

Learn how chat templates, prompt formats, and role definitions structure conversations for language model instruction tuning and reliable inference.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Instruction Format
When you fine-tune a language model to follow instructions, the instruction format you use to structure those instructions matters enormously. A model trained on one format will struggle to understand inputs presented in a different format at inference time. This chapter explores the conventions, templates, and special tokens that transform raw text into structured conversations that language models can reliably interpret.
The core challenge is deceptively simple: language models process sequences of tokens, but we want them to understand the distinction between user instructions and assistant responses. We need consistent delimiters that tell the model "this is an instruction" versus "this is the expected response." These delimiters must be unambiguous, consistent during training and inference, and robust enough to handle complex multi-turn conversations.
As we discussed in the Instruction Following chapter, instruction-tuned models learn to recognize patterns in how instructions are presented. The format serves as a structural scaffold that helps the model parse inputs correctly and generate outputs in the expected positions. Without consistent formatting, the model cannot reliably distinguish between instruction and response, between the user and the assistant, or between system context and conversation content.
Prompt Templates
A prompt template defines the structure that wraps each instruction-response pair during training. Think of it as a contract between you and the model: you promise to always present instructions in a certain way, and in return, the model learns to recognize and respond to that presentation reliably. At its simplest, a template specifies where the instruction goes, where the response goes, and what separates them. However, template design has a significant impact on model behavior.
Language models are pattern recognition engines. During pre-training, they learn statistical regularities in text. During instruction tuning, we want them to learn a new regularity: the pattern that connects instructions to appropriate responses. The template creates this pattern by providing consistent structural cues that the model can latch onto. Without these cues, the model would have no way to determine where an instruction ends and where it should begin generating.
Consider the most basic template structure:
### Instruction:
{instruction}
### Response:
{response}
This template uses natural language markers to delineate sections. The model learns that text after "### Instruction:" contains what it should respond to, and text after "### Response:" contains the expected output. During training, both sections are present, allowing the model to learn the mapping from instruction to response. During inference, you provide everything up through "### Response:" and let the model generate the continuation. The blank space after "### Response:" serves as an invitation for the model to fill in what should come next.
Why do these markers work? The model learns through thousands of training examples that whenever it sees "### Instruction:" followed by some text and then "### Response:", the text that follows "### Response:" should be a helpful, relevant answer to whatever appeared after "### Instruction:". The consistency of this pattern allows the model to generalize: when it encounters the same structure with a new instruction at inference time, it knows exactly what role it should play.
The Alpaca dataset, which pioneered many instruction-tuning practices, used a slightly more elaborate template that included an optional input field:
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{instruction}
### Input:
{input}
### Response:
{response}
This three-part structure separates the task description from any context needed to complete it. For a translation task, the instruction might be "Translate the following text to French" while the input contains the actual text to translate. This separation helps the model distinguish between instructions and context. The preamble at the beginning also serves an important function: it primes the model with context about what kind of task this is, setting expectations before the specific instruction appears.
The exact template you use matters less than using it consistently. A model trained with "### Instruction:" markers will expect those same markers at inference time. Switching to "[INST]" delimiters without retraining will degrade performance because the model has never learned to recognize those markers as instruction boundaries.
Modern templates typically use special tokens rather than natural language markers. Special tokens are added to the tokenizer's vocabulary specifically to serve as structural delimiters. They're less likely to appear in normal text, making them unambiguous markers of format structure. Consider the difference: if you use "### Response:" as a marker, and you ask the model to "explain what ### Response: means in the Alpaca format," the model might become confused about where the actual response should begin. Special tokens like <|assistant|> avoid this ambiguity because they exist outside the normal vocabulary of human-written text.
