

Explore the GPT-1 architecture, pre-training objective, fine-tuning approach, and transfer learning results that established the foundation for modern large language models.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
GPT-1
In June 2018, OpenAI released a paper titled "Improving Language Understanding by Generative Pre-Training." The model it introduced, later known as GPT-1, wasn't the largest language model of its time, nor did it immediately dominate benchmarks. But it showed that a simple recipe of unsupervised pre-training on raw text followed by supervised fine-tuning could achieve state-of-the-art results across diverse NLP tasks. This "pre-train then fine-tune" approach would become the dominant paradigm.
GPT-1 arrived at an important moment. Researchers knew that language models trained on large corpora learn useful representations, but the prevailing wisdom held that task-specific architectures were necessary for each downstream application. GPT-1 challenged this assumption. By using a single, unified transformer decoder architecture for both pre-training and fine-tuning, it showed that generative pre-training creates representations rich enough to transfer across classification, similarity, entailment, and question answering tasks with minimal architectural changes.
This chapter explores the GPT-1 architecture in detail. We'll examine its decoder-only design, understand the pre-training objective and data, walk through the fine-tuning approach that enabled transfer learning, and assess the model's impact on the trajectory of NLP research.
The Architecture
GPT-1 uses a decoder-only transformer architecture, a design choice that distinguished it from contemporary models like ELMo (which used bidirectional LSTMs) and from the later BERT (which used bidirectional transformer encoders). The decoder-only choice wasn't arbitrary: it enabled a simple, scalable pre-training objective based on next-token prediction.
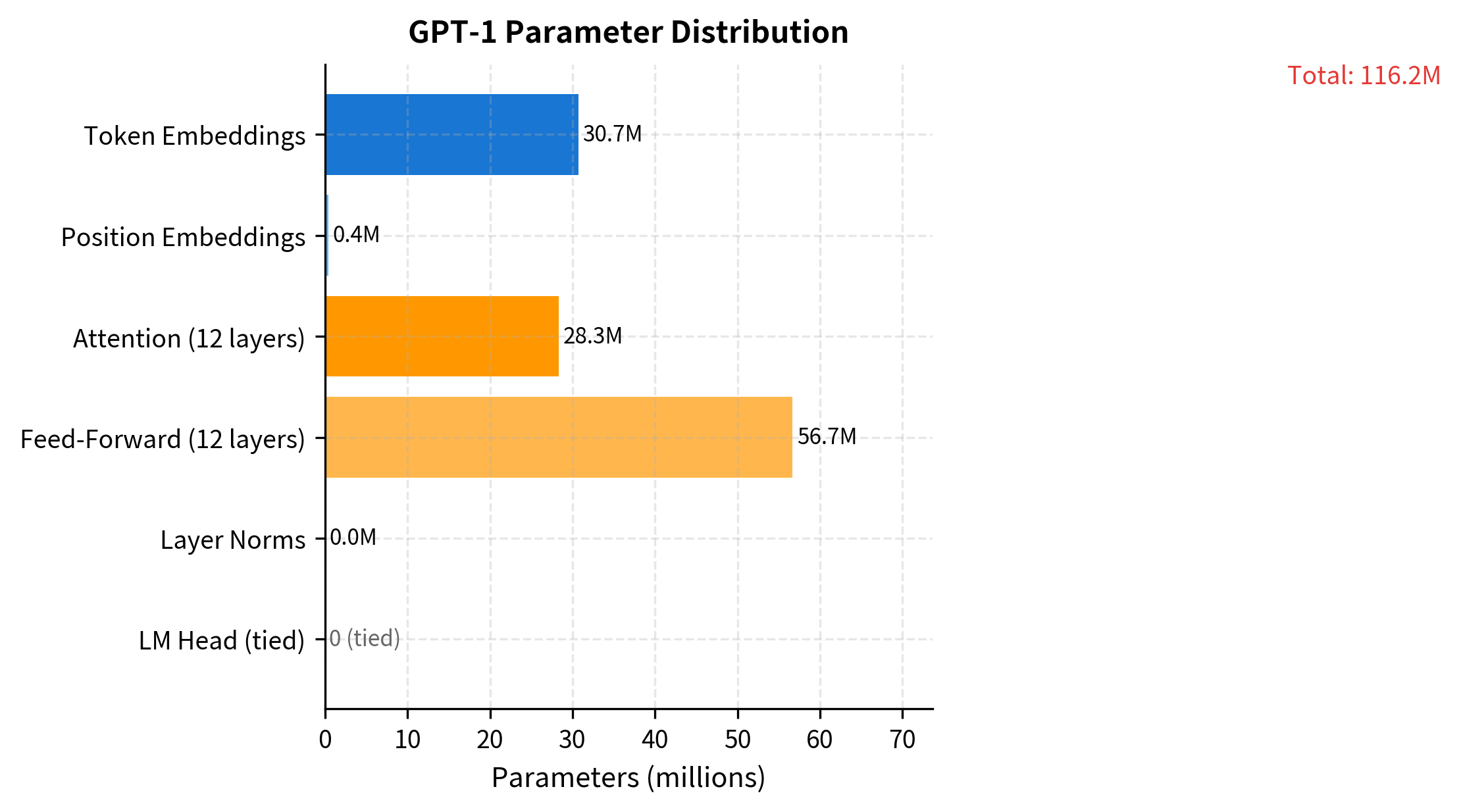
GPT-1 consists of 12 transformer decoder layers with 12 attention heads each, a hidden dimension of 768, and a context window of 512 tokens. The model contains approximately 117 million parameters.
The architectural specifications are:
| Parameter | Value |
|---|---|
| Layers | 12 |
| Hidden size () | 768 |
| Attention heads | 12 |
| Head dimension | 64 |
| Feed-forward size | 3072 |
| Context window | 512 tokens |
| Vocabulary size | 40,000 (BPE) |
| Parameters | ~117M |
These numbers match BERT-Base closely (which also has 12 layers, 768 hidden dimensions, and 12 heads), enabling direct comparisons. The key architectural difference lies in the attention pattern: GPT-1 uses causal masking where each position can only attend to previous positions, while BERT uses bidirectional attention where each position attends to the full sequence.
Transformer Decoder Stack
Each layer in GPT-1 follows the standard transformer decoder block pattern. The input passes through masked multi-head self-attention, then a position-wise feed-forward network, with residual connections and layer normalization around each sublayer:
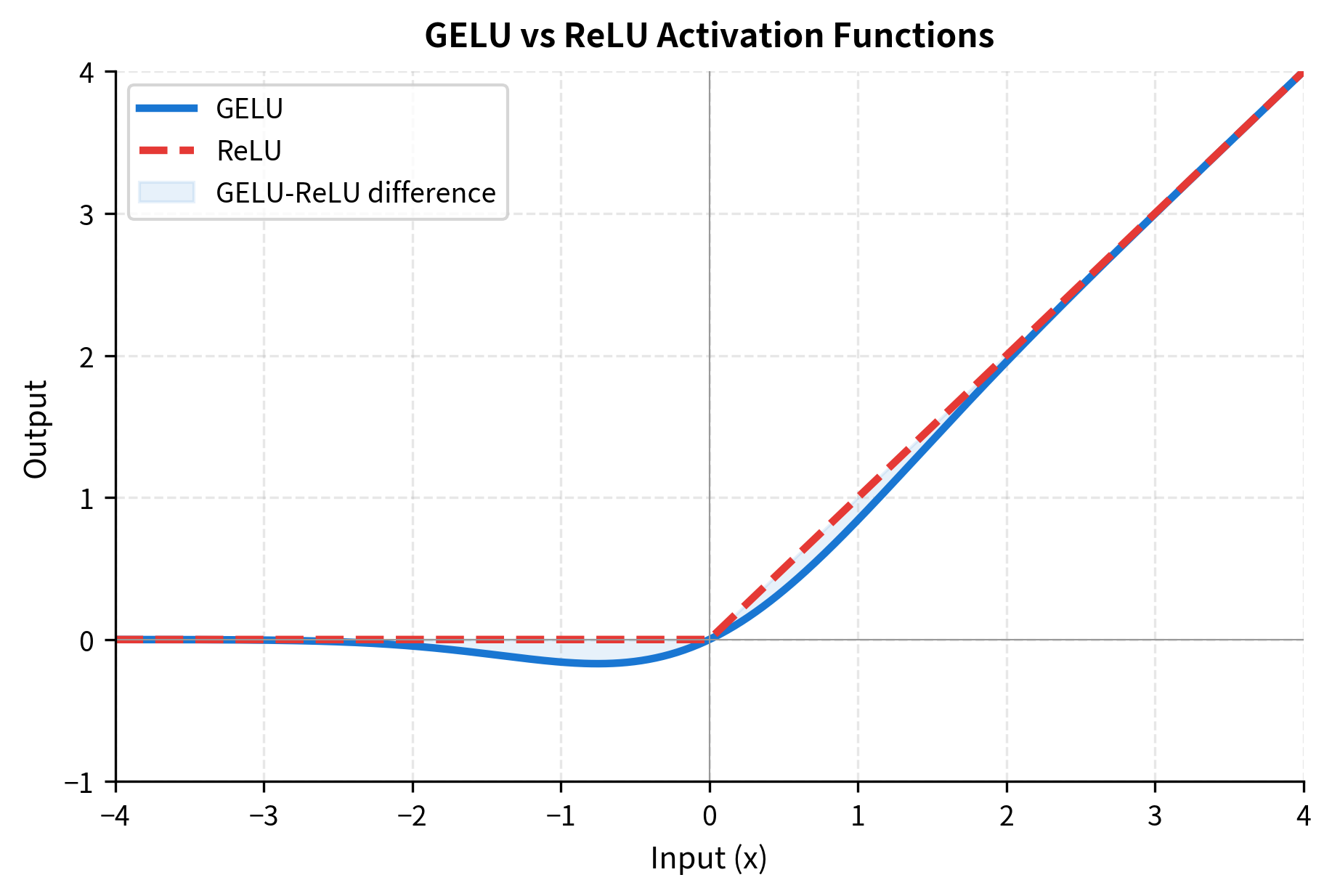
GPT-1 uses GELU activation in the feed-forward network rather than ReLU. GELU provides a smoother non-linearity that empirically improves training dynamics in transformer models. The activation function multiplies each input value by the probability that a standard normal random variable would be less than that value:
where:
- : the input value to the activation function
- : the cumulative distribution function (CDF) of the standard normal distribution, which gives the probability that a standard Gaussian random variable is less than
- : the output, which smoothly transitions between suppressing small/negative values and passing large positive values
This formulation creates a smooth gating effect. For large positive , , so the output is approximately . For large negative , , so the output is approximately 0. Unlike ReLU's hard cutoff at zero, GELU provides a gradual transition that can improve gradient flow during training.
