

Learn how RoPE encodes position through vector rotation, making attention scores depend on relative position. Includes mathematical derivation and implementation.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Rotary Position Embedding (RoPE)
The transformer attention mechanism, as we've seen, is inherently position-blind. Sinusoidal encodings and learned position embeddings address this by adding position information to token embeddings before attention. But these approaches encode absolute position. Token at position 5 always receives the same positional signal, regardless of context. What if the relationship between positions 5 and 7 matters more than the absolute locations? Relative position encoding tackles this, but earlier methods required modifying the attention architecture or adding explicit bias terms.
Rotary Position Embedding, or RoPE, takes an elegant geometric approach. Instead of adding position to embeddings, it rotates them. Each position corresponds to a rotation angle, and the rotation is applied directly to query and key vectors. The ingenious part: when you compute the dot product between a rotated query at position and a rotated key at position , the result depends only on their relative distance . Absolute positions vanish, leaving only the relationship between tokens.
This chapter develops RoPE from first principles. We'll start with rotations in 2D, extend to higher dimensions through paired rotations, derive why the mechanism captures relative position, and implement it in code. By the end, you'll understand why RoPE has become the dominant position encoding in modern language models like LLaMA, PaLM, and many others.
Why Rotation?
Consider what we want from a position encoding. When a query at position attends to a key at position , the attention score should somehow reflect their relative distance . If token 3 attends to token 1, the model should "know" they're 2 positions apart, exactly as if token 8 attends to token 6.
Rotations have a beautiful property that accomplishes this. If you rotate vector by angle and vector by angle , then compute their dot product, the result depends on the angle difference . The absolute angles cancel out.
For two vectors and , rotating both by the same angle preserves their dot product: . This is because rotations preserve lengths and angles between vectors.
Now imagine we associate each position with an angle: position gets angle for some base angle . If we rotate the query vector at position by and the key vector at position by , their dot product will involve the angle . That's exactly the relative position information we want.
This is the core insight of RoPE: encode position through rotation, and let the geometry of dot products naturally extract relative position.
Rotation Matrices in 2D
Let's build up the mechanics. In two dimensions, rotating a vector by angle counterclockwise uses the rotation matrix:
where:
- : the 2D rotation matrix that rotates vectors by angle
- : the rotation angle in radians (counterclockwise is positive)
- , : trigonometric functions evaluated at angle
Applying this rotation matrix to a 2D vector transforms its coordinates:
where:
- : the original vector coordinates
- : the rotated vector coordinates
- The first row computes the new -coordinate by combining the original coordinates with and
- The second row computes the new -coordinate using and
The rotated vector has the same length as but points in a direction shifted by . This is because rotation matrices are orthogonal, meaning they preserve vector lengths (norms) and angles between vectors.
Let's visualize how rotation transforms a vector:
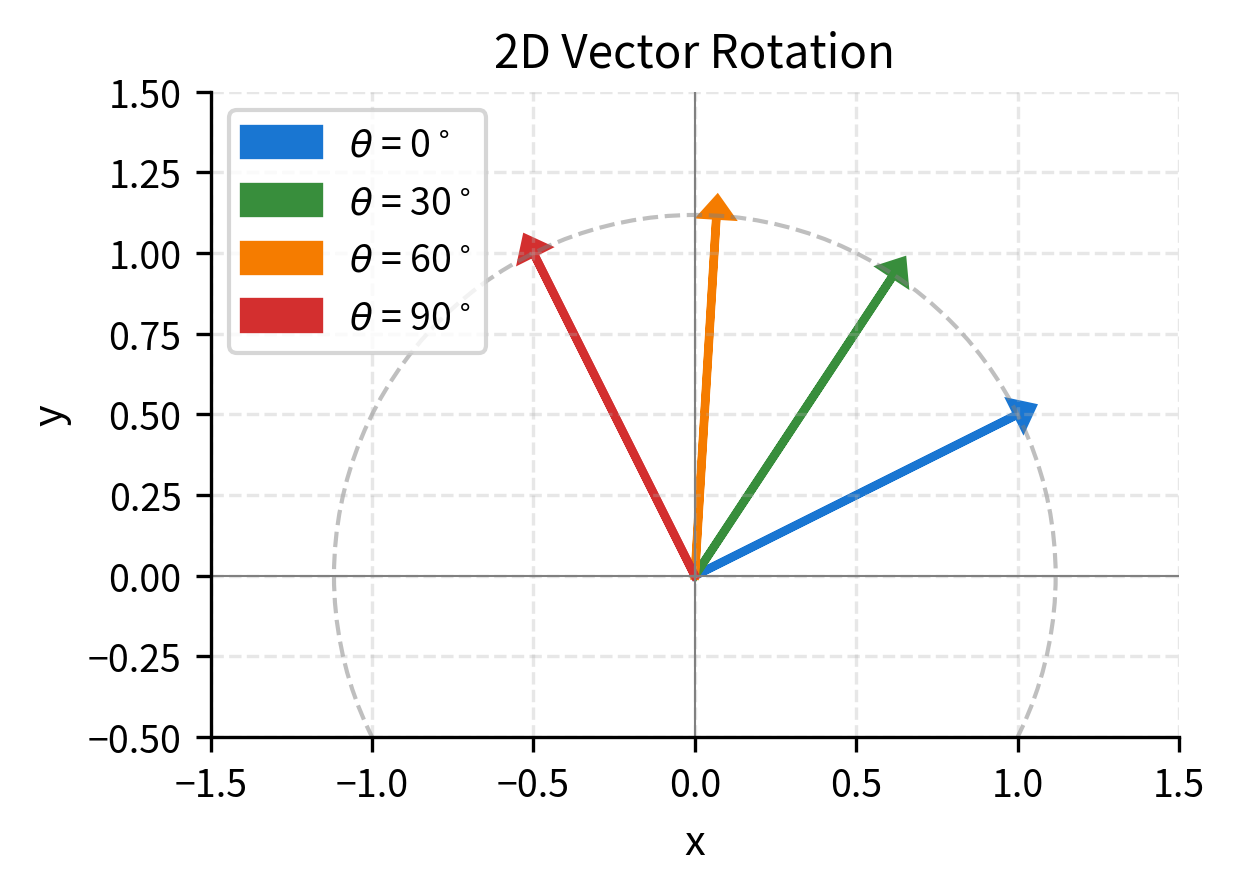
The dashed circle shows the path traced by the vector tip as it rotates. Crucially, the length (magnitude) never changes. Rotation is an isometry, a transformation that preserves distances.
