

Learn how instruction tuning transforms base language models into helpful assistants. Explore format design, data diversity, and quality principles.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Instruction Following
Imagine you've just finished pre-training a large language model on trillions of tokens from the internet. The model can complete sentences, generate coherent text, and even demonstrate surprising capabilities like answering questions when prompted correctly. But when you ask it to "Summarize this article in three bullet points," it continues writing more of the article instead. When you request "Translate the following sentence to French," it sometimes translates and sometimes just keeps generating English. The model has learned language, but it hasn't learned to follow instructions.
This gap between language modeling capability and practical utility motivated one of the most important developments in modern LLMs: instruction tuning. As we explored in Part XVIII with GPT-3's in-context learning, pre-trained models can perform tasks when given the right examples in their context. But this requires careful prompt engineering, wastes context space on demonstrations, and fails unpredictably on novel phrasings. Instruction tuning offers a different approach: teaching models to understand and execute your requests directly, without requiring examples at inference time.
This chapter introduces the motivation behind instruction tuning, explores how to design effective instruction formats, examines why diversity in training data matters for generalization, and discusses what distinguishes high-quality instruction data from noise. Understanding these foundations prepares you for the subsequent chapters on data creation, training procedures, and evaluation methods.
The Pre-training Gap
Pre-trained language models like those we studied in Parts XVI through XX excel at one specific task: predicting the next token given a context. During causal language modeling, the model learns to assign high probability to continuations that match the statistical patterns in its training data. This training paradigm produces models with remarkable capabilities, but it creates a fundamental mismatch with how humans want to use these systems. The core issue is that predicting likely continuations and following your instructions are fundamentally different objectives, even though they both involve generating text.
Consider what happens when you prompt a base GPT-style model with "Write a poem about autumn leaves." The model doesn't interpret this as a request requiring action. Instead, it treats the text as a prefix to be continued in the most likely way given its training distribution. The model asks itself, in effect, what text would most plausibly follow these words based on everything it learned during pre-training. Depending on what similar text appeared in pre-training, it might:
