

Mathematical equivalence between confidence intervals and hypothesis tests, test assumptions (independence, normality, equal variances), and choosing between z and t tests. Learn how to validate assumptions and select appropriate tests.

This article is part of the free-to-read Machine Learning from Scratch
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Confidence Intervals and Test Assumptions
In the previous chapter, we established the foundations of hypothesis testing: p-values, null and alternative hypotheses, and test statistics. Now we explore two complementary concepts that complete your understanding of statistical inference.
First, we'll discover that confidence intervals and hypothesis tests are mathematically equivalent. They're not two different methods for analyzing data; they're two perspectives on the same underlying calculation. Understanding this equivalence transforms how you interpret both tools.
Second, we'll examine the assumptions that make statistical tests work. Every test rests on mathematical assumptions, and when these assumptions are violated, tests can mislead you. Knowing what assumptions matter, when they matter, and what to do when they fail is essential for responsible data analysis.
Confidence Intervals: A Deeper Look
You've probably seen confidence intervals before: "The average treatment effect was 5.2 with a 95% confidence interval of [3.1, 7.3]." But what does this actually mean, and how does it connect to hypothesis testing?
What a Confidence Interval Really Means
A 95% confidence interval does NOT mean there's a 95% probability that the true parameter lies within the interval. The true parameter is fixed (though unknown). It's either inside the interval or it isn't. There's no probability involved once you've computed the interval.
A 95% confidence interval means: if we repeated our sampling procedure many times and computed a confidence interval each time, 95% of those intervals would contain the true parameter value.
This is a subtle but important distinction. The confidence refers to the procedure, not to any particular interval. Over many repetitions, 95% of the intervals produced by this method will capture the true value.
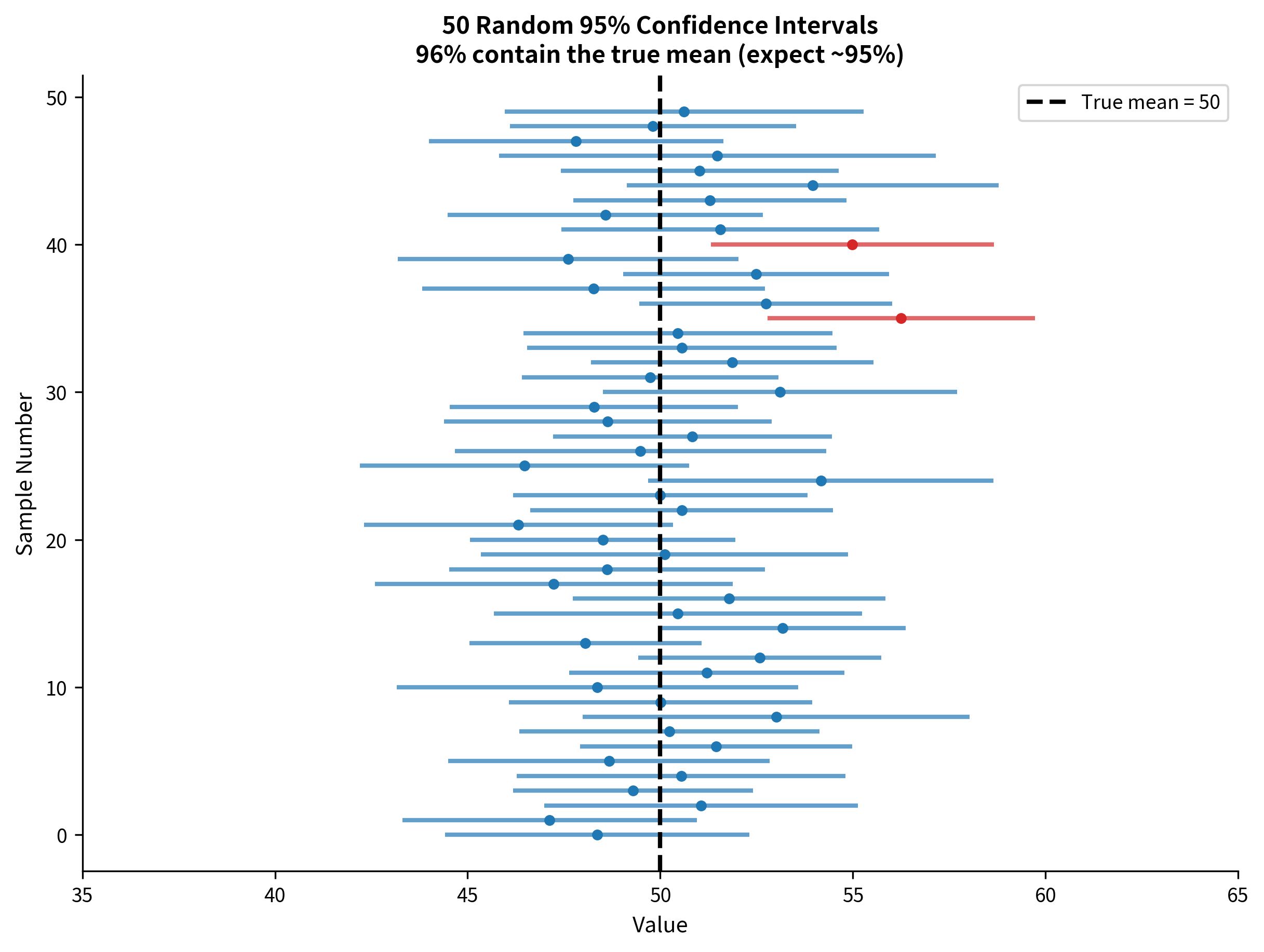
Constructing a Confidence Interval Step by Step
Let's build a confidence interval from first principles. Suppose you have a sample of n observations and want a confidence interval for the population mean.
Step 1: Calculate the sample mean
Step 2: Calculate the standard error
The standard error measures how much the sample mean varies from sample to sample. If you know the population standard deviation :
If you don't know (the usual case), estimate it with the sample standard deviation:
Step 3: Find the critical value
For a 95% confidence interval (), you need the value that cuts off 2.5% in each tail of the distribution.
