

Explore GPT-3's 175B parameter architecture, the emergence of few-shot learning, in-context learning mechanisms, and how scale unlocked new capabilities in large language models.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
GPT-3
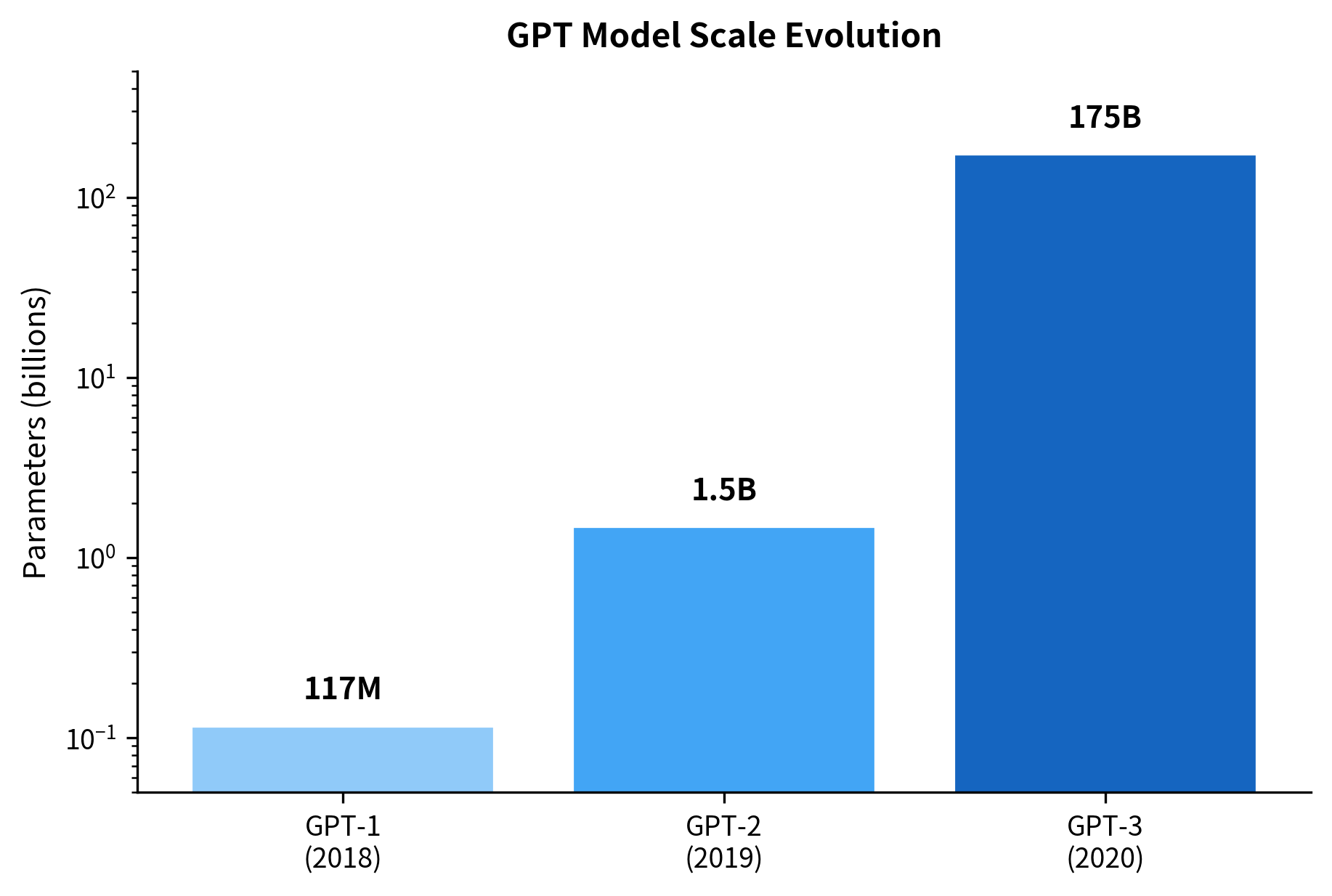
GPT-2 demonstrated that language models could perform tasks without task-specific training, achieving modest zero-shot performance on reading comprehension, translation, and summarization. But this capability was limited: the model often required fine-tuning to match specialized systems. GPT-3 changed this equation through sheer scale. With 175 billion parameters, over 100 times larger than GPT-2, it revealed that massive language models could learn new tasks from just a few examples provided in the prompt, a capability called few-shot learning.
This discovery reshaped how we think about language model capabilities. Instead of training separate models for each task, a single pretrained model could adapt on the fly. Prompting replaced fine-tuning for many applications. The implications extended beyond NLP: GPT-3 demonstrated that scale itself could be a source of emergent capabilities, behaviors that appear suddenly as models grow larger.
In this chapter, we explore GPT-3's architecture and training, the discovery of in-context learning, the difference between zero-shot, one-shot, and few-shot prompting, and what GPT-3 revealed about the relationship between scale and capability.
The Scale of GPT-3
GPT-3's defining characteristic is its size. At 175 billion parameters, it dwarfed all previous language models. To understand what this means in practice, let's compare it to its predecessors:
The jump from GPT-2 to GPT-3 represents more than a linear improvement. With 96 transformer layers, a hidden dimension of 12,288, and 96 attention heads, GPT-3 can represent far more complex patterns and relationships. The context length of 2,048 tokens means the model can consider roughly 1,500 words of context when making predictions.
