

Master LoRA's mathematical foundations including low-rank decomposition, gradient computation, rank selection, and initialization schemes for efficient fine-tuning.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
LoRA Mathematics
In the previous chapter, we introduced LoRA as a parameter-efficient fine-tuning method that adapts large language models by learning low-rank updates to weight matrices. Instead of modifying the full weight matrix , LoRA learns two smaller matrices whose product represents the weight change. Now we turn to the mathematical foundations that make this approach work. Understanding LoRA's mathematics reveals why the method is both theoretically grounded and practically effective. The formulation connects to fundamental concepts from linear algebra, specifically matrix decomposition techniques from Part III. By examining the initialization scheme, gradient flow, and rank selection criteria, You will gain the intuition needed to apply LoRA effectively and understand its variants covered in upcoming chapters.
The LoRA Formulation
LoRA reparameterizes weight updates using a factorized form that captures the essence of efficient adaptation. Rather than learning an arbitrary update to each weight matrix, LoRA constrains the update to live in a low-dimensional subspace. This constraint reflects the empirical observation that useful fine-tuning updates often have simple structure, revealing important patterns in how models adapt to new tasks.
For a pre-trained weight matrix , LoRA expresses the adapted weight as:
where:
- : the adapted weight matrix (final parameters)
- : the pre-trained weight matrix (frozen)
- : the weight update matrix (learned)
- : the up-projection matrix
- : the down-projection matrix
- : the rank of the adaptation
The key insight is that has rank at most . To understand why, recall that the rank of a matrix product cannot exceed the rank of either factor. Since has rows and has columns, the product can have rank at most . Even though has the same dimensions as , potentially millions of entries, it lives in a much lower-dimensional subspace determined by the choice of . This constraint is what enables LoRA's parameter efficiency: instead of learning independent parameters, we learn only parameters while still producing updates that span the full weight matrix dimensions.
Forward Pass Computation
During the forward pass, the network must compute the output of each adapted layer. This computation reveals opportunities for efficient implementation and clarifies each matrix's role in the decomposition.
For an input , the output is computed as:
where:
- : the output vector of the layer
- : the full adapted weight matrix
- : the input vector to the layer
- : the frozen pre-trained weight matrix
- : the trainable up-projection matrix
- : the trainable down-projection matrix
The final line reveals LoRA's computational structure. The parenthesization in is critical for computational efficiency. The naive approach would form the full matrix explicitly and then multiply by . This defeats the purpose of the low-rank decomposition because we would need to compute and store a matrix with entries.
Instead, we exploit the associativity of matrix multiplication to compute the result sequentially through a bottleneck of dimension . The computation proceeds in three stages:
- First, we compute , yielding . This operation involves an matrix multiplying a -dimensional vector, requiring operations.
- Next, we compute , yielding . This involves a matrix multiplying an -dimensional vector, requiring operations.
- Finally, we add the base model's output: .
This sequential computation requires operations for the LoRA path, compared to if we materialized the full update matrix. When , which is the regime where LoRA operates, this provides significant savings during both training and inference. For a typical transformer layer where and , the LoRA path requires roughly 0.8% of the operations needed to compute with a full update matrix.
Scaling Factor
The original LoRA paper introduces a scaling factor to control the magnitude of the low-rank update. This scaling factor plays a crucial role in making LoRA practical across different settings and ranks.
The scaled formulation is:
where:
- : the output vector
- : the pre-trained weight matrix
- : the input vector
- : a constant scaling factor (hyperparameter)
- : the rank of the LoRA matrices
- : the up-projection matrix
- : the down-projection matrix
- : the low-rank update matrix product
The ratio serves several important purposes.
- Learning rate stability: Without the scaling factor, changing the rank would fundamentally alter the magnitude of updates produced by the LoRA path. A higher rank means more terms contributing to the product , which, all else being equal, would produce larger outputs. By dividing by , we normalize this effect, allowing the same learning rate to produce updates of similar magnitude regardless of rank choice.
- Initialization compatibility: As we'll see in the initialization section below, the scaling interacts with how we initialize and to ensure consistent behavior. The combination of proper initialization and scaling means that the model's behavior at the start of training doesn't depend sensitively on the rank choice.
- Hyperparameter transfer: Because the scaling normalizes the effect of rank, a good value of often transfers across different rank choices. This simplifies hyperparameter search considerably: you can tune at a lower rank where experiments are cheaper, then scale up the rank while keeping fixed.
In practice, many implementations set , making the scaling factor equal to 1 and effectively removing the normalization. Others treat as a tunable hyperparameter, typically in the range . The choice depends on whether you want rank-independent behavior (use scaling) or prefer to absorb any magnitude adjustments into the learning rate (set ).
Low-Rank Decomposition Analysis
The mathematical foundation of LoRA rests on the hypothesis that weight updates during fine-tuning have low intrinsic rank. This is a strong claim that deserves careful examination. Why should task-specific adaptations live in a low-dimensional subspace? To understand why this might be true, we can connect LoRA to concepts from matrix approximation theory and explore what empirical evidence tells us about the structure of fine-tuning updates.
Connection to Singular Value Decomposition
Recall from our discussion of SVD in Part III that any matrix can be decomposed into a sum of rank-1 components, ordered by their importance. This decomposition shows when and why low-rank approximations work well.
Any matrix can be decomposed as:
where:
- : the matrix to be decomposed
- : orthogonal matrices containing singular vectors
- : diagonal matrix containing the singular values
- : the singular values, ordered such that
- : the left and right singular vectors corresponding to
The singular values tell us how much each rank-1 component contributes to the matrix. The largest singular value corresponds to the most important direction, the direction along which the matrix stretches inputs the most. Subsequent singular values capture progressively less important directions.