If you know , use the z critical value:
If you're estimating with , use the t critical value with degrees of freedom:
Step 4: Construct the interval
The Remarkable Equivalence
Here's the key insight that connects confidence intervals to hypothesis testing: a 95% confidence interval contains exactly those parameter values that would NOT be rejected by a two-sided hypothesis test at the 0.05 significance level.
Why the Equivalence Holds
Let's prove this algebraically. Consider testing versus at significance level .
We reject when the test statistic exceeds the critical value:
Rearranging this inequality:
The last line says: we reject when falls outside the interval .
But this interval is exactly the 95% confidence interval! So:
- inside the CI hypothesis test fails to reject
- outside the CI hypothesis test rejects
The confidence interval is the set of all parameter values that would not be rejected as null hypotheses.
Visualizing the Equivalence
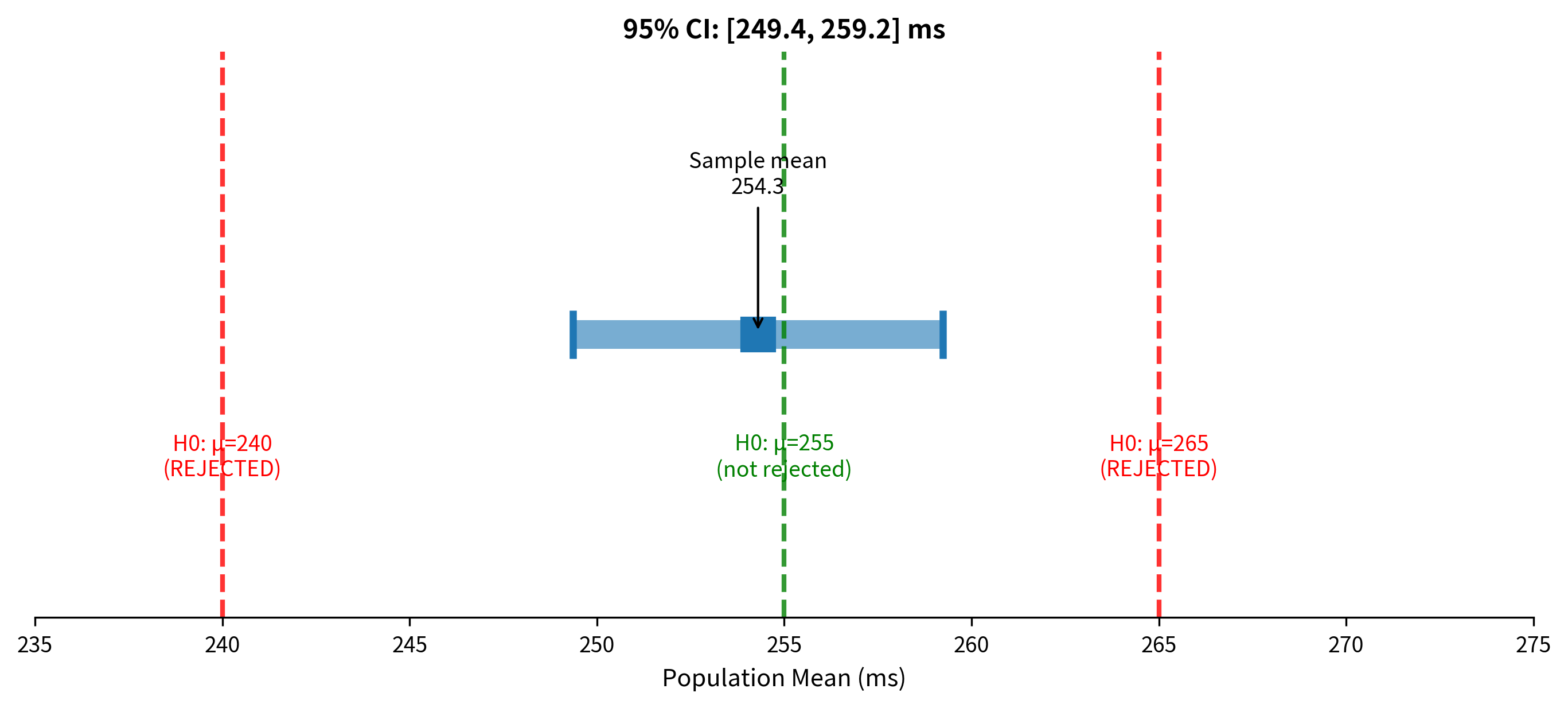
Why This Matters Practically
This equivalence has important practical implications:
-
Confidence intervals are more informative than p-values. A p-value tells you whether one specific null hypothesis is rejected. A confidence interval tells you which values would be rejected and which wouldn't. It's like the difference between asking "Is the speed limit 65 mph?" versus "What range of speed limits are consistent with my speedometer reading?"
-
You can read significance from a CI. If a 95% CI for a difference doesn't include zero, the difference is significant at the 0.05 level. If the CI for a ratio doesn't include 1, the ratio is significant. You don't need to compute a separate test.
-
CIs convey precision. A CI of [0.1, 0.3] and a CI of [-2, 5] might both exclude zero (both "significant"), but the first shows you know the effect is small and positive, while the second shows you barely know anything at all.