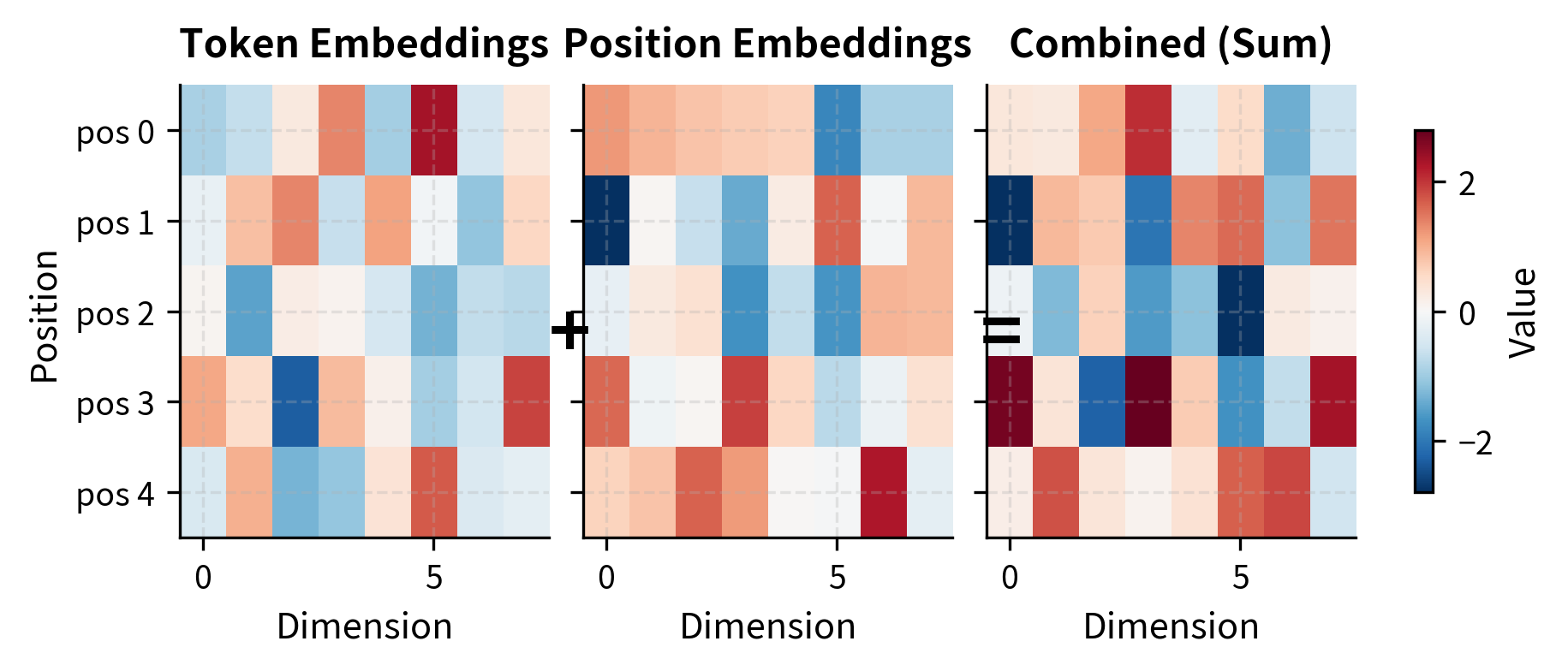
Input Representation
GPT-1's input representation combines token embeddings with learned position embeddings. Unlike the sinusoidal positional encodings from the original transformer paper, GPT-1 learns position embeddings during training. This allows the model to discover position-specific patterns relevant to its training data:
The embedding layer transforms input token IDs into 768-dimensional vectors. Adding position embeddings directly to token embeddings (rather than concatenating) keeps the hidden dimension constant throughout the network, matching the original transformer design.
Causal Masking
The defining characteristic of GPT-1's decoder architecture is causal masking. During the forward pass, each token can only attend to tokens at earlier positions in the sequence. This constraint ensures that the model cannot "cheat" by looking at future tokens when predicting the next token:
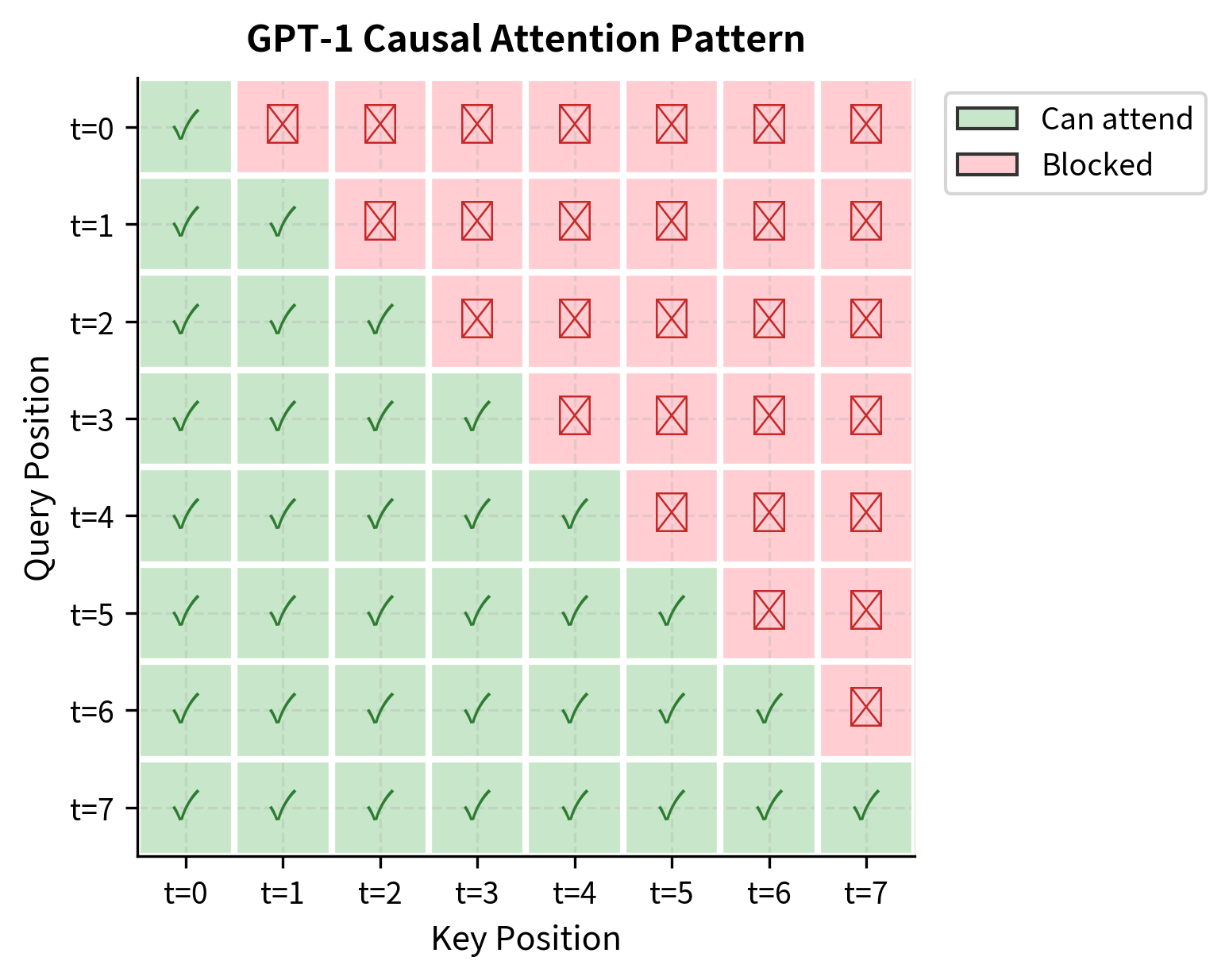
The triangular pattern shows that position 0 can only attend to itself, position 1 can attend to positions 0 and 1, and so on. Position 7 (the last position) can attend to all positions. This asymmetry means that later positions have access to more context, which is why language models typically generate text from left to right.