Role Definitions
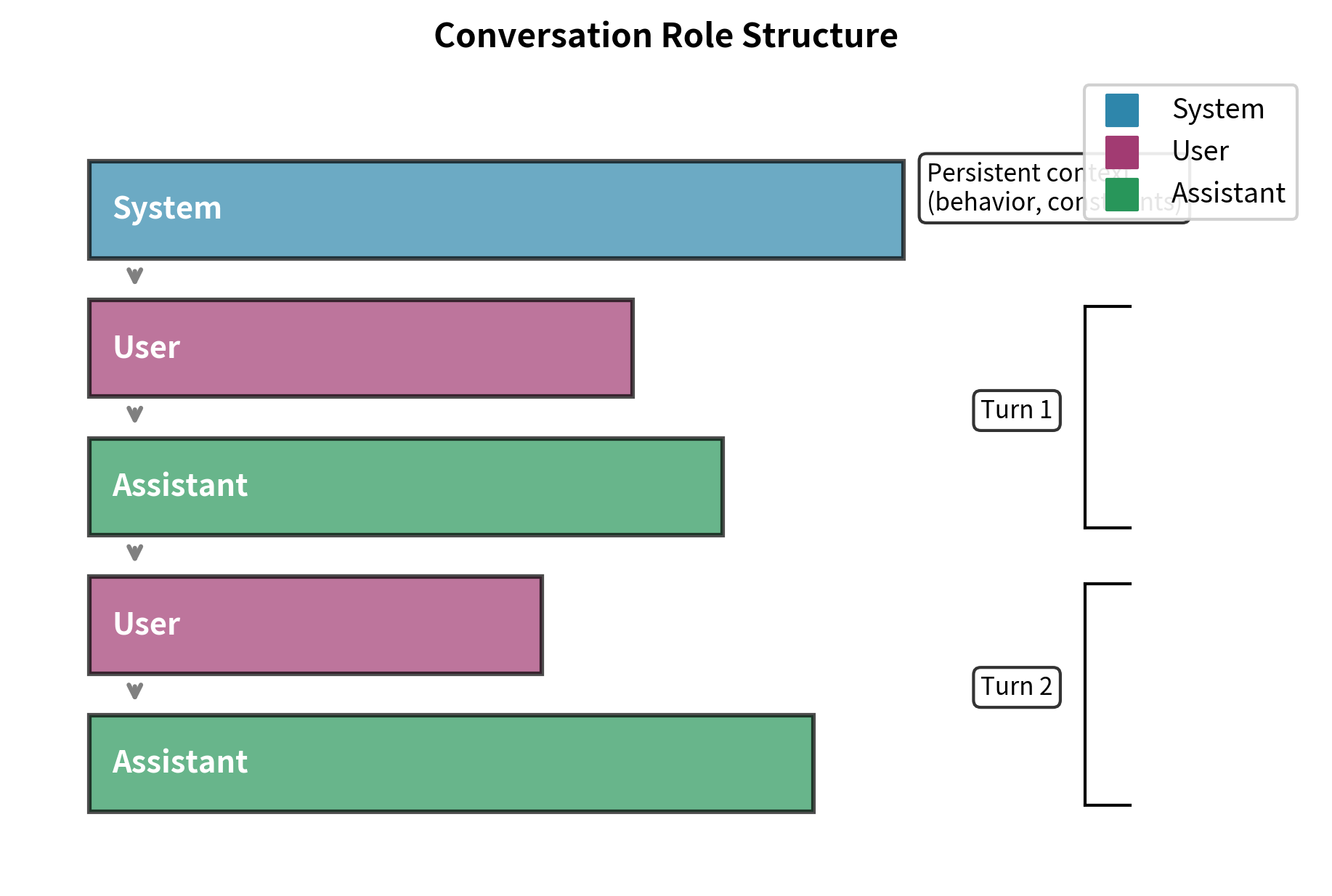
Structured conversations require clear identification of who is speaking. This might seem obvious when you think about human conversation, where we always know who said what, but for a language model processing a stream of tokens, speaker identity is not inherent in the text. The model must learn to recognize speaker boundaries and adjust its behavior accordingly. Instruction-tuned models typically recognize three fundamental roles, each serving a distinct purpose in the conversation architecture:
-
System: Provides context and persona definitions. The system role defines the behavior and persona for the conversation.
-
User: Represents the user interacting with the model. User messages contain the questions or instructions that the model must address.
-
Assistant: Represents the model itself. This role defines the identity and style of the generated responses.
These roles emerged from practical necessity rather than theoretical elegance. Early chatbots needed to distinguish human input from bot output to maintain coherent conversations. As models became more sophisticated, practitioners discovered that adding a system role allowed behavior customization without cluttering the conversation with meta-instructions. Instead of asking the user to include "remember to be concise" in every message, you could establish that expectation once in the system prompt and have it apply throughout.
Role separation serves several purposes. First, it enables training on multi-turn conversations where the model must track who said what and respond appropriately to the conversational context. Second, it allows system prompts that establish consistent behavior across interactions, meaning the same base model can behave differently for different applications. Third, it provides clear boundaries for computing the training loss: typically, we only compute loss on assistant tokens, not on user or system tokens. This choice ensures the model learns to generate appropriate responses rather than predicting user inputs.
System Messages
System messages establish the behavioral context for an entire conversation. Unlike user messages that represent turn-by-turn interaction, system messages set persistent instructions that influence all subsequent responses. They act as a kind of meta-instruction that shapes how the model interprets and responds to everything that follows.
