

A comprehensive guide covering relationships between variables, including covariance, correlation, simple and multiple regression. Learn how to measure, model, and interpret variable associations while understanding the crucial distinction between correlation and causation.

This article is part of the free-to-read Machine Learning from Scratch
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Relationships Between Variables: Understanding How Data Moves Together
Understanding how variables relate to one another is fundamental to data science and statistical analysis. Whether we're exploring patterns in data, building predictive models, or testing hypotheses, the ability to quantify and interpret relationships between variables enables us to extract meaningful insights from complex datasets and make informed decisions based on empirical evidence.
Introduction
In real-world data, variables rarely exist in isolation. Customer age might relate to purchasing behavior, temperature might affect sales patterns, and education level might correlate with income. Recognizing and quantifying these relationships forms the backbone of exploratory data analysis, predictive modeling, and causal inference.
This chapter explores the fundamental tools for measuring and interpreting relationships between variables. We begin with covariance and correlation, which quantify the strength and direction of linear associations. We then examine regression analysis (superficially as we have a whole chapter dedicated to it), which models these relationships explicitly to enable prediction and inference. Finally, we address one of the most important distinctions in data science: the difference between correlation and causation. Understanding when an observed association reflects a genuine causal mechanism versus a spurious correlation helps avoid misinterpretation and supports sound conclusions.
By the end of this chapter, you'll understand how to measure variable relationships, model them mathematically, interpret them correctly, and recognize the boundaries of what these methods can tell us about the underlying data-generating process.
Covariance: Measuring Joint Variability
Covariance quantifies how two variables change together. When one variable tends to be above its mean at the same time the other is above its mean, they have positive covariance. When one tends to be above its mean while the other is below its mean, they have negative covariance. A covariance near zero suggests little linear relationship between the variables.
The population covariance between two variables and is defined as:
Where:
- : Expected value operator
