

Learn how z-loss stabilizes Mixture of Experts training by penalizing large router logits. Covers formulation, coefficient tuning, and implementation.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Router Z-Loss
The auxiliary balancing loss we covered in the previous chapter addresses one critical challenge in Mixture of Experts training: ensuring tokens distribute evenly across experts. But MoE models face another subtle yet dangerous problem: router instability during training. As router logits grow unboundedly large, softmax computations become numerically unstable, gradients explode or vanish, and training can collapse entirely. Router z-loss provides an elegant solution by penalizing large router logits, keeping the gating network well-behaved throughout training. Z-loss is critical for stable MoE training. The success of a training run often depends on this single auxiliary loss term.
The Router Instability Problem
To understand why router instability occurs, first revisit how routing decisions are made. Recall from the discussion of gating networks that the router produces logits for each input token . These logits represent the raw, unnormalized scores that indicate how strongly the router prefers each expert for a given token. These logits pass through a softmax to produce routing probabilities:
where:
- : the probability assigned to expert
- : the router logit for expert
- : the total number of experts
- : the exponential of the logit, ensuring a positive value
- : the sum over all experts, serving as the normalization constant
The softmax function transforms the arbitrary real-valued logits into a proper probability distribution where all values are positive and sum to one. This transformation is elegant and widely used, but it introduces subtle numerical challenges when the input logits span extreme ranges.
During training, nothing explicitly constrains the magnitude of these logits. The neural network is free to produce logits of any size, and the gradient descent process will adjust parameters in whatever direction minimizes the loss function. The softmax function is scale-invariant in its output probabilities: multiplying all logits by a constant doesn't change the relative probabilities. If you double all the logits, you still get the same ranking and the same probability assignments. However, scale dramatically affects the sharpness of the distribution and the numerical stability of the computation. This simple property creates a hidden danger that only appears as training progresses.
Logit Drift
As training progresses, the router learns to route tokens to appropriate experts by increasing the logits for preferred experts relative to others. This is exactly what we want: the router should learn to distinguish which expert is best suited for each type of input. Without constraints, however, this creates a natural logit drift toward larger logit magnitudes. If expert 3 is consistently preferred for certain tokens, the router learns to make large and positive while other logits become large and negative. The optimization process finds that making these differences more extreme leads to more confident routing decisions.
This drift accelerates over time through a self-reinforcing feedback loop. Larger logits create sharper probability distributions, which produce stronger gradients for the "winning" experts. When the probability assigned to the chosen expert approaches 1.0, the gradient signal becomes very clear: this expert should handle this token. These stronger gradients further increase the logit gap, which creates even sharper distributions, which produce even stronger gradients. This positive feedback loop pushes logits toward extreme values without any natural stopping point.
