

Learn the mathematical framework for speculative decoding, including the exact acceptance criterion, rejection sampling logic, and deriving optimal draft lengths.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Speculative Decoding Math
In the previous chapter, we introduced speculative decoding as a technique for accelerating autoregressive generation by having a small draft model propose multiple tokens that a larger target model verifies in parallel. The key insight was that verification is faster than sequential generation because it allows parallel processing. However, a critical question remains: how do we decide which draft tokens to accept?
The answer involves carefully designed acceptance criteria that guarantee mathematical correctness. We need a rejection sampling scheme that preserves the target model's output distribution exactly, not approximately. This chapter develops the mathematical framework for speculative decoding, including the acceptance criterion, expected speedup analysis, draft quality effects, and optimal draft length selection.
The Acceptance Criterion
The fundamental challenge in speculative decoding is accepting draft tokens in a way that produces the exact same distribution as sampling directly from the target model. If we simply accept tokens when the draft and target models agree, we would bias the output toward the intersection of their distributions. Instead, we need a principled rejection sampling approach.
Setting Up the Problem
To understand the acceptance criterion, we must first appreciate the subtle problem it solves. When a draft model proposes a token, we face a fundamental question: how do we decide whether to keep that token while ensuring our final output looks exactly as if we had sampled directly from the target model? This is not merely about accepting "good" tokens and rejecting "bad" ones; it is about maintaining a precise mathematical relationship between what we accept and what the target model would have produced on its own.
Let denote the target model's probability distribution over the next token, and let denote the draft model's distribution. When the draft model proposes token , we need an acceptance probability such that the final output distribution equals .
The key insight comes from rejection sampling, a classical technique in computational statistics that allows us to sample from one distribution by filtering samples from another. The fundamental idea is to sample from a "proposal" distribution (our draft model) and then selectively keep or reject those samples in a way that reshapes the distribution to match our target. If we accept with probability:
where:
- : acceptance probability for token
- : target model probability of token
- : draft model probability of token
then tokens where are always accepted, while tokens where are accepted with probability proportional to how much the target model favors them relative to the draft model.
To build intuition for this formula, consider what happens in two contrasting scenarios. In the first scenario, suppose the target model assigns probability 0.3 to token while the draft model only assigns probability 0.1. The ratio exceeds 1, so we set and always accept. This makes sense: the draft model is underproposing this token relative to what the target wants, so we should accept it whenever it appears. In the second scenario, suppose the target model assigns probability 0.1 to token while the draft model assigns probability 0.3. Now the ratio , so we accept with probability 1/3. The draft model is overproposing this token, so we need to reject some instances to bring its frequency down to what the target model expects.
Why This Works
Let's verify that this acceptance criterion produces the correct distribution. The verification proceeds through careful probability calculations that track what happens when we combine sampling from the draft model with our acceptance decision. When we sample and accept with probability , the probability of accepting a specific token is:
where:
- : probability of generating and accepting token
- : probability of drafting token
- : probability of accepting drafted token
- : probability of token under the target distribution
This derivation reveals that the probability of accepting any particular token is the minimum of the two distributions at that point. This creates a kind of "clipping" effect where we keep only the overlapping probability mass between the draft and target distributions.
The total acceptance probability across all tokens is:
where:
- : probability that a drafted token is accepted
- : sum over the entire vocabulary
- : draft model probability of token
- : target model probability of token
This sum has a geometric interpretation. If you plot both distributions as histograms over the vocabulary, equals the total area of overlap between the two histograms. When the distributions are identical, every token is accepted (total overlap equals 1). When they share no common support, no tokens are accepted (overlap equals 0).
Conditional on acceptance, the distribution over accepted tokens is:
where:
- : probability of token given it was accepted
- : normalization sum over all possible tokens
- : draft model probability
- : target model probability
This does not yet equal . The distribution is corrected by handling rejections appropriately.
