

Master root-finding, interpolation, and numerical integration for finance. Learn to compute implied volatility, build yield curves, and price derivatives.
Choose your expertise level to adjust how many terms are explained. Beginners see more tooltips, experts see fewer to maintain reading flow. Hover over underlined terms for instant definitions.
Numerical Methods and Algorithms in Finance
Many problems in quantitative finance lack closed-form analytical solutions. When you need to find the yield-to-maturity of a bond, extract the implied volatility from an option price, or value a complex derivative, you often encounter equations that cannot be solved algebraically. Numerical methods provide systematic algorithms to approximate these solutions to arbitrary precision.
These techniques form the computational backbone of modern finance. Every trading platform that displays implied volatilities runs root-finding algorithms thousands of times per second. Every risk management system that constructs yield curves relies on interpolation methods. Every exotic derivative pricing engine uses numerical integration when analytical formulas are unavailable.
This chapter introduces three foundational categories of numerical methods: root-finding algorithms for solving equations, interpolation techniques for constructing continuous curves from discrete data, and numerical integration for computing definite integrals. You'll learn both the mathematical foundations and practical implementations, with applications to real financial problems including bond pricing, options valuation, and curve construction.
Root-Finding Algorithms
Root-finding algorithms solve equations of the form , where you seek the value such that the function equals zero. In finance, these appear whenever you need to invert a pricing formula. Given an observed market price, what input parameter produces that price? This question is central to financial calculations, from basic bond analytics to derivatives pricing.
The challenge arises because financial pricing formulas typically express price as a function of some underlying parameter (yield, volatility, or credit spread), but markets quote prices directly. To convert between prices and rates or volatilities, you must solve the inverse problem: given the price, find the parameter. When the forward function is a complex nonlinear expression, its inverse rarely has a closed-form solution, and numerical methods become essential.
Consider the bond pricing equation:
where:
- : observed market price of the bond
- : periodic coupon payment
- : face value (par value) of the bond
- : total number of payment periods until maturity
- : yield-to-maturity (the discount rate we seek)
The first term sums the present values of all coupon payments, while the second term adds the present value of the face value repaid at maturity. This formula embodies the fundamental principle of fixed-income valuation: a bond's fair price equals the present value of all its future cash flows, discounted at a rate that reflects the required return. Finding analytically is impossible because the equation is a polynomial of degree . You know from the market, but solving for analytically is impossible for most bonds. For a 10-year bond with semi-annual payments, you face a polynomial equation of degree 20, beyond the reach of algebraic techniques. You must use numerical methods.
Similarly, the Black-Scholes formula gives option price as a function of volatility :
where:
- : call option price
- : current stock price
- : strike price
- : time to expiration
- : risk-free interest rate
- : cumulative standard normal distribution function
- : parameters depending on volatility (defined later)
Given an observed option price , finding the implied volatility requires solving . The Black-Scholes formula involves the standard normal cumulative distribution function, which itself has no closed-form inverse. Combined with the complex dependence of and on , the resulting equation demands numerical solution. This problem of finding the volatility implied by a market price is solved billions of times daily across global options markets.
The Bisection Method
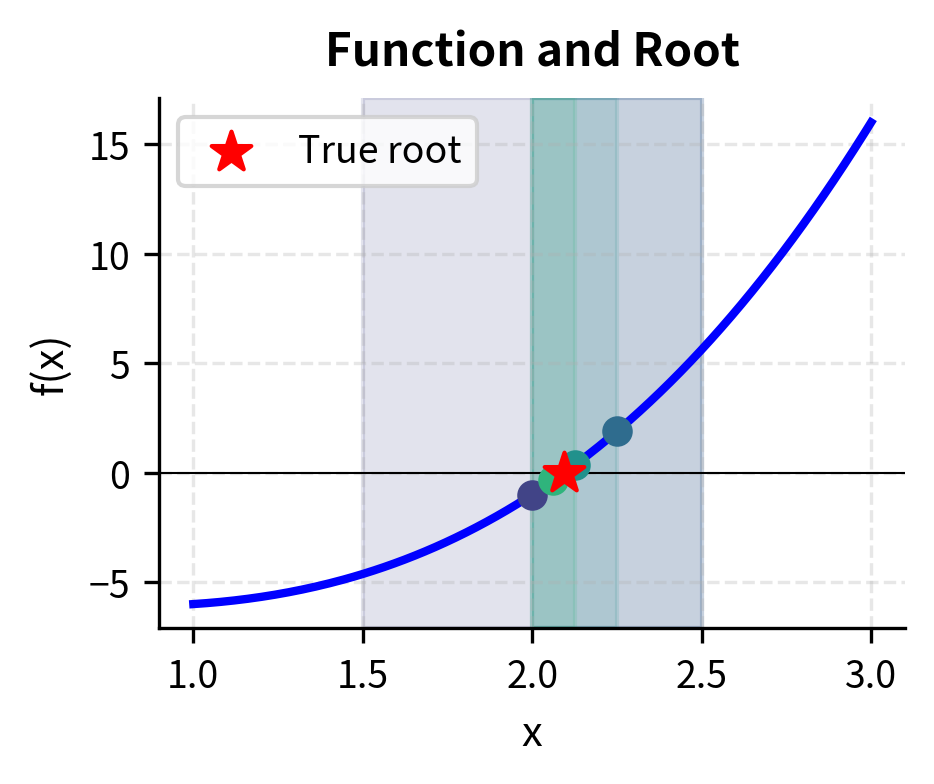
The bisection method is the simplest and most robust root-finding algorithm. It exploits the intermediate value theorem: if a continuous function has opposite signs at two points and , then it must cross zero somewhere between them. This elegant mathematical principle guarantees that a root exists within the interval, providing the foundation for a systematic search strategy.
The intuition behind bisection is straightforward. If you know the root lies somewhere in an interval, the best way to narrow down its location is to check the midpoint. Depending on which half contains the root, you discard the other half and repeat. Each iteration cuts the uncertainty in half, inexorably converging toward the answer. This divide-and-conquer approach trades speed for certainty. Bisection may be slow, but it never fails when properly initialized.
The algorithm proceeds by repeatedly halving the interval:
- Start with an interval where and have opposite signs
- Compute the midpoint
- Evaluate
- If has the same sign as , replace with ; otherwise replace with
- Repeat until the interval is sufficiently small
Step 4 requires careful attention. Since and have opposite signs and the function is continuous, the root must lie between them. After computing , we ask: which half-interval still brackets the root? If shares the same sign as , then the root lies between and (where signs still differ). Conversely, if shares the same sign as , the root lies between and . Either way, we've reduced the search interval by exactly half while maintaining the crucial sign-change property.
