
Master learning rate strategies for fine-tuning transformers. Learn discriminative fine-tuning, layer-wise decay, warmup schedules, and decay methods.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Fine-tuning Learning Rates
When you fine-tune a pre-trained language model, choosing the right learning rate is more important than when training from scratch. A learning rate that works well for pre-training can destroy months of computational effort in minutes of fine-tuning. Conversely, a learning rate that's too small might never adapt the model to your task. The challenge lies in finding the narrow band of learning rates that enable meaningful adaptation without erasing the knowledge the model has already acquired. This chapter explores specialized learning rate strategies developed specifically for fine-tuning: discriminative fine-tuning, layer-wise learning rate decay, warmup schedules, and decay strategies that help navigate the delicate balance between adaptation and preservation.
The Fine-tuning Learning Rate Challenge
As we discussed in the previous chapter on catastrophic forgetting, fine-tuning involves a fundamental tension. You want the model to learn task-specific patterns, but you don't want to overwrite the rich linguistic knowledge acquired during pre-training. Learning rates sit at the heart of this tension because they directly control how much each gradient update changes the model's parameters.
During pre-training, models typically use learning rates between and with the Adam optimizer. These relatively large rates help the model explore the parameter space efficiently when learning from scratch. At this stage, there is nothing to preserve: the model begins with random weights, and large updates are not only safe but necessary for making rapid progress across billions of training tokens. But fine-tuning presents a fundamentally different scenario: you're starting from a carefully optimized point that already captures meaningful language structure. The pre-trained weights represent a local minimum that took enormous computational resources to reach, and this minimum encodes valuable knowledge about syntax, semantics, and world knowledge. Large updates can push parameters far from this optimum, destroying valuable representations that took the original training process millions of gradient steps to construct.
The standard solution is to use much smaller learning rates for fine-tuning, typically in the range of to for BERT-style models. This reduction of roughly one to two orders of magnitude reflects the different nature of the optimization problem: rather than exploring a vast parameter landscape, we are making careful adjustments around an already-good solution. But even this simple observation raises deeper questions:
- Should all layers receive the same learning rate?
- Should the rate start small and grow, or start larger and decay?
- How do these choices interact with different model architectures?
The strategies we'll explore in this chapter emerged from attempts to answer these questions systematically. Rather than treating fine-tuning as simply "training with a smaller learning rate," we have developed nuanced approaches that consider which parts of the model need to change and by how much.
Discriminative Fine-tuning
Discriminative fine-tuning assigns different learning rates to different parts of the model based on the intuition that not all parameters should adapt equally. This approach recognizes that a pre-trained language model is not a monolithic entity but rather a hierarchy of representations, each capturing different levels of linguistic abstraction.
A fine-tuning strategy where different parameter groups receive different learning rates, typically with lower layers learning more slowly than higher layers to preserve general features while allowing task-specific adaptation.
Different layers in a neural network learn different features. Deep networks develop a natural hierarchy: lower layers in transformer models capture general linguistic patterns such as tokenization boundaries, basic syntax, and fundamental semantic relationships. These patterns apply broadly across virtually any language task you might encounter. Higher layers capture more task-specific features that build on these foundations, developing representations increasingly tailored to the pre-training objective. When fine-tuning for a specific task, you want to:
- Preserve lower-layer representations: These capture transferable knowledge that applies across tasks. The basic understanding of language structure, word relationships, and syntactic patterns learned in these layers will be useful regardless of whether you're doing sentiment analysis, question answering, or named entity recognition.
- Adapt higher-layer representations: These need to specialize for your specific task. The upper layers, which were optimized for masked language modeling or next-token prediction, need to reconfigure their representations to support your new objective.
- Train the new task head aggressively: This is entirely task-specific and needs full adaptation. Unlike the pre-trained backbone, the task head starts from random initialization and has no prior knowledge to preserve.
This suggests a natural structure: assign progressively larger learning rates as you move up through the network. Lower layers receive small learning rates that allow only gentle adjustments, nudging the representations slightly while preserving their overall structure. Higher layers receive larger rates that enable substantial adaptation to the new task. The task-specific head receives the largest rate of all, allowing it to rapidly learn the mapping from pre-trained representations to task outputs.
Mathematical Formulation
To implement discriminative fine-tuning, we need a principled way to assign learning rates across layers. The most common approach uses geometric decay, where each step down the network reduces the learning rate by a constant factor. This creates a smooth gradient of adaptation rates that respects the hierarchical nature of the model's representations.
Let's denote the base learning rate as and define a decay factor (typically between 0.9 and 0.95). For a model with layers, layer receives learning rate:
where:
- : the learning rate assigned to layer (the value we compute)
- : the base learning rate assigned to the top layer (typically the highest rate in the backbone)
- : the multiplicative decay factor (usually 0.9 to 0.95), which scales down the rate for each step down the network
- : the total number of layers in the model
- : the index of the current layer (where is the top layer, is the bottom transformer layer, and embeddings are treated as )
The key to this formulation is the exponent , which represents the layer's distance from the top of the network. Consider how this distance-based calculation works in practice. The top layer () has a distance of 0, so , receiving the full base rate . Each subsequent layer down increases the distance by 1, compounding the decay factor . This compounding effect means that the learning rate doesn't just decrease linearly as we move down the network; instead, it decreases geometrically, with each layer receiving a fixed fraction of the rate assigned to the layer above it.
Geometric decay ensures that the relative difference between adjacent layers remains constant throughout the network. If layer 10 receives 95% of the rate of layer 11, then layer 5 also receives 95% of the rate of layer 6. This proportional relationship ensures that the adaptation dynamics remain consistent regardless of which part of the network we examine.