System messages define the model's personality and constraints for a conversation. The model learns during training that system content should be treated as foundational truth that shapes all its responses.
A system message might specify:
You are a helpful assistant that provides concise, accurate answers.
You always cite sources when making factual claims. If you're unsure
about something, you acknowledge your uncertainty rather than guessing.
This tells the model how to behave across the entire conversation. Every response should be concise, should cite sources, and should acknowledge uncertainty. These constraints persist regardless of what the user asks. If the user later asks for a long, detailed explanation, the model must balance that request against the system instruction for conciseness. Through training, the model learns to navigate these tensions appropriately.
System messages became prominent with ChatGPT and similar conversational AI systems. They allow the same base model to behave differently in different contexts without any additional fine-tuning. A customer service application might use a system prompt emphasizing politeness and company policy, while a coding assistant might use one emphasizing technical accuracy and code quality. A creative writing assistant might receive a system prompt encouraging imagination and stylistic flourish. This flexibility means a single trained model can power many different applications, each with its own personality and constraints.
The positioning of system messages matters for how the model processes them. Most formats place the system message at the very beginning of the conversation, before any user turns. This ensures the model processes instructions before encountering user requests, allowing those instructions to condition all subsequent attention computations. Some formats allow system messages to appear mid-conversation, but this is less common and can confuse models not trained to expect it. The model has learned that system messages come first and set the stage; encountering one mid-conversation violates that learned pattern.
During training, system messages are typically included in the input but excluded from the loss calculation. The model sees the system message and learns to condition its responses on it, but it's not penalized for not predicting the system message tokens themselves. This makes sense: we don't want the model to learn to generate system messages, we want it to learn to follow them.
Multi-Turn Conversation Format
Real conversations involve multiple exchanges between the user and the assistant. A single question and answer might suffice for simple tasks, but complex interactions require context to build over time. A multi-turn format must track the full conversation history while clearly marking each turn's boundaries and roles. This creates a cumulative context where each response can draw on everything that came before.
A simple multi-turn structure looks like:
User: What is the capital of France?
Assistant: The capital of France is Paris.
User: What's the population?
Assistant: Paris has a population of approximately 2.2 million in the city proper, or about 12 million in the greater metropolitan area.
The model processes the entire history when generating each new response. For the second question, it sees both the original question about France's capital, the assistant's response, and the follow-up question about population. This context allows it to resolve the ambiguous reference "What's the population?" to mean Paris's population. Without the conversation history, the model would have no way to know what "the population" refers to. Multi-turn formats enable natural, contextual conversation instead of isolated question-answering.