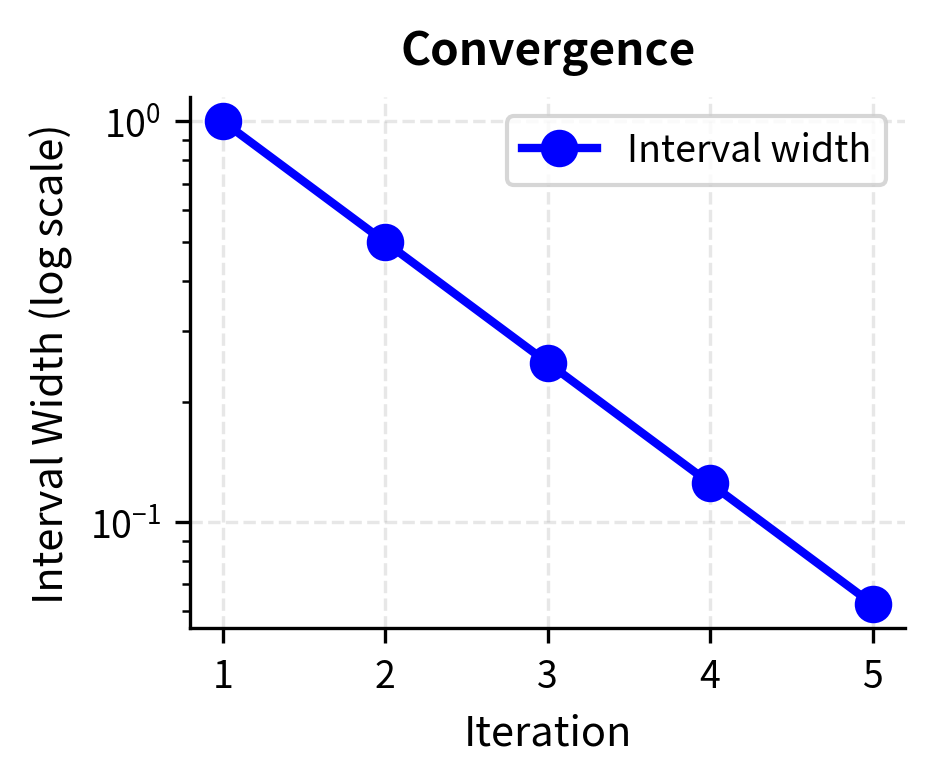
Each iteration halves the interval width, so after iterations, the error is at most:
where:
- : initial interval width
- : number of iterations performed
- : factor by which the interval shrinks after halvings To achieve precision , you need approximately iterations.
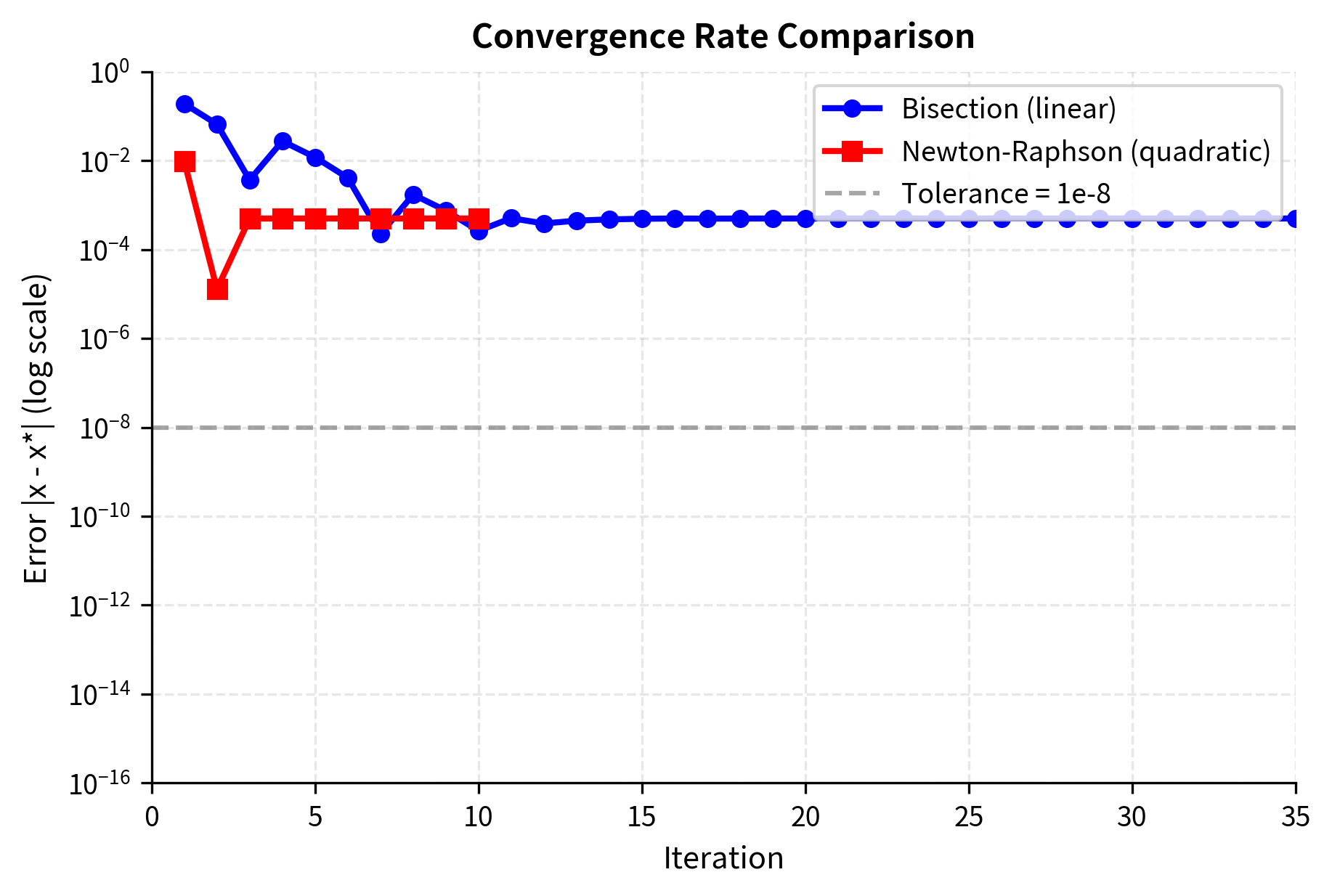
This logarithmic relationship means bisection is reliable but slow: achieving 10 decimal places of accuracy requires about 33 iterations regardless of the function. The method treats every function identically: it does not exploit any special structure like smoothness or convexity. A rapidly varying function and a nearly constant one require the same number of iterations for a given precision. This indifference to the function's character is both a strength (universal applicability) and a weakness (missed opportunities for acceleration).