Complete Model Architecture
Assembling the components, the complete GPT-1 architecture stacks 12 decoder layers between the embedding layer and a final language modeling head:
The model contains approximately 117 million parameters. Note the weight tying between the input token embeddings and the output projection layer (lm_head). This technique reduces parameters by about 30 million (40,000 vocabulary × 768 dimensions) and has been shown to improve performance by enforcing consistency between how tokens are represented at input and predicted at output.
Pre-Training Objective
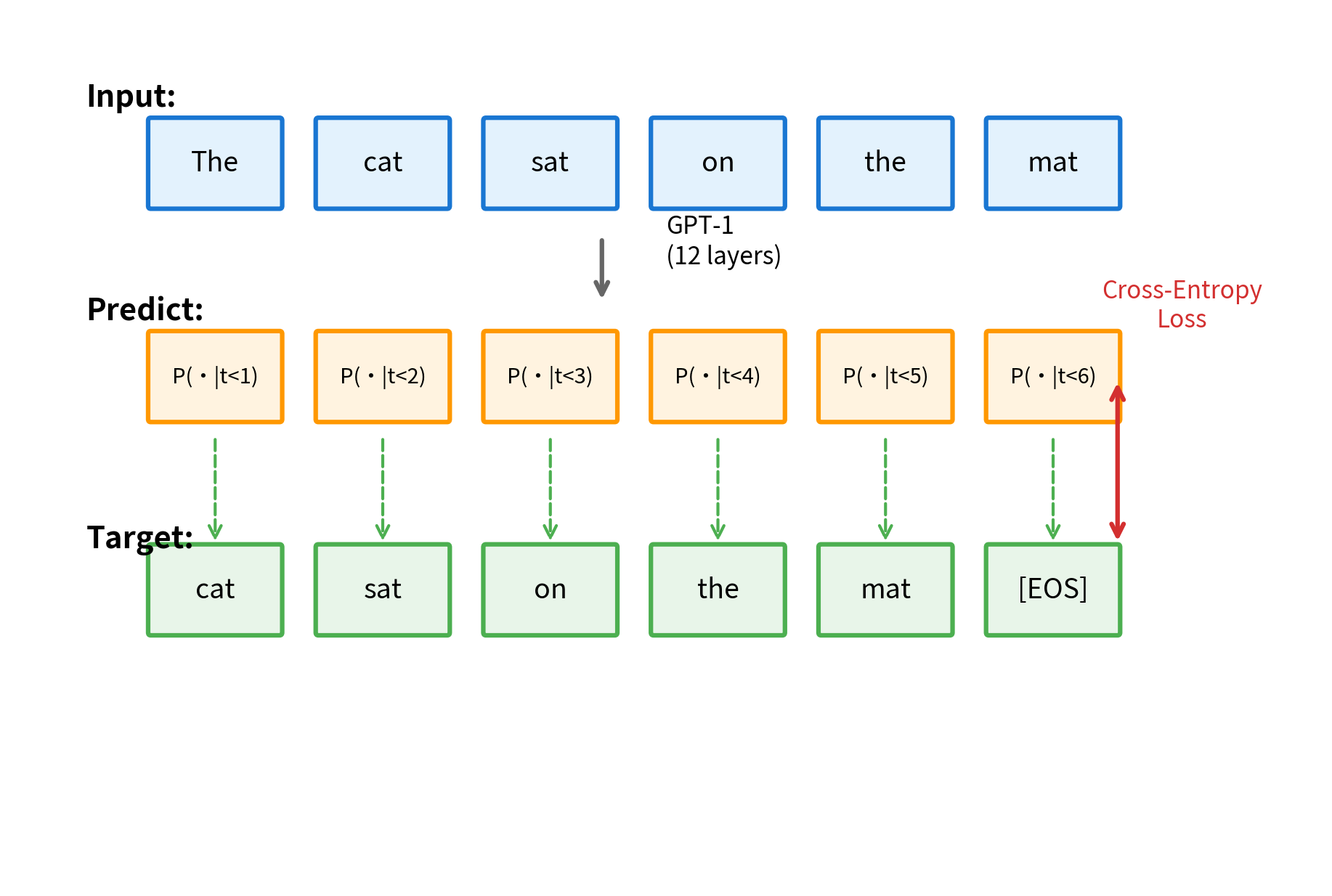
GPT-1's pre-training objective is straightforward: predict the next token given all previous tokens. This is the standard language modeling objective, also called causal language modeling or autoregressive language modeling.
Given a sequence of tokens , the model learns to maximize the likelihood of each token given its prefix: .
For a sequence of tokens , the pre-training objective is to maximize:
where:
- : the language modeling loss function (log-likelihood to maximize)
- : the input sequence of tokens
- : the token at position
- : the probability of token given all preceding tokens, parameterized by model weights
- : all learnable parameters of the model (embeddings, attention weights, feed-forward weights)
In practice, this is implemented as cross-entropy loss between the model's predicted distribution over the vocabulary and the actual next token at each position:
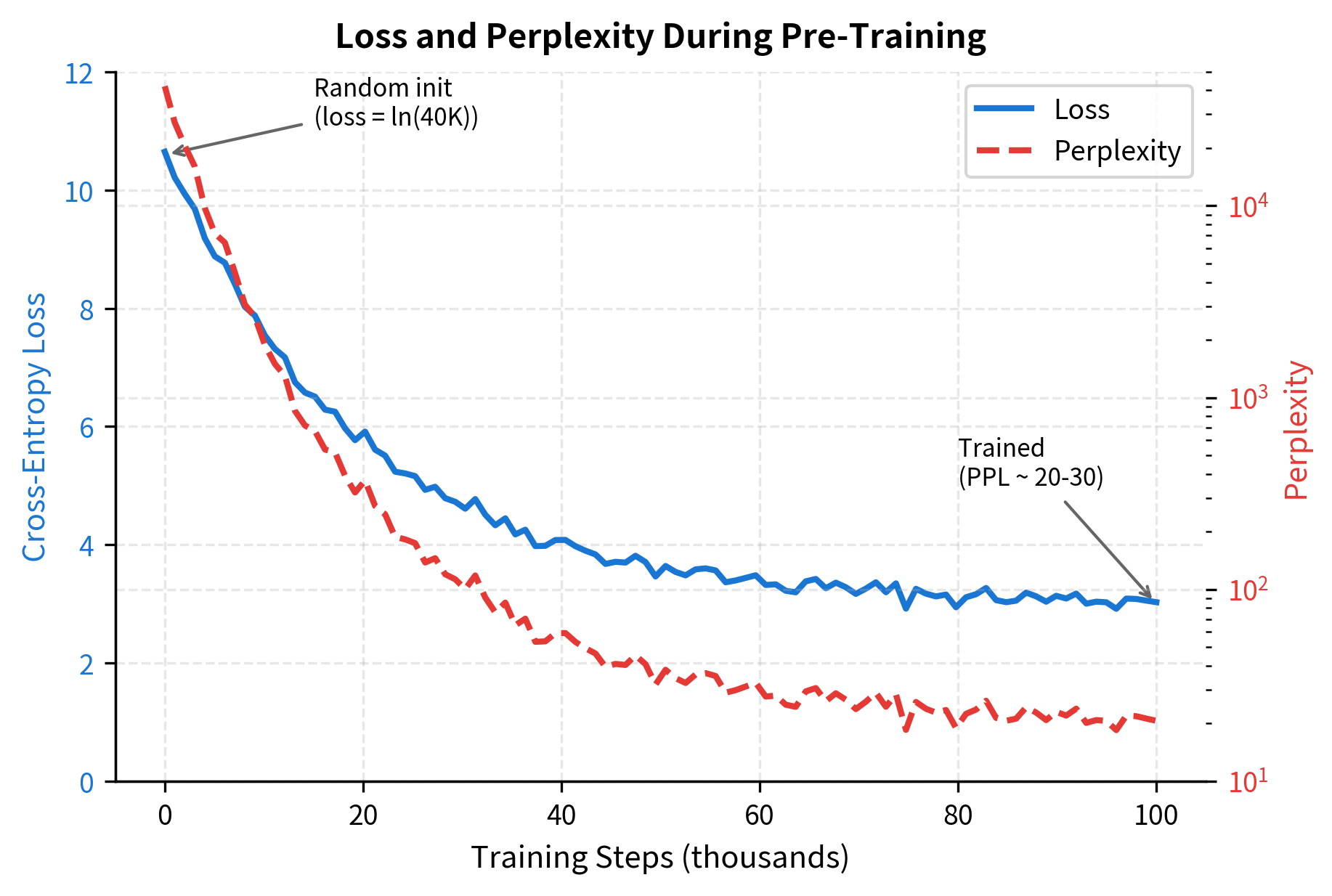
The loss on random input is approximately , which corresponds to perplexity equal to the vocabulary size. This is expected for an untrained model that assigns roughly uniform probability across the vocabulary. Training drives this loss down as the model learns to predict more accurately.