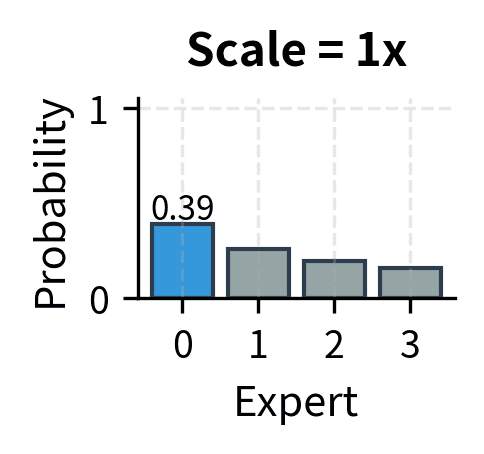
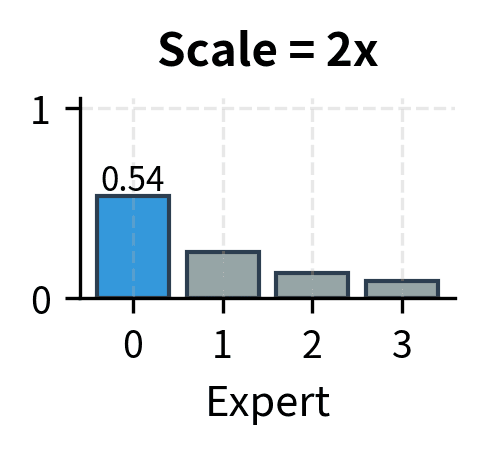
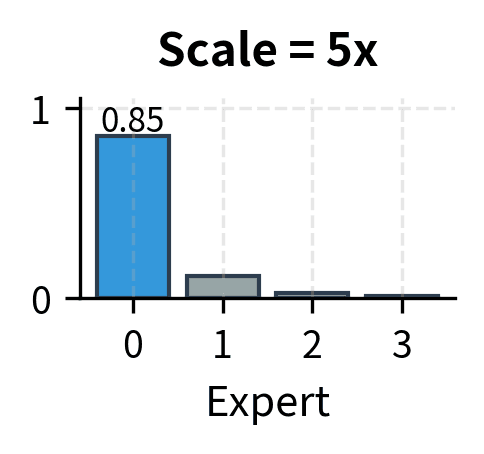
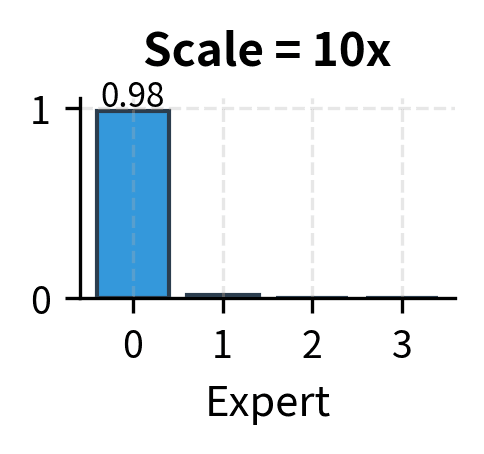
To illustrate this phenomenon concretely, consider a router that starts with logits around . The corresponding probabilities might be roughly , which is a reasonably soft distribution. After many training steps, if expert 1 is consistently correct, the logits might evolve to , giving probabilities closer to . The training process has learned to be more confident, but the logit magnitudes have increased dramatically. Left unchecked, this drift continues until logits reach values that cause computational problems.
Numerical Consequences
Large logits cause several numerical problems that can derail training entirely. These issues show why z-loss targets logit magnitudes:
-
Softmax overflow: Computing for (float64) or (float32) produces infinity. When any exponential term overflows, the entire softmax computation becomes undefined. Even a single overflowed value corrupts the probability calculation for all experts.
-
Softmax underflow: Computing for very negative produces zero due to floating-point underflow. This might seem harmless since small probabilities should be near zero anyway. However, when combined with division operations, these zeros can cause division-by-zero errors or produce undefined gradients.
-
Gradient instability: The softmax gradient involves terms like , which vanishes as probabilities approach 0 or 1. When the router becomes extremely confident, assigning probability 0.9999 to one expert and 0.0001 to others, the gradients become tiny. This gradient saturation prevents the router from learning to change its routing decisions even when it should.
-
Loss of precision: When logits span a huge range, floating-point arithmetic loses significant digits. A computation involving and cannot represent both values accurately in the same calculation, even with double precision. This precision loss introduces numerical noise that accumulates over training steps.
While the softmax-with-max-subtraction trick (subtracting before exponentiation) prevents overflow in the forward pass, it doesn't address the fundamental instability that large logit magnitudes create for gradient flow. The backward pass still suffers from saturated gradients and precision issues. Moreover, the max-subtraction trick only helps with the exponential computation; it doesn't prevent the underlying logit drift that causes all these problems.
Manifestation in Training
Router instability typically manifests in several recognizable ways that you should monitor:
-
Training loss spikes: Sudden, unexpected increases in loss occur as numerical issues cascade through the network. The loss might be decreasing smoothly for thousands of steps, then suddenly jump to a much higher value or even become NaN. These spikes often indicate that router logits have grown large enough to cause computational problems.
-
Gradient explosions: NaN or inf values appearing in gradients signal that the numerical instability has propagated to the backward pass. Once gradients contain invalid values, parameter updates become meaningless, and the model parameters can become corrupted. Recovering from gradient explosions often requires rolling back to an earlier checkpoint.