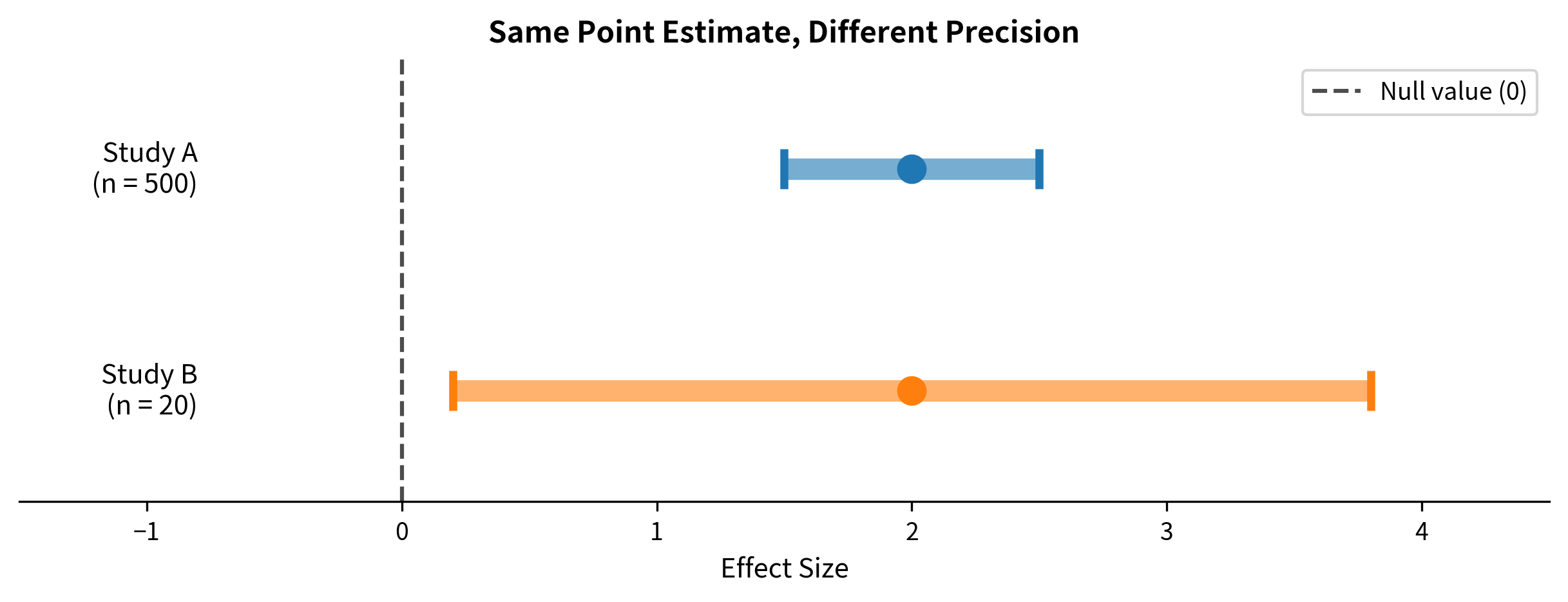
Test Assumptions: The Foundation of Valid Inference
Every statistical test is built on assumptions. When these assumptions hold, the test does what it claims: it controls the Type I error rate at the specified level and has known power properties. When assumptions are violated, these guarantees may break down.
Understanding assumptions isn't about rigidly checking boxes. It's about understanding when violations matter, when they don't, and what alternatives exist.
Assumption 1: Independence
Independence is the most important assumption and the one most commonly violated without recognition.
What independence means: Each observation provides unique information. The value of one observation doesn't tell you anything about another observation's value.
Why it matters: Statistical tests calculate standard errors assuming each observation contributes independent information. When observations are correlated, the effective sample size is smaller than the actual sample size. The test "thinks" it has more information than it does, leading to standard errors that are too small, test statistics that are too large, and p-values that are too small.
Common violations:
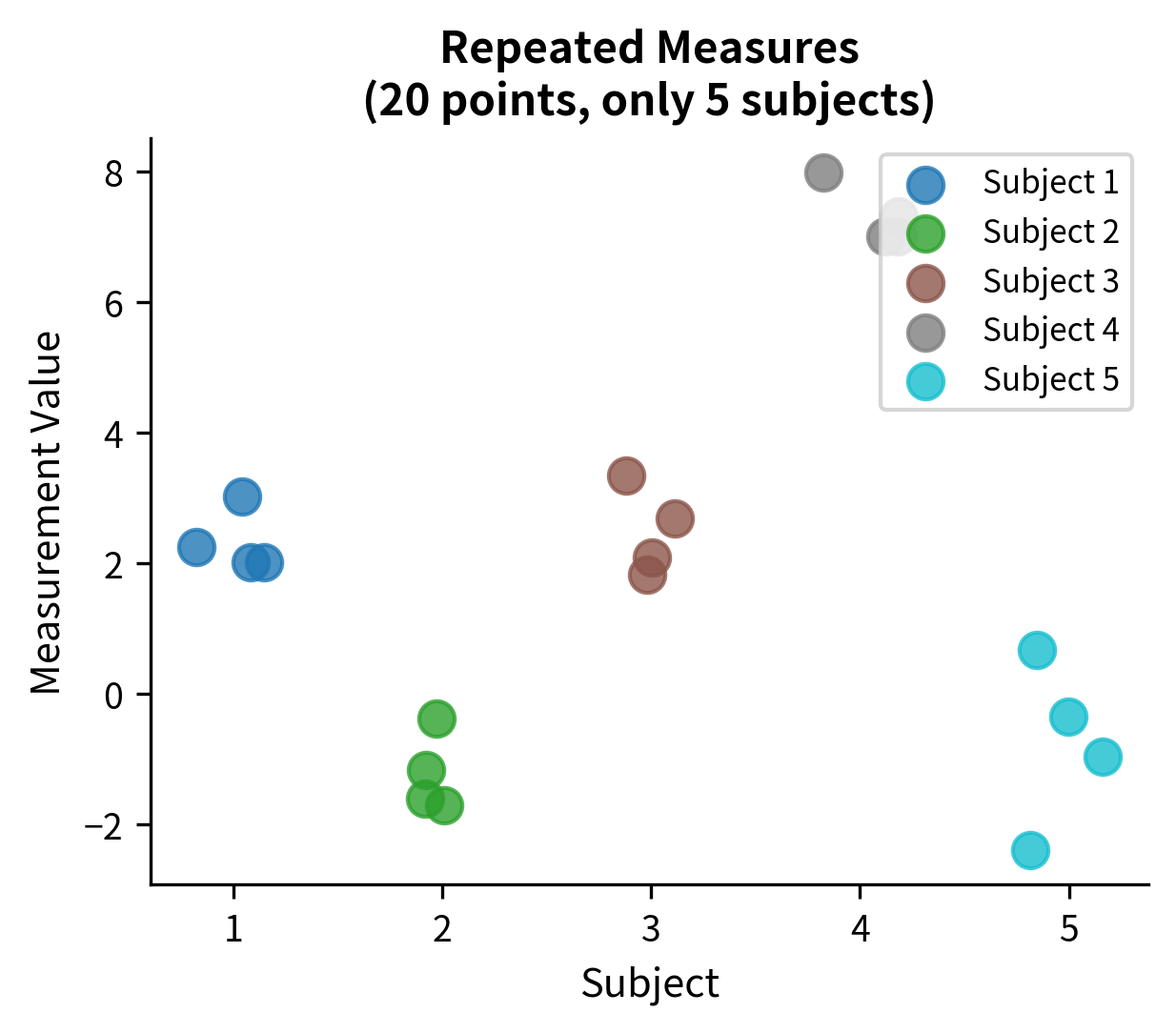
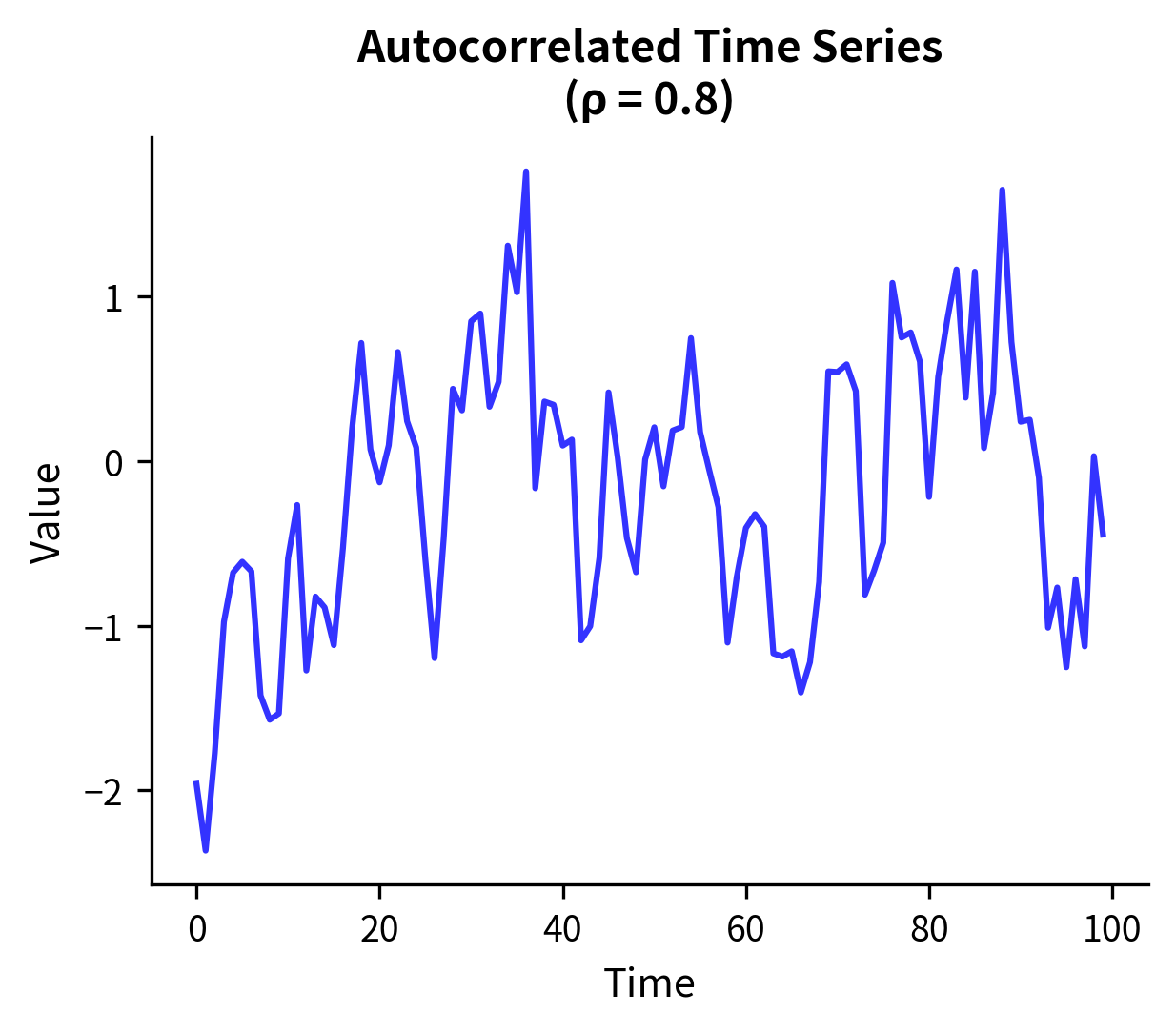
The consequences: If you analyze repeated measures as if they were independent, your standard errors will be too small (often dramatically so), your p-values will be too small, and you'll make many more false positive claims than you think. A study that appears to have n=100 might effectively have n=10 if each of 10 subjects contributes 10 correlated measurements.
Solutions: Use methods designed for your data structure:
- Repeated measures: paired t-tests, repeated measures ANOVA, mixed-effects models
- Clustered data: cluster-robust standard errors, mixed-effects models
- Time series: ARIMA models, autocorrelation-corrected standard errors
Assumption 2: Normality
Many tests assume the data (or the sampling distribution of a statistic) is normally distributed.
What normality means: The t-test and z-test assume that the sampling distribution of the mean is normal. For small samples, this requires the population itself to be approximately normal. For large samples, the Central Limit Theorem saves us.
The Central Limit Theorem: This remarkable theorem states that the sampling distribution of the mean approaches normality as sample size increases, regardless of the population distribution. This is why t-tests work even when individual observations aren't normal.