Training Data and Compute
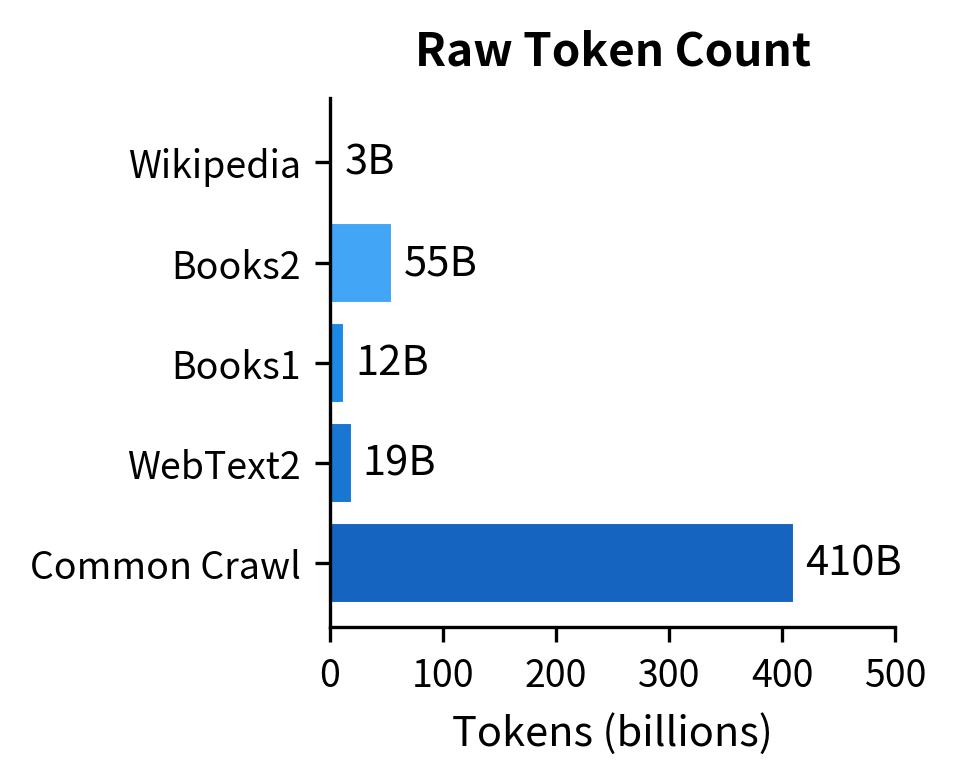
GPT-3's training data, while not publicly disclosed in full detail, was substantially larger than GPT-2's WebText. The training corpus included:
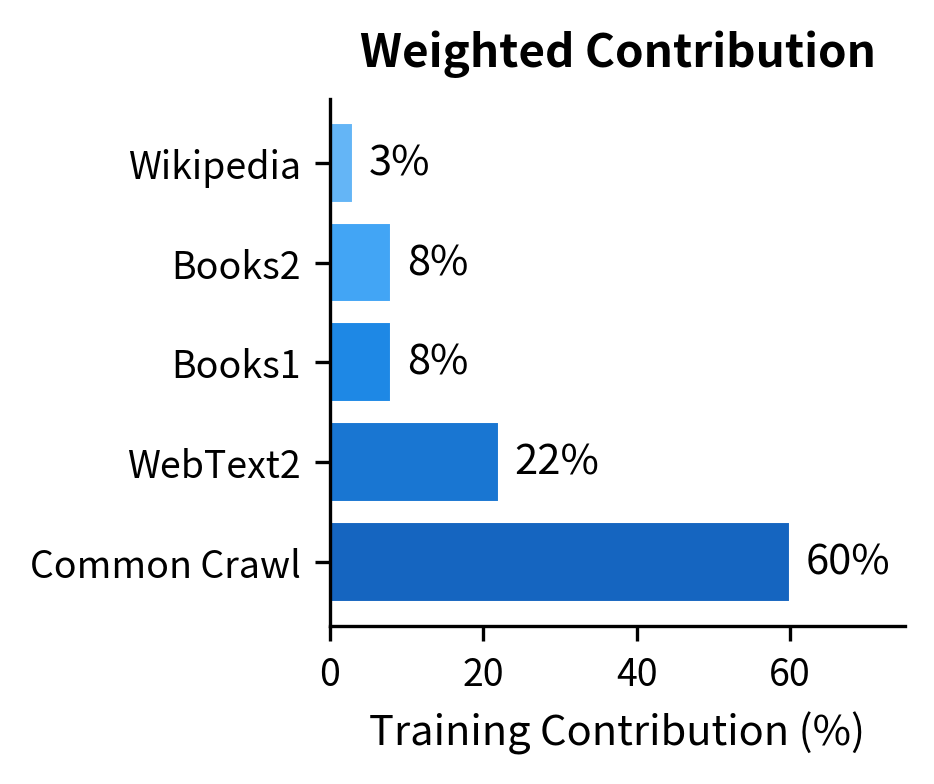
- Common Crawl: A filtered version of web pages (410 billion tokens, weighted to contribute 60% of training)
- WebText2: An expanded version of GPT-2's Reddit-curated dataset (19 billion tokens)
- Books1 and Books2: Two internet-based book corpora (12 billion and 55 billion tokens)
- Wikipedia: The English Wikipedia (3 billion tokens)
The total training corpus contained approximately 499 billion tokens, though the model saw roughly 300 billion tokens during training due to dataset weighting that favored higher-quality sources.
GPT-3 required approximately floating-point operations (FLOPs) to train, roughly 1,000 times more compute than GPT-2. At 2020 cloud computing prices, the estimated training cost exceeded $4 million.
The compute required for training grew even faster than the parameter count. This wasn't just about having more parameters; each parameter needed more training data to be utilized effectively. A rough estimate of training compute for a language model is:
where:
- : total floating-point operations (FLOPs) for training
- : number of model parameters
- : number of training tokens
- The factor of 6 accounts for the forward and backward passes (approximately 2 FLOPs per parameter per token for forward, 4 for backward)
For GPT-3 with parameters trained on tokens, this yields FLOPs, matching the reported training compute. This observation, later formalized in scaling laws, showed that optimal training balances model size with data quantity and training compute.