- : Population mean of
- : Population mean of
In practice, we work with sample data and estimate covariance using the sample covariance:
Where:
- : Sample size
- : Individual observations
- : Sample means
The interpretation of covariance is straightforward in terms of direction: positive values indicate variables tend to move together in the same direction, while negative values indicate they move in opposite directions. However, the magnitude of covariance is difficult to interpret because it depends on the units and scales of the variables. A covariance of 100 might indicate a strong relationship for variables measured in small units, but a weak relationship for variables measured in large units. This limitation motivates the need for a standardized measure of association.
To better understand how covariance captures joint variability, consider the geometric interpretation. Each data point contributes to the covariance based on whether both variables are above their means (positive contribution), both below their means (positive contribution), or one above and one below (negative contribution). The following visualization shows this structure and how different quadrants contribute to the overall covariance measure.
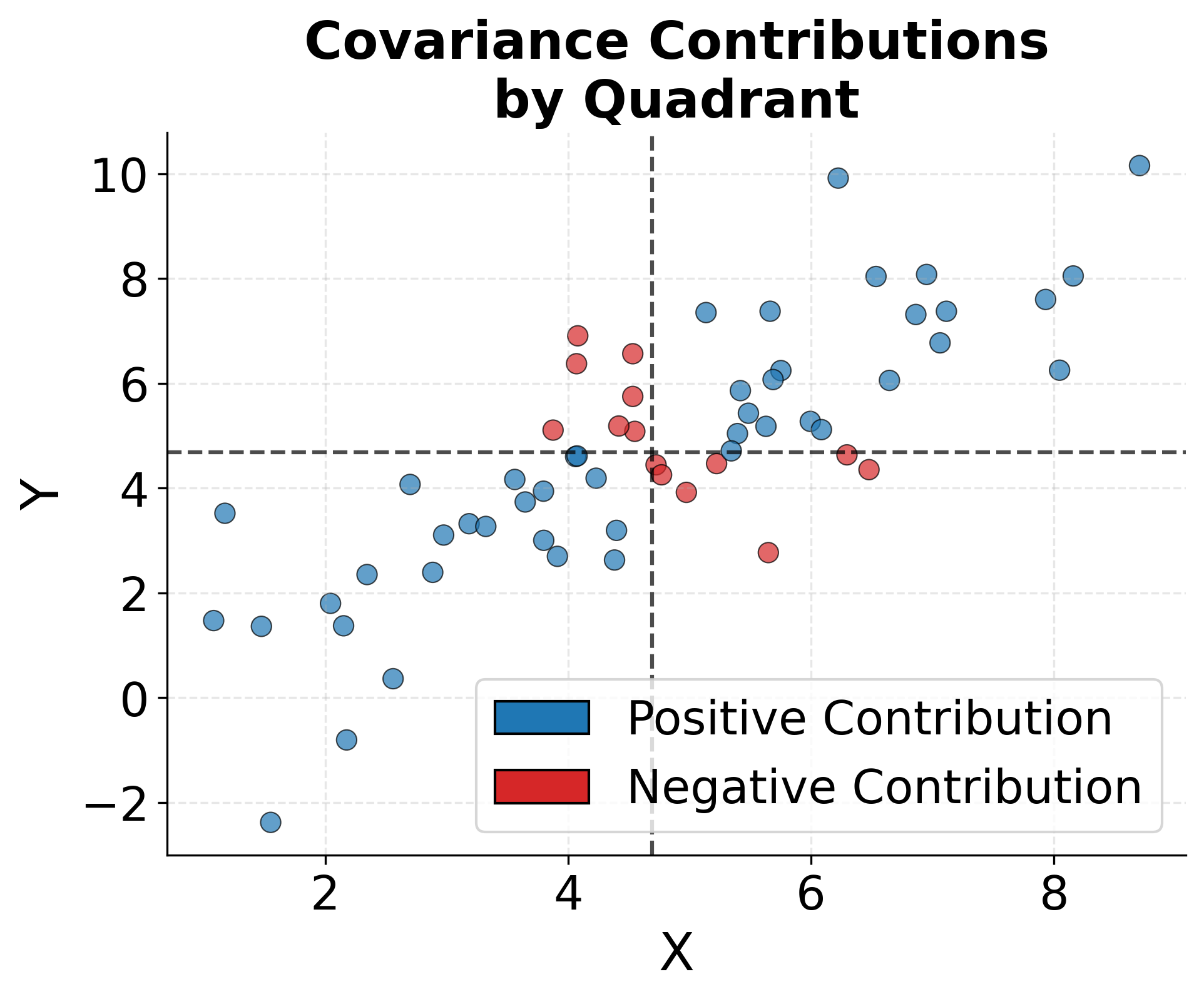
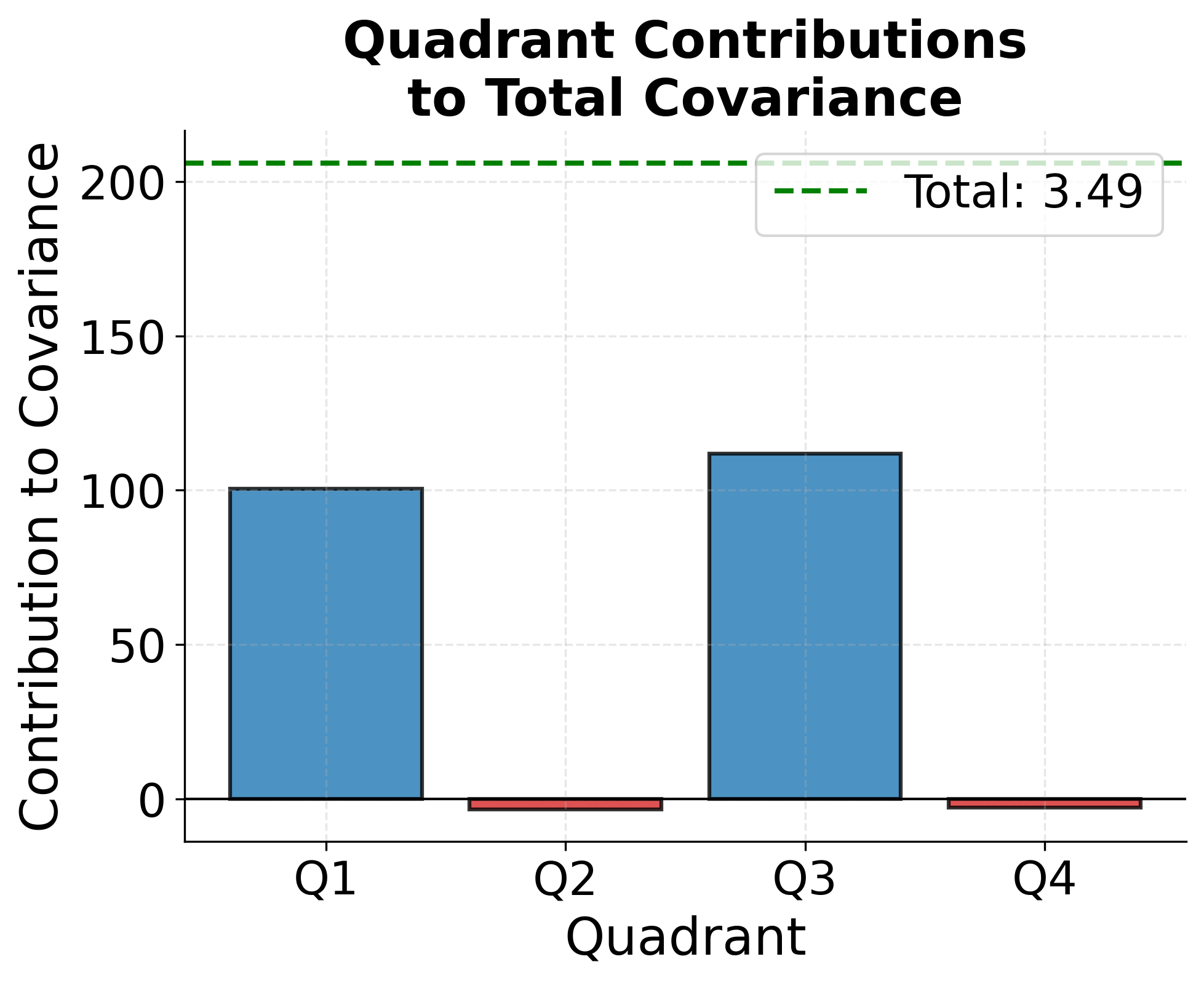
Correlation: Standardized Relationship Strength
Correlation addresses the scale-dependence problem of covariance by standardizing the measure. The Pearson correlation coefficient, the most commonly used correlation measure, divides the covariance by the product of the standard deviations of both variables. This normalization ensures that correlation always falls between -1 and +1, regardless of the original units.
The population correlation coefficient is:
Where:
- : Standard deviation of
- : Standard deviation of
The sample correlation coefficient is:
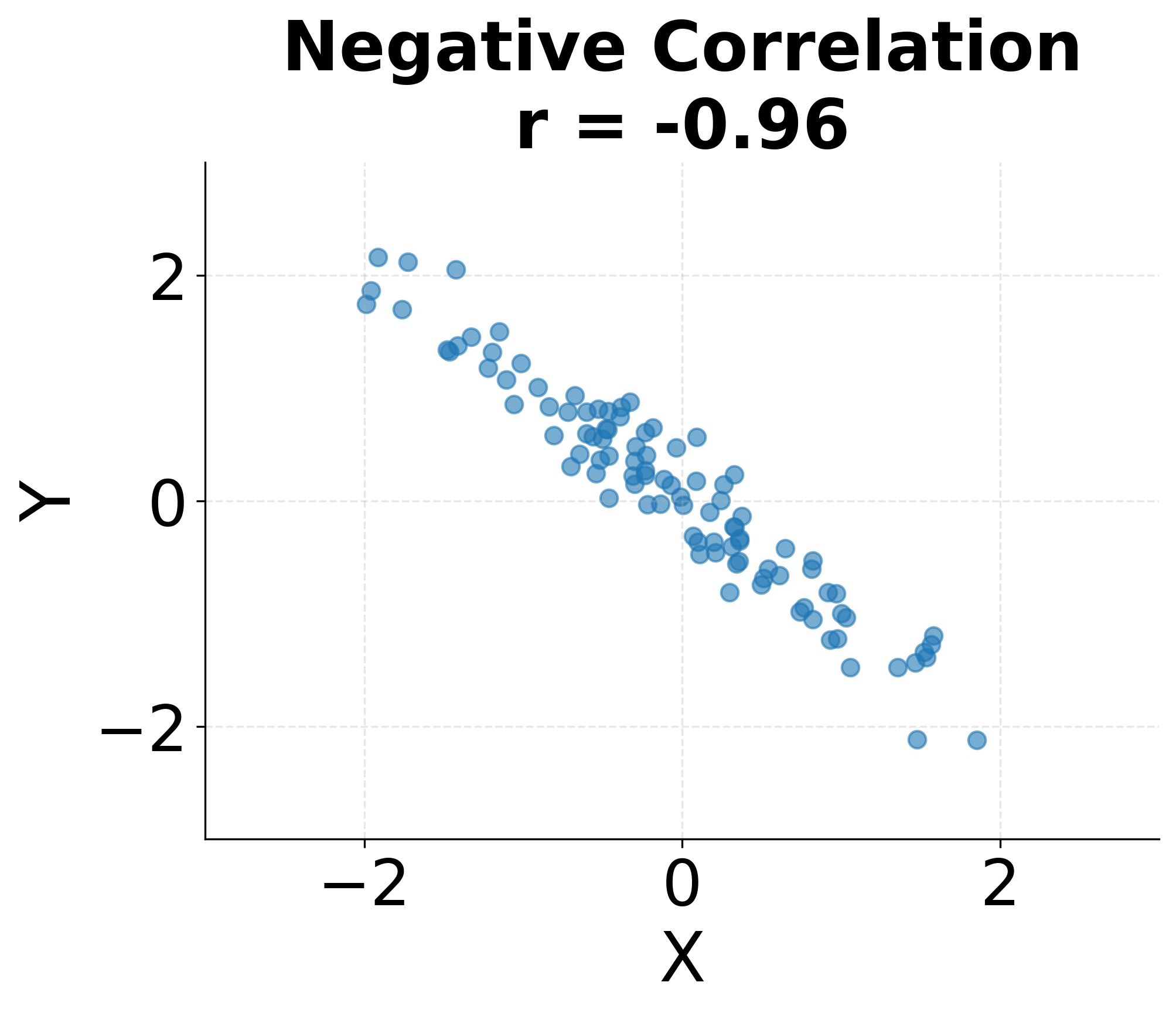
Correlation values have clear interpretations. A correlation of indicates a perfect positive linear relationship where all points fall exactly on a line with positive slope. A correlation of indicates a perfect negative linear relationship. A correlation of suggests no linear relationship, though non-linear relationships may still exist. In practice, correlations between 0.7 and 1.0 or -0.7 and -1.0 are generally considered strong, 0.3 to 0.7 (or -0.3 to -0.7) moderate, and below 0.3 weak, though these thresholds vary by field and context.
The following visualization demonstrates these different correlation patterns, showing how various relationships between variables manifest in scatter plots and their corresponding correlation coefficients.