- Complete the sentence: "Write a poem about autumn leaves falling gently..."
- Generate a meta-discussion: "Write a poem about autumn leaves. This is a common creative writing prompt..."
- Produce the poem directly if similar instructional content appeared frequently in training
This unpredictability stems from the fact that the pre-training objective optimizes for continuation probability, not instruction compliance. The model has no explicit training signal that says "when text looks like a request, generate a response that fulfills that request." From the model's perspective, there is no meaningful distinction between your instruction and any other piece of text. Everything is simply context to be continued. This fundamental design characteristic explains why base models, despite their impressive language understanding, often fail to behave as useful assistants.
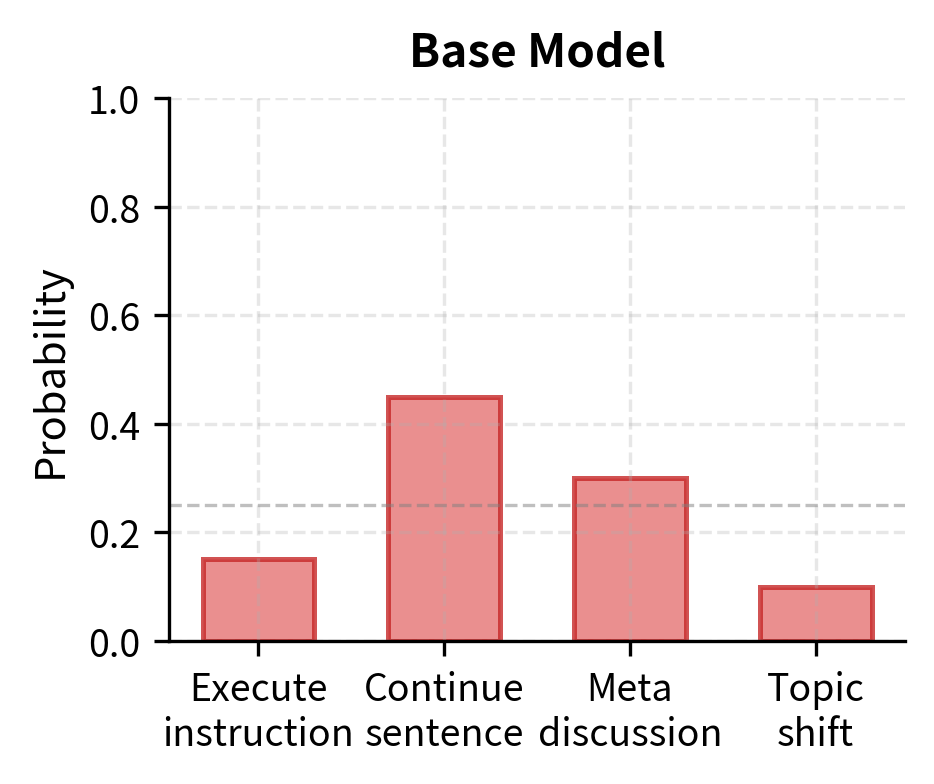
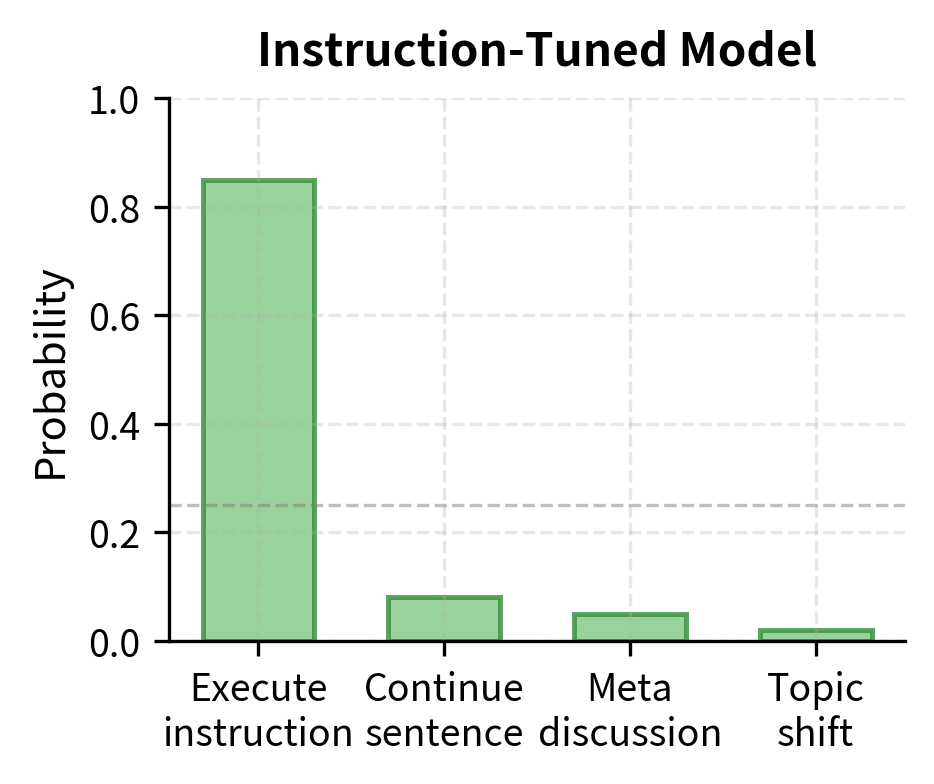
A base model (or foundation model) is trained only on the language modeling objective, learning to predict the next token. An instruction-tuned model receives additional training specifically on instruction-response pairs, teaching it to interpret and follow your requests. The base model knows how to generate plausible text; the instruction-tuned model knows how to generate text that specifically addresses what you asked for.
The Format Problem
Beyond the objective mismatch, base models don't understand conversational conventions. When you interact with an assistant, there's an implicit structure: you provide a request, and the assistant responds. This turn-taking pattern requires the model to know when to stop generating (it has produced a complete response) and what role it should adopt (helpful assistant rather than document author). These conventions, which humans learn through years of social interaction, must be explicitly taught to language models.
Base models trained on web text have seen conversations, but they've also seen novels, code, advertisements, forum threads, and countless other formats. Without additional training, the model cannot reliably distinguish "this is an instruction I should execute" from "this is text I should continue in its style." A base model might generate a response to your question, or it might generate more questions, or it might continue as if writing a FAQ document, or it might shift into a completely different register. The model simply doesn't have a consistent understanding of its role in the interaction.
