

Learn how mT5 extends T5 to 101 languages using temperature-based sampling, the mC4 corpus, and 250K vocabulary for effective cross-lingual transfer.

This article is part of the free-to-read Language AI Handbook
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
mT5
T5's text-to-text framework demonstrated that a single model could handle diverse NLP tasks through unified formatting. However, T5 was trained exclusively on English text from the C4 corpus. This English-only focus meant the model could not process other languages without substantial additional training. mT5 (multilingual T5) addresses this limitation by extending the T5 paradigm to 101 languages while preserving the elegant text-to-text approach we covered in the T5 chapters.
The challenge of building a truly multilingual model goes beyond simply adding more training data. Languages differ dramatically in their available text resources. English dominates the web, while many languages have orders of magnitude less content. Training naively on this imbalanced data would produce a model that excels at English but performs poorly for low-resource languages. mT5 addresses this imbalance through careful corpus curation, temperature-based language sampling, and an expanded multilingual vocabulary.
The mC4 Corpus
Building a multilingual model requires multilingual data. The mT5 team created mC4 (multilingual Colossal Clean Crawled Corpus) by applying language-specific filtering to Common Crawl web data. This process extracted text in 101 languages, resulting in a corpus orders of magnitude larger than previous multilingual datasets.
The corpus construction followed similar quality filtering steps to the English C4 we discussed in the T5 pre-training chapter, but applied language detection to separate content:
- Language identification: Each page was classified using CLD3 (Compact Language Detector), keeping only pages where the primary language exceeded a confidence threshold
- Line-level deduplication: Removed duplicate lines within each language's subcorpus to reduce boilerplate and repeated content
- Quality filtering: Applied heuristics to remove pages with too few words, excessive punctuation, or other quality issues
The resulting corpus shows extreme size variation across languages:
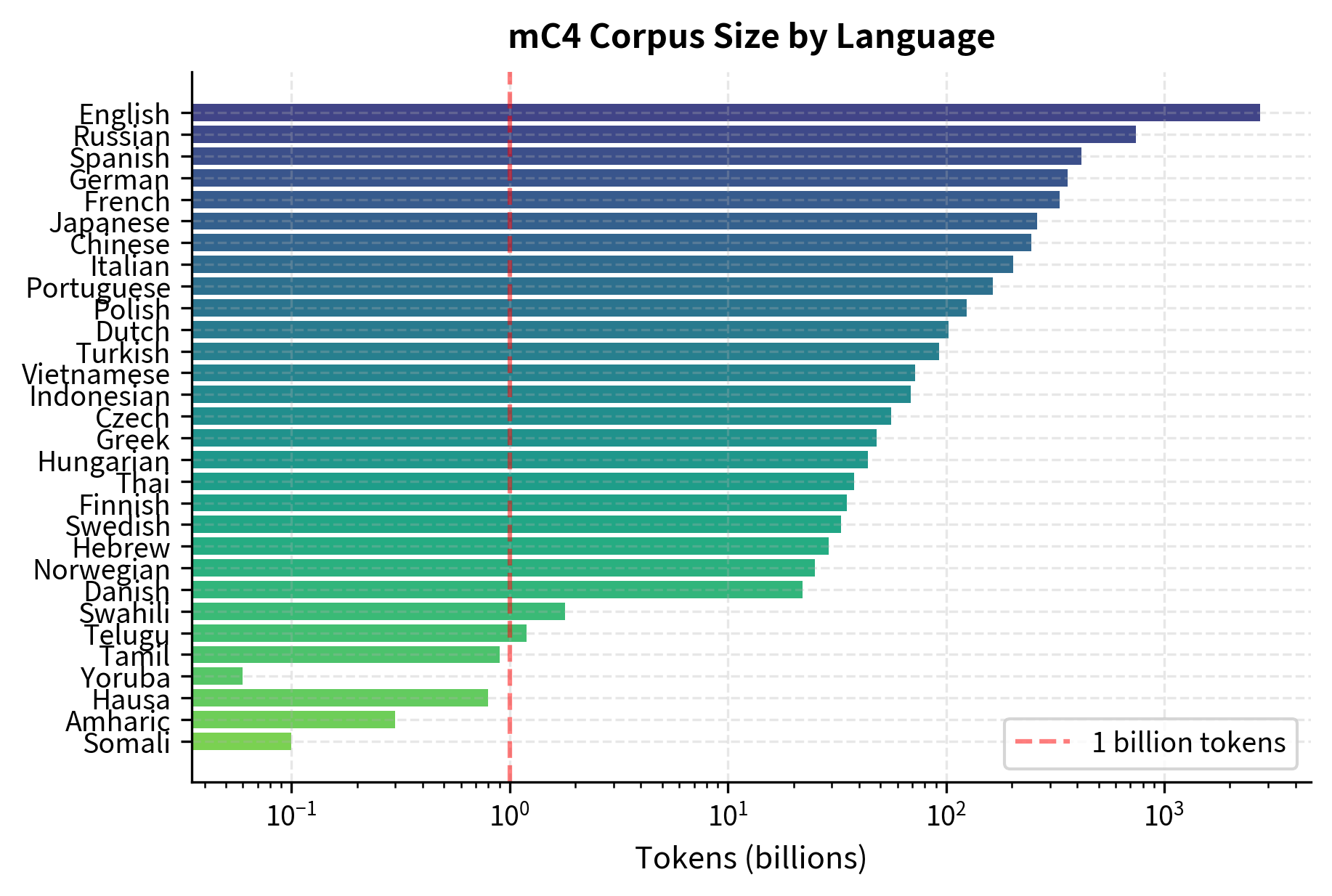
English contains roughly 2.7 trillion tokens, while some African languages like Yoruba have only 60 million tokens, a ratio of over 45,000:1. This imbalance creates a fundamental problem: training proportionally to data size would essentially ignore low-resource languages. Equal sampling would massively oversample (and overfit to) low-resource data while underutilizing high-resource content.
