

Master Black-Litterman models, robust optimization, practical constraints, and risk parity for institutional portfolio management.
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Advanced Portfolio Construction Techniques
Mean-variance optimization, introduced by Markowitz and covered in our earlier discussion of Modern Portfolio Theory, provides an elegant theoretical framework for portfolio construction. The approach offers mathematical precision: given expected returns and a covariance matrix, we can identify portfolios that deliver the maximum return for any given level of risk. However, we quickly discovered that applying MVO directly to real-world portfolios often produces disappointing results. The optimized portfolios tend to concentrate heavily in a small number of assets, exhibit extreme long and short positions, and suffer from poor out-of-sample performance. These pathologies arise not from flaws in the theory itself, but from the sensitivity of the optimization to estimation errors in expected returns and covariances. When we treat uncertain estimates as if they were known truths, the optimizer exploits our estimation errors just as eagerly as it exploits genuine opportunities.
This chapter addresses these challenges through four complementary approaches. We begin with the Black-Litterman model, which provides a principled way to combine market equilibrium returns with your views. Rather than estimating expected returns from scratch, Black-Litterman starts from a stable reference point and adjusts it based on your beliefs. We then examine robust optimization techniques that explicitly account for parameter uncertainty by designing portfolios that perform well across a range of possible parameter values. Next, we explore how to incorporate practical constraints such as position limits, turnover restrictions, and sector exposures, transforming theoretical optimization into implementable portfolio management. Finally, we introduce risk parity, an alternative paradigm that constructs portfolios based on risk contributions rather than expected returns, offering a fundamentally different perspective on diversification.
These techniques represent the evolution from academic portfolio theory to institutional practice. Understanding them is essential for you to build portfolios that perform well not just in theory, but in the messy reality of financial markets where parameters are uncertain, constraints are numerous, and implementation costs are real.
The Problem with Mean-Variance Optimization
Before diving into solutions, we must first understand why traditional MVO fails in practice. The problem is not conceptual but statistical: we are asking the optimizer to work with inputs that we cannot measure precisely. Recall from Part IV, Chapter 1 that mean-variance optimization finds the portfolio weights that minimize portfolio variance for a given target return:
where:
- : vector of portfolio weights
- : asset covariance matrix
- : vector of expected asset returns
- : target portfolio return
- : vector of ones (sum of weights constraint)
The mathematical elegance of this formulation masks a fundamental challenge: every input to this optimization must be estimated from historical data, and even small estimation errors can produce dramatically different optimal portfolios. To understand why, consider what the optimizer is doing. It searches for the portfolio that achieves the target return with minimum variance, which means it naturally gravitates toward assets that appear to have high returns and low volatilities, while avoiding assets that seem risky or poorly performing. The problem is that "appear to have" and "seem" are doing a lot of work in that sentence. An asset that happened to perform well in our historical sample might have been lucky rather than fundamentally superior. An asset with low measured volatility might simply have experienced a calm period. The optimizer cannot distinguish genuine signal from noise, so it treats every fluctuation in our estimates as real information to be exploited.
The results reveal a troubling sensitivity: even with several years of data, the "optimal" weights fluctuate dramatically depending on which particular sample we observe. With five years of monthly data (60 observations), the standard deviation of optimal weights across simulations is substantial. Even with over 40 years of data (504 observations), the instability remains problematic. This instability arises because MVO treats the estimated parameters as if they were known with certainty, when in fact they are noisy estimates of unknown true values. The optimizer has no mechanism to express doubt or hedge against the possibility that its inputs are wrong.
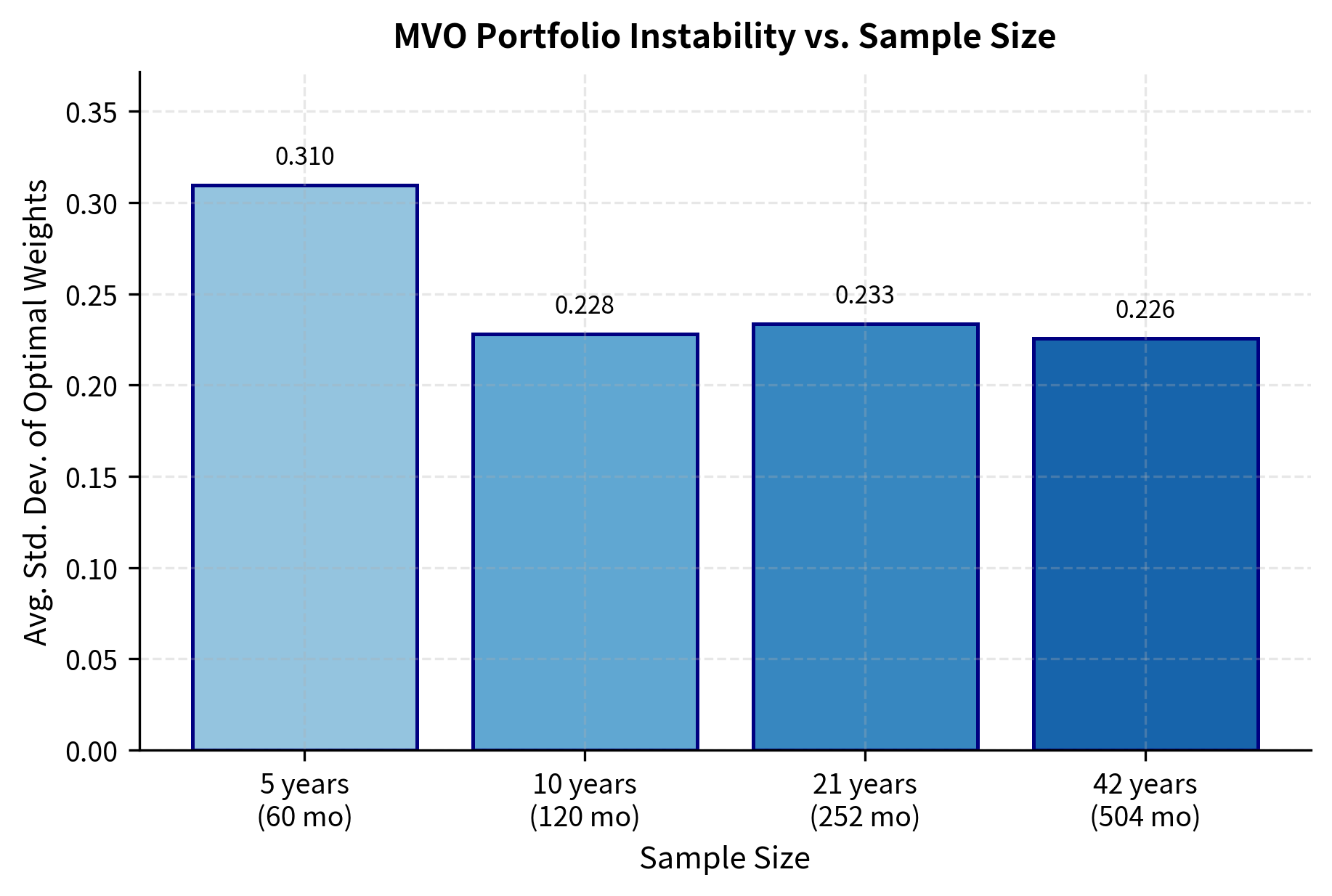
Mean-variance optimization acts as an "error maximizer" because it assigns the largest weights to assets with the highest estimated expected returns and lowest estimated variances. Unfortunately, these extremes are often due to estimation error rather than true superior risk-adjusted returns. An asset that happened to have unusually good returns in our sample will receive a large positive weight, while an asset that happened to have poor returns will be shorted heavily. The optimizer is not wrong given its inputs; the problem is that its inputs are unreliable.