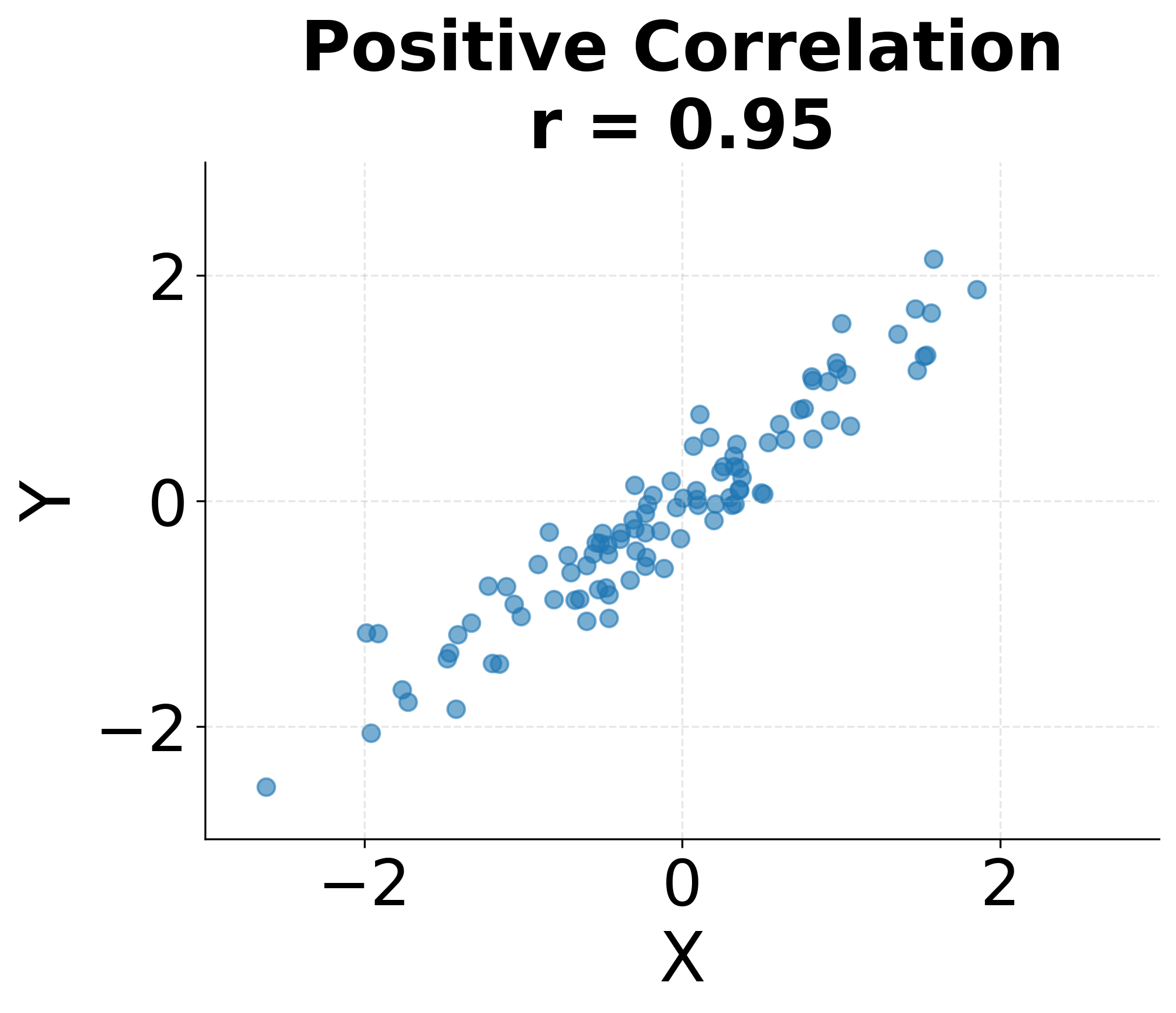
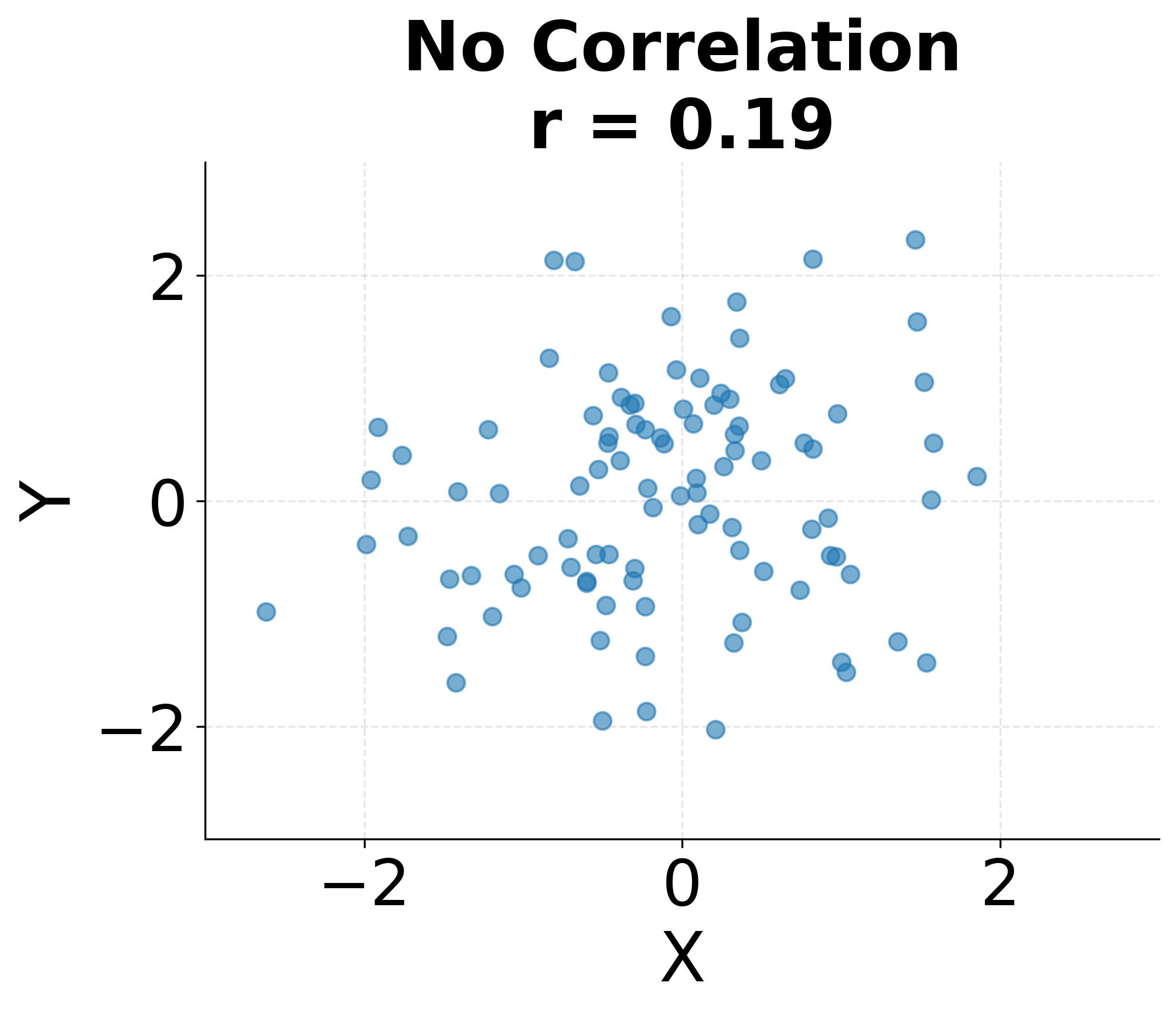
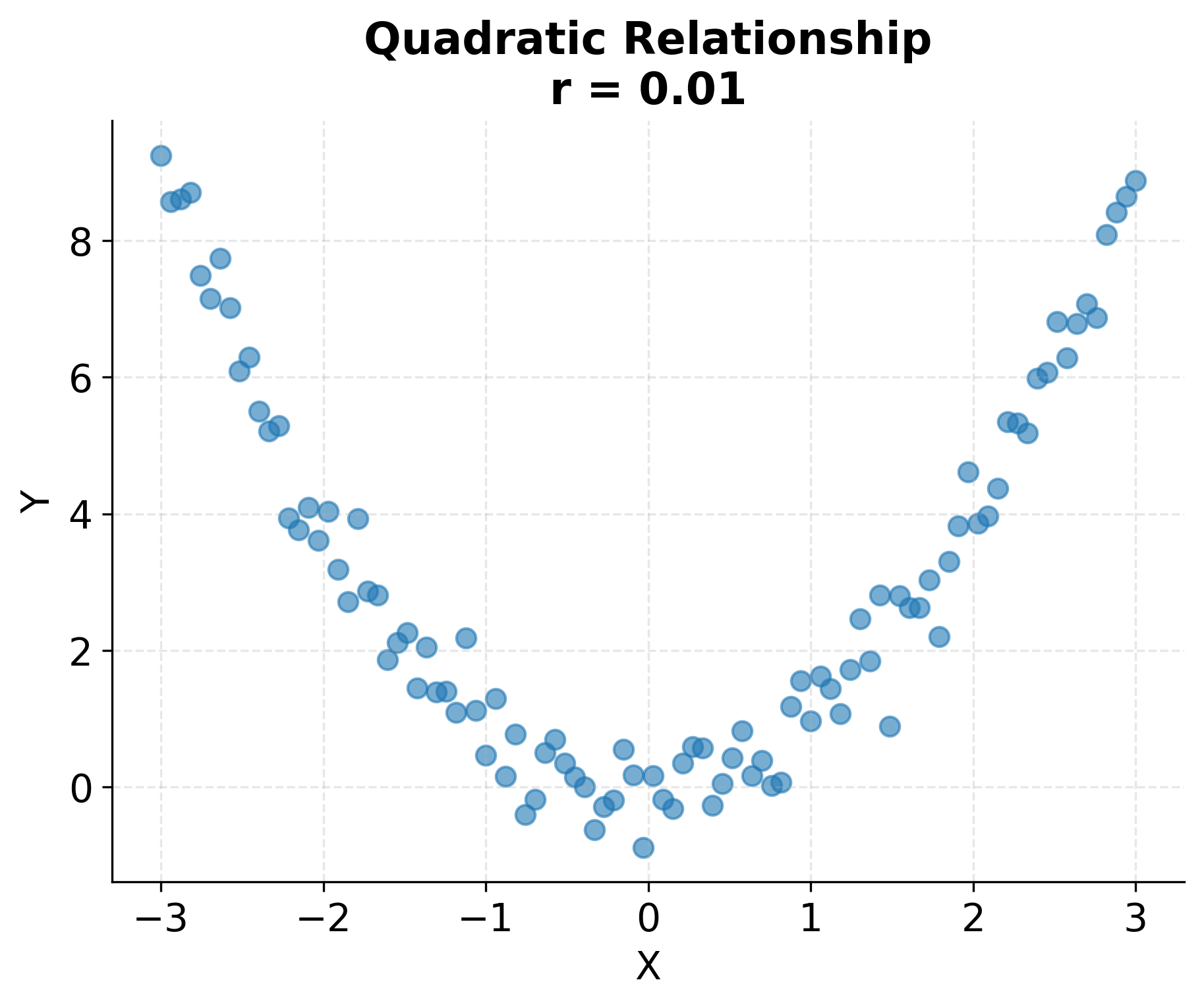
Correlation measures only linear relationships. Two variables can have zero correlation yet still be strongly related through a non-linear pattern such as a quadratic or sinusoidal relationship. This limitation makes visualization essential: plotting your data before relying solely on correlation coefficients helps identify non-linear patterns that correlation cannot detect. The following example demonstrates this limitation with a quadratic relationship where the correlation coefficient is near zero despite a clear pattern.
Simple Linear Regression: Modeling Relationships
While correlation measures the strength of a linear relationship, regression goes further by modeling the relationship explicitly. Simple linear regression fits a line through the data to predict a dependent variable from an independent variable . This line represents the best linear approximation of how changes as changes.
The simple linear regression model is:
Where:
- : Dependent variable (response)
- : Independent variable (predictor)
- : Intercept (value of when )
- : Slope (change in for unit change in )
- : Error term (unexplained variation)