The Eckart-Young-Mirsky theorem tells us that the best rank- approximation to in the Frobenius norm is obtained by keeping only the first terms:
where:
- : the rank- matrix that best approximates
- : the target rank (number of components retained)
- : the singular values
- : the singular vectors
Among all possible rank- matrices, the truncated SVD provides the one closest to . The approximation error is precisely:
where:
- : the squared Frobenius norm of the approximation error
- : the Frobenius norm (square root of sum of squared elements)
- : the singular values corresponding to the discarded directions
This formula reveals when low-rank approximations work well: if the singular values decay rapidly, then the terms we discard when truncating contribute little to the total, and a low-rank approximation captures most of the matrix's structure. Conversely, if all singular values are similar in magnitude, truncation loses substantial information.
Empirical studies of fine-tuned models provide encouraging evidence for LoRA's approach. When researchers compute the weight changes from full fine-tuning runs and examine their singular value spectra, they find rapid decay. A small number of singular values dominate while most are near zero. This suggests that the actual weight changes needed for successful fine-tuning can be well approximated by low-rank matrices.

Intrinsic Dimensionality Hypothesis
The effectiveness of LoRA connects to the broader concept of intrinsic dimensionality in neural network training. Despite millions or billions of parameters, models need far fewer degrees of freedom for successful training. Called the "lottery ticket hypothesis" or "intrinsic dimensionality," this phenomenon shows that neural networks are vastly overparameterized for their tasks.
For fine-tuning specifically, the intuition supporting low-rank updates emerges from understanding what fine-tuning actually accomplishes:
- Pre-training captures general structure: The pre-trained weights already encode rich representations of language. These weights have been shaped by exposure to vast amounts of text, learning general patterns about syntax, semantics, world knowledge, and reasoning. These representations are highly expressive and broadly useful.
- Fine-tuning makes targeted adjustments: Adapting to a specific task requires modifying only certain aspects of these representations. A sentiment classifier needs only to adjust how certain features map to sentiment labels, not reorganize the model's understanding of language. A summarization model doesn't need new linguistic knowledge; it needs to learn task-specific patterns about what information to preserve and condense.
- Targeted adjustments are low-rank: These task-specific modifications can often be expressed as linear combinations of a small number of directions in weight space. If fine-tuning primarily adjusts how the model uses existing features rather than learning entirely new ones, the weight changes will have structure that low-rank matrices can capture.
Full unconstrained fine-tuning doesn't produce exactly low-rank updates. Instead, we find that low-rank approximations suffice for most downstream tasks. Full-rank updates might capture noise or provide marginal gains on very demanding tasks, but for typical applications, the low-rank constraint sacrifices little while gaining substantial efficiency.
Rank Constraint Interpretation
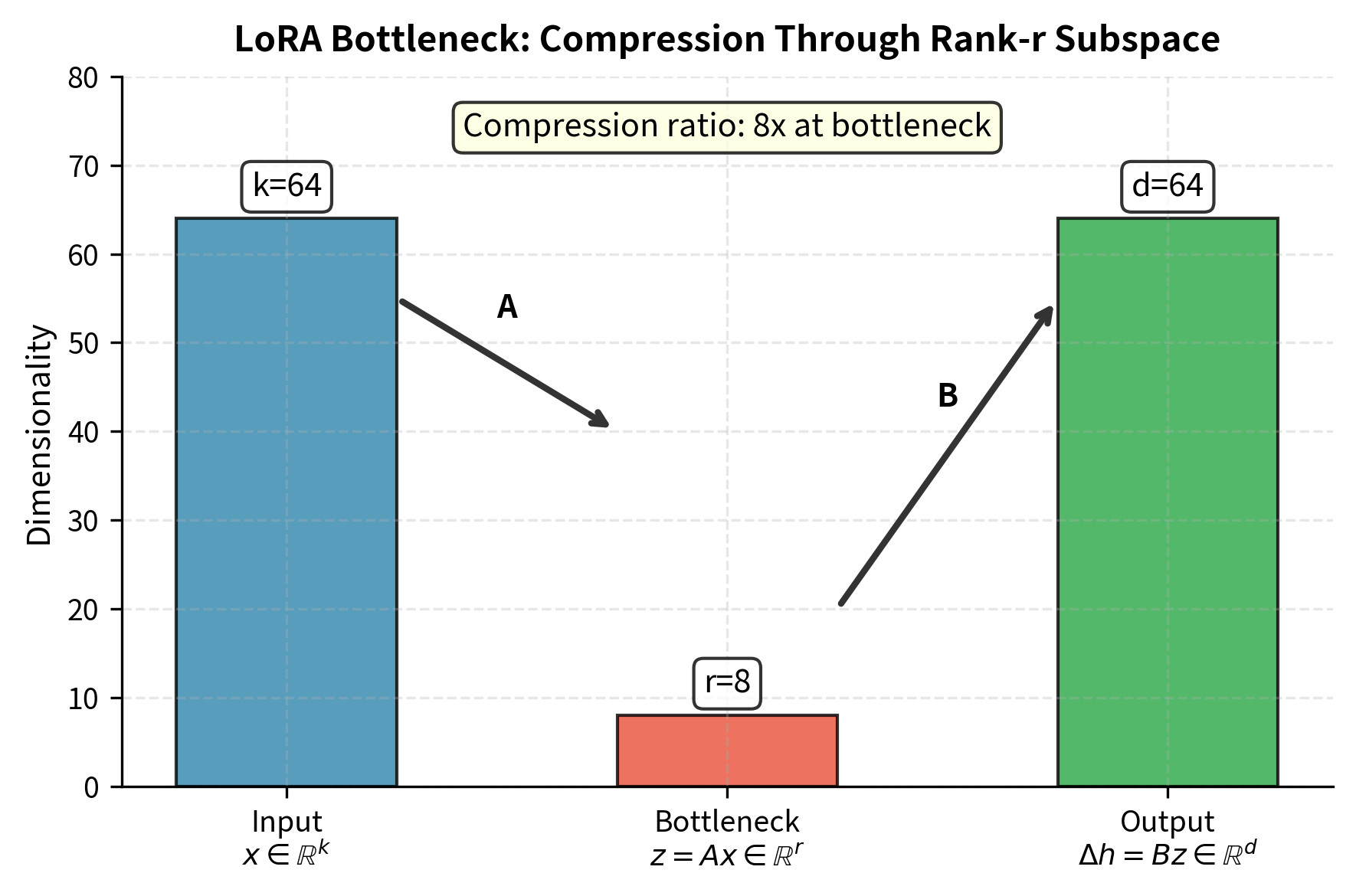
The rank constraint has a geometric interpretation that shows what LoRA learns during training. The matrix maps inputs through an -dimensional bottleneck, forcing all information about the input to pass through a low-dimensional representation before influencing the output.