The Black-Litterman Model
The Black-Litterman model, developed by Fischer Black and Robert Litterman at Goldman Sachs in 1990, addresses the estimation problem by starting from a stable reference point: the market equilibrium. The key insight is that if we have no special information about expected returns, we should assume the market is in equilibrium, meaning current prices are fair and expected returns reflect risk. Rather than estimating expected returns from historical data, which is notoriously unreliable, Black-Litterman reverse-engineers the expected returns implied by market capitalization weights, then adjusts these based on your views. This approach sidesteps the return estimation problem while providing a systematic framework for incorporating investment insights.
Reverse Optimization and Equilibrium Returns
The first insight underpinning the Black-Litterman model is that if markets are in equilibrium and investors hold the market portfolio, we can infer the expected returns that would make the market portfolio optimal. This is reverse optimization: rather than using expected returns to find optimal weights, we use the observed weights (market capitalizations) to deduce what expected returns market participants must believe. The logic is compelling: if millions of investors, collectively representing the market, have chosen to hold assets in certain proportions, then the expected returns implied by those proportions represent a kind of consensus expectation.
We start with the unconstrained mean-variance utility function with risk aversion . You seek to maximize utility, defined as expected return minus a penalty for variance. The penalty captures your discomfort with uncertainty: higher variance means more potential for adverse outcomes, and you demand compensation for bearing that risk.
where:
- : investor utility
- : vector of portfolio weights
- : vector of expected excess returns
- : risk aversion coefficient
- : covariance matrix of asset returns
The utility function captures a fundamental tradeoff. The first term, , represents the expected return of the portfolio: higher returns increase utility. The second term, , represents a penalty for portfolio variance: higher variance decreases utility. The parameter determines how severely you penalize variance. If you are highly risk-averse (large ), you will sacrifice substantial expected return to reduce variance, while if you are more risk-tolerant (small ), you will accept higher variance in pursuit of higher returns.
To find the implied equilibrium returns, we solve for the return vector that makes the market portfolio optimal. Setting the gradient of the utility function to zero gives us the first-order condition for optimality:
where:
- : vector of implied equilibrium excess returns
- : risk aversion coefficient of the market representative investor
- : covariance matrix of asset returns
- : vector of portfolio weights
- : vector of market capitalization weights
This derivation reveals a powerful insight: given the covariance matrix and market weights, we can back out the expected returns that rational investors must collectively believe. The formula tells us that implied returns depend on both the asset's own risk contribution (through the covariance matrix) and its market weight. Assets that receive large allocations in the market portfolio must offer attractive risk-adjusted returns, or investors would not hold them. Conversely, assets with small market weights must offer less attractive returns, or investors would demand more of them.
These implied returns have a crucial advantage over historical estimates: by construction, they produce the market portfolio as the optimal solution. If we were to run mean-variance optimization using these returns, we would recover exactly the market capitalization weights. This makes them a natural, stable starting point. They represent a neutral prior that says, "In the absence of any special views, we believe current market prices are fair." From this baseline, we can then incorporate our own investment insights to tilt the portfolio away from the market.
Incorporating Investor Views
The second component of Black-Litterman is a framework for expressing and incorporating your views. Views are expressed as linear combinations of asset returns, providing flexibility to capture both absolute predictions ("Asset X will return Y%") and relative predictions ("Asset X will outperform Asset Z by Y%"). This flexibility is essential because many investment insights are naturally expressed in relative terms. We might believe technology will outperform financials without having strong convictions about either sector's absolute return.
The mathematical representation of views takes the following form:
where:
- : matrix specifying views on assets
- : vector of expected asset returns
- : vector of view returns
- : error term capturing uncertainty in the views
- : covariance matrix of view errors
Each row of corresponds to one view, and the entries in that row indicate which assets are involved and with what weights. For an absolute view on a single asset, the row contains a 1 in that asset's column and zeros elsewhere. For a relative view comparing two assets, the row contains a 1 for the asset expected to outperform and a -1 for the asset expected to underperform. More complex views involving multiple assets can be expressed through appropriate combinations of positive and negative weights.
The vector specifies the expected returns associated with each view. For an absolute view, this is simply the predicted return. For a relative view, it is the expected outperformance. The error term acknowledges that views are uncertain: we might believe Asset B will outperform Asset A by 3%, but we recognize this prediction could be wrong. The covariance matrix captures how uncertain we are about each view, with larger values indicating less confidence.
The Black-Litterman Formula
Black-Litterman combines the equilibrium prior with your views using Bayesian updating, a principled statistical framework for combining prior beliefs with new information. The approach weights different sources of information according to their precision: strong views with high confidence will move the posterior returns substantially, while weak views with low confidence will have little effect. Similarly, if the equilibrium prior is considered very precise (small ), views will have less impact, but if the prior is considered uncertain (larger ), views will be more influential.