The GPT-3 Model Family
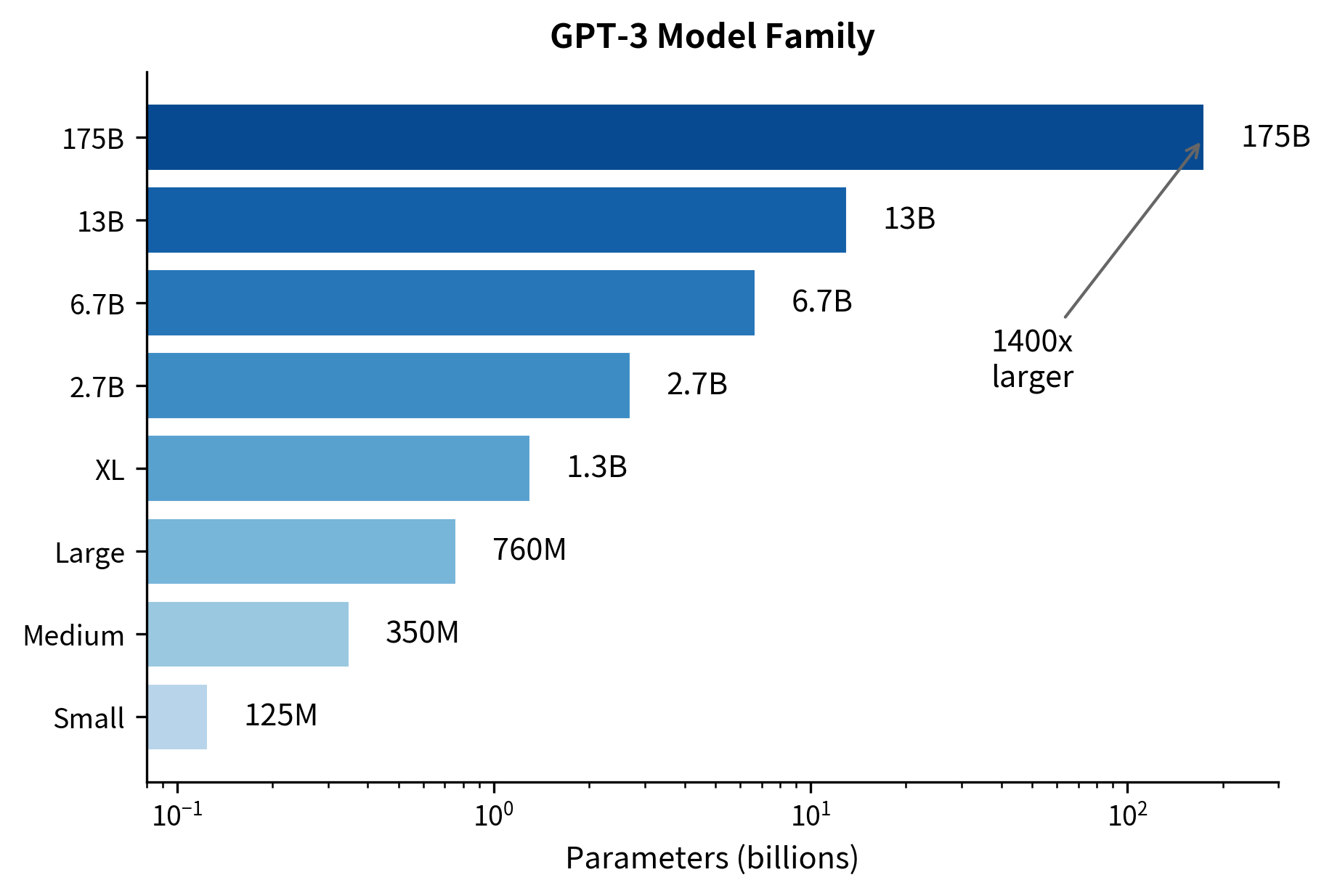
OpenAI released GPT-3 not as a single model but as a family of eight models spanning four orders of magnitude in size. This range enabled researchers to study how capabilities scale with model size:
| Model Name | Parameters | Layers | Hidden Size | Heads |
|---|---|---|---|---|
| GPT-3 Small | 125M | 12 | 768 | 12 |
| GPT-3 Medium | 350M | 24 | 1024 | 16 |
| GPT-3 Large | 760M | 24 | 1536 | 16 |
| GPT-3 XL | 1.3B | 24 | 2048 | 24 |
| GPT-3 2.7B | 2.7B | 32 | 2560 | 32 |
| GPT-3 6.7B | 6.7B | 32 | 4096 | 32 |
| GPT-3 13B | 13B | 40 | 5120 | 40 |
| GPT-3 175B | 175B | 96 | 12288 | 96 |
The smallest GPT-3 model is roughly equivalent to GPT-1 in size, while the largest is over 1,000 times bigger. This range allowed researchers to study emergent capabilities: abilities that appear suddenly at certain scales rather than improving gradually.
Architectural Details
GPT-3 uses the same fundamental decoder-only transformer architecture as GPT-2. The core design remains unchanged: a stack of transformer decoder blocks with masked self-attention, each followed by a feed-forward network. However, the model includes a few modifications for training stability at scale:
The key architectural differences from GPT-2 include:
- Alternating dense and sparse attention: In some layers, GPT-3 uses sparse attention patterns that attend to every other token, reducing computational cost for long sequences
- Learned position embeddings: Like GPT-2, positions are represented by learned embeddings rather than sinusoidal functions
- Pre-layer normalization: Layer normalization is applied before each sublayer (attention and FFN) rather than after, following the Pre-LN configuration that stabilizes training for deep networks
Parameter Count Calculation
When we say GPT-3 has 175 billion parameters, what exactly are we counting? Understanding where these parameters live reveals the model's structure and helps explain why scale matters so much for capability.
A transformer model stores its learned knowledge in weight matrices. Each weight is a single floating-point number that the model adjusts during training. The total count of these numbers determines the model's capacity to represent patterns in language. To understand GPT-3's scale, we need to trace through each component and count its parameters systematically.
The Building Blocks
A GPT-style model consists of several distinct components, each contributing parameters:
- Token embeddings: A lookup table that converts each vocabulary token into a dense vector
- Position embeddings: A separate lookup table that encodes where each token appears in the sequence
- Transformer layers: The repeated blocks that process and transform token representations
- Final layer normalization: A normalization layer before the output projection
- Output projection: A matrix that converts hidden states back to vocabulary probabilities
Let's formalize this. For a model with vocabulary size , maximum sequence length , model dimension , number of layers , and feed-forward dimension , the total parameter count is:
where:
- : token embedding parameters. Each of the vocabulary tokens gets its own -dimensional vector, requiring parameters total.
- : position embedding parameters. Each of the possible positions gets a -dimensional vector.
- : parameters per transformer layer, which we'll derive below.
- : final layer normalization has a learnable scale and bias vector, each of dimension .
- : the output projection maps from hidden dimension back to vocabulary size . This is often weight-tied with the token embeddings (sharing the same matrix), but GPT-3 uses separate weights.
The formula captures the intuition that larger vocabularies, longer sequences, and higher dimensions all increase parameter count. But the dominant term is : the transformer layers, repeated times.
Inside a Transformer Layer
Each transformer layer consists of two sublayers, each followed by layer normalization:
- Multi-head self-attention: Allows tokens to gather information from other positions
- Feed-forward network (FFN): Applies the same transformation to each position independently
The attention sublayer requires four projection matrices: Query (), Key (), Value (), and Output (). Each matrix has shape , contributing parameters. With four matrices, attention adds parameters.
The feed-forward network consists of two linear transformations. The first expands from dimension to (typically ), and the second contracts back from to . This requires parameters.
Each layer also has two layer normalizations (one before attention, one before FFN in the Pre-LN configuration), each with scale and bias vectors of dimension . This adds parameters per layer.
Putting it together:
where:
- : the four attention projection matrices (, , , )
- : the two feed-forward linear layers. With , this becomes .
- : scale and bias for two layer normalizations
Notice that the per-layer count scales with . This quadratic dependence explains why increasing the hidden dimension has such a dramatic effect on model size: doubling quadruples the parameters in each layer.
A Worked Example: GPT-3 175B
Let's apply these formulas to GPT-3's actual configuration:
- Vocabulary size: tokens (the GPT-2 tokenizer vocabulary)
- Maximum sequence length: tokens
- Model dimension:
- Number of layers:
- Feed-forward dimension:
First, we calculate the per-layer parameters:
Each layer contributes about 1.81 billion parameters. With 96 layers, the transformer stack alone accounts for approximately 174 billion parameters. The remaining 1+ billion come from embeddings and the output projection.