For a 12-layer BERT model with and :
| Layer | Learning Rate |
|---|---|
| Layer 12 (top) | |
| Layer 11 | |
| Layer 10 | |
| Layer 6 | |
| Layer 1 (bottom) | |
| Embeddings |
This creates a smooth gradient of adaptation rates throughout the network. Notice that even the bottom layer still receives a meaningful learning rate, roughly half of the top layer's rate. This reflects the philosophy that all layers should be allowed to adapt, just to different degrees. The embeddings receive the lowest rate because they encode fundamental vocabulary semantics that should remain maximally stable across different downstream tasks.
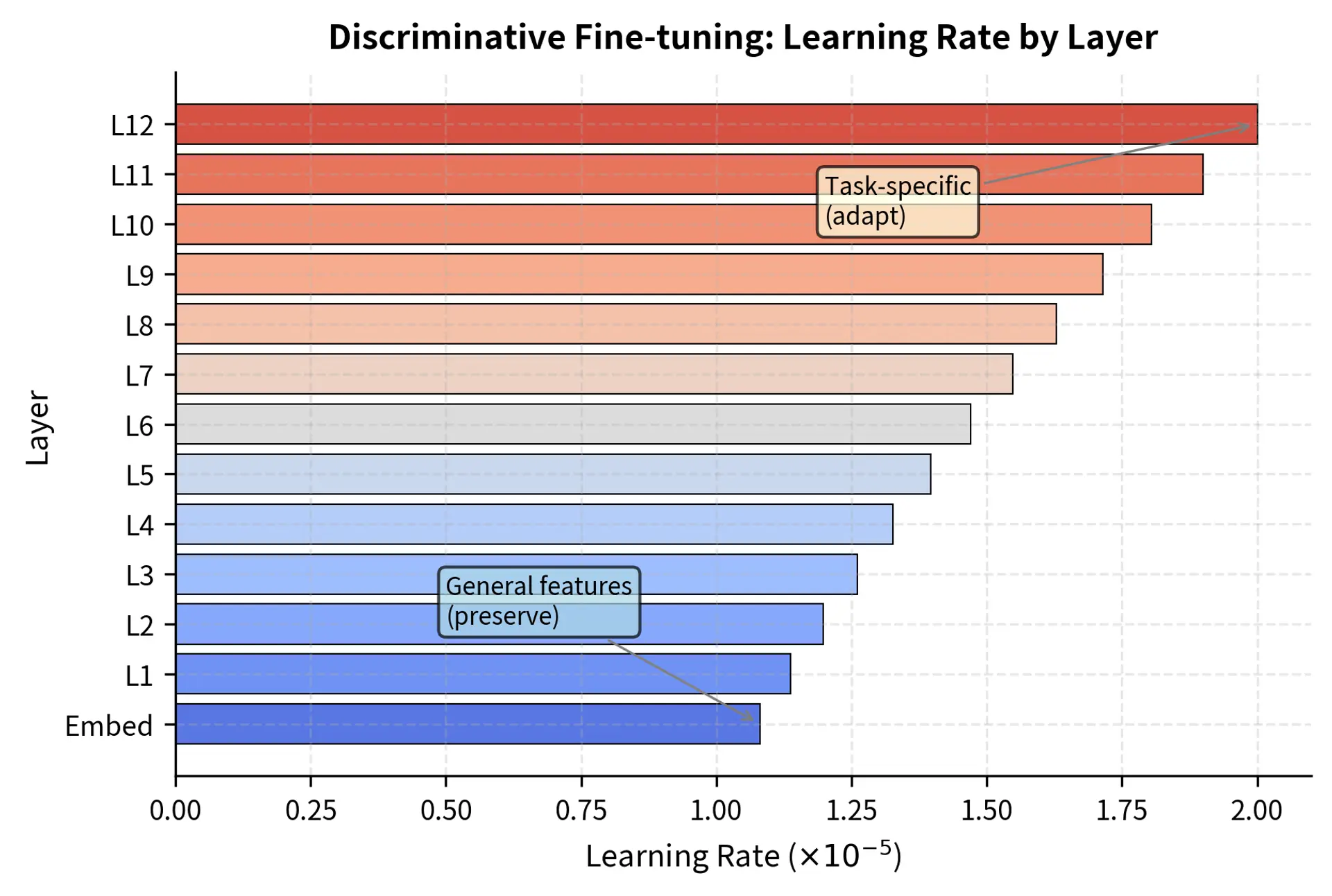
Layer-wise Learning Rate Decay
Layer-wise learning rate decay (LLRD) is the most common implementation of discriminative fine-tuning for transformer models. It was popularized by the ULMFiT paper and has become standard practice for fine-tuning BERT and similar models. While the underlying mathematics are identical to discriminative fine-tuning, LLRD specifically emphasizes the layer-by-layer structure of modern transformer architectures and has been refined through extensive empirical study.
Why Layer Position Matters
LLRD works because transformer representations are hierarchical. Varying learning rates by layer is based on research into what each layer learns during pre-training. Research on probing tasks, where simple classifiers are trained on frozen layer representations, has systematically mapped out this hierarchy:
- Embedding layers capture lexical semantics and basic word relationships. At this level, the model encodes what words mean in isolation and how they relate to other words with similar meanings. These representations are highly general and transfer well to virtually any downstream task.
- Lower transformer layers (1-4 in BERT) capture syntactic structure and local dependencies. These layers develop sensitivity to part-of-speech patterns, phrase boundaries, and local word order. They learn to distinguish nouns from verbs, identify subject-verb relationships, and recognize basic grammatical patterns.
- Middle layers (5-8) develop richer semantic representations that integrate local syntactic information with broader contextual meaning. These layers begin to capture coreference, semantic roles, and the flow of meaning across sentences.