The Residual Distribution
When we reject a draft token, we don't simply redraft. Instead, we sample from a carefully constructed residual distribution that "fills in" the probability mass that rejection sampling missed. This residual distribution is the mathematical key that makes speculative decoding exact rather than approximate.
To understand why we need a residual distribution, consider what happens with pure rejection sampling. When we accept with probability , we capture all the probability mass where the draft distribution meets or exceeds the target. But what about tokens where ? For these tokens, the draft model underestimates the target probability, and our rejection sampling only captures the portion up to . The residual distribution accounts for this missing mass.
Define:
where:
- : residual distribution probability for token
- : target model probability of token
- : draft model probability of token
- : difference between target and draft probabilities
- : normalizing constant,
The residual distribution captures the probability mass where , which is exactly the mass that acceptance sampling misses. Geometrically, if you imagine the target distribution as a histogram and the draft distribution as another histogram overlaid on top, the residual distribution represents the portions of the target histogram that "stick out above" the draft histogram. By sampling from on rejection, we ensure the overall distribution matches .
Notice that the normalizing constant equals , which is the total rejection probability. The probability mass captured by the residual distribution exactly equals the probability mass that rejection sampling misses, ensuring everything adds up correctly.
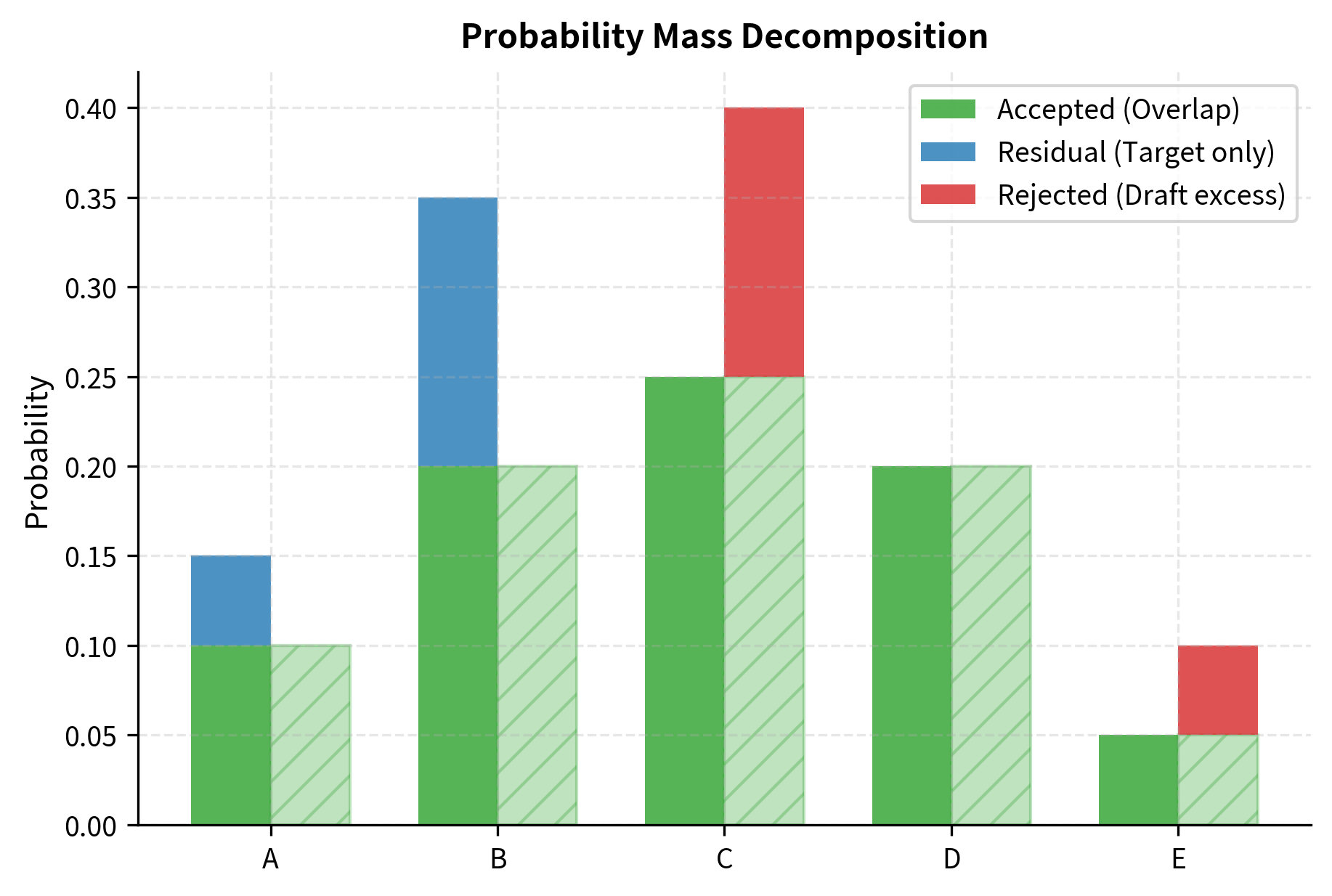
Complete Algorithm for One Token
The full acceptance procedure for a single token position works as follows. This algorithm combines the acceptance criterion with the residual distribution to guarantee exact sampling from the target model:
- Sample draft token
- Sample uniform
- If , accept
- Otherwise, sample
This procedure guarantees that the output follows distribution exactly. To see why, consider that there are two mutually exclusive ways to generate a token . The first path is through acceptance: we draft with probability and accept it with probability , contributing to the total probability. The second path is through rejection and resampling: with probability we reject and then sample from the residual with probability , contributing to the total probability. Adding these two contributions gives , exactly as desired.
The acceptance criterion with residual resampling produces outputs that are statistically indistinguishable from sampling directly from the target model. This is not an approximation; it is mathematically exact.