The regression coefficients are typically estimated using ordinary least squares (OLS), which minimizes the sum of squared residuals. The OLS estimates are:
Notice that the slope coefficient is directly related to the correlation coefficient , scaled by the ratio of standard deviations. This connection reveals that regression and correlation are closely related: correlation measures association strength, while regression quantifies the specific form of that association.
The regression line provides several useful capabilities. First, it enables prediction: given a new value of , we can predict the expected value of using . Second, the slope coefficient quantifies the average change in associated with a one-unit change in , providing an interpretable measure of the relationship strength. Third, the regression framework allows for statistical inference: we can test whether the relationship is statistically significant and construct confidence intervals for the coefficients.
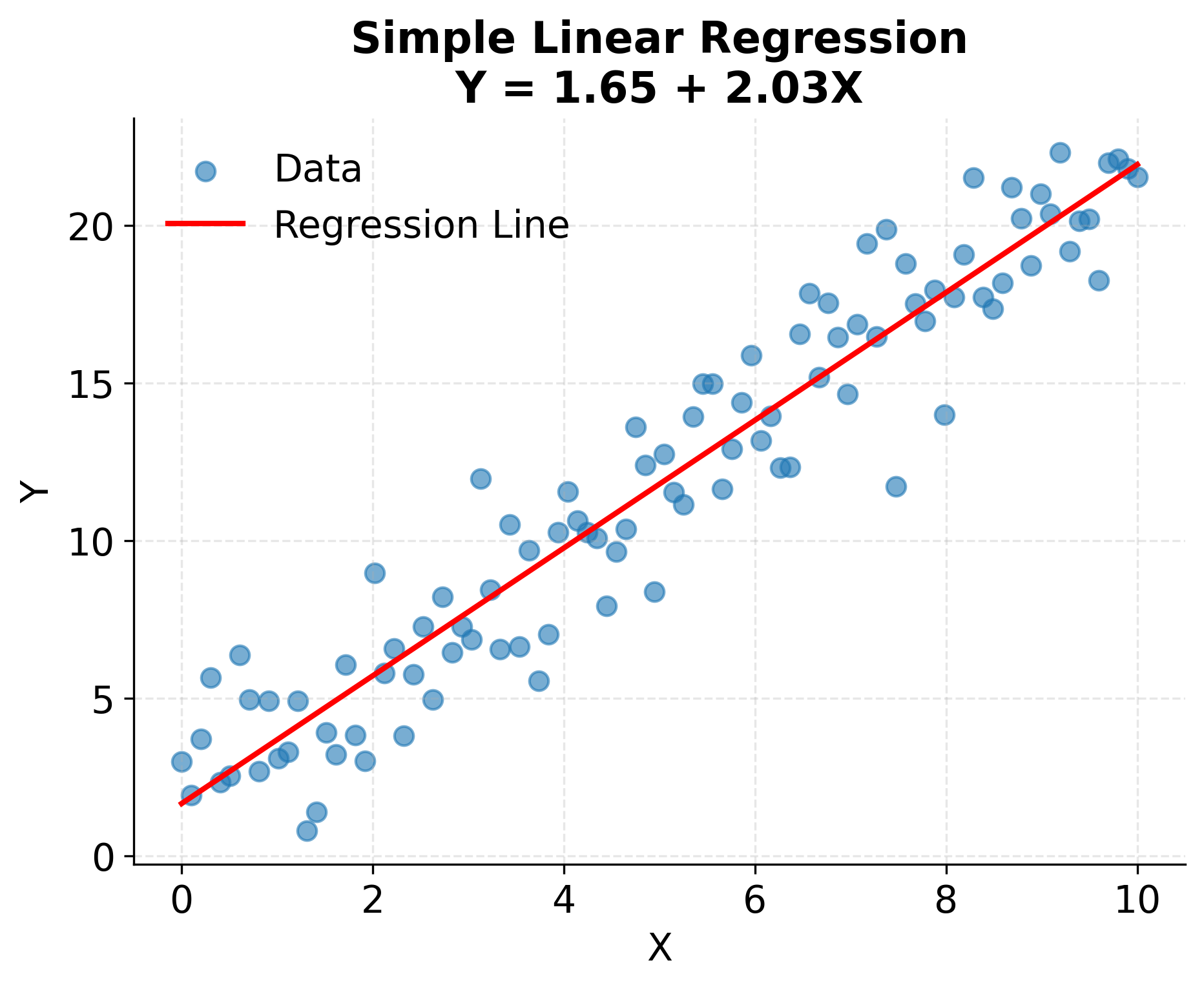
The following example demonstrates a simple linear regression fit to data with a clear linear relationship. The regression line captures the average tendency of Y to increase with X, while the residuals represent the unexplained variation around this trend.
