

Master backtesting frameworks to validate trading strategies. Avoid look-ahead bias, measure risk-adjusted returns, and use walk-forward analysis for reliability.
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Backtesting and Simulation of Trading Strategies
Throughout Part VI, we developed a rich toolkit of quantitative trading strategies, from mean reversion and momentum to machine learning-based approaches. Two questions arise: would these strategies have been profitable historically, and will that performance translate to the future?
Backtesting evaluates a trading strategy by simulating its performance on historical data. It acts as a simulation tool to test ideas against past market conditions. A well-designed backtest reveals profitability, behavior during market stress, capital requirements, and the source of returns.
However, backtesting presents significant risks. The flexibility to test many ideas can lead to strategies that appear robust in hindsight but fail in live trading. Biases, data errors, and methodological flaws often create a discrepancy between simulated results and real-world profitability.
This chapter covers the complete backtesting workflow: building a simulation framework, avoiding common pitfalls, measuring performance rigorously, and testing whether your results generalize beyond the data you used to develop them. By the end, you'll understand not just how to run a backtest, but how to interpret one critically, a skill that separates you from those who fool themselves with beautiful but meaningless equity curves.
The Backtesting Framework
A backtesting framework simulates the operation of a trading strategy through historical time. At each point in the past, the system must answer a fundamental question: what trades would the strategy have made given only the information available at that moment? This simple requirement, respecting the flow of time, is the foundation of all valid backtesting. The framework must faithfully reconstruct the decision-making environment that would have existed at each historical moment, using only the data that would have been observable then and applying the same rules consistently throughout the simulation period.
Core Components
Every backtesting system consists of five essential components that work together to produce simulated results. Understanding how these components interact is crucial for building reliable simulations and diagnosing problems when results seem too good to be true.
The core components are:
-
Historical Data: This includes price series, fundamental data, or alternative data. Data quality directly determines validity, as errors propagate through subsequent calculations. Clean, accurate, and properly aligned data forms the foundation of analysis.
-
Signal Generation: This logic transforms available information into trading decisions (buy, sell, or hold). This module encodes the strategy rules and must rely solely on information available at each specific time step.
-
Position Management: This layer converts signals into portfolio allocations, handling position sizing, rebalancing, and constraints. It translates abstract signals into concrete capital deployment.
-
Execution Simulation: This component models order fills, transaction costs, slippage, and market impact, bridging the gap between theoretical positions and realistic outcomes.
-
Performance Tracking: This records portfolio values and returns, maintaining the historical record required for statistical analysis and visualization.
The interaction between these components creates a simulation loop that processes one time step at a time. At each step, the system receives new market data, generates signals based on available information, converts those signals into target positions, simulates the execution of any required trades, and records the resulting portfolio state. This sequential processing mirrors how a real trading system operates, making it easier to ensure temporal consistency.
Event-Driven vs Vectorized Backtesting
Two architectural approaches dominate backtesting implementations, each with distinct advantages and trade-offs that make them suitable for different situations.
Event-driven backtesting processes data one event at a time, maintaining explicit state throughout the simulation. This approach mimics how a live trading system operates and naturally prevents look-ahead bias because each decision is made in isolation, using only information available at that moment. The explicit state management makes it straightforward to model complex portfolio dynamics, such as margin requirements, position limits, and multi-asset interactions. However, the sequential nature of event-driven processing makes it computationally slower than alternatives, and the additional complexity can introduce implementation bugs if not carefully managed.
Vectorized backtesting uses array operations to compute signals and positions across the entire dataset simultaneously. This approach leverages the highly optimized linear algebra libraries underlying NumPy and pandas to achieve dramatic speed improvements, often running hundreds of times faster than equivalent event-driven code. The concise syntax also makes strategies easier to read and verify. However, vectorized backtesting requires careful attention to prevent future information from leaking into past calculations. Time-alignment of arrays becomes critical, and a single misplaced index can introduce look-ahead bias that makes results meaningless.
The shift(1) operations in the code above are essential for maintaining temporal integrity. They ensure that the position we hold today was determined by yesterday's signal, which in turn was computed from data available before yesterday's close. The first shift ensures the momentum calculation doesn't include today's return, while the second shift ensures we're measuring the return earned on a position that was already established. Any misalignment here introduces look-ahead bias, which would make the backtest results invalid and potentially misleading.
Data Requirements and Alignment
Proper data handling requires attention to several timing issues that can subtly corrupt backtest results if not addressed correctly. These issues arise because the data we observe today often differs from what was available in the past, and because different data sources may use different conventions for timestamps and adjustments.
The first concern is point-in-time accuracy. Financial databases often update historical records as new information becomes available, meaning the data you see today may differ significantly from what was available in the past. For example, earnings figures are frequently restated, economic indicators are revised, and index compositions change over time. If your backtest uses today's version of historical data, you may be implicitly assuming knowledge that wasn't available when the trading decisions would have been made. When available, use point-in-time databases that preserve the data exactly as it appeared on each historical date.
The second concern involves timestamp conventions. You must know whether your prices represent open, close, or some other time within the trading day. A strategy that trades on the close needs close prices, and using daily high prices would overstate returns by assuming you could consistently buy at the low and sell at the high. Similarly, be careful with time zones: a strategy trading US equities based on European market signals must account for the hours of overlap and delay between markets.
The third concern relates to corporate actions. Stock splits, dividends, and mergers change price series in ways that can distort return calculations if not handled properly. Use adjusted prices for return calculations to ensure that a 2-for-1 stock split doesn't appear as a 50% price drop. However, if your position sizing depends on share counts rather than dollar amounts, you may need raw prices to determine how many shares to trade.
The sample data confirms we have two aligned price series over 500 trading days. Ensuring correct timestamp alignment and data completeness is a prerequisite for any valid backtest. Before proceeding with strategy development, you should always verify that your data has no gaps, that prices are properly adjusted for corporate actions, and that the timestamps correspond to the market events your strategy depends on.
Biases in Backtesting
The greatest danger in backtesting is self-deception. Historical data is finite, and with enough searching, you can find patterns that look profitable but arise purely from chance. These patterns reflect the random quirks of a particular dataset rather than any genuine market inefficiency that will persist into the future. Understanding the biases that afflict backtests is essential for producing results you can trust and for avoiding the costly mistake of deploying strategies that looked great in simulation but fail in live trading.
Look-Ahead Bias
Look-ahead bias occurs when a backtest uses information that would not have been available at the time a trading decision was made. This is the most fundamental error in backtesting because it violates the causal structure of time. In the real world, you cannot use tomorrow's news to make today's trading decisions. But in a backtest, where all historical data sits in memory simultaneously, it's disturbingly easy to accidentally let future information leak into past calculations.
Common sources of look-ahead bias include several categories of errors that can creep into even carefully designed backtests.