Temperature-Based Language Sampling
The large disparity in corpus sizes across languages presents a fundamental challenge for multilingual model training. If we simply train on data in proportion to how much exists, English would dominate the training process. The model would see English text roughly 45,000 times more often than Yoruba text. Such a model might achieve excellent English performance, but would perform poorly for speakers of low-resource languages. On the other hand, if we sample equally from all languages, we would cycle through the entire Yoruba corpus thousands of times while barely scratching the surface of available English data. This leads to severe overfitting on low-resource languages and underutilization of high-resource ones.
To address the resource imbalance, mT5 uses temperature-based sampling that interpolates between proportional and uniform sampling. This approach allows practitioners to control the tradeoff between respecting natural data proportions and ensuring adequate representation for all languages. Let represent the probability of sampling from language during training. If we sample proportionally to corpus size, we have:
where:
- : the probability of sampling from language during training
- : the number of tokens in language 's subcorpus
- : the total number of tokens across all languages, serving as a normalizing constant
This straightforward proportional approach would give English roughly 27% of all samples while many languages would appear in less than 0.01% of batches, essentially invisible during training.
The key insight behind temperature sampling is that we can systematically compress the differences between corpus sizes by applying a mathematical transformation. Temperature sampling modifies these probabilities by raising them to a power , where is the temperature. The intuition is that the exponent acts as a "flattening" operator on the distribution. When we raise numbers of vastly different magnitudes to a small power, their differences shrink dramatically. Consider what happens when you raise both 1,000,000 and 1 to the power 0.01: you get approximately 1.15 and 1.0 respectively. The millionfold difference has compressed to just 15%. This compression is precisely what temperature sampling exploits:
where:
- : the temperature-adjusted sampling probability for language
- : the temperature parameter controlling the balance between proportional and uniform sampling
- : the corpus size raised to power , which compresses differences between languages as increases
- : the sum of adjusted corpus sizes across all languages, ensuring probabilities sum to 1
The key insight is that as temperature increases, the exponent approaches zero, making approach 1 for all languages regardless of their original corpus size. This progressively flattens the distribution toward uniform sampling. Understanding this behavior requires thinking carefully about what happens to the exponentiation as the temperature parameter changes.
To see why this works mathematically, consider two extreme cases:
- When : We have , so probabilities are exactly proportional to corpus size
- When : We have for all languages, giving uniform probabilities of where is the number of languages
The benefit of this approach becomes clear when we consider intermediate temperatures. Rather than requiring a separate mechanism to interpolate between proportional and uniform sampling, the temperature parameter provides a continuous dial that smoothly transitions between these extremes. For example, with English at 2749B tokens and Yoruba at 0.06B tokens, at the ratio is 45,817:1, but at the ratio becomes \approx 1.1{:}1$, a significant compression. This means that even with temperature sampling, high-resource languages still receive slightly more training signal, reflecting their richer and more diverse content, but the gap narrows enough that low-resource languages can learn meaningful representations.
Temperature controls interpolation between sampling strategies. At , sampling is proportional to corpus size. As , sampling approaches uniform across languages. The mT5 authors found to work well, significantly boosting low-resource languages while still favoring high-resource languages.