The Instruction Tuning Insight
The key insight behind instruction tuning is deceptively simple: if you want models to follow instructions, train them on examples of instructions being followed. By fine-tuning a pre-trained model on a dataset of (instruction, response) pairs, you explicitly teach it the behavior you want. Rather than hoping the model infers the correct behavior from ambiguous pre-training data, you directly demonstrate what good instruction-following looks like.
This approach was pioneered by several research efforts in 2021-2022, including Google's FLAN (Fine-tuned LAnguage Net), OpenAI's InstructGPT, and various academic projects. Despite using relatively small amounts of instruction data compared to pre-training corpora (thousands to millions of examples versus trillions of tokens), instruction tuning produces dramatic improvements in model usability. Models go from being powerful but unpredictable text generators to being cooperative assistants that understand and respond to your needs.
The effectiveness of instruction tuning reveals something important about large pre-trained models: they already possess the underlying capabilities needed to follow instructions. Pre-training gives models broad knowledge about language, facts, and reasoning patterns. Instruction tuning doesn't teach new capabilities so much as it teaches models to activate existing capabilities in response to your requests. Think of it like this: a pre-trained model is like a highly skilled professional who doesn't know they're supposed to be helping you. Instruction tuning teaches them to recognize when they're being asked to do something and to respond accordingly.
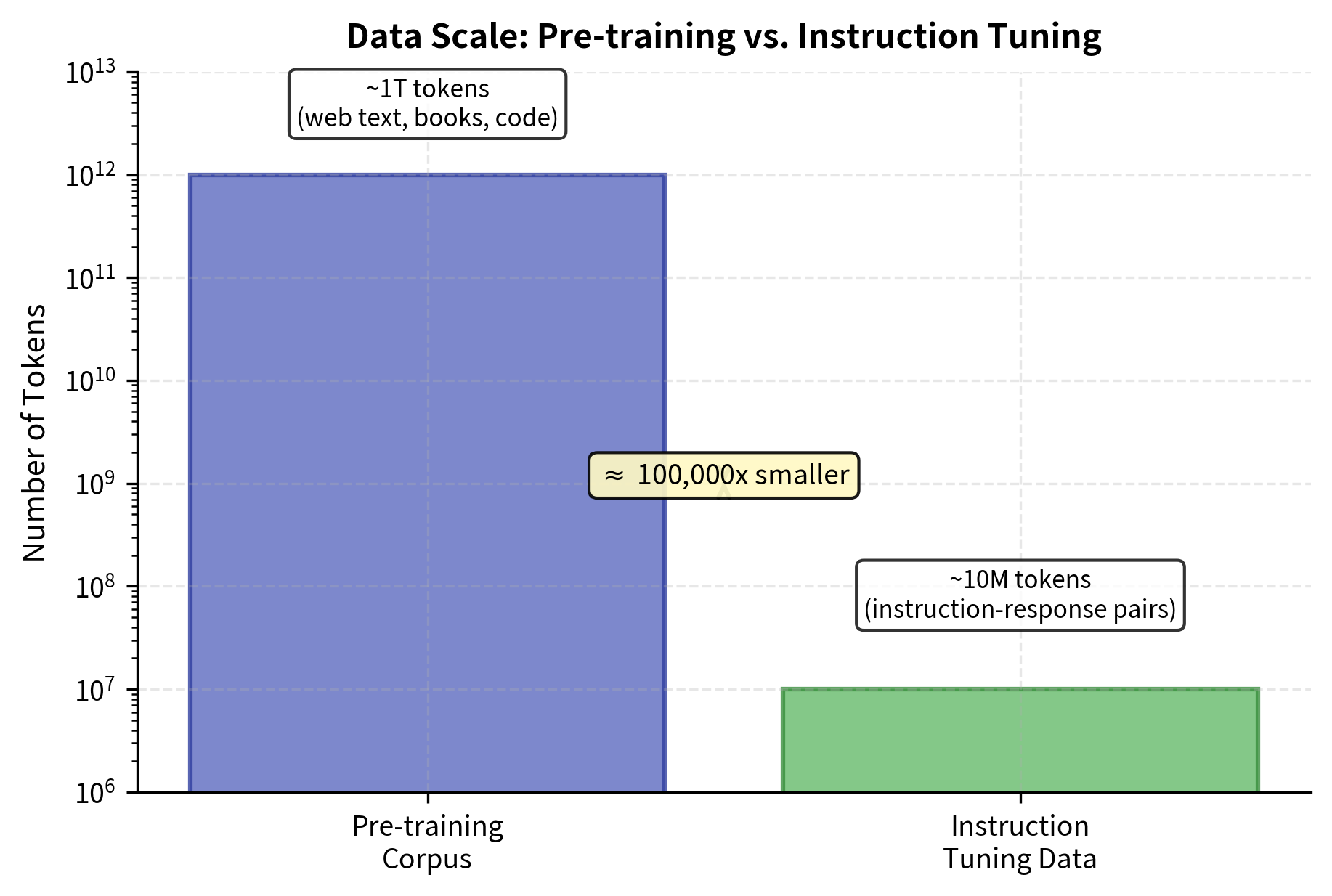
Why Small Datasets Work
Given the scale of pre-training (hundreds of billions to trillions of tokens), it might seem surprising that instruction tuning works with datasets that are orders of magnitude smaller. Several factors explain this efficiency, and understanding them illuminates why instruction tuning is so effective:
Capability already exists. The model has already learned to summarize, translate, answer questions, and perform other tasks during pre-training. It encountered examples of summaries, translations, and question-answer pairs throughout the web data it was trained on. What it lacks is the understanding that when you present an instruction, it should deploy these existing capabilities. Instruction tuning provides this missing link, teaching the model to recognize and respond to requests.
Format is learnable. The instruction-following format (receive request, generate response, stop) is a relatively simple pattern compared to the full complexity of language. Unlike learning grammar, world knowledge, or reasoning, which requires exposure to vast amounts of text, learning to recognize and respond to instructions is a much more constrained problem. Models can learn this convention quickly because it's fundamentally a formatting task rather than a capability-building task.