-
Using future data in calculations: Computing a signal using today's price when it should be based on yesterday's close. This often results from off-by-one indexing errors or rolling calculations that include the current observation.
-
End-of-period knowledge: Using full-year earnings data at the start of the year when reports are released later. This assumes knowledge of figures before they are publicly available.
-
Restatements and revisions: Using revised economic or fundamental data (e.g., GDP, earnings) that was corrected months after the initial release, rather than the data actually available at the time.
-
Survivorship in filtering: Selecting a universe based on current criteria (e.g., "current top 100 stocks") rather than historical criteria, effectively filtering for companies that were successful enough to survive and grow.
The biased version achieves high returns because it uses future information to determine trade direction. No real strategy can achieve this level of performance, yet subtle forms of look-ahead bias appear in many backtests. The biased strategy relies on foresight, making it profitable in simulation but unreplicable in practice. When you see backtest results that seem too good to be true, look-ahead bias should be your first suspicion.
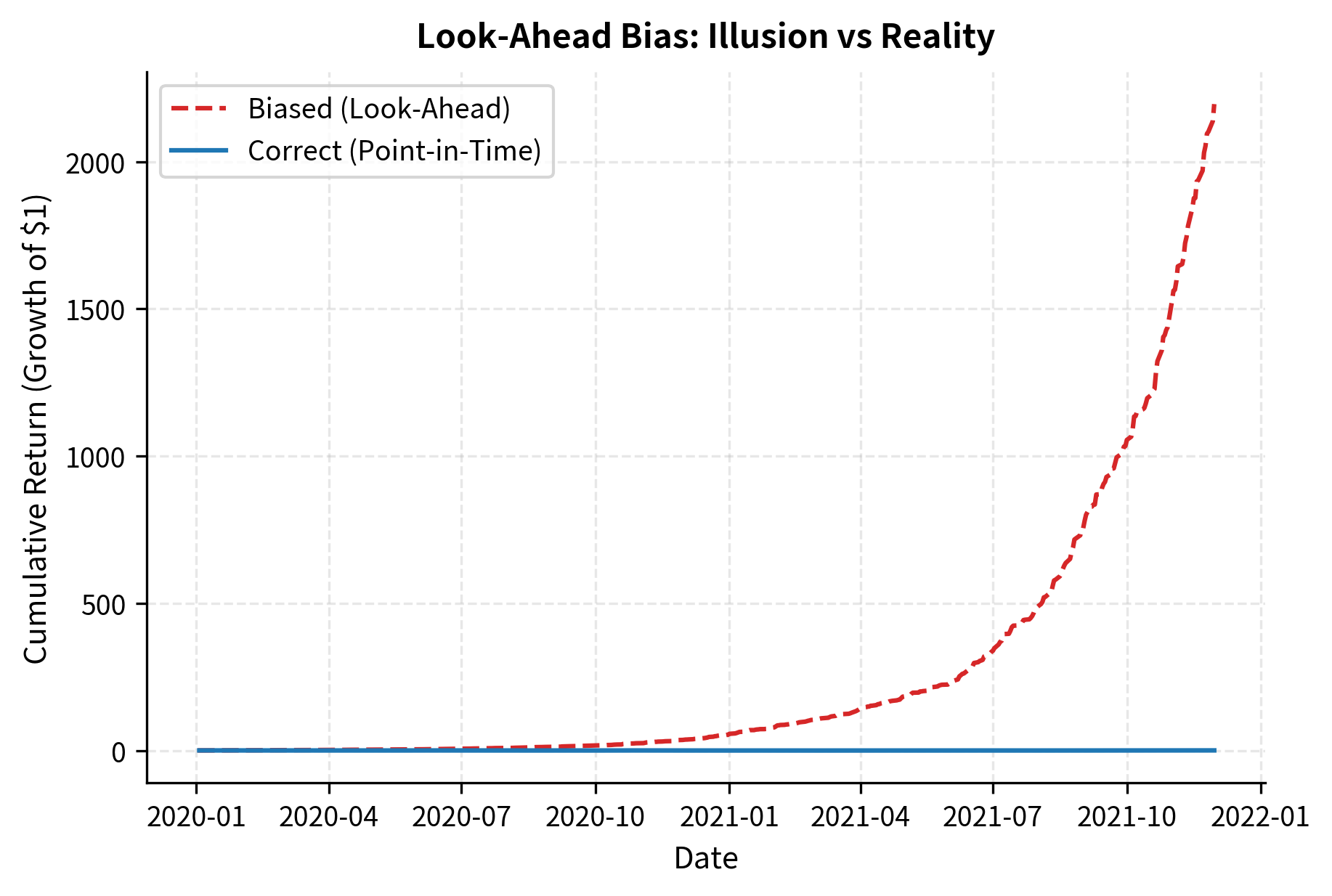
Survivorship Bias
Survivorship bias occurs when your backtest only includes assets that survived to the present day, excluding those that were delisted, went bankrupt, or were acquired. This systematically overstates returns because failed investments become invisible in the historical record. You only see the winners, which makes the average past performance look better than it actually was.
Consider testing a strategy on "S&P 500 stocks" using today's index constituents. Companies currently in the index are, by definition, successful: they've grown large enough to be included and have avoided the failures that would have caused delisting. But a strategy trading in 2010 would have held different companies, including some that subsequently went bankrupt, were acquired at distressed prices, or shrank enough to be removed from the index. By testing only on survivors, you implicitly give your strategy perfect foresight about which companies to avoid, making your backtested returns look better than you could have achieved.
The magnitude of survivorship bias can be substantial. Academic research has shown that survivorship bias can add several percentage points per year to apparent returns in equity backtests. The effect is particularly pronounced for strategies that involve small-cap stocks, distressed securities, or other areas where failure rates are high.