Let's see how temperature affects sampling probabilities:
The table reveals the substantial effect of temperature on sampling distribution. At (proportional sampling), English would comprise over 65% of training data while Yoruba gets essentially zero. At (used by mT5), English is reduced to about 4.5% while Yoruba increases to 2.5%. This represents a large boost for low-resource languages. Yoruba's sampling probability increases by a factor of over 1000. The practical consequence is important: a model trained with proportional sampling would see Yoruba text so rarely that it could never learn the language's patterns, while temperature sampling ensures Yoruba appears frequently enough to develop genuine language understanding.
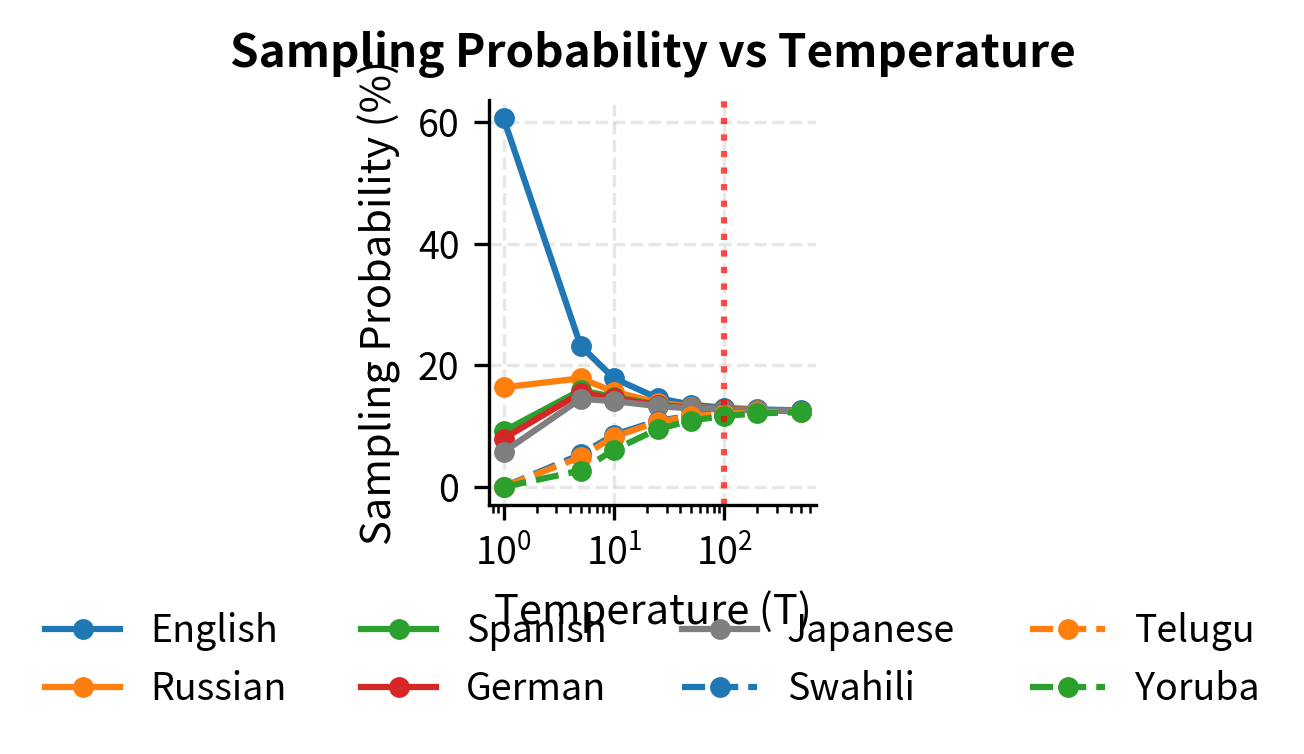
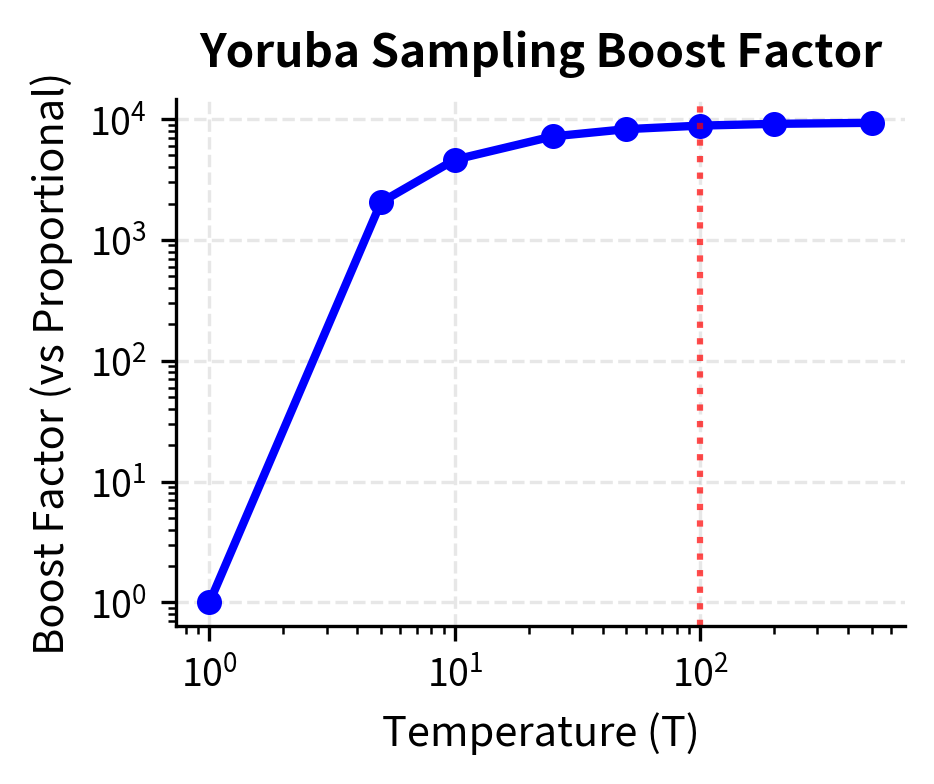
The temperature-based approach allows low-resource languages to receive meaningful training signal without completely ignoring the abundant high-resource data. However, this comes with a tradeoff: high-resource language performance slightly decreases compared to what could be achieved with proportional sampling. The mT5 authors found provided a good balance between these competing objectives. This choice reflects careful empirical tuning. Lower temperatures would still underrepresent low-resource languages, while higher temperatures would waste the rich diversity of high-resource data by undersampling it.
The code demonstrates that at , English's sampling probability drops from over 65% to around 14%, while Yoruba increases from nearly 0% to about 2%. This represents a boost factor of over 1000x for the low-resource language.
Multilingual Tokenization
Training a single model on 101 languages requires a vocabulary that can effectively tokenize all of them. This presents a challenging problem combining computational linguistics and machine learning efficiency. As we covered in the SentencePiece chapter, subword tokenization algorithms learn vocabularies from data by identifying frequently occurring character sequences. The challenge for multilingual models is that vocabulary slots are finite. A larger vocabulary means more parameters in the embedding layer and slower softmax computation during training and inference. Yet a vocabulary that is too small cannot adequately represent the diverse morphological patterns and writing systems found across 101 languages.
mT5 uses a SentencePiece unigram model with a vocabulary of 250,000 subword tokens, compared to T5's 32,000 tokens for English only. This 8x increase accommodates the diverse character sets and morphological patterns across 101 languages. The expansion is necessary because different language families have fundamentally different word formation rules: agglutinative languages like Turkish build complex words by chaining morphemes, while isolating languages like Chinese use single characters to represent concepts. A vocabulary optimized for English would fragment Turkish words into unrecognizable pieces while failing to provide useful decompositions for Chinese characters.
The vocabulary training process samples from mC4 using the same temperature-based sampling as model training. This design choice is crucial for ensuring low-resource languages contribute meaningful vocabulary entries rather than being drowned out by English. Without temperature sampling during vocabulary construction, the tokenizer would learn subword patterns primarily from English text, leading to poor tokenization quality for low-resource languages.
Temperature sampling ensures that even low-resource languages contribute substantial training data for vocabulary learning. Without this adjustment, languages like Yoruba might have fewer than 200 characters in the training sample. This is far too few for meaningful subword discovery. The SentencePiece algorithm needs sufficient examples of each language to identify common character patterns and build effective subword units.