Multi-turn training requires careful attention to what receives gradient updates. Typically, you only compute loss on the assistant turns, not user turns or the system message. Standard causal attention masking ensures only assistant tokens contribute to the loss, preventing the model from learning to predict user inputs. User turns provide context that shapes the assistant's response, but they are not targets for prediction.
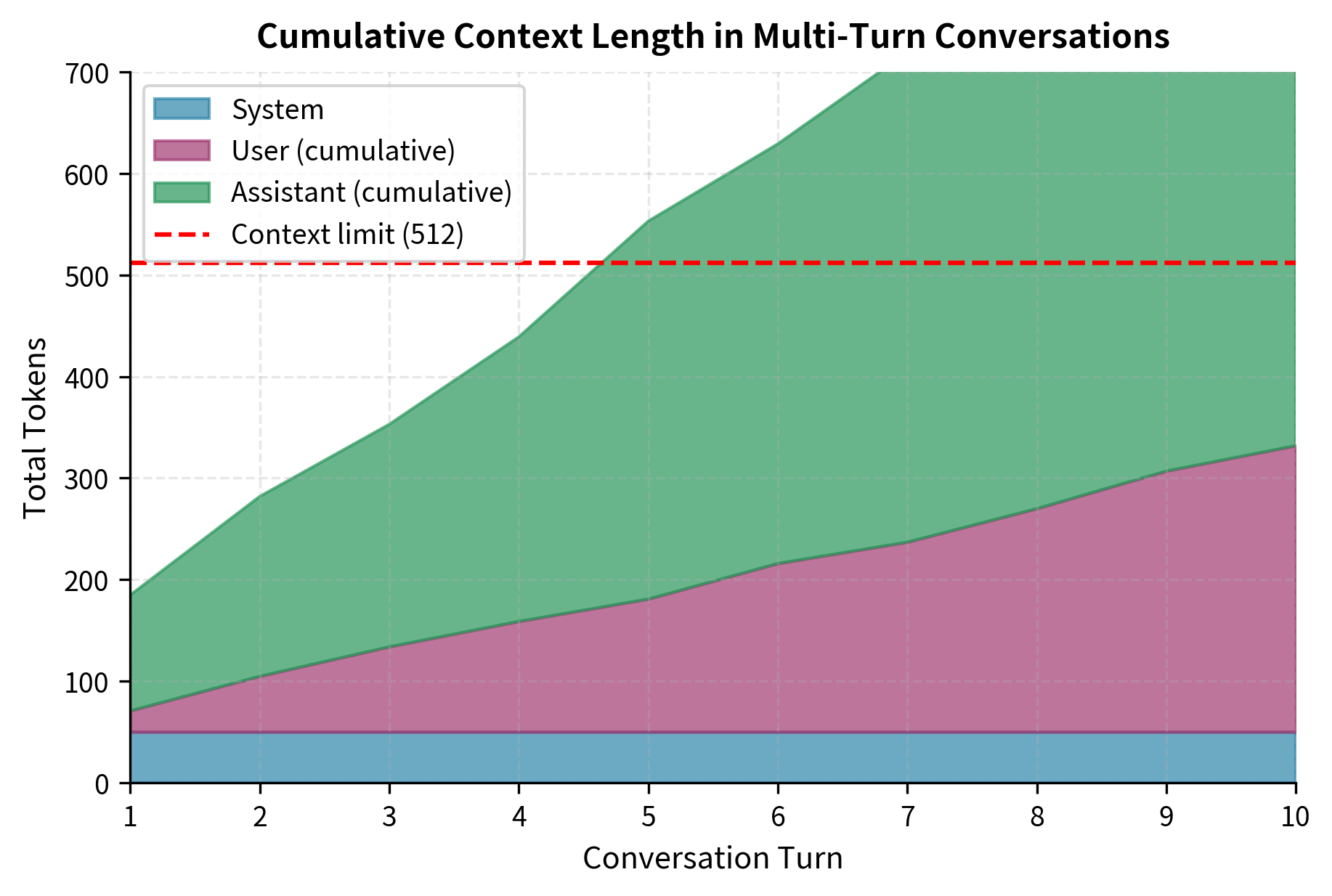
The conversation format must handle several edge cases that arise in real-world applications. What happens if a user message is empty? What if there are consecutive user messages without assistant responses? How should the model handle extremely long conversation histories that exceed context length? Different formats and training procedures handle these cases differently, and your choice depends on your application's requirements. Some applications might truncate long histories, while others might summarize earlier turns, and still others might refuse to continue conversations that exceed certain lengths.
Chat Templates
Chat templates standardize how conversations are converted to token sequences. Standardization ensures the training and inference formats match. Different model families use different templates, reflecting different design choices and historical developments. Using the wrong template for a given model produces poor results because the model encounters structural cues it has never seen before.
ChatML Format
ChatML, which stands for Chat Markup Language, was introduced by OpenAI and has become one of the most common formats in the open-source ecosystem. It uses special tokens to mark message boundaries, providing clear and unambiguous structure:
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
What is 2 + 2?<|im_end|>
<|im_start|>assistant
2 + 2 equals 4.<|im_end|>
The key elements are designed for clarity and consistency:
<|im_start|>marks the beginning of a message<|im_end|>marks the end of a message- The role immediately follows
<|im_start|>on the same line - Message content follows the role on subsequent lines
ChatML's structure makes role boundaries unambiguous. The special tokens are unlikely to appear in normal text, and the consistent structure simplifies parsing both for the model and for any code that needs to process these conversations. Many open-source models, including various Qwen versions, use ChatML or close variants. The widespread adoption of ChatML makes it easier to share training data and inference code across different projects.
Llama Chat Format
Meta's Llama models use a different format that evolved across model generations, reflecting lessons learned and changing design priorities. Llama 2's chat format uses:
<s>[INST] <<SYS>>
You are a helpful assistant.
<</SYS>>
What is 2 + 2? [/INST] 2 + 2 equals 4. </s><s>[INST] What about 3 + 3? [/INST]
The format nests the system message within special <<SYS>> tags, places instructions within [INST] and [/INST] markers, and uses <s> and </s> as sequence boundaries. For multi-turn conversations, each turn is wrapped with these markers. This nesting structure reflects a hierarchical view of the conversation where system content is embedded within the first instruction turn rather than standing alone.
Llama 3 simplified and modified this format, introducing new special tokens like <|begin_of_text|>, <|start_header_id|>, and <|end_header_id|>:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
What is 2 + 2?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
2 + 2 equals 4.<|eot_id|>
This format provides more explicit structure with dedicated tokens for headers, end-of-turn markers, and text boundaries. The evolution from Llama 2 to Llama 3 format shows how template design improves as practitioners gain experience. The Llama 3 format separates concerns more cleanly: there are distinct tokens for marking role headers versus marking content boundaries, making the structure more regular and easier to parse programmatically.