Information flows through the LoRA path in three stages. First, the input vector is projected down to an -dimensional representation by the matrix . Then, this compressed representation is expanded back to the full output dimension by the matrix . Mathematically:
where:
- : the input vector
- : the down-projection matrix
- : the intermediate low-rank representation
- : the up-projection matrix
- : the update vector in the output space
- : the rank of the adaptation
- : the output dimension
This bottleneck structure implies several important properties. First, the update necessarily lies in the column space of , which has dimension at most . No matter what input we provide, the LoRA path can only produce outputs in this restricted subspace. Second, different inputs can only produce updates in this same -dimensional subspace. The LoRA update cannot independently adjust every dimension of the output; it must work within the constraints of the learned subspace. Third, and importantly, the subspace is learned during training, not predetermined. The optimization process discovers which directions in weight space are most useful for the task at hand.
The training process simultaneously learns two complementary aspects of the adaptation. The matrix encodes which -dimensional subspace in the output space should receive updates, effectively selecting the "directions" in which the model's behavior should change. The matrix encodes how to project inputs onto this subspace, determining which aspects of the input should influence these changes and by how much. Together, and learn both the structure of the adaptation and how to apply it based on the input.
Rank Selection
Choosing the rank involves balancing expressiveness against efficiency. Rank is a primary hyperparameter in LoRA. Understanding its trade-offs is essential for practical application. Lower ranks use fewer parameters and computation but constrain the adaptation's capacity to represent complex changes to the model's behavior.
Parameter Count Analysis
To understand the efficiency gains from LoRA, we need to compare the number of trainable parameters against full fine-tuning. For a weight matrix , full fine-tuning requires learning parameters. LoRA instead introduces:
where:
- : output dimension of the layer
- : input dimension of the layer
- : rank of the adaptation
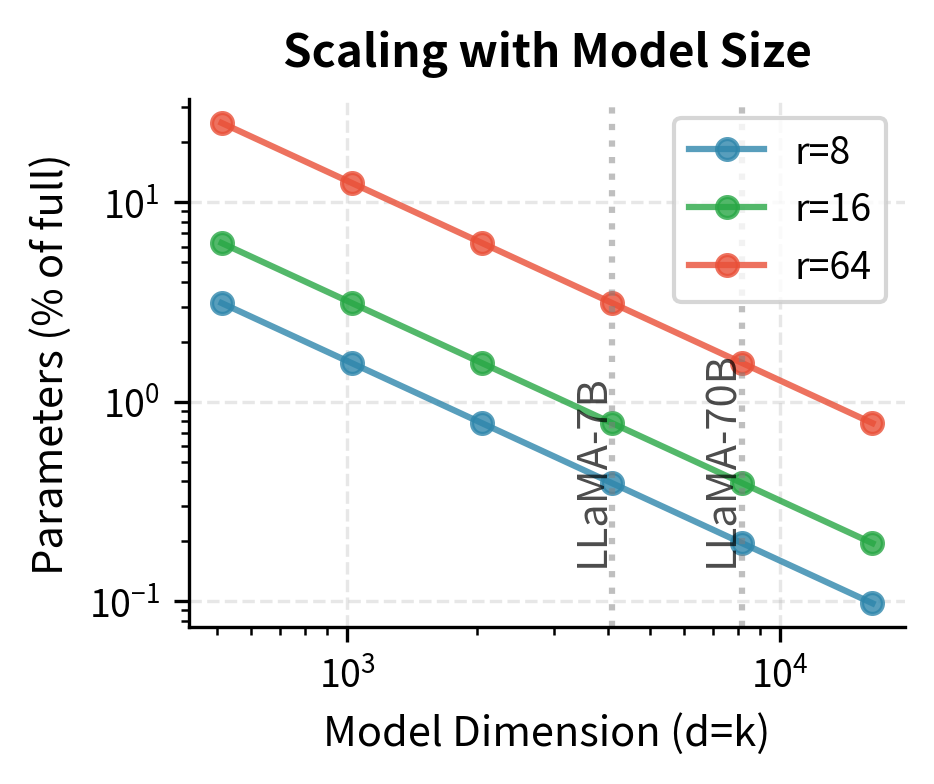
The parameter ratio compared to full fine-tuning reveals the compression achieved:
where:
- : total parameters in the full weight matrix
- : total parameters in the LoRA adapters
- : rank of the adaptation
- : output dimension
- : input dimension
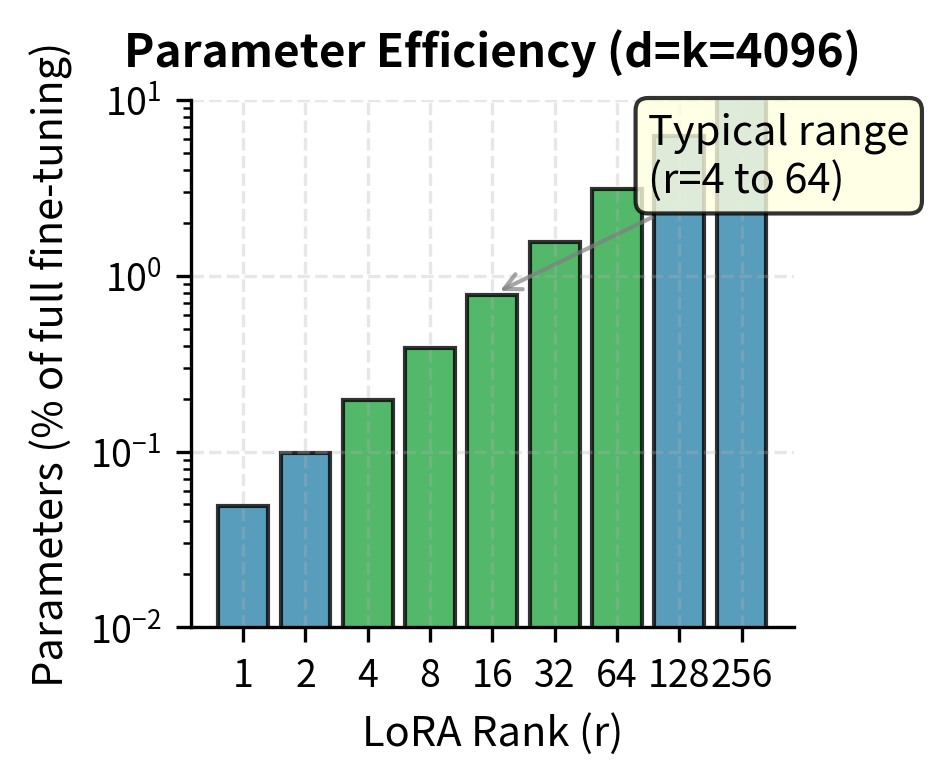
This ratio decreases as the layer dimensions grow, meaning LoRA becomes proportionally more efficient for larger models. For a transformer with , which is typical of modern large language models, and :
where:
- : the rank used in this example
- : the input and output dimensions ( and )
- : the resulting parameter efficiency ratio