Script Coverage
The 250K vocabulary must cover diverse writing systems including Latin, Cyrillic, Arabic, Hebrew, Chinese, Japanese, Korean, and many others. Each writing system brings its own characteristics: alphabetic scripts like Latin and Cyrillic build words from individual letters, syllabic scripts like Japanese hiragana represent syllables, and logographic scripts like Chinese use characters that represent morphemes or words. The vocabulary breakdown reflects this diversity, with capacity allocated across script families to ensure adequate coverage:
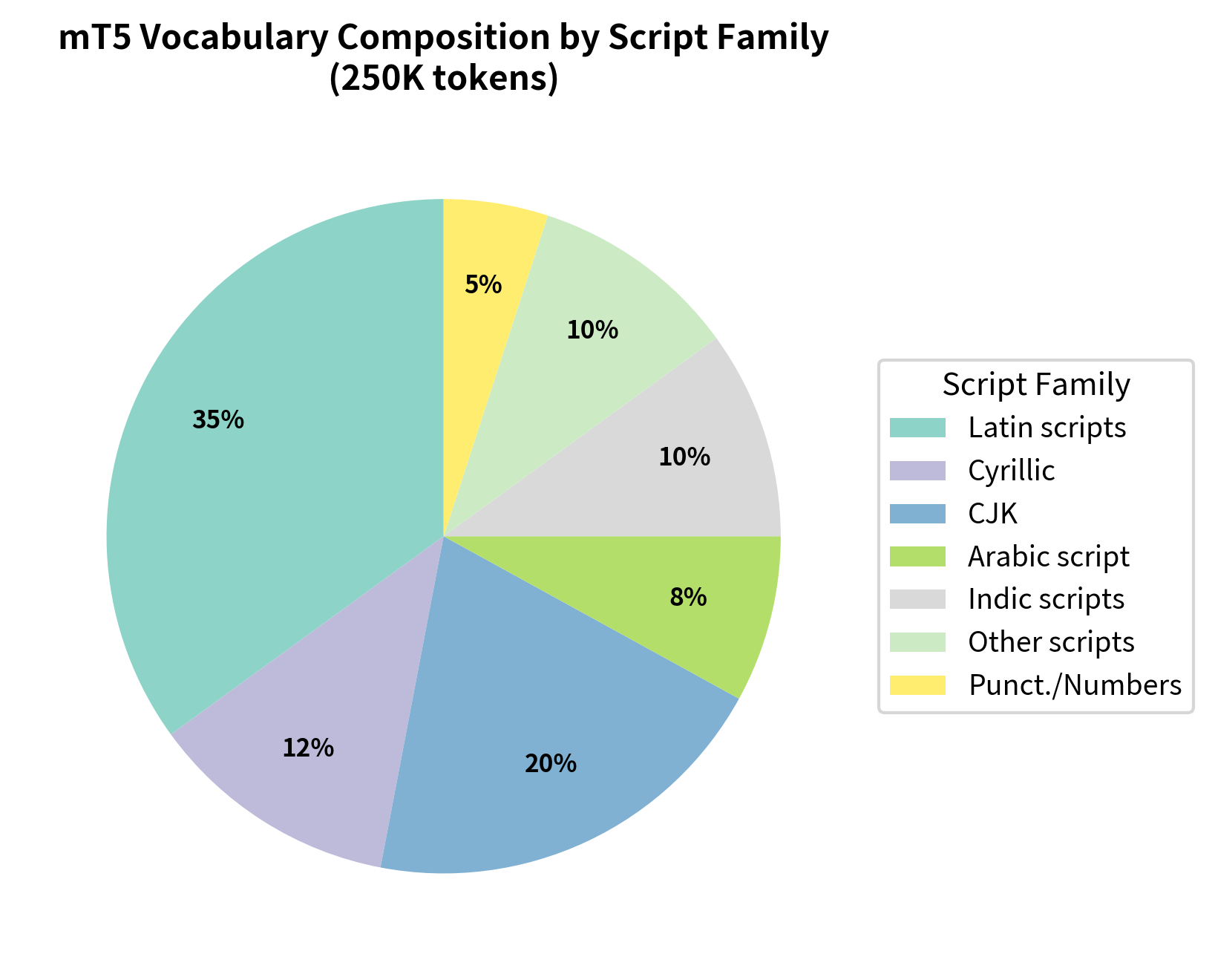
The vocabulary expansion from 32K to 250K tokens has significant implications for model efficiency. Each token requires an embedding vector that maps the discrete token to a continuous representation the model can process. The embedding matrix size therefore grows proportionally with vocabulary size, creating a direct tradeoff between linguistic coverage and parameter efficiency:
The embedding layer expansion from 32.8M to 256M parameters represents a significant overhead, particularly for smaller model variants. For mT5-Small with approximately 300M total parameters, the embeddings alone account for a substantial fraction of model capacity. This means that a non-trivial portion of the model's learning capacity is dedicated purely to representing the expanded vocabulary, leaving less capacity for learning language understanding and generation. The designers of mT5 judged this tradeoff worthwhile because adequate vocabulary coverage is foundational. A model cannot learn patterns in text it cannot properly tokenize.
