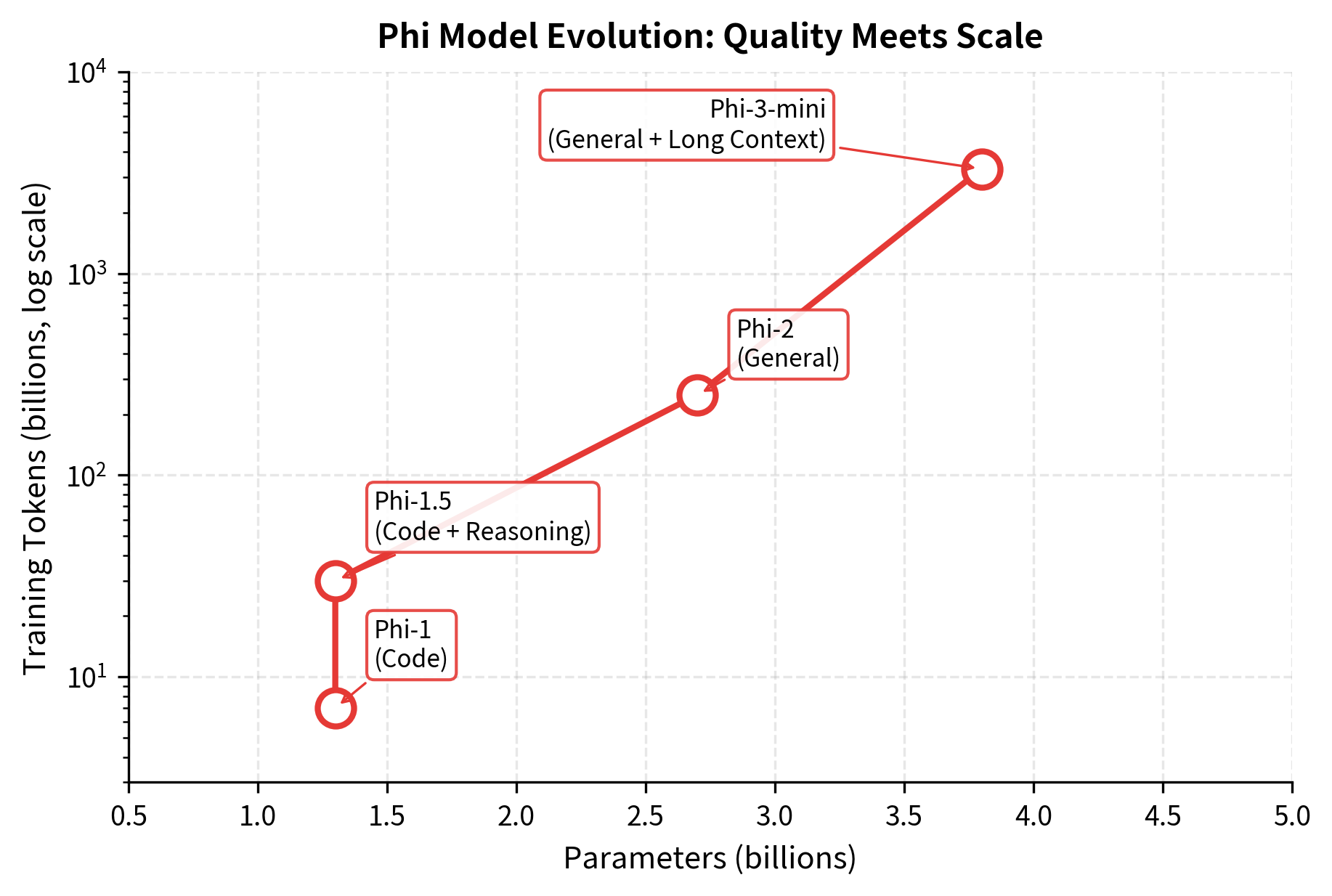
Phi-3: Quality Meets Scale
Phi-3, released in 2024, represents the maturation of the textbook-quality approach. With 3.8B parameters in the mini variant, it was trained on an unprecedented 3.3 trillion tokens of heavily filtered and synthetic data. Phi-3 closed the gap with much larger models across nearly all benchmarks.
Data Pipeline Innovations
The Phi-3 training pipeline incorporated several innovations:
- Multi-stage filtering: Multiple rounds of quality filtering using trained classifiers
- Diverse synthetic generation: Using multiple large models (not just GPT-4) to generate diverse content
- Domain coverage expansion: Systematic coverage of academic subjects, professional domains, and world knowledge
- Instruction tuning: Post-training alignment using synthetic instruction-response pairs
Phi-3 Model Variants
Phi-3 comes in multiple sizes to suit different deployment scenarios:
The 128K context length is notable, achieved through RoPE scaling techniques. Standard RoPE is trained for a fixed context length, but the frequencies can be adjusted to extrapolate to longer sequences. Phi-3 uses a technique where the base frequency is modified:
where is a scaling factor that stretches the rotational frequencies, allowing the model to handle longer sequences than it was originally trained on. This allows Phi-3 models to process long documents, complete codebases, or extended conversations while maintaining their small footprint.