This breakdown reveals an important pattern: the transformer layers dominate the parameter count. Increasing the number of layers or the hidden dimension has a much larger effect than expanding the vocabulary or context length.
Implementation
Let's implement this calculation to verify our formulas and explore how parameters distribute across components:
The output confirms our manual calculation. The vast majority of parameters, over 173 billion, reside in the 96 transformer layers. This makes sense: each layer contributes about 1.8 billion parameters through its attention projections and feed-forward network, and with 96 layers, these add up quickly.
The embedding layers tell an interesting story. Despite handling a vocabulary of 50,257 tokens, the token embeddings account for only about 0.62 billion parameters, less than 1% of the total. The position embeddings are even smaller at 0.025 billion (25 million) parameters. The output projection mirrors the token embedding in size but is kept separate in GPT-3 rather than being weight-tied.
This distribution has practical implications. If you want a larger model, adding layers or increasing the hidden dimension is far more effective than expanding the vocabulary or context length. Conversely, if you want a smaller model, the layers are where you need to cut.
The visualization below makes this distribution strikingly clear:
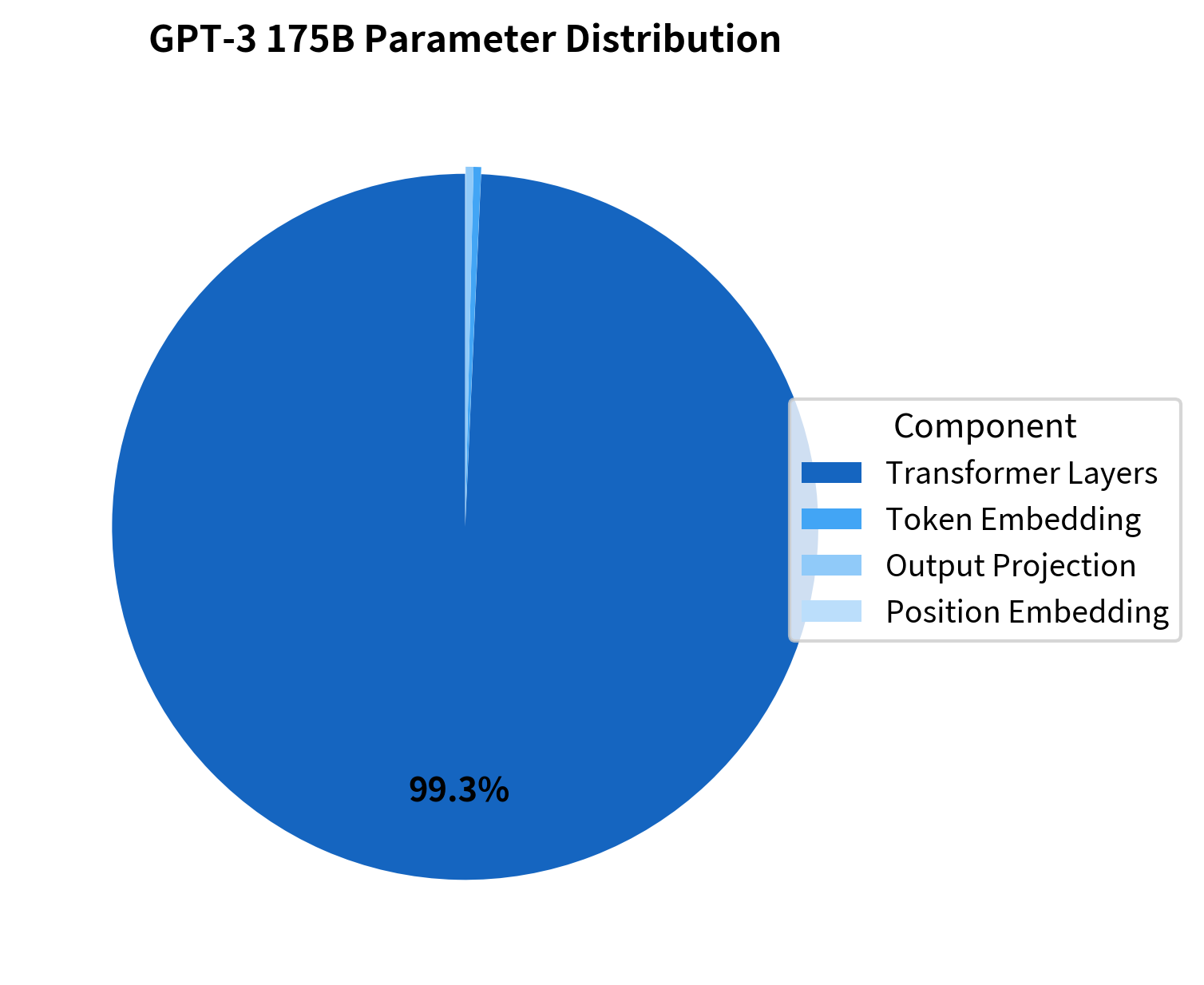
The pie chart reveals just how lopsided the distribution is: the transformer layers are so dominant that the embeddings and output projection are barely visible. This concentration of parameters in the processing layers, rather than the input/output interfaces, reflects where the model's computational "thinking" happens. The embeddings convert tokens to vectors and back, but the layers are where the model transforms and reasons about those representations.
The Discovery of In-Context Learning
GPT-3's most significant contribution wasn't its architecture but what it revealed about large-scale language models: they can learn new tasks from examples provided in the prompt, without any gradient updates. This capability, called in-context learning (ICL), emerged as a surprise during evaluation.
In-context learning is the ability of a language model to perform a task by conditioning on a few examples (demonstrations) in the input prompt, without updating the model's parameters. The model "learns" the task pattern from the examples and applies it to new inputs.
Consider a sentiment classification task. Instead of fine-tuning a model on thousands of labeled examples, you can simply show GPT-3 a few examples in the prompt:
Review: "This movie was absolutely fantastic!"
Sentiment: Positive
Review: "I wasted two hours of my life on this garbage."
Sentiment: Negative
Review: "The acting was decent but the plot made no sense."
Sentiment:
GPT-3 would then complete this with "Negative" or "Mixed", having inferred the classification pattern from just two examples.