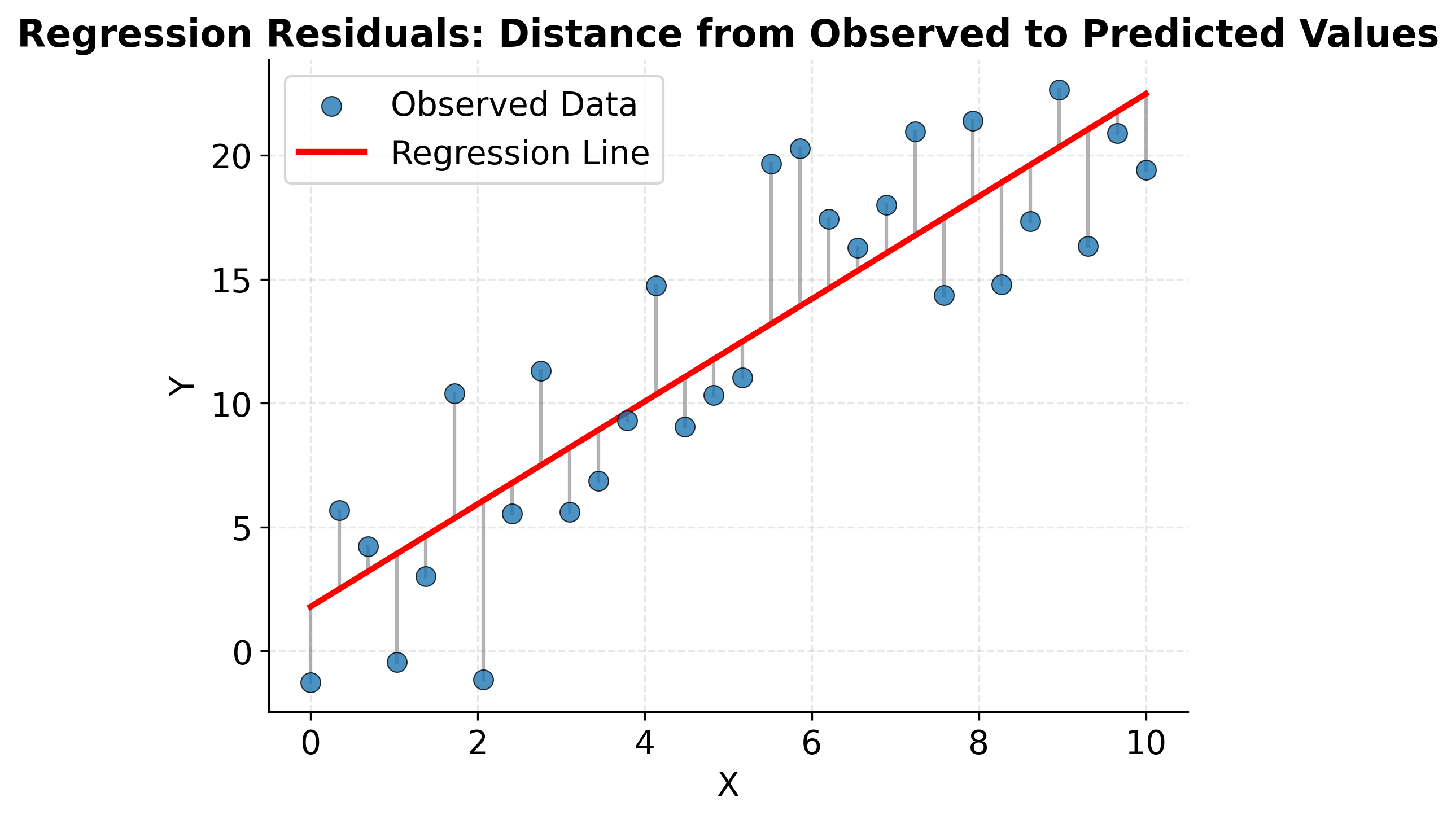
Understanding what regression is actually optimizing helps build intuition for how the method works. The "least squares" criterion means we're finding the line that minimizes the sum of squared vertical distances from points to the line. These vertical distances are called residuals, and they represent the prediction errors. The following visualization shows these residuals explicitly and illustrates what the regression line accomplishes.
Multiple Linear Regression: Multiple Predictors
Real-world phenomena typically depend on multiple factors, not just a single predictor. Multiple linear regression extends simple regression to model the relationship between a dependent variable and multiple independent variables simultaneously. This approach allows us to estimate the effect of each predictor while controlling for the others, providing a more nuanced understanding of complex relationships.
The multiple linear regression model is:
Where:
- : Dependent variable
- : Independent variables (predictors)
- : Intercept
- : Regression coefficients
- : Error term
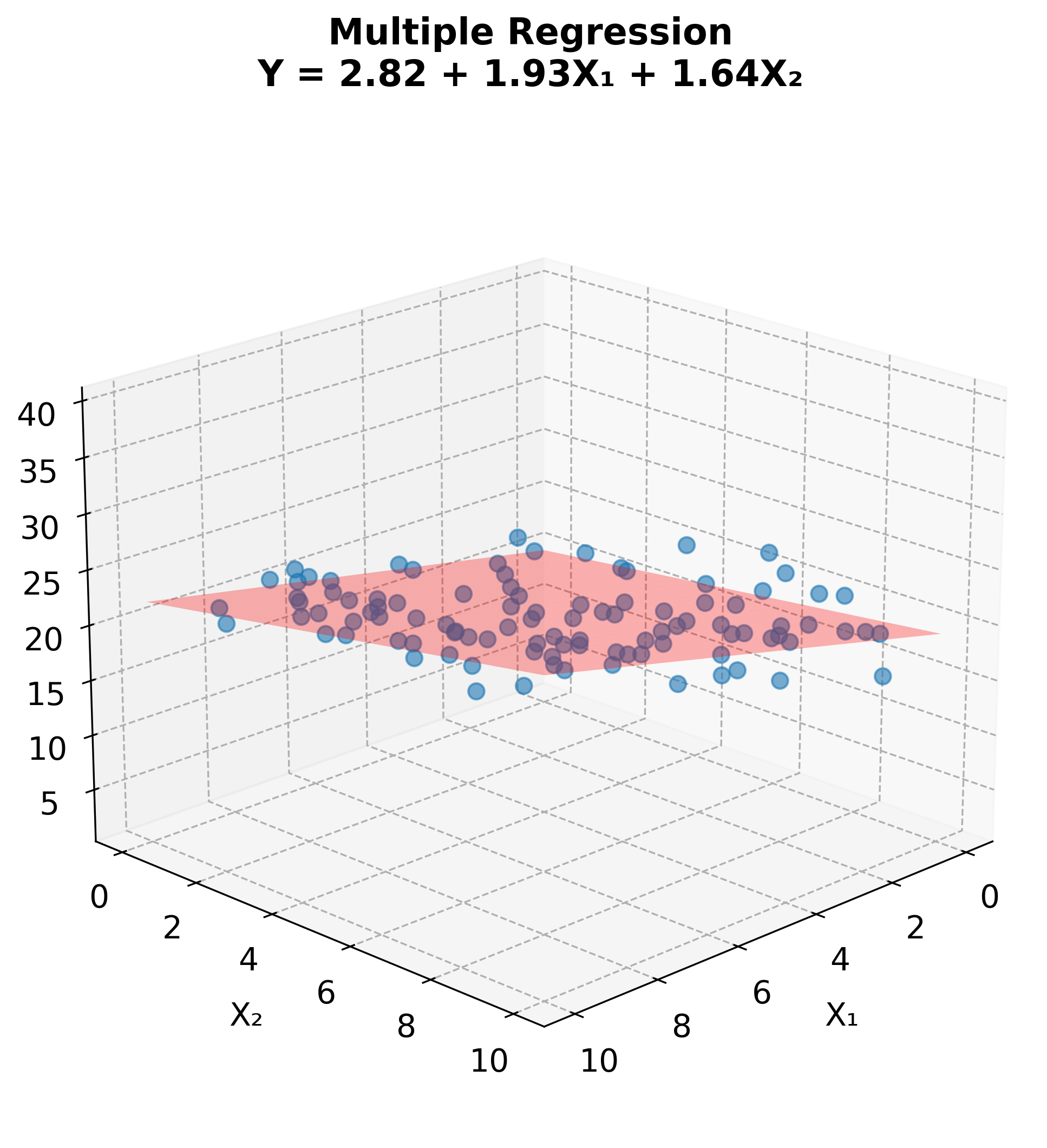
Each coefficient represents the expected change in for a one-unit change in , holding all other predictors constant. This "holding constant" interpretation is crucial: it means we're estimating the partial effect of each variable, adjusting for the influence of other variables in the model. This capability makes multiple regression particularly valuable for disentangling the effects of correlated predictors.