The posterior expected returns are given by:
where:
- : posterior expected return vector
- : scalar scaling factor for the uncertainty of the prior
- : covariance matrix of asset returns
- : matrix identifying the assets involved in the views
- : diagonal covariance matrix of view error terms
- : vector of implied equilibrium returns
- : vector of expected returns for the views
While this formula may appear complex at first glance, its structure becomes clear when we understand it as a precision-weighted average of two information sources. In Bayesian statistics, precision is the inverse of variance and represents how confident we are about an estimate. Higher precision means greater confidence.
The formula decomposes into these interpretable components:
- : the precision (inverse covariance) of the market equilibrium prior. Smaller means higher precision, making the prior more influential.
- : the precision of your views projected onto the asset space. Smaller means higher precision, making the views more influential.
- The first bracketed term, , is the inverse of total precision, combining information from both sources.
- The second bracketed term sums the precision-weighted returns from the prior () and the views ().
This structure essentially pulls the posterior means away from the equilibrium returns toward the views, with the degree of pull depending on the relative confidence in each source. The parameter (typically ranging from 0.01 to 0.10) controls how much weight is given to the prior relative to the views. A smaller makes the prior more precise and harder to move, while a larger makes the prior less precise and more susceptible to being influenced by views.
Notice how the posterior returns reflect our views in an intuitive way: Asset C's expected return increased toward 15%, and Asset B's return increased relative to Asset A. But the model also captures something subtler: the other assets' returns shifted slightly due to their correlations with the view assets. When we become more bullish on Asset C, we implicitly become somewhat more bullish on assets correlated with C. This propagation of views through the correlation structure is one of the elegant features of Black-Litterman.
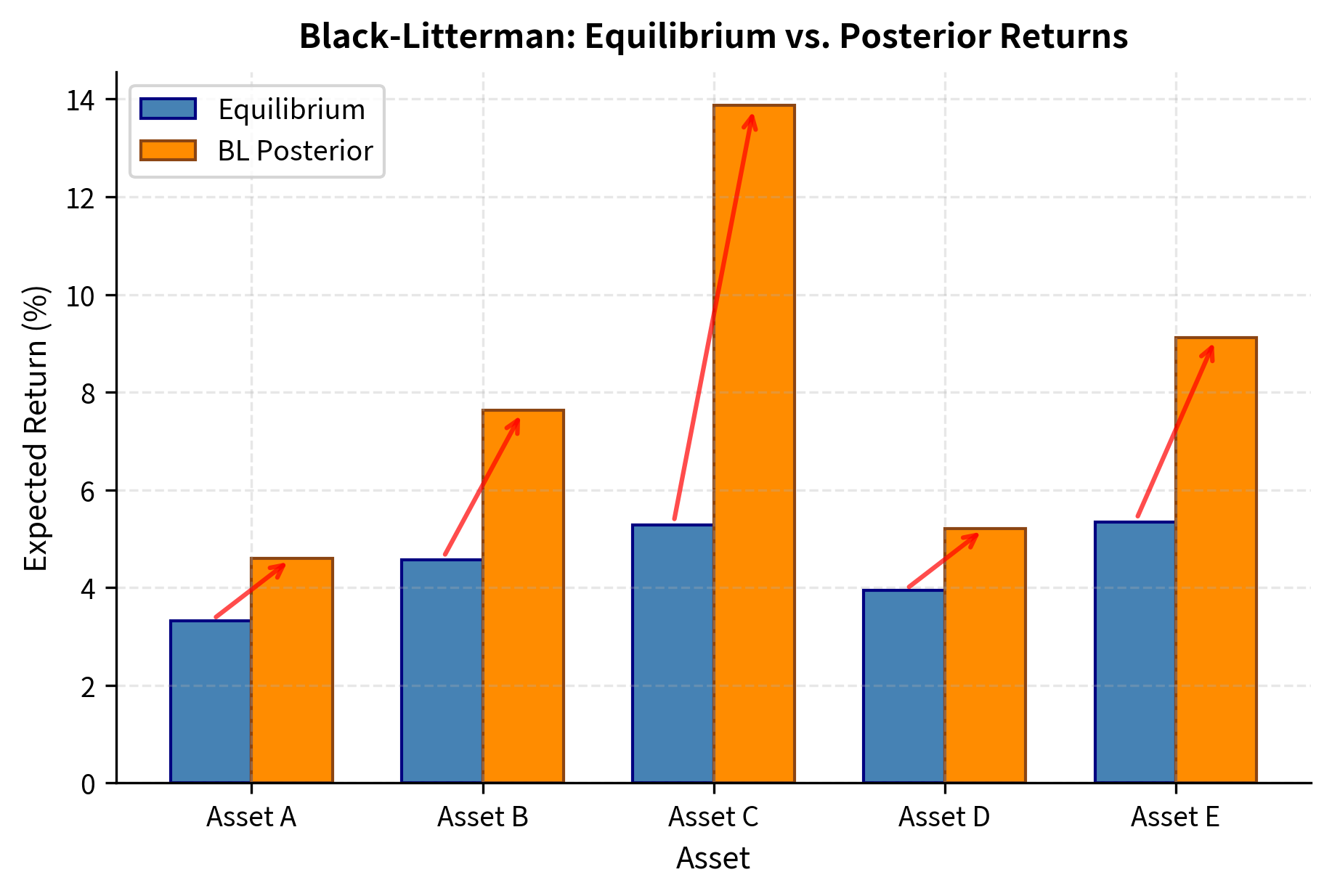
Black-Litterman Portfolio Construction
With the posterior expected returns in hand, we can now perform mean-variance optimization with stable, economically sensible inputs. The resulting portfolio will tilt toward our views while maintaining reasonable diversification, avoiding the extreme positions that plague traditional MVO.
The Black-Litterman portfolio tilts toward assets favored by our views (C and B) while maintaining reasonable diversification across all five assets. This is markedly different from what traditional MVO would produce: the equilibrium anchor prevents extreme positions, while the view-blending mechanism systematically incorporates our investment insights. Without views, the equilibrium portfolio would closely resemble the market portfolio, providing a stable default that requires positive conviction to deviate from.