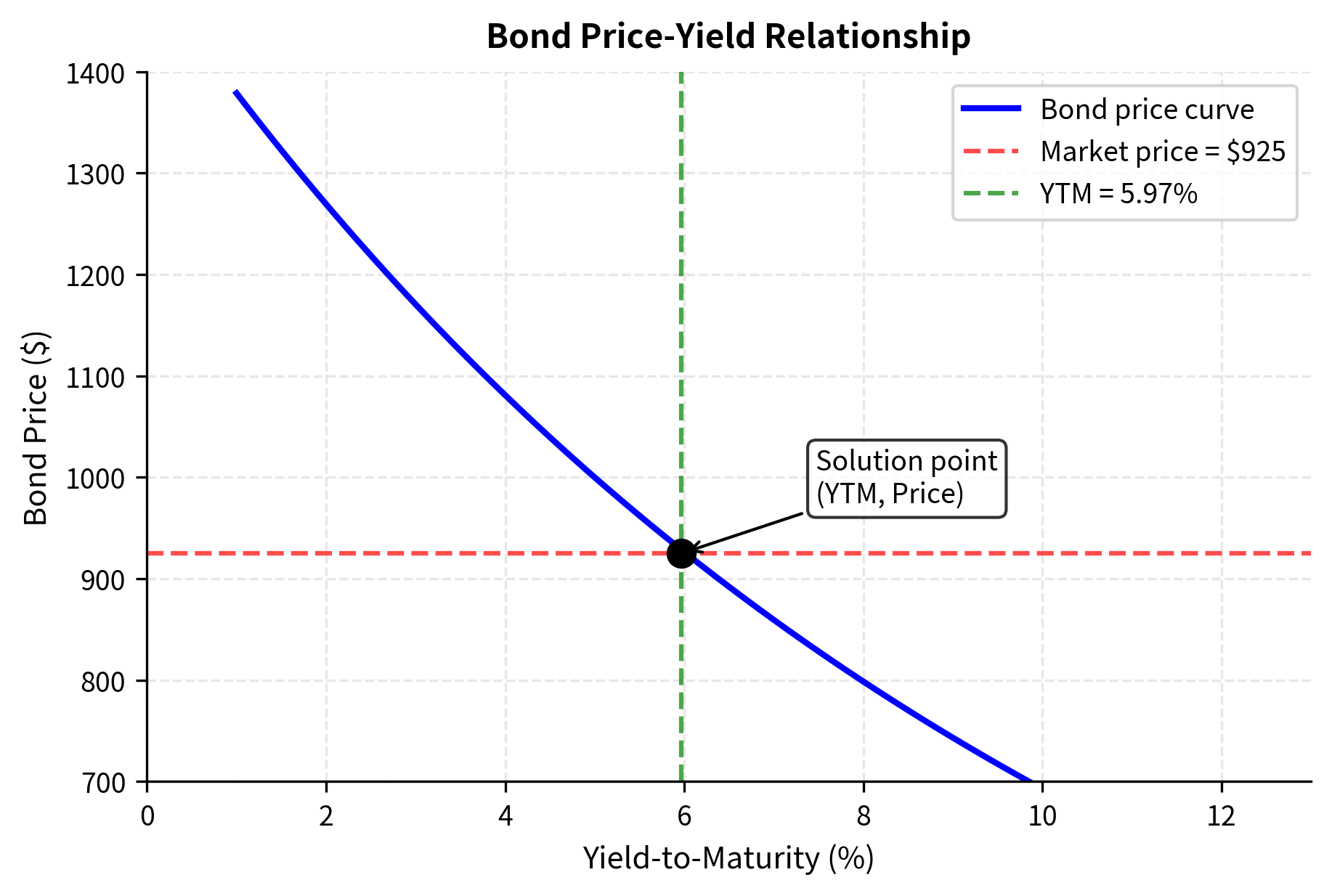
Let's implement bisection to find the yield-to-maturity of a bond:
Now let's apply this to a concrete example. Consider a 10-year bond with a 5% annual coupon, 925:
The bond trades below par (at a discount), so the yield exceeds the coupon rate. The bisection method converged in about 30 iterations to find a YTM of approximately 5.97%. This result makes economic sense: investors demand a higher effective return than the stated coupon rate to compensate for the discount purchase price. Over the bond's life, they receive not only the coupon payments but also the capital gain from the price rising toward par at maturity.
Newton-Raphson Method
While bisection is reliable, it converges slowly. The Newton-Raphson method achieves much faster convergence by using derivative information. The key insight is that the derivative tells us not just where the function is, but where it's going. By using this directional information, we can take informed steps toward the root rather than blindly halving intervals.
The geometric intuition is illuminating. At any point , we can approximate the function by its tangent line, a linear approximation that matches both the function's value and its slope at that point. Where does this tangent line cross zero? That crossing point becomes our next estimate . If the function is reasonably well-behaved near the root, the tangent line provides an excellent local approximation, and following it leads us closer to the root.
Starting from an initial guess , each iteration updates:
where:
- : current estimate of the root
- : function value at current estimate
- : derivative of function at current estimate
- : improved estimate after one iteration
Geometrically, this finds where the tangent line to at crosses the x-axis. The ratio represents how far to step: a large function value requires a larger step, and a steep slope (large derivative) means we are close and need only a small step. To understand why, consider that the tangent line equation is . Setting and solving for yields exactly the Newton-Raphson update formula. The method thus asks: if the function behaved exactly like its tangent line, where would the root be?