- Upper layers (9-12) capture task-relevant features that are more specific to the pre-training objective. For a model trained with masked language modeling, these layers specialize in predicting missing words given context. This specialization is valuable but also means these representations are most tightly coupled to the pre-training task.
When fine-tuning for a downstream task, the upper layers typically need the most adaptation because they were optimized for the pre-training task (like masked language modeling) rather than your specific objective. Lower layers, which capture more universal linguistic properties that any NLP task would benefit from, need less adjustment. Aggressive updates to lower layers risk disrupting the carefully learned syntactic and semantic foundations that the entire model relies upon.
Implementing LLRD for Transformers
For transformer models, we typically define parameter groups corresponding to:
- Embedding layer: Token embeddings and position embeddings
- Encoder/decoder layers: Each transformer block as a separate group
- Task head: The newly added classification or regression layer
Let's examine the learning rate distribution across layers:
Learning rates decay geometrically through the layers. The embeddings receive the lowest rate (), ensuring the model's fundamental vocabulary representations remain stable. This stability is crucial because the embedding layer defines the basic semantic space that all other layers build upon. If embeddings shift dramatically during fine-tuning, the higher layers must relearn how to interpret these shifted representations, potentially causing cascading disruptions throughout the network.
This visualization shows the learning rate hierarchy. The embeddings and lower layers remain relatively stable to preserve fundamental language understanding, while the learning rate increases exponentially toward the task head to facilitate rapid adaptation to the new problem. The smooth progression ensures that no single layer boundary experiences a dramatic discontinuity in adaptation rates, which could create optimization instabilities.
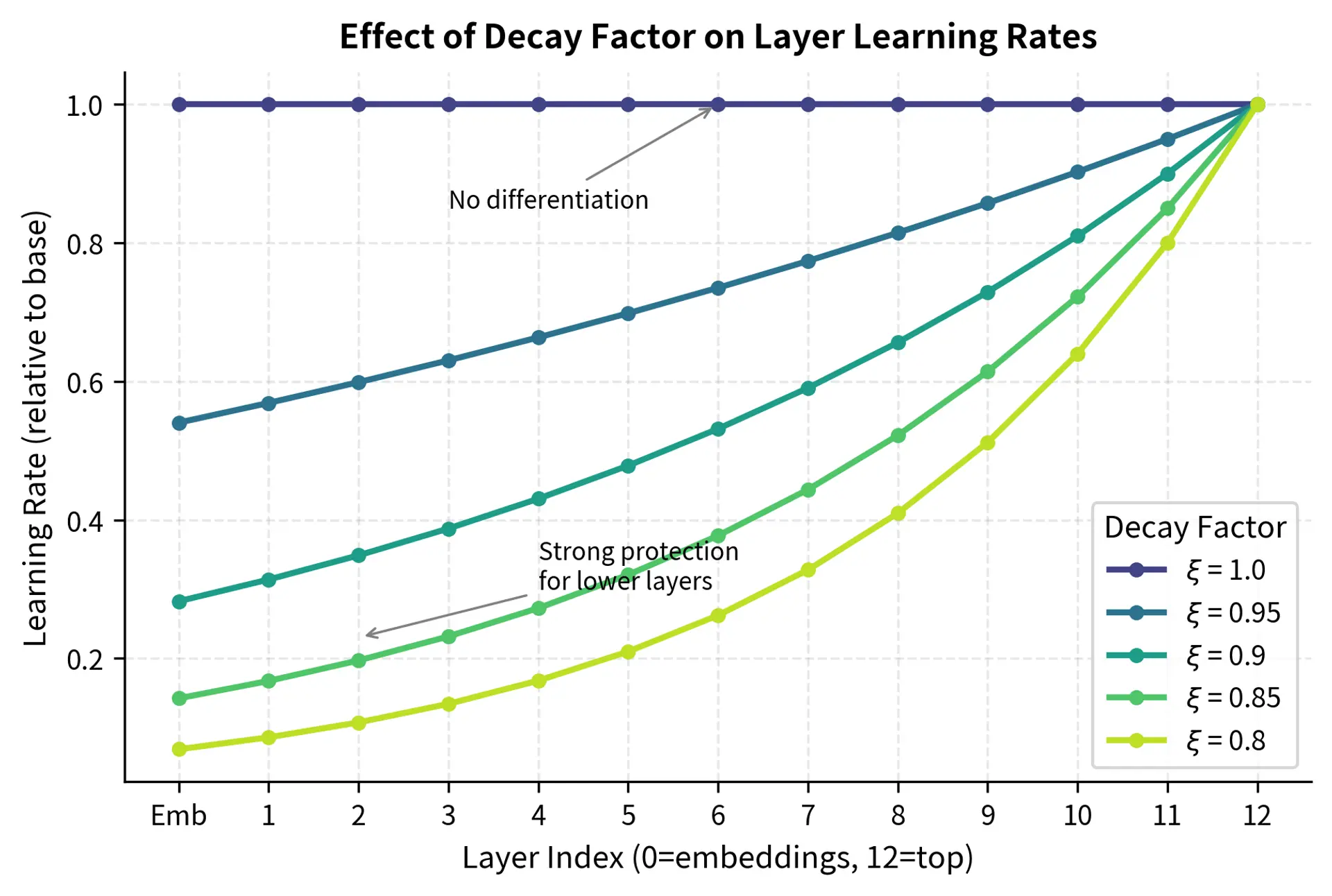
Choosing the Decay Factor
The decay factor controls how aggressively learning rates differ between layers, and choosing the right value requires balancing two competing concerns. A decay factor too close to 1.0 provides insufficient differentiation between layers, losing the benefits of discriminative fine-tuning. A decay factor too small may prevent lower layers from adapting at all, which can be problematic if your task requires the model to learn new low-level patterns. The optimal value depends on your task and how much the pre-trained representations need to change:
- : No decay; all layers receive the same learning rate (standard fine-tuning). This is equivalent to ignoring the hierarchical structure of the network and may be appropriate when you have abundant data and the task differs substantially from pre-training.