Transfer across instructions. Training on "summarize this article" helps the model understand "condense this text" and "give me the main points" even without explicit examples. The model generalizes from the specific examples it sees to the broader concept of summarization requests. This transfer effect multiplies the value of each training example, as one example can inform the model's behavior across many related phrasings and variations.
Alignment with generation. Following instructions aligns with the model's core capability: generating text. The model simply learns to generate the kind of text that represents a helpful response to the given instruction. Unlike training objectives that require the model to perform fundamentally new operations, instruction tuning asks the model to do what it already does (generate text) but with a different intent (fulfill your requests rather than continue documents).
Instruction Format Design
Creating effective instruction-tuning data requires careful attention to format. The structure of training examples teaches models what inputs to expect and what outputs to produce. A well-designed format makes the distinction between instruction, input, and response crystal clear, helping the model learn the appropriate boundaries and behaviors. Several components define an instruction format, and each plays a crucial role in the training signal.
Instruction Component
The instruction component tells the model what to do. This is the core directive that specifies the task the model should perform. Effective instructions are clear, specific, and actionable:
- Clear: "Translate the following English sentence to Spanish" leaves no ambiguity about the task. The model knows exactly what language pair to work with and what direction the translation should go.
- Specific: "Summarize in exactly three sentences" provides concrete constraints that guide the model's output. Without such specificity, the model must guess at the appropriate length and format.
- Actionable: The instruction describes something the model can actually generate as text output. Instructions like "feel happy about this text" aren't actionable because they don't translate into specific textual output.
Instructions can range from single-word commands ("Translate:") to detailed multi-sentence specifications explaining exactly what output is expected. The level of detail often depends on the task complexity and the desired output format. Simple tasks may need only brief instructions, while complex tasks benefit from more elaborate specifications that reduce ambiguity and set clear expectations.
Input Component
Many instructions operate on provided content. The input component contains the material the model should process, serving as the raw data that the instruction acts upon:
Some instructions don't require separate input (e.g., "Write a haiku about spring") while others are meaningless without it (e.g., "Translate the following sentence"). The format must clearly distinguish the instruction from the input to prevent confusion. Without clear separation, the model might incorporate parts of the instruction into its understanding of the input, or vice versa, leading to incorrect responses.