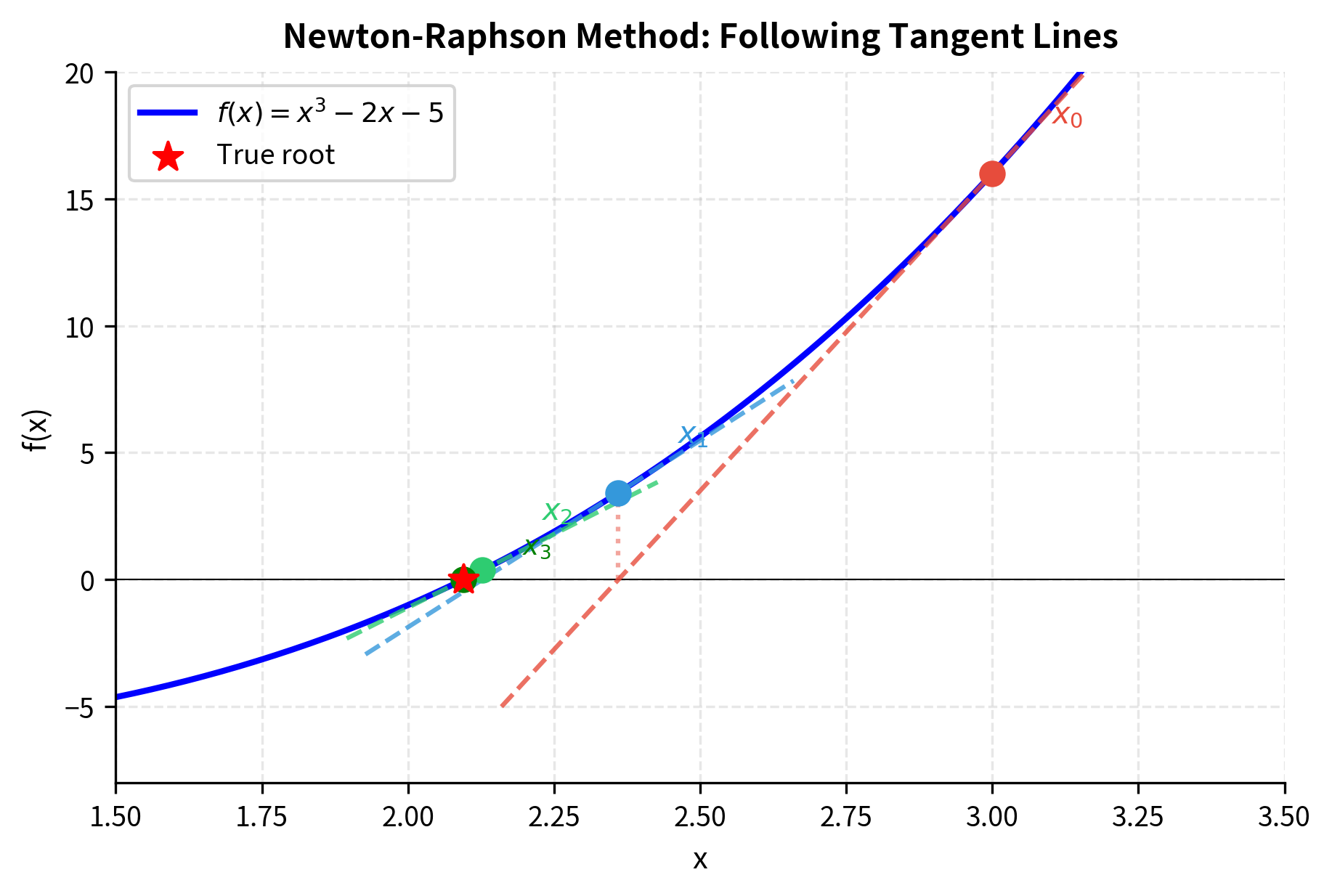
Near a simple root, Newton-Raphson exhibits quadratic convergence: the number of correct digits roughly doubles with each iteration.
An algorithm has quadratic convergence if the error at step is proportional to the square of the error at step : for some constant . This means if you have 2 correct decimal places, the next iteration gives roughly 4, then 8, then 16.
This property explains why Newton-Raphson is faster than bisection. Bisection adds roughly one bit of precision per iteration (linear convergence), while Newton-Raphson adds roughly as many new bits as it already has (quadratic convergence). Once you're close to the root, convergence becomes explosive.
The main requirement is computing the derivative . For bond pricing, the derivative of price with respect to yield is:
where:
- : rate of change of bond price with respect to yield (negative of dollar duration)
- : time period index
- : periodic coupon payment
- : total number of periods
- : face value
- : discount factor raised to power (one more than in the price formula due to differentiation)
This derivative, known as the bond's dollar duration (up to a sign), measures price sensitivity to yield changes. The negative sign indicates that prices fall when yields rise, a fundamental inverse relationship in fixed income. Each term is weighted by its time to payment , reflecting that longer-dated cash flows are more sensitive to yield changes. This makes intuitive sense: a payment far in the future is discounted many times, so any change in the discount rate compounds over more periods.
The derivative formula emerges directly from applying the power rule to each term in the bond pricing equation. For a single cash flow at time , we have . Summing over all cash flows gives the complete expression.
Newton-Raphson typically converges in 4-6 iterations compared to 25-30 for bisection. This efficiency matters when you are computing implied volatilities for thousands of options in real-time. The computational savings compound dramatically across an entire options chain, where a trading desk might need fresh implied volatilities for hundreds of strikes across multiple expirations, updated continuously throughout the trading day.
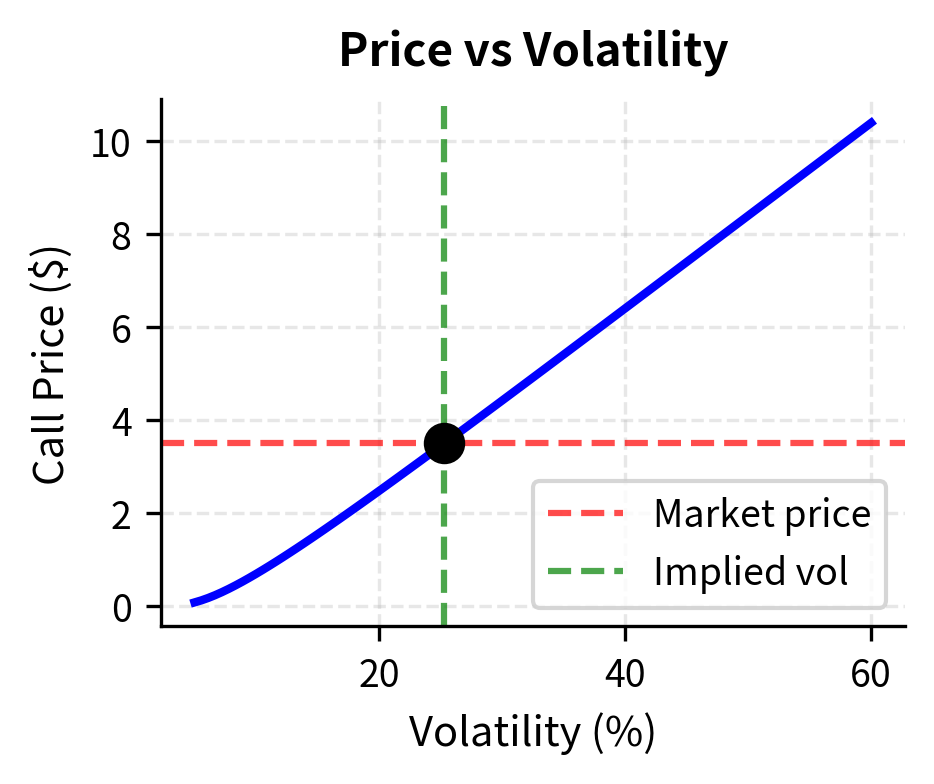
Computing Implied Volatility
Implied volatility calculation is the canonical application of root-finding in options trading. Every options desk needs to convert between prices and volatilities rapidly. Traders think in terms of volatility, the natural unit for comparing options across different strikes, expirations, and underlying assets. But markets quote prices. The translation between these two representations happens through implied volatility calculation, making root-finding algorithms a critical piece of trading infrastructure.
The Black-Scholes formula for a European call option is:
where:
- : call option price
- : current stock price
- : strike price of the option
- : time to expiration in years
- : risk-free interest rate (continuously compounded)
- : volatility of the underlying asset (the parameter we seek)
- : measures how far in-the-money the option is, adjusted for drift and volatility
- : adjusts for the volatility effect over the option's lifetime
- : cumulative standard normal distribution function
The first term represents the expected stock value at expiration (conditional on exercise), while is the present value of the strike payment weighted by the probability of exercise. The parameters and encode how likely the option is to finish in the money, measured in standard deviations of the log-price distribution. Notice that both depend on volatility in complex ways. The parameter appears in the numerator, the denominator, and implicitly through the function. This tangled dependence makes analytical inversion impossible.
