

Master KV cache compression techniques including eviction strategies, attention sinks, the H2O algorithm, and INT8 quantization for efficient LLM inference.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
KV Cache Compression
As we explored in the previous chapters on KV cache fundamentals and memory analysis, the cache grows linearly with sequence length and can consume tens of gigabytes for long contexts. Paged attention addresses memory fragmentation, but the total memory footprint remains substantial. KV cache compression tackles this problem directly by reducing the amount of data stored, either through selective eviction of less important cache entries or by quantizing the cached values to lower precision.
The key insight driving compression research is that not all cached tokens contribute equally to generation quality. Attention patterns in transformers are highly non-uniform: certain tokens receive concentrated attention while others are nearly ignored. This sparsity creates an opportunity. If we can identify and preserve the high-value cache entries while discarding the rest, we can dramatically reduce memory usage with minimal impact on output quality.
This chapter covers the three main approaches to KV cache compression: eviction-based strategies that remove entire token representations from the cache, attention sink preservation that protects critical initial tokens, and cache quantization that reduces the numerical precision of stored values. We'll examine the H2O (Heavy-Hitter Oracle) algorithm in detail as a representative eviction method, then explore how these techniques can be combined for maximum compression.
The Compression Opportunity
Before diving into specific techniques, let's understand why compression is feasible in the first place. The fundamental question we need to answer is this: can we discard information from the KV cache without significantly harming generation quality? To answer this, consider the attention patterns in a typical language model generating the 500th token. The query for this new token computes attention scores against all 499 previous key vectors. In a perfectly uniform distribution, each previous token would receive of the attention. In practice, attention is far from uniform, and this non-uniformity is precisely what makes compression possible.
Studies of transformer attention patterns reveal several consistent phenomena that explain why some tokens matter far more than others:
- Local focus: Recent tokens often receive disproportionate attention, especially in lower layers. This makes intuitive sense because language exhibits strong local coherence, with adjacent words often being grammatically and semantically related.
- Anchor tokens: Certain semantically important tokens (subjects, verbs, key entities) attract attention regardless of distance. These tokens carry the core meaning of a passage and remain relevant throughout generation.
- Attention sinks: As we covered in Part XV, initial tokens accumulate attention even when semantically irrelevant. This curious phenomenon appears to serve a computational purpose rather than a semantic one.
- Sparse activation: Many tokens receive near-zero attention and contribute minimally to the output. These tokens are candidates for removal without significant quality degradation.
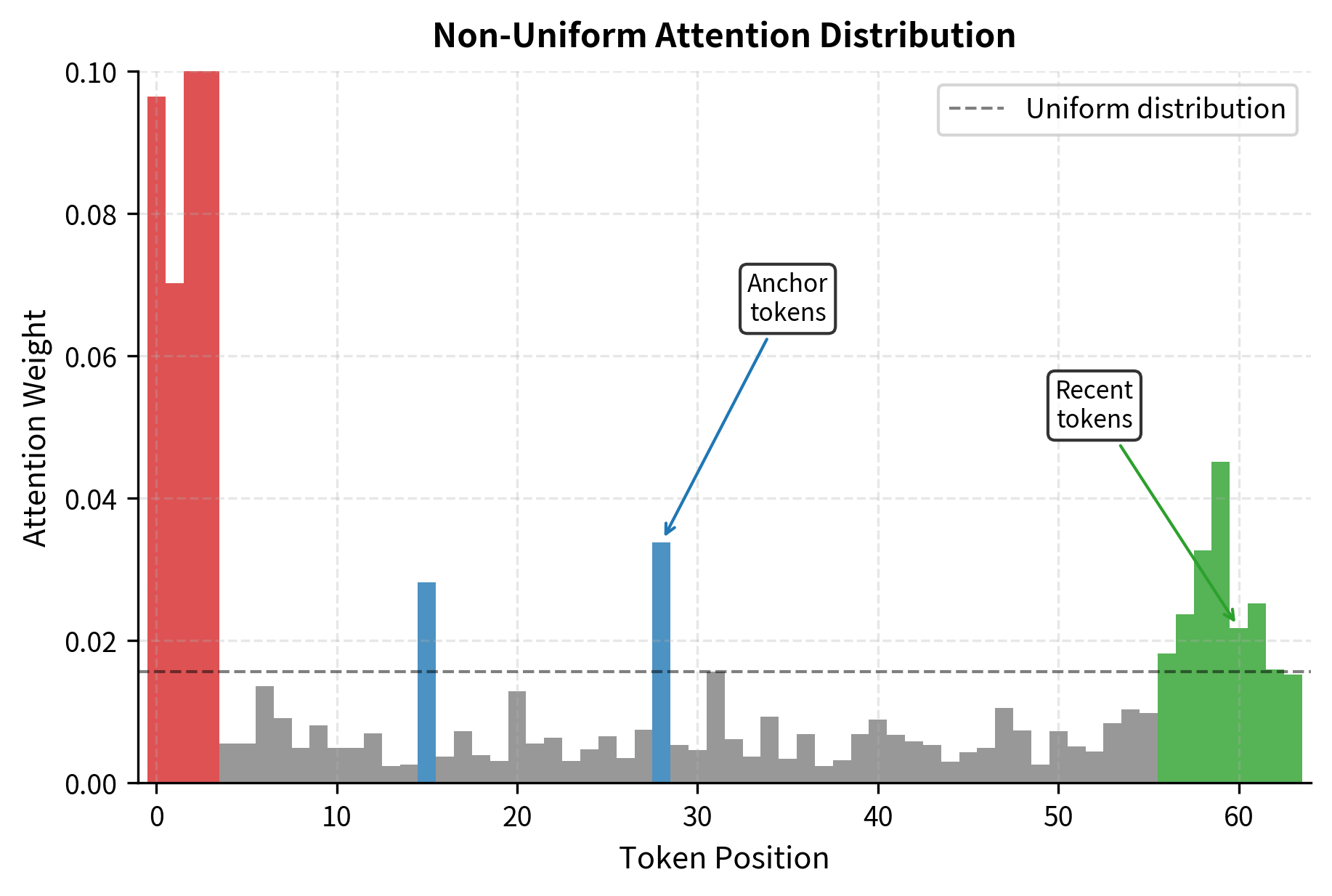
This non-uniformity means that a cache storing only the high-attention tokens might preserve most of the information needed for accurate generation. The attention distribution is not merely slightly skewed; it is often dramatically concentrated on a small subset of tokens. The challenge lies in identifying these important tokens efficiently, without requiring expensive computation at each generation step. We need methods that can predict which tokens will be important for future generation steps, not just which tokens have been important in the past.