Extending to Multiple Tokens
In practice, the draft model proposes tokens at once. We verify them sequentially from left to right, accepting tokens until the first rejection. This sequential verification is essential because language models produce conditional distributions: the probability of each token depends on all preceding tokens.
Let be the draft sequence. For position , conditioning on the prefix :
where:
- : acceptance probability for the -th token
- : the -th token in the draft sequence
- : target model conditional probability
- : draft model conditional probability
If position rejects, we sample from the residual distribution and discard positions . This maintains correctness because each accepted token was drawn from the correct conditional distribution. The key insight is that we cannot "skip" a rejection and continue verifying later tokens, because those tokens were conditioned on the rejected token. Once we sample a different token from the residual distribution, the entire subsequent sequence becomes invalid and must be regenerated.
This left-to-right verification creates an important efficiency consideration. Even though we verify all positions in a single parallel forward pass of the target model, we can only use tokens up to the first rejection. However, because we always sample from the residual distribution upon rejection, we are guaranteed to produce at least one valid token per iteration, even if all draft tokens are rejected. In fact, when all tokens are accepted, we get tokens, since the target model's forward pass also provides the distribution for the next position beyond the draft sequence.
Expected Speedup Analysis
Understanding the expected speedup from speculative decoding requires analyzing how many tokens we expect to accept from each draft sequence and how this translates to wall-clock improvements. This analysis provides both theoretical insights and practical guidance for deploying speculative decoding systems.
Token Acceptance Probability
Let denote the average acceptance probability for a single token. Under simplifying assumptions where each position has the same acceptance rate, we can derive a clean expression for this probability. While real-world acceptance rates vary by position and context, this i.i.d. assumption provides valuable analytical insights.
where:
- : expected acceptance probability
- : expectation over tokens proposed by the draft model
- : draft model probability of token
- : target model probability of token
- : overlap between the two distributions
This quantity measures the overlap between the draft and target distributions. When the distributions are identical, . When they are completely disjoint, . In practice, typically falls between 0.6 and 0.9 for well-matched draft and target model pairs.