From Rotation to Relative Position
Now let's see how rotation makes dot products depend on relative position. Take two 2D vectors (query) and (key). Rotate by angle (for position ) and by angle (for position ).
The dot product of the rotated vectors is:
where:
- : the query vector at position
- : the key vector at position
- : rotation matrix that rotates by angle (position times base angle)
- : rotation matrix that rotates by angle
Using properties of rotation matrices, we can simplify this expression step by step:
The derivation proceeds as follows:
- Rewrite the dot product as matrix multiplication:
- Apply the transpose-inverse property: The transpose of a rotation matrix equals its inverse, so . This gives us .
- Apply the composition property: Multiplying two rotation matrices adds their angles, so . Therefore .
The final result depends only on the difference , not on the absolute values of and separately.
When we rotate query by and key by , their dot product depends only on , the relative position. The absolute positions and vanish, replaced by their difference.
This is remarkable. We encode absolute position through rotation angle, but the attention mechanism, which uses dot products, automatically extracts relative position. No architectural changes needed. No explicit bias terms. Just geometry.
Let's verify this numerically:
All four pairs have the same relative distance (2 positions apart), and their dot products are identical despite wildly different absolute positions. This confirms the relative position property holds numerically.
Extending to Higher Dimensions
We've established that 2D rotation elegantly encodes relative position. But real transformer embeddings have hundreds or thousands of dimensions, not just 2. How do we extend this geometric insight to high-dimensional space?
The challenge is that rotations in high dimensions are more complex than in 2D. A naive approach might try to define a single rotation that affects all dimensions simultaneously, but this would be computationally expensive and wouldn't preserve the relative position property we just derived.
RoPE's solution is both clever and efficient: treat the -dimensional embedding as independent pairs. A -dimensional embedding is split into pairs: , , ..., . Each pair is rotated independently as a 2D vector, and since the pairs don't interact, the relative position property holds for each pair separately. When we sum up the contributions from all pairs in a dot product, the overall score still depends only on relative position.
But here's where RoPE becomes truly expressive: each pair rotates at a different frequency. The first pair might rotate by per position, the second by , the third by , and so on. Think of it like the hour, minute, and second hands of a clock: each moves at a different rate, and together they can represent any time uniquely. Similarly, by using multiple frequencies, RoPE creates a rich encoding where different dimension pairs capture position information at different scales.
The rotation angle for dimension pair at position is:
where:
- : the rotation angle (in radians) for dimension pair at sequence position
- : the position in the sequence (0, 1, 2, ..., for a sequence of length )
- : the dimension pair index (0, 1, 2, ..., )
- : the total embedding dimension (must be even)
- : the base frequency for dimension pair , which decreases exponentially as increases
- 10000: the base constant (same as in sinusoidal position encodings), chosen empirically for good performance
To understand why this formula creates a multi-scale representation, consider the exponent :
- When : (fastest rotation, one radian per position)
- When : (slower rotation)
- When : (slowest rotation)
This exponential decay means early dimension pairs (small ) rotate quickly, capturing fine-grained position differences, while later dimension pairs (large ) rotate slowly, capturing longer-range relationships.
The table shows the exponential decay: pair 0 completes a full cycle in about 6 positions (high frequency), while pair 3 takes over 600 positions (low frequency). This 100× difference in wavelength is what allows RoPE to encode positions at multiple scales simultaneously.
Let's visualize this frequency spectrum to see the exponential decay more clearly:
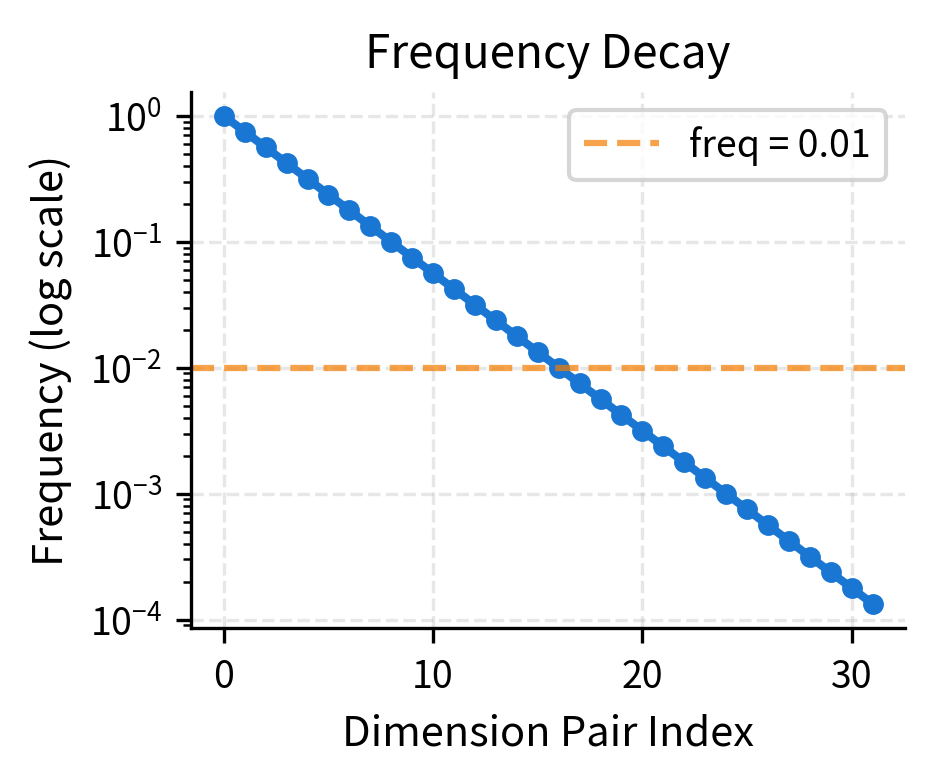
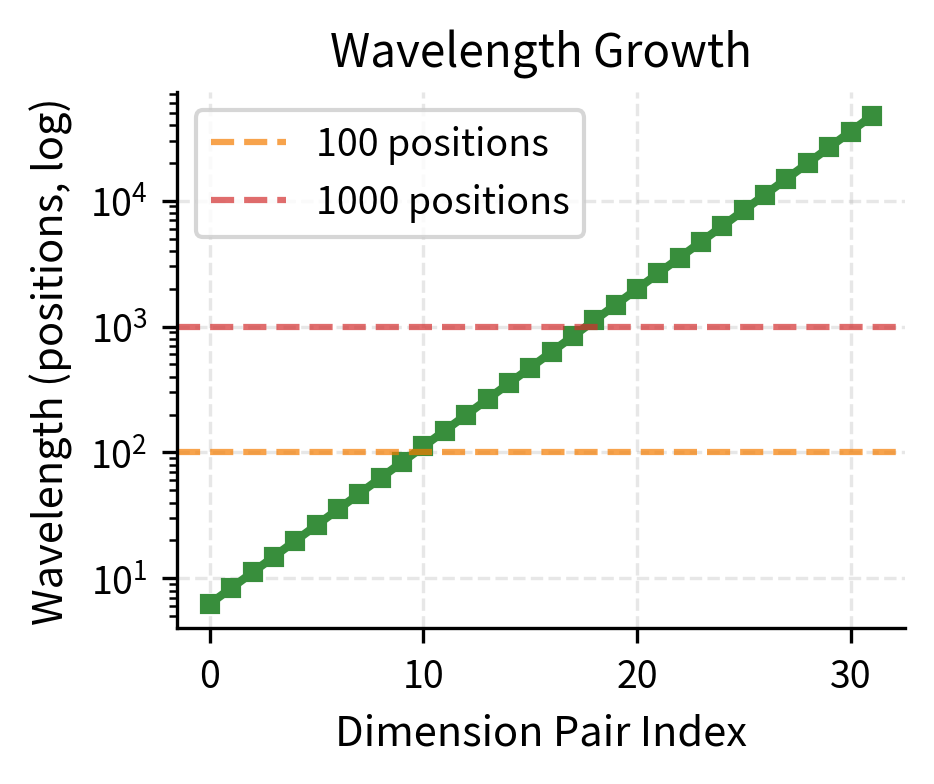