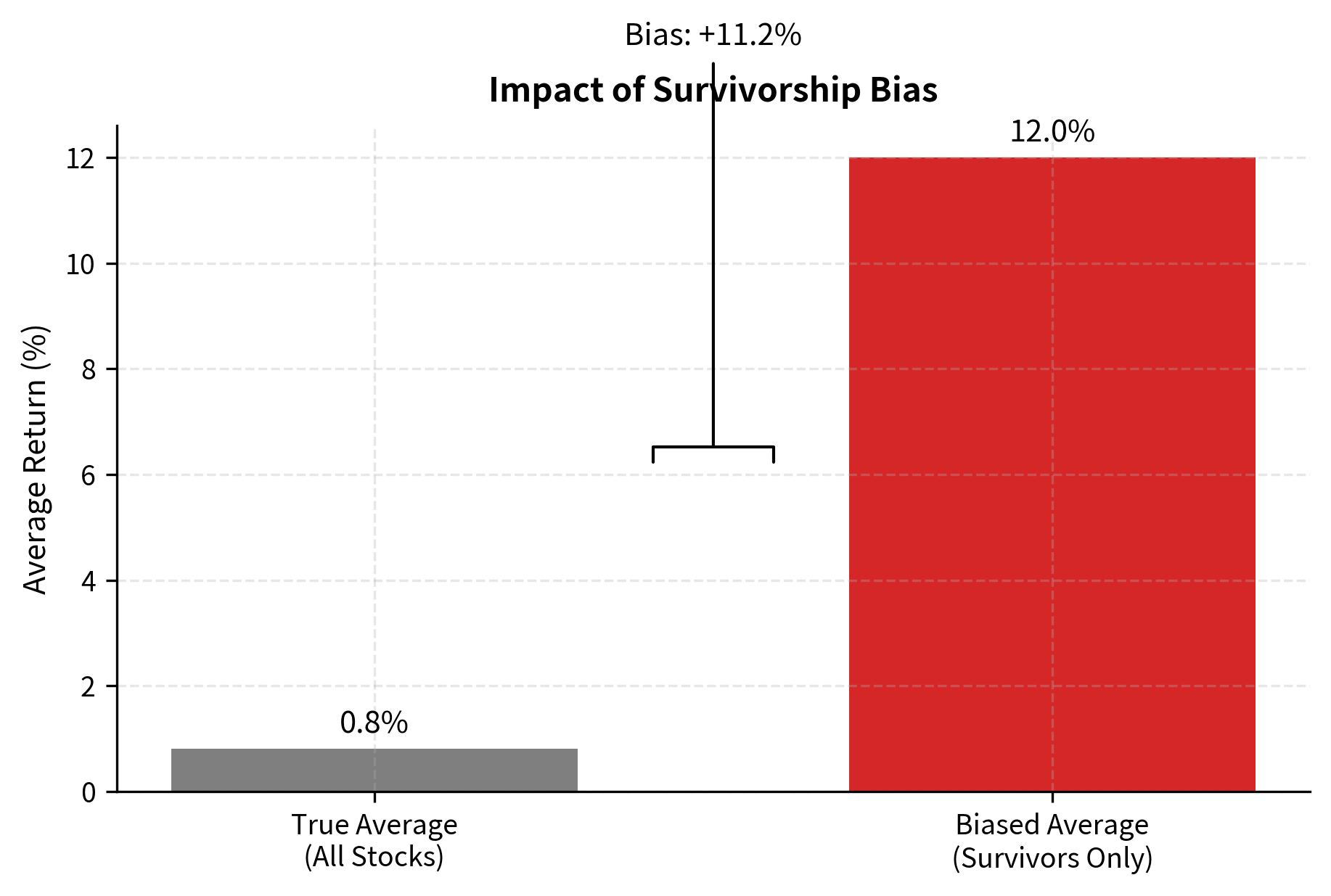
To avoid survivorship bias, use point-in-time databases that include delisted securities, such as CRSP or similar academic databases that preserve the complete historical record. When such databases aren't available, explicitly track when securities exit your investment universe and include their terminal returns in your calculations. This means recording the final price at which a delisted stock traded, or the acquisition price in a merger, rather than simply dropping the security from your dataset.
Overfitting and Data Snooping
Overfitting occurs when a strategy's parameters are tuned too precisely to historical data, capturing noise rather than genuine patterns. A strategy with many adjustable parameters can always be made to fit past data perfectly, because with enough flexibility, you can find a configuration that would have profited from the specific sequence of price movements that happened to occur. However, such over-optimized strategies typically fail in live trading because the idiosyncratic patterns they exploit are random coincidences that won't repeat.
Overfitting is the tendency of a model with too many degrees of freedom to fit the idiosyncratic features of a particular dataset rather than the underlying signal. In backtesting, an overfit strategy exploits historical coincidences that won't repeat. The strategy has learned the noise in the training data rather than the signal, and this noise-fitting provides no predictive power for future market behavior.
The problem intensifies through data snooping, which occurs when you test many strategies on the same dataset and select the best performer. Even if each individual strategy is reasonable and based on sound economic intuition, selecting the winner from a large pool of candidates introduces statistical bias. You're effectively optimizing across all strategies simultaneously, and the "best" strategy may simply be the one that happened to fit the random patterns in your particular dataset most closely.
To understand why this happens, consider that if you test 100 strategies with no genuine predictive power, you would expect about 5 of them to show "statistically significant" results at the 5% level purely by chance. If you test 1000 strategies, you'd expect about 50 false positives. The more strategies you test, the more likely you are to find one that looks profitable but has no real edge.
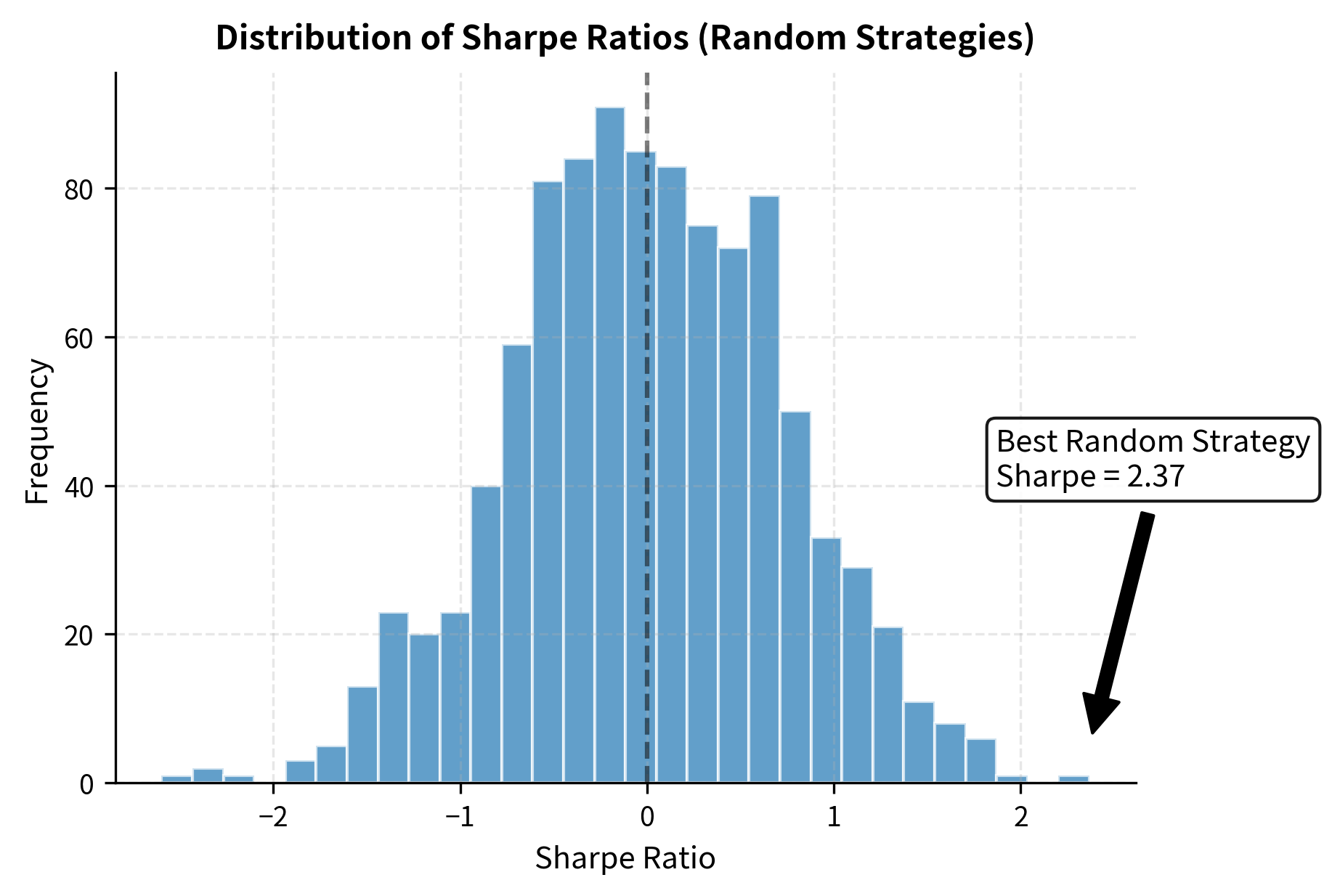
The best of 1000 random strategies shows a Sharpe ratio that would be impressive for a real strategy, but it has no predictive power whatsoever. The random strategy that happened to align with the market's movements during this particular period looks skilled, but this apparent skill is entirely illusory. This demonstration illustrates why we must account for the number of strategies tested when evaluating results, and why out-of-sample validation is so critical. A strategy that survives rigorous out-of-sample testing is much more likely to have genuine predictive power than one selected purely based on in-sample performance.
Other Common Biases
Several additional biases can corrupt backtest results and lead to overoptimistic assessments of strategy performance. Being aware of these pitfalls helps you design more robust simulations and interpret results more critically.
Additional biases include:
-
Transaction cost neglect: Ignoring costs can turn a profitable strategy into a losing one. High-turnover strategies are particularly vulnerable to the cumulative drag of commissions and spreads.
-
Market impact neglect: Assuming unlimited liquidity. Large orders often move prices against you, meaning historical closing prices may not be achievable for substantial volumes.
-
Rebalancing frequency mismatch: Testing at a higher frequency (e.g., daily) than is operationally feasible (e.g., monthly), ignoring execution delays.
-
Selection bias in time period: Testing only during favorable regimes, such as bull markets, which overstates performance compared to a full market cycle.
-
Data quality issues: Errors, missing values, or incorrect adjustments can produce spurious signals and persistent bias.
As we'll explore in the next chapter on transaction costs and market impact, realistic friction modeling can reduce apparent strategy returns by 50% or more for active strategies. This makes cost modeling one of the most important aspects of realistic backtesting.
Performance Metrics