This calculation shows that LoRA with rank 16 uses less than 1 percent of the parameters that full fine-tuning would require for this single layer. The dramatic reduction holds across the entire model. If we apply LoRA to all attention projections (the query, key, value, and output matrices denoted , , , ) in each layer, the total trainable parameters remain a small fraction of the original model while still adapting the most important components of the transformer architecture.
Expressiveness vs. Efficiency Trade-off
The rank determines the capacity of the adaptation, controlling how expressive the learned weight changes can be. Different ranks are appropriate for different scenarios:
- : The update is a rank-1 matrix (outer product of two vectors). This is highly constrained, representing the simplest possible non-trivial update. Despite this severe limitation, rank-1 adaptations sometimes suffice for simple tasks like binary classification where the model primarily needs to adjust a single decision boundary.
- to : These are common choices that balance efficiency and expressiveness for most NLP tasks. Many benchmarks show that ranks in this range achieve performance comparable to full fine-tuning while maintaining substantial parameter efficiency. This range represents the "sweet spot" for typical applications.
- to : Higher capacity for complex adaptations, multi-task scenarios, or cases where lower ranks demonstrably underperform. These ranks sacrifice some efficiency for increased expressiveness, appropriate when the task demands more complex adaptations than lower ranks can represent.
- : Full rank, equivalent to unconstrained fine-tuning of the layer. At this extreme, LoRA provides no parameter reduction but still maintains the structure of learning updates as a product of two matrices. This is primarily useful as a theoretical comparison point.
Empirically, rank selection depends on several factors that practitioners should consider. Task complexity plays a significant role. Simple classification may need only r = 8, while complex generation might benefit from r = 64 or higher. Dataset size interacts with rank in interesting ways. Smaller datasets benefit from lower ranks because the rank constraint provides implicit regularization, preventing overfitting. Larger datasets can exploit higher ranks without overfitting and may show continued improvement as rank increases. Finally, target modules often have different optimal ranks. Attention projections frequently need lower ranks than feed-forward layers, possibly because attention primarily routes information while feed-forward layers perform more complex transformations.
Effective Rank During Training
Trained LoRA adapters show an interesting pattern: even when is set relatively high, the effective rank of the learned is often lower than the maximum possible. The optimization process tends to concentrate the adaptation into fewer dimensions than the allocated rank would allow.