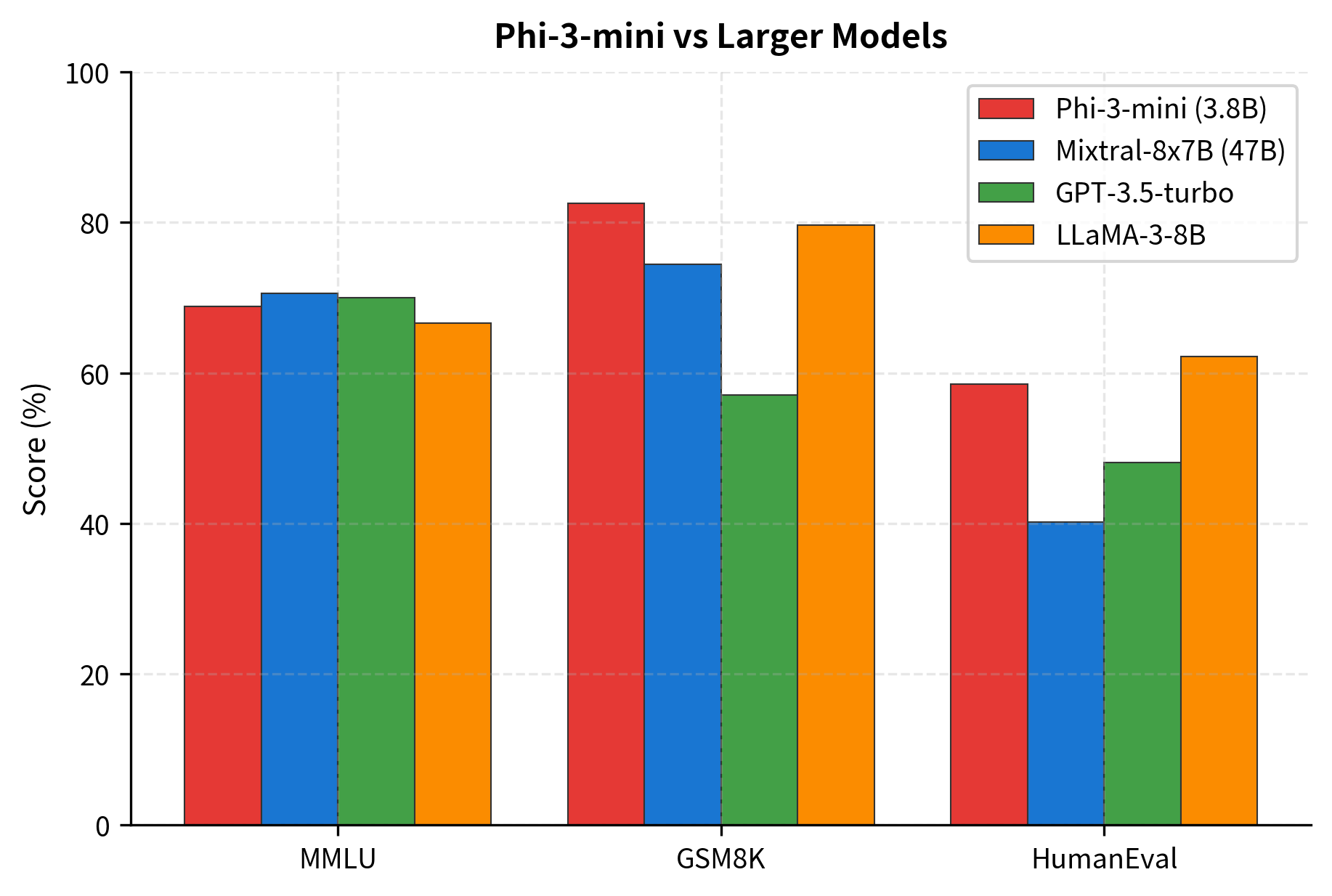
Phi-3 Performance
Phi-3-mini matches or exceeds much larger models on key benchmarks:
Code Implementation: Phi-Style Attention
To truly understand how Phi models work, we need to examine their core computational mechanism: multi-head attention with rotary positional embeddings (RoPE). While the architecture is standard, implementing it from scratch reveals the elegant mathematics that enables transformers to process sequences.
Our implementation journey proceeds through three stages:
- Positional encoding: How RoPE embeds position information through rotation
- Attention computation: How queries, keys, and values interact to produce contextual representations
- Integration: How these components combine in a complete attention layer
Understanding Rotary Position Embeddings
Before diving into code, let's build intuition for why positional encoding matters. A transformer's attention mechanism computes similarity between all pairs of tokens, but this computation is inherently position-agnostic. The same query-key pair produces the same similarity score regardless of where the tokens appear in the sequence. Yet position clearly matters: "The cat sat on the mat" has different meaning than "mat the on sat cat The."
Traditional approaches add positional embeddings to token embeddings before attention. RoPE takes a different approach: it encodes position by rotating the query and key vectors in embedding space. The key insight is that rotation preserves vector magnitudes while changing the angle between vectors. When we compute the dot product (attention score) between a rotated query and key, the result depends on their relative positions, not just their content.
Think of it geometrically: if we rotate a query vector by angle and a key vector by angle , their dot product depends on the difference . By making these rotation angles position-dependent, we encode relative position directly into the attention computation.
The Mathematics of Rotation
RoPE applies a 2D rotation to each pair of consecutive dimensions in the embedding. A 2D rotation by angle transforms a vector to:
This is exactly what our apply_rotary_embeddings function computes: for each pair of dimensions, it applies the rotation using the precomputed cosine and sine values.