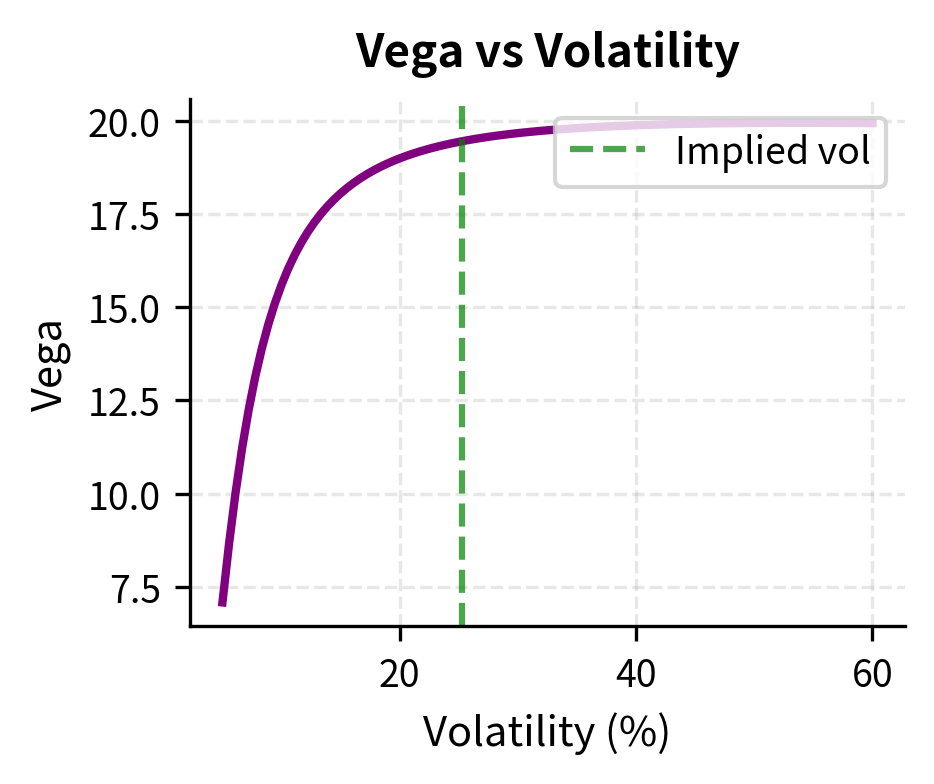
To use Newton-Raphson, we need the derivative of the option price with respect to volatility, known as vega:
where:
- : standard normal probability density function
- : scales the sensitivity by stock price and time horizon
- : peaks when the option is at-the-money and decays for deep in/out-of-the-money options
Vega is always positive because higher volatility increases option value. This makes economic sense: options are bets on movement, and more volatility means more potential movement in either direction. Since the option holder benefits from favorable moves but has limited downside (the premium paid), increased uncertainty is valuable. Vega peaks for at-the-money options with longer time to expiration, which explains why Newton-Raphson struggles for deep out-of-the-money options or near-expiration options where vega approaches zero. When the derivative is tiny, the Newton-Raphson step becomes enormous, potentially overshooting the valid range of volatilities entirely.
The simplicity of the vega formula, despite the complexity of the Black-Scholes price itself, reflects the lognormal structure of the model and the fact that differentiating the normal CDF yields the normal PDF. This has practical consequences: computing the exact derivative costs almost nothing beyond computing the price, making Newton-Raphson highly efficient for this problem.
Let's calculate implied volatility for a sample option:
The algorithm converged in just a few iterations. This efficiency is crucial because trading systems may need to compute implied volatilities for entire option chains, potentially thousands of contracts, multiple times per second. Each time a quote updates anywhere in the chain, the entire volatility surface needs refreshing to maintain a consistent view of market expectations.
Practical Considerations
When implementing root-finding in production systems, several considerations arise.
Initial guess selection significantly affects Newton-Raphson convergence. For implied volatility, a reasonable starting point is 20-30% for equity options, adjusted based on the option's moneyness. Poor initial guesses can lead to divergence or convergence to invalid solutions (like negative volatility).
Hybrid methods combine the robustness of bisection with the speed of Newton-Raphson. Start with Newton-Raphson, and if the iterate leaves a reasonable range or the step is too large, fall back to bisection for a few iterations to stabilize.
Brent's method is a sophisticated hybrid that combines bisection, secant, and inverse quadratic interpolation. It guarantees convergence like bisection while typically achieving superlinear convergence. Most production systems use Brent's method or similar hybrids.
Interpolation Techniques
Interpolation constructs continuous functions from discrete data points. In finance, you observe prices or rates at specific points, but need values at other locations. A yield curve might have observed rates at 3-month, 6-month, 1-year, 2-year, 5-year, and 10-year maturities, but you need to price a bond maturing in 3.5 years. The market provides data at certain locations, and interpolation fills in the values between them.
The challenge goes beyond convenience. Financial instruments exist at arbitrary maturities and strikes, not just at the discrete points where we have direct market observations. A corporate treasurer hedging a loan with a specific maturity, a portfolio manager pricing an off-the-run bond, or a derivatives trader valuing an exotic option at an unusual strike: all require rates or volatilities at points not directly quoted. Interpolation bridges this gap, but the choice of interpolation method affects pricing, hedging, and risk management in subtle but important ways.
Linear Interpolation
Linear interpolation connects adjacent data points with straight lines. Given points and , the interpolated value at is:
where:
- and : the two known data points bracketing
- : the point at which we want to interpolate
- : the slope of the line connecting the two points
- : horizontal distance from the left point
The formula starts at and adds the slope times the horizontal distance traveled. This geometric interpretation makes linear interpolation intuitive: we're simply walking along the straight line connecting two known points. The rate of change (slope) is constant within each segment, jumping discontinuously as we cross from one segment to the next.
This can be written as a weighted average:
where:
- : interpolation parameter ranging from 0 to 1
- When : and (at the left endpoint)
- When : and (at the right endpoint)
- When : is the midpoint and is the average of and
This weighted average form shows how linear interpolation works. The result is a convex combination of the two endpoint values, with weights determined by relative position. The parameter measures progress from the left point to the right point, normalized to the unit interval. This formulation generalizes naturally to higher dimensions and forms the basis for barycentric coordinates in computer graphics.
Linear interpolation is simple and computationally efficient, but it has a significant drawback. The interpolated curve has discontinuous first derivatives at the data points, creating "kinks." For many financial applications, this lack of smoothness is problematic. Consider computing the forward rate from a yield curve. The forward rate involves derivatives of the discount function, and kinks in the yield curve translate to jumps in forward rates. These artificial jumps have no economic meaning. They are purely artifacts of the interpolation method.