Once you've run a bias-free backtest, you need metrics to evaluate the results and understand the risk-return characteristics of your strategy. As we discussed in Part IV on portfolio performance measurement, returns alone are insufficient for making informed decisions. We need risk-adjusted measures that account for the volatility and drawdowns incurred to achieve those returns. A strategy that earns 20% annual returns with 10% volatility is quite different from one that earns 20% with 40% volatility, even though the raw returns are identical.
Return Metrics
The foundation of performance measurement is the return series, which captures how the portfolio's value changed over time. From the simulated portfolio values, we compute various return statistics that describe the strategy's profitability and growth characteristics.
The Sharpe Ratio and Its Variants
The Sharpe ratio, covered extensively in Part IV, remains the dominant risk-adjusted performance measure in quantitative finance. It normalizes returns against risk, allowing for fair comparison between strategies with different volatility profiles. The fundamental insight behind the Sharpe ratio is that returns should be evaluated relative to the risk taken to achieve them. A high-return, high-risk strategy may be less attractive than a moderate-return, low-risk strategy when viewed through this lens.
The Sharpe ratio expresses excess return per unit of volatility, providing a standardized measure of risk-adjusted performance:
To understand this formula, let's examine each component. The term represents the annualized portfolio return, measuring how much the strategy earned over the evaluation period expressed as an annual rate. The term denotes the risk-free interest rate, typically proxied by Treasury bill yields, which represents the return you could have earned without taking any market risk. The difference is the excess return generated by the strategy over the risk-free alternative, capturing the additional compensation you received for bearing the strategy's risks. Finally, is the annualized standard deviation of portfolio returns, commonly called volatility, which measures the typical magnitude of return fluctuations around the mean.
The Sharpe ratio thus answers a crucial question: how much excess return did the strategy generate for each unit of risk it assumed? A Sharpe ratio of 1.0 means the strategy earned 1% of excess return for every 1% of volatility. Higher values indicate more efficient risk-reward tradeoffs, while negative values indicate the strategy failed to beat the risk-free rate.
The Sharpe ratio has important limitations that you should keep in mind when using it to evaluate strategies. It penalizes upside and downside volatility equally, treating a strategy that experiences large gains the same as one that experiences large losses. Additionally, it assumes returns are normally distributed, which may not hold for strategies with fat tails or asymmetric return profiles. Several alternative metrics address these limitations by focusing on specific aspects of risk that the Sharpe ratio overlooks.
Alternative metrics address specific limitations of the Sharpe ratio:
-
Sortino Ratio: Uses downside deviation (volatility of negative returns) instead of total volatility. This rewards strategies that achieve volatility through upside gains rather than losses.
-
Calmar Ratio: Divides annualized return by maximum drawdown. This highlights the worst loss experience, which is critical for assessing psychological and capital feasibility.
-
Information Ratio: Measures excess return relative to a benchmark divided by tracking error, capturing the consistency of outperformance.
Maximum Drawdown
Maximum drawdown measures the largest peak-to-trough decline in portfolio value. It represents the worst loss you would have experienced if you had the misfortune of buying at the top and selling at the bottom during the evaluation period. This metric captures a dimension of risk that volatility-based measures may miss: the severity of the worst period of losses.
To calculate drawdown at any point in time, we first need to establish the high-water mark, which is the highest portfolio value achieved up to that moment. The drawdown is then the percentage decline from that peak:
In this formula, represents the portfolio value at time , while denotes the high-water mark, which is the highest portfolio value observed up to time . The numerator gives the drawdown magnitude, measuring the current loss relative to the running peak. This value is always zero or negative, with more negative values indicating larger declines from the peak.