The effective rank can be measured using the singular values of BA. One natural measure based on information theory follows.
where:
- : the normalized singular value such that
- : the -th singular value of the matrix
- : exponential function (computes the perplexity of the singular value distribution)
This entropy-based measure, sometimes called the spectral entropy or perplexity of the singular value distribution, indicates how many singular values contribute meaningfully to the matrix. If all singular values are equal, the effective rank equals . If one singular value dominates, the effective rank approaches 1. Values between these extremes indicate intermediate concentration.
Studies examining trained LoRA adapters show that they often converge to solutions where only a few singular values dominate, even when the specified is much larger. This observation suggests that the actual intrinsic rank needed for the adaptation is lower than the specified . It also suggests potential improvements: methods like AdaLoRA, covered in a later chapter, exploit this observation by adaptively adjusting the rank during training rather than fixing it in advance.
Initialization Scheme
LoRA's initialization is crucial for training stability and convergence. How you initialize matrices and determines the model's starting point and influences the entire training trajectory. The standard scheme is:
- Matrix : Initialized from (Gaussian) or Kaiming initialization
- Matrix : Initialized to zero
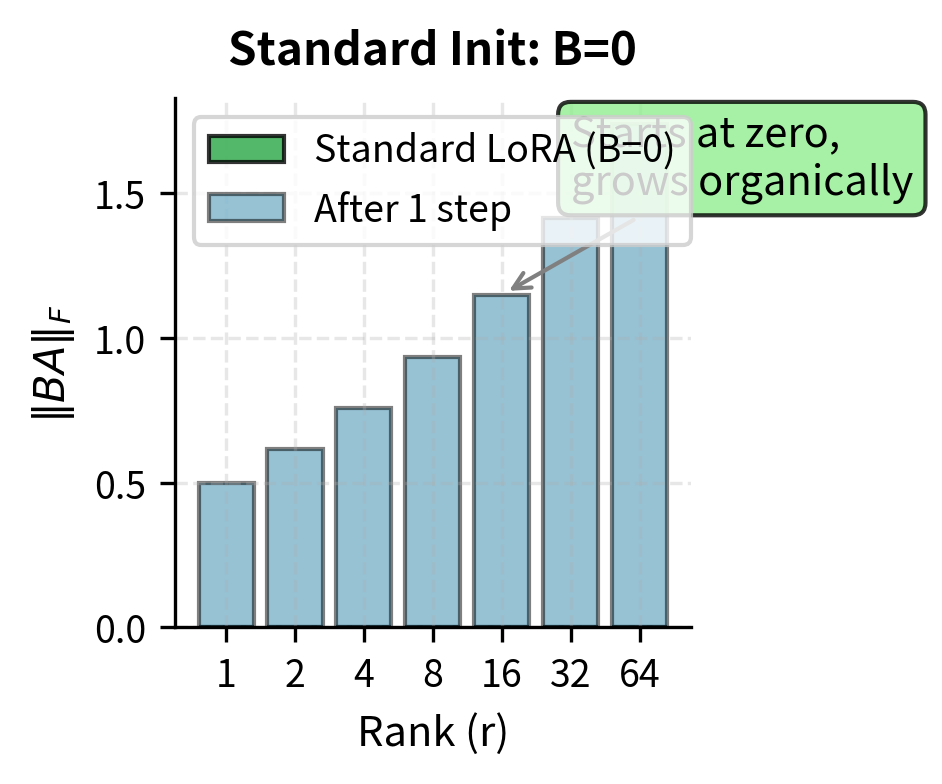
This asymmetric initialization, with random and zero, ensures that the product at the start of training. This means the model begins with its pre-trained behavior completely intact: the LoRA path contributes nothing to the output until training begins to modify the parameters.
Rationale for Zero Initialization of B
Starting with has several important advantages:
-
Continuity from pretraining: The model's initial behavior exactly matches the pretrained model. This is valuable because the pretrained model already performs well on many tasks. No "warm-up" period is needed for the model to recover from a random perturbation. From the first training step, we are refining good behavior rather than recovering from a disrupted starting point.
-
Stable training dynamics: Large random initializations of both and could produce values that significantly perturb the pre-trained representations. If the initial perturbation is large, early training might focus on undoing this damage rather than learning the task. By starting at zero, we ensure that the first training steps are devoted entirely to task-relevant adaptation.
-
Gradient flow: A natural concern with zero initialization is whether gradients will flow properly. If initially, won't the gradient with respect to also be zero, preventing any learning? Fortunately, this is not the case. The gradient with respect to depends on the input to the LoRA layer and the upstream gradient, not on the current value of . As we'll derive in the gradient section below, receives non-zero gradients even when it equals zero.
Variance Analysis
The initialization variance explains why the standard scheme works better. If we initialize both and randomly with entries drawn from , what magnitude would we expect in the product ?
For a single entry of the product:
where:
- : element at row , column of the product
- : elements of the random matrices
- : variance of the initialization distribution
- : rank (number of terms in the sum)
The key observation is that this expected squared magnitude grows linearly with . This rank dependence creates a problem: if we use the same initialization variance and learning rate for different ranks, higher ranks will produce larger initial perturbations and larger gradients. This would require rank-dependent learning rate adjustment to maintain consistent training dynamics. Zero-initializing sidesteps this issue entirely by ensuring the initial perturbation is exactly zero regardless of rank.
For matrix , the standard initialization uses variance that scales inversely with rank:
where:
- : element of matrix at row , column
- : normal distribution with mean and variance
- : rank of the adaptation
- : variance chosen to scale with the rank
This scaling ensures that when gradients begin flowing and starts to move away from zero, the updates to have reasonable magnitude regardless of . The variance is chosen so that the projection has expected squared norm that doesn't grow with . Some implementations use Kaiming initialization instead, setting:
where:
- : element of matrix
- : input dimension of the layer
Kaiming initialization is designed to preserve the variance of activations through deep networks and is a reasonable alternative choice.