Cubic Spline Interpolation
Cubic spline interpolation addresses the smoothness problem by fitting piecewise cubic polynomials that are continuous in both first and second derivatives. The name comes from a physical analogy: imagine bending a thin, flexible strip of material (a "spline") so that it passes through a set of fixed points. The strip naturally assumes a shape that minimizes bending energy, which turns out to be mathematically equivalent to the cubic spline solution.
Given data points, cubic splines fit cubic polynomials, each of the form:
where:
- : cubic polynomial on the interval
- : constant term, equals (the data value at )
- : linear coefficient, controls the slope at
- : quadratic coefficient, related to curvature
- : cubic coefficient, allows the curvature to vary across the interval
A cubic polynomial has four coefficients, and we have such polynomials, giving unknowns in total. To determine all these coefficients uniquely, we need equations. These come from the interpolation and smoothness requirements that make splines so useful.
The coefficients are determined by requiring:
- Interpolation: each polynomial passes through its endpoint data
- Continuity: adjacent polynomials match at data points
- Smoothness: first and second derivatives match at interior data points
- Boundary conditions: typically "natural" splines with zero second derivatives at endpoints, or "clamped" splines with specified first derivatives
The interpolation conditions provide equations (each polynomial must match the data at both its left and right endpoints). Derivative matching at the interior points adds more equations (one each for first and second derivatives). This gives equations. The two boundary conditions supply the remaining two equations needed to determine all coefficients uniquely.
This creates a smooth curve that passes exactly through all data points, with no discontinuities in slope or curvature. The smoothness properties make cubic splines particularly valuable for computing Greeks and other derivatives-based quantities. Where linear interpolation would produce artificial jumps in forward rates, cubic splines yield smooth forward curves that behave more like actual market rates.
Let's visualize the difference between linear and cubic spline interpolation:
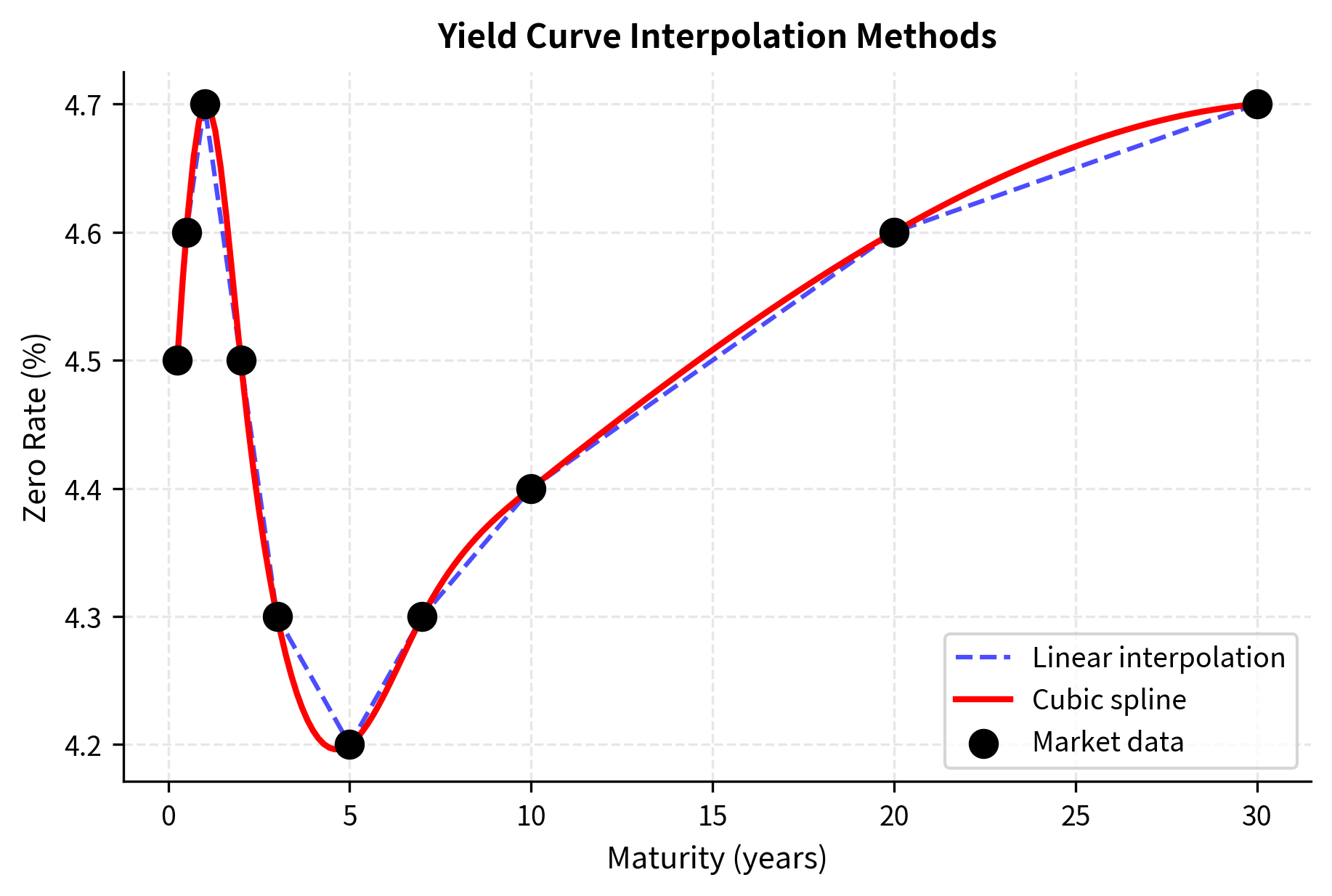
The cubic spline creates a smooth curve that follows the general shape of the data without the angular appearance of linear interpolation. Notice how the spline captures the inverted portion of the curve (rates dipping between 2-7 years) more naturally. The transition through the minimum is gradual, without the artificial corners that linear interpolation would produce at the 3-year and 5-year data points.