Robust Portfolio Optimization
While Black-Litterman addresses the expected return estimation problem through a clever change in starting point, robust optimization takes a fundamentally different approach: explicitly acknowledging that we do not know the true parameters and designing portfolios that perform well across a range of possible values. Rather than pretending we have precise estimates, robust optimization admits uncertainty and hedges against it.
Uncertainty Sets
The core idea of robust optimization is to represent parameter uncertainty through uncertainty sets. Rather than assuming we know the exact expected return vector , we specify a set of possible values that might take. The robust portfolio then maximizes performance in the worst-case scenario within this set:
where:
- : portfolio weight vector
- : set of possible expected return vectors
- : expected return vector
- : risk aversion parameter
- : covariance matrix (assumed known here)
This formulation reflects a pessimistic but prudent worldview: nature will choose the returns within our uncertainty set that are worst for our chosen portfolio, and we should pick the portfolio that performs best even under this adversarial scenario. The objective function balances two competing goals:
- : finds the worst-case expected return within the uncertainty set for a given allocation. This term captures the downside risk from parameter uncertainty.
- : penalizes portfolio variance based on the risk aversion parameter . This term captures the traditional risk-return tradeoff.
The most common uncertainty set in practice is ellipsoidal, based on the statistical confidence region for estimated means. If we have estimated our mean returns from a sample, statistical theory tells us that the true mean lies within an ellipsoid centered at our estimate with high probability:
where:
- : uncertainty set for the expected returns
- : true (unknown) expected return vector
- : estimated mean vector from data
- : estimation error covariance matrix
- : parameter controlling the size of the uncertainty set (confidence level)
The shape of this ellipsoid reflects the correlation structure of estimation errors. If two assets' returns are highly correlated, our estimates of their means will also be correlated, and the ellipsoid will be elongated along the direction where both returns move together. The parameter controls the size of the uncertainty set, with larger values corresponding to higher confidence levels but also more conservative portfolios.
With , we recover the standard MVO weights, which are often concentrated in assets that happen to have the highest estimated returns. As increases, the optimization accounts for greater uncertainty, leading to more conservative and diversified portfolios. The robust optimizer recognizes that concentrated bets on high-return assets are risky if those high returns turn out to be estimation errors.
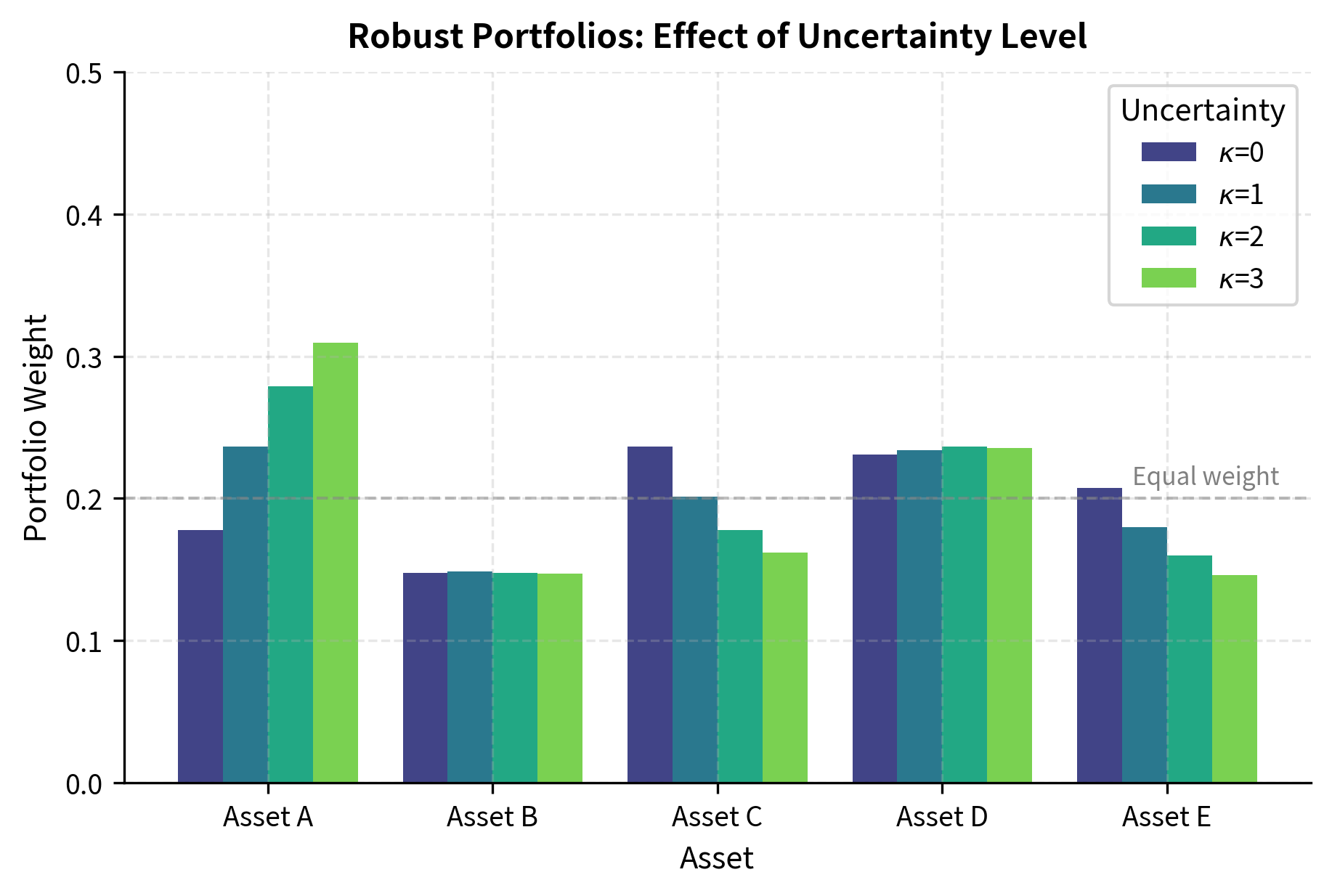
As the uncertainty level increases, the robust portfolio becomes progressively more conservative and diversified. With , we recover standard MVO, which assumes our estimates are perfectly accurate. But as uncertainty grows, the optimizer hedges against the possibility that its estimates are wrong by spreading risk across more assets. This behavior is precisely what we want: when we are uncertain, we should not make large bets.