Expected Accepted Tokens
Given a draft of length , the number of accepted tokens follows a truncated geometric distribution. This distribution arises because we accept tokens sequentially until the first rejection, but we stop at position even if no rejection has occurred. Let be the number of tokens we generate (accepted drafts plus one from rejection sampling or the th position). The expected value is:
where:
- : expected number of accepted tokens (plus one verification)
- : draft sequence length
- : probability of accepting a single token
- : position of the first rejection
- : probability that the first rejection occurs at position
- : contribution from the case where all tokens are accepted
The first term accounts for rejecting at position (we keep tokens including the resampled one). The second term accounts for accepting all drafts (we get tokens including the bonus verification token).
We can simplify this sum by observing that is 1 plus the count of accepted draft tokens. Since the probability of accepting the first tokens is for all (under the simplified i.i.d. assumption), we can use the linearity of expectation:
where:
- : closed-form expected number of tokens generated per iteration
- : acceptance probability
- : draft length
This closed-form expression shows that expected tokens per iteration grow as a geometric series in the acceptance probability. When is close to 1, almost all draft tokens are accepted, and approaches . When is close to 0, most drafts are rejected immediately, and approaches 1 (we generate just one token from the residual distribution).
![Expected number of valid tokens generated per iteration (E[N]) as a function of acceptance probability (alpha) for different draft lengths (k). The expected yield scales as a geometric sum of the acceptance probability, approaching the maximum limit of k+1 tokens as the draft model quality nears perfection.](https://cnassets.uk/notebooks/12_speculative_decoding_math_files/theoretical-speedup-curves.png)
The Speedup Formula
Let be the cost ratio, defined as the time for one target model forward pass divided by the time for one draft model forward pass. Typically since the target model is much larger. For example, if the target model has 70 billion parameters and the draft model has 7 billion parameters, we might expect to be roughly 10, depending on hardware and batching configurations.
Without speculative decoding, generating tokens requires target model passes, taking time .
With speculative decoding, each iteration requires:
- One draft model pass generating tokens, taking time
- One target model pass verifying all positions, taking time
The iteration produces tokens on average and takes time .
The speedup ratio compares how fast we generate tokens with speculative decoding versus standard autoregressive generation. We derive this by computing the time per token under both approaches:
where:
- : speedup ratio
- : time for standard autoregressive generation per token
- : draft length
- : cost ratio ()
- : acceptance probability (used in )
- : cost of one speculative iteration in units of target model passes
- : average tokens produced per iteration
This formula captures the essential tradeoff in speculative decoding. The numerator measures benefit, specifically how many tokens we expect to generate per iteration. The denominator measures cost, specifically how much computation that iteration requires. Speedup greater than 1 means speculative decoding is faster than standard generation.
When the draft model is very fast (), this simplifies to:
where:
- : theoretical maximum speedup with a zero-cost draft model
- : acceptance probability
- : draft length
This limiting case represents the best possible speedup when the draft model adds negligible overhead. In practice, draft models incur costs, so the actual speedup is lower than this bound. However, this formula provides a useful upper limit for what speculative decoding can achieve.
Draft Quality Effects
The acceptance probability directly depends on how well the draft model approximates the target model. Understanding this relationship helps us choose appropriate draft models and predict performance. The choice of draft model is a critical practical decision in deploying speculative decoding.
Measuring Draft Quality
Draft quality can be quantified by the expected acceptance probability:
where:
- : measure of draft quality (higher is better)
- : draft distribution
- : target distribution
This quantity has a clear interpretation: it is the probability mass that the two distributions share. A high-quality draft model assigns similar probabilities to most tokens as the target model, resulting in large overlap. A poor draft model might assign high probability to tokens the target model dislikes, or vice versa, resulting in small overlap.