This formula quantifies the "pain" you experience at any point in time relative to your previous high-water mark. When the portfolio reaches a new high, the drawdown is zero. When the portfolio declines, the drawdown becomes negative, showing how far the portfolio has fallen from its best performance.
The maximum drawdown measures the worst loss over the entire evaluation period by finding the minimum, that is, the most negative, value in the drawdown series:
Here, is the percentage decline calculated at each time step , and the operator selects the most negative value from the entire series, representing the deepest trough reached during the evaluation period.
Maximum drawdown is particularly important because it relates directly to investor psychology and practical capital requirements. A strategy might have excellent risk-adjusted returns on paper but require holding through a 50% loss, which few investors can tolerate psychologically or financially. Many investors will abandon a strategy during a large drawdown, realizing losses at the worst possible time. Understanding the maximum drawdown helps set realistic expectations and determine appropriate position sizing.
Win Rate and Profit Factor
Beyond volatility-based metrics, traders often examine win/loss statistics that describe the distribution of individual trading outcomes. These metrics provide intuition about how the strategy generates its returns and can help identify potential problems.
Comprehensive Performance Report
Let's combine these metrics into a comprehensive performance analysis that provides a complete picture of strategy behavior:
The performance report quantifies the strategy's risk-return profile through multiple lenses. Metrics like the Sharpe ratio, which measures excess return per unit of risk, and maximum drawdown, which captures the worst peak-to-trough decline, provide a more complete picture than total return alone. By examining these metrics together, you can assess whether the strategy's returns are commensurate with the risks it takes and whether those risks are acceptable for your investment objectives.
Visualizing Performance
Visual analysis complements numerical metrics by revealing patterns in strategy behavior over time. While summary statistics condense performance into single numbers, charts show how that performance unfolded, making it easier to identify regime changes, unusual periods, and potential concerns.
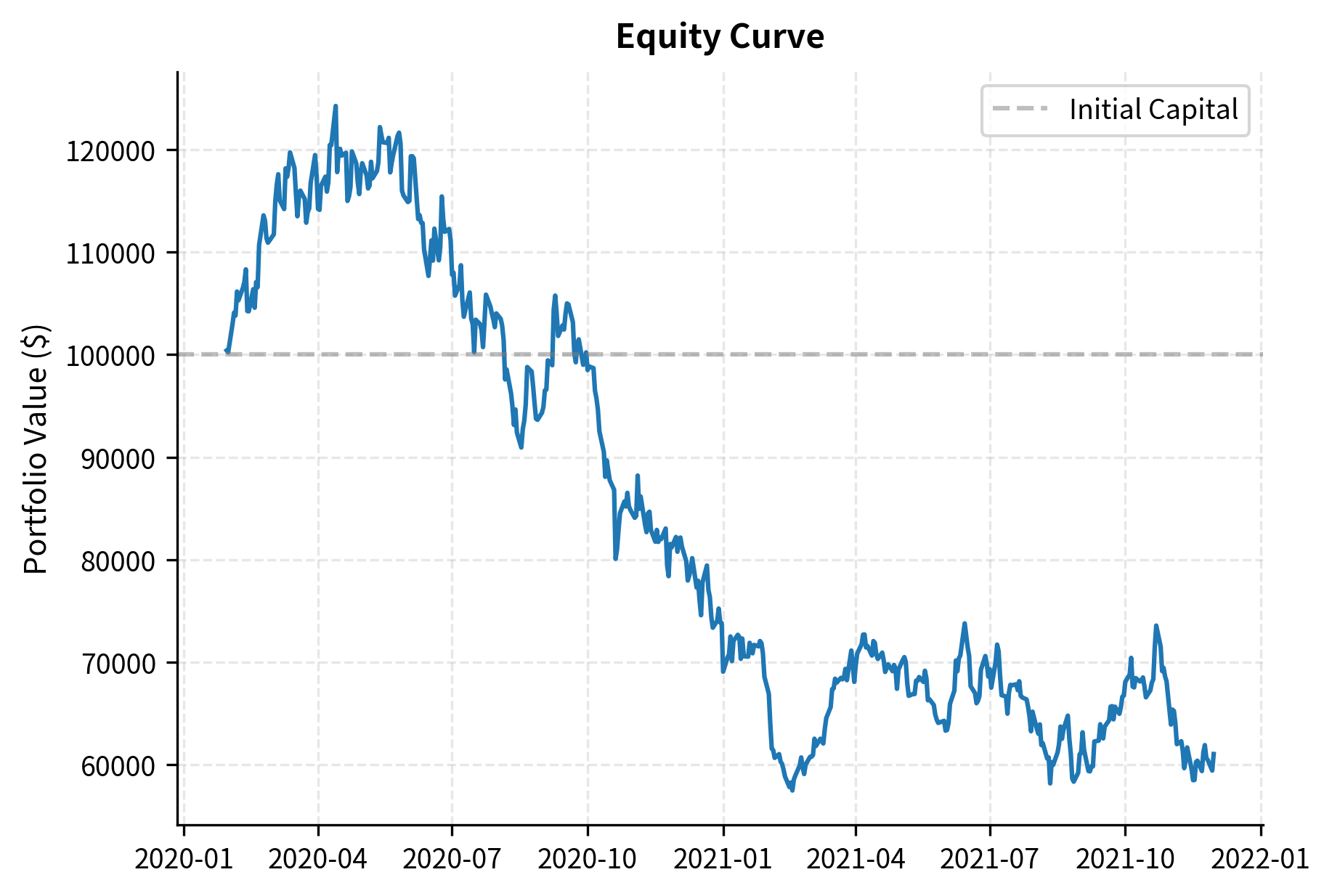
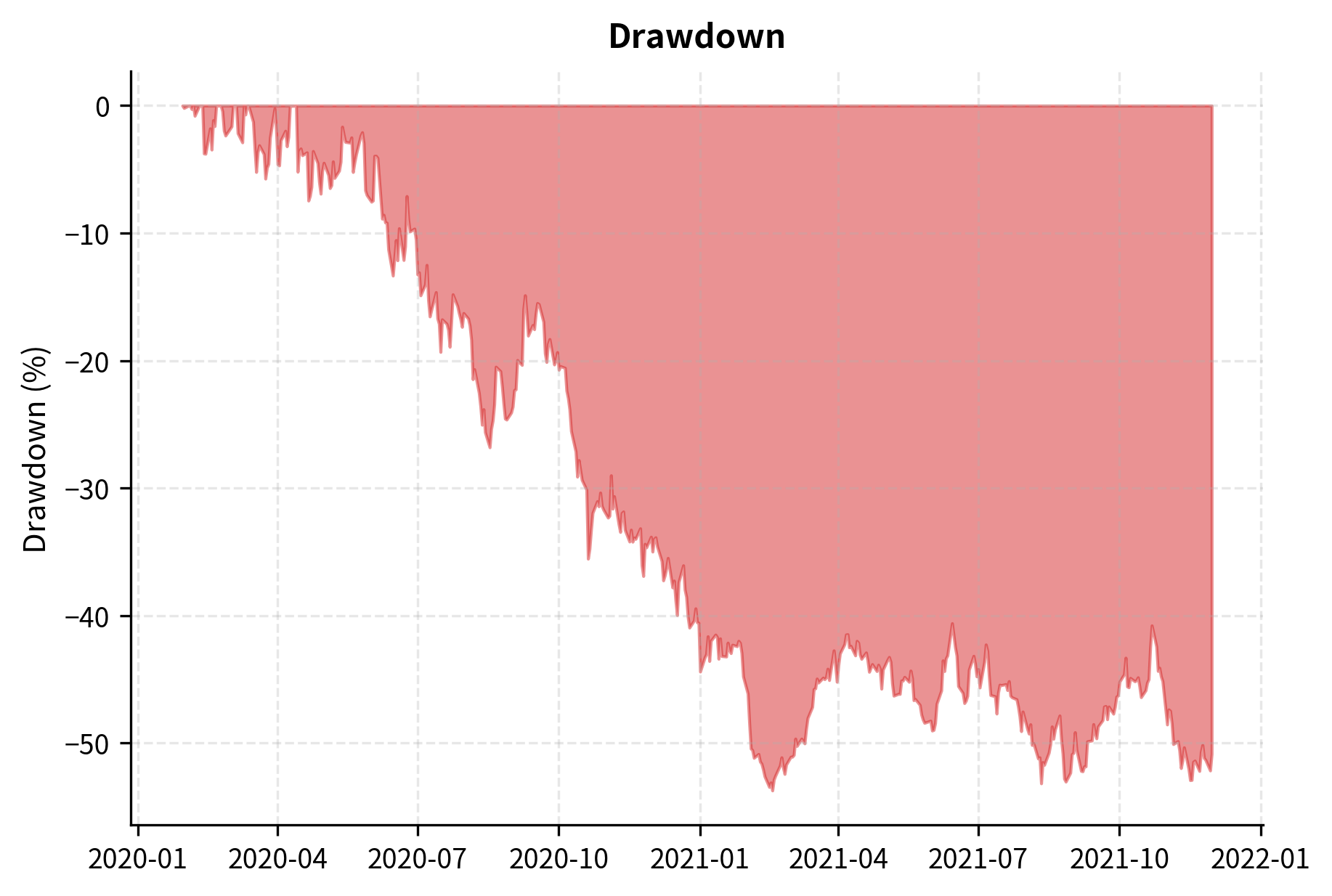
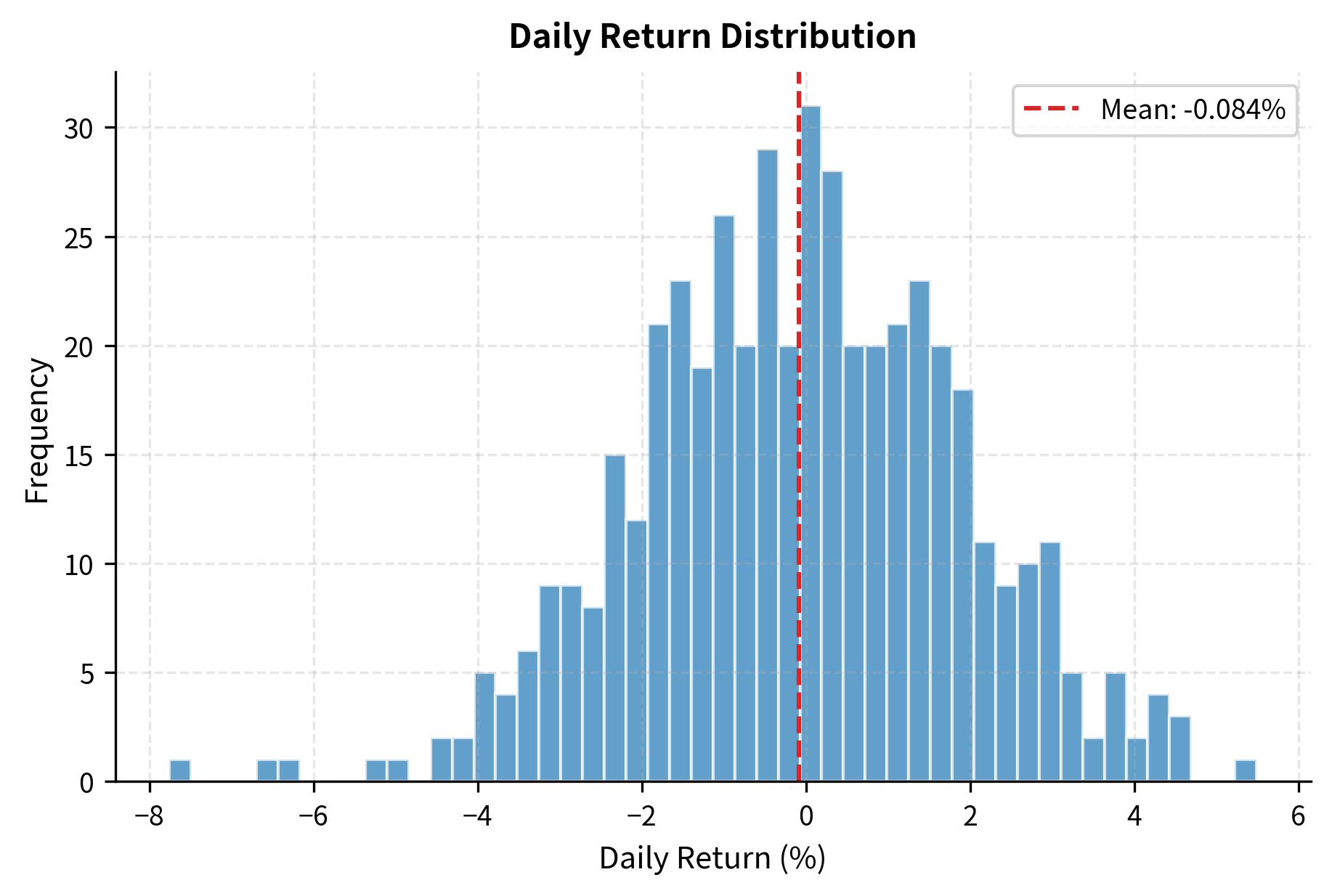
Out-of-Sample Testing and Validation
In-sample performance, which measures how a strategy did on the data used to develop it, tells us almost nothing about future performance. This is a counterintuitive but critical insight: the strategy was designed to perform well on that specific data, so finding that it does perform well provides little evidence of genuine predictive power. The true test of a strategy is out-of-sample evaluation, which assesses how it performs on data it has never seen. Only out-of-sample results can distinguish between strategies that have discovered real patterns and those that have merely memorized historical noise.