Zero-Shot, One-Shot, and Few-Shot Learning
OpenAI's GPT-3 paper systematically compared three prompting strategies:
- Zero-shot: The model receives only a task description, with no examples
- One-shot: The model sees one example before the test input
- Few-shot: The model sees multiple examples (typically 10-100, limited by context length)
The key insight from GPT-3's evaluation was that performance scaled predictably with both model size and number of examples:
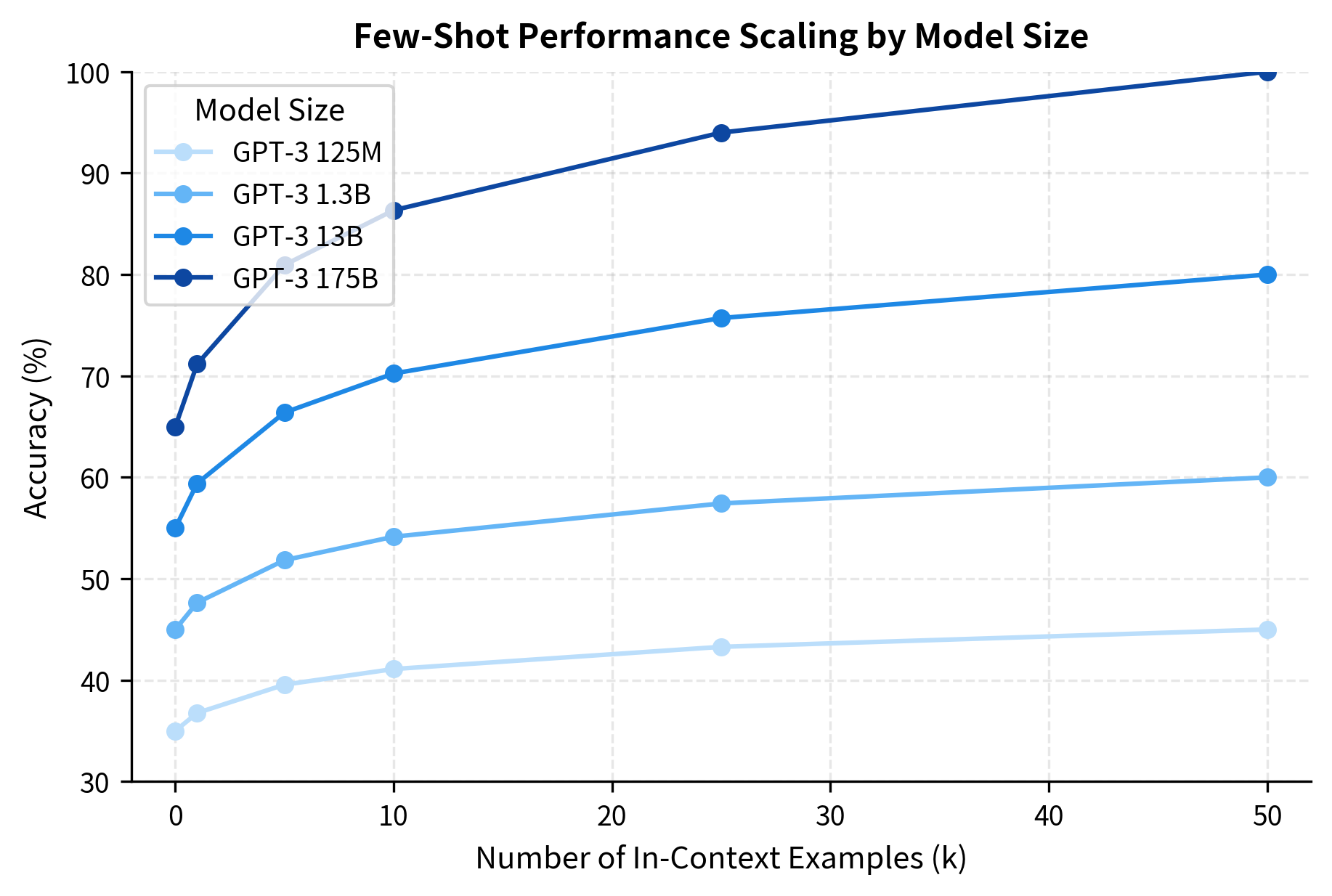
This scaling pattern revealed something important: in-context learning is not simply pattern matching or memorization. It requires sufficient model capacity to represent the task and generalize from examples. Smaller models plateau quickly, while larger models continue to benefit from additional demonstrations.
Evaluating GPT-3's Capabilities
The GPT-3 paper evaluated the model across dozens of NLP benchmarks. Performance varied dramatically by task type, revealing both the potential and limits of in-context learning.
Strong Performance: Language Understanding
GPT-3 achieved impressive results on tasks requiring broad language understanding:
| Task | Dataset | GPT-3 Few-Shot | Fine-Tuned SOTA |
|---|---|---|---|
| Reading Comprehension | RACE-h | 46.8% | 90.0% |
| Question Answering | TriviaQA | 71.2% | 75.4% |
| Commonsense Reasoning | PIQA | 82.8% | 79.4% |
| Word Scrambling | Anagrams | 66.9% | N/A |
On TriviaQA, GPT-3's few-shot performance (71.2%) approached the fine-tuned state-of-the-art (75.4%), despite never being explicitly trained on the task. On physical commonsense reasoning (PIQA), it actually exceeded the previous best fine-tuned model.