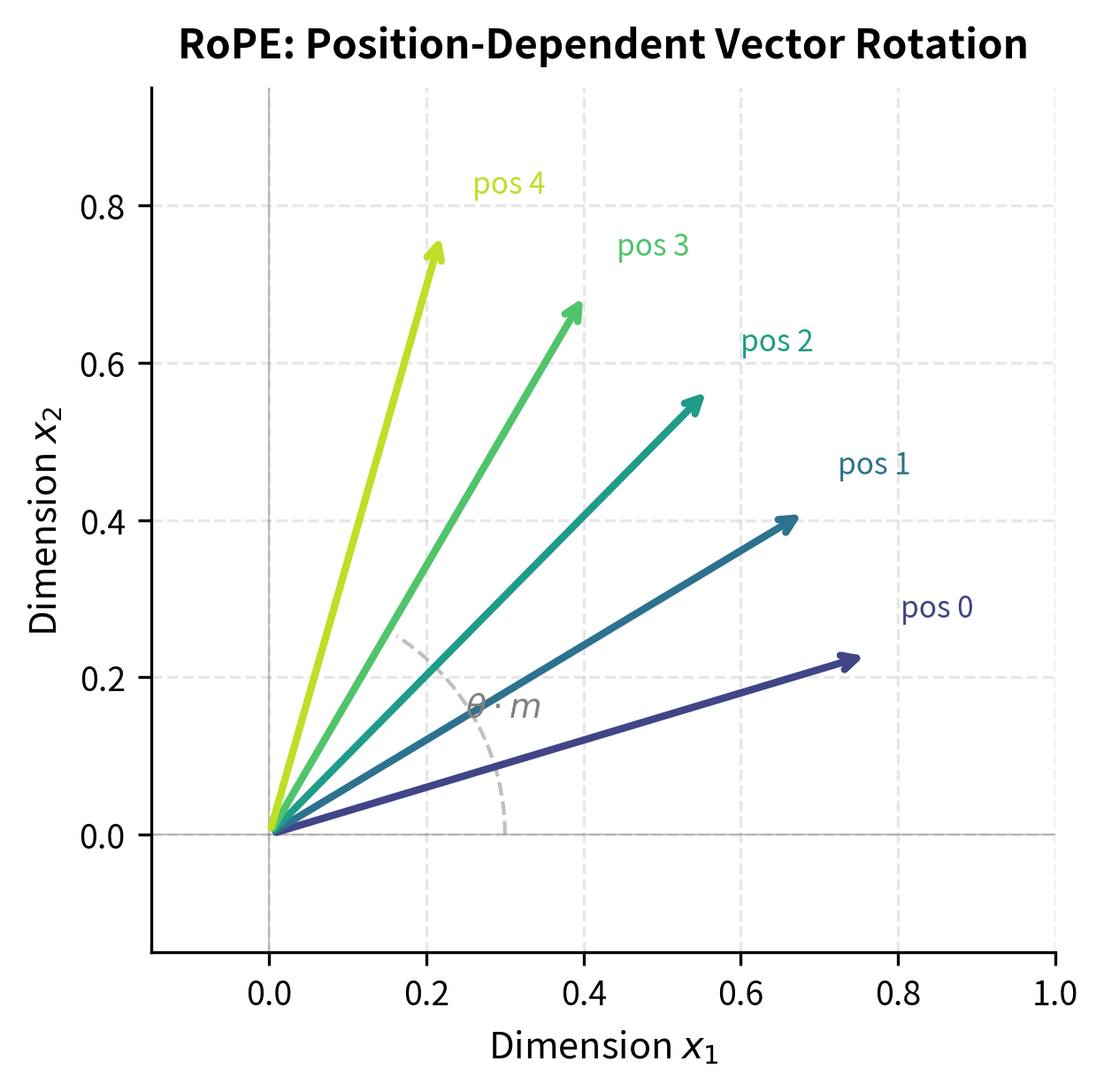
The rotation angle for position and dimension pair is computed as:
where:
- : the position index in the sequence (0, 1, 2, ...)
- : the dimension pair index (0, 1, 2, ..., )
- : the head dimension (e.g., 64)
- : a hyperparameter controlling the frequency scale (typically 10,000)
Lower-indexed dimensions rotate more slowly (smaller ), capturing longer-range positional relationships, while higher-indexed dimensions rotate faster, encoding fine-grained local position information.
This frequency hierarchy is crucial: it allows the model to represent both local patterns (through high-frequency dimensions) and long-range dependencies (through low-frequency dimensions) simultaneously. Let's see this in practice:
The output shows how RoPE frequencies vary across positions and dimensions. Notice that the first column (lowest frequency) changes slowly across positions, while higher-frequency components (rightmost columns) oscillate more rapidly. At position 0, all sine values are 0 and cosine values are 1, meaning no rotation occurs. As position increases, the rotation angles grow, with higher-indexed dimensions accumulating rotation faster.