Resampling Methods
An alternative approach to robust optimization is resampled efficiency, proposed by Richard Michaud in the 1990s. Rather than specifying an explicit uncertainty set and solving a worst-case problem, resampling uses Monte Carlo simulation to capture the range of possible optimal portfolios consistent with our estimation uncertainty. The approach is intuitive and requires no special optimization software.
The resampling procedure works as follows: First, generate many bootstrap samples from the return distribution by sampling with replacement from historical returns. Second, compute the optimal portfolio for each bootstrap sample using standard mean-variance optimization. Third, average the resulting weights across all samples to obtain the resampled efficient portfolio.
The averaging step is crucial. Each bootstrap sample produces a slightly different "optimal" portfolio, reflecting the fact that our estimates fluctuate with the data. Some samples will favor Asset A, others will favor Asset B. By averaging across samples, we obtain a portfolio that is robust to the particular quirks of any single sample. Assets that are consistently favored across samples will receive high average weights, while assets that are favored only in some samples will receive lower average weights.
The resampled portfolio is typically more diversified than the single-sample MVO portfolio. The standard deviation column reveals which assets have stable optimal weights across bootstrap samples (low standard deviation) versus which assets have volatile optimal weights (high standard deviation). This information itself is valuable: assets with high weight volatility are those where our estimate is most uncertain, and we should perhaps be cautious about large positions in them.
Shrinkage Estimators
Another powerful technique for improving portfolio stability is shrinkage estimation of the covariance matrix. The sample covariance matrix, computed directly from historical returns, is an unbiased estimator of the true covariance matrix, meaning it is correct on average. However, it is also a high-variance estimator, meaning any particular sample can produce estimates that are far from the truth. This is particularly problematic when the number of assets is large relative to the number of time periods, a common situation in portfolio management.
Shrinkage reduces variance by pulling the estimate toward a structured target. The intuition is that while we do not know the true covariance matrix, we do know some things about its general structure. For example, we might believe that correlations are positive on average, or that volatilities do not differ too dramatically across assets. By shrinking toward a target that embodies these beliefs, we trade off some bias for a reduction in variance, often improving overall estimation accuracy.
The Ledoit-Wolf estimator, one of the most popular shrinkage approaches, shrinks the sample covariance toward a scaled identity matrix:
where:
- : the shrunk covariance matrix estimator
- : shrinkage intensity constant between 0 and 1
- : sample covariance matrix
- : identity matrix
- : number of assets (dimension of the covariance matrix)
- : trace operator (sum of diagonal elements)
The shrinkage intensity is typically estimated from the data using a formula that balances bias and variance optimally. A value of gives the raw sample covariance, while gives a diagonal matrix with equal variances (the scaled identity). The optimal depends on the ratio of assets to observations and the dispersion of the true eigenvalues.
Shrinkage pulls the covariance estimate toward a structured target (the identity matrix), reducing the impact of noise in the off-diagonal elements. This results in a portfolio that is less concentrated than the one based on the raw sample covariance, as the extreme correlations in the sample data are dampened. Pairs of assets that appeared highly correlated in the sample are assumed to have somewhat lower true correlation, and pairs that appeared uncorrelated are assumed to have some positive correlation. This conservative approach often leads to better out-of-sample performance.
Practical Constraints in Portfolio Construction
Real-world portfolios face numerous constraints beyond the basic budget constraint that weights must sum to one. Incorporating these constraints transforms portfolio optimization from a theoretical exercise into a practical tool that produces implementable recommendations. A portfolio that is "optimal" in theory but violates regulatory limits or exceeds trading capacity is useless in practice.
Common Constraint Types
You typically face several categories of constraints, each arising from different practical considerations:
- Position limits: Minimum and maximum weights for individual assets. Regulatory requirements, risk limits, or liquidity concerns often mandate these bounds. For example, a mutual fund might be prohibited from holding more than 10% in any single security, or a pension fund might require minimum allocations to certain asset classes.
- Sector/industry constraints: Maximum exposure to any single sector or minimum allocation to certain sectors (e.g., ESG mandates). These constraints ensure diversification across different parts of the economy and can implement policy objectives like promoting sustainable investment.
- Turnover constraints: Limits on how much the portfolio can change from one period to the next, driven by transaction costs or tax considerations. Frequent rebalancing incurs trading costs and may trigger taxable events, so many investors limit how aggressively they adjust positions.
- Factor exposure constraints: Limits on exposure to risk factors like beta, size, or value. These constraints allow you to control your portfolio's sensitivity to systematic risk drivers, maintaining a desired risk profile regardless of individual security selection.
- Cardinality constraints: Limits on the number of assets in the portfolio (often driven by monitoring costs). Managing a portfolio of 500 securities requires more resources than managing 50, so some investors cap the number of holdings.
Implementing Constraints
Let us build a constrained portfolio optimizer that handles position limits, sector constraints, and turnover simultaneously. The key insight is that most constraints can be expressed as linear or simple nonlinear functions of the weights, allowing standard optimization algorithms to find solutions efficiently.
The constrained optimization respects all limits: no asset exceeds 35% weight, sector exposures are capped, and turnover is limited to 15%. While these constraints reduce the theoretical utility compared to an unconstrained optimum, they produce a portfolio that is actually implementable. The gap between the constrained and unconstrained solutions represents the "cost" of being practical, but this cost is usually worth paying for a portfolio that can actually be traded.
Transaction Cost Optimization
When rebalancing a portfolio, transaction costs can significantly impact returns. Every trade incurs costs from bid-ask spreads, market impact, and commissions. For large institutional portfolios, market impact alone can represent tens of basis points per trade. We can incorporate estimated costs directly into the optimization, finding portfolios that balance the benefits of rebalancing against the costs of trading.
As transaction costs increase, the optimal rebalancing becomes less aggressive. With zero transaction costs, the optimizer freely adjusts weights to chase the best risk-adjusted returns. But at higher cost levels, the optimizer avoids small adjustments where the marginal benefit in risk-adjusted return does not justify the trading expense. This leads to weights closer to the previous portfolio, a phenomenon sometimes called "no-trade regions." The width of these regions depends on the transaction cost level: higher costs mean wider regions and less frequent rebalancing.