Tokenization Efficiency
Multilingual tokenizers face a fertility tradeoff. Tokens optimized for one language may fragment words in another, leading to longer sequences and slower processing. This phenomenon occurs because subword patterns that are common in one language may be rare or nonexistent in another. For instance, the English suffix "-tion" appears frequently and would likely become a single token. However, this character sequence rarely occurs in Japanese. When mT5's tokenizer encounters Japanese text, it must use different subword patterns entirely. Let's examine how mT5's tokenizer handles different languages:
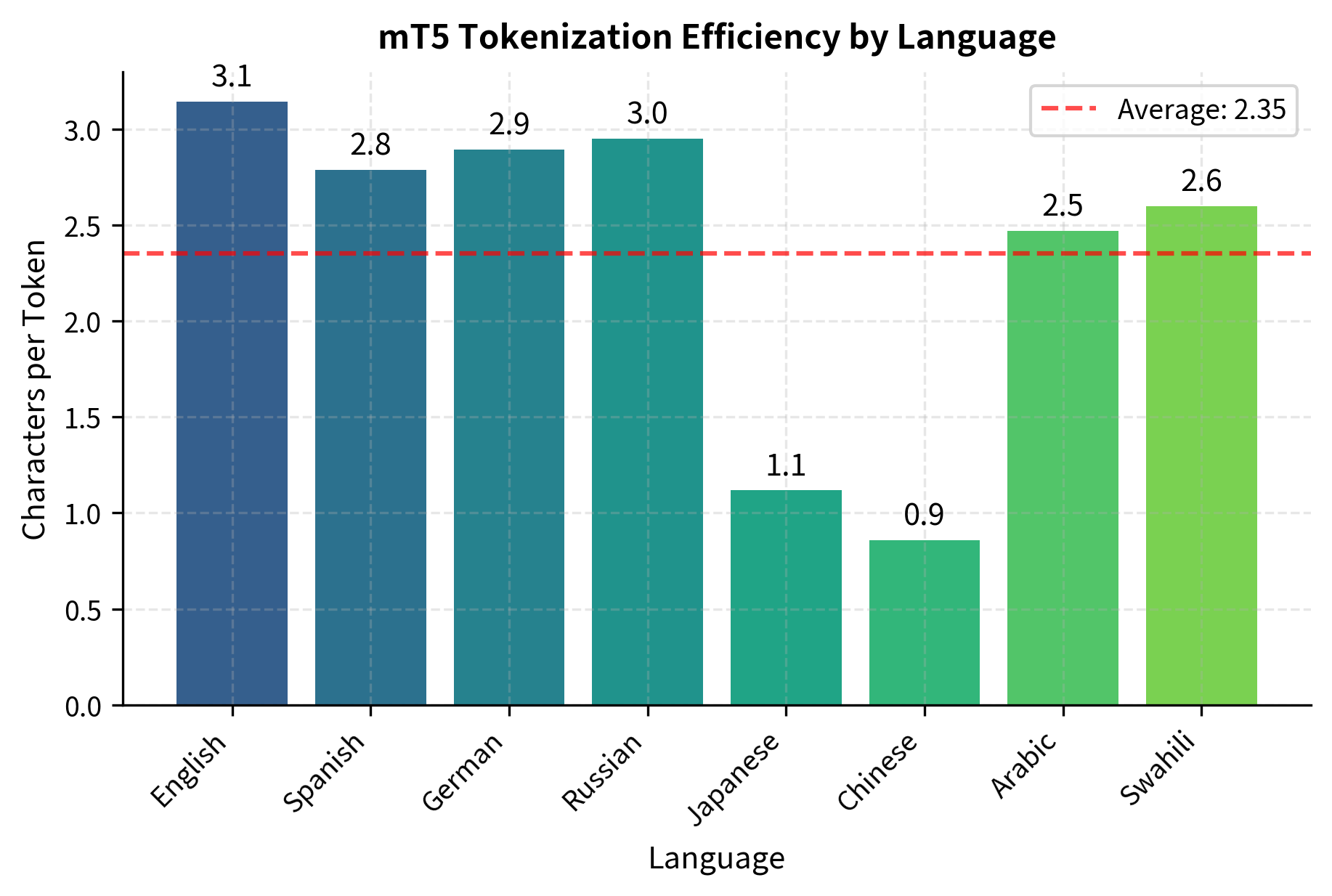
The tokenization efficiency results show that Latin-script languages like English, Spanish, and German achieve roughly 4-6 characters per token, while languages like Japanese and Chinese with unique scripts show different patterns. Arabic script languages fall somewhere in between. These efficiency differences directly impact sequence lengths. Less efficient tokenization means longer sequences for the same content, which affects both computational cost and the model's ability to capture long-range dependencies within its context window. A sentence that tokenizes to 10 tokens in English might require 20 tokens in another language, effectively halving the amount of context the model can consider for that language within a fixed context window.
Cross-Lingual Transfer
One of mT5's most powerful capabilities is cross-lingual transfer: the ability to fine-tune on data in one language and achieve reasonable performance in others. This property emerges from the shared multilingual representations learned during pre-training. When the model learns to predict masked spans across 101 languages simultaneously, it develops internal representations that capture language-universal patterns in how text structures information and expresses meaning.
Zero-Shot Cross-Lingual Transfer
In zero-shot transfer, a model is fine-tuned on task data in one language (typically English, where labeled data is abundant) and evaluated on the same task in other languages without seeing any target-language training examples. This capability is valuable because practitioners can leverage English datasets and achieve reasonable performance across dozens of languages without requiring labeled data in every language:
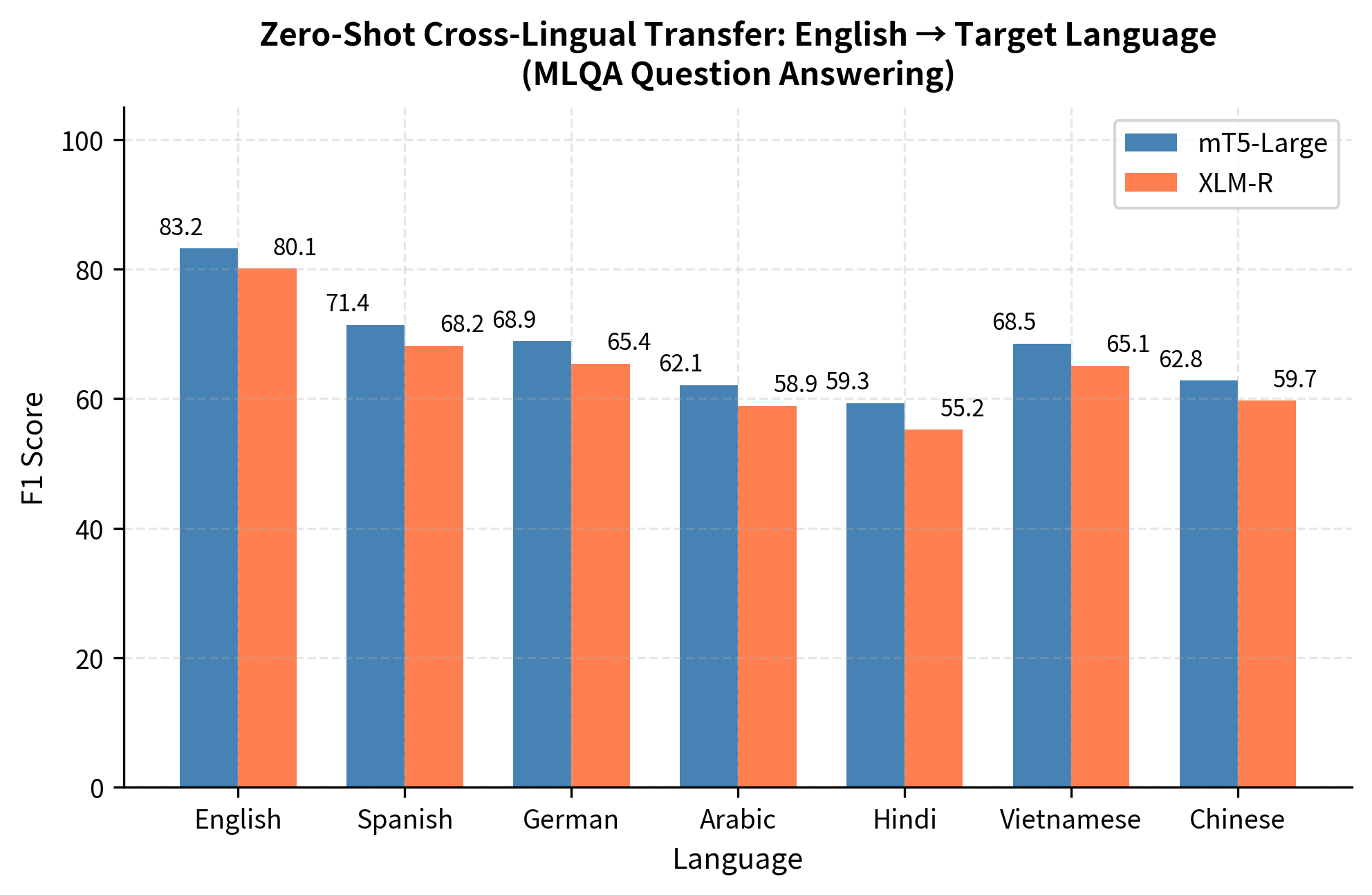
The visualization shows that mT5-Large achieves strong cross-lingual transfer, with Spanish and German (both related to English) reaching F1 scores above 68, while more distant languages like Hindi and Arabic show scores around 59-62. Notably, mT5 outperforms XLM-R across all languages, with improvements ranging from 2-4 F1 points. The performance gradient from English through related languages to distant languages reveals how linguistic similarity affects transfer success.
Transfer performance correlates with several factors:
- Linguistic similarity: Languages related to English (like German and Spanish) typically show better transfer than distant languages