Pre-Training Data
GPT-1 was pre-trained on the BooksCorpus dataset, which contains approximately 7,000 unpublished books totaling about 800 million words. The BooksCorpus was chosen for its long-range coherent text, spanning many pages of continuous narrative. This differs from datasets like Wikipedia, where articles are relatively short and self-contained.
Key characteristics of the pre-training setup:
- Dataset: BooksCorpus (~800M words from ~7,000 books)
- Tokenization: Byte Pair Encoding (BPE) with 40,000 merge operations
- Context window: 512 tokens per training example
- Batch size: 64 sequences
- Training steps: 100 epochs over the dataset
- Optimizer: Adam with learning rate 2.5e-4, linear warmup over 2,000 steps, cosine annealing
The choice of BooksCorpus enabled the model to learn long-range dependencies across paragraphs and chapters. This was critical for the transfer learning hypothesis: if the model learned to predict coherent narratives, it might develop representations useful for understanding meaning, not just local syntax.
Visualizing Pre-Training Dynamics
Let's visualize how next-token prediction works during pre-training. At each position, the model outputs a probability distribution over the vocabulary, and training pushes this distribution toward placing high probability on the actual next token:
The key insight is that this objective provides dense supervision: every position in every training sequence contributes a gradient signal. Unlike masked language modeling (used in BERT), where only 15% of tokens are predicted, causal language modeling uses every token as a training signal. This makes efficient use of the training data.
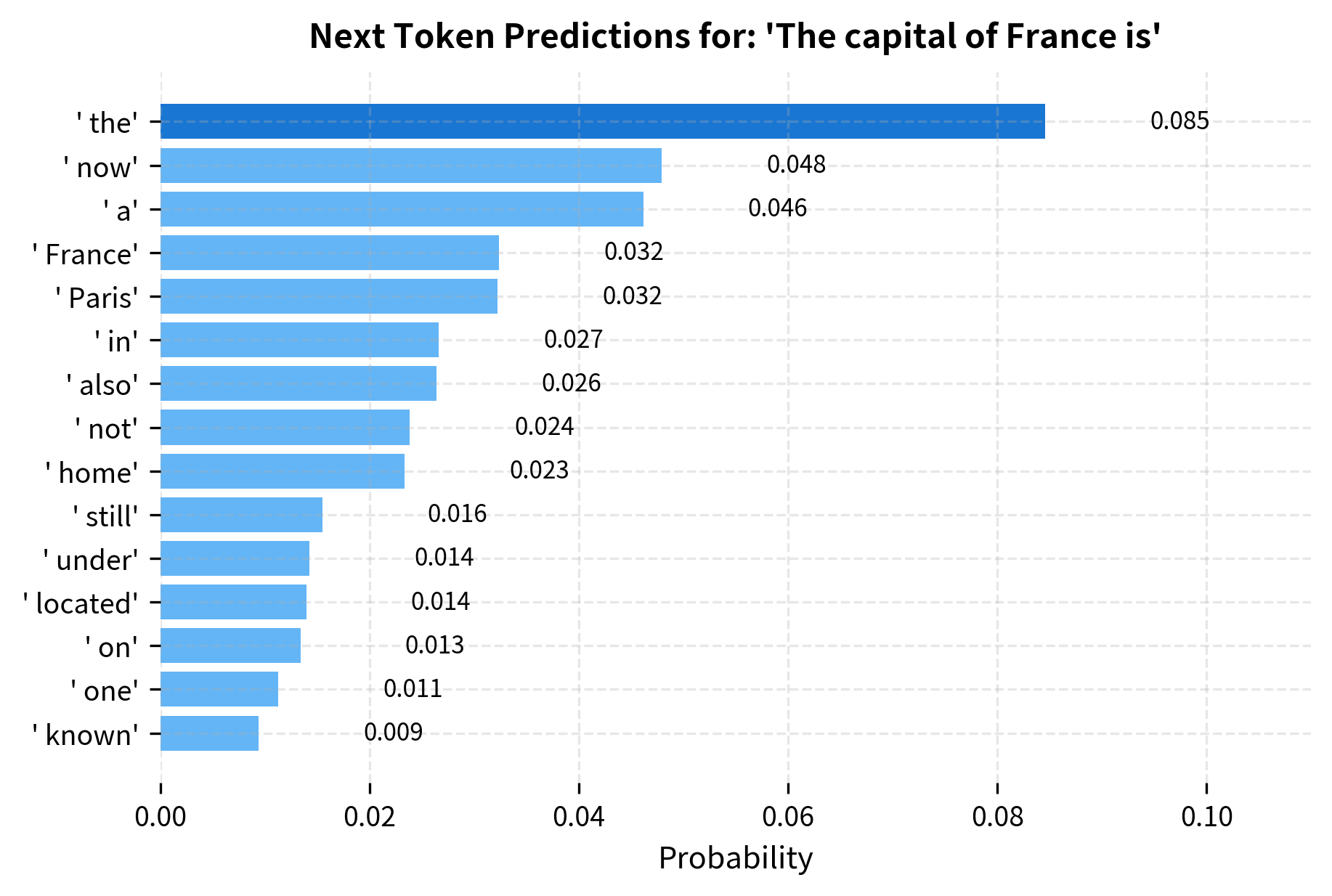
Fine-Tuning Approach
GPT-1's fine-tuning approach was central to its success. Rather than designing task-specific architectures, the same pre-trained model was adapted to each task with minimal modifications: add a simple classifier head and fine-tune all parameters end-to-end.