This is related to the total variation distance between distributions, one of the most fundamental measures of dissimilarity between probability distributions:
where:
- : total variation distance
- : target distribution probability for token
- : draft distribution probability for token
- : absolute difference in probability for token
- : acceptance probability
Higher draft quality means smaller total variation distance, which means higher acceptance probability. This connection to total variation distance indicates that the acceptance probability captures the most fundamental notion of distributional similarity: the maximum probability that an adversary could distinguish between samples from the two distributions.
Quality-Size Tradeoffs
Larger draft models tend to produce distributions closer to the target, increasing . However, larger models are slower, decreasing . The optimal draft model balances these factors, and finding this balance requires understanding the tradeoffs involved.
Consider three scenarios:
-
Very small draft model: Fast inference ( large) but poor distribution match ( small). We accept few tokens per iteration, limiting speedup. As a concrete example, imagine using a tiny 125M parameter model as the draft for a 70B parameter target. The draft model runs 100 times faster than the target, but it might only match the target's distribution 40% of the time. Most iterations produce just one or two tokens before rejection.
-
Medium draft model: Moderate speed and moderate acceptance rate. Often the sweet spot for practical applications. A 7B draft model for a 70B target might run 10 times faster while achieving 75% acceptance rates. This combination often yields the highest speedups in practice.
-
Large draft model: Good distribution match ( close to 1) but slow ( small). The overhead of running the draft model eats into speedup gains. A 30B draft for a 70B target might achieve 90% acceptance rates, but if it only runs 2-3 times faster than the target, the iteration cost is too high to achieve meaningful speedup.
Empirical Observations
In practice, acceptance rates typically range from 0.6 to 0.9 depending on:
- Model family similarity (using a smaller model from the same family yields higher )
- Task difficulty (easier, more predictable text has higher )
- Temperature settings (lower temperature often increases )
These factors interact in interesting ways. For instance, at very low temperatures where sampling becomes nearly deterministic, both draft and target models tend to select the same highest-probability token, resulting in acceptance rates approaching 1. At higher temperatures where sampling explores more of the distribution, the models are more likely to disagree, reducing acceptance rates.
Optimal Draft Length
Choosing the draft length involves balancing the cost of generating more drafts against the diminishing probability of accepting them all. This optimization problem has both theoretical and practical importance.
The Optimization Problem
We want to find that maximizes speedup:
where:
- : optimal draft length
- : expected tokens generated with draft length
- : cost ratio
Taking the derivative with respect to and setting to zero is analytically intractable, but we can understand the behavior through analysis of the numerator and denominator.
Diminishing Returns
The expected tokens grows sublinearly in :
where:
- : expected tokens for draft length
- : asymptotic limit of expected tokens
- : acceptance probability
The growth rate decreases exponentially because decays exponentially. Meanwhile, the cost grows linearly in . This tension creates an interior optimum. Intuitively, each additional draft token has a diminishing marginal benefit (it is only useful if all previous tokens were accepted, which becomes increasingly unlikely) but a constant marginal cost (one more draft model forward pass). At some point, the marginal cost exceeds the marginal benefit, and we should stop drafting.
Approximate Optimal
For large (fast draft model), we can derive an approximate optimal draft length. When , the optimal is infinite since there's no cost to drafting more tokens. For finite , the optimal satisfies:
where:
- : derivative with respect to draft length
- : acceptance probability
- : cost ratio
- The expression in brackets is the speedup function
Applying the quotient rule for differentiation:
where:
- : acceptance probability
- : draft length
- : cost ratio
- : derivative of the numerator term
- : derivative of the denominator term
- : squared denominator from the quotient rule
Setting the numerator to zero gives:
where:
- : acceptance probability
- : draft length
- : cost ratio
- : marginal gain term
- Right side: marginal cost term
This equation balances marginal benefit against marginal cost. The left side represents the expected additional tokens from extending the draft by one position. The right side represents the cost of that extension in terms of reduced speedup per existing token. While this equation cannot be solved in closed form, it can be solved numerically for any specific values of and .