Output Component
The output (or response) component contains the desired model behavior. During training, this is the target text the model learns to generate. The output should directly address the instruction and, where applicable, properly process the input. This component serves as the ground truth that the model optimizes toward during training.
Quality outputs exhibit several properties:
- Responsiveness: The output addresses exactly what the instruction asks. A summarization instruction should produce a summary, not additional commentary or tangential information.
- Completeness: All parts of the instruction are fulfilled. If the instruction asks for three points, the output should contain three points, not two or four.
- Conciseness: No unnecessary elaboration beyond what's requested. Verbose responses that pad the output with irrelevant information teach the model to be similarly unfocused.
- Correctness: Factually accurate and logically sound. Training on incorrect outputs teaches the model to produce errors confidently.
Format Templates
Instruction-tuning datasets typically use consistent templates to structure examples. A common template might look like:
The specific delimiters and formatting vary across datasets, but consistency within a dataset helps models learn the pattern reliably. When the model sees consistent markers like "### Instruction:" and "### Response:", it learns to associate these patterns with the instruction-following behavior. This consistency reduces ambiguity and accelerates learning. We'll explore format templates in depth in the upcoming chapter on instruction format.
Instruction Diversity
The diversity of instructions in training data critically affects how well the tuned model generalizes. A model trained only on translation examples won't learn to summarize, because it has never seen the pattern of summarization requests and responses. A model trained only on formal phrasings won't understand casual requests, because it has learned to expect a specific register of language. Diversity operates along multiple dimensions, and each dimension contributes to the model's overall flexibility and robustness.
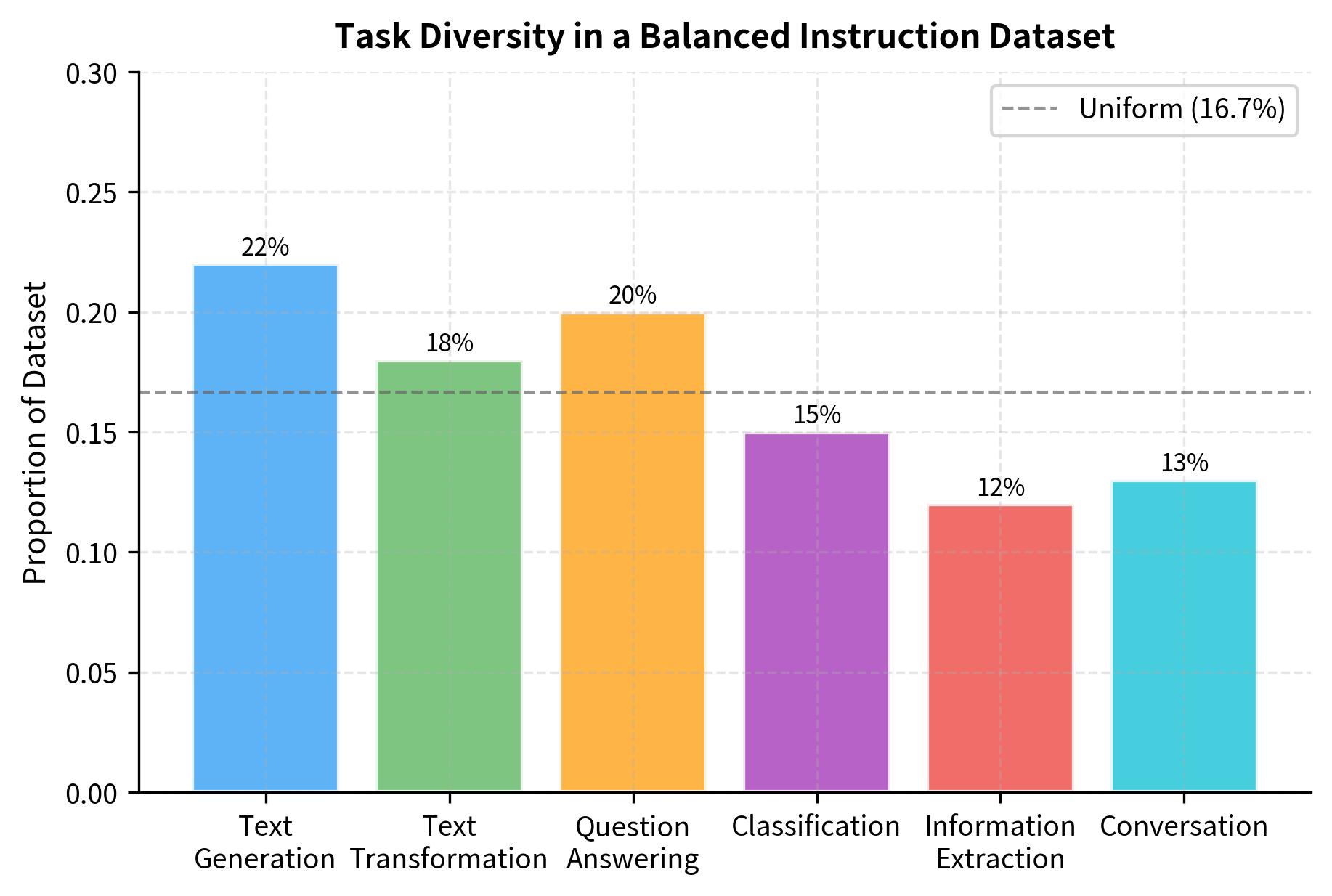
Task Diversity
Task diversity means covering many different types of instructions. Rather than specializing in one particular capability, a truly instruction-following model should be able to handle the full range of tasks you might request. Comprehensive instruction datasets include examples across categories like:
- Text generation: Writing stories, poems, emails, code, essays. These tasks require the model to create content from scratch based on specifications.
- Text transformation: Summarization, paraphrasing, style transfer, translation. These tasks require the model to take existing text and modify it in specific ways.
- Information extraction: Named entity recognition, relation extraction, key point identification. These tasks require the model to identify and isolate specific information from provided text.
- Question answering: Factual questions, reasoning questions, reading comprehension. These tasks require the model to provide information in response to queries.