Window-Based Eviction
The simplest eviction strategy maintains a fixed-size sliding window, keeping only the most recent tokens in the cache. This approach has clear appeal for several reasons. It is trivial to implement, requires no analysis of attention patterns, and guarantees constant memory usage regardless of sequence length. The underlying assumption is that recent context is the most relevant context, which holds true for many language modeling scenarios.
Truncating to 32 tokens reduces cache memory by 68% in this example. The implementation is straightforward: we simply slice the tensor to keep only the final positions. However, this simplicity comes with a fundamental limitation: the approach discards all context beyond the window, including potentially crucial information from the beginning of the sequence.
Consider the practical implications through a concrete example. Imagine generating a response to a question. The question might appear at token positions 0-50, followed by supporting context at positions 51-400, with generation starting at position 401. A sliding window of 100 tokens would retain only tokens 301-400, losing the original question entirely. The model would have no memory of what it was asked, potentially producing irrelevant or incoherent responses. This illustrates why pure window-based approaches often fail for tasks requiring long-range dependencies. The approach works well for streaming applications or local language modeling, but breaks down when the task requires referencing distant context.
Attention-Based Eviction
A more sophisticated approach selects tokens based on their historical attention scores rather than their recency. The intuition behind this method is straightforward: tokens that have received high attention in the past are likely to be important for future generation. These tokens have already proven their value, so preserving them makes sense. By tracking cumulative attention and evicting low-attention tokens, we can maintain a compact cache of the most relevant context while adapting to the specific content being processed.
The key insight here is that attention scores provide a signal of token importance. When the model attends heavily to a particular token, it extracts information from that token to inform its output. Tokens that consistently receive high attention across multiple generation steps are carrying information that the model repeatedly needs. These "frequently consulted" tokens are prime candidates for preservation, while tokens that receive negligible attention can likely be removed without consequence.
This approach adapts dynamically to the content being processed. Important tokens accumulate high attention scores over time and remain in the cache, while less relevant tokens get evicted as their scores remain low. The method naturally identifies semantically meaningful tokens like subjects, key entities, and important verbs that the model needs to reference repeatedly.
However, the approach introduces computational overhead for tracking scores and, more critically, has a fundamental flaw that we must address. The flaw relates to a peculiar attention pattern we covered earlier: attention sinks. We will explore this issue and its solution in the next section.
Attention Sink Preservation
As we discussed in Part XV, Chapter 5 on attention sinks, transformers exhibit a curious behavior that complicates attention-based eviction: initial tokens in a sequence accumulate disproportionate attention even when they carry no semantic importance. These "attention sinks" appear to serve as computational anchors, providing a stable target for attention heads to discharge probability mass when no relevant context exists. The phenomenon emerges from training dynamics: the model learns to use early tokens as a default attention target, creating a dependency that persists even when those tokens are semantically meaningless.
When we evict tokens based purely on historical attention scores, we risk removing these sink tokens because they may not have the highest cumulative attention. Counterintuitively, the initial tokens that receive high attention are not necessarily the tokens we should prioritize keeping based on semantic importance. The consequences of removing sinks can be severe. Without attention sinks available, models may produce incoherent outputs, fall into repetition loops, or exhibit generally degraded quality. The attention mechanism loses its computational anchor, disrupting the learned patterns that depend on its presence.
This creates a paradox for attention-based eviction strategies. The tokens receiving highest attention (the sinks) may not be semantically important, while truly important content tokens may receive only moderate attention because they share the attention budget with the sinks. Pure attention-score-based eviction conflates two distinct sources of high attention: semantic importance and computational anchoring.
The solution is elegantly simple: protect initial tokens from eviction regardless of their attention scores. By unconditionally preserving the first few tokens, we ensure the attention sinks remain available while still allowing the eviction policy to remove genuinely unimportant tokens from the rest of the sequence.
The StreamingLLM approach maintains exactly sink_size + window_size tokens once the cache is full, providing predictable memory usage while preserving the critical attention sinks. The cache size grows linearly during the initial phase, then plateaus at the maximum size and remains constant regardless of how many additional tokens are generated. This bounded memory behavior enables indefinitely long streaming generation.