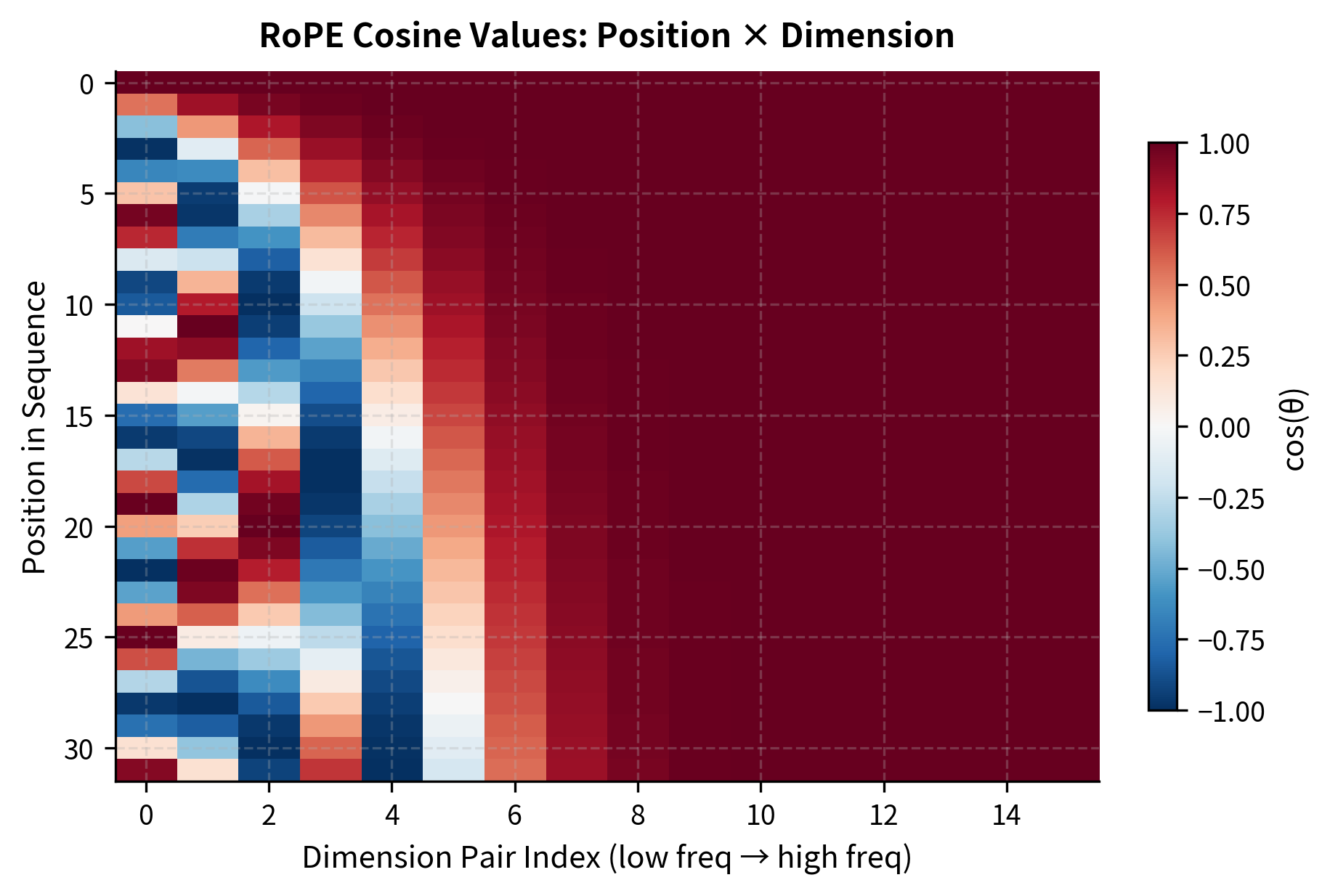
From Position Encoding to Attention
With position encoding understood, we can now build the complete attention mechanism. The core idea of attention is simple: each position in the sequence should be able to gather information from other positions, weighted by relevance. A query asks "what information do I need?", keys answer "here's what I have", and values provide the actual information to aggregate.
The mathematical formulation captures this intuition precisely. The core attention computation follows the standard scaled dot-product formula:
where:
- : the query matrix, where each row represents a position asking "what should I attend to?"
- : the key matrix, where each row represents a position answering "here's what I contain"
- : the value matrix, containing the actual information to be aggregated
- : the key/query dimension (typically 64 in Phi models)
- : the sequence length
- : scaling factor that prevents dot products from becoming too large
The softmax normalizes attention scores so each query position's weights sum to 1, creating a valid probability distribution over key positions.
Why divide by ? As the dimension grows, dot products tend to grow in magnitude (they're sums of terms). Large dot products push softmax into regions where gradients vanish, making training unstable. The scaling factor keeps the variance of dot products roughly constant regardless of .
Putting It All Together: The PhiAttention Class
Now we can combine RoPE with scaled dot-product attention in a complete implementation. The PhiAttention class orchestrates the full computation:
- Project input to queries, keys, and values using learned weight matrices
- Reshape to separate attention heads (each head attends independently)
- Apply RoPE to queries and keys (encoding position)
- Compute scaled dot-product attention
- Apply causal mask for autoregressive generation
- Project output back to model dimension
The implementation follows the mathematical formulation closely. Notice how the forward method mirrors our six-step process: projection, reshaping, RoPE application, attention computation, masking, and output projection.
Key implementation details worth noting:
- Small initialization scale (0.02): Phi uses smaller weight initialization than some models, which can help training stability
- Pre-computed RoPE frequencies: We compute cosine and sine values once and slice them per sequence length, avoiding redundant computation
- Causal masking: The mask ensures position can only attend to positions , enabling autoregressive generation
Testing the Implementation
Let's verify our attention layer works correctly by processing a small sequence and examining the outputs:
The output confirms our implementation is working correctly. The input and output shapes match (preserving dimensions through the attention layer), and each row of attention weights sums to exactly 1.0, indicating proper softmax normalization. The weights tensor has shape (1, 4, 6, 6), representing 4 attention heads each producing a 6x6 attention matrix for the 6-position sequence.