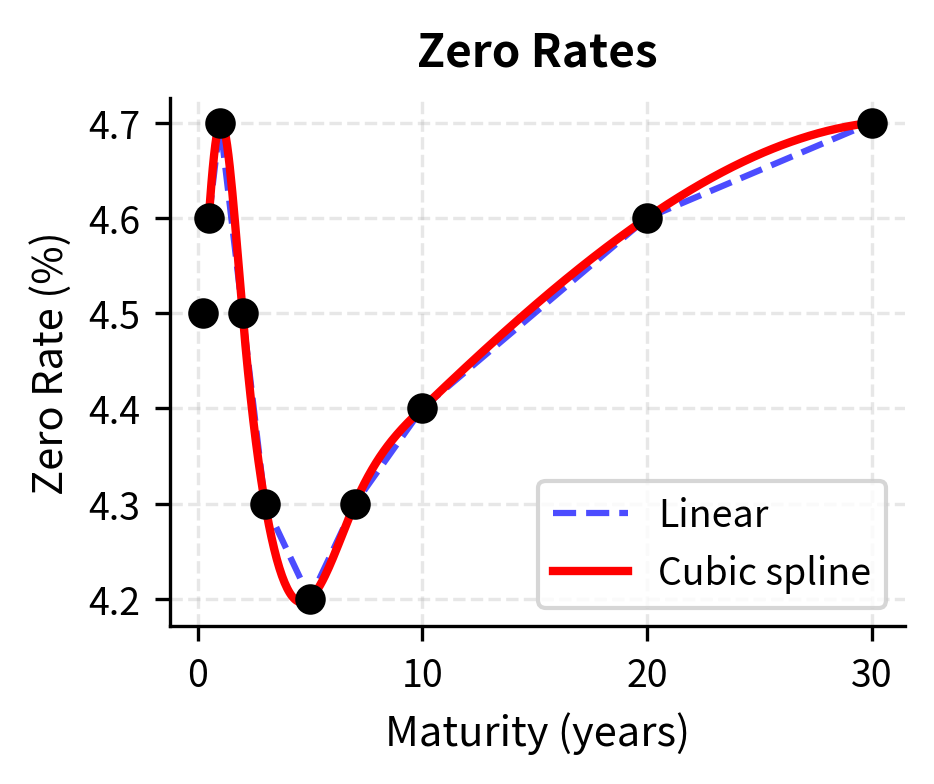
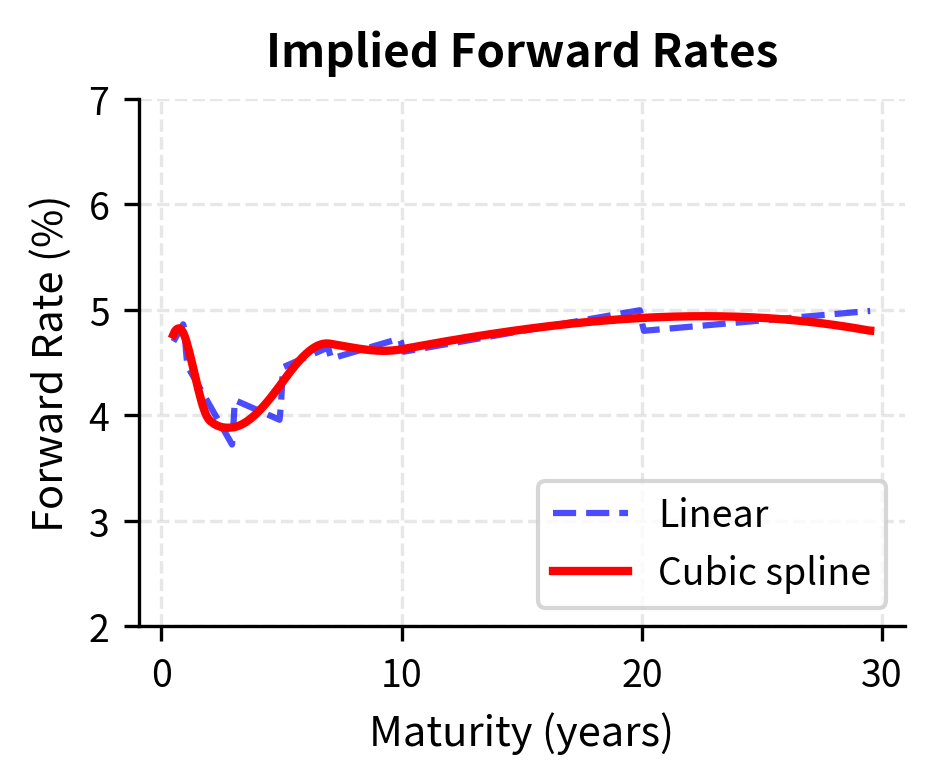
Interpolation in Volatility Surfaces
Volatility surfaces present a harder interpolation problem because they are two-dimensional: volatility depends on both strike price and time to expiration. Options traders need to interpolate these surfaces to price options at strikes and expirations not directly quoted in the market. A yield curve requires fitting a function of maturity alone, but a volatility surface requires fitting a function of two variables simultaneously.
The two-dimensional nature adds complexity. Not only must the surface pass through observed data points, but it should also exhibit sensible behavior between them: smoothness in both directions, no artificial valleys or peaks, and consistency with arbitrage constraints. The surface must make economic sense: volatility should not be negative, should not oscillate wildly between quoted points, and should follow the patterns (smiles, skews, term structure) that characterize real options markets.
The interpolated volatility of approximately 21% for this 9-month, slightly out-of-the-money option falls between the observed 6-month and 1-year values, as expected. The bivariate spline smoothly interpolates both the strike and expiration dimensions simultaneously, producing a value consistent with the surrounding observations in the volatility surface.
Let's visualize the full interpolated surface:
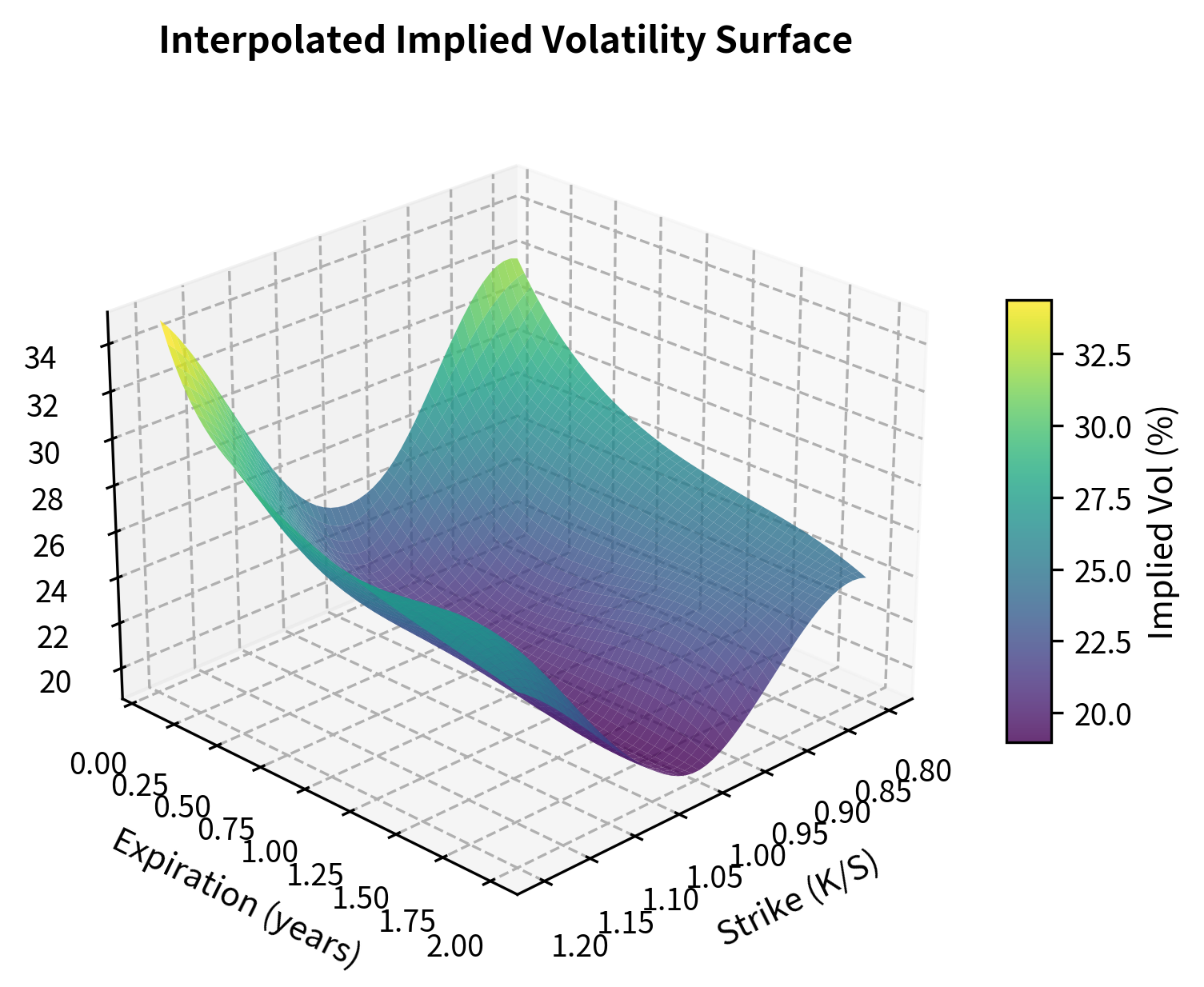
The surface displays the classic "volatility smile" pattern where out-of-the-money options (both puts with low K/S and calls with high K/S) have higher implied volatilities than at-the-money options. The smile flattens as expiration increases, a phenomenon known as the term structure of volatility. This flattening reflects the market's belief that while extreme moves are relatively more likely in the short term (perhaps due to jump risk or liquidity effects), over longer horizons the distribution looks more Gaussian and volatility becomes more uniform across strikes.
Choosing Interpolation Methods
The choice of interpolation method depends on the application.
Linear interpolation is appropriate when:
- Speed is critical and you are doing millions of lookups
- The data is already dense enough that smoothness does not matter much
- You want to avoid oscillation artifacts that can occur with higher-order methods
Cubic splines are preferred when:
- Smoothness is important for risk calculations (Greeks require derivatives)
- You're constructing curves for pricing that will be used across many instruments