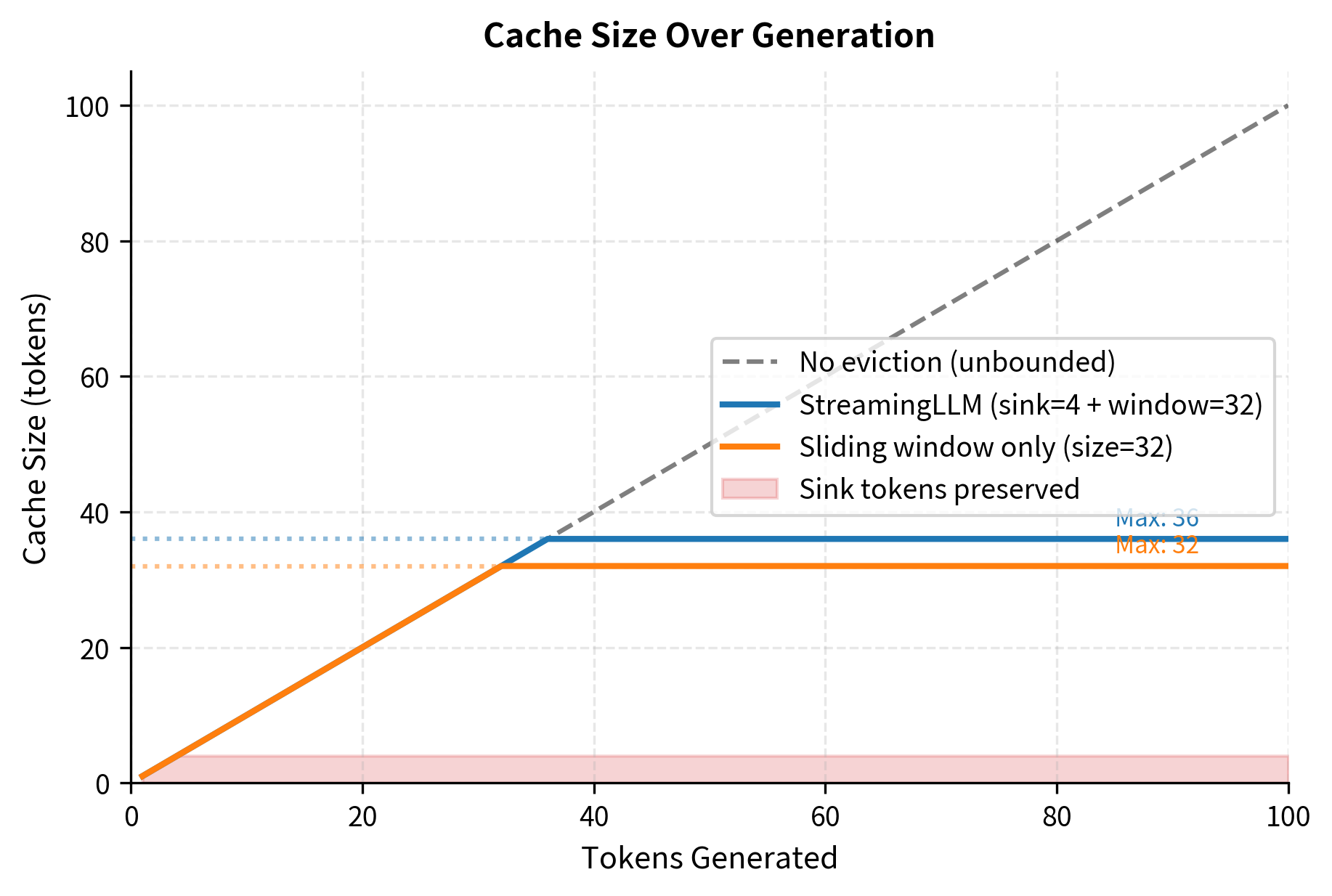
Research has shown that just 4 sink tokens are typically sufficient to maintain generation quality, making this a highly efficient solution. The small sink budget adds minimal memory overhead while providing the computational anchoring the model requires. Combined with a modest window size, the approach achieves substantial compression while maintaining coherent generation for streaming applications.
The H2O Algorithm
Heavy-Hitter Oracle (H2O) represents a more sophisticated eviction policy that extends beyond simple recency or sink preservation. The algorithm combines attention-based selection with sink preservation, addressing the limitations of both pure window-based and pure attention-based approaches. The key insight motivating H2O is that tokens exhibit different temporal importance patterns. Some tokens are "heavy hitters," consistently receiving high attention across many generation steps because they carry information the model repeatedly needs. Other tokens are transient, relevant only briefly before becoming obsolete as generation proceeds.
Consider how these patterns manifest in practice. A subject noun at the beginning of a paragraph might be a heavy hitter, receiving attention throughout the paragraph as the model maintains coherence. A transition word, by contrast, might receive attention only from the immediately following tokens before becoming irrelevant. H2O captures this distinction by tracking cumulative attention over time and using it to identify tokens worthy of long-term preservation.
H2O maintains two categories of tokens that serve complementary purposes:
- Recent tokens: A sliding window of the most recent tokens. These provide immediate local context and ensure the model can maintain coherent generation based on what was just produced.
- Heavy hitters: Tokens with the highest cumulative attention scores, capped at tokens. These represent semantically important content that the model has repeatedly consulted, suggesting continued relevance.
The algorithm dynamically balances these sets throughout generation, ensuring that both recency and historical importance are considered when making eviction decisions. Tokens can transition between categories: a recent token that accumulates high attention becomes a heavy hitter candidate, while a former heavy hitter that stops receiving attention may eventually be evicted.