Visualizing Attention Patterns
The causal mask creates a distinctive lower-triangular pattern in the attention weights. This pattern is fundamental to autoregressive language modeling: when predicting position 5, the model can only see positions 0-5, not future positions 6 and beyond. Let's visualize this:
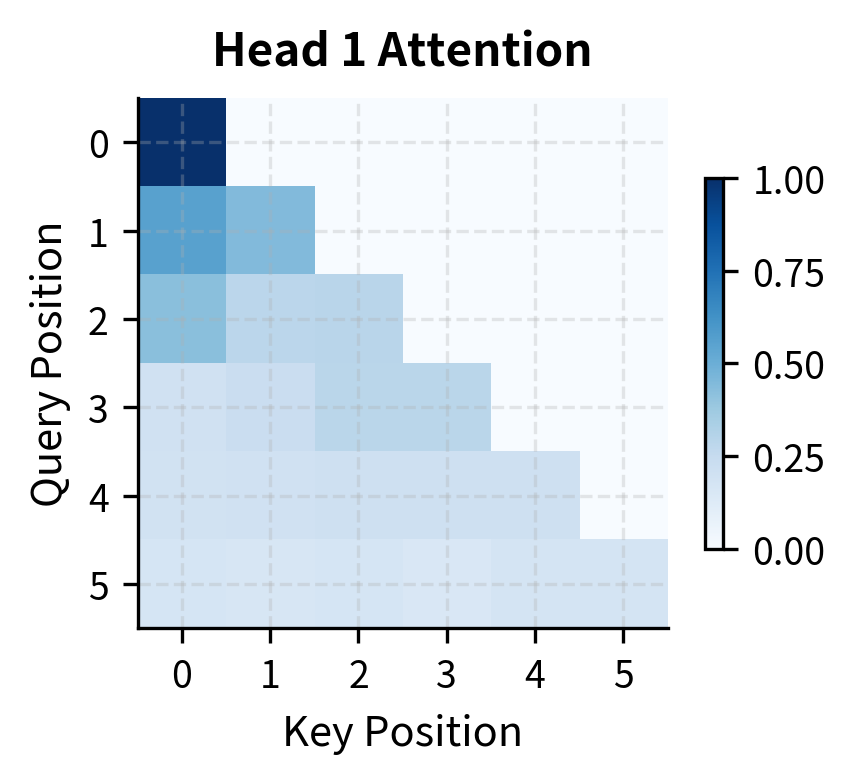
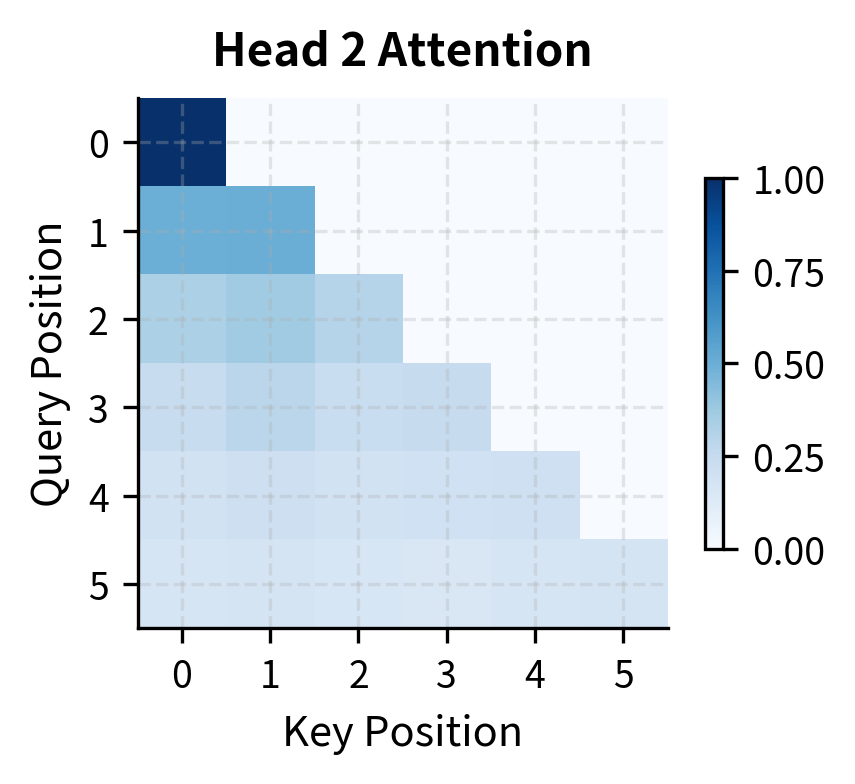
Understanding Phi's Efficiency
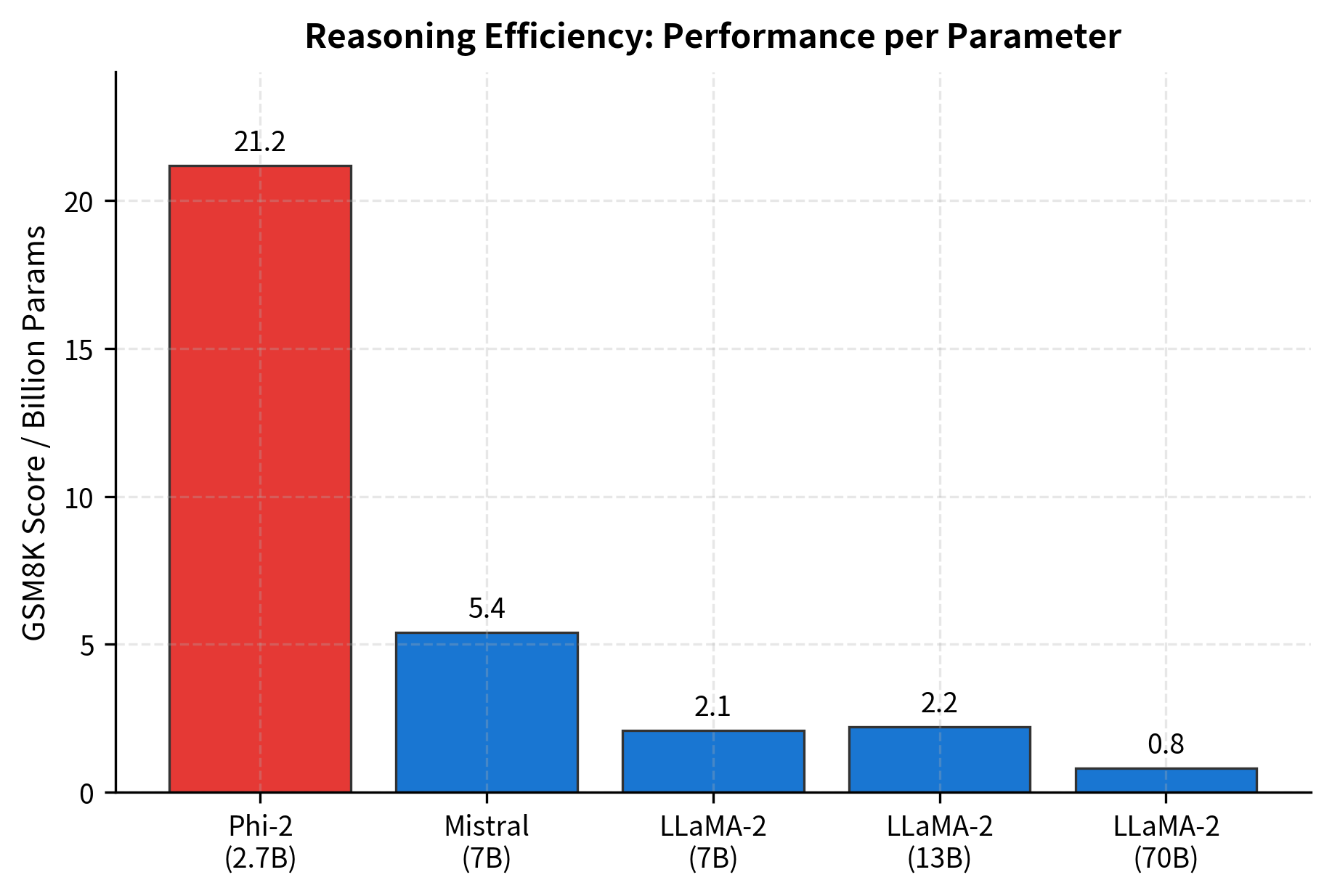
Why can Phi models achieve competitive performance with fewer parameters? Several factors contribute:
Data Efficiency
The textbook-quality approach maximizes learning per token. Instead of exposing the model to repetitive or low-quality content, every training example teaches something. This is analogous to the difference between learning from a well-designed curriculum versus random exposure to information.
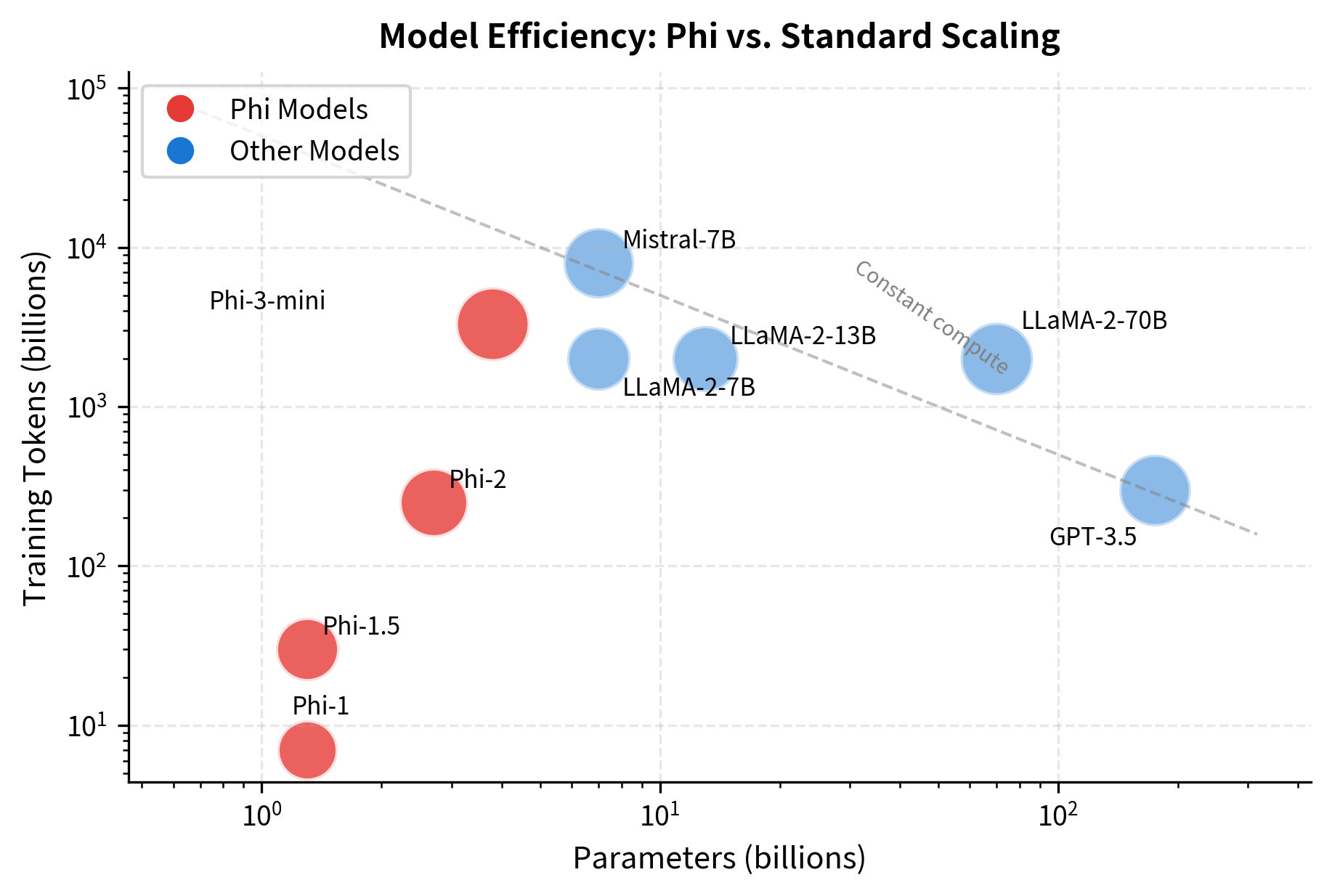
High-quality data allows Phi models to achieve comparable performance to much larger models while using significantly fewer training tokens. The key insight is that learning per token can vary by an order of magnitude depending on data quality.
Capacity Utilization
Large models trained on noisy data may dedicate significant capacity to memorizing spurious patterns, formatting quirks, or redundant information. A smaller model trained on cleaner data can allocate more of its limited capacity to genuinely useful patterns.