Emergent Capabilities
Perhaps most striking were capabilities that emerged without explicit training:
- Arithmetic: GPT-3 could perform multi-digit addition and subtraction with reasonable accuracy, despite never being trained on a math curriculum
- Code generation: It could write functional code snippets in Python and JavaScript from natural language descriptions
- Translation: Few-shot GPT-3 matched or exceeded supervised baselines on some language pairs, particularly for translating into English
- News article generation: Given headlines, it produced articles that human evaluators struggled to distinguish from real news
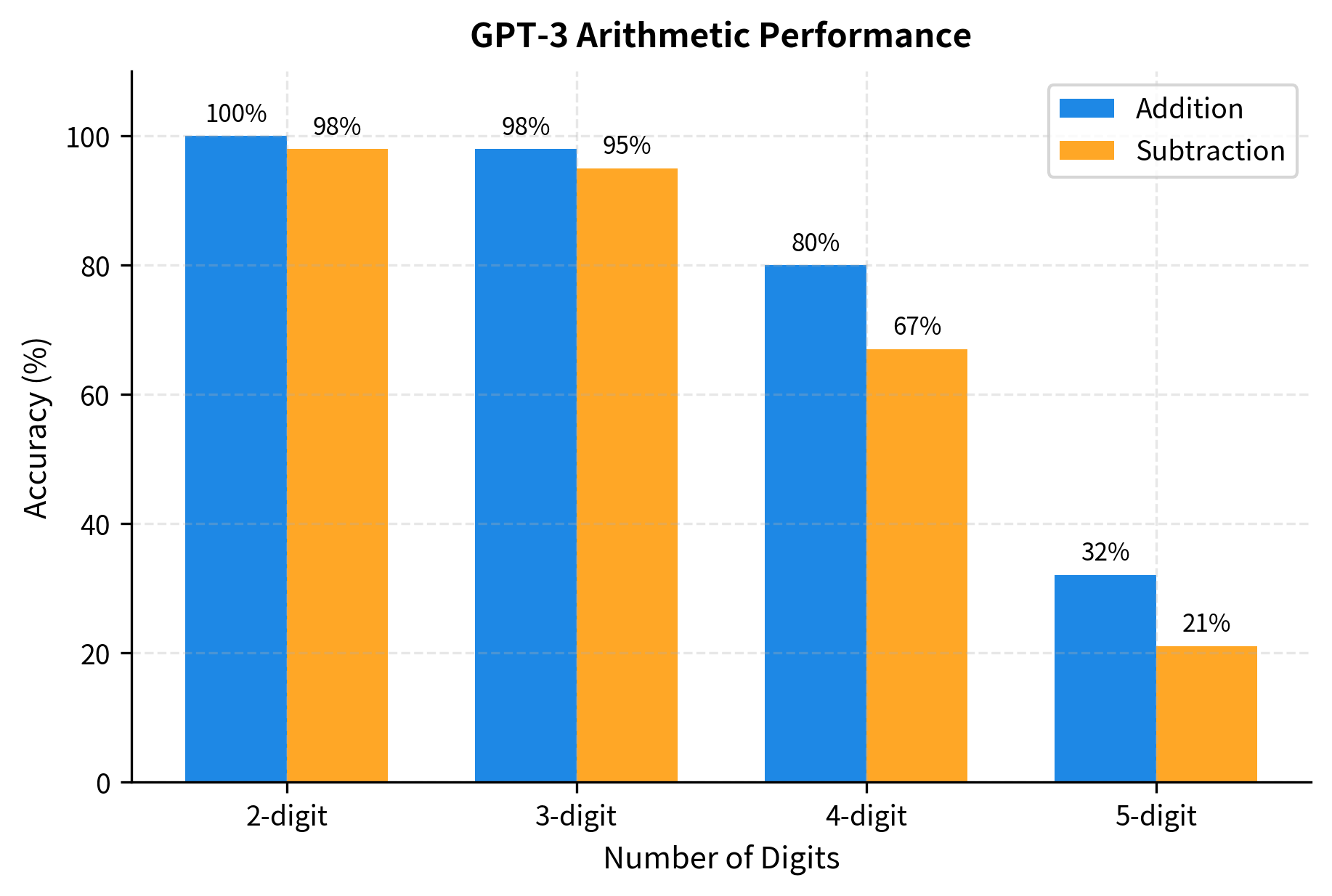
The arithmetic results are particularly interesting because they suggest the model learned algorithmic procedures rather than memorizing specific calculations. Performance degrades gracefully with more digits, the pattern you'd expect from imperfect procedure learning rather than lookup table failure.
Weak Performance: Structured Tasks
GPT-3 struggled on tasks requiring precise, structured outputs or multi-step reasoning:
- Reading comprehension with multiple choice: On RACE-h, GPT-3 achieved only 46.8% compared to 90% for fine-tuned models
- Natural language inference: Performance on ANLI (adversarial NLI) remained below random chance for some splits
- Math word problems: Multi-step reasoning with intermediate calculations proved challenging
- Fact verification: Distinguishing true from false claims required external knowledge verification
These weaknesses pointed to fundamental limitations: GPT-3 excels at pattern completion and surface-level understanding but struggles with tasks requiring careful logical reasoning or precise knowledge retrieval.
How In-Context Learning Works
The mechanism behind in-context learning remained mysterious. How can a model "learn" a task without updating its weights? Several hypotheses emerged from subsequent research:
Hypothesis 1: Task Recognition
One theory suggests that pretraining exposes the model to many implicit task formats. When given few-shot examples, GPT-3 recognizes the pattern from pretraining and activates the appropriate "circuit" for that task. The examples don't teach the model something new; they help it identify which of its existing capabilities to apply.
The analysis reveals structural patterns that a model might use to identify the task. With only two unique outputs (Positive, Negative) and short single-word responses, the format clearly signals a binary classification task. The model may recognize this pattern from similar structures encountered during pretraining, such as review datasets or labeled examples in web text.
Hypothesis 2: Implicit Fine-Tuning
Another perspective views the forward pass through GPT-3's 96 layers as an implicit optimization process. The key insight is that transformer layers can implement gradient-descent-like updates on the representations. Consider a single attention layer operating on demonstrations followed by a test input . The attention mechanism computes:
where:
- : the initial representation of the test input before attention
- : the attention weight from the test input to demonstration
- : the value vector derived from demonstration
- : the number of demonstrations in context
This weighted sum resembles a gradient update: the model adjusts its representation of the test input based on the demonstrations. With 96 layers, the model has substantial "depth" to iteratively refine this adaptation. Research has shown that in-context learning and fine-tuning produce similar representational changes, even though one updates weights and the other doesn't.
Hypothesis 3: Bayesian Inference
A third hypothesis frames in-context learning as Bayesian inference over tasks. The model implicitly maintains a prior distribution over possible tasks from pretraining. Each demonstration updates this posterior according to Bayes' rule:
where:
- : the prior probability of each task, learned during pretraining from exposure to diverse text formats
- : the likelihood of output given input under a specific task interpretation
- : the posterior probability of each task after observing demonstrations
By the time the model reaches the test input, it has narrowed down the task distribution sufficiently to make a confident prediction. This view explains why more demonstrations help: each one provides additional evidence that sharpens the posterior.



Prompt Engineering Principles
The success of in-context learning spawned a new discipline: prompt engineering. Researchers discovered that how you format prompts dramatically affects performance.
Format Matters
Small changes in prompt format can yield large performance differences:
Research showed that the conversational format often performs best for GPT-3, likely because its training data contains many examples of conversational task-solving. The optimal format varies by model and task, requiring empirical experimentation.