The wavelengths tell us how many positions before a dimension pair completes a full rotation (360°). Pair 0 completes a cycle in about 6 positions, while pair 3 takes over 600 positions. This exponential spread ensures RoPE can distinguish positions both locally and globally.
The Complete RoPE Formula
Now that we understand the individual components, let's bring everything together into the complete RoPE transformation. We've established three key ideas:
- Rotation encodes position: Each position corresponds to a rotation angle
- Dot products extract relative position: When query and key are rotated by different amounts, their dot product depends only on the angle difference
- Multiple frequencies create richness: Different dimension pairs rotate at different rates, capturing both local and global position information
The complete RoPE formula combines these insights into a single elegant operation. Given a query or key vector at position , we apply RoPE as follows:
where:
- : the rotated vector, a function of both the input vector and position
- : the input query or key vector with dimensions
- : the sequence position (integer index)
- : the 22 rotation matrix for angle , applied to dimension pair
- : the base frequency for dimension pair (decreases exponentially with )
- The block-diagonal structure means each 22 rotation block operates independently on its corresponding dimension pair
- Empty off-diagonal blocks are zeros, so dimensions in different pairs don't interact during rotation
The large block-diagonal matrix applies different rotations to each dimension pair simultaneously. This is efficient because each 2D rotation is independent of the others, allowing for parallel computation.
Expanding the rotation for a single dimension pair :
where:
- , : the -th and -th components of the input vector (using 1-based indexing)
- , : the corresponding components after rotation
- : the rotation angle, which increases linearly with position at a rate determined by frequency
Written out element-wise, the transformation is:
Complex Number Perspective
The matrix formulation we've developed is mathematically complete, but there's an even more elegant way to express RoPE using complex numbers. This isn't just a notational convenience: the complex perspective reveals the deep connection between rotations and exponentials, and leads to more efficient implementations.
The key insight is that a 2D rotation is equivalent to multiplication by a complex exponential. Every 2D vector can be viewed as a complex number , where is the imaginary unit. In this representation, rotating the vector by angle is simply multiplying by .
For the dimension pair , interpret them as the real and imaginary parts of a complex number:
where:
- : a complex number representing dimension pair
- : the real part (first element of the pair)
- : the imaginary part (second element of the pair)
- : the imaginary unit (satisfying )
Rotation by angle in the complex plane is achieved by multiplication:
where:
- : the rotated complex number
- : the complex exponential, a point on the unit circle at angle
- : the expanded form via Euler's formula
Euler's formula states that . Geometrically, represents a point on the unit circle at angle from the positive real axis. Multiplying any complex number by rotates it by angle counterclockwise in the complex plane, preserving its magnitude.
For RoPE at position , we apply this rotation with the position-dependent angle:
where:
- : the sequence position
- : the base frequency for dimension pair
- : the total rotation angle (increases linearly with position)
This formulation is mathematically equivalent to the rotation matrix approach. The complex perspective leads to more concise code and can be more efficient on hardware with optimized complex number operations.
Let's verify that the complex formulation gives the same result as explicit rotation matrices:
The two implementations produce identical results (up to floating-point precision). The complex formulation is often preferred in practice because it's more concise and can leverage optimized complex number operations.
Visualizing RoPE Patterns
With both the matrix and complex formulations implemented, let's build intuition by visualizing how RoPE actually transforms embeddings. Understanding these patterns helps explain why RoPE is so effective at encoding position information.