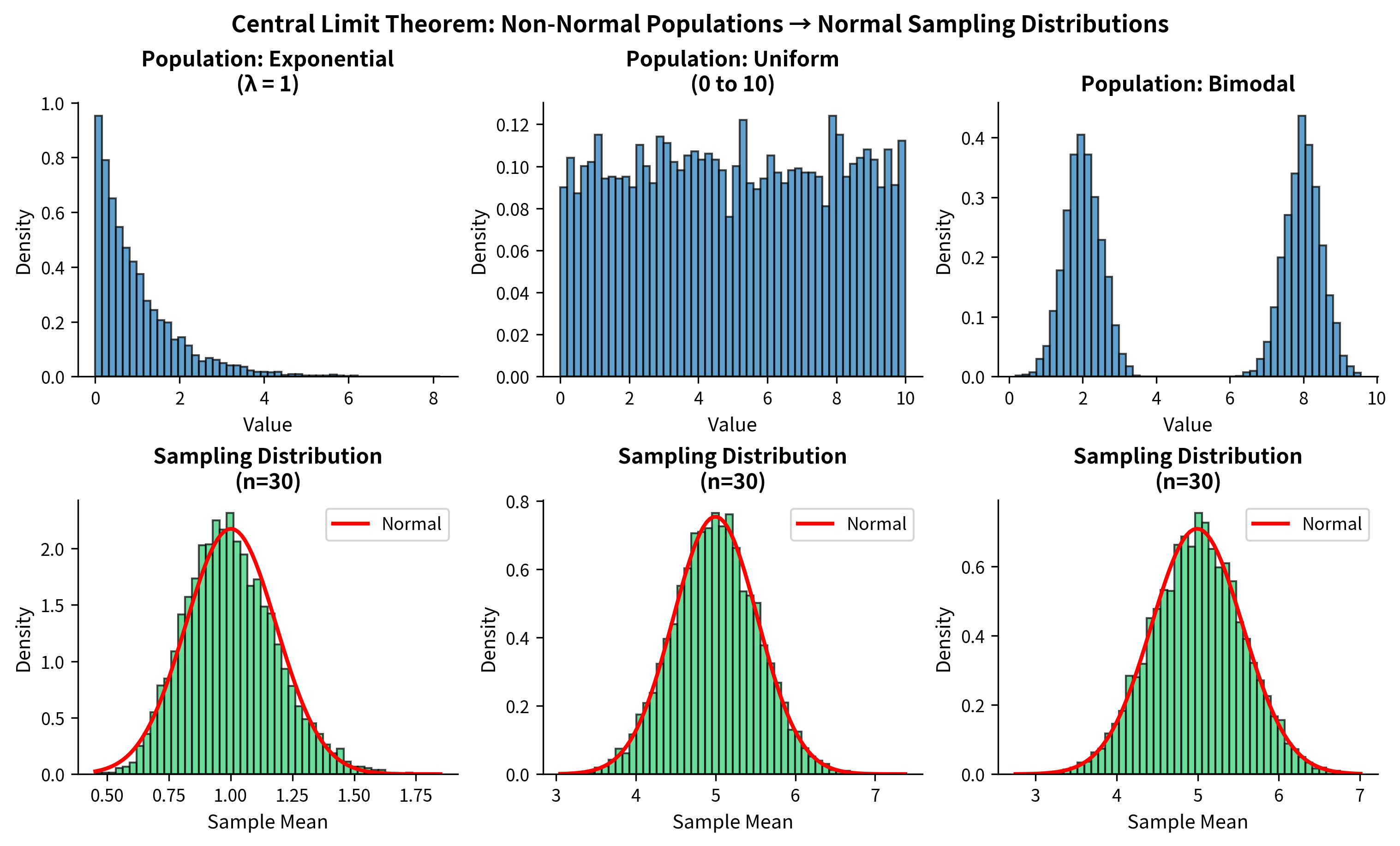
How fast does the CLT work? It depends on the population distribution:
| Population Distribution | Sample Size Needed for Approximate Normality |
|---|---|
| Already normal | Any n works |
| Symmetric, light tails | n ≥ 10 usually sufficient |
| Moderately skewed | n ≥ 30 is a common guideline |
| Heavily skewed | n ≥ 50 to 100 may be needed |
| Very heavy tails | n ≥ 100+ may be needed |
When normality matters most: For small samples (n < 20 or so), the shape of the population distribution affects test validity. Severe skewness or outliers can inflate or deflate Type I error rates.