- : Gentle decay; good default for most NLP tasks. This creates roughly a 2:1 ratio between the top and bottom layer learning rates, providing differentiation while still allowing all layers to adapt meaningfully.
- : Moderate decay; useful when lower layers should change minimally. This creates approximately a 3:1 ratio and is appropriate when you have limited data or when the pre-training domain closely matches your target task.
- : Aggressive decay; for tasks very similar to pre-training. This can create ratios of 5:1 or greater and essentially "freezes" the lower layers by giving them very small learning rates.
Empirically, values between 0.9 and 0.95 work well for most transformer fine-tuning scenarios. When in doubt, 0.95 provides a safe starting point that rarely hurts performance and often helps.
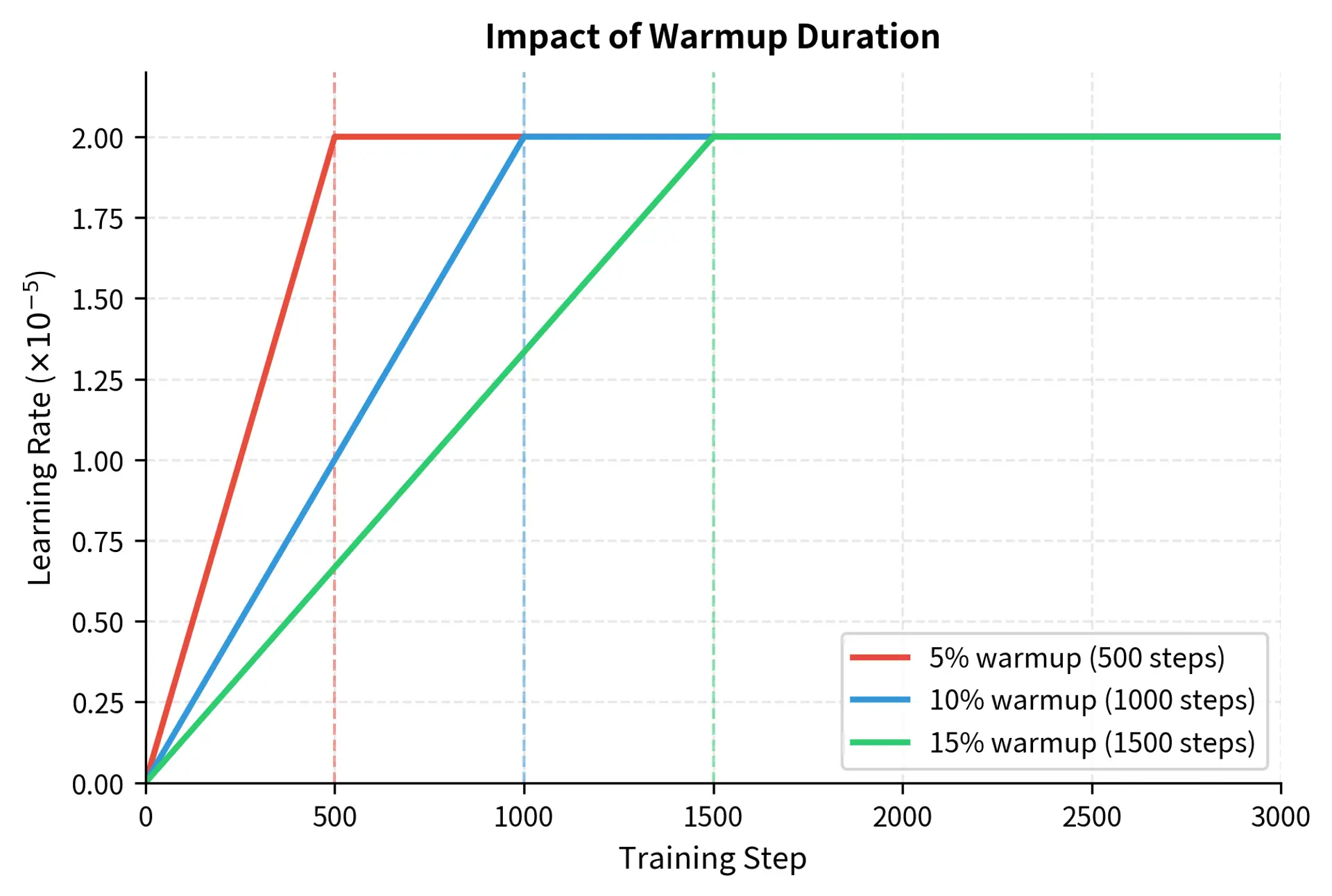
Learning Rate Warmup for Fine-tuning
Warmup refers to starting training with a very small learning rate and gradually increasing it to the target value. This technique is especially important for fine-tuning. While warmup was originally motivated by considerations specific to the Adam optimizer and very deep networks, its benefits during fine-tuning arise from slightly different concerns.
Why Warmup Matters for Fine-tuning
At the start of fine-tuning, several factors make large learning rates dangerous. Understanding these factors helps explain why warmup, which might seem like an unnecessary complication, provides substantial practical benefits:
-
Task head initialization: The newly added classification head is randomly initialized while the pre-trained backbone is well-optimized. This creates an asymmetry in the network: the backbone produces meaningful representations, but the randomly initialized head transforms these into essentially random predictions. The gradients flowing back from this random head can be large and poorly directed. Large initial updates from the random head can destabilize the entire network, propagating noise deep into the pre-trained layers. Warmup allows the task head to "catch up" to the backbone before the learning rate becomes large enough to cause damage.