-
Expert collapse: The router becoming stuck on a single expert due to saturated gradients represents a subtle but serious failure mode. When logits become extreme, the router cannot learn to route tokens to different experts even when the current routing is suboptimal. The gradients for non-selected experts become vanishingly small, freezing the routing pattern in place.
-
Poor generalization: Overconfident routing that doesn't transfer to new inputs indicates that the model has memorized routing patterns rather than learning generalizable features. When the router makes extremely sharp decisions based on subtle input features, small changes in input distribution can completely change routing behavior in unpredictable ways.
These issues become more severe as model scale increases. Larger models have more parameters in the router network, more capacity to push logits to extreme values, and longer training runs that provide more opportunity for drift to accumulate. The ST-MoE paper from Google observed that without z-loss, larger MoE models frequently experienced training instabilities that smaller models avoided. This scale-dependent behavior makes z-loss increasingly important as the field moves toward ever-larger MoE architectures.
Z-Loss Formulation
Router z-loss directly penalizes large logit magnitudes by adding a regularization term to the training objective. Rather than placing hard constraints on logit values, which would require constrained optimization techniques, z-loss uses soft regularization that integrates smoothly with standard gradient descent. The formulation targets the log-sum-exp of router logits, a smooth, differentiable proxy for the maximum logit that has particularly nice mathematical properties.
Mathematical Definition
For a batch of tokens, where token has router logits for expert , the z-loss is defined as:
where:
- : the router z-loss
- : the batch size (number of tokens)
- : the number of experts
- : the logit for token and expert
- : the log-sum-exp term approximating the maximum logit
Let's unpack this formula to understand how it works. The innermost part, , computes the sum of exponentials of all logits for a single token. This sum is exactly the normalization constant that appears in the denominator of the softmax function. Taking the logarithm of this sum gives us the log-sum-exp (LSE), which has a natural interpretation as a "soft maximum" of the logits.
The inner term is the log-sum-exp (LSE) of the logits for token . This function has a useful property that makes it ideal for our purposes: it approximates the maximum logit while remaining smooth and differentiable everywhere:
where:
- : the largest logit value for token
- : the total number of experts
- : the maximum bound on the approximation error
This inequality tells us that the LSE always lies between the maximum logit and the maximum logit plus . For typical expert counts (8, 16, or 64 experts), is a small constant (approximately 2, 2.8, or 4.2 respectively), so the LSE closely tracks the maximum logit. However, unlike the hard maximum function, which has discontinuous gradients at points where multiple logits are tied, the LSE is smooth everywhere. This smoothness is crucial for gradient-based optimization.
Squaring this quantity and averaging across tokens creates a penalty that grows quadratically as logits increase. The squaring operation has two important effects: it ensures the loss is always non-negative, and it provides increasingly strong regularization as logits grow. A token with LSE value of 10 contributes 100 to the loss, while a token with LSE value of 20 contributes 400. This quadratic growth creates strong pressure to keep logits bounded without overly penalizing moderate values.


Why Log-Sum-Exp?
The log-sum-exp formulation has several advantages over alternative approaches to constraining logit magnitudes. These advantages show why this design is standard:
-
Smooth gradients: Unlike penalties on (which has discontinuous gradients at points where the maximum switches from one logit to another) or (which penalizes all logits equally regardless of their relative magnitudes), LSE smoothly emphasizes the largest logits while providing gradients to all experts. When one logit is much larger than the others, the LSE gradient is concentrated on that logit. When multiple logits are similar, the gradient is distributed among them. This smooth interpolation between these cases makes optimization well-behaved.
-
Scale awareness: The LSE naturally captures the "effective scale" of the logit distribution in a way that considers both the maximum value and the spread. For example, a distribution with logits has an LSE of approximately , while a distribution with logits has an LSE of approximately . Although both produce identical uniform probability distributions (and thus have the same entropy), their LSE values differ significantly, correctly reflecting that the larger logits pose greater stability risks.