Checking normality: Use histograms and Q-Q plots to visually assess normality. Q-Q plots compare your data quantiles to theoretical normal quantiles. Points should fall roughly on a straight line if the data are normal.
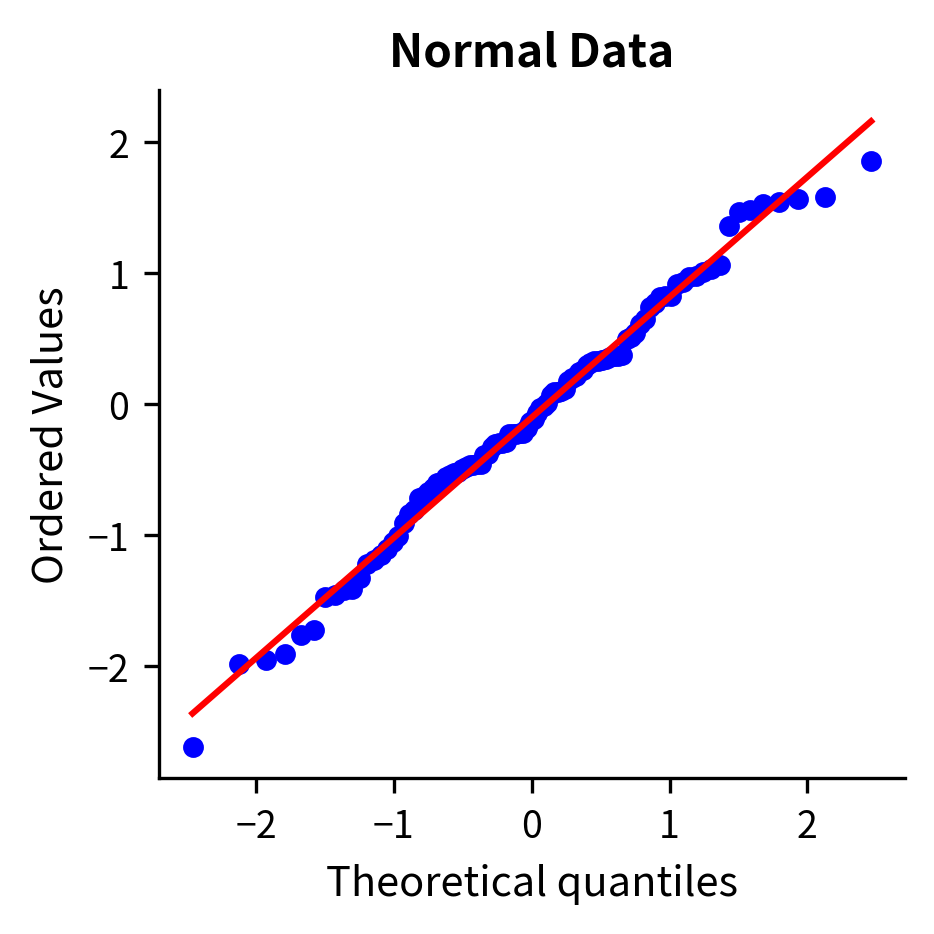
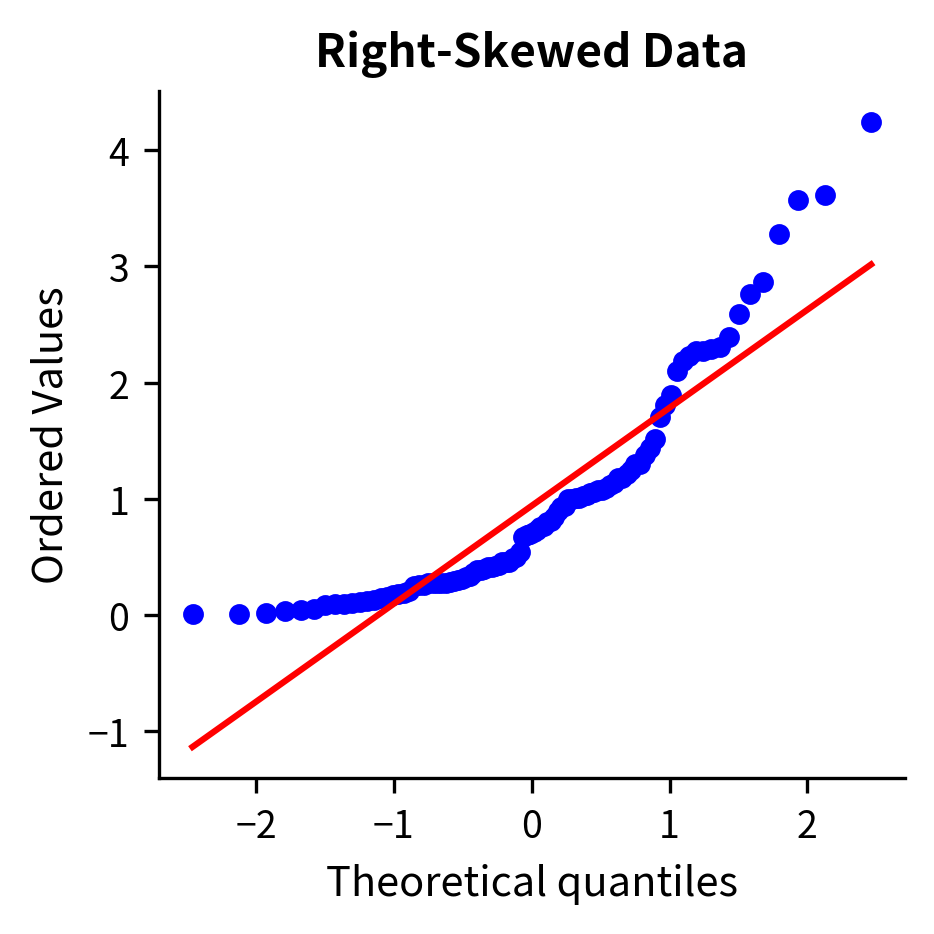
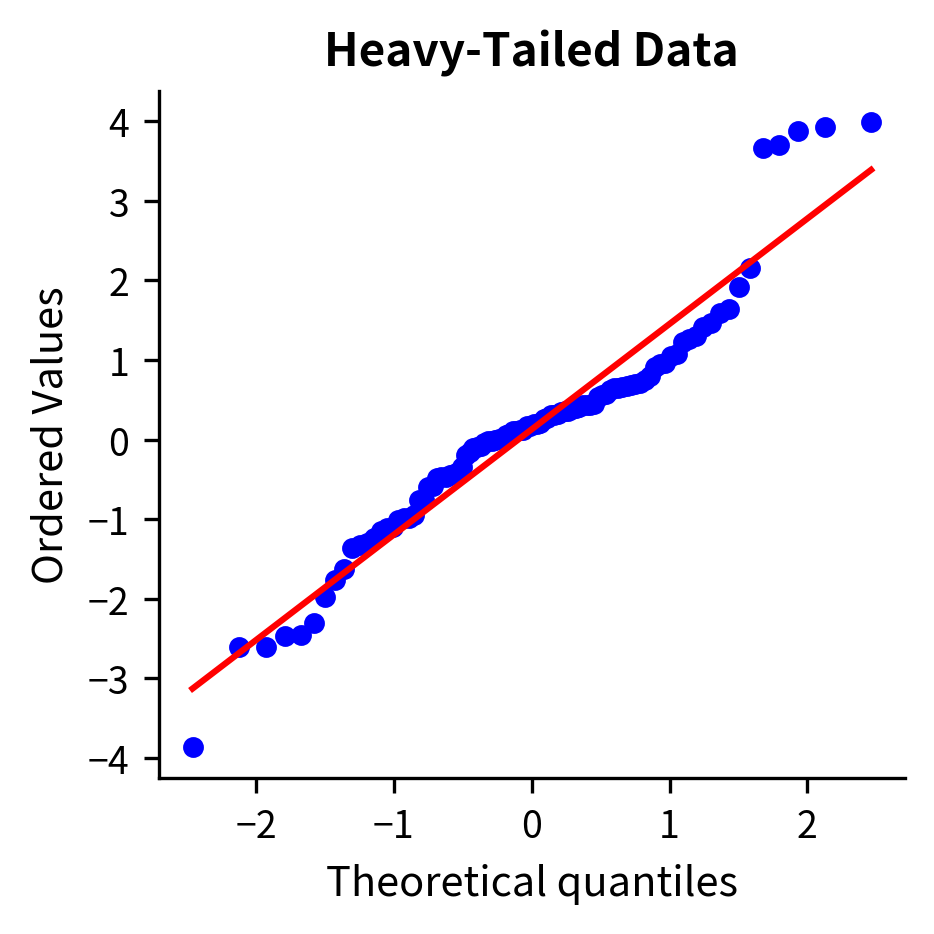
Assumption 3: Equal Variances (Homoscedasticity)
Two-sample t-tests can assume equal variances in both groups (pooled t-test) or allow unequal variances (Welch's t-test).