We'll plot the rotation patterns for each dimension pair, tracking how a unit vector moves as position increases:
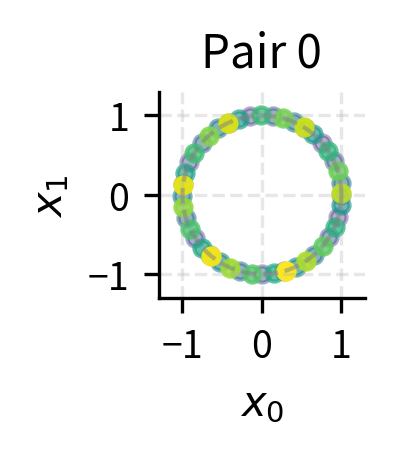
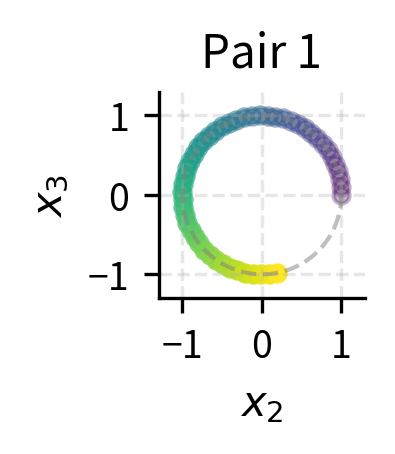
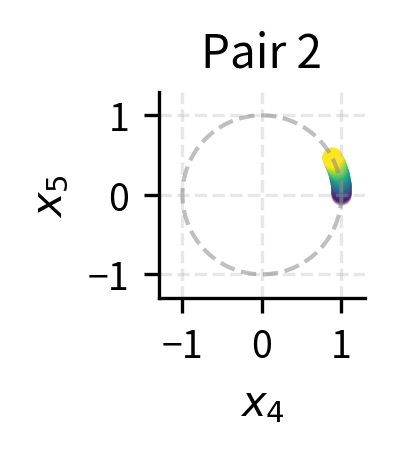
The color gradient (dark to light) shows increasing position. Pair 0 makes multiple full rotations within 50 positions, while Pair 3 barely completes an arc. This multi-frequency structure is what gives RoPE its expressiveness.
Relative Position Through Dot Products
We've derived mathematically that RoPE should make attention scores depend only on relative position. Now let's verify this core property empirically and see what it looks like in practice.
The test is straightforward: create identical query and key vectors at different positions, apply RoPE, and compute attention scores. If RoPE works as intended, the scores should form a Toeplitz matrix, where each diagonal contains identical values. This structure proves that scores depend only on relative position (the difference between query and key positions), not on absolute positions.
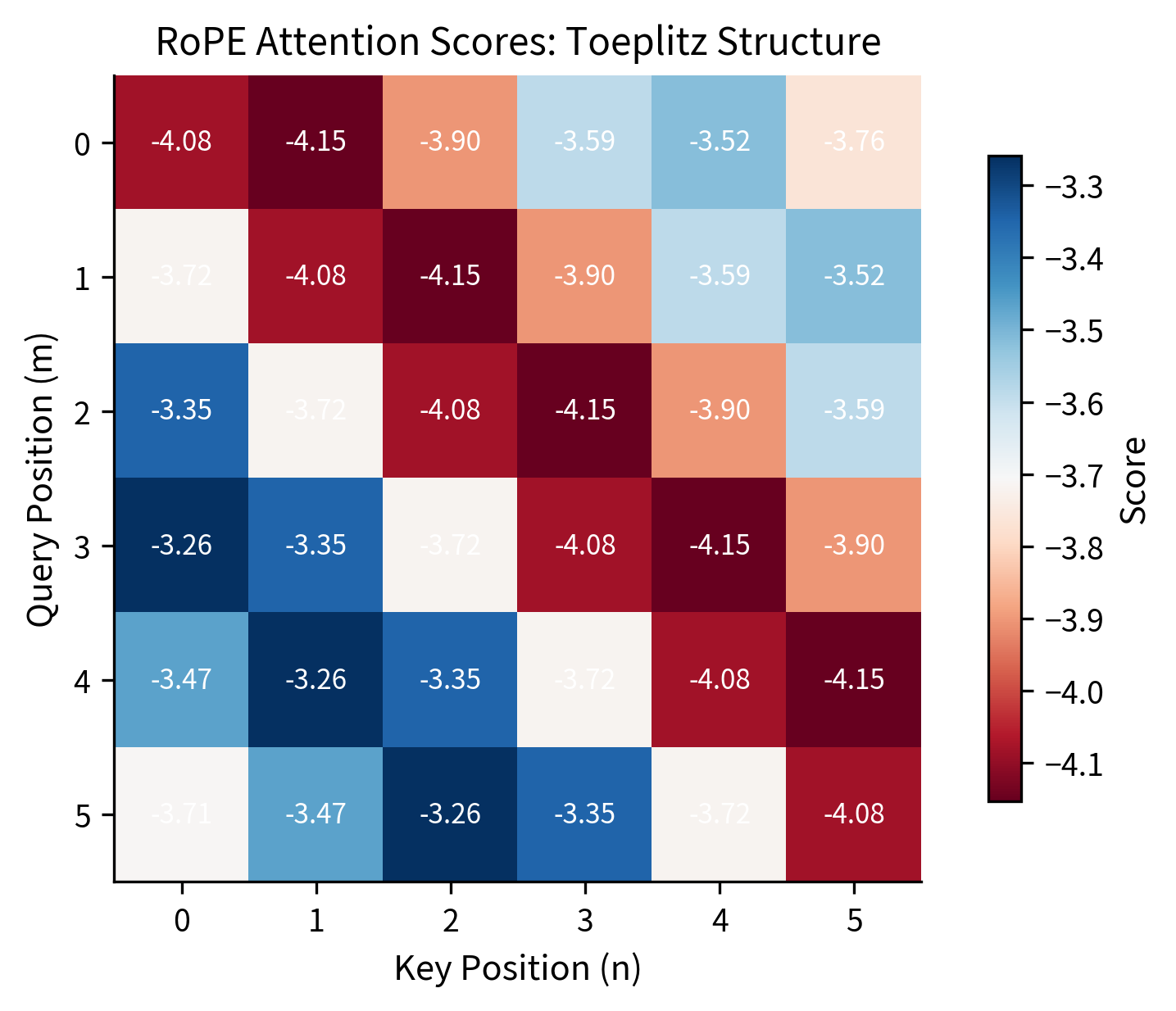
The Toeplitz structure is clear: all entries along each diagonal are identical. Position (0,0), (1,1), (2,2) all have the same score (relative distance 0). Position (0,1), (1,2), (2,3) all match (relative distance 1). This is the relative position property in action.
Let's verify numerically by extracting scores for each relative distance:
All standard deviations are effectively zero (within floating-point precision), confirming that scores at each relative distance are identical.