- Analysis: Sentiment classification, topic identification, text comparison. These tasks require the model to evaluate and categorize text according to various criteria.
- Conversation: Dialogue responses, follow-up handling, context maintenance. These tasks require the model to participate in multi-turn exchanges while tracking context.
Training across diverse tasks teaches models the general skill of instruction following rather than specific task patterns. A model that has learned to follow summarization instructions and classification instructions and generation instructions develops a meta-understanding of what it means to receive and execute an instruction. It learns the abstract pattern: "receive a directive, understand what's being asked, generate appropriate output." This meta-learning is far more valuable than mastering any single task.
Phrasing Diversity
Even within a single task, instructions can be phrased countless ways. Human language is remarkably flexible, and you will express the same intent using vastly different words and structures. Consider these equivalent summarization requests:
- "Summarize this text"
- "What are the main points?"
- "Give me a brief overview"
- "TL;DR"
- "Can you condense this?"
- "I need a quick summary"
- "Break this down for me"
If training data only contains one phrasing, the model may fail on others because it has learned to pattern-match on specific words rather than understanding the underlying intent. Phrasing diversity ensures the model learns the underlying intent rather than pattern-matching on specific words. The model should recognize that all these phrasings point to the same underlying request for summarization, even though they use completely different vocabulary.
Difficulty Diversity
Instructions vary in complexity from simple single-step requests to intricate multi-part specifications. A robust instruction-following model must handle this entire spectrum, from straightforward commands to nuanced, multi-faceted directives. Training data should span this spectrum:
Simple instructions:
- "Translate 'hello' to German"
- "What is 2 + 2?"
Moderate instructions:
- "Summarize this article in 3 bullet points, focusing on the economic implications"
- "Rewrite this paragraph in a more formal tone while preserving the key information"
Complex instructions:
- "Compare and contrast these two research papers, identifying their methodological differences and evaluating the strength of their conclusions"
- "Write a response to this customer complaint that acknowledges their frustration, explains our policy, offers a reasonable solution, and maintains a professional tone"
Exposure to varying difficulty levels helps models handle the full range of your requests they'll encounter in deployment. If training data contains only simple instructions, the model may struggle to decompose and address complex multi-part requests. Conversely, training only on complex instructions may not help the model learn the fundamental patterns of instruction following that simpler examples demonstrate clearly.