For typical values (, ), optimal ranges from 4 to 8 tokens.
Adaptive Draft Length
In practice, the optimal varies based on context. Some systems use adaptive strategies:
- Fixed : Simple to implement, works well when acceptance rates are stable
- Adaptive : Adjust based on recent acceptance rates
- Tree-based drafting: Generate multiple candidate continuations, increasing effective acceptance probability
The adaptive approach monitors acceptance rates during generation and increases when rates are high (indicating the draft model is performing well on the current content) or decreases when rates are low (indicating more challenging content where longer drafts would be wasteful).
Code Implementation
Let's implement the speculative decoding mathematics to see these concepts in action.
First, we'll implement the acceptance criterion for a single token:
Let's verify that this produces the correct distribution:
The empirical distribution closely matches the target, confirming our acceptance criterion preserves the correct distribution.
Now let's calculate expected speedup for different configurations:
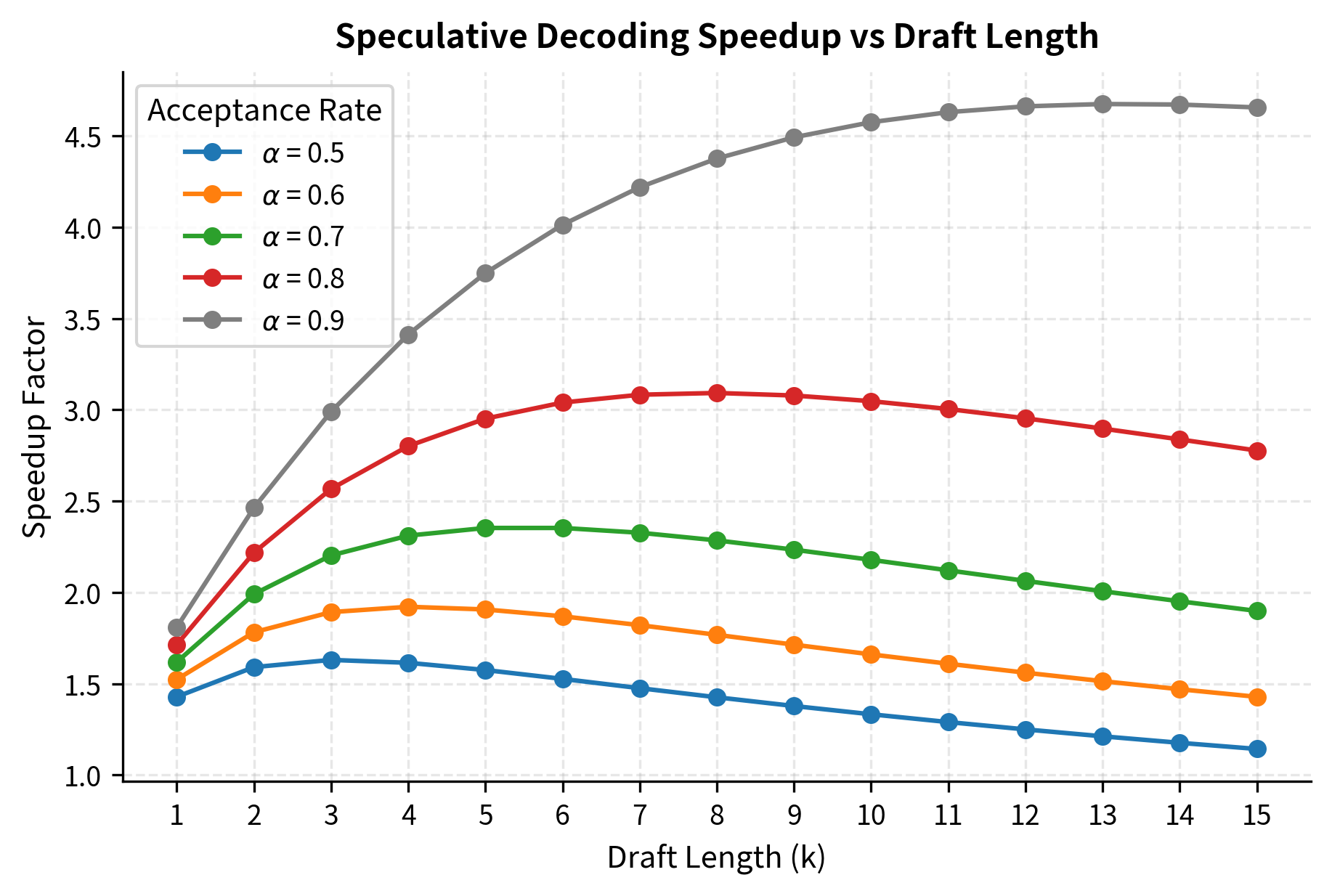
Let's visualize how speedup varies with draft length for different acceptance rates:
The plot shows that optimal draft length increases with acceptance probability. For , we can productively use 8-10 draft tokens, while shows diminishing returns after just 3-4 tokens.
Let's find the optimal for different scenarios:
The results confirm our analysis: higher acceptance rates and faster draft models (larger ) support longer draft sequences and achieve greater speedup.
Finally, let's visualize the acceptance rate as a function of distribution similarity:
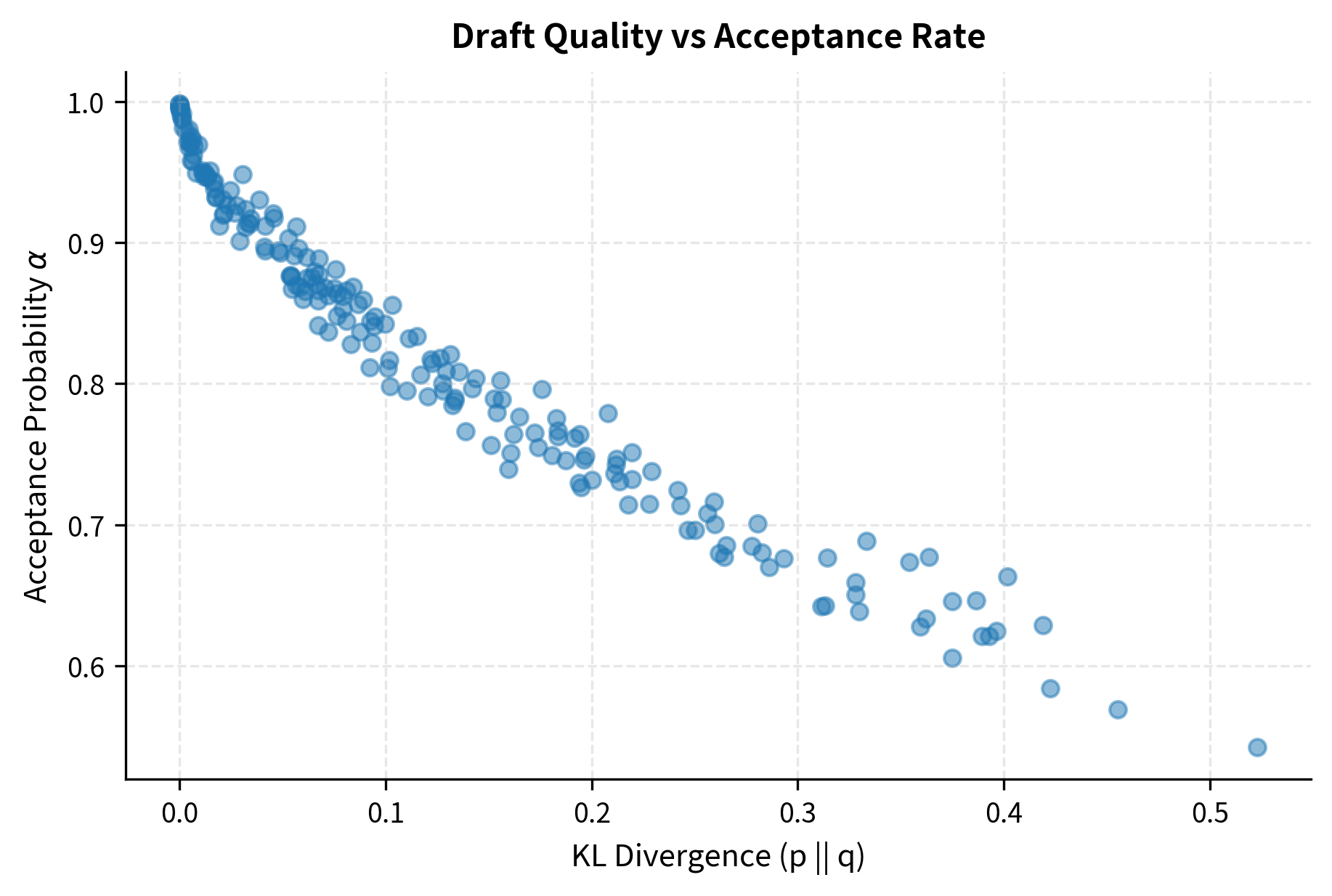
The relationship between distribution divergence and acceptance probability is clear: as the draft model's distribution diverges from the target, acceptance rates drop substantially. This underscores the importance of choosing draft models that approximate the target well.
Key Parameters
The key parameters for the speculative decoding implementation are:
- k: Draft length. The number of tokens proposed by the draft model in each step.
- c: Cost ratio (). Represents how much faster the draft model is compared to the target model.
- alpha: Acceptance probability (). The probability that a draft token is accepted by the target model, derived from distribution overlap.
Limitations and Practical Considerations
While the mathematics of speculative decoding provides strong theoretical guarantees, several practical challenges affect real-world performance.
The acceptance criterion assumes we can efficiently compute both and for all tokens. In practice, this means running the full forward pass of both models, even though we only need the probability of specific draft tokens. Some implementations optimize this by caching intermediate states, but the full softmax computation remains a bottleneck. The residual distribution sampling also requires computing the full target distribution, making it difficult to apply speculative decoding with certain memory-efficient generation techniques.
The i.i.d. assumption in our speedup analysis rarely holds in practice. Acceptance rates vary significantly based on context: function names and common phrases have high acceptance rates, while creative or technical content sees more rejections. This variance means actual speedups may differ from theoretical predictions, and systems should monitor acceptance rates to adapt draft lengths dynamically. Additionally, the tree-structured extensions to speculative decoding (generating multiple candidate continuations) can improve effective acceptance rates but add implementation complexity.
Hardware considerations also affect practical speedup. The theoretical model assumes draft and target passes don't interfere with each other's memory or compute. On GPUs with limited memory bandwidth, loading both models' weights can create contention. Some deployments use separate GPUs for draft and target models, while others time-multiplex on a single device. Continuous batching systems, which we'll explore in the next chapter, add another layer of complexity to speculative decoding integration.
Summary
This chapter developed the mathematical foundations of speculative decoding, providing tools to understand and optimize this important inference acceleration technique.
The acceptance criterion uses rejection sampling with a residual distribution to guarantee that speculative decoding produces outputs identical in distribution to standard autoregressive sampling. The acceptance probability ensures we accept tokens where the draft model underestimates the target probability while probabilistically rejecting overestimated tokens.
Expected speedup depends on the acceptance probability , draft length , and cost ratio . The formula captures the tradeoff between generating more draft tokens and the diminishing probability of accepting them all.
Optimal draft length balances these factors. Higher acceptance rates support longer drafts, with practical optima typically ranging from 4 to 10 tokens depending on model quality and hardware configuration.
Draft model quality directly impacts speedup through the acceptance probability . Smaller models within the same family often provide the best balance of speed and distribution similarity.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about speculative decoding math.

Comments