How Dot Products Vary with Relative Distance
The Toeplitz structure tells us scores depend only on relative position, but how do they vary? Let's trace how the dot product changes as we increase the relative distance between query and key:
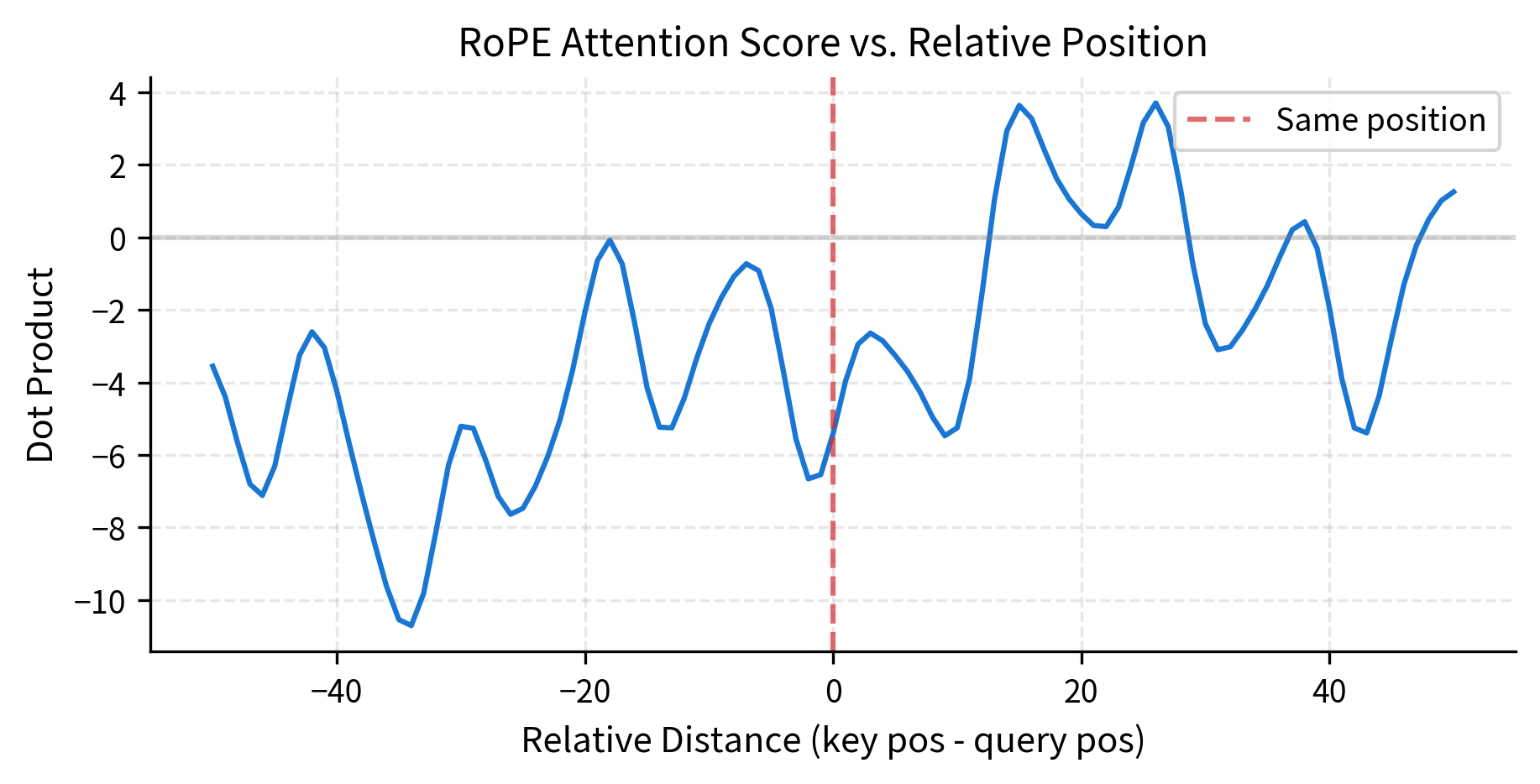
The oscillating pattern is characteristic of RoPE. The multiple frequencies create a complex interference pattern where some relative distances produce higher scores than others. This structure allows the model to learn position-dependent attention patterns during training.
Efficient Implementation
The implementations we've shown so far process one token at a time, which is clear for understanding but inefficient in practice. Modern deep learning frameworks excel at vectorized operations, so we want to apply RoPE to all tokens in a sequence simultaneously.
The key insight is that we can precompute all rotation angles as a matrix and apply them through broadcasting. Instead of looping over positions and dimension pairs, we compute everything in parallel:
Let's verify this batch implementation matches the per-token version:
The maximum difference between implementations is on the order of , which is essentially machine epsilon for 64-bit floating point. This confirms that the batch implementation produces numerically identical results while being much more efficient through vectorization.
Integration with Self-Attention
With efficient RoPE implementation in hand, let's see how it fits into a complete self-attention layer. The integration is remarkably clean: RoPE slots in between the QKV projections and the attention computation, requiring no architectural changes to the transformer.
Here's the complete flow:
- Project input embeddings to Q, K, V using learned weight matrices
- Apply RoPE to Q and K (but not to V)
- Compute scaled dot-product attention as usual
- Return the attention output
The critical detail is step 2: we rotate queries and keys but leave values untouched. Let's implement this:
Note that RoPE is applied only to queries and keys, not to values. This is because:
- Queries and keys determine attention patterns: The dot product between them computes compatibility. RoPE makes this compatibility position-aware.
- Values carry content: They should not be position-encoded because the content itself doesn't depend on position, only how much weight it receives.
The output confirms correct behavior: input of shape (8, 16) produces output of shape (8, 8) after projection to the query/key/value dimension. The attention weights form an 8×8 matrix where each row sums to exactly 1.0, confirming proper softmax normalization. The RoPE transformations are applied internally to queries and keys, making attention position-aware without changing the external interface.