Alternative Initializations
While zero-initialization of is standard and works well in most cases, researchers have explored alternatives that may offer advantages in certain scenarios:
- SVD initialization: Initialize as a low-rank approximation of from a reference full finetuning run. This requires running full fine-tuning once, but if you need to train many LoRA variants, initializing from the SVD of a reference solution can accelerate convergence significantly.
- Symmetric initialization: Initialize both and with small random values, accepting the initial perturbation to pre-trained behavior. This may help when the pre-trained model's initial behavior is far from desired, though it requires careful tuning of the initialization scale.
- Task-informed initialization: Use task-specific heuristics based on prior knowledge about the adaptation needed. For example, if adapting for a specific domain, initialize using SVD of domain-specific text representations.
We'll explore adaptive initialization strategies in the AdaLoRA chapter, where the initialization interacts with mechanisms that adjust rank during training.
LoRA Gradient Computation
Gradient flow through LoRA reveals training dynamics and connects to optimization concepts from Part VII. The gradient formulas reveal why the zero initialization of doesn't prevent learning and how and co-evolve during training.
Gradient Derivation
Consider the forward pass for a single layer with LoRA adaptation:
where:
- : the output vector
- : the pre-trained weight matrix
- : the input vector
- : the scaling factor
- : the rank
- : the LoRA up-projection and down-projection matrices
Let be the loss function we're minimizing. To update and via gradient descent, we compute and . The chain rule traces how parameter changes propagate through the computation to affect the loss.
First, let's define the upstream gradient. Let be the gradient of the loss with respect to the layer's output. This gradient comes from the layers above in the network and tells us how changes in affect the loss.
For the gradient with respect to , we apply the chain rule. The LoRA contribution to is . Differentiating this with respect to , and then multiplying by how changes in affect the loss:
where:
- : the loss function
- : the upstream gradient vector
- : the intermediate vector (input projected down to rank )
- : the scaling factor
- : the rank
The gradient of is an outer product between the upstream gradient and the intermediate representation . Each entry of the gradient measures how much increasing that entry would affect the loss, which depends on how much gradient signal arrives at output dimension (captured by ) and how active the corresponding bottleneck dimension was (captured by ).
For processing batches efficiently, we extend this to matrix form:
where:
- : loss function
- : scaling factor
- : rank
- : matrix of upstream gradients for the batch
- : matrix of input vectors for the batch
- : down-projection matrix
For the gradient with respect to , we again apply the chain rule. Now we need to trace how changes in affect through the intermediate computation :
where:
- : transpose of the up-projection matrix
- : the loss function
- : the scaling factor
- : the rank
- : the upstream gradient vector
- : the input vector
This formula shows that the gradient with respect to involves projecting the upstream gradient back through (using ) and then forming an outer product with the input . In matrix form for batch processing:
where:
- : loss function
- : scaling factor
- : rank
- : transpose of the up-projection matrix
- : upstream gradient matrix
- : transpose of the input batch matrix
Gradient Flow Properties
Several properties of these gradients are noteworthy and reveal important aspects of LoRA's training dynamics.
Independence from : The gradients and are independent of . Frozen weights affect the upstream gradient but never appear explicitly in the LoRA gradient formulas. This separation enables efficient training where is never updated. You don't need to compute or store gradients for the much larger frozen weight matrices.
Coupled dynamics: Although and are separate parameters, their gradients are intimately coupled:
- depends on through the term
- depends on through the term
This coupling means and co-evolve during training, with 's current value determining 's gradient and vice versa. This is similar to the dynamics in other factorized parameterizations, leading to interesting optimization behavior.
Zero initialization dynamics: At initialization ():
- (generally non-zero)
This asymmetry is important: updates immediately from the first gradient step, while has zero gradient initially. However, after the first update step, , and both matrices begin receiving non-zero gradients. The initial zero-gradient phase for is brief, lasting only a single step in theory, though in practice the gradients for remain small until has moved appreciably away from zero.
Computational Cost of Gradient Computation
LoRA's gradient computations are efficient, requiring operations proportional to the parameter count rather than the full weight matrix size.
Computing where has the following costs: during the forward pass, we must store , adding minimal memory overhead. The gradient computation itself is an outer product between vectors of dimension and , requiring operations.
Computing requires first computing , which is a matrix-vector product costing operations, followed by forming the outer product with , which costs operations.
The total gradient computation is therefore , matching the parameter count. This is optimal. We need at least one operation per parameter to compute a gradient, and LoRA achieves this lower bound up to constant factors. This efficiency extends to the memory required for gradient storage, which also scales with rather than .
Worked Example
Concrete numbers solidify the mathematical concepts. This example connects abstract formulas to actual numerical operations.
Consider a small weight matrix with rank r = 2 adaptation.
where:
- : the pre-trained weight matrix
Initialize LoRA matrices following the standard scheme:
where:
- : the down-projection matrix (randomly initialized)
- : the up-projection matrix (initialized to zero)
For input with scaling factor :
Forward pass:
Tracing through each step of forward computation:
-
Pre-trained output: We compute by multiplying the pre-trained weight matrix with the input. For the first element: . Continuing for all elements:
-
LoRA intermediate: We compute , projecting the input down to the rank-2 bottleneck. First element: . Second element: . So
-
LoRA update: We compute , projecting back up to the output dimension. Since , this gives
-
Final output:
At initialization, the output equals the pre-trained output exactly. This confirms that zero-initializing preserves the pre-trained model's behavior.