Domain Diversity
Instructions span many knowledge domains: science, history, technology, arts, law, medicine, and more. Domain diversity ensures the model doesn't overfit to particular subject areas and can handle requests across the full breadth of human knowledge. A model trained predominantly on technology-related instructions might struggle with history questions, not because it lacks historical knowledge (that comes from pre-training) but because it hasn't learned how historical inquiries are typically phrased.
This doesn't mean the model needs domain expertise (that comes from pre-training knowledge), but it needs to understand how instructions are phrased in different domains. A medical question might use terminology differently than a legal question, even if both are asking for clarification. Scientific instructions might favor precise, technical language, while creative writing instructions might use more evocative, open-ended phrasing. Domain diversity teaches the model to navigate these variations in communication style.
Instruction Quality
Not all instruction examples are equally valuable. The quality of training data directly impacts model behavior, often in ways that may not be immediately apparent but compound over time. High-quality instruction data exhibits several characteristics that distinguish it from noise or low-value examples.
Response Accuracy
The response must correctly fulfill the instruction. An instruction asking for the capital of France paired with a response saying "London" teaches the wrong behavior. The model learns to produce confident but incorrect answers because that's what it sees in training. Quality control processes must verify that responses accurately address their instructions, especially for factual or deterministic tasks where correctness can be objectively assessed.
For subjective tasks like creative writing, accuracy means appropriateness: does the response reasonably satisfy what a human would expect from the instruction? A poem about autumn should actually be about autumn, not about spring. A formal letter should sound formal, not casual. These judgments require human evaluation to ensure the training data teaches appropriate behavior.
Response Completeness
Partial or truncated responses teach models to stop prematurely. If an instruction asks for "five examples" but the response only provides three, the model learns incomplete behavior. It learns that three examples constitute an acceptable response to a request for five. Over many training examples, such patterns accumulate, teaching the model that incomplete responses are acceptable. Quality instruction data includes complete responses that fully address all aspects of the instruction.
Instruction Clarity
Ambiguous or confusing instructions produce training noise. If an instruction could reasonably be interpreted multiple ways, the response may align with one interpretation while you have another in mind. When the model encounters similar ambiguous instructions during deployment, it may produce responses that don't match your expectations because it learned a different interpretation during training. High-quality instructions minimize ambiguity.
Consider the instruction "Make this better." Better in what way? More formal? More concise? More engaging? Such vague instructions should either be clarified or paired with responses that interpret the intent reasonably and explicitly state their interpretation. A high-quality response might begin, "I'll improve this text by making it more concise and formal:" before providing the revised version, thereby demonstrating how to handle ambiguity constructively.
Naturalness
Instructions should reflect how you actually make requests. Overly formal or artificial instructions create a distribution mismatch between training and deployment. If all training instructions follow a rigid template like "Please perform the following action: [task description]" but you write "hey can you help me with something," the model may struggle with natural language inputs. It has learned to expect a particular format that you don't employ.
Effective instruction datasets include a mix of formal and informal phrasings, complete sentences and fragments, explicit requests and implied needs. This variety prepares the model to handle the messy, inconsistent ways humans actually communicate.
Safety and Appropriateness
Training data shapes model behavior, including potentially harmful behaviors. If the training data includes examples of generating harmful content, the model learns to produce such content when asked. Quality instruction data excludes examples that would teach models to:
- Generate harmful or dangerous content
- Reveal private information
- Exhibit biases or discriminatory patterns
- Bypass safety considerations
This concern becomes particularly important in the alignment work we'll explore in Part XXVII, where human preferences guide models toward helpful, harmless, and honest behavior.
Worked Example: Creating Instruction Examples
Let's create a few instruction examples to illustrate format and quality considerations. We'll develop examples for a summarization task, showing how different format choices affect the training signal. By examining these examples closely, you can see how small variations in instruction phrasing lead to meaningfully different expected outputs.
Basic format:
More constrained format:
Informal phrasing:
Notice how the response style matches the instruction style. Formal instructions receive formal responses; casual questions get conversational answers. This stylistic alignment teaches models to adapt their output to your preferences. The model learns not just what to say but how to say it, matching the register and tone of your request.
Code Implementation
Let's implement a basic instruction data processor that validates and formats instruction examples. This prepares raw data for instruction tuning.
Now let's create a collection of sample instruction examples spanning different task types.
Let's examine how these examples look when formatted with different templates.