Why equal variances matter for the pooled test: The pooled t-test combines variance estimates from both groups to get a single "pooled" variance:
This pooling is only valid if both groups truly have the same variance. When variances differ, the pooled estimate doesn't accurately represent either group.
What happens when variances differ: The consequences depend on the relationship between variance and sample size:
- If the group with larger variance has smaller n: Type I error is inflated (you reject too often)
- If the group with larger variance has larger n: Type I error is deflated (you reject too rarely)
- If sample sizes are equal: Effects are minimal
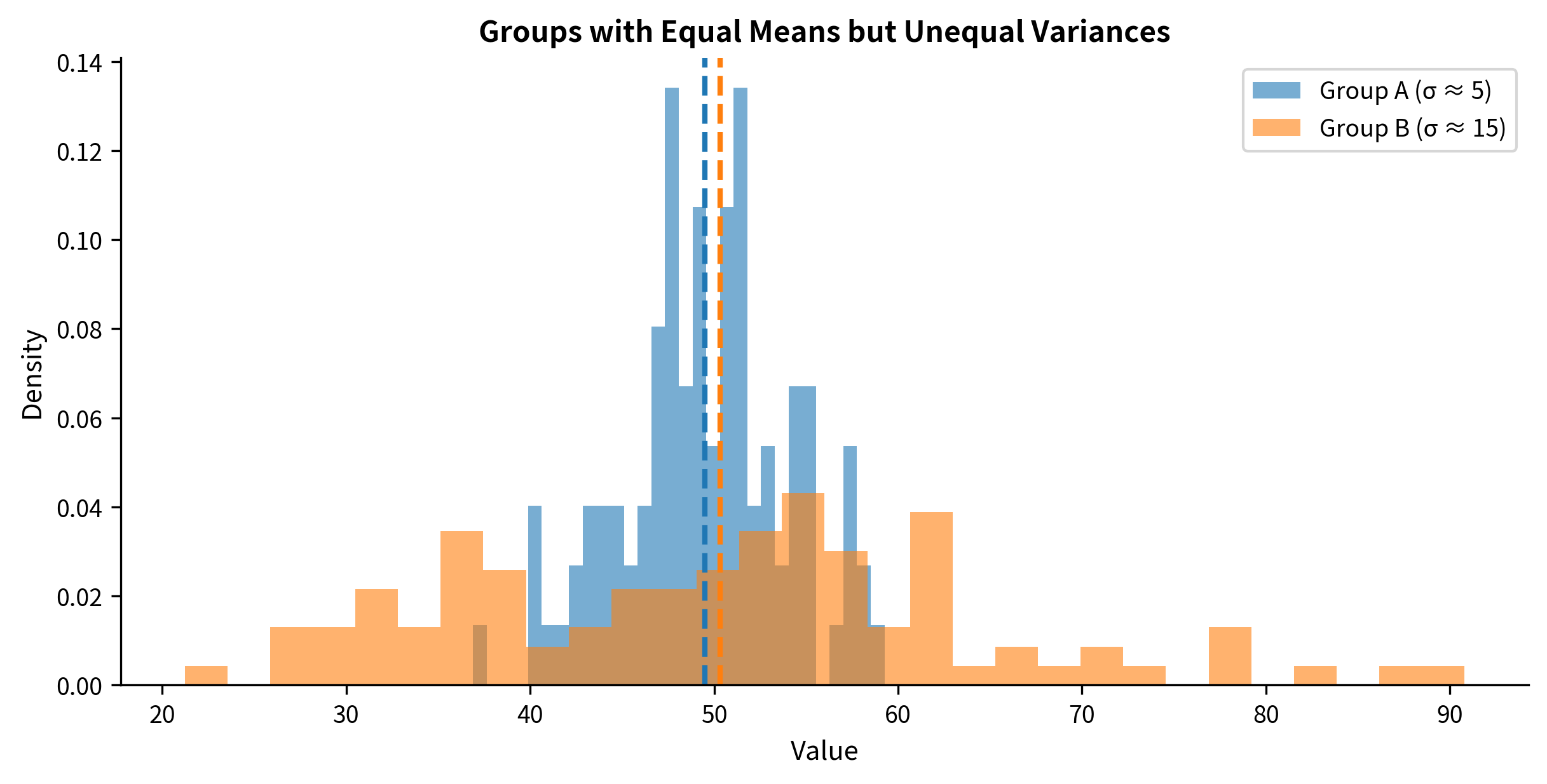
The solution: Welch's t-test: Welch's t-test doesn't assume equal variances. It calculates standard errors separately for each group and uses a modified degrees of freedom (the Welch-Satterthwaite approximation).
The key insight is that Welch's test is nearly as powerful as the pooled test when variances ARE equal, but much more accurate when they're not. This asymmetry makes Welch's test the recommended default.
Choosing Between Z-Tests and T-Tests
The choice between z-tests and t-tests depends on whether you know the population standard deviation.
The Z-Test: Known Variance
The z-test assumes you know the population standard deviation :
Under , this follows a standard normal distribution .
When do you actually know ? Rarely. Possible scenarios include:
- Measurement instruments with known precision from extensive calibration
- Standardized tests with established population parameters
- Very large historical datasets that effectively reveal the population
The T-Test: Unknown Variance
The t-test estimates from the sample using :
Under , this follows a t-distribution with degrees of freedom.
Why the t-distribution? When you estimate with , you introduce additional uncertainty. The sample standard deviation is itself a random variable. The t-distribution has heavier tails than the normal to account for this uncertainty.