- Script overlap: Languages sharing Latin script often transfer better due to shared subword tokens
- Pre-training data quantity: Languages with more mC4 data develop richer representations that support better transfer
Mechanisms of Cross-Lingual Transfer
Cross-lingual transfer works because mT5 learns language-agnostic representations during pre-training. The model doesn't learn 101 separate languages in isolation. Instead, it learns a unified representation space where similar concepts across languages map to similar regions, regardless of how those concepts are expressed on the surface. Several factors contribute to this alignment:
Shared vocabulary: When languages share subword tokens, especially cognates and loanwords, knowledge about these tokens transfers directly. For example, "computer" appears in similar forms in many languages. This allows the model to leverage what it learns about technology concepts in English text when processing Spanish or German text about the same topics. This lexical overlap creates anchor points that align representations across languages.
Parallel structure learning: The span corruption objective forces the model to learn syntactic and semantic patterns. Many of these patterns, such as subject-verb-object ordering, generalize across languages. When the model learns that a certain span position typically contains an action word in English, this knowledge can transfer to languages with similar sentence structure. Even when word orders differ, the model learns abstract notions of "what information completes this context" that transcend specific grammatical rules.
Semantic alignment: By processing text in multiple languages about similar topics, the model learns that certain concepts are expressed similarly across languages, even when the surface forms differ. News articles about international events, Wikipedia pages about scientific concepts, and web content about popular topics appear in many languages, providing implicit supervision for semantic alignment.
The shared tokens analysis reveals how mT5's vocabulary captures common subword patterns across related languages. Words derived from the same root (like 'computer' in English, German, and Italian) often share subword components, enabling direct knowledge transfer. Languages with unique scripts like Japanese require entirely distinct tokens, which is why cross-lingual transfer to such languages relies more heavily on semantic alignment learned during pre-training rather than surface-level lexical overlap. The model must learn that the Japanese concept corresponding to "computer" should map to the same region of representation space as the English word, even though they share no characters.
mT5 vs T5 Performance
Comparing mT5 and T5 reveals the tradeoffs involved in multilingual training. On English-only benchmarks, mT5 slightly underperforms T5. This reflects the "curse of multilinguality": the model must divide its capacity across many languages.