Reasoning Focus
Phi's training data emphasizes step-by-step reasoning, code with explanations, and mathematical derivations. This may help the model develop stronger reasoning circuits compared to models that see mostly surface-level text patterns.
Limitations and Considerations
Despite their impressive efficiency, Phi models have limitations worth understanding.
Knowledge breadth: While Phi excels at reasoning and code, models trained on more diverse web data may have broader world knowledge. A larger model might know more obscure facts simply because it has seen more text. Phi's focus on high-quality synthetic data means it may miss niche domains that weren't explicitly covered in the curriculum.
Long-tail capabilities: The textbook-quality approach works well for structured domains like programming and mathematics where educational content is well-defined. For more open-ended creative tasks or understanding of cultural nuance, the synthetic data generation process may not capture the full richness needed.
Synthetic data limitations: While synthetic data can be high-quality, it ultimately reflects the capabilities and biases of the models that generated it. If the teacher models (like GPT-3.5 or GPT-4) have systematic blind spots, these may propagate to Phi. There's also a risk of "mode collapse" where synthetic data becomes repetitive or stylistically narrow.
Benchmark saturation: As Phi models achieve strong benchmark performance, questions arise about whether benchmarks truly measure the capabilities we care about. A model optimized for textbook-style reasoning might excel at clean benchmark problems while struggling with messy real-world inputs.
Deployment and Practical Use
Phi models are designed for efficient deployment. Their small size enables scenarios that would be impractical with larger models.
Edge deployment: Phi-3-mini can run on smartphones and laptops without cloud connectivity. This enables privacy-preserving applications where user data never leaves the device.
Quantization: The small parameter count makes quantization more effective. Quantization reduces memory by representing weights with fewer bits. For a model with parameters, the memory requirement scales as:
where:
- : the number of model parameters
- : the number of bits per parameter (e.g., 16 for FP16, 4 for INT4)
A 4-bit quantized Phi-3-mini (3.8B parameters) requires approximately of memory while maintaining most of its capabilities.
Batched inference: The smaller memory footprint allows processing more requests simultaneously on a single GPU, reducing per-query costs.
Fine-tuning: With fewer parameters, fine-tuning Phi models requires less compute and memory, making customization accessible to more users.