Notice how positions 5 and 10 are retained in the cache despite not being among the most recent tokens. Their high cumulative attention scores qualify them as heavy hitters, preserving important context while still maintaining recency through the recent token budget. The algorithm has automatically identified these tokens as carrying important information that the model repeatedly needs, and it protects them from eviction even as dozens of newer tokens have been generated.
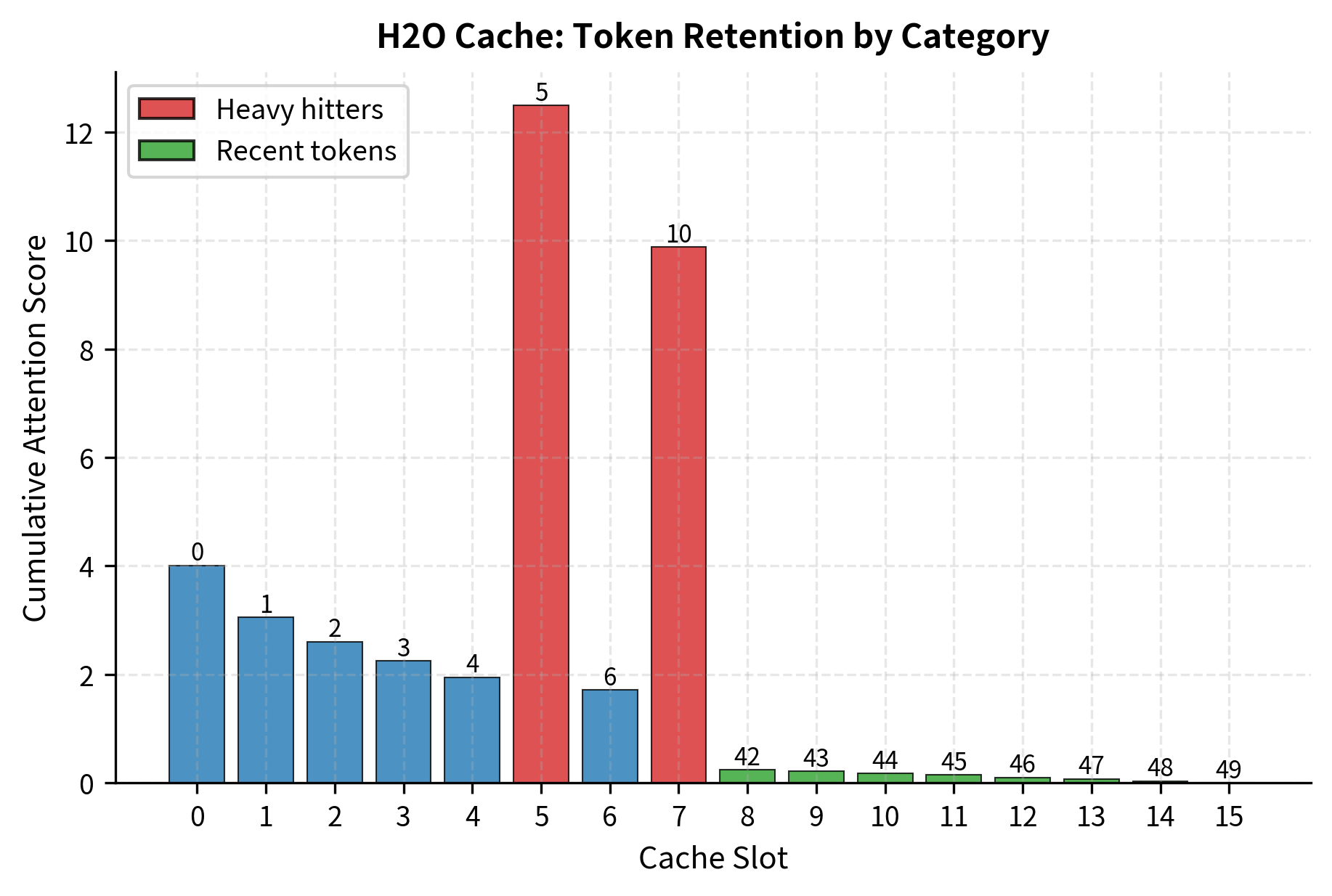
The cumulative attention scores reveal the distinction between heavy hitters and ordinary tokens. Positions 5 and 10 have accumulated substantially higher scores than other retained positions because the simulated attention pattern consistently attended to them. In a real model, these high-attention tokens would typically correspond to semantically important content: the subject of a sentence, a key entity being discussed, or a critical fact that informs subsequent generation.
Cache Quantization
Orthogonal to eviction strategies, cache quantization reduces memory by storing key and value vectors at lower numerical precision. While model weights typically use FP16 or BF16 during inference, the cached activations can often tolerate even lower precision without significant quality loss. This approach complements eviction: rather than removing tokens entirely, we keep all tokens but represent each one using fewer bits.