In matrix notation, the model can be written compactly as , and the OLS solution is . This formulation reveals the mathematical elegance of regression and enables efficient computational implementation.
While multiple regression with many predictors is difficult to visualize fully, we can illustrate the concept with two predictors. The regression model fits a plane through three-dimensional space, predicting Y from both X₁ and X₂.
Causation vs. Correlation: A Critical Distinction
Perhaps the most important lesson in studying variable relationships is understanding the difference between correlation and causation. Correlation tells us that two variables move together, but it does not tell us whether one causes the other. This distinction is fundamental to sound statistical reasoning and prevents serious errors in interpretation and decision-making.
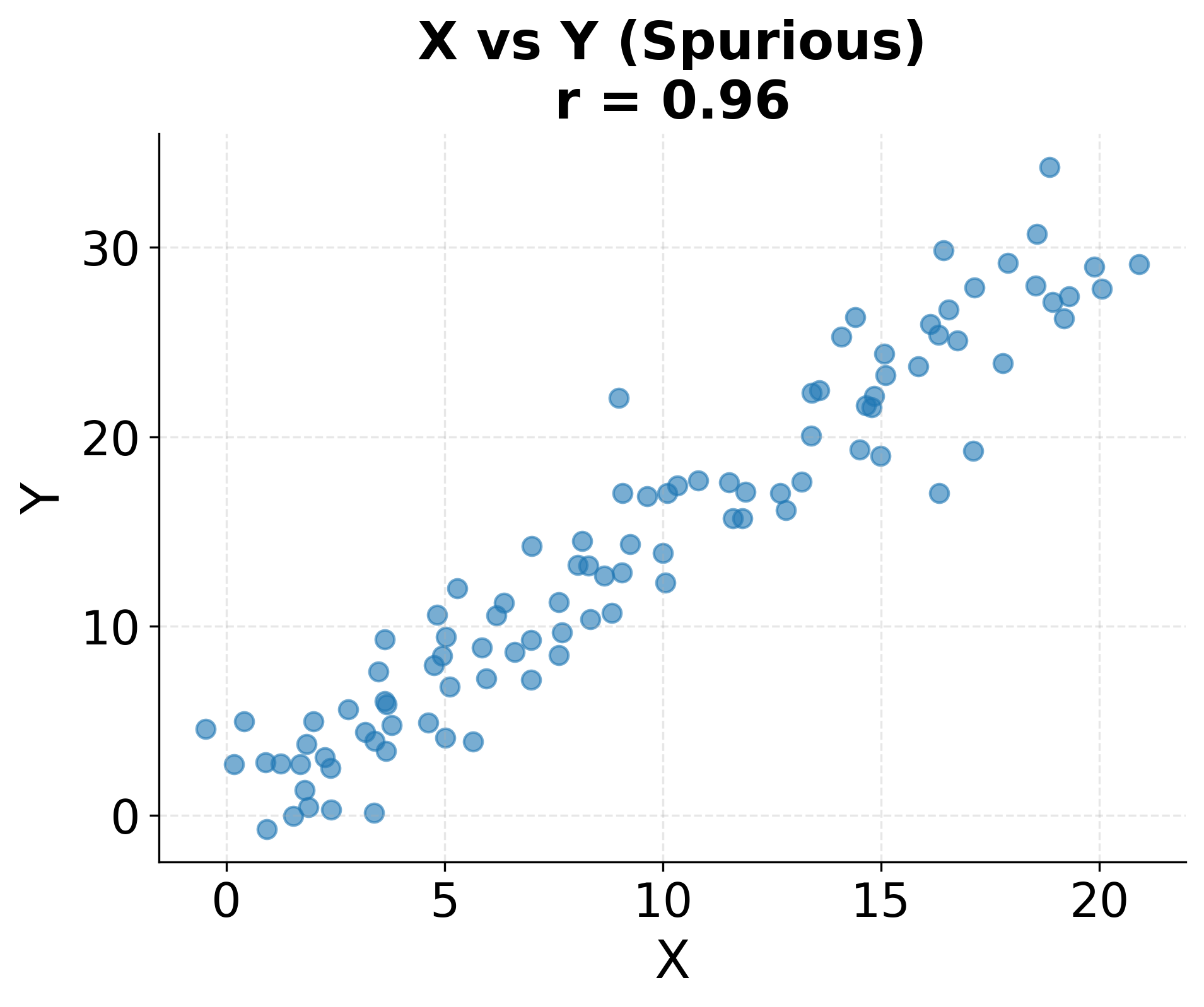
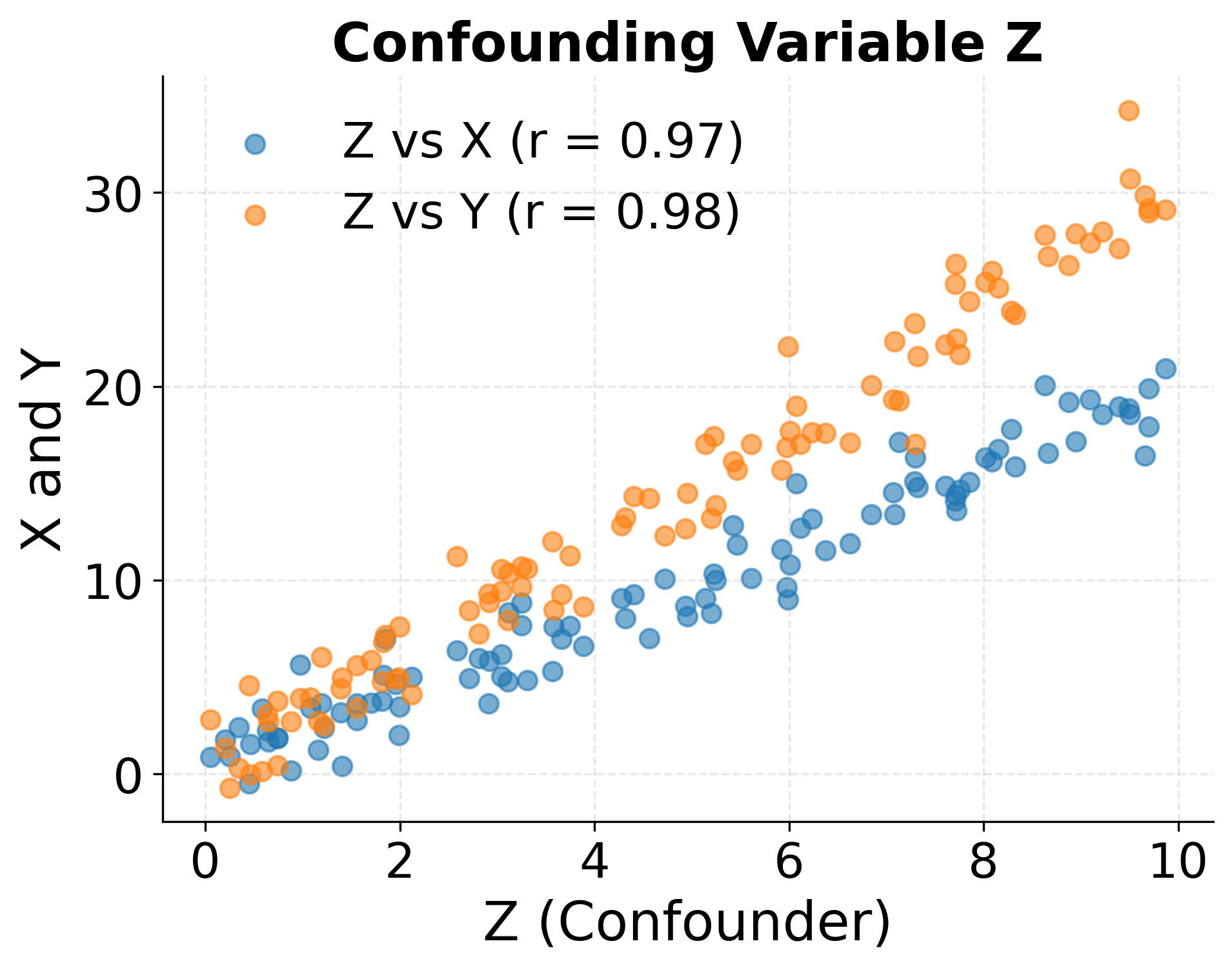
When we observe a correlation between variables and , several scenarios could explain the relationship. First, might genuinely cause . Second, might cause (reverse causation). Third, both and might be caused by a third variable that we haven't measured (confounding). Fourth, the correlation might be purely coincidental, especially when examining many variable pairs (spurious correlation). Without additional information or careful study design, we cannot determine which scenario applies.