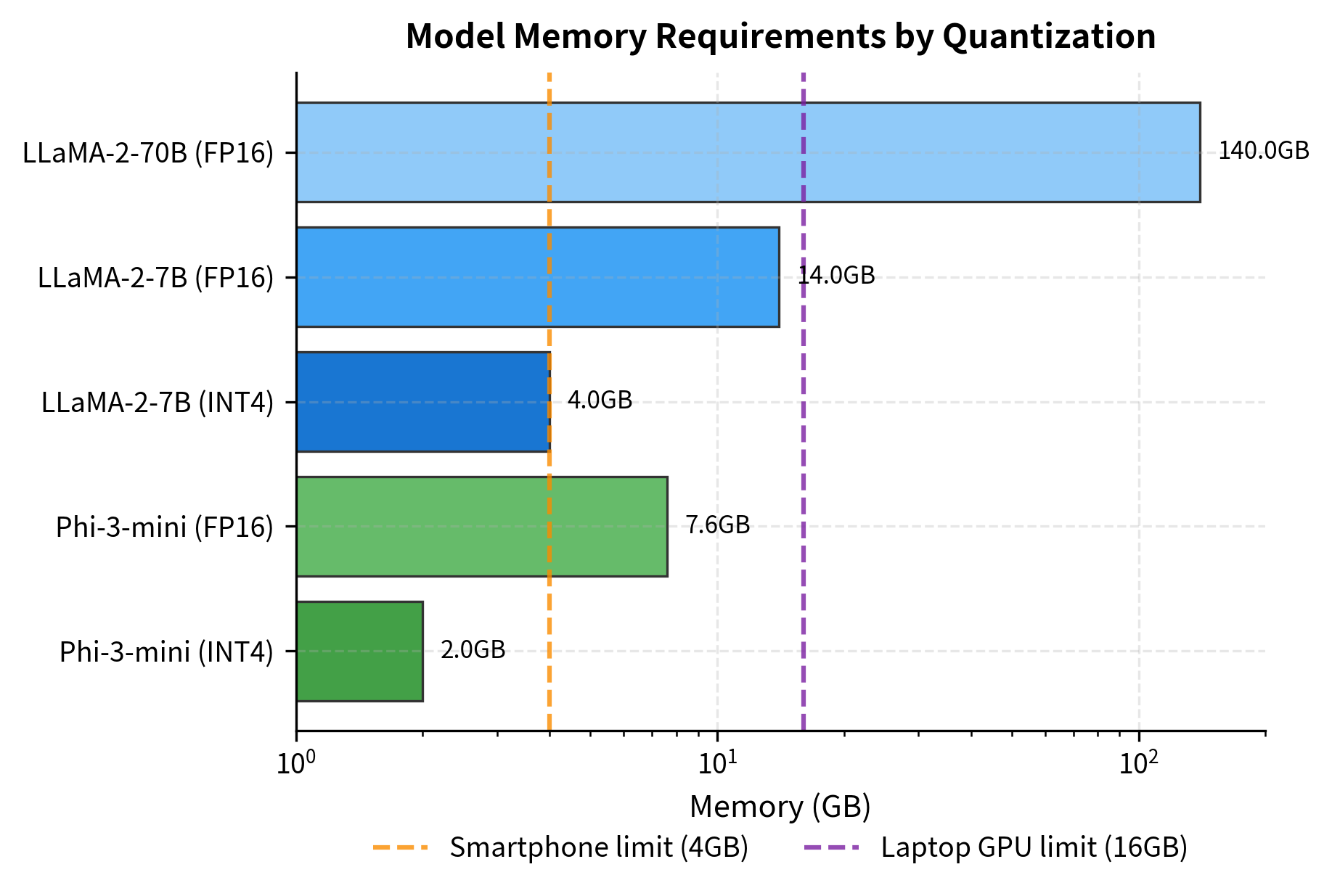
Summary
The Phi model family demonstrates that data quality can substitute for model scale. By training on carefully curated "textbook-quality" data, Phi models achieve remarkable efficiency.
The key innovations and insights from this chapter:
-
Textbook-quality hypothesis: Carefully curated educational content enables more efficient learning than raw web data. Quality trumps quantity when data is engineered for pedagogical value.
-
Synthetic data generation: Using larger models to generate structured, educational training data creates a new paradigm for dataset construction. The resulting data can teach concepts more effectively than naturally-occurring text.
-
Evolution across versions: Phi-1 proved the concept for code, Phi-1.5 extended it to reasoning, Phi-2 scaled the approach, and Phi-3 achieved near-parity with models 10-25x larger.
-
Architecture simplicity: Phi uses standard transformer architecture with RoPE and Flash Attention. The innovation is entirely in the training data, validating that architecture alone doesn't determine capability.
-
Deployment efficiency: Small parameter counts enable edge deployment, efficient quantization, and lower inference costs. Phi-3-mini can run on devices where larger models are impractical.
-
Tradeoffs: Phi models excel at structured reasoning tasks but may have narrower knowledge coverage than larger models trained on diverse web data. The synthetic data approach has inherent limitations around diversity and coverage.
The Phi series challenges us to think differently about model development. Rather than assuming that scale is the only path to capability, the textbook-quality approach suggests that thoughtful data curation may be equally important. As the field matures, we may see convergence between these strategies: large-scale training on carefully filtered and augmented data that combines the benefits of both approaches.
Key Parameters
When working with or fine-tuning Phi models, the following parameters have the most significant impact:
Model Selection
- Model variant: Choose Phi-3-mini (3.8B) for edge deployment and mobile, Phi-3-small (7B) for balanced performance, or Phi-3-medium (14B) for maximum capability. The mini variant offers the best efficiency-to-capability ratio for most use cases.
Inference Configuration
- Context length: Phi-3 supports up to 128K tokens through RoPE scaling. Use shorter contexts (4K-8K) for faster inference; extend to 128K only when processing long documents.
- Quantization: INT4 quantization reduces memory by approximately 4x with minimal quality degradation. Recommended for edge deployment; use FP16 or BF16 for maximum quality on server hardware.
- Batch size: Smaller model size allows larger batch sizes on the same hardware, improving throughput for high-volume applications.
Fine-tuning Configuration
- LoRA rank: Ranks of 16-64 work well for domain adaptation. Lower ranks (8-16) suffice for style transfer; higher ranks (32-64) for learning new capabilities.
- Learning rate: Use 1e-5 to 5e-5 for full fine-tuning, 1e-4 to 3e-4 for LoRA. Phi's smaller size makes it more sensitive to learning rate than larger models.
- Training epochs: 1-3 epochs typically sufficient given the model's strong base capabilities. Monitor for overfitting on small datasets.
The next chapter examines other efficient model architectures and techniques for reducing the computational requirements of large language models while maintaining their capabilities.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about Phi models and the textbook-quality data hypothesis.

Comments