-
Gradient variance: Early mini-batches may not be representative of the full dataset, leading to noisy gradient estimates. The first few batches might happen to contain unusual examples or reflect sampling artifacts rather than the true data distribution. Small learning rates during warmup prevent over-reacting to this noise, giving the optimizer time to aggregate gradient information from more representative samples.
-
Adam statistics: As we discussed in the Adam optimizer chapter, Adam maintains running estimates of gradient moments, specifically the first moment (mean) and second moment (variance) of the gradients. These estimates are unreliable early in training because they are initialized to zero and require many updates to become accurate. The bias correction terms in Adam help, but they don't fully compensate for the lack of historical information. Warmup gives these moment estimates time to stabilize before making large parameter updates that rely on their accuracy.
Linear warmup
The most common warmup schedule increases the learning rate linearly from 0 to the target value. This approach is simple to implement, easy to understand, and effective in practice:
where:
- : the learning rate at step
- : the current training step
- : the total number of warmup steps (defining the duration of the ramp-up phase)
- : the target learning rate to reach at the end of warmup (the peak rate)
The ratio represents the fraction of the warmup phase completed, scaling the learning rate linearly from 0 up to . At step 0, this ratio equals 0, so the learning rate is 0. At step , the ratio equals 1, so the learning rate reaches its target. The linear relationship means that the learning rate increases by a constant amount at each step, providing a predictable and smooth ramp-up.
For fine-tuning, warmup typically spans 5-10% of total training steps. For a fine-tuning run of 10,000 steps, you might use 500-1,000 warmup steps. This duration allows Adam's moment estimates to stabilize and the task head to begin learning patterns without wasting training time.
Let's visualize the warmup schedule:
This schedule prevents the optimizer from making dangerously large updates during the initial training phase, when gradient estimates are most volatile. The shaded warmup region represents the protective phase where the model's pre-trained knowledge is most vulnerable to disruption.
Gradual Unfreezing as Warmup
A more aggressive warmup strategy combines warmup with gradual unfreezing. Instead of training all layers from the start, you begin by training only the task head, then progressively unfreeze layers from top to bottom:
- Epoch 1: Train only the task head
- Epoch 2: Unfreeze top transformer layers
- Epoch 3: Unfreeze middle layers
- Epoch 4+: Train all layers
This approach, introduced in ULMFiT, provides an extreme form of "warmup" where lower layers literally receive zero gradient until later in training. The philosophy is that by the time lower layers are unfrozen, the task head and upper layers have already adapted substantially, providing more stable and informative gradients. While effective, gradual unfreezing requires more epochs and careful tuning of the unfreezing schedule. It has fallen somewhat out of favor for transformer fine-tuning because LLRD achieves similar goals with less complexity, but it remains a useful technique when maximum caution is warranted.
Learning Rate Decay
After warmup completes, learning rate decay schedules reduce the rate throughout training. This helps the model converge to a stable minimum rather than oscillating around it. The intuition is that large learning rates are useful early in training when the model needs to make significant adjustments, but become counterproductive later when the model is close to a good solution and only needs fine adjustments.
Linear Decay
The simplest decay schedule reduces the learning rate linearly to zero (or some minimum value) by the end of training. This approach provides a steady, predictable reduction in learning rate that is easy to reason about and implement:
where:
- : the learning rate at step
- : the learning rate at the start of decay (end of warmup)
- : the current training step
- : the step number where decay begins
- : the total number of training steps
The structure of this formula becomes clearer when we break it into parts. The fraction represents the progress through the decay phase, ranging from 0 at the start of decay to 1 at the final step. Subtracting this from 1 yields the remaining proportion of the learning rate, creating a steady linear decline from down to 0. At each step during the decay phase, the learning rate decreases by exactly the same amount, ensuring a uniform reduction throughout training.
This is the default schedule for most BERT fine-tuning recipes because it strikes a reasonable balance between simplicity and effectiveness.
Cosine Decay
Cosine decay provides a smoother transition that decays slowly at first, accelerates in the middle, and slows again near the end. This schedule has become increasingly popular because it maintains higher learning rates for longer during the middle of training, allowing the optimizer more opportunity to explore the loss landscape before settling into a final minimum:
where:
- : the learning rate at step
- : the minimum learning rate to reach at the end of training
- : the target learning rate at the start of decay
- : the current training step
- : the step number where decay begins
- : the total number of training steps
We can trace the mathematical transformations to see how this formula produces an S-curve:
- Progress Ratio: The term goes from 0 to 1 as training proceeds through the decay phase. This is the same progress measure used in linear decay.
- Angle Mapping: Multiplying by converts this linear progress to an angle from 0 to radians. This mapping is what transforms linear progress into the characteristic cosine shape.
- Cosine Transform: Taking the cosine of this angle produces values that vary smoothly. At the start of decay, , and at the end, . Crucially, the rate of change of cosine is zero at both endpoints and maximal in the middle.
- Scaling: The term shifts the range from to . This is then halved (yielding a range of ) and scaled by the learning rate difference . Adding shifts the final result to the desired range.
This results in a learning rate that decreases slowly at the start and end of training, with a faster decrease in the middle.
Let's compare these decay schedules:
While all three schedules eventually reach zero, they allocate learning rate differently throughout training. Cosine decay maintains higher learning rates for longer in the middle of training, potentially allowing the model to escape local minima more effectively than linear decay. Polynomial decay with power 2 drops quickly at first and then more slowly, front-loading the high learning rate period. The choice between these schedules represents a trade-off between exploration and convergence speed.