-
Numerical stability: The LSE is itself computed stably using the max-subtraction trick, avoiding the very overflow issues we're trying to prevent. Modern deep learning frameworks implement numerically stable versions of log-sum-exp that never overflow, making z-loss robust to compute even when logits have already drifted to large values. This means z-loss can be applied as a corrective measure even when training has already started experiencing instability.
Gradient Analysis
To understand the effect of z-loss on training dynamics, we derive its gradient with respect to the router logit . This derivation reveals how the loss creates corrective pressure on large logits. Applying the chain rule to the squared term:
where:
- : the gradient of the loss with respect to a specific logit
- : the batch size
- : the log-sum-exp value for token
- : the probability assigned to expert
The key insight in this derivation is that the derivative of the log-sum-exp with respect to one of its inputs is exactly the corresponding softmax probability. This elegant relationship emerges from the structure of the exponential function and is a standard result in deep learning.
This gradient formula reveals important behavior that explains why z-loss is effective:
-
The gradient is proportional to the current softmax probability: experts receiving more routing get larger gradients pushing their logits down. This is exactly what we want, as the experts with the largest logits (and therefore highest probabilities) receive the strongest corrective signal. Experts that are already receiving little routing probability receive only small gradients from z-loss, allowing them to remain available for future routing without being artificially suppressed.
-
The gradient scales with the current LSE value: larger logits create stronger corrective pressure. When the LSE is small (indicating well-behaved logits), the z-loss gradient is correspondingly small and doesn't interfere much with task learning. When the LSE grows large (indicating potential instability), the gradient grows proportionally, creating a stronger restoring force.
-
The quadratic nature (from squaring) provides increasingly strong regularization as logits grow. The factor of 2 from the power rule, combined with the LSE scaling, means the gradient grows faster than linearly with logit magnitude. This provides gentle regularization for moderate logits but strong correction for extreme values, striking a balance between allowing useful routing patterns and preventing numerical instability.


Why Z-Loss Works
Z-loss addresses router instability through several complementary mechanisms that work together to maintain training stability. These mechanisms explain why this regularization works.
Bounded Logit Growth
By continuously penalizing large LSE values, z-loss creates a restoring force that counteracts the natural drift toward larger logits. Whenever logits grow too large, the z-loss gradient pushes them back down. This establishes an equilibrium where the router learns discriminative logit patterns without unbounded growth. The router can still learn to prefer certain experts for certain inputs, but the absolute magnitude of the preferences remains bounded.
The key insight is that useful routing doesn't require extreme logits. A router with logits can effectively route to expert 1 with probability approximately 0.54, which is sufficient to ensure expert 1 is selected in top-2 routing. Increasing these to makes the probability approximately 0.999999, but this extreme confidence adds no practical benefit while creating numerical hazards. The routing decision is the same in both cases, but the numerical properties are vastly different.
This equilibrium behavior is similar to other regularization techniques like weight decay, which creates restoring forces that prevent unbounded parameter growth. The difference is that z-loss specifically targets the router logits, which are the quantities most directly responsible for numerical stability in MoE training.
Softmax Temperature Effect
Z-loss implicitly encourages a "softer" probability distribution over experts, as if the softmax were computed at a higher temperature. By penalizing the logit scale, it prevents the extremely peaked distributions that arise from large logit differences. When logit differences are bounded, the resulting probability distributions maintain non-trivial probabilities for multiple experts rather than concentrating all probability mass on a single expert.
This softer routing has several benefits that extend beyond mere numerical stability:
-
Better gradient flow: Non-zero probabilities for multiple experts mean gradients flow to more expert parameters during each training step. Even experts that aren't selected still receive gradient signals through the softmax probabilities, allowing them to continue learning and remain competitive. This prevents the "rich get richer" dynamic where selected experts improve while others stagnate.
-
Improved exploration: The router remains willing to try alternative experts rather than fixating on past choices. Soft probabilities mean that stochastic routing (if used) can occasionally select non-preferred experts, allowing the model to discover better routing patterns. Even with deterministic top-k routing, softer probabilities mean the router can more easily shift its preferences as the experts evolve during training.
-
Smoother learning: Gradual probability shifts rather than sudden expert switches create more stable training dynamics. When routing probabilities can change continuously rather than jumping between extremes, the experts experience more consistent training signals. This consistency helps experts develop coherent specializations rather than being whipsawed by sudden changes in their token assignments.