Example Selection and Ordering
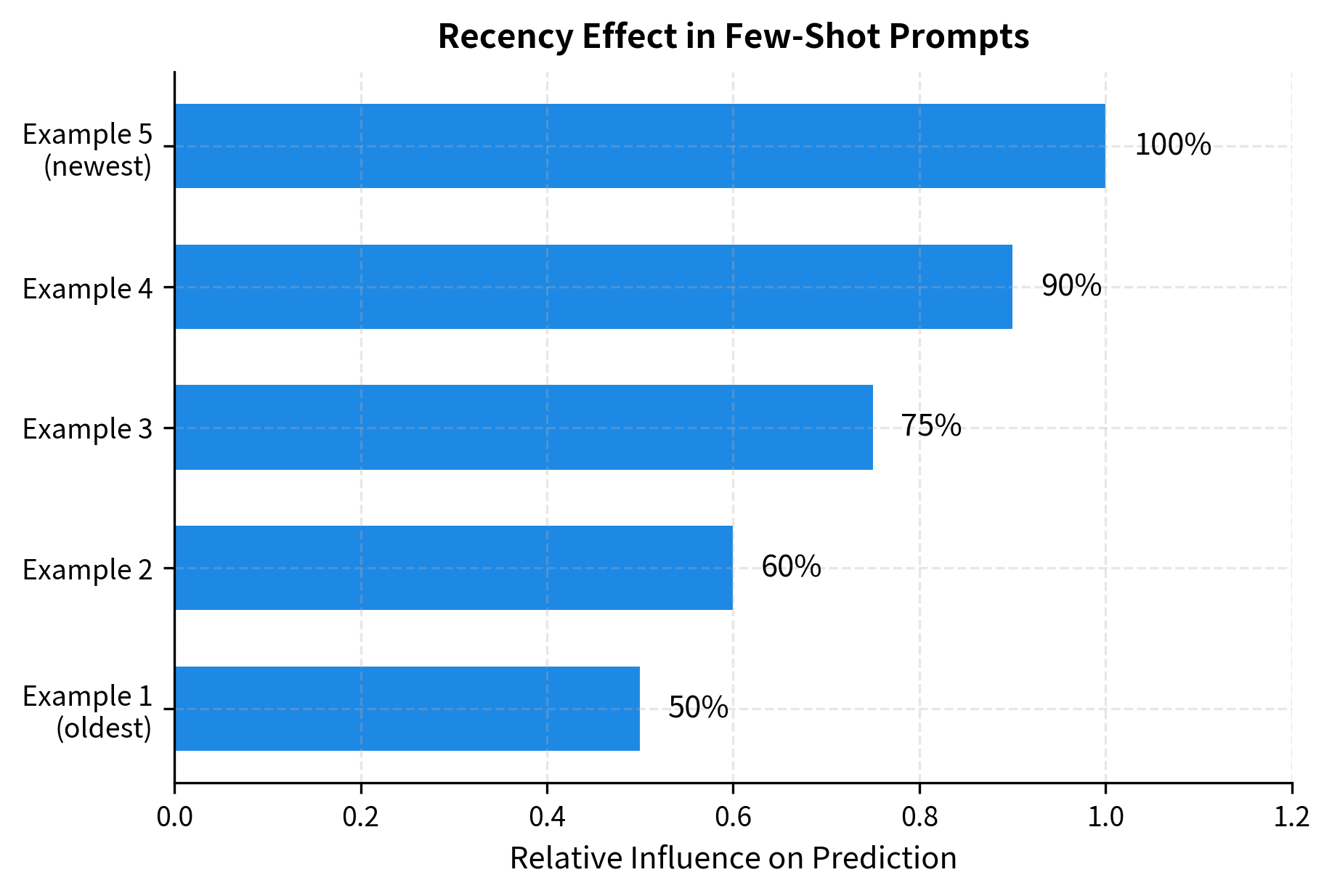
The choice and order of few-shot examples strongly affects performance:
- Diversity: Examples should cover the range of possible inputs and outputs
- Similarity: Examples semantically similar to the test input often help more
- Recency: Examples closer to the end of the prompt have stronger influence
- Balance: For classification, examples should be balanced across classes
The Label Matters (Sometimes)
A surprising finding was that the actual labels in few-shot examples don't always matter. In some experiments, randomly assigning labels (positive reviews labeled "Negative" and vice versa) still improved performance over zero-shot, suggesting the model was learning format rather than task semantics.
However, for more complex tasks, correct labels improve performance considerably. The model can leverage both the format pattern and the actual input-output mapping.
Limitations and Concerns
GPT-3's release sparked both excitement and concern. While the model demonstrated impressive capabilities, it also exposed fundamental challenges that persist in large language models today. These limitations fall into several categories: reliability of outputs, sensitivity to inputs, societal impacts, and practical constraints.
Factual Errors and Hallucinations
GPT-3 confidently produces plausible-sounding but incorrect information. It might cite nonexistent studies, invent historical events, or provide wrong answers to factual questions. The model has no mechanism to verify claims against external sources or acknowledge uncertainty.
This limitation is particularly dangerous because GPT-3's outputs are fluent and authoritative. Users may accept incorrect information because it sounds convincing. The model's confidence is orthogonal to its accuracy.
Sensitivity to Prompts
Performance is brittle with respect to prompt phrasing. Changing a single word or reordering examples can shift accuracy by 10-20 percentage points. This makes reliable deployment challenging: a prompt that works well on test examples might fail unexpectedly on edge cases.
Bias and Fairness
GPT-3 amplifies biases present in its training data. It associates certain occupations with genders, exhibits racial stereotypes, and can generate toxic content when prompted. The model learned these patterns from internet text and has no mechanism to distinguish harmful biases from useful patterns.




Context Length Constraints
With a 2,048 token context, GPT-3 cannot process long documents or maintain extended conversations. Few-shot learning is limited by how many examples fit in the context window. For tasks requiring synthesis across multiple documents, GPT-3 must work with truncated or summarized inputs.
Environmental and Access Concerns
Training GPT-3 consumed enormous computational resources with associated carbon emissions. Access was restricted to an API controlled by OpenAI, raising concerns about democratization of AI research. Only well-funded organizations could experiment with the full model, creating imbalances in who could study and critique these systems.
Impact on the Field
GPT-3's impact extended far beyond its benchmark scores. It changed how researchers and practitioners think about NLP.
Prompting as a New Paradigm
Before GPT-3, the standard approach was to fine-tune pretrained models for specific tasks. GPT-3 demonstrated that sufficiently large models could be steered through prompting alone. This shifted research attention toward:
- Prompt engineering: Systematic study of how prompt design affects performance
- Instruction tuning: Training models to follow natural language instructions
- Chain-of-thought prompting: Encouraging models to show reasoning steps
Scaling Laws
GPT-3 contributed to the formalization of scaling laws: mathematical relationships between model size, training compute, dataset size, and performance. The key insight is that test loss follows a power-law relationship with each scaling factor:
where:
- : the test loss as a function of model parameters
- : the number of model parameters
- : a constant that depends on the dataset and architecture
- : the scaling exponent for parameters (empirically determined)
Similar relationships hold for dataset size and training compute :
where for dataset tokens and for compute. These power laws mean that each 10x increase in resources yields a predictable (though diminishing) improvement in loss.