Choosing a Decay Schedule
The choice of decay schedule depends on your training dynamics and the specific characteristics of your task:
- Linear decay: Simple and effective; good default for short fine-tuning runs. The predictable reduction makes it easy to reason about training dynamics and diagnose issues.
- Cosine decay: Often slightly better performance; allows more learning early and late in training. The gentler decay at both ends can help the model both explore better initially and converge more precisely at the end.
- Polynomial decay: Useful when you want to front-load learning (higher powers) or extend it (lower powers). This provides more control over the shape of the decay curve.
Empirically, cosine and linear decay perform similarly for most fine-tuning tasks, with cosine sometimes providing a small improvement. The difference is often smaller than the effect of other hyperparameters like the base learning rate or batch size, so either choice is reasonable for most applications.
Complete Implementation
Let's combine all these techniques into a complete fine-tuning setup. We'll create a training configuration that uses layer-wise learning rate decay, warmup, and cosine decay. This implementation demonstrates how the individual components we've discussed work together in practice.
Let's see this in action with a simple classification task:
In this configuration, the task head has a higher learning rate () than the embeddings. This hierarchy ensures that the randomly initialized task head can adapt quickly while the pre-trained backbone layers are updated more cautiously.
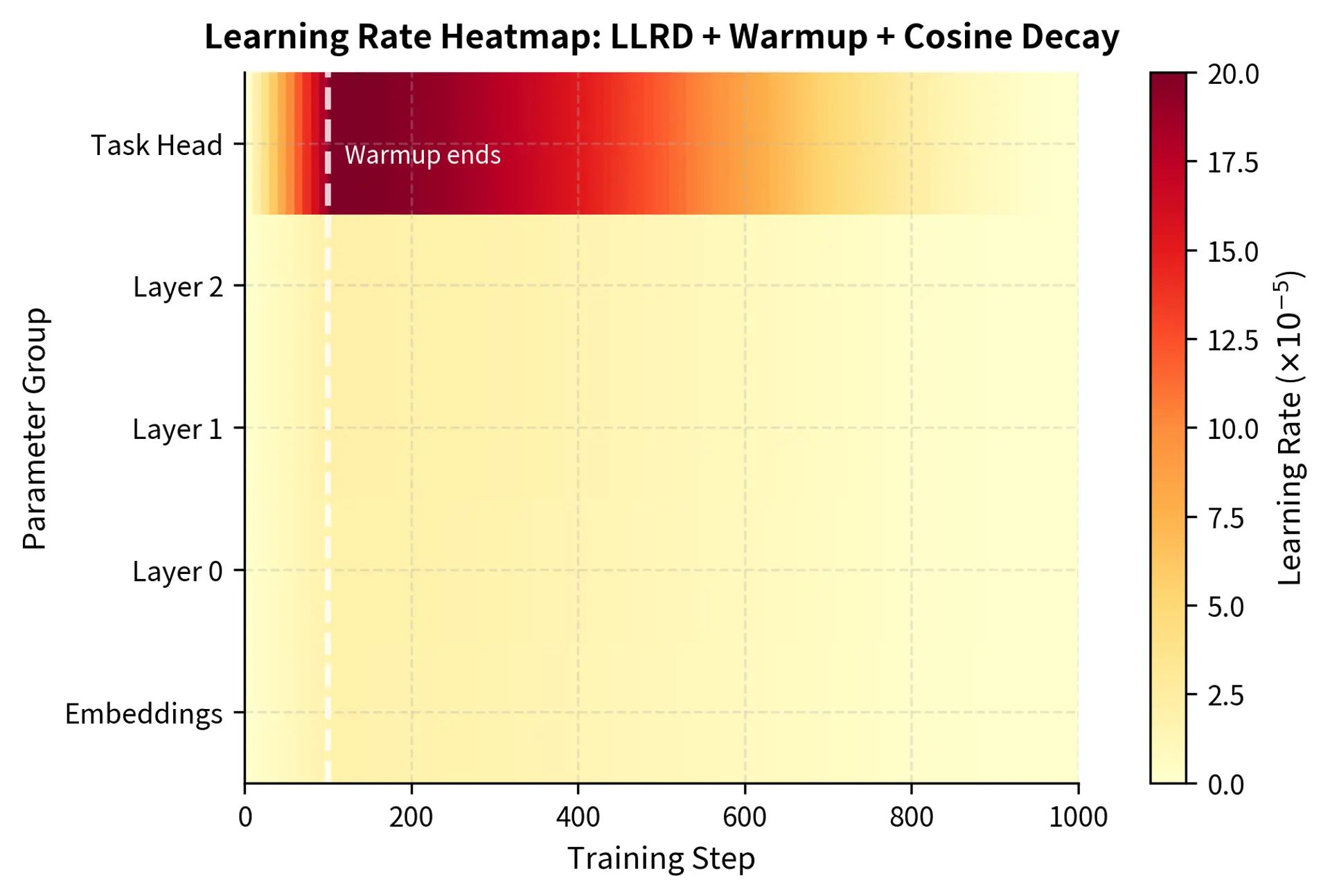
Now let's simulate a training run and visualize how learning rates evolve:
The separate trajectories show the combined effect of our strategies: all layers warm up together, but they peak at different values due to LLRD, and then decay in sync according to the cosine schedule. The task head's learning rate (shown at the top) is an order of magnitude larger than the embeddings' rate throughout training, reflecting our confidence that the task head needs rapid adaptation while the embeddings should remain relatively stable.