The mathematical foundation of quantization is straightforward. We need to map continuous floating-point values to a discrete set of integers that can be stored compactly. The simplest form is uniform quantization which divides the value range into equally-spaced bins and maps each floating-point value to the nearest bin:
Let us carefully examine each component of this formula to understand how it accomplishes the mapping from floating-point to integer representation:
- : the resulting quantized integer index, which will be stored in place of the original floating-point value
- : the original floating-point value that we wish to compress
- : the minimum value in the group being quantized, establishing the lower bound of the value range
- : the maximum value in the group being quantized, establishing the upper bound of the value range
- : the target bit width (e.g., 8 for INT8 or 4 for INT4), determining how many discrete levels are available
- : the total number of discrete quantization levels, which equals the maximum integer value representable
This transformation accomplishes its goal through a sequence of intuitive steps. First, it normalizes the original value to the range by computing the fraction . This fraction represents where falls within the overall range of values. Second, it scales this normalized value to the full integer range by multiplication. Finally, it rounds to the nearest integer to obtain a discrete representation that can be stored efficiently. This approach preserves the relative ordering and approximate magnitudes of values while dramatically reducing storage requirements.
When we need to use the cached values for computation, we must reverse this process. Dequantization recovers an approximation of the original value:
Again, let us examine each component to understand the reconstruction process:
- : the reconstructed floating-point value, which approximates the original
- : the stored quantized integer retrieved from memory
- : the target bit width used during quantization
- : the minimum value from the original group, serving as the offset that restores the correct baseline
- : the dynamic range of the original values, used to restore the correct magnitude
The reconstruction process precisely reverses the quantization steps. It first converts the integer back to a proportion in by dividing by the maximum integer value. It then maps that proportion onto the original dynamic range by multiplying by . Finally, it adds the offset to restore the correct baseline. The reconstructed value will differ from the original by at most half a quantization step, introducing a small but bounded error.
INT8 quantization achieves 2x compression with minimal error, maintaining cosine similarity above 0.99. This high cosine similarity is particularly important because attention operates on dot products between queries and keys. The dot product is fundamentally a measure of similarity, and if the quantized keys preserve high cosine similarity with their original values, the resulting attention scores will be nearly identical to what they would have been without quantization.
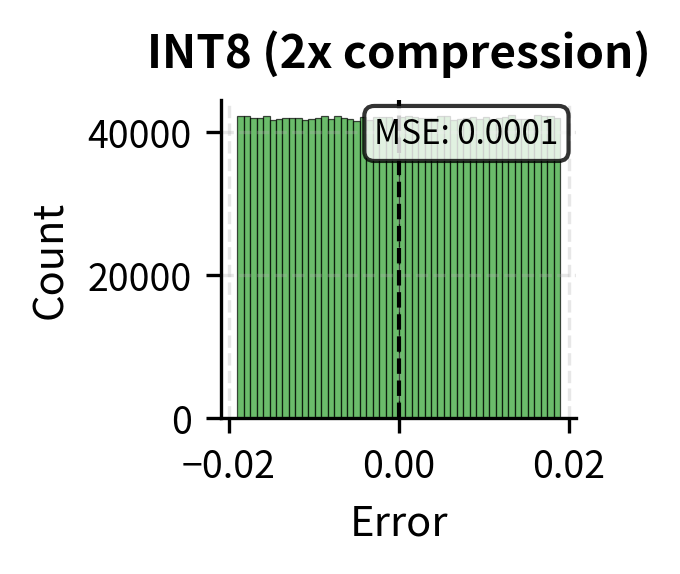
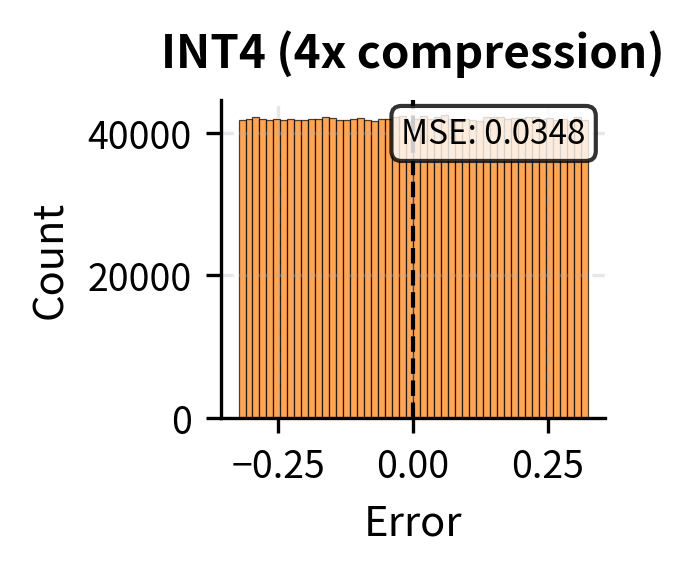
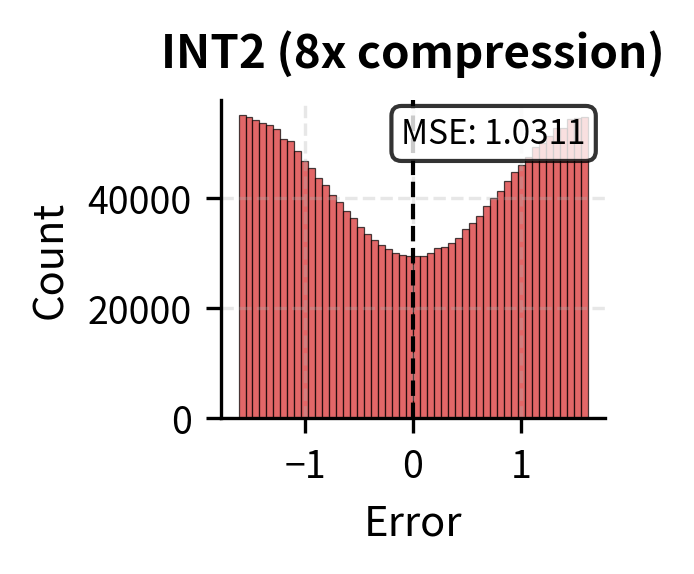
Even INT4 quantization, which provides 4x compression, often preserves sufficient similarity for acceptable generation quality. However, quality degradation becomes noticeable for precision-sensitive tasks at this level. The trade-off between compression and accuracy depends heavily on the specific application: chat applications may tolerate INT4 well, while code generation or mathematical reasoning may require the precision of INT8 or higher.