Classic examples illustrate the danger of conflating correlation with causation. Ice cream sales and drowning deaths are positively correlated across months, but neither causes the other: both increase during summer when weather is warm. The number of firefighters at a scene correlates with fire damage, but firefighters don't cause damage: larger fires require more firefighters and cause more damage. These examples seem obvious, but similar logical errors occur frequently in data analysis when domain knowledge is insufficient or causal reasoning is neglected.
Establishing causation requires more than observing correlation. Randomized controlled experiments provide the gold standard by randomly assigning subjects to treatment and control groups, ensuring that the only systematic difference is the treatment itself. When experiments are infeasible, causal inference methods such as instrumental variables, regression discontinuity designs, or difference-in-differences can help under specific assumptions. Longitudinal data showing that changes in precede changes in provide suggestive evidence, though temporal precedence alone doesn't prove causation. Strong domain theory explaining a plausible causal mechanism strengthens causal claims.
The practical implications of this distinction are profound. In policy decisions, prescribing interventions based on correlations without understanding causation can be ineffective or harmful. In business, optimizing for correlated metrics rather than causal drivers may waste resources. In science, publishing correlations as causal claims erodes credibility and misinforms the public. Approaching correlations with healthy skepticism and asking "What other factors might explain this relationship?" and "What evidence would demonstrate causation rather than mere association?" helps avoid these pitfalls.
The following example illustrates how a confounding variable can create a spurious correlation between two variables that have no direct causal relationship.
Practical Applications
Understanding variable relationships underpins nearly every data science application. In exploratory data analysis, correlation matrices and scatter plot matrices reveal patterns in multivariate datasets, guiding feature selection and hypothesis generation. Identifying which variables correlate strongly with the target variable helps prioritize modeling efforts and can reveal unexpected relationships worthy of investigation.
In predictive modeling, regression serves as both a standalone algorithm and a component of more complex methods. Linear regression provides interpretable baseline models whose coefficients quantify the strength and direction of predictor effects. Even when more sophisticated algorithms like random forests or neural networks ultimately provide better predictions, regression analysis helps understand which features matter most and whether relationships are approximately linear or highly non-linear.
In A/B testing and causal inference, distinguishing correlation from causation becomes paramount. Randomized experiments enable causal conclusions by ensuring that treatment assignment is independent of potential confounders. Observational studies require careful attention to confounding variables and may employ techniques like propensity score matching or instrumental variables to approximate causal estimates from correlational data.
In quality control and process monitoring, correlation analysis identifies which process variables affect product quality, enabling targeted interventions. In finance, correlation between assets informs portfolio diversification strategies. In epidemiology, identifying correlates of disease helps generate hypotheses about risk factors, though establishing causation requires additional evidence from controlled studies or natural experiments.
Limitations and Considerations
Correlation and regression methods rest on important assumptions that should be verified in practice. Linearity is perhaps the most fundamental assumption: these methods measure and model linear relationships, so they may fail to capture non-linear patterns. Visualizing relationships before computing correlations or fitting regression models helps ensure linearity is plausible. If relationships are non-linear, transformations like logarithms or polynomials may help, or alternative methods like generalized additive models may be more appropriate.
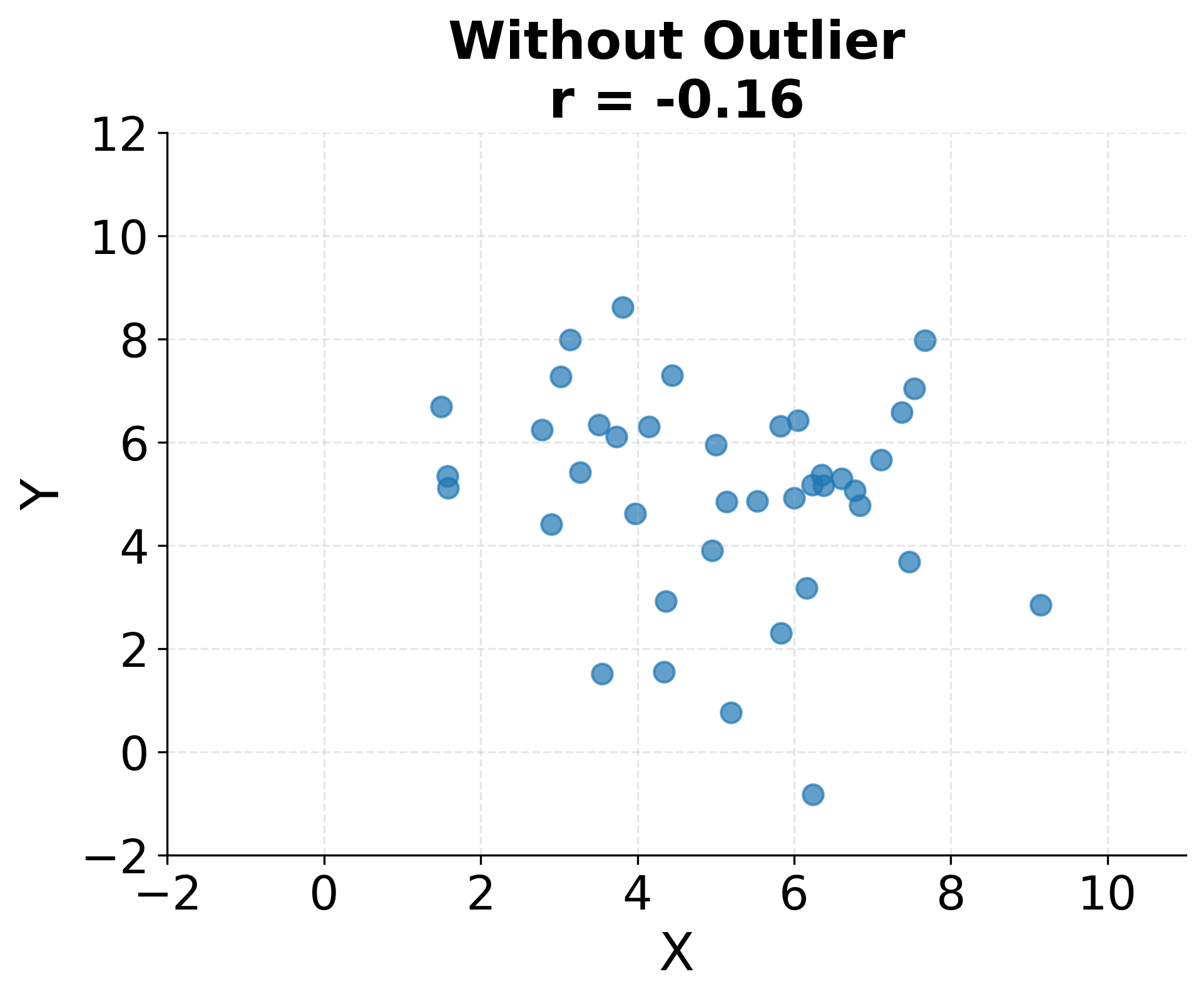
Outliers can dramatically influence correlation and regression estimates because both methods involve squared deviations. A single extreme observation can inflate or deflate correlation coefficients substantially and can rotate regression lines away from the bulk of the data. Robust methods exist that downweight outliers, but understanding why outliers occur and whether they represent valid data points is important before deciding how to handle them.