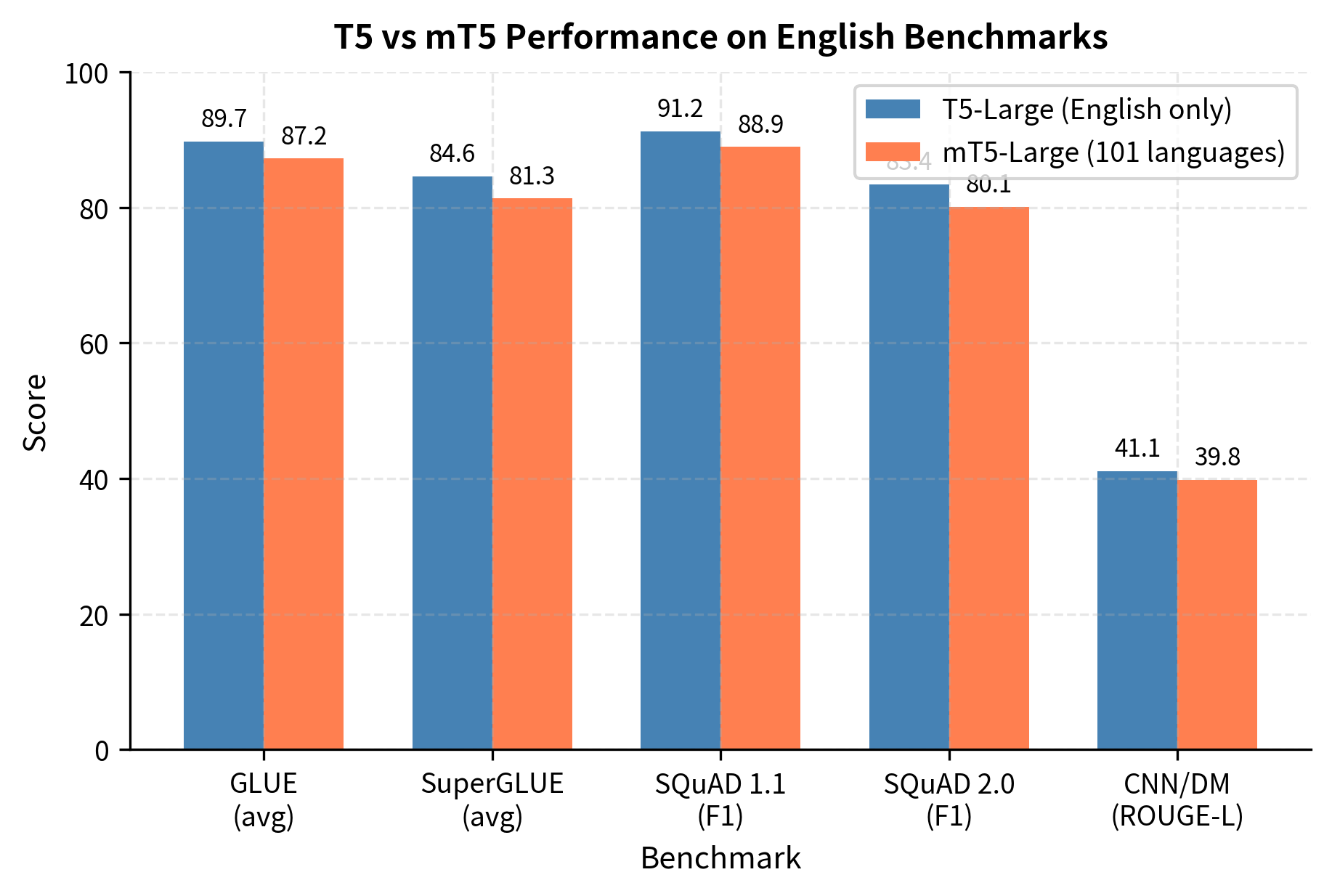
The benchmark comparison reveals consistent but modest performance gaps: mT5-Large scores approximately 2-3 points lower on GLUE (87.2 vs 89.7), SuperGLUE (81.3 vs 84.6), and both SQuAD variants. The ROUGE-L gap on CNN/DM is similarly small at about 1.3 points. This English performance gap is relatively small, typically 2-4 points, while mT5 gains the ability to process 100 additional languages. For applications requiring multilingual support, this tradeoff is highly favorable.
Performance Across Model Sizes
mT5 was released in multiple sizes, following T5's scaling approach:
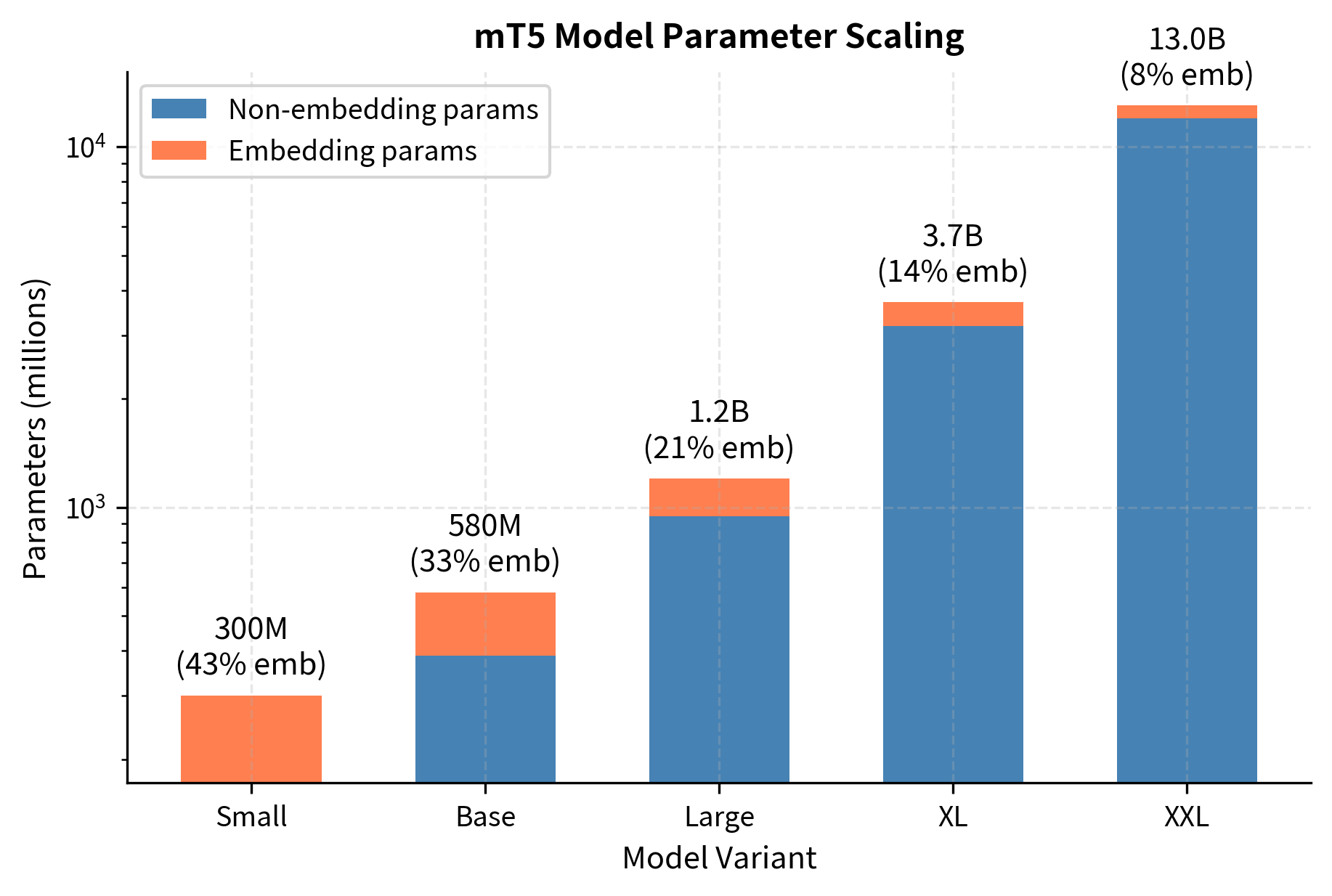
The table shows how mT5 scales from 300M to 13B parameters. Each size increase brings proportionally larger hidden dimensions (d_model) and feed-forward dimensions (d_ff), with the largest models using 24 layers consistently. Larger variants show better cross-lingual transfer, suggesting that additional capacity helps the model maintain stronger representations across more languages. The relationship between model size and multilingual performance is an area we'll explore further in the scaling laws chapters.