The default template provides a minimal structure, while the Alpaca template adds a context-setting preamble that helps the model understand its role. Both formats clearly separate the instruction from the input content using distinct headers.
Now let's implement quality checks for instruction data.
The validator successfully identifies common quality issues. Example 1 fails due to brevity, Example 2 lacks a complete instruction and output, and Example 3 contains placeholder text, while Example 4 passes all checks.

Let's also implement a function to analyze diversity in an instruction dataset.
The analysis reveals the structural properties of our dataset. We see a distribution of different task verbs and a mix of examples with and without input text. Monitoring these statistics helps ensure the training data covers the necessary variety of instruction types and lengths required for robust generalization.
Finally, let's implement a function to prepare instruction data for training by tokenizing and creating the appropriate format for a language model.
Key Parameters
The key parameters for the instruction processing pipeline are:
- template: The formatting style for instructions (e.g., "default", "alpaca"). Different templates provide different context cues to the model.
- max_length: The maximum sequence length allowed for training examples. Filtering long sequences ensures data fits within the model's context window.
- min_instruction_length: The minimum character count for instructions. This threshold helps filter out noise or trivial inputs.
- min_output_length: The minimum character count for responses to ensure meaningful training signals.
Limitations and Practical Considerations
Instruction tuning represents a significant advance in making language models practically useful, but it comes with important limitations that you must understand.
The most fundamental limitation is that instruction tuning cannot teach capabilities the model doesn't already possess. If a base model lacks knowledge about a particular domain or cannot perform certain reasoning, no amount of instruction tuning will create that capability from nothing. Instruction tuning is more about eliciting and formatting existing capabilities than creating new ones. This means the quality of the pre-trained base model fundamentally limits what instruction tuning can achieve.
Data quality presents persistent challenges. Creating high-quality instruction data requires significant human effort, and scaling this effort is expensive. Crowdsourced data may contain errors, inconsistencies, or biases. Model-generated instruction data (which we'll explore in the chapter on Self-Instruct) can propagate and amplify the generating model's mistakes. The old principle of "garbage in, garbage out" applies with full force: models trained on low-quality instruction data learn low-quality behaviors.
Instruction tuning also introduces the risk of capability degradation. As discussed in Part XXIV on catastrophic forgetting, fine-tuning on instruction data can cause the model to forget some pre-training knowledge. This is particularly concerning when instruction datasets don't cover the full breadth of capabilities the base model possessed. Careful dataset design and training procedures can mitigate but not eliminate this risk.
The generalization boundaries of instruction tuning remain unclear. While instruction-tuned models often generalize impressively to instruction phrasings they've never seen, they can also fail unexpectedly on seemingly simple variations. The exact factors determining when generalization succeeds versus fails are active areas of research. You should not assume that instruction tuning creates robust, failure-free instruction following.
Finally, instruction tuning alone doesn't solve the alignment problem. Teaching a model to follow instructions efficiently also means it will follow harmful instructions efficiently. The subsequent work on preference learning and RLHF, which we'll cover in Part XXVII, addresses this limitation by teaching models to follow instructions while also avoiding harmful outputs.
Summary
Instruction tuning bridges the gap between language models that can generate text and assistants that respond helpfully to your requests. Pre-trained models optimize for next-token prediction, not instruction compliance, creating a fundamental mismatch with your expectations. Instruction tuning addresses this by fine-tuning on datasets of instruction-response pairs, teaching models to recognize and execute requests.
Effective instruction data requires careful attention to format, with clear structure distinguishing instructions, inputs, and expected outputs. Diversity across task types, phrasings, difficulty levels, and domains enables models to generalize beyond their training examples. Quality considerations including response accuracy, completeness, and naturalness determine whether training produces reliable or erratic behavior.
The surprising efficiency of instruction tuning, achieving dramatic behavioral changes with relatively small datasets, reveals that pre-trained models already possess the necessary capabilities. Instruction tuning teaches them when and how to deploy these capabilities in response to your needs.
The next chapter examines how instruction data is created at scale, exploring both human annotation approaches and the increasingly important role of model-generated synthetic data. Understanding data creation methods will help you evaluate and create instruction datasets for your own applications.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about instruction tuning and instruction-following in large language models.

Comments