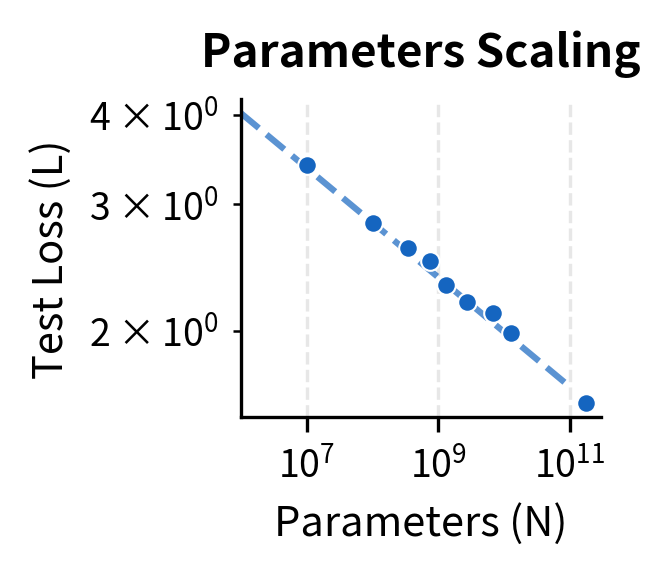
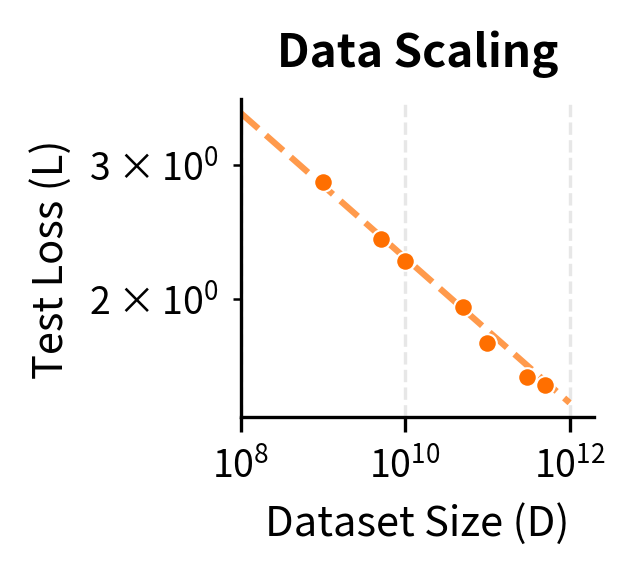
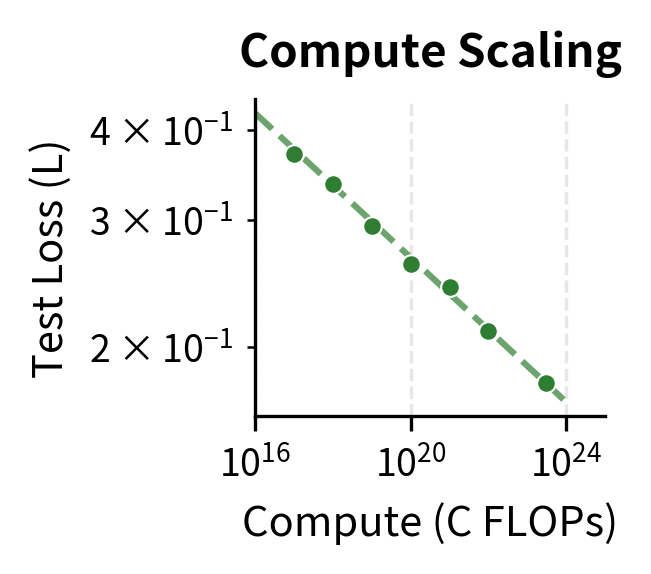
The scaling law perspective suggested that many apparent limitations might be overcome by simply training larger models on more data. This hypothesis, controversial at the time, proved partially correct with subsequent models.
Foundation Models
GPT-3 exemplified the "foundation model" concept: a single large model pretrained on diverse data that can be adapted to many downstream tasks. Rather than training separate models for translation, summarization, and question answering, a single foundation model handles all tasks through different prompts or lightweight adaptation.
This paradigm consolidated AI development around a few very large models, shifting the field toward centralized training and distributed deployment.
Summary
GPT-3 marked a turning point in language AI, demonstrating that scale itself could unlock new capabilities. Its 175 billion parameters, trained on hundreds of billions of tokens, produced a model capable of few-shot learning: adapting to new tasks from just a handful of examples in the prompt.
Key takeaways from GPT-3:
- Scale enables emergence: In-context learning appeared as model size increased, suggesting that some capabilities require a threshold of capacity before manifesting
- Few-shot learning works: Providing examples in the prompt can match or exceed fine-tuned models for certain tasks, without any parameter updates
- Prompt design matters: The format, ordering, and content of prompts strongly affect performance, spawning the field of prompt engineering
- Limitations persist: Hallucinations, bias, reasoning failures, and context constraints remain challenges that scale alone doesn't solve
- Paradigm shift: GPT-3 accelerated the move from task-specific fine-tuning toward general-purpose foundation models
The model's release catalyzed an industry-wide race to scale, leading to GPT-4, Claude, PaLM, and other models that pushed beyond GPT-3's capabilities. But GPT-3's core insight endures: with sufficient scale, language models develop surprising and useful behaviors that weren't explicitly trained.
Key Parameters
When working with GPT-3 and similar large language models, several parameters affect performance and behavior:
-
temperature: Controls randomness in token sampling. Values range from 0.0 (deterministic, always choosing the highest probability token) to 2.0 (highly random). Common values are 0.7-1.0 for creative tasks and 0.0-0.3 for factual tasks. Lower temperatures produce more focused, predictable outputs; higher temperatures increase diversity but may reduce coherence.
-
max_tokens: The maximum number of tokens to generate in the response. Set this based on expected output length to control costs and latency. GPT-3 supports up to 2,048 tokens total (prompt + completion combined), so longer prompts leave less room for generation.
-
top_p (nucleus sampling): An alternative to temperature that samples from the smallest set of tokens whose cumulative probability exceeds the threshold. A value of 0.9 means the model considers tokens until their probabilities sum to 90%. Generally, adjust either temperature or top_p, but not both simultaneously.
-
frequency_penalty: Reduces repetition by penalizing tokens based on how often they appear in the generated text so far. Values range from 0.0 to 2.0. Higher values discourage the model from repeating the same phrases, useful for open-ended generation.
-
presence_penalty: Penalizes tokens based on whether they have appeared at all, regardless of frequency. This encourages the model to introduce new topics. Values range from 0.0 to 2.0. Useful when you want diverse, wide-ranging outputs.
-
n_examples (few-shot count): The number of demonstrations to include in the prompt. More examples generally improve performance but consume context space. Empirically, 4-8 examples often provide good results while leaving room for the test input and response. Beyond 20-30 examples, returns typically diminish.
-
stop sequences: Tokens or strings that signal generation should stop. For few-shot prompts, include delimiters like
"\n\n"or"Input:"to prevent the model from generating additional examples. Proper stop sequences ensure clean, usable outputs.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about GPT-3, few-shot learning, and in-context learning.

Comments