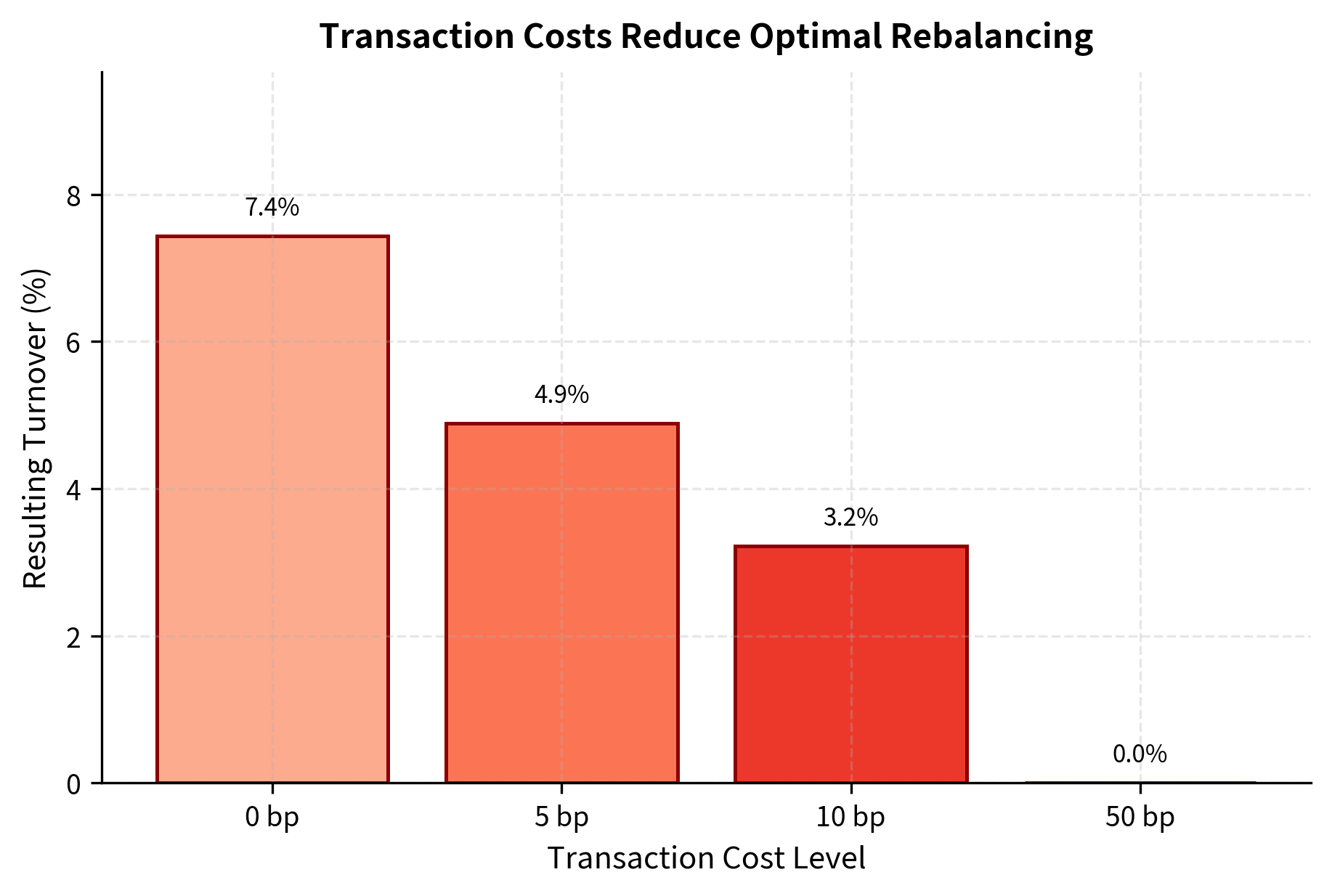
Risk Parity and Risk Budgeting
Risk parity represents a fundamentally different approach to portfolio construction. Rather than optimizing expected return per unit of risk, risk parity allocates capital so that each asset contributes equally to total portfolio risk. This approach gained prominence after the 2008 financial crisis, when traditional 60/40 stock-bond portfolios suffered large losses due to their concentration of risk in equities. Many investors holding 60% stocks and 40% bonds believed they were diversified, only to discover that over 90% of their portfolio risk came from the equity allocation.
Risk Contribution
To understand risk parity, we first need to define precisely what we mean by an asset's contribution to portfolio risk. Intuitively, we want to answer the question: if we slightly increase our position in Asset X, how much will our portfolio volatility change? This marginal contribution to risk, combined with the current position size, tells us how much each asset contributes to the total.
The total portfolio volatility can be decomposed into contributions from each asset:
where:
- : total portfolio volatility (standard deviation)
- : number of assets
- : weight of asset
- : risk contribution of asset
This decomposition follows from Euler's theorem for homogeneous functions: portfolio volatility is homogeneous of degree one in the weights, meaning if we scale all weights by a factor , volatility also scales by . Euler's theorem then guarantees that volatility can be exactly decomposed into the sum of each weight times its marginal contribution.
The marginal contribution to risk (MCR) for asset is derived from the portfolio volatility derivative using the chain rule:
where:
- : portfolio volatility
- : vector of portfolio weights
- : covariance matrix of asset returns
This formula has an intuitive interpretation. The term is a vector whose -th element represents the covariance between asset and the overall portfolio. An asset's marginal contribution to risk depends not just on its own volatility, but on how it comoves with the portfolio as a whole. An asset with high own volatility but negative correlation with other holdings might actually reduce portfolio risk at the margin.
For a single asset , the MCR is the -th element:
where:
- : marginal contribution to risk of asset
- : portfolio volatility
- : covariance matrix of asset returns
- : vector of portfolio weights
- : the -th element of the vector product
The total risk contribution (RC) for asset combines the position size with the marginal contribution:
where:
- : total risk contribution of asset
- : weight of asset
- : marginal contribution to risk of asset
- : covariance matrix of asset returns
- : vector of portfolio weights
- : the -th element of the vector product
- : portfolio volatility
By construction, the risk contributions sum to total portfolio volatility: . This additive decomposition allows us to express what fraction of portfolio risk comes from each asset, enabling meaningful comparisons across holdings.