Regularization Properties
Beyond stability, z-loss provides genuine regularization that improves generalization to new data. By preventing overconfident routing, it encourages the model to develop routing patterns that depend on genuine, robust input features rather than spurious correlations or memorized associations. The regularization effect is similar to adding noise or using dropout, both of which prevent overconfident predictions.
Models trained with z-loss often show better performance on held-out data, particularly for inputs that differ from training distributions. When the router is forced to maintain some uncertainty in its routing decisions, it learns to base those decisions on stable, generalizable features rather than memorizing specific training examples. This improved generalization is especially valuable in language models, which must handle diverse inputs that may differ substantially from training data.
The regularization benefit of z-loss complements the stability benefit: both arise from the same mechanism of preventing extreme logit values, but they manifest in different ways. Stability is visible during training as the absence of loss spikes and gradient explosions. Regularization is visible during evaluation as improved performance on out-of-distribution inputs.
Z-Loss Coefficient
The z-loss coefficient controls the strength of logit regularization and represents the primary hyperparameter that you must tune when using this technique:
where:
- : the combined training objective
- : the primary task loss
- : the z-loss weighting coefficient
- : the auxiliary z-loss term
Choosing an appropriate coefficient requires balancing stability against routing effectiveness. Too small a coefficient provides insufficient regularization and allows instability. Too large a coefficient over-regularizes the router, preventing it from learning sharp routing patterns that enable expert specialization. The optimal coefficient lies in a middle ground that must be found empirically for each setting.
Coefficient Guidelines
Typical z-loss coefficients fall in the range to , with several factors influencing the optimal choice:
-
Model scale: Larger models often need stronger z-loss (higher ) because they have more capacity for logit growth. The router network in a large model has more parameters and processes higher-dimensional representations, giving it more "room" to develop extreme logit patterns. The longer training runs typical of larger models also provide more time for drift to accumulate.
-
Number of experts: More experts slightly increase the LSE for a given max logit because of the term in the LSE bounds, so the coefficient may need adjustment. However, this effect is typically small compared to other factors, since grows slowly with the number of experts.
-
Training stability requirements: If training instabilities occur despite using z-loss, increasing by 2-5x often helps stabilize training. This is a common first response to observed instability. However, if instabilities persist even with high z-loss coefficients, other factors like learning rate or batch size may need adjustment.
-
Routing sharpness: Very high can make routing too soft, reducing the benefit of expert specialization. When routing becomes nearly uniform, different experts receive similar token mixtures, preventing them from developing distinct specializations. Monitoring expert utilization and specialization can reveal if the z-loss coefficient is too high.
The ST-MoE paper used as a starting point, finding it sufficient to stabilize training while preserving routing quality. This value has become a common default in subsequent MoE implementations, though you should treat it as a starting point rather than a universal optimum.
Tuning Strategy
A practical approach to setting the z-loss coefficient involves the following steps, which balance systematic exploration with responsive adjustment:
-
Start conservative: Begin with and monitor training stability. This conservative starting point provides some regularization without being so strong that it prevents useful routing patterns from developing. Most training runs will be stable at this coefficient.
-
Track LSE statistics: Log the mean and max LSE values across training batches. Healthy values typically stay below 10, though this depends on the number of experts. If LSE values grow steadily throughout training, the z-loss coefficient may need to be increased. If LSE values drop quickly to very small values, the coefficient may be too high.
-
Watch for instability: If loss spikes or NaN gradients occur, increase by 2-5x. These events indicate that the current regularization strength is insufficient to prevent numerical problems. After increasing the coefficient, training may need to restart from an earlier checkpoint before the instability occurred.
-
Check routing quality: If routing becomes too uniform (all experts receiving similar load), reduce . Uniform routing defeats the purpose of having multiple experts, since all experts would receive the same training signal and develop similar capabilities. Some variation in expert load is healthy and indicates that the router is learning useful distinctions.
-
Validate on held-out data: Ensure z-loss isn't hurting generalization through over-regularization. While z-loss typically improves generalization by preventing overconfident routing, excessively strong regularization could prevent the model from learning useful routing patterns altogether.