Complete Training Loop Example
Here's how these components integrate into a complete fine-tuning loop:
Practical Guidelines
Based on extensive empirical research, here are practical recommendations for fine-tuning learning rates:
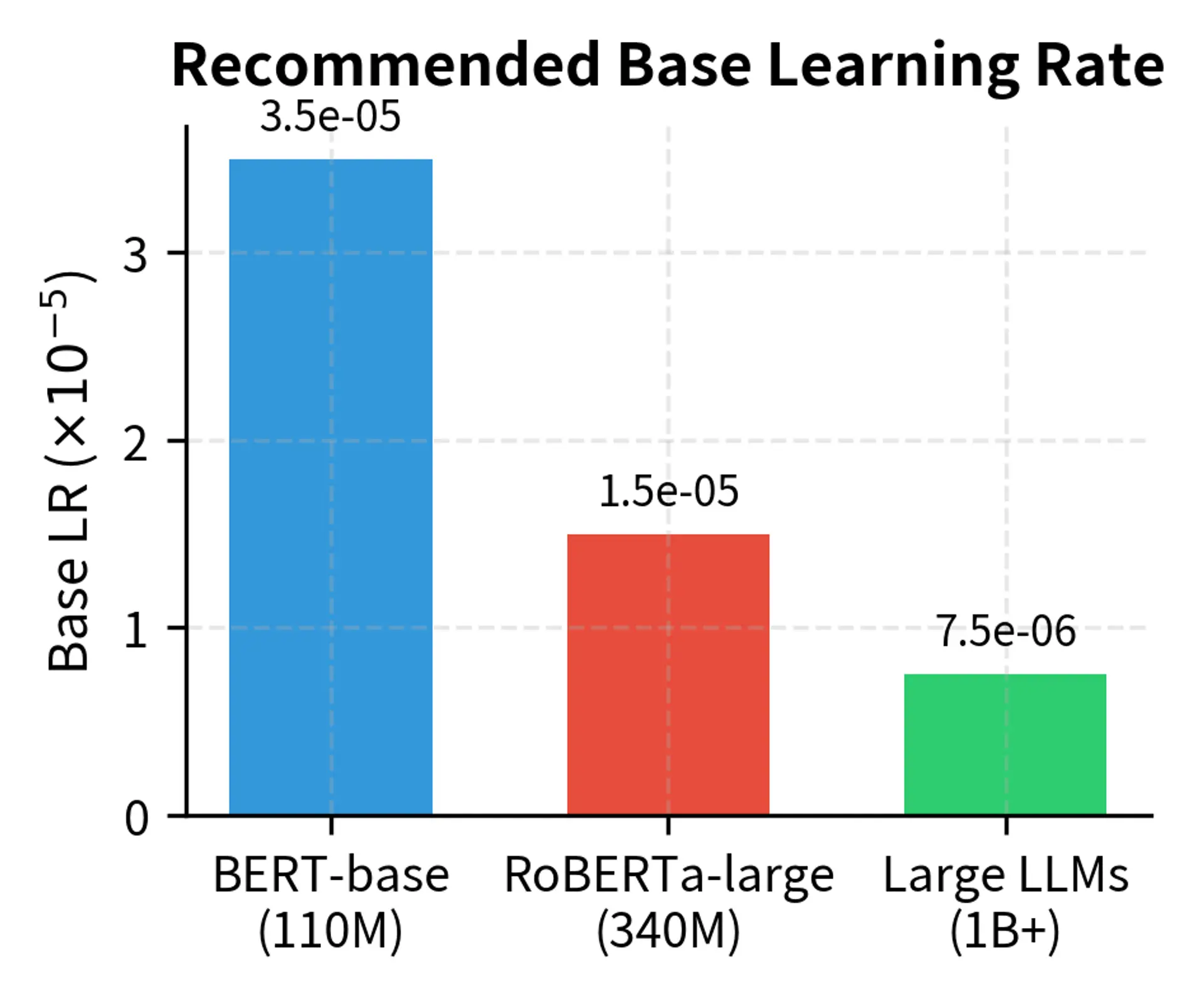
For BERT-base and similar models (110M parameters):
- Base learning rate: to
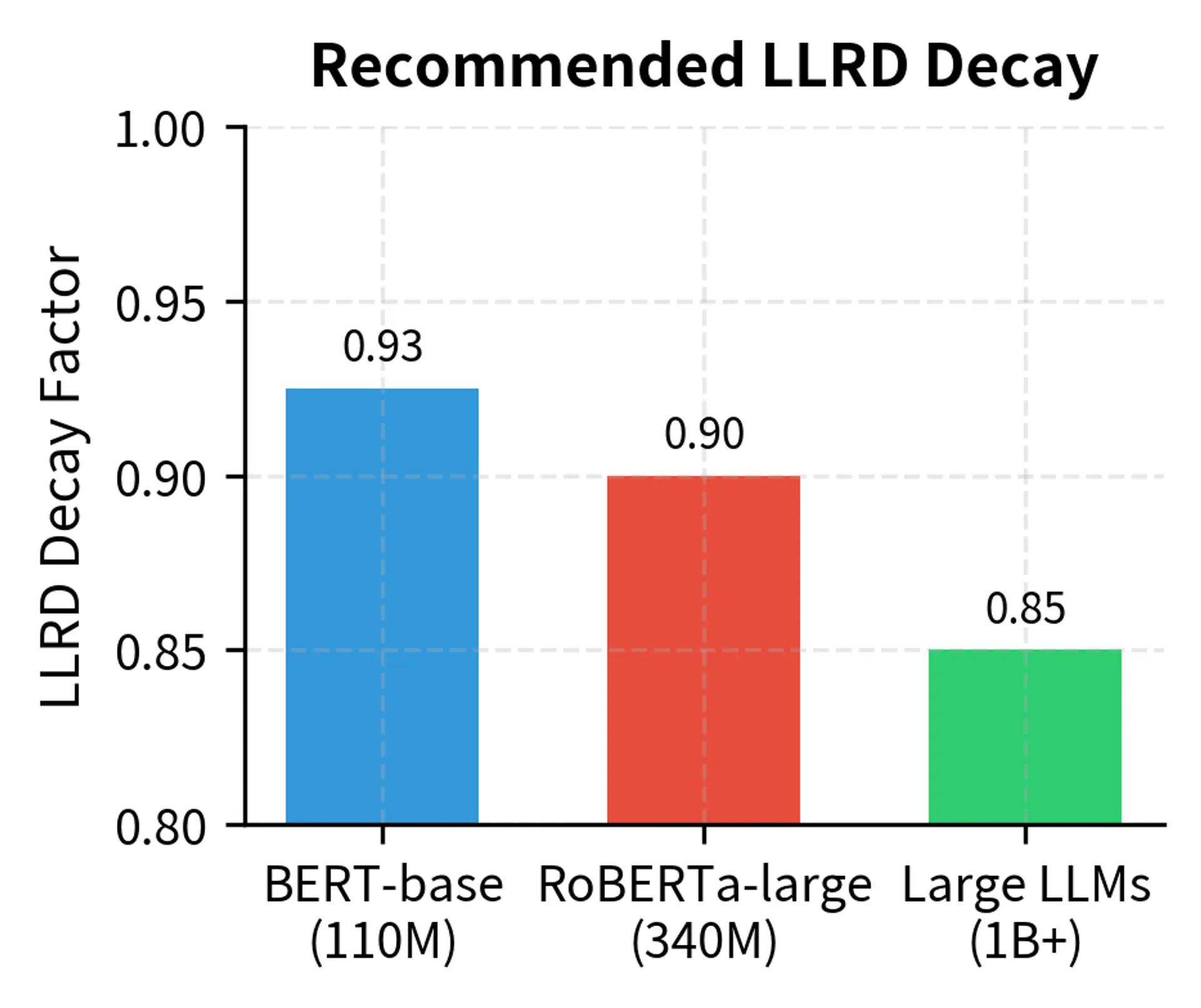
- LLRD decay: 0.9 to 0.95
- Warmup: 6-10% of training steps
- Task head learning rate: 10× base rate
For larger models (GPT-2, RoBERTa-large, 340M+ parameters):
- Base learning rate: to (lower due to more layers)
- LLRD decay: 0.85 to 0.95
- Warmup: 10% of training steps
- Consider lower weight decay (0.001 instead of 0.01)
For very large models (1B+ parameters):
- Base learning rate: to
- More aggressive LLRD decay: 0.8 to 0.9
- Longer warmup: 10-15% of training steps
- Often better to use parameter-efficient methods like LoRA, which we'll cover in upcoming chapters
General principles:
- Start with the lower end of learning rate ranges and increase if learning is too slow
- Monitor both training loss and validation metrics; overfitting indicates the rate may be too high
- If loss spikes early, increase warmup steps or decrease initial learning rate
- If loss plateaus too early, try a higher learning rate or different decay schedule
Limitations and Impact
These learning rate strategies have significantly improved fine-tuning results across many NLP tasks, but they come with important caveats.
The effectiveness of layer-wise learning rate decay depends on the assumption that lower layers capture more general features. While this holds for many tasks, it may not apply universally. For tasks that differ substantially from the pre-training distribution (such as fine-tuning an English model for code generation), the optimal learning rate hierarchy might differ from standard recommendations. Some practitioners have found that uniform learning rates perform just as well on certain tasks, suggesting that LLRD's benefits are task-dependent.
The interaction between these techniques and other regularization methods (dropout, weight decay, batch size) creates a complex optimization landscape. A learning rate that works perfectly with one dropout rate might be suboptimal with another. This interdependence means that comprehensive hyperparameter search often yields better results than following any single recipe, though this can be computationally expensive.