Per-Channel Quantization
The per-tensor quantization approach we examined computes global statistics across the entire tensor, using a single minimum and scale value for all elements. This approach is simple but can be suboptimal when different attention heads or dimensions have varying value ranges. If one head has values concentrated in a narrow range while another has a wide range, using global statistics forces the narrow-range head to use only a fraction of the available quantization levels, wasting precision.
Per-channel quantization improves accuracy by computing separate scales for each head or channel. Each attention head gets its own minimum and scale values, allowing it to use the full range of quantization levels regardless of what other heads are doing. This independence is particularly valuable because different attention heads often specialize in different types of patterns and may exhibit quite different value distributions.
Per-channel quantization significantly reduces error at the same bit width because each attention head can use its full quantization range independently. The improvement is particularly pronounced at lower bit widths where the limited number of quantization levels makes efficient range utilization critical. This technique allows INT4 per-channel quantization to approach the accuracy of INT8 per-tensor quantization in many cases.
Combining Techniques
The most effective KV cache compression strategies combine multiple approaches to achieve multiplicative benefits. Rather than choosing between eviction and quantization, we can apply both: first reduce the number of cached tokens through intelligent eviction, then store the remaining tokens at reduced precision through quantization. This layered approach addresses memory from two complementary angles.
A practical configuration might use the following combination:
- Attention sink preservation: Keep the first 4 tokens unconditionally to maintain computational stability
- H2O-style eviction: Maintain heavy hitters plus recent tokens to preserve both semantic importance and local context
- INT8 quantization: Store all cached values at 8-bit precision to halve the per-token memory footprint
The combined approach achieves dramatic memory reduction through the multiplication of two independent compression factors. Eviction reduces the token count from 1000 to 64, providing approximately 15.6x compression. INT8 quantization then provides an additional 2x reduction by halving the bytes per token. The total compression ratio exceeds 30x, transforming what would require substantial memory into a compact representation that fits easily in limited GPU memory.
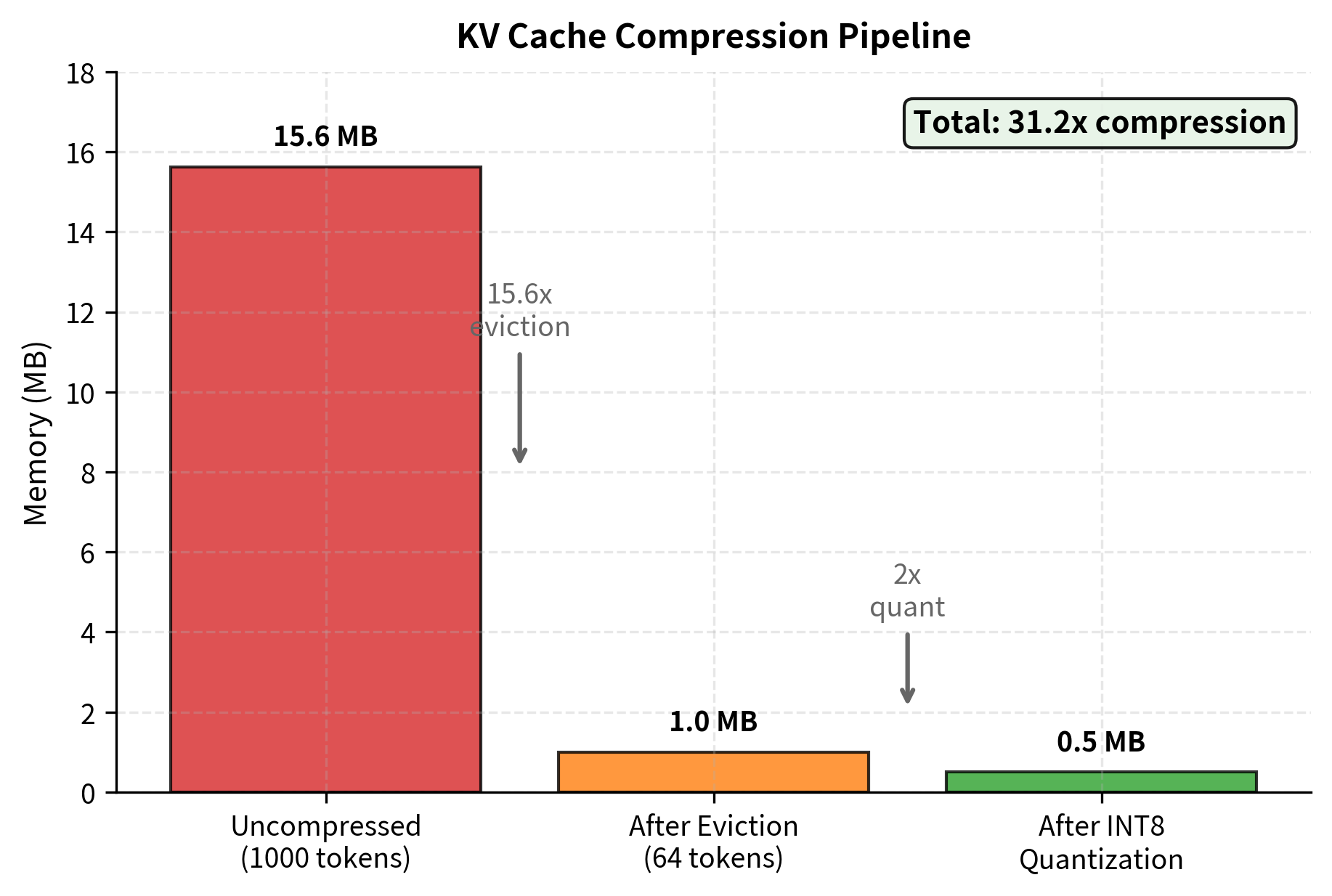
This level of compression enables generation at context lengths that would otherwise exceed available memory. A configuration that might require 16GB of KV cache memory without compression can operate within 500MB using these combined techniques. For deployment scenarios where memory is constrained or costs must be minimized, such aggressive compression makes previously infeasible applications practical.