Dynamic Coefficient Schedules
Some implementations use dynamic z-loss coefficients that change during training, adapting the regularization strength to the needs of different training phases:
-
Warmup: Start with higher during early training when instabilities are most common, then reduce as training stabilizes. Early training often sees rapid parameter changes that can push logits to extreme values, making strong regularization especially valuable. As training converges and parameters change more slowly, weaker regularization allows sharper routing.
-
Curriculum: Increase as model scale grows during progressive training. Some training approaches start with a small model and gradually increase its size. As the model grows, the capacity for logit drift increases, motivating stronger regularization.
-
Adaptive: Adjust based on observed LSE statistics, increasing when values exceed a threshold and decreasing when values are safely bounded. This approach automatically responds to the actual training dynamics rather than following a predetermined schedule.
Combined Auxiliary Losses
Real MoE systems use both load balancing loss (from the previous chapter) and z-loss together. These losses address complementary problems and work synergistically to create stable, effective MoE training. Neither loss alone is sufficient: load balancing without z-loss can still experience numerical instability, while z-loss without load balancing allows expert collapse and utilization imbalance.
Joint Objective
The complete MoE training objective combines the task loss with both auxiliary losses:
where:
- : the complete joint objective
- : the primary task loss
- : the auxiliary balancing loss (encourages uniform expert utilization)
- : the z-loss (prevents logit instability)
- : weighting coefficients for the auxiliary terms
This combined objective guides the model toward three goals simultaneously: achieving good task performance, maintaining balanced expert utilization, and preserving numerical stability. The relative importance of these goals is controlled by the two auxiliary coefficients.
Complementary Roles
The two auxiliary losses serve distinct purposes that together create a robust training framework:
| Aspect | Load Balancing Loss | Z-Loss |
|---|---|---|
| Target | Expert load distribution | Router logit magnitudes |
| Problem addressed | Expert collapse, imbalanced utilization | Numerical instability, gradient issues |
| Mechanism | Penalizes deviation from uniform load | Penalizes large log-sum-exp values |
| Effect on routing | Encourages diversity | Encourages softness |
Load balancing loss ensures that all experts are used and that no expert becomes overloaded or underutilized. Z-loss ensures that the routing computation itself remains numerically stable. These concerns are orthogonal: a model could have perfectly balanced load with numerically unstable logits, or stable logits with highly imbalanced load. Both auxiliary losses are needed to achieve both goals.
Interaction Effects
The two losses can interact in subtle ways that you should understand:
-
Synergy: Z-loss keeps routing soft, making it easier for load balancing to spread tokens across experts. Hard routing with very peaked probabilities resists load balancing pressure because the gradient from load balancing loss is proportional to softmax probabilities. When probabilities are nearly binary (0.99 for one expert, 0.01 for others), the load balancing gradient can only adjust the dominant expert's logit. Softer probabilities distribute the gradient across all experts, making load balancing more effective.
-
Tension: Very strong z-loss ( too high) can make routing nearly uniform, reducing the importance of load balancing. When z-loss forces all logits to be similar, the resulting routing probabilities are already close to uniform regardless of load balancing. In this regime, further increasing load balancing coefficient has little effect. Conversely, aggressive load balancing might push some expert logits up to attract more tokens, which increases z-loss.
-
Balance: Finding the right coefficient combination requires considering both effects. A common starting point is and , making load balancing the stronger constraint with z-loss providing background stabilization. This ratio reflects the fact that expert imbalance is typically a more pressing problem than numerical instability in early training, though both must be controlled.
Implementation
Let's implement z-loss and observe its effect on router behavior. We'll build on the MoE infrastructure from previous chapters.
Z-Loss Computation
The core z-loss computation follows directly from the mathematical definition.
The z-loss increases dramatically with logit scale, providing strong incentive to keep logits bounded.

Router with Z-Loss
Now let's create a router class that computes both routing probabilities and the z-loss.
Visualizing Z-Loss Effects
Let's visualize how z-loss affects logit distributions during training.