Even with equal capital weights, the risk contributions are far from equal. Higher-volatility assets contribute disproportionately to portfolio risk. Asset C, with 25% volatility, contributes roughly 25% of portfolio risk despite having only 20% of capital. Meanwhile, Asset A, with 15% volatility, contributes only about 15% of risk. This mismatch between capital allocation and risk allocation is precisely what risk parity seeks to address.
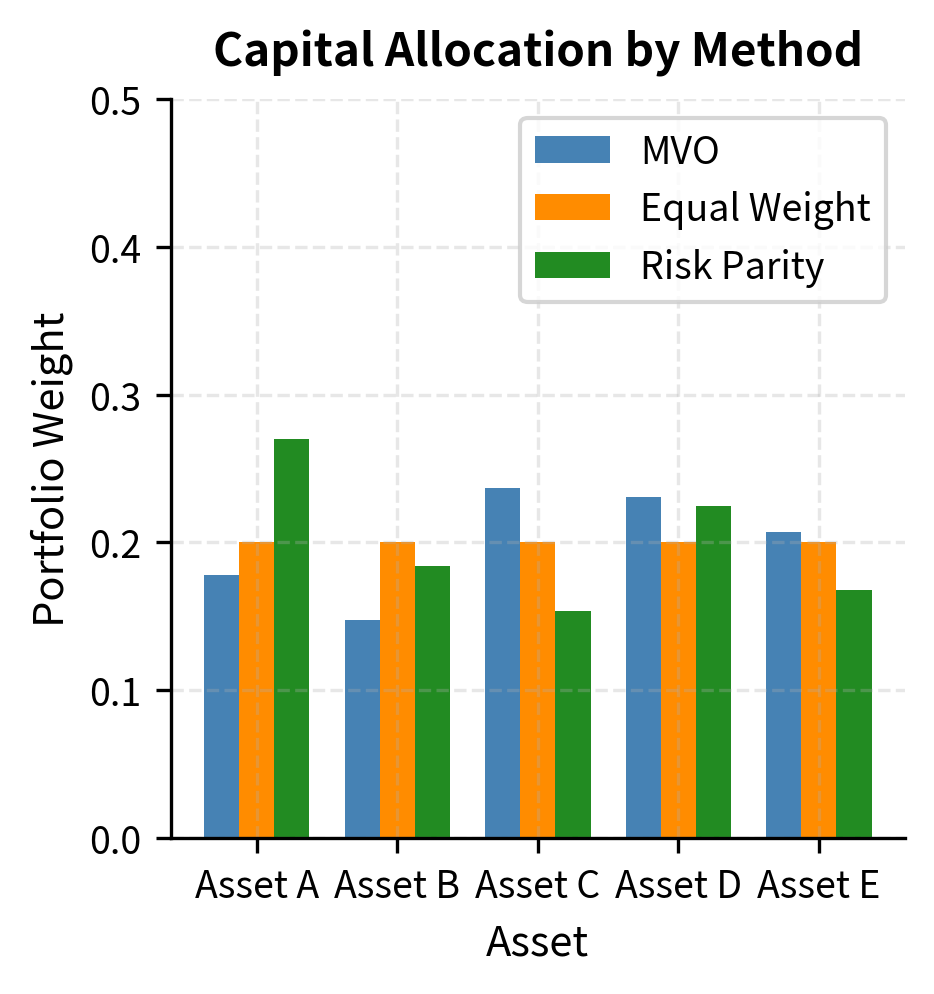
The Risk Parity Portfolio
A risk parity portfolio equalizes risk contributions across all assets. Rather than asking 'how should you allocate your capital?', risk parity asks 'how should you allocate your risk budget?' The answer is to find weights such that:
where:
- : risk contribution of asset
- : risk contribution of asset
or equivalently, expressed in terms of weights and marginal contributions:
where:
- : weights of assets and
- : the -th element of the covariance-weight product (proportional to marginal risk)
This is a nonlinear system of equations because the marginal contributions themselves depend on the weights. There is no closed-form solution in general, so we must solve numerically. The optimization finds weights that minimize the dispersion of risk contributions, subject to the constraint that weights sum to one.
Each asset now contributes approximately 20% of total portfolio risk, as intended. The risk parity weights are inversely related to asset volatility: low-volatility assets receive higher capital allocations, while high-volatility assets receive lower allocations. Asset A, with the lowest volatility at 15%, receives the highest weight, while Asset C, with the highest volatility at 25%, receives the lowest weight. This inverse relationship ensures that despite unequal capital allocations, each asset contributes equally to portfolio risk.
Risk Budgeting
Risk parity is actually a special case of a more general framework called risk budgeting, where we can specify arbitrary target risk contributions. Rather than requiring equal contributions from all assets, we might want specific allocations based on our views about asset classes or our risk tolerance. For example, we might want 50% of risk from equities and 50% from bonds, even if we hold only two equity assets and three bond assets. Or we might want to allocate more risk budget to assets we believe have higher Sharpe ratios.
The optimization successfully matches the target risk budget. Assets C and B, which we assigned higher risk budgets of 25%, receive larger risk allocations, while the capital weights adjust to account for both the target budget and the asset volatilities. Notice that even though Assets B and C have the same risk budget, their capital weights differ because they have different volatilities. The optimizer finds the unique set of weights that delivers the desired risk allocation.
Comparing Portfolio Approaches
Let us visualize how different portfolio construction methods allocate capital and risk, making the philosophical differences between approaches concrete and visible.
The comparison highlights the structural differences between approaches. MVO chases returns by concentrating in Assets B and C, which have the highest expected returns, accepting that these assets will dominate portfolio risk. Equal weighting ignores both return forecasts and risk differences, treating all assets as interchangeable. Risk parity inversely weights by volatility to equalize risk contribution, focusing entirely on diversification without regard to expected returns. Each approach embodies different beliefs about what we can reliably estimate and what matters most for long-term performance.
Integrating Multiple Techniques
In practice, you can combine multiple techniques rather than relying on any single approach. The techniques we have studied are not mutually exclusive; they address different aspects of the portfolio construction problem and can be layered together. Your workflow might proceed as follows:
- Start with Black-Litterman to generate stable expected returns that blend market equilibrium with proprietary views
- Use shrinkage for covariance estimation to reduce the impact of sampling noise
- Apply risk budgeting to set target risk allocations across asset classes or risk factors
- Incorporate practical constraints such as position limits, turnover caps, and sector restrictions
- Account for transaction costs in rebalancing decisions to avoid excessive trading
Key Parameters
The key parameters for the portfolio construction models are summarized below. Understanding how to calibrate these parameters is essential for applying the techniques effectively in practice.