Input Transformation
The crucial innovation was transforming each task into a format compatible with the language model's interface. All tasks were converted into sequences of tokens that the model processes left-to-right:
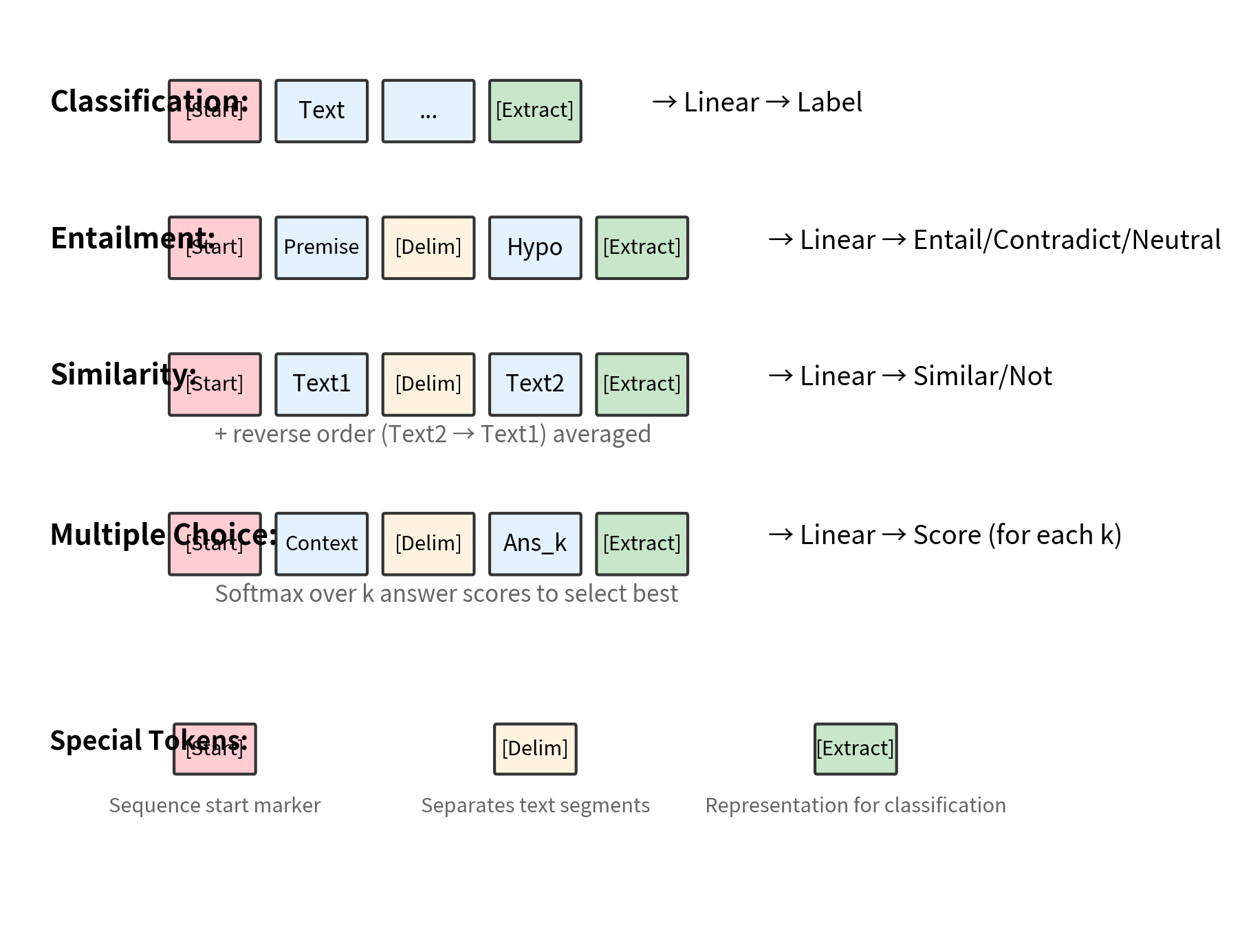
The input transformations follow a consistent pattern:
- Classification:
[Start] text [Extract], where the representation at[Extract]is used for classification - Entailment:
[Start] premise [Delim] hypothesis [Extract], which determines if premise entails hypothesis - Similarity:
[Start] text1 [Delim] text2 [Extract], processing both orderings and averaging - Multiple Choice/QA:
[Start] context [Delim] answer [Extract], scoring each answer independently with softmax over scores
The [Extract] token (sometimes called [CLS] in other models) is a special token whose final representation is used for the classification head. Because of causal attention, this token's representation aggregates information from the entire preceding sequence.
Fine-Tuning Loss
During fine-tuning, GPT-1 uses a combined objective that includes both the task-specific loss and a language modeling auxiliary loss:
where:
- : the task-specific loss (e.g., cross-entropy for classification)
- : the ground truth label for the task
- : the input sequence
- : the auxiliary loss weight (set to 0.5 in the original paper)
- : the language modeling loss on the input
The auxiliary language modeling loss serves two purposes. First, it acts as a regularizer, preventing the model from forgetting useful language patterns during fine-tuning. Second, it provides additional gradient signal, particularly useful when task-specific training data is limited.
The classification head adds minimal parameters (just 768 × num_classes), keeping fine-tuning efficient. The combined loss balances learning the task while maintaining the language model's learned representations.
Fine-Tuning Hyperparameters
GPT-1 used the following hyperparameters for fine-tuning:
- Learning rate: 6.25e-5 (lower than pre-training)
- Batch size: 32
- Epochs: 3 (most tasks)
- LM auxiliary weight (): 0.5
- Warmup: Linear warmup over 0.2% of training
- Dropout: 0.1 on classifier, 0.1 in attention/residual
The lower learning rate prevents catastrophic forgetting of pre-trained knowledge. Just 3 epochs were typically sufficient because the model started from a strong initialization. This contrasts sharply with training from scratch, which might require hundreds of epochs.
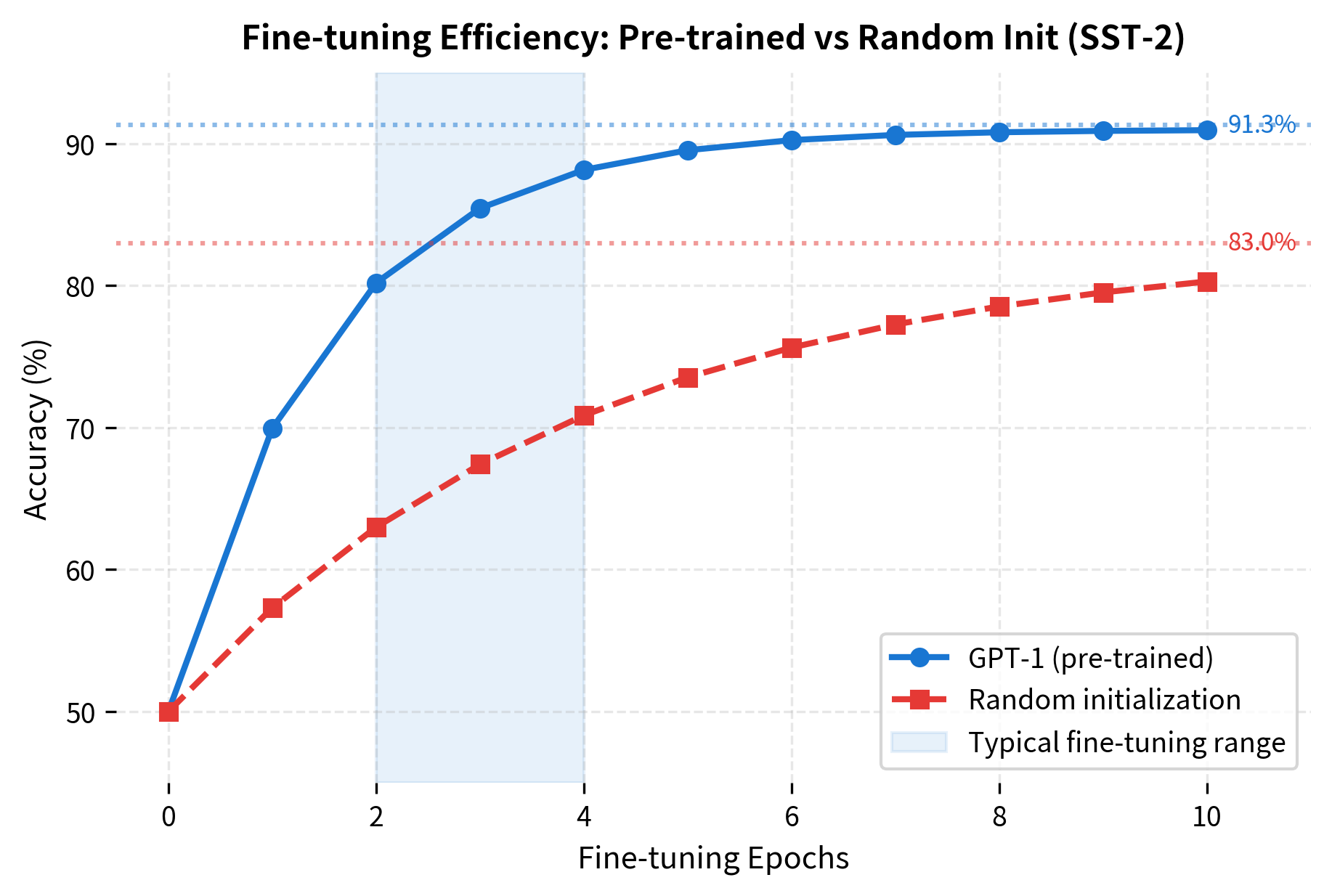
Transfer Learning Results
GPT-1 demonstrated strong transfer learning across 12 diverse NLP tasks. The pre-training on BooksCorpus, despite never seeing task-specific supervision, produced representations that transferred effectively to classification, similarity, and question answering.