With upstream gradient from the loss and layers above, we compute gradients for both LoRA matrices.
For :
where:
- : the loss function
- : the up-projection matrix
- : the scaling factor ()
- : the rank ()
- : the upstream gradient vector
- : the intermediate activation vector computed in the forward pass
For :
where:
- : the loss function
- : the down-projection matrix
- : the transpose of the up-projection matrix (currently zero)
- : the upstream gradient vector
- : the input vector
As expected from our theoretical analysis, receives non-zero gradients while 's gradient is zero at initialization. After one gradient descent step updates , subsequent forward passes will produce non-zero terms, and will begin receiving gradients as well.
Code Implementation
We'll implement the LoRA mathematics in PyTorch, demonstrating the forward pass, gradient computation, and initialization. The implementation verifies our theoretical predictions empirically.
Let's verify the initialization produces zero updates:
The product is exactly zero because is initialized to zero, confirming our model starts with pretrained behavior. Matrix has dimensions (rank, in_features) for the down-projection, while has dimensions (out_features, rank) for the up-projection. Their product maintains the full weight matrix dimensions but contains only zeros at initialization, meaning the LoRA path contributes nothing to the output until training begins.
Verifying Gradient Flow
Let's trace gradients through a forward-backward pass:
As predicted by analysis, matrix 's gradient is zero at initialization because in the gradient formula, while receives non-zero gradients. This asymmetry demonstrates the coupled dynamics derived mathematically. Matrix begins learning only after has moved away from zero, creating a brief initial phase where adapts alone before both matrices co-evolve.
Parameter Efficiency Calculation
Let's compute the parameter savings for a realistic scenario:
The 128x compression achieves dramatic parameter reduction while maintaining strong adaptation capability. Full finetuning of these attention layers requires 2.1 billion parameters, while LoRA needs only 16.8 million trainable parameters, making finetuning practical on consumer GPUs with 16-24GB of memory. This dramatic reduction enables efficient multi-task serving where different LoRA adapters can be swapped without duplicating the base model weights.
Visualizing Rank Effects
Let's visualize how different ranks affect the approximation capacity:
The error drops sharply until we reach the true intrinsic rank of the target matrix (8 in this case), then decreases more slowly. This shows why moderate ranks like 8 to 16 often suffice in practice.
Gradient Magnitude Analysis
Let's examine how gradients evolve during the first few training steps:
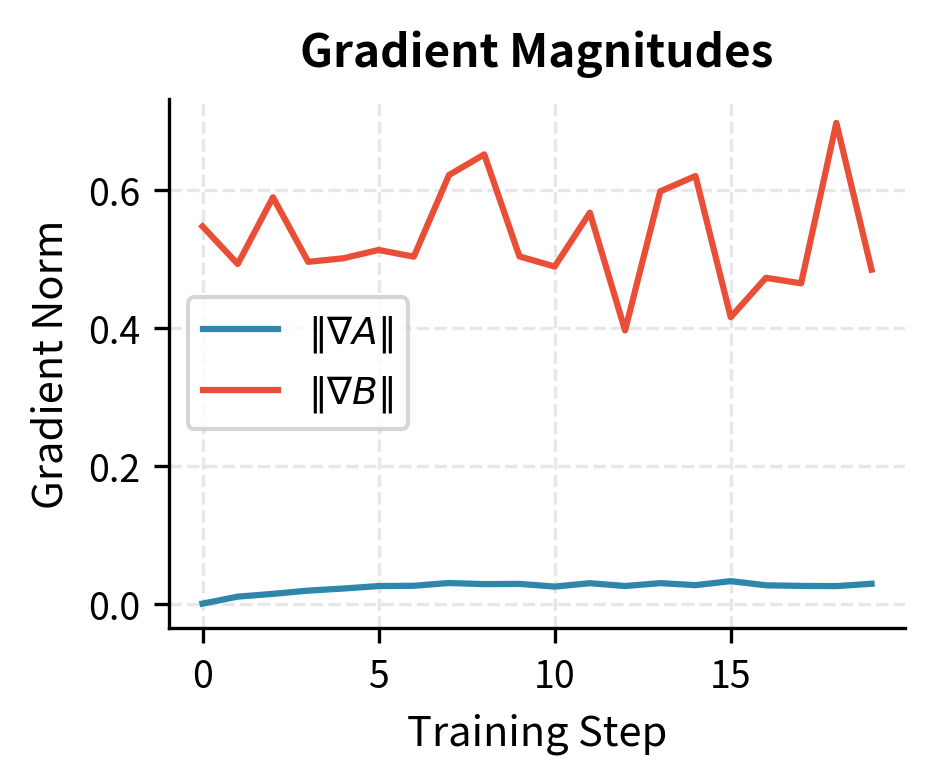
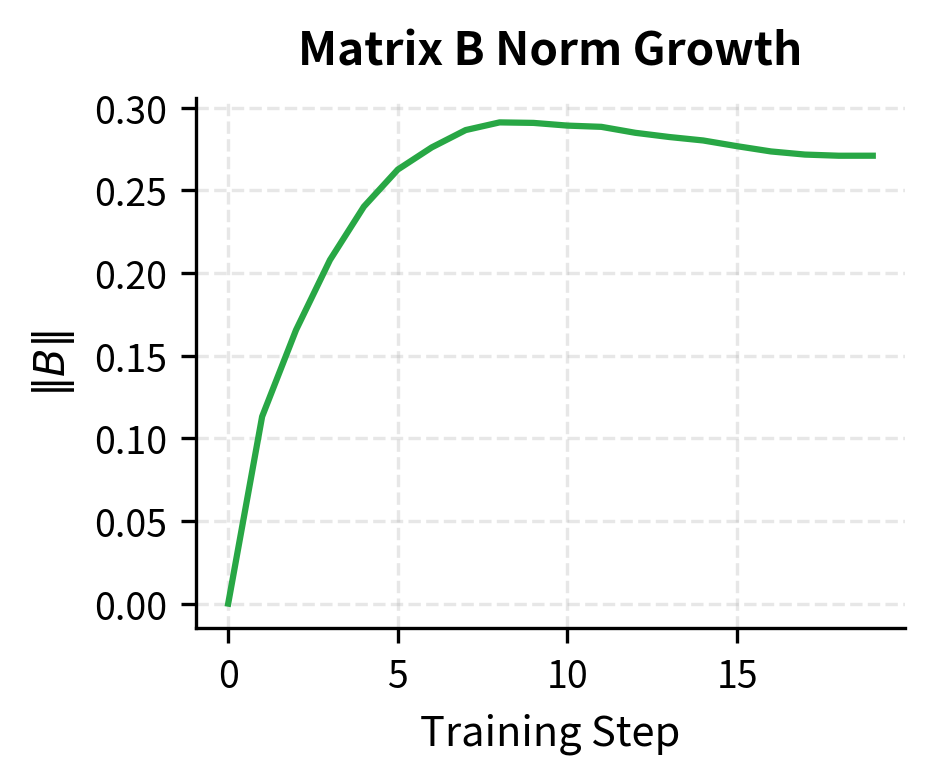
The plot confirms the mathematical analysis. Matrix A's gradient starts at zero and grows as B moves away from zero. The coupled dynamics quickly bring both matrices into active training.
Weight Merging for Inference
LoRA's trained adapters can be merged into the base weights for inference:
After merging, the LoRA matrices can be discarded and replaced with a single weight matrix that has zero inference overhead compared to the original model. The negligible difference confirms that merging is mathematically exact within floating-point accuracy. This property matters for deployment. During development, separate A and B matrices provide flexibility, while production uses merged weights to eliminate computational overhead from the low-rank decomposition.
Key Parameters
The key parameters for LoRA are:
- rank (r): The bottleneck dimension of the low-rank decomposition. Lower ranks use fewer parameters but constrain adaptation capacity. Typical values range from 4 to 64.
- alpha: Scaling factor that controls the magnitude of LoRA updates. Often set equal to rank or tuned in the range 8 to 64.
- target_modules: Which weight matrices to apply LoRA to (e.g., query, key, value, output projections in attention layers).
- initialization: Matrix A typically uses Gaussian or Kaiming initialization, while matrix B is initialized to zero to preserve pretrained behavior.
Conclusion
LoRA's mathematical elegance stems from the simplicity of the factorized decomposition combined with its effectiveness in practice. The low-rank constraint is not arbitrary but grounded in the empirical observation that fine-tuning updates concentrate in low-dimensional subspaces. Understanding the mathematics—from the basic formulation through initialization, gradient flow, and rank selection—reveals why LoRA works and how to apply it effectively across diverse applications and architectures.
Limitations and Impact
LoRA achieves remarkable parameter efficiency, but its limitations matter for practical application.
The low-rank constraint limits adaptation expressiveness. Empirical evidence shows this rarely hurts performance on common NLP benchmarks, though certain tasks require higher-rank updates that LoRA cannot efficiently represent. Tasks requiring significant architectural changes, such as cross-domain or cross-modality adaptation, may need ranks higher than LoRA typically provides. The intrinsic dimensionality hypothesis provides theoretical grounding but cannot guarantee that low-rank approaches suffice for all adaptations.
The initialization scheme creates a particular training dynamic that may not be optimal for all scenarios. Zero-initializing B means early training updates only affect B, potentially slowing convergence compared to methods that update all parameters immediately. The scaling factor introduces hyperparameters that interact with learning rates in non-obvious ways, requiring careful tuning.
Despite these limitations, LoRA's mathematical formulation has significantly influenced the field. The decomposition W = W₀ + BA provides a clean interface for modular adaptation, where different LoRA matrices can be trained for different tasks and swapped at inference without modifying the base model. This enables multi-tenant serving where a single base model serves many specialized applications. The formulation also inspired numerous extensions, including QLoRA (quantization with LoRA), AdaLoRA (dynamic rank adaptation), and structured approaches that exploit domain-specific priors about where low-rank updates should be applied.
Summary
This chapter covered the mathematical foundations of LoRA:
-
Core formulation: expresses weight updates as a product of two smaller matrices, constraining updates to rank .
-
Low-rank approximation: SVD theory and the intrinsic dimensionality hypothesis show that fine-tuning updates live in low-dimensional subspaces of weight space.
-
Rank selection: Balances expressiveness against efficiency. Ranges of r from 4 to 64 achieve over 100x compression while maintaining adaptation quality.
-
Initialization: B starts at zero while A is randomly initialized, ensuring training begins from pre-trained behavior with stable gradient dynamics.
-
Gradient flow: A and B co-evolve during training. A receives zero gradients initially but learns as B moves away from zero.
The next chapter covers practical implementation patterns for applying LoRA to transformer architectures and integrating it with existing training pipelines.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about LoRA's mathematical foundations.

Comments