Mistral Format
Mistral models use a simpler format that minimizes token overhead:
<s>[INST] You are a helpful assistant.
What is 2 + 2? [/INST]2 + 2 equals 4.</s>[INST] What about 3 + 3? [/INST]
Mistral's format combines the system message with your first message and uses minimal special tokens. This design choice prioritizes simplicity and efficiency. Notice there's no space after [/INST] before the assistant response. This detail matters for exact token alignment. During training, the model learns that the assistant response begins immediately after the closing instruction marker. Introducing a space at inference time would create a token sequence the model has never encountered, potentially affecting output quality.
Zephyr Format
Zephyr models, built on Mistral architecture, use a ChatML-like format with different tokens:
<|system|>
You are a helpful assistant.</s>
<|user|>
What is 2 + 2?</s>
<|assistant|>
2 + 2 equals 4.</s>
The structure resembles ChatML but uses <|system|>, <|user|>, and <|assistant|> as role markers with </s> as the end-of-message delimiter. This hybrid approach combines the clarity of ChatML-style role markers with the familiarity of the standard end-of-sequence token. The choice of format reflects the Zephyr team's design preferences and the training data they used.
Working with Chat Templates in Practice
The Hugging Face transformers library provides a standardized way to apply chat templates through the tokenizer's apply_chat_template method. This ensures you use the correct format for each model without manually constructing the template strings, which would be error-prone and tedious. The library abstracts away the differences between formats, allowing you to write code that works across multiple model families.
Let's explore how chat templates work with a concrete example:
The conversation is represented as a list of dictionaries, each with a role and content key. This standardized format works across different models regardless of their underlying template structure. The tokenizer handles converting it to the model-specific template, so you can write model-agnostic code that processes conversations uniformly.
The output displays the conversation formatted with the model's control tokens. The add_generation_prompt=True parameter is crucial for inference. It adds whatever tokens signal the start of an assistant turn, so the model knows to generate a response. Without it, you'd get the conversation history but no prompt for the model to continue. The model would see a complete conversation and have no indication that it should add anything.
Let's examine how the same conversation looks with different model templates:
Notice how each model uses different delimiters and structures. The Phi model uses its specific template markers. Qwen uses ChatML-style <|im_start|> and <|im_end|> tokens. Mistral uses [INST] and [/INST] markers. Using the wrong template for a model would produce nonsensical outputs because the model has only been trained to recognize its specific format. This comparison illustrates why the apply_chat_template abstraction is so valuable: it shields you from needing to know these details for every model you work with.
Tokenizing for Training
During instruction tuning, you need to not only format the conversation but also create labels that mask out non-assistant tokens from the loss calculation. This loss masking is fundamental to instruction tuning because it focuses the learning signal on what we actually care about: teaching the model to generate good responses. Let's see how to prepare training data:
The decoded sequence shows the conversation history merged into a single string with appropriate control tokens. Notice that we set add_generation_prompt=False because this is training data with a complete assistant response already included. We don't need to prompt for generation; we need to present the complete example for the model to learn from.
For training, we need to identify which tokens are from the assistant response, so we only only compute loss on those:
These outputs confirm the separation between the instruction context and the target response. By tokenizing the conversation with and without the assistant response, we can precisely identify which tokens constitute the response. This identification is crucial because those are the only tokens that should contribute to the training loss.