The following visualization demonstrates just how sensitive correlation coefficients are to outliers. A single extreme point can completely change the correlation from near zero to strongly negative, highlighting why outlier detection and investigation must precede correlation analysis.
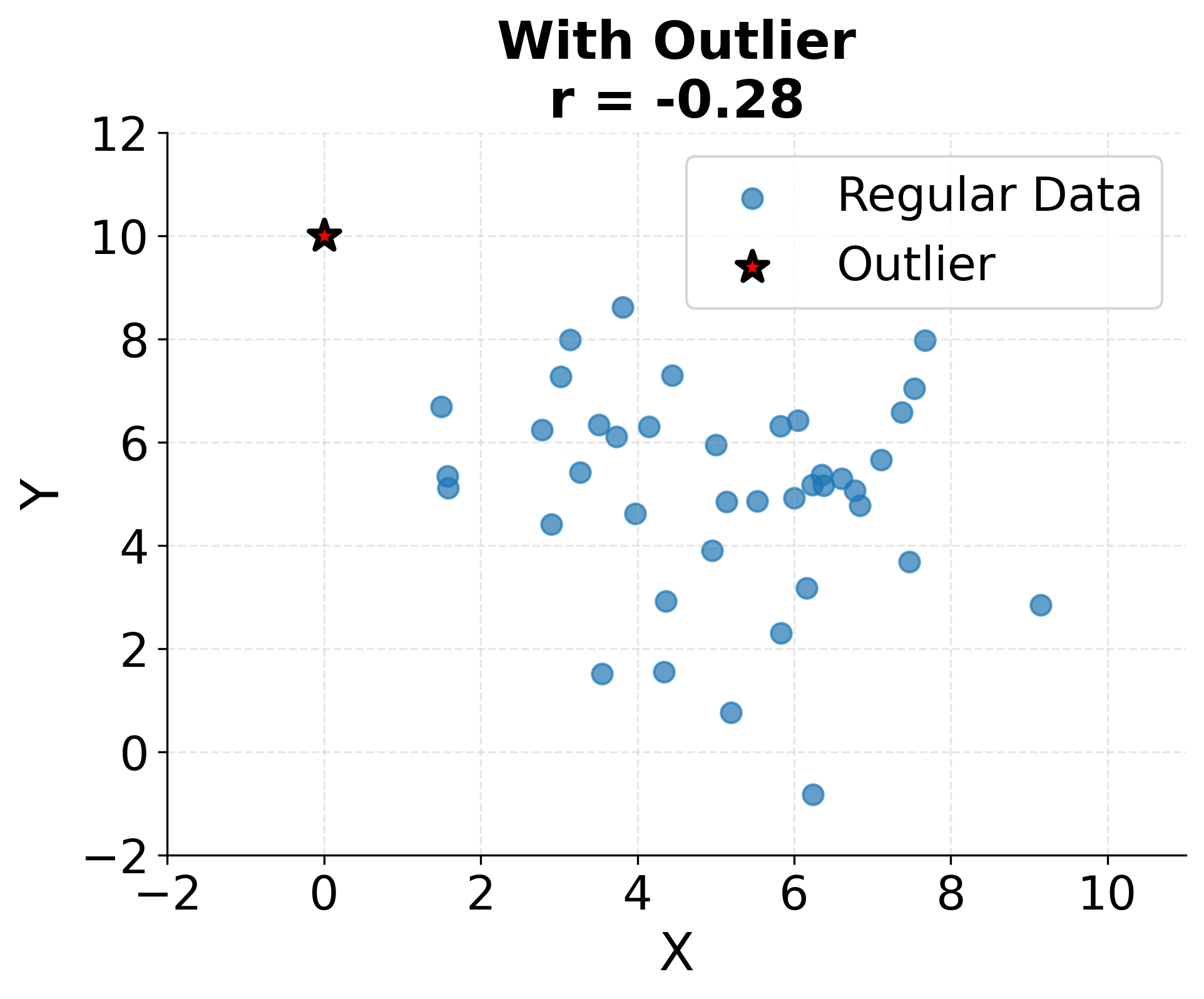
Regression additionally assumes that errors are independent, identically distributed, and have constant variance (homoscedasticity). When these assumptions are violated (for example, when errors are correlated across time or when variance increases with the predicted value), standard errors and confidence intervals become unreliable. Residual diagnostics including plots of residuals versus fitted values help detect such violations and guide corrective actions like transformation or switching to weighted regression.
Sample size affects the reliability of correlation and regression estimates. Small samples yield imprecise estimates with wide confidence intervals, and correlations can appear strong due to chance even when no relationship exists in the population. Statistical significance testing helps distinguish real relationships from sampling variability, but practical significance also matters: a statistically significant but tiny correlation may have little practical value despite low p-values in large datasets.
Finally, correlation and regression describe associations in observed data but do not, by themselves, establish causation. Claims about causal relationships require additional evidence from experimental manipulation, temporal ordering, elimination of confounders, or strong theoretical justification. Interpreting regression coefficients as causal effects requires study designs that support such interpretation, such as randomized experiments or appropriate causal inference methods.
Summary
Understanding relationships between variables forms the foundation of statistical analysis and data science. Covariance and correlation quantify how variables move together, with correlation providing a standardized measure that ranges from -1 to +1 regardless of units. These metrics reveal the strength and direction of linear associations, guiding exploratory analysis and feature selection.
Regression extends correlation by explicitly modeling relationships, enabling prediction and quantifying how changes in predictors associate with changes in the response. Simple linear regression models the relationship between two variables, while multiple regression accommodates many predictors simultaneously and estimates partial effects while controlling for other variables. The regression framework provides both point predictions and statistical inference about the nature and significance of relationships.
Perhaps most critically, correlation does not imply causation. Observed associations can arise from direct causal effects, reverse causation, confounding variables, or pure chance. Establishing causation requires careful study design, often involving randomization or sophisticated observational methods. Conflating correlation with causation leads to flawed conclusions and misguided decisions, making this distinction one of the most important lessons in data science.
These tools (covariance, correlation, and regression) provide the foundation for understanding variable relationships. Used thoughtfully with attention to assumptions and limitations, they enable powerful insights into complex data. Visualizing your data, verifying assumptions, considering alternative explanations for observed patterns, and recognizing that statistical associations rarely tell the complete story on their own are all important practices for sound analysis.
Quiz
Ready to test your understanding of relationships between variables? Take this quiz to reinforce what you've learned about covariance, correlation, and the critical distinction between correlation and causation.

Comments