RoPE Frequency Patterns
The choice of frequencies is crucial to RoPE's effectiveness. Let's visualize how the multi-frequency structure creates unique position signatures:
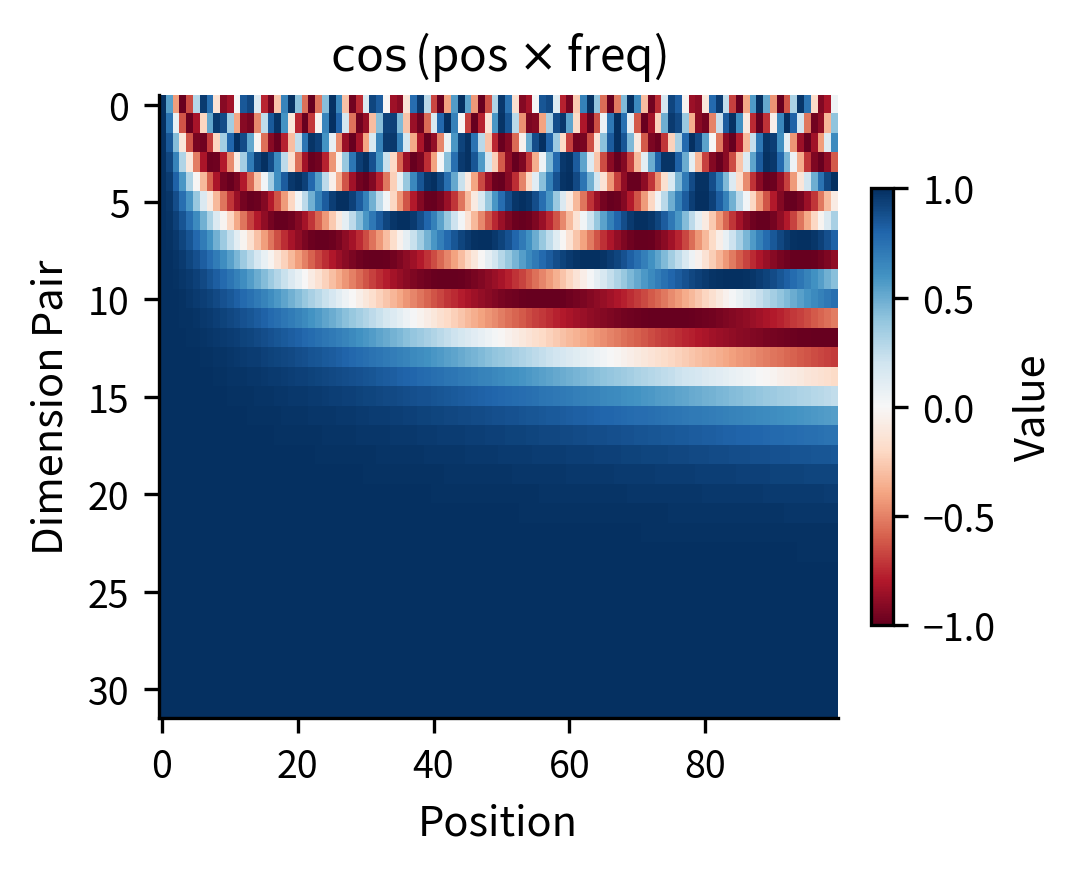
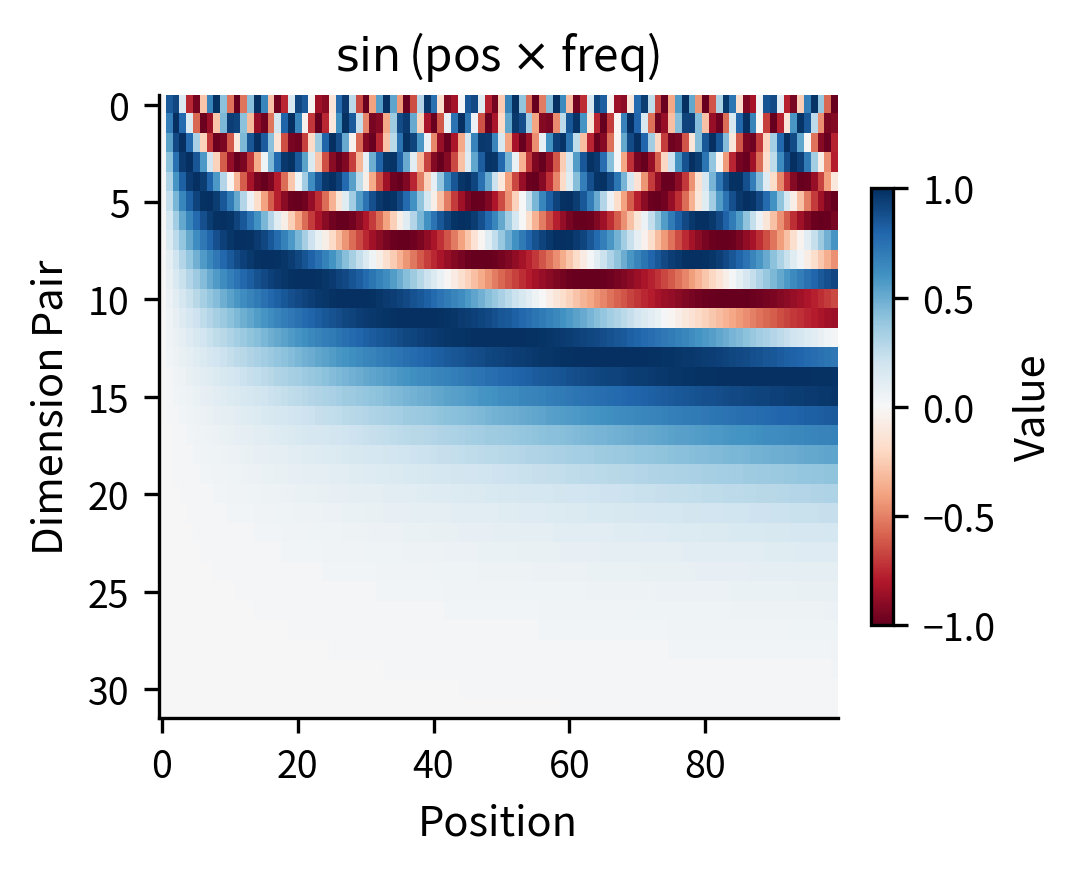
The heatmaps reveal the multi-scale nature of RoPE. Low-index dimension pairs (top rows) cycle rapidly, distinguishing nearby positions. High-index pairs (bottom rows) change slowly, providing a coarse position signal. This structure resembles sinusoidal position encodings since both use similar frequency patterns. The key difference is that sinusoidal encodings add position information to embeddings, while RoPE rotates the embeddings themselves.
Why RoPE Works So Well
Several properties make RoPE particularly effective:
Relative position by design. Unlike additive position encodings that must learn to extract relative position, RoPE provides it automatically through the geometry of rotations. The model doesn't need to learn that positions 5 and 7 are "2 apart"; the attention scores inherently reflect this.
Length generalization. Because RoPE encodes relative rather than absolute position, models can often generalize to longer sequences than seen during training. Position 1000 rotating relative to position 1002 works the same as position 0 rotating relative to position 2.