The computational overhead of implementing these strategies is minimal, but the engineering complexity is not. Maintaining separate learning rates for dozens of parameter groups, coordinating warmup schedules, and debugging learning rate issues all add development time. For rapid prototyping, uniform learning rates with basic warmup often provide 90% of the benefit with 10% of the complexity.
These techniques also don't address all fine-tuning challenges. Catastrophic forgetting can still occur even with optimal learning rates, particularly on small datasets or with many training epochs. As we'll explore in upcoming chapters on parameter-efficient fine-tuning, methods like LoRA offer complementary approaches that limit the number of parameters updated rather than just their learning rates.
Summary
Fine-tuning learning rates require careful consideration that goes beyond simply selecting a single value. The strategies covered in this chapter address different aspects of the fine-tuning challenge:
Layer-wise learning rate decay assigns different learning rates to different layers based on the principle that lower layers capture general features (requiring less adaptation) while upper layers capture task-specific features (requiring more adaptation). Using a decay factor between 0.9 and 0.95 across layers typically provides a good balance.
Learning rate warmup gradually increases the learning rate from zero during the first 5-10% of training. This stabilizes optimization by allowing Adam's moment estimates to accumulate and preventing the randomly initialized task head from destabilizing pre-trained weights.
Learning rate decay reduces the rate throughout training, helping the model converge to a stable minimum. Cosine and linear decay are both effective choices, with cosine sometimes providing slight improvements.
Combining these techniques creates a robust fine-tuning setup: warmup followed by decay, with different base rates for different layers. The task head typically receives 10× the base learning rate since it starts from random initialization and needs aggressive training.
These strategies represent one dimension of efficient fine-tuning. In the next chapter, we'll examine data efficiency: how to get the most out of limited labeled data when adapting pre-trained models to new tasks.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about fine-tuning learning rate strategies.

Comments