- Visual quality matters for reporting
Specialized financial interpolation methods exist for specific applications. For yield curves, monotone-preserving splines prevent spurious oscillations. For volatility surfaces, stochastic volatility models or SABR parameterization may be more appropriate than generic interpolation.
Numerical Integration
Numerical integration approximates definite integrals when analytical solutions are unavailable. In finance, this arises when computing expected values, pricing path-dependent options, or evaluating probability distributions. Integration is the continuous analog of summation. Many financial quantities are expressed as continuous sums over possible outcomes, weighted by their probabilities.
The connection between integration and expected values makes numerical integration central to derivatives pricing. Under risk-neutral valuation, the price of any derivative equals the discounted expected value of its payoff. When the expectation can be written as an integral, numerical integration provides a direct path to the price. Even when Monte Carlo simulation is the primary tool, numerical integration often handles sub-problems more efficiently.
Consider the expected payoff of an option under a probability distribution :
where:
- : expected value of the option payoff
- : stock price at expiration time
- : option payoff as a function of terminal stock price
- : probability density function of the stock price at expiration
This integral accumulates the payoff at each possible terminal price, weighted by the probability of that price occurring. The integral runs from zero to infinity because stock prices are non-negative but have no upper bound. For simple European options under Black-Scholes, this integral has a closed form. But for more complex payoffs or distributions, numerical integration is necessary.
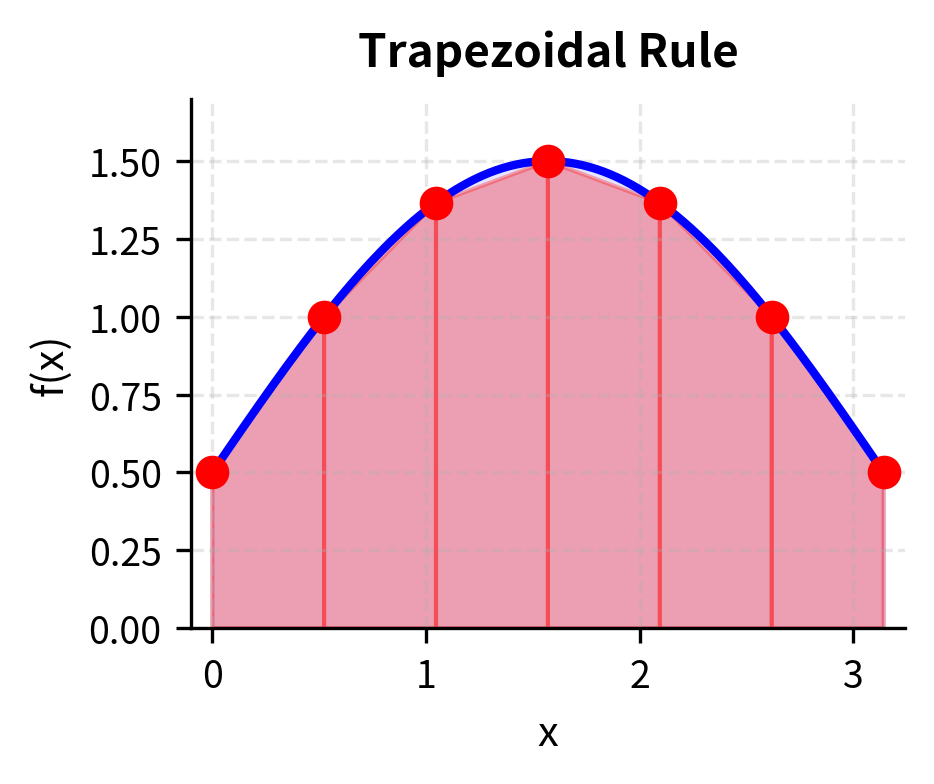
The Trapezoidal Rule
The trapezoidal rule approximates the area under a curve by dividing it into trapezoids. The key insight is that trapezoids.quadrilaterals with two parallel sides.provide a better approximation to curved regions than rectangles. Where a rectangle overestimates or underestimates the area depending on which corner matches the curve, a trapezoid averages between the two endpoints, typically achieving a more balanced approximation.
For an integral with equally-spaced points :
where:
- : step size (width of each trapezoid)
- and : function values at endpoints (each effectively weighted by )
- for : function values at interior points (coefficient 2 