Compression Quality Analysis
Compression introduces approximation error that can degrade generation quality, and understanding the nature of this error is essential for making informed trade-offs. Different compression techniques produce qualitatively different error patterns, which affects how they impact the attention mechanism and ultimately the generated text.
Let's visualize how different compression strategies affect the attention computation:
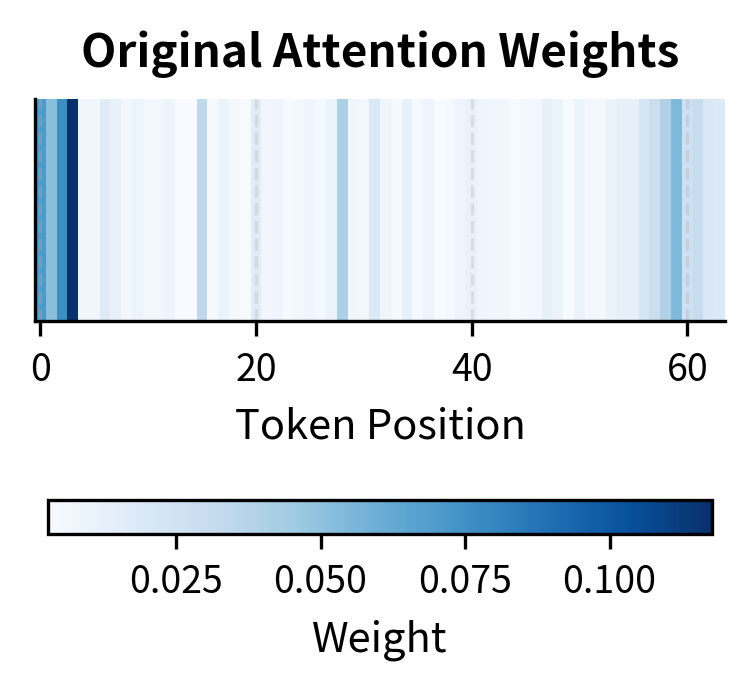
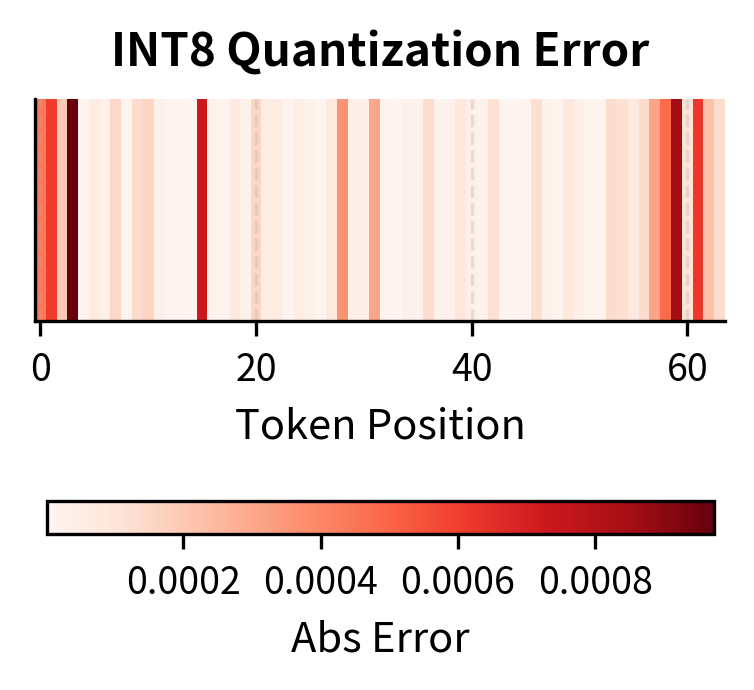
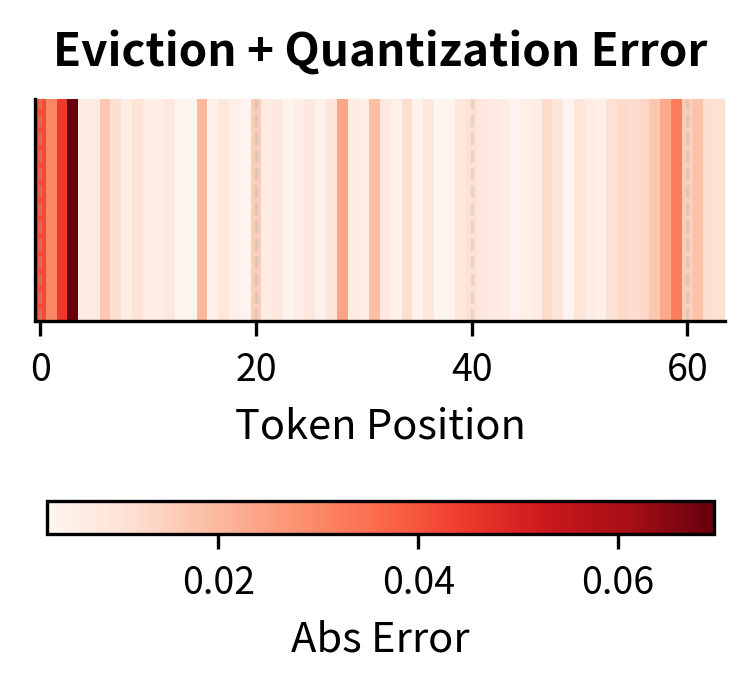
The visualization reveals the distinct error profiles of each compression technique, illustrating a fundamental difference in how they affect the attention computation. Quantization introduces small, distributed errors across all positions, preserving the overall attention pattern while adding noise uniformly. The relative importance of tokens remains intact, and the model can still attend to the information it needs, albeit with slight imprecision.