The T-Distribution: Heavy Tails for Small Samples
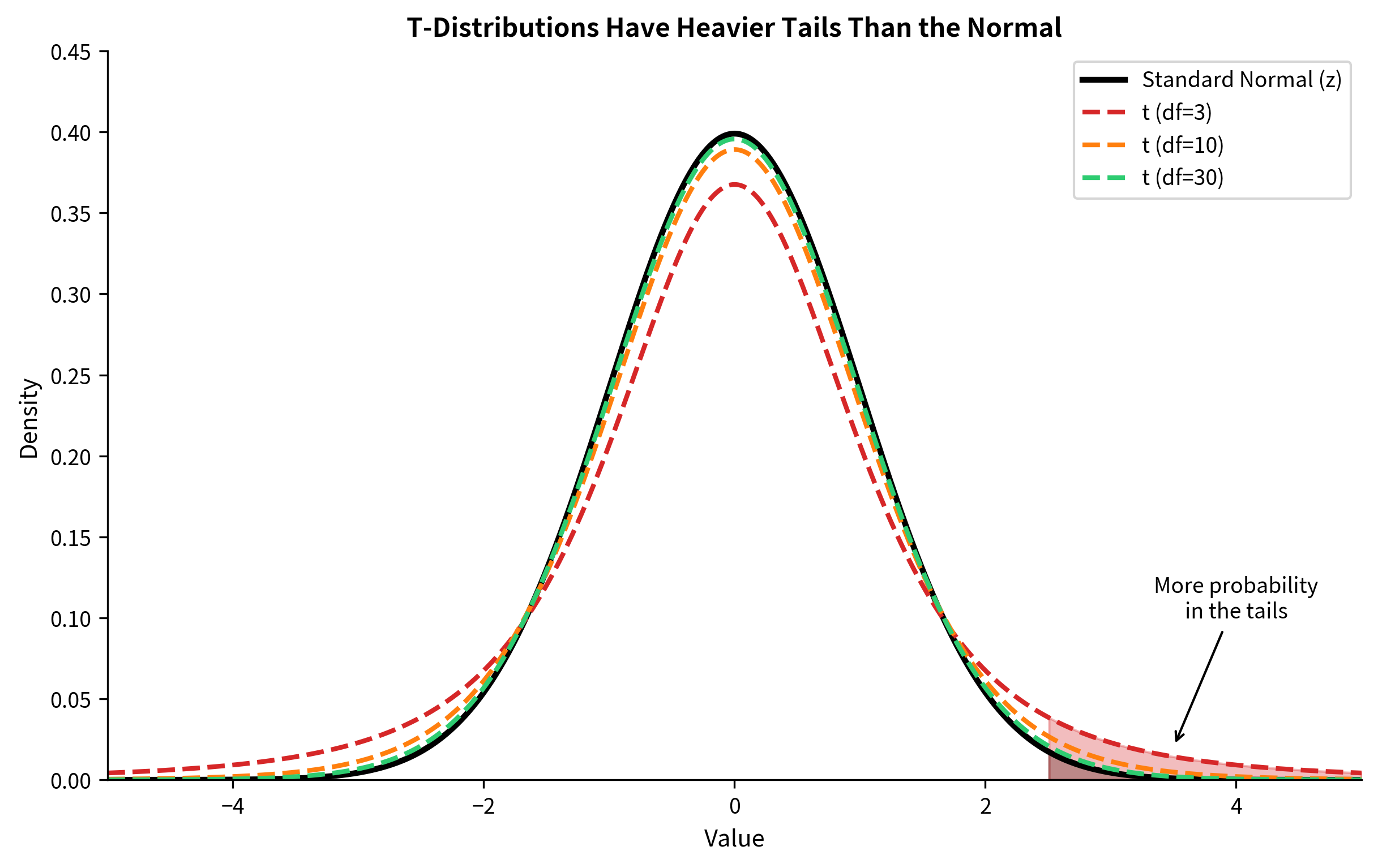
The practical consequence: t-tests give larger p-values (and wider confidence intervals) than z-tests for the same data. This is appropriate because we're less certain when we don't know .
| Degrees of Freedom | t Critical Value (95% CI) | Compared to z = 1.96 |
|---|---|---|
| 5 | 2.571 | 31% larger |
| 10 | 2.228 | 14% larger |
| 20 | 2.086 | 6% larger |
| 30 | 2.042 | 4% larger |
| 100 | 1.984 | 1% larger |
| ∞ | 1.960 | Same as z |
For practical purposes, with n > 30, the difference between t and z is usually negligible. But always use the t-test when is unknown. There's no benefit to using z when you don't actually know , and it can inflate your Type I error rate for small samples.
Welch's T-Test: The Robust Default
When comparing two independent groups, Welch's t-test should be your default choice.
The Pooled vs Welch Comparison
Pooled (Student's) t-test assumes equal variances:
Welch's t-test allows unequal variances:
The degrees of freedom for Welch's test are calculated using the Welch-Satterthwaite formula:
This formula typically gives a non-integer value for degrees of freedom.
When to Use Which
| Condition | Recommended Test | Reason |
|---|---|---|
| Variances clearly equal | Either works | Pooled slightly more powerful |
| Variances uncertain | Welch's | Robust to violation |
| Variances clearly unequal | Welch's | Pooled will be biased |
| Default choice | Welch's | Minimal cost, high robustness |
In this example, Treatment B has more than twice the variance of Treatment A. The Welch's t-test correctly accounts for this, while the pooled test uses an inappropriate compromise variance estimate.
Summary
This chapter covered two essential complementary topics:
Confidence Intervals and Their Equivalence to Hypothesis Tests
- A 95% CI contains all parameter values that would not be rejected at the 0.05 level
- CIs are more informative than p-values because they show the range of plausible values
- CI width communicates precision: narrow intervals indicate precise estimates
Test Assumptions
- Independence: The most important assumption. Violations lead to inflated Type I errors.
- Normality: The CLT makes this less critical for large samples (n > 30), but small samples require caution
- Equal variances: Use Welch's t-test as your default for two-sample comparisons
Choosing Between Tests
- Use t-tests when is unknown (almost always)
- Use Welch's t-test as the default for two-sample comparisons
- The z-test is appropriate only when you genuinely know from prior information
What's Next
In the next chapter, The Z-Test, we'll explore z-tests in depth: one-sample tests, two-sample tests, and tests for proportions. You'll learn when the z-test is appropriate and how to apply it correctly.
Subsequent chapters cover the t-test (the workhorse of hypothesis testing), the F-test for comparing variances, ANOVA for comparing multiple groups, Type I and Type II errors, power analysis, effect sizes, and multiple comparison corrections. Each chapter builds on the foundations established here.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about confidence intervals and test assumptions.

Comments