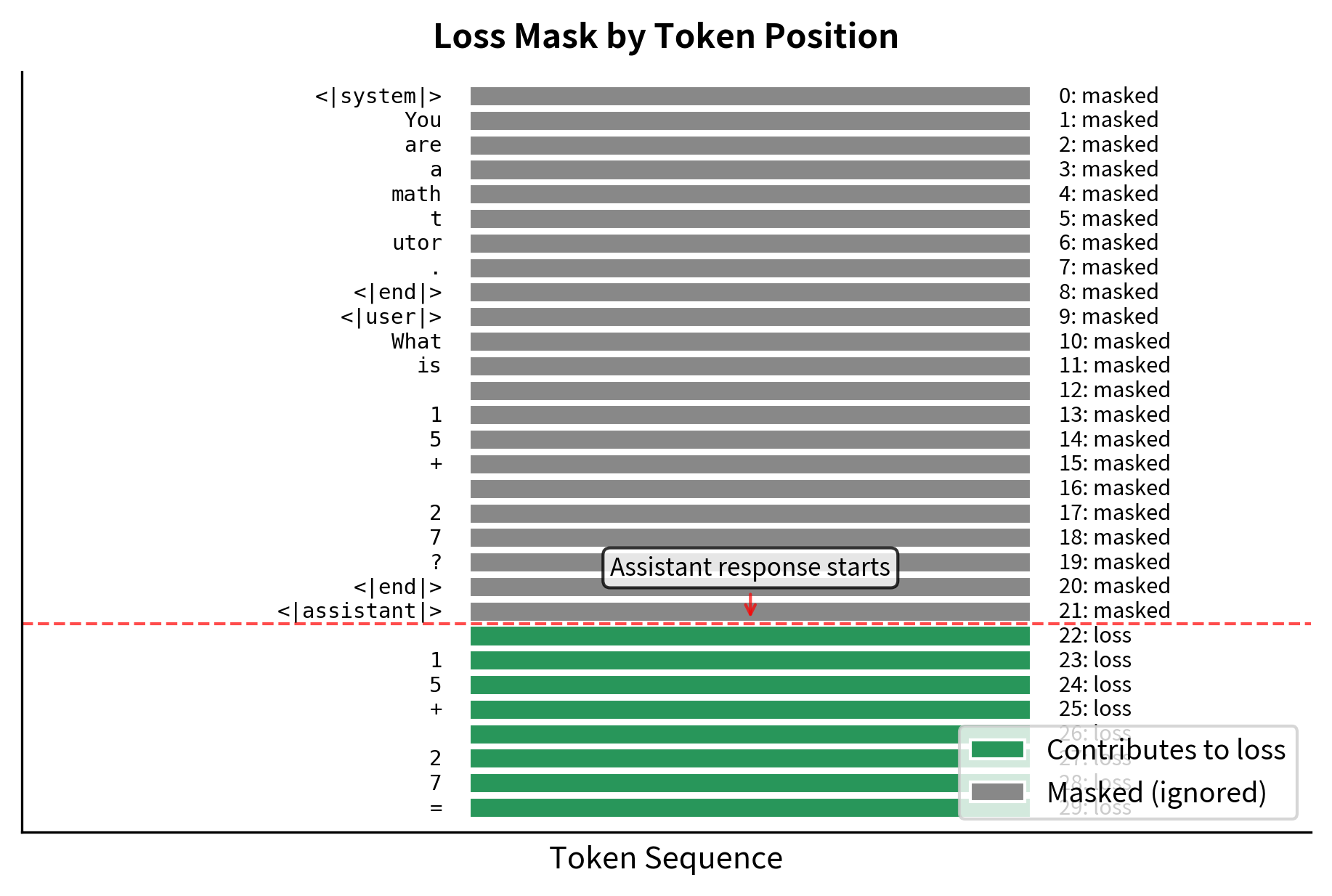
Now we can create labels with masking for the prompt tokens:
The tokens marked with "✓ loss" are from the assistant response and contribute to training. The masked tokens are from the system message, your message, and format tokens. During backpropagation, gradients only flow from the assistant tokens, teaching the model to generate appropriate responses while preserving its understanding of how to parse the format. The special value -100 is recognized by PyTorch's CrossEntropyLoss as an ignore index, causing those positions to be excluded from the loss calculation entirely.
Custom Chat Templates
Sometimes you need to define a custom template for models that don't have one, or modify an existing template for specific use cases. This might occur when you're working with a base model that was never instruction-tuned, when you want to add new roles beyond the standard three, or when you need need to match a specific data format that differs from standard templates. Hugging Face tokenizers use Jinja2 templating syntax, which provides the flexibility to define arbitrary formatting logic:
The Jinja2 template iterates over messages, applies role-specific formatting, and optionally adds a generation prompt. This flexibility allows you to design templates that match your training data format exactly. The template syntax supports conditionals, loops, and variable interpolation, giving you full control over how conversations are rendered to text.
When creating custom templates, ensure your special tokens (like [SYSTEM], [USER], [ASSISTANT]) are added to the tokenizer's vocabulary as special tokens. Otherwise, they'll be split into subword pieces, making them harder for the model to recognize as format boundaries:
The output verifies that the new tokens are now part of the vocabulary with assigned IDs. Each special token receives its own unique ID, ensuring it will always be tokenized as a single token rather than being broken into pieces. After adding special tokens, you must resize the model's embedding layer to accommodate the new vocabulary entries. This is typically done with model.resize_token_embeddings(len(tokenizer)). The new embeddings will be randomly initialized and will learn appropriate representations during fine-tuning.