Train-Test Split
The simplest validation approach divides data into training and testing periods. The training period is used to develop and tune the strategy, while the testing period is held out for final evaluation. This mirrors how the strategy would actually be deployed: you develop it on historical data and then trade it going forward on new, unseen data.
The critical rule of out-of-sample testing is that you may only test on the held-out data once. If you test, don't like the results, modify your strategy, and test again, you've converted your test set into a training set. The strategy is now implicitly optimized to the "out-of-sample" data, because your modifications were guided by feedback from that data. This contamination is insidious because it's easy to rationalize each modification as a reasonable improvement, but the cumulative effect is to fit the test data just as thoroughly as the original training data.
Walk-Forward Analysis
Walk-forward analysis extends the train-test concept by repeatedly retraining the strategy as new data becomes available. This approach better simulates real-world conditions where strategies are periodically updated to adapt to changing market conditions. Rather than training once and testing once, walk-forward analysis creates a sequence of train-test cycles that together span the entire evaluation period.
The process works as follows: first, train the strategy on an initial window of data and select the best parameters. Then, apply those parameters to the subsequent testing window and record the out-of-sample results. Next, roll the windows forward, incorporating the previous test data into the new training set. Repeat this process until you've walked through the entire dataset. The final performance is measured by combining all the out-of-sample testing periods.
Walk-forward analysis reveals whether a strategy's edge persists when parameters are updated over time. It also shows parameter stability: if the optimal lookback swings wildly between windows, the strategy may be fitting noise rather than capturing a stable relationship. Stable parameters that change gradually over time suggest a more robust underlying pattern, while erratic parameter changes indicate that the optimization is chasing random fluctuations in the training data.
Cross-Validation for Strategy Development
When developing new strategies, k-fold cross-validation can provide more robust estimates of out-of-sample performance by averaging results across multiple train-test splits. However, standard cross-validation ignores the time-series nature of financial data, where random shuffling would create look-ahead bias by mixing future observations into the training set.
Time-series cross-validation respects temporal ordering by always training on earlier data and testing on later data. This ensures that each test fold uses only information that would have been available at the time of trading. The training window typically expands over time, incorporating more historical data as it becomes available.
The expanding window cross-validation creates multiple test sets while respecting the time order. Notice that each training set ends before its corresponding test set begins, and that the training sets grow larger over time. This approach allows us to evaluate how the strategy would have performed across different market conditions without using future data. By averaging performance across all folds, we get a more stable estimate of out-of-sample performance than a single train-test split would provide.
Statistical Significance Testing
Even with proper out-of-sample testing, observed performance could arise from luck rather than skill. A strategy might show positive returns in the test period purely by chance, especially if the test period is short or the returns are highly variable. Statistical tests help quantify this uncertainty by estimating the probability that the observed results could have occurred under the assumption that the strategy has no genuine predictive power.
The null hypothesis is typically that the strategy has zero expected return, meaning no skill. We compute the t-statistic to measure how many standard errors the observed mean return is away from zero:
This formula tells us how unusual the observed returns are under the null hypothesis of no skill. The term is the mean periodic return of the strategy, representing the average profit or loss per period. The term denotes the standard deviation of returns, capturing the typical variability in performance from period to period. The term represents the total number of observations, which determines how precisely we can estimate the true mean. The denominator is the standard error of the mean, representing our uncertainty about the true expected return given the observed data. Finally, is the number of standard errors the mean is away from zero, the null hypothesis value.
A large positive t-statistic suggests the strategy's returns are unlikely to have arisen by chance. We can convert this to a p-value that represents the probability of observing such extreme results if the strategy truly had no edge.
A low p-value, typically below 0.05, suggests the strategy's returns are unlikely to result from chance alone. However, remember to adjust for multiple testing if you've evaluated many strategies. Methods like the Bonferroni correction or false discovery rate (FDR) control, which we covered in Part I on statistical inference, become essential when you've tested dozens or hundreds of strategy variants. Without such adjustments, the probability of finding at least one spuriously significant result grows rapidly with the number of tests conducted.
Building a Complete Backtest
Let's bring together all the concepts into a complete, realistic backtest implementation. We'll test a simple mean-reversion strategy while carefully avoiding biases and applying proper validation. This comprehensive example demonstrates how the individual components combine into a coherent backtesting workflow.
Strategy Definition
Our strategy will trade based on Bollinger Bands, a mean-reversion approach where we buy when price falls below the lower band and sell when it rises above the upper band. The economic intuition is that prices tend to revert to their recent average, so extreme deviations represent temporary mispricings that will correct. When the price falls significantly below its moving average, the asset is potentially oversold and likely to bounce back. When the price rises significantly above its moving average, the asset is potentially overbought and likely to pull back.
Backtest Engine with Transaction Costs
We'll incorporate transaction costs to make the simulation more realistic. Transaction costs are a critical component of any serious backtest because they can dramatically affect net profitability, especially for strategies that trade frequently. A strategy that looks highly profitable before costs may become marginal or even unprofitable after accounting for the friction of trading.
The trade log allows us to verify that the strategy executes as intended, buying and selling at the correct signals. Each trade record includes the date, action type, number of shares, execution price, and transaction cost. This detailed logging is essential for debugging and for understanding how the strategy behaves in different market conditions. The total transaction costs figure highlights the friction that will reduce net returns, a critical factor often overlooked in theoretical models that assume frictionless markets.