Eviction, by contrast, creates complete information loss for removed tokens. The error is not small and distributed but rather binary: retained tokens have zero error while evicted tokens have error equal to their original attention weight. The key to successful eviction is ensuring that evicted tokens would have received near-zero attention anyway. When this condition holds, the total attention error is minimal because we are only losing tokens that contributed negligibly. When eviction removes a token that the model would have attended to significantly, generation quality suffers because that information is permanently lost.
The H2O algorithm's tracking of cumulative attention helps identify which tokens can be safely removed by providing evidence of their historical importance. Tokens that have consistently received minimal attention are unlikely to suddenly become critical, making them safe eviction candidates. However, this heuristic is not perfect: a token that received little attention during the first 500 generation steps might become crucial at step 501 if the generated content shifts to reference that earlier context.
Limitations and Practical Considerations
KV cache compression involves fundamental trade-offs that you must understand. The most significant limitation is task sensitivity: some tasks are highly sensitive to long-range dependencies that may be evicted or distorted by compression. Summarization, question answering over long documents, and multi-hop reasoning can degrade significantly when important context is removed.
Eviction strategies face the challenge of predicting future importance from past attention. A token that received little attention during the first 500 generation steps might become crucial at step 501, but if it was evicted, that information is permanently lost. This is particularly problematic for tasks where relevance depends on the specific query or generated content. Heavy hitter detection helps, but cannot anticipate all future needs.
Quantization interacts with numerical precision in subtle ways. While INT8 typically works well, INT4 can cause issues for models that rely on precise attention scores. Grouped query attention and multi-query attention, as we covered in Part XIX, already reduce KV cache memory. Combining these architectural choices with aggressive quantization requires careful validation. The upcoming chapters on weight quantization will explore similar precision trade-offs in more depth.
Cache compression also complicates batched inference. Different sequences in a batch may have different important tokens, requiring either per-sequence eviction decisions (complex) or a union of important tokens across sequences (less aggressive compression). PagedAttention, covered in the previous chapter, handles this elegantly by allowing non-contiguous cache storage, but the combination with dynamic eviction adds implementation complexity.
Finally, the computational overhead of compression must be considered. Tracking cumulative attention scores, identifying heavy hitters, and performing quantization all consume compute and memory bandwidth. For latency-sensitive applications, the overhead may offset memory savings. Simple approaches like StreamingLLM's sink plus window strategy often provide the best latency-memory trade-off because they require no attention tracking.
Key Parameters
The key parameters for KV cache compression are:
- sink_size: Number of initial tokens to always preserve in the cache. These "attention sinks" are critical for stability.
- window_size (or recent_size): Number of most recent tokens to keep. Ensures local context is available.
- heavy_hitter_size: Number of high-attention tokens to preserve based on historical importance.
- bits: Target bit width for quantization (e.g., 4 or 8). Lower bits save more memory but may increase error.
Summary
KV cache compression addresses the memory bottleneck of long-sequence generation through two complementary approaches: reducing the number of cached tokens through eviction, and reducing the precision of stored values through quantization.
Window-based eviction provides the simplest implementation but sacrifices all long-range context. Attention sink preservation recognizes that initial tokens serve as computational anchors and must be protected from eviction. The H2O algorithm extends this by tracking cumulative attention to identify and preserve "heavy hitter" tokens that consistently receive high attention, balancing recency with historical importance.
Cache quantization offers orthogonal memory savings. INT8 quantization typically achieves 2x compression with negligible quality impact. INT4 provides 4x compression but requires per-channel quantization and careful validation. Combining eviction with quantization can achieve compression ratios exceeding 30x for long sequences.
The choice of compression strategy depends on the specific use case. Tasks requiring precise long-range reasoning may tolerate only light compression, while streaming applications or tasks with primarily local dependencies can use aggressive compression. Understanding these trade-offs enables you to select appropriate configurations that balance memory efficiency with generation quality.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about KV cache compression techniques.

Comments