Key Parameters
The key parameters for chat templating and tokenization are:
- messages: List of dictionaries containing the conversation history (roles and content).
- tokenize: If
True, returns token IDs; ifFalse, returns a formatted string. - add_generation_prompt: If
True, adds tokens to signal the start of an assistant response. - return_tensors: Specifies the format for returned data (e.g.,
'pt'for PyTorch tensors). - special_tokens: A dictionary of tokens to add to the tokenizer's vocabulary.
Format Considerations for Training Data
The format you choose affects several aspects of instruction tuning, from computational efficiency to model quality. Here are key considerations when designing or selecting a template:
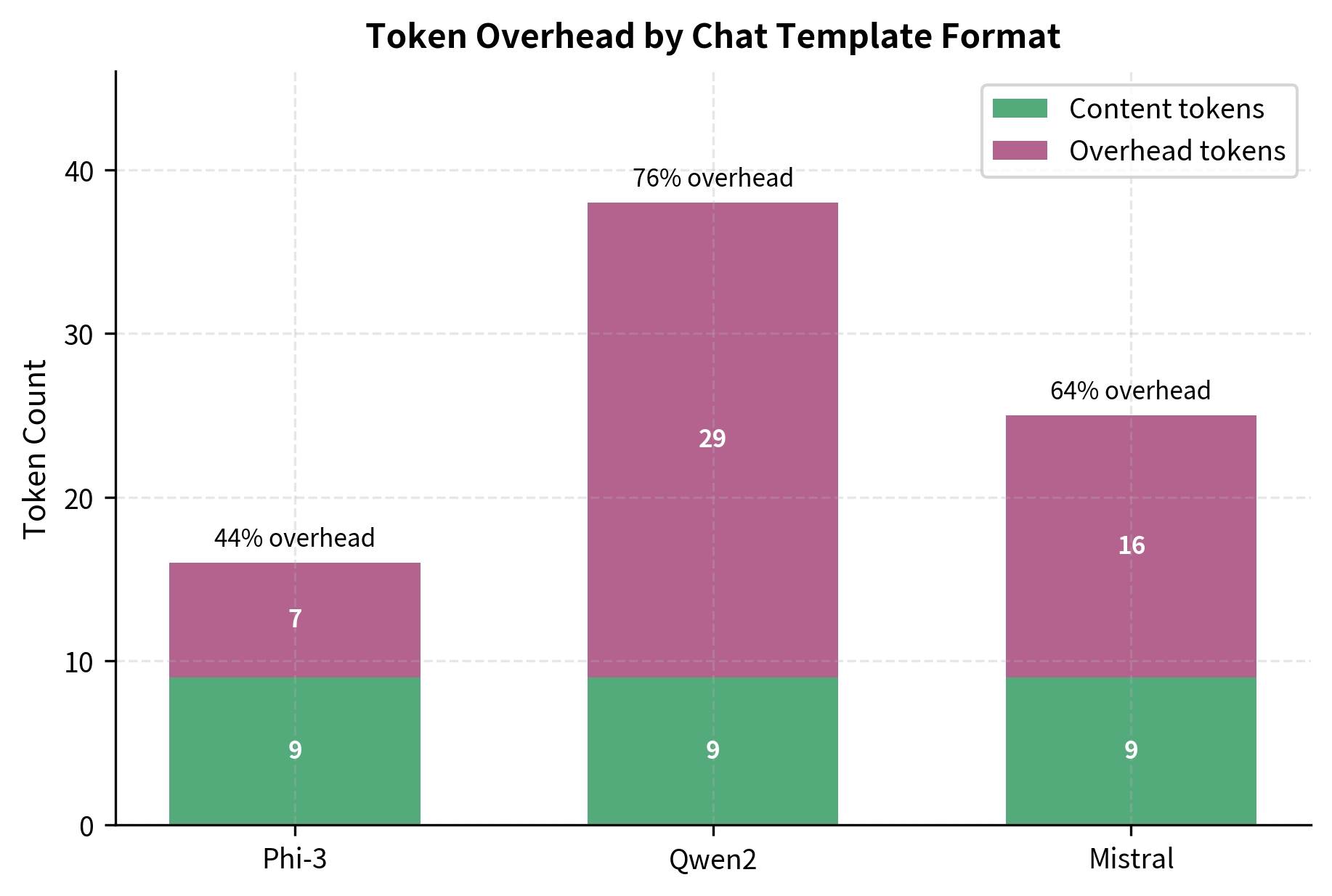
Token efficiency matters for training speed and cost. Some formats use verbose markers that consume many tokens per message. A format that adds 20 tokens of overhead per turn might seem negligible, but across millions of training examples and dozens of turns per conversation, that overhead becomes substantial. ChatML's <|im_start|> and <|im_end|> are single tokens in models trained with them, but if you're adding them to a base model, they might tokenize into multiple pieces initially. Compare the token counts of different formats on your data to understand the overhead and make informed decisions about format selection.