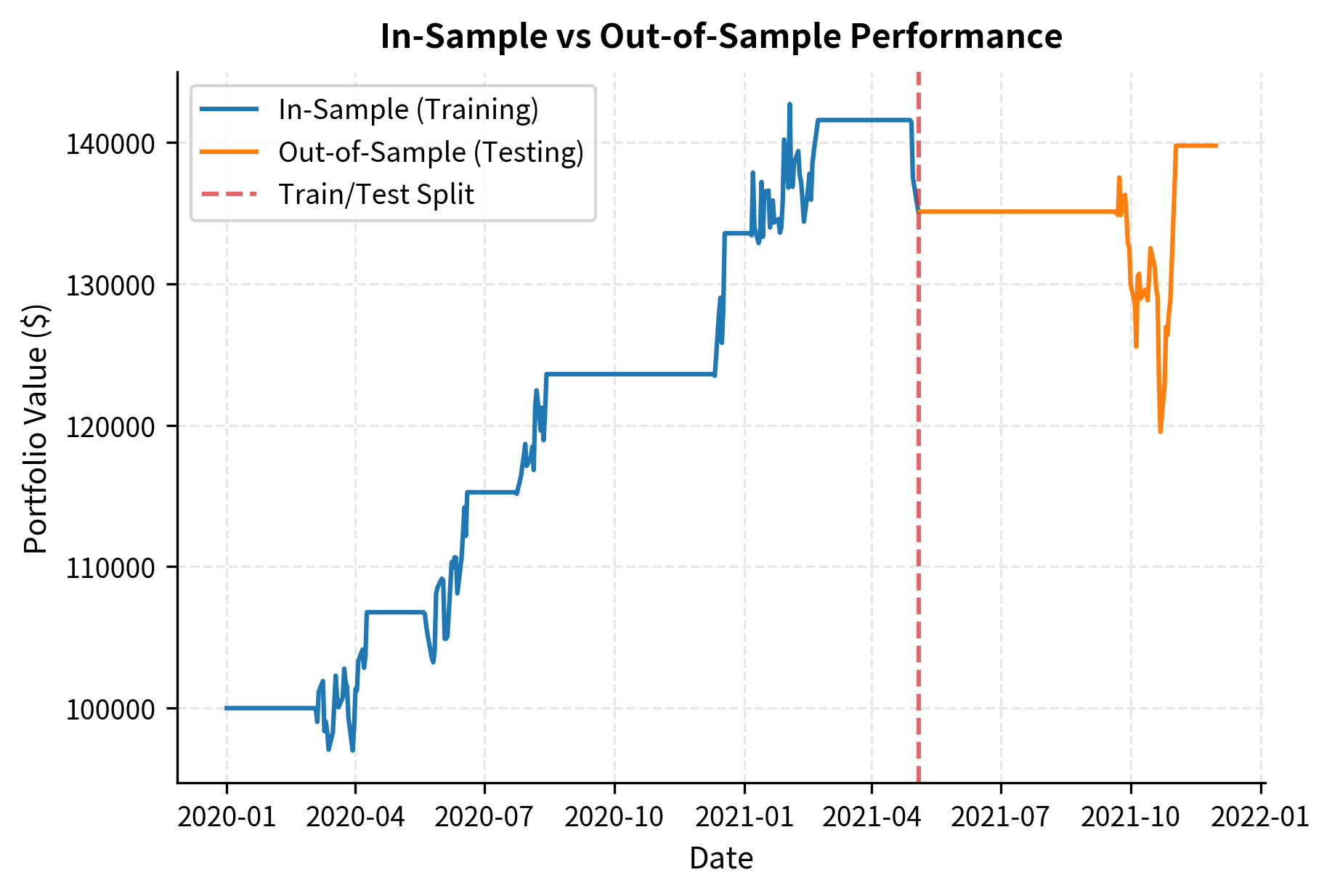
Comparing In-Sample vs Out-of-Sample Performance
Finally, let's validate our strategy using proper train-test methodology. We'll optimize the strategy parameters on training data and then evaluate performance on held-out test data to assess how much of the apparent alpha is genuine versus overfit.
The gap between in-sample and out-of-sample performance is typical and expected. This performance degradation, where out-of-sample results are worse than in-sample results, occurs because some of the patterns captured during optimization are noise rather than signal. A strategy that shows similar performance in both periods is more likely to be robust than one where in-sample results far exceed out-of-sample results. When you observe a large gap, it suggests that a significant portion of the apparent alpha was actually overfitting to the training data rather than capturing genuine market inefficiencies that will persist going forward.
Limitations and Impact
Backtesting, despite its importance, has fundamental limitations that you must understand. Recognizing these limitations doesn't mean abandoning backtesting, but rather using it with appropriate humility and supplementing it with other forms of analysis.
Key limitations include:
-
Testing the past, not the future: Markets evolve and regimes change. Strategies that exploited specific historical conditions (e.g., falling interest rates) may fail as those conditions disappear. Stationarity rarely holds in financial markets.
-
Data limitations: High-resolution data often has limited history, while long-term data may lack the granularity needed for certain strategies. This necessitates a tradeoff between simulation realism and historical depth.
-
Execution reality: Simulations often assume trades execute at observed prices without friction. In reality, large orders impact prices. Ignoring market impact can make non-scalable strategies appear profitable.
Despite these limitations, backtesting remains indispensable because it provides the only systematic way to evaluate ideas before risking real capital. The discipline of building a rigorous backtesting framework forces you to formalize your strategy completely, think through data requirements, and establish performance expectations. Strategies that fail in backtests almost certainly fail in live trading; strategies that pass are at least candidates for further testing.
The impact of proper backtesting methodology on quantitative trading has been enormous. The development of walk-forward analysis, cross-validation for financial data, and statistical significance testing for trading strategies has raised the bar for what constitutes evidence of alpha. Techniques for detecting and correcting biases have made it harder for fund managers to present spurious results as genuine skill. The widespread availability of backtesting tools has democratized quantitative trading, allowing individual traders to test ideas that once required institutional resources.
Looking ahead, the next chapters on transaction costs, market microstructure, and execution algorithms will add the remaining pieces needed for realistic strategy evaluation. A complete simulation must account for how you'll actually trade, not just what positions you want to hold.
Summary
This chapter covered the complete workflow for backtesting trading strategies, from building simulation frameworks to validating results statistically. The key takeaways are:
Backtesting architecture requires careful attention to time-series ordering. Whether using event-driven or vectorized approaches, signals must be computed using only past information, and positions must be lagged relative to the data used to generate them.
Biases corrupt backtests in subtle but devastating ways. Look-ahead bias uses future information; survivorship bias excludes failed assets; overfitting finds patterns in noise. Multiple testing across many strategies virtually guarantees finding spuriously profitable results if not properly adjusted.
Performance metrics must be risk-adjusted. The Sharpe ratio remains the standard, but supplementary metrics like maximum drawdown, Sortino ratio, and win rate provide additional perspective. Statistical significance testing quantifies how likely observed performance is to have arisen by chance.
Out-of-sample validation is essential for any serious strategy development. Simple train-test splits provide a first check; walk-forward analysis and time-series cross-validation offer more robust estimates of real-world performance. The gap between in-sample and out-of-sample results reveals how much of apparent alpha is actually overfitting.
Transaction costs matter and must be included even in preliminary backtests. We'll explore sophisticated cost models in the following chapter, but even a simple percentage cost changes which strategies appear viable.
The ultimate purpose of backtesting is not to prove a strategy works but to rigorously test whether it might work. A strategy that survives comprehensive backtesting with realistic assumptions and shows robust out-of-sample performance is a candidate for paper trading and, eventually, live deployment, topics we'll address in later chapters on trading systems and strategy deployment.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about backtesting and simulation.

Comments