Without z-loss, the logit magnitudes grow freely. With z-loss applied, the optimizer continuously pushes logits back toward smaller values, establishing a stable equilibrium.
Complete MoE with Combined Losses
Let's implement a complete MoE layer that computes both load balancing and z-loss.
The model processes the input shape [4, 16, 128] and produces a matching output shape. The auxiliary losses are non-zero, indicating that both balancing and z-loss constraints are active and contributing to the training objective.
Monitoring Auxiliary Losses
During training, tracking both auxiliary losses helps diagnose issues.



The auxiliary losses quickly reach stable values while the task loss continues to improve. This indicates healthy MoE training where routing stability is maintained without interfering with model learning.
Expert Load Distribution
We can also track how the auxiliary losses affect expert utilization.

The combined effect of load balancing loss and z-loss produces well-distributed expert utilization, close to the ideal uniform distribution.
Key Parameters
The key parameters for the MoE layer with z-loss are:
- aux_loss_coeff: Weighting coefficient for the load balancing loss (typically ~0.01).
- z_loss_coeff: Weighting coefficient for the router z-loss (typically 1e-4 to 1e-2).
- num_experts: Total number of experts in the layer.
- top_k: Number of experts active for each token (usually 1 or 2).
Limitations and Impact
Router z-loss has proven essential for stable MoE training at scale, but it comes with trade-offs worth understanding.
The primary limitation is that z-loss introduces an additional hyperparameter () that must be tuned. While default values work reasonably well across many settings, the optimal coefficient depends on model architecture, training dynamics, and the specific task. Setting too high can over-regularize the router, making it unable to develop sharp routing patterns that let experts specialize effectively. Too low, and the stability benefits disappear. This adds complexity to the already challenging process of training large MoE models.
Z-loss also has subtle interactions with other training choices. Batch size affects the LSE statistics, meaning coefficients tuned for one batch size may not transfer directly to another. Learning rate schedules that cause rapid parameter changes can temporarily spike router logits, triggering large z-loss gradients that may disrupt training. You might find that z-loss requires more careful warmup schedules than load balancing loss alone.
Despite these considerations, z-loss has become a standard component of MoE training. The ST-MoE paper demonstrated that without z-loss, larger MoE models frequently experienced training instabilities: loss spikes, gradient explosions, and in some cases complete training collapse. With z-loss, these same models trained smoothly to completion. This stability benefit scales with model size, becoming more important as MoE architectures grow larger.
The technique also provides a useful diagnostic. Monitoring z-loss values during training reveals router health: steadily increasing z-loss suggests the router is drifting toward instability, even before overt failures occur. This early warning allows you to intervene by adjusting coefficients or learning rates before training derails.
Looking ahead to the next chapter on expert parallelism, z-loss becomes even more important. Distributed training across multiple devices introduces additional sources of instability from gradient synchronization and communication delays. The regularization provided by z-loss helps maintain consistent router behavior across the distributed system.
Summary
Router z-loss addresses a critical but often overlooked problem in MoE training: the tendency for router logits to grow unboundedly, causing numerical instabilities that can derail training. The key concepts are:
-
The instability problem: Router logits naturally drift toward larger values during training because nothing explicitly constrains them. Large logits cause softmax overflow, gradient instability, and poor generalization.
-
Z-loss formulation: The z-loss penalizes the squared log-sum-exp of router logits, . This provides smooth gradients that push large logits back toward reasonable values.
-
Stabilization mechanism: Z-loss creates a restoring force that counteracts logit drift, maintaining bounded logits throughout training without preventing the router from learning discriminative patterns.
-
Coefficient selection: Typical values range from to , with larger models often needing higher coefficients. Start conservative and adjust based on observed LSE statistics and training stability.
-
Combined auxiliary losses: Z-loss works alongside load balancing loss to address complementary problems. Load balancing encourages uniform expert utilization while z-loss ensures numerical stability. The combined objective is .
With both auxiliary losses in place, MoE models train stably while maintaining balanced expert utilization. The next chapter explores expert parallelism: how to distribute MoE computation across multiple devices efficiently.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about router z-loss and its role in stabilizing MoE training.

Comments