Consistency with pre-training improves results. If you're fine-tuning a model that was pre-trained with a specific format, continuing to use that format leverages what the model already learned. The model has already developed internal representations for those format tokens and patterns. This is why using the official chat template for instruct models is important: they were trained expecting that exact format, and any deviation forces the model to generalize in ways it wasn't prepared for.
Edge cases need explicit handling. What happens when a message is empty? When the user sends multiple messages before the assistant responds? When the conversation exceeds context length and must be truncated? Your template and data processing pipeline should handle these cases gracefully. Consider whether empty messages should be included with empty content or skipped entirely. Define clear truncation strategies that preserve the most important context, typically the system message and the most recent exchanges.
System messages aren't always supported. Some formats and models don't support system messages, or support them only in limited ways. Mistral's original chat format, for instance, had limited system message support, requiring the system content to be prepended to the first user message. If your application relies on system prompts for behavior control, verify your chosen model and format support them properly before committing to a particular approach.
Limitations and Practical Considerations
Specific formats can make deployed systems fragile. A model trained on ChatML format will produce degraded outputs if you accidentally include text that looks like format markers. If your message contains <|im_end|>, the model might interpret it as an end-of-message signal and behave unexpectedly, potentially truncating its response or switching to a confused state. Robust deployment requires input sanitization to escape or remove potential format tokens from your content before passing it to the model. This sanitization must be comprehensive, covering all special tokens the model recognizes as structural.
Format lock-in is another concern that affects long-term system design. Once you've trained a model on a specific format, changing formats requires retraining. This limits your ability to adopt new, potentially better formats as they emerge. Some practitioners address this by training on multiple formats simultaneously, teaching the model to recognize several template styles, though this increases training complexity and data requirements. The multi-format approach also requires careful attention to data balancing to ensure the model learns all formats equally well.
The separation of roles, while useful, is an abstraction that doesn't perfectly map to all use cases. Some applications need more nuanced roles than system, user, and assistant: perhaps a "tool" role for function calling results, or an "observation" role for chain-of-thought reasoning steps. Extended formats like those used in function-calling models introduce additional roles, but each extension adds complexity and requires format-specific training data. The more roles you introduce, the more sophisticated your training data must be to teach the model when and how each role should be used.
Multi-turn context management also presents challenges that become more pronounced as conversations grow longer. As conversations grow longer, they eventually exceed context length limits. Truncation strategies must preserve enough history for coherent responses while respecting token budgets. Simply truncating from the beginning can remove the system prompt or early context that later messages depend on. If a conversation began with establishing user preferences, truncating that information will break references to it in later turns. More sophisticated approaches keep the system message and recent turns while summarizing or dropping middle content, but these strategies require careful implementation and may introduce their own artifacts.
The training loss masking strategy, where loss is only computed on assistant tokens, means the model never directly learns to generate your messages or system prompts. This is intentional: we want the model to respond to instructions, not to generate them. However, it means the model's understanding of these roles comes only from their influence on its own outputs, not from explicit prediction of those tokens. The model learns that certain patterns precede assistant turns and uses that context, but it doesn't learn to produce those patterns itself.
Summary
Instruction formats provide the structure that allows language models to parse conversations and generate correct responses. The key concepts we covered include:
-
Prompt templates wrap instruction-response pairs with consistent delimiters that the model learns to recognize. Whether using natural language markers like "### Instruction:" or special tokens, consistency between training and inference is essential.
-
Role definitions separate system context from user input and assistant output. This three-role structure enables multi-turn conversations, behavioral customization through system prompts, and appropriate loss masking during training.
-
System messages establish persistent behavioral context that influences all subsequent responses. They allow the same base model to behave differently across applications without retraining.
-
Chat templates standardize how conversations become token sequences. Different model families use different formats: ChatML for many OpenAI-style models,
[INST]markers for Llama and Mistral, and various others. Using the tokenizer'sapply_chat_templatemethod ensures correct formatting for each model. -
Training data preparation requires identifying assistant tokens for loss computation while masking out prompts, system messages, and format tokens. This teaches the model to generate responses while preserving its ability to parse the format structure.
The next chapter on Instruction Tuning Training will cover how to actually train models using these formatted datasets, including learning rate schedules, batch construction strategies, and convergence monitoring.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about instruction format and chat templates.

Comments