Computational efficiency. RoPE requires no additional parameters beyond the pre-computed frequencies. The rotation can be implemented as element-wise operations, making it very fast.
Compatibility with linear attention. Some efficient attention approximations rely on the inner product structure of attention. RoPE preserves this structure (rotation is a linear transformation), making it compatible with these methods.
Identical scores at identical relative distances, regardless of absolute position. This is why RoPE-based models can extrapolate to longer contexts more gracefully than models with absolute position encodings.
Let's visualize this length generalization property more comprehensively by testing many absolute position pairs:
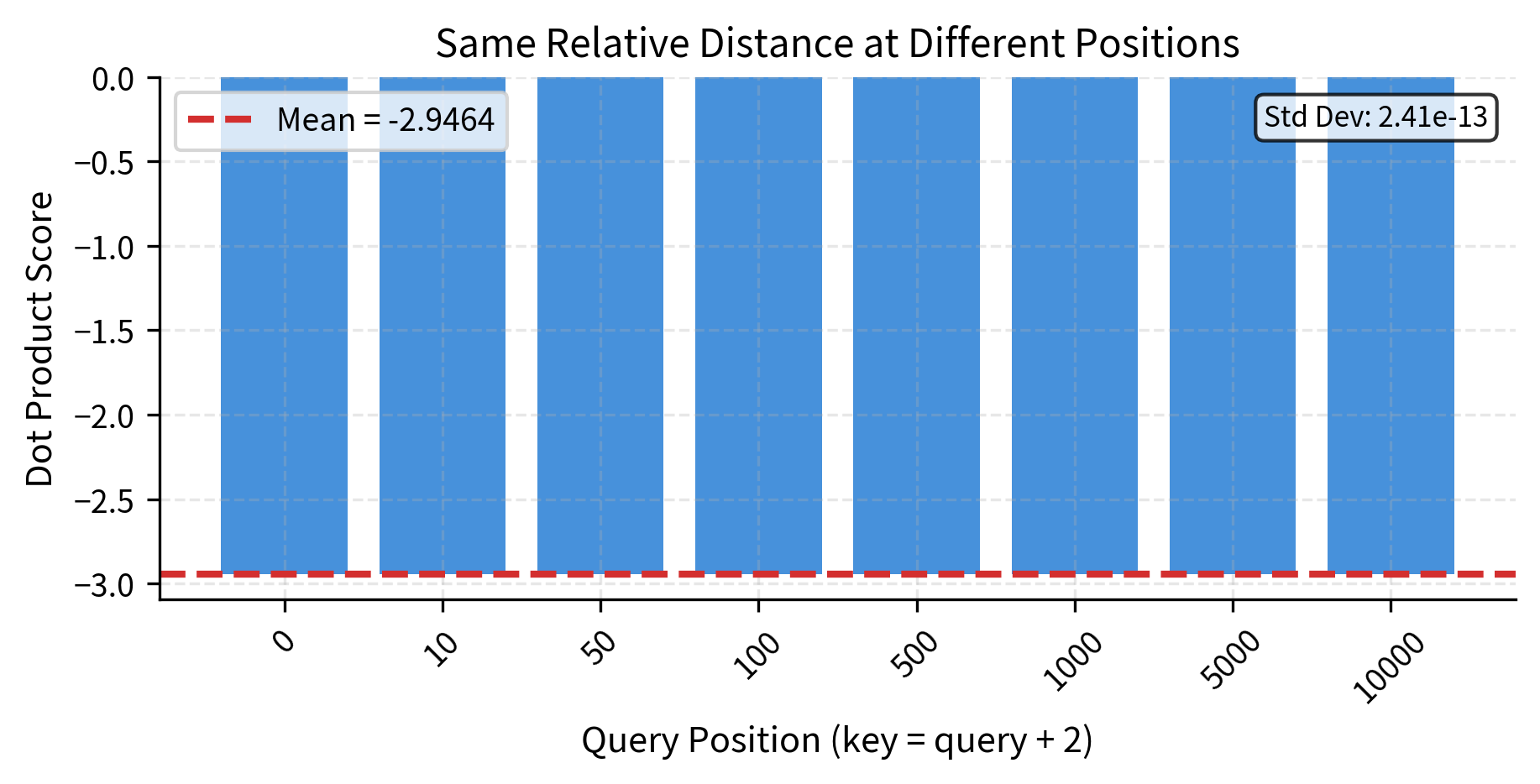
The nearly zero standard deviation confirms that RoPE perfectly preserves relative position information regardless of where in the sequence we look. This is the mathematical foundation for length generalization in RoPE-based models.
Comparing RoPE to Other Position Encodings
Let's position RoPE within the broader landscape of position encodings:
| Property | Sinusoidal | Learned | Relative (Shaw) | RoPE |
|---|---|---|---|---|
| Parameters | 0 | 0 | ||
| Position type | Absolute | Absolute | Relative | Relative |
| Attention modified | No | No | Yes | No (uses rotation) |
| Length extrapolation | Moderate | Poor | Moderate | Good |
| Computational cost | Low | Low | Higher | Low |
RoPE combines the parameter efficiency of sinusoidal encodings with the relative position benefits of learned relative encodings, without the architectural complexity. This balance explains its widespread adoption.