Working with mT5
Let's implement a practical example using mT5 for multilingual text generation. We'll use the Hugging Face Transformers library to demonstrate fine-tuning on a simple translation-like task:
The mT5-Small model loads successfully with its full 250K vocabulary. The embedding layer alone accounts for a significant portion of the total parameters, reflecting the vocabulary expansion needed for multilingual support. Despite being the smallest variant, it still provides strong multilingual capabilities for experimentation and deployment in resource-constrained settings.
Multilingual Span Corruption Example
mT5 uses the same span corruption objective as T5. Let's examine how it works on different languages:
The span corruption examples demonstrate how mT5's pre-training objective works uniformly across languages. Regardless of script or language family, the model learns to predict masked spans given surrounding context. This consistent training signal across all 101 languages encourages the model to develop language-agnostic representations that capture universal patterns in how information is structured in text.
Fine-Tuning for Multilingual Tasks
Fine-tuning mT5 follows the same text-to-text format as T5. Here's an example setup for multilingual question answering:
The examples demonstrate mT5's text-to-text format for question answering: questions and contexts are combined into a single input string, and the model learns to generate the answer span. The consistent formatting across English, Spanish, and German allows the model to learn the task structure and leverage cross-lingual representations.
Generation Across Languages
Let's examine how mT5 generates text in different languages:
Note that the base mT5 model requires fine-tuning on specific tasks to produce high-quality outputs. The pre-trained model has learned multilingual representations through span corruption but hasn't been trained to follow specific task instructions.
Limitations and Impact
mT5 represented a significant advance in multilingual NLP, but several limitations affect its practical deployment and performance.
Capacity constraints: The curse of multilinguality means that as more languages are added, each language receives less of the model's total capacity. This creates a trade-off between language coverage and per-language performance. For applications requiring maximum performance in a single language, language-specific models may be preferable. The 101 languages in mT5 must share the same parameter space, leading to interference effects where learning one language can slightly degrade another.
Resource imbalance persistence: Despite temperature sampling, low-resource languages still receive less total training signal than high-resource languages. Languages with only millions of tokens, compared to trillions for English, develop weaker representations. This means cross-lingual transfer from English to Yoruba will be less effective than transfer to Spanish, continuing existing gaps in NLP system availability across languages.
Tokenization efficiency gaps: The 250K vocabulary cannot achieve optimal tokenization for all 101 languages simultaneously. Some languages experience significantly higher token-to-word ratios than others, leading to longer sequences, slower processing, and potentially worse performance for a given context length.
Evaluation challenges: Benchmark availability varies dramatically across languages. Most NLP benchmarks exist primarily in English and a handful of other high-resource languages, making it difficult to properly evaluate mT5's performance on many languages it supports.
Despite these limitations, mT5 had a major impact on multilingual NLP:
- Democratized access: mT5 made strong NLP capabilities available for many languages that previously had minimal model support
- Cross-lingual transfer: The strong transfer capabilities enable zero-shot or few-shot learning for languages where task-specific training data doesn't exist
- Research foundation: mT5 spawned numerous follow-up works exploring multilingual modeling, including mC4 becoming a standard resource for multilingual training
- Production systems: Many real-world multilingual applications (translation, search, classification) leverage mT5 or its successors as foundation models
The scaling laws we'll explore in upcoming chapters suggest that many of mT5's limitations can be addressed through increased model scale, improved training data curation, and more sophisticated sampling strategies.
Summary
mT5 extends the T5 text-to-text paradigm to 101 languages through several innovations:
- mC4 corpus: A massive multilingual dataset extracted from Common Crawl, with language-specific filtering applied to create subcorpora for each supported language
- Temperature-based sampling: Uses with to balance between proportional and uniform language sampling, boosting low-resource languages by orders of magnitude
- Expanded vocabulary: 250K SentencePiece tokens (vs. 32K for T5) to cover diverse scripts and morphological patterns, trained with the same temperature sampling
- Cross-lingual transfer: Learns language-agnostic representations that enable fine-tuning on English data and evaluation on other languages
- Performance tradeoffs: Slightly lower English performance compared to T5, but gains 100 additional languages with strong multilingual capabilities
The temperature sampling formula and multilingual tokenization strategies pioneered by mT5 have influenced subsequent multilingual models, establishing patterns for handling resource imbalance that remain relevant for current model development.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about mT5 and multilingual language modeling.

Comments