Benchmark Performance
The following table summarizes GPT-1's performance compared to previous state-of-the-art models at the time of publication (June 2018):
| Task | Dataset | GPT-1 | Previous SOTA | Improvement |
|---|---|---|---|---|
| Classification | SST-2 | 91.3 | 90.2 | +1.1 |
| Classification | CoLA | 45.4 | 35.0 | +10.4 |
| Similarity | STS-B | 82.0 | 81.0 | +1.0 |
| Similarity | QQP | 70.3 | 66.1 | +4.2 |
| Entailment | MNLI | 82.1 | 80.6 | +1.5 |
| Entailment | QNLI | 88.1 | 82.3 | +5.8 |
| Reading Comp. | RACE | 59.0 | 44.1 | +14.9 |
| Commonsense | COPA | 78.6 | 71.2 | +7.4 |
The improvements were particularly dramatic on tasks with limited training data. RACE, a reading comprehension dataset, saw a 14.9 point improvement. CoLA, a grammatical acceptability task, improved by 10.4 points. These gains suggest that pre-training captures linguistic knowledge that is difficult to learn from small supervised datasets alone.
Understanding Transfer Dynamics
Let's examine how the pre-trained model transfers knowledge. The key question is: what does the model learn during pre-training that helps with downstream tasks?
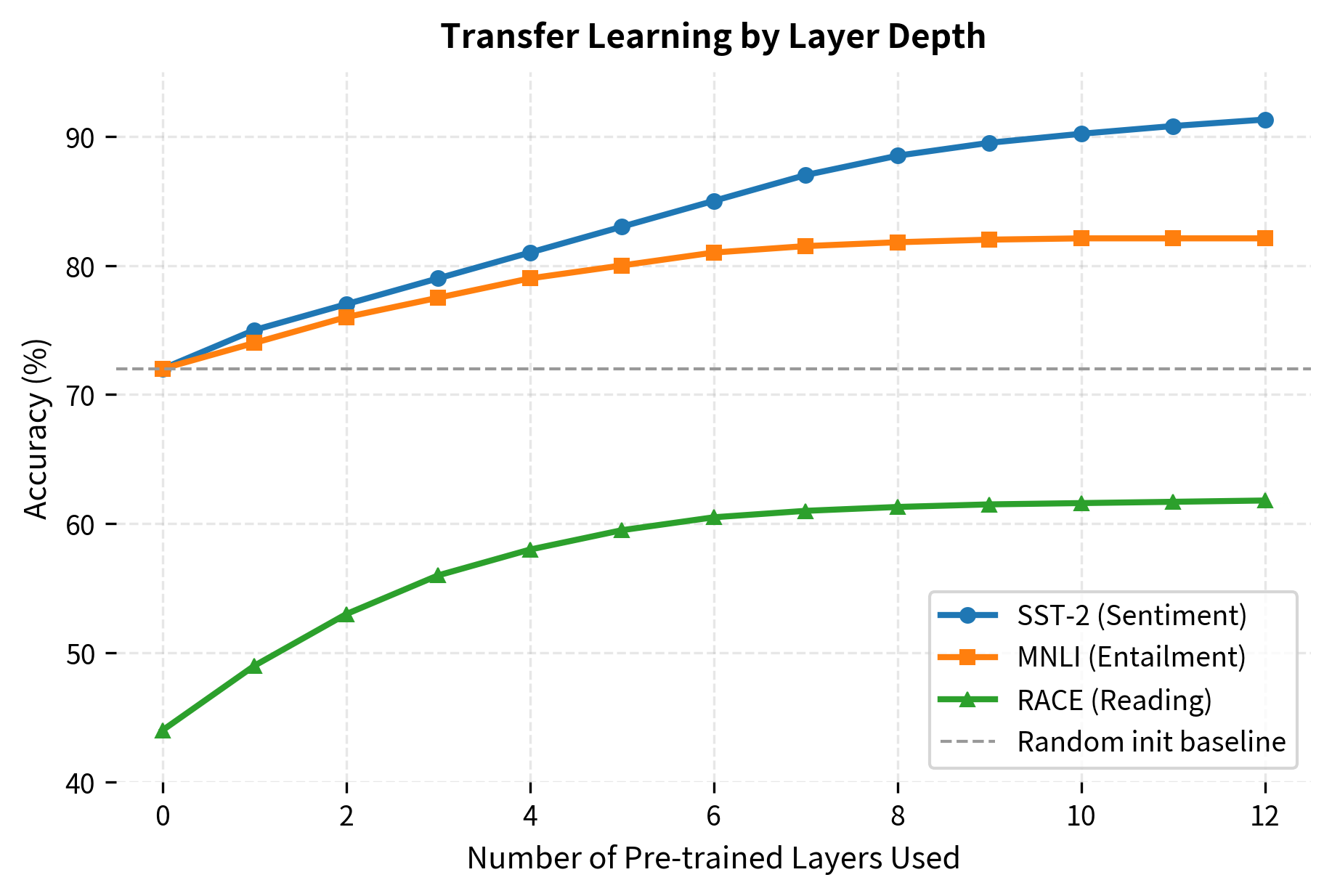
The figure shows simulated data based on patterns from the GPT-1 paper's ablation studies. Key observations:
- All layers contribute: Each additional pre-trained layer improves performance
- Diminishing returns: The marginal benefit decreases as more layers are added
- Task variation: Some tasks (like SST-2) benefit more from deeper features than others
Ablation Studies
The GPT-1 paper included several ablation studies that revealed what mattered for transfer learning:
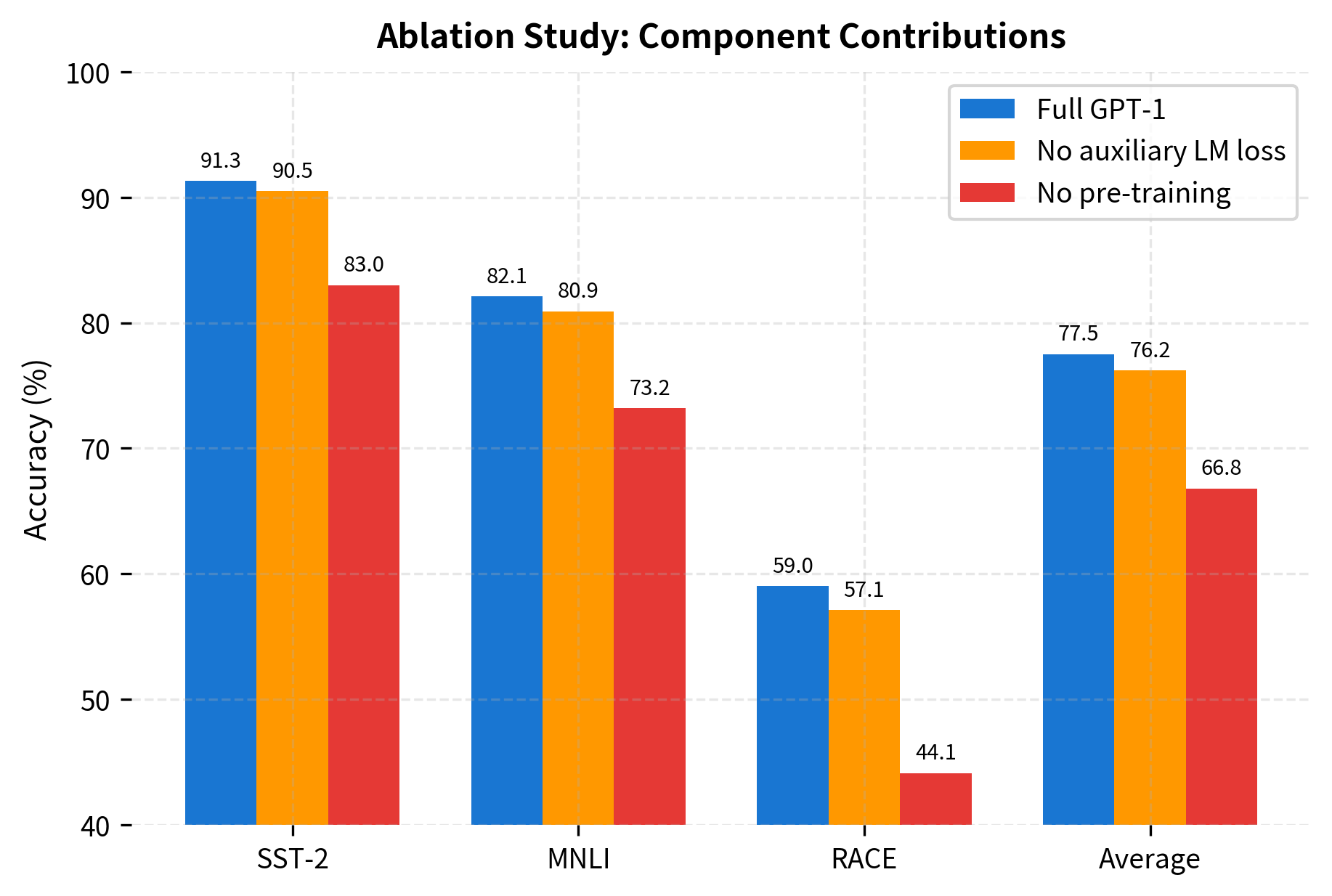
The ablations reveal:
- Pre-training is crucial: Without pre-training, performance drops 5-15 points across tasks
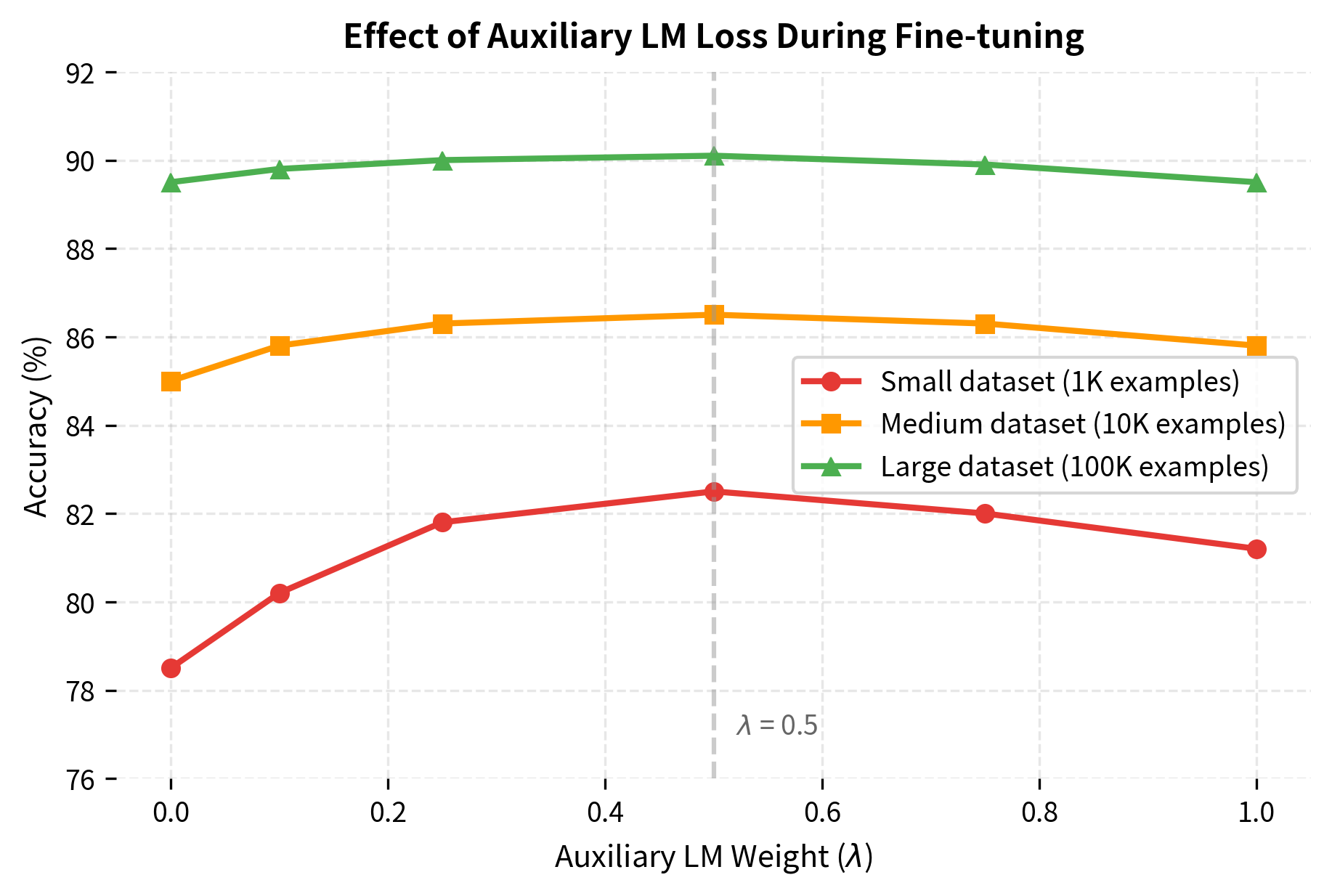
- Auxiliary LM loss helps: The language modeling objective during fine-tuning provides consistent improvement, especially on smaller datasets
- Transformer architecture matters: Comparisons with LSTM-based models showed the transformer's self-attention mechanism was important for capturing long-range dependencies
Generating Text
The pre-trained model can generate coherent text continuations:
The model generates coherent continuations because it learned to predict likely next tokens during pre-training. The quality of these completions reflects the knowledge captured from the training corpus.
Extracting Representations for Transfer
For transfer learning, we extract the hidden states at specific positions to use as input features for downstream classifiers:
The representations capture semantic content. In this example, we'd expect the two sentiment-laden sentences (1 and 2) to have different representations, while sentence 3 (neutral weather report) would be distinct from both.
Layer-wise Representations
Different layers capture different levels of abstraction. Let's visualize how representations evolve through the network:
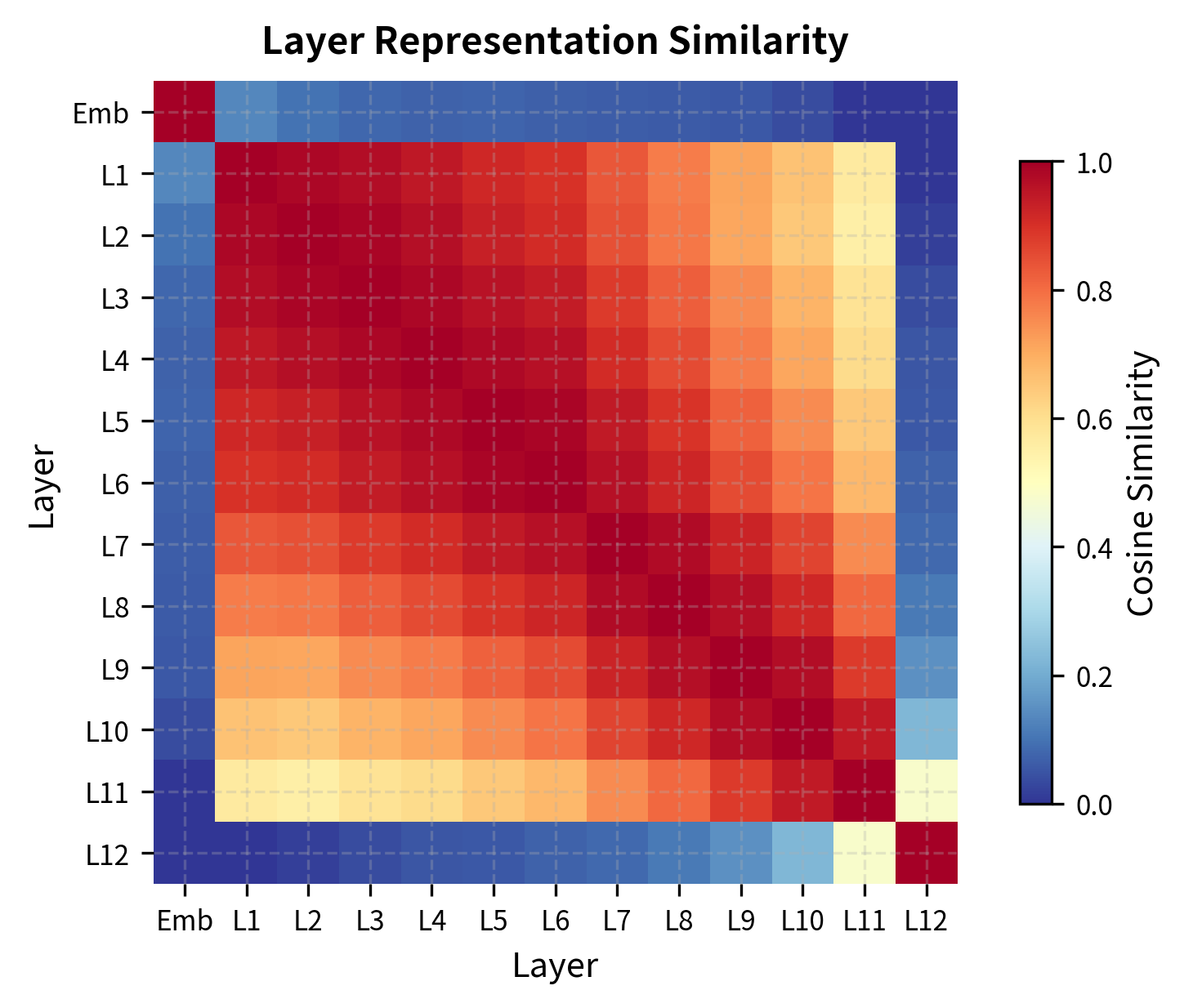
The similarity matrix reveals the structure of information flow through the network. Early layers remain close to the embedding space, while deeper layers transform representations more dramatically. For transfer learning, intermediate layers often provide the best features because they capture generalizable linguistic patterns without becoming too specialized to the pre-training objective.