- : Risk aversion coefficient. Determines the tradeoff between expected return and variance in the utility function. Typical values range from 2 to 4. Higher values produce more conservative portfolios that prioritize risk reduction over return maximization.
- : Black-Litterman scalar. Controls the weight given to the equilibrium prior relative to investor views. Typical values range from 0.01 to 0.10. Smaller values make the prior more influential, requiring stronger views to move the posterior significantly.
- : Robust optimization parameter. Defines the size of the uncertainty set (confidence level) for expected returns. Larger values produce more conservative portfolios that hedge against greater estimation error.
- P, Q: View matrices. P maps views to assets, specifying which assets are involved in each view and with what signs. Q specifies the expected returns for those views.
- : View uncertainty matrix. Represents the confidence (variance) in each expressed view. Smaller diagonal elements indicate higher confidence and greater influence on the posterior.
- : Shrinkage intensity. Determines how much the sample covariance is pulled toward the structured target. The optimal value depends on the ratio of assets to observations and is typically estimated from the data.
Limitations and Impact
The techniques covered in this chapter have transformed portfolio management from a theoretical exercise into a practical discipline, but each carries important limitations that you must understand.
The Black-Litterman model elegantly addresses the challenge of expected return estimation but introduces new challenges in its place. The results are sensitive to the choice of the scaling parameter and the specification of view confidence levels. In practice, calibrating these parameters requires judgment, and different reasonable choices can lead to meaningfully different portfolios. Two analysts with identical views but different confidence specifications might produce quite different portfolios. Additionally, the model assumes normally distributed returns, which may not capture tail risks adequately. Extreme events occur more frequently than normal distributions predict, and portfolios optimized under normality assumptions may be vulnerable to market crashes. We often combine Black-Litterman with stress testing and scenario analysis, topics we will explore further in Part V when discussing market risk measurement.
Robust optimization provides theoretical guarantees about worst-case performance, but can be overly conservative in practice. The uncertainty sets are themselves specified by you, and the results depend heavily on how these sets are calibrated. Too narrow an uncertainty set provides little protection against estimation error, while too wide a set produces portfolios that barely differ from holding cash. Finding the right balance requires understanding both the statistical properties of estimation error and the practical consequences of underperformance. Moreover, the worst-case scenario within an uncertainty set may be highly unrealistic, leading to portfolios optimized against scenarios that will never occur.
Risk parity has gained enormous popularity, with trillions of dollars invested in risk parity strategies globally. However, the approach has critics who point out that equal risk contribution does not necessarily lead to optimal risk-adjusted returns. A portfolio can have beautifully balanced risk contributions while still delivering poor performance if its assets have low Sharpe ratios. Risk parity also assumes that volatility is a complete measure of risk, ignoring tail dependencies, liquidity risk, and other important considerations. The strategy's reliance on leverage to achieve competitive returns introduces its own risks, particularly during periods of rising interest rates or market stress when borrowing costs increase.
Practical constraints improve portfolio realism but introduce computational challenges. Many real-world constraints, particularly cardinality constraints and minimum position sizes, transform the optimization into a mixed-integer program that is NP-hard to solve. This means that as the problem size grows, computational time can increase exponentially. Commercial portfolio construction systems use sophisticated heuristics and branch-and-bound algorithms to find good solutions, but optimality guarantees are often sacrificed for computational tractability.
Despite these limitations, the impact of these techniques on investment practice has been profound. Black-Litterman is now standard at most institutional asset managers for combining quantitative models with fundamental views. Robust optimization ideas have influenced how we think about estimation risk, even when they do not formally solve robust optimization problems. Risk parity has challenged the traditional 60/40 portfolio paradigm and sparked important conversations about risk budgeting and the distinction between capital allocation and risk allocation. And the integration of practical constraints has made quantitative portfolio construction a genuine decision support tool rather than a theoretical curiosity that produces unimplementable recommendations.
Summary
This chapter extended classical portfolio theory into practical tools for institutional portfolio construction. The key concepts covered include:
Black-Litterman Model: Combines market equilibrium returns with investor views using Bayesian updating. The equilibrium returns, derived by reverse-engineering the returns implied by market capitalization weights, provide a stable anchor that prevents extreme positions. The view-blending mechanism allows systematic incorporation of investment insights while maintaining diversification. The approach addresses both the instability of mean-variance optimization and the difficulty of estimating expected returns from historical data.
Robust Optimization: Explicitly acknowledges parameter uncertainty through uncertainty sets and optimizes for worst-case performance within those sets. This approach produces more diversified, stable portfolios that are less sensitive to estimation errors. By designing portfolios that perform reasonably well across a range of possible parameter values, robust optimization hedges against the risk that our estimates are wrong. Resampling methods achieve similar goals through a different mechanism, averaging optimal portfolios across many bootstrap samples to wash out the influence of any single sample's idiosyncrasies.
Practical Constraints: Real portfolios face position limits, sector constraints, turnover restrictions, and transaction costs. Incorporating these constraints transforms optimization from a theoretical exercise into a decision support tool that produces implementable recommendations. The key is formulating constraints as linear or convex functions that maintain computational tractability while capturing the essential restrictions faced by real investors.
Risk Parity: Allocates capital so each asset contributes equally to portfolio risk. This approach deemphasizes expected returns, which are notoriously difficult to estimate, and focuses on risk allocation, which is more stable and reliably measured. By ensuring that no single asset or asset class dominates portfolio risk, risk parity provides a form of diversification that traditional capital-weighted approaches often fail to deliver. Risk budgeting generalizes this to arbitrary target risk contributions, allowing investors to express views about how risk should be distributed.
These techniques are not mutually exclusive. Sophisticated practitioners combine multiple approaches: Black-Litterman for expected returns, shrinkage for covariance estimation, risk budgeting for diversification, and practical constraints for implementability. The resulting portfolios reflect both theoretical insights and practical realities, bridging the gap between academic finance and institutional investment management. The next part of this book addresses risk management, where we will see how concepts like Value-at-Risk and stress testing complement the portfolio construction techniques introduced here.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about advanced portfolio construction techniques.

Comments