To make this comparison concrete, let's visualize how position similarity decays with distance for different encoding schemes:
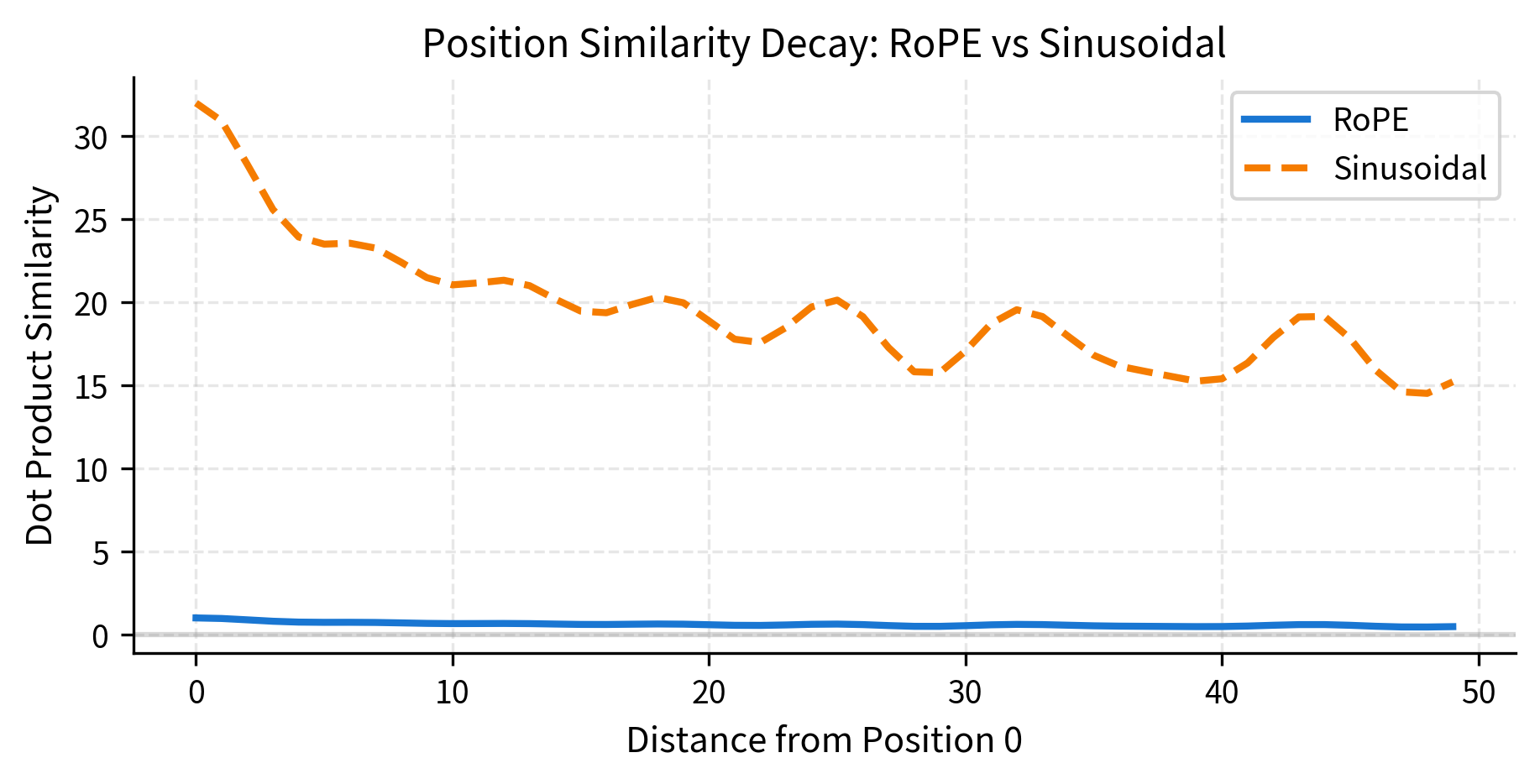
Both methods show oscillating similarity patterns due to their multi-frequency structure. The key difference: sinusoidal encodings add this pattern to the input, while RoPE modulates the attention computation directly through rotation.
Limitations and Considerations
Despite its elegance, RoPE has limitations worth understanding.
Frequency base sensitivity. The base (typically 10000) determines the frequency range. Models trained with one base may not transfer well to contexts requiring different frequency patterns. Recent work like YaRN and NTK-aware scaling addresses this by adjusting frequencies for longer contexts.
High-frequency aliasing. At very long positions, high-frequency dimension pairs may "wrap around" multiple times, potentially creating aliasing where distant positions appear similar. In practice, this is rarely problematic within reasonable context lengths, but it's a theoretical limitation.
Dimension divisibility. RoPE requires even-dimensional queries and keys since it operates on pairs. This is a minor constraint but must be considered in architecture design.
Training distribution effects. While RoPE theoretically supports any position, the model's other components (feed-forward networks, layer norms) are trained on a specific position distribution. Significant extrapolation may still degrade performance due to these other components, not RoPE itself.
These limitations are generally manageable. The community has developed extensions like Position Interpolation and NTK-aware RoPE that modify the frequency computation for better long-context performance. The core rotation mechanism remains unchanged.
Key Parameters
When implementing RoPE in your models, these parameters control its behavior:
-
d_model(embedding dimension): The total dimension of query and key vectors. Must be even since RoPE operates on dimension pairs. Common values range from 64 to 4096, typically matching the model's hidden dimension divided by the number of attention heads. -
base(frequency base): Controls the range of rotation frequencies. The default value of 10000 provides a good balance between local and global position sensitivity. Larger values (e.g., 100000) extend the effective context length by slowing all rotations; smaller values make the encoding more sensitive to nearby positions. -
theta_i(per-dimension frequency): Computed as for dimension pair . Not typically set directly, but understanding this helps diagnose behavior: the first pair rotates once per radian, while the last pair completes a full rotation over approximately positions. -
Position offset: Some implementations support a starting position offset for key-value caching during inference. This allows continuing generation from a specific position without recomputing RoPE for all previous positions.
Summary
Rotary Position Embedding encodes position through geometric rotation rather than additive signals. This approach elegantly captures relative position through the natural properties of dot products between rotated vectors.
Key takeaways:
-
Rotation as position encoding. Each position corresponds to a rotation angle. Rotating query and key vectors embeds position information directly into their geometric relationship.
-
Relative position emerges. When a rotated query at position attends to a rotated key at position , the dot product depends only on . Absolute positions cancel out through rotation mathematics.
-
Multi-frequency structure. Different dimension pairs rotate at different frequencies, creating a rich position representation. High frequencies capture local position differences; low frequencies capture global structure.
-
No additional parameters. Like sinusoidal encodings, RoPE uses deterministic frequencies based on dimension index. The only computation is the rotation itself.
-
Applied to Q and K only. Values are not rotated because they carry content, not position information. Rotation affects attention patterns, not the content that flows through them.
-
Good extrapolation. Because relative position is baked into the mechanism, models can often generalize to longer sequences than seen during training, though other model components may still limit this.
RoPE has become the dominant position encoding in modern large language models. Its combination of theoretical elegance, computational efficiency, and practical effectiveness makes it a foundational technique for transformer architectures. In the next chapter, we'll explore ALiBi, an alternative approach that adds relative position bias directly to attention scores.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about Rotary Position Embedding (RoPE).

Comments