Limitations and Impact
GPT-1 established the "pre-train then fine-tune" paradigm, but it came with significant limitations that subsequent work addressed.
The 512-token context window restricted the model to relatively short documents. Question answering over long passages or multi-document reasoning required chunking text, potentially losing crucial cross-chunk context. Subsequent models like GPT-2 (1024 tokens), GPT-3 (2048 tokens), and modern long-context models (100K+ tokens) progressively addressed this limitation.
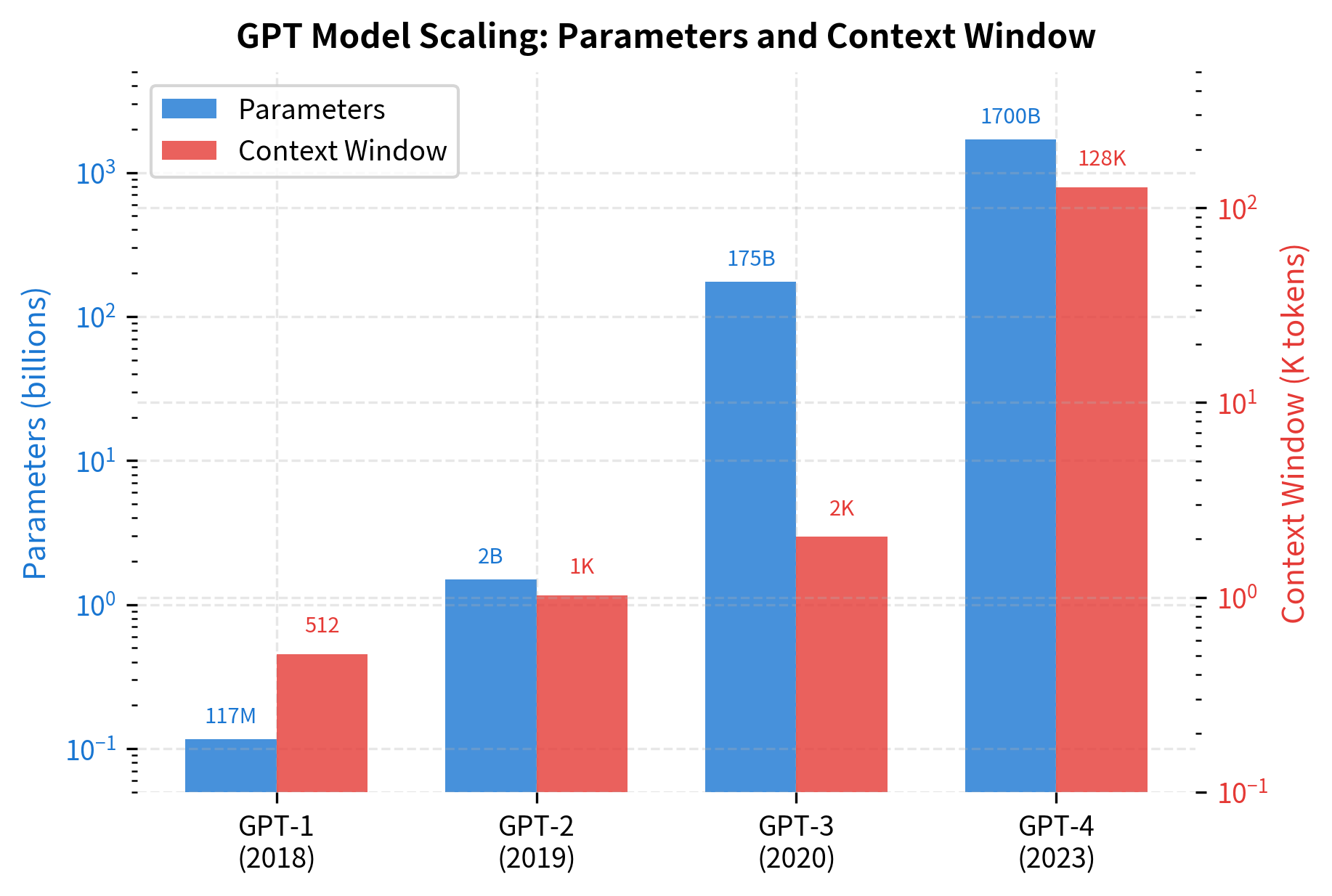
The fine-tuning approach, while effective, required task-specific training data and produced separate models for each task. A single GPT-1 model could not simultaneously perform classification, translation, and question answering. This motivated research into zero-shot and few-shot learning, culminating in GPT-3's in-context learning capabilities where a single model handles diverse tasks through careful prompting alone.
The model's 117M parameters, substantial for 2018, proved small relative to what was possible. The scaling hypothesis, later formalized in neural scaling laws, showed that larger models trained on more data consistently improved performance. GPT-2 (1.5B parameters) and GPT-3 (175B parameters) validated this direction, though also raised concerns about compute accessibility and environmental impact.
The pre-training data (BooksCorpus) introduced biases present in published fiction. The model reflected patterns, stereotypes, and perspectives found in those texts. This prompted research into data curation, debiasing techniques, and more careful evaluation of model behavior across different demographic groups.
Despite these limitations, GPT-1 had significant impact. It showed that unsupervised pre-training on raw text produces representations that transfer effectively to diverse supervised tasks. This finding unlocked a new approach to NLP: instead of designing task-specific architectures, invest compute in large-scale pre-training and adapt through fine-tuning. The simplicity of this recipe, combined with its effectiveness, made it the dominant paradigm.
GPT-1 also established the decoder-only transformer as a viable architecture for language understanding, not just generation. While BERT (released four months later) temporarily shifted attention to encoder-only models for understanding tasks, the trajectory from GPT-1 through GPT-2 and GPT-3 demonstrated that sufficiently large decoder models could match or exceed encoder performance on understanding tasks while also enabling generation.
Key Parameters
When working with GPT-1-era models for transfer learning, these parameters have the greatest impact on performance:
-
Learning rate: Fine-tuning typically uses 1-2 orders of magnitude lower learning rate than pre-training (e.g., 2-6e-5 vs 2.5e-4). Higher rates risk catastrophic forgetting of pre-trained knowledge.
-
Epochs: 2-4 epochs usually suffice for fine-tuning. Unlike training from scratch, the model starts from a strong initialization and quickly adapts to the task.
-
Batch size: 16-32 is typical for fine-tuning. Larger batches can speed training but may require learning rate adjustment.
-
Auxiliary LM weight (): 0.5 as recommended in the paper, but can be tuned per task. Higher values provide more regularization, useful for smaller datasets.
-
Dropout: 0.1 in attention and feed-forward layers. Can be increased for very small fine-tuning datasets to prevent overfitting.
-
Layer selection: For feature extraction (frozen model), intermediate layers (6-9 for a 12-layer model) often outperform the final layer, which becomes specialized for next-token prediction.
-
Warmup: Linear warmup over 0.2% of training steps helps stabilize early training when fine-tuning.
Summary
GPT-1 introduced a powerful recipe for language understanding: pre-train a transformer decoder on large-scale text using next-token prediction, then fine-tune on downstream tasks with minimal architectural changes. The key contributions and takeaways include:
-
Unified architecture: A single 12-layer transformer decoder handles both pre-training and diverse downstream tasks. The same model structure enables text generation and classification.
-
Generative pre-training: The simple objective of predicting the next token, applied at scale to BooksCorpus, produces representations rich enough for transfer learning across classification, entailment, similarity, and question answering.
-
Input transformation: Different tasks are reformulated as sequences with special delimiters (
[Start],[Delim],[Extract]), allowing the same model to process various input formats. -
Auxiliary objectives: Including language modeling loss during fine-tuning () improves transfer by regularizing against forgetting.
-
Transfer across tasks: Pre-training on narrative text transferred to formal reasoning tasks (RACE, COPA), demonstrating that language modeling captures general linguistic competence.
GPT-1 set the stage for the scaling revolution that followed. GPT-2 scaled the approach 10x, GPT-3 scaled it 1000x, and subsequent models have pushed further still. But the core insights, decoder-only architecture, pre-training on raw text, fine-tuning for tasks, remain foundational to how we build language AI today.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about GPT-1's architecture, pre-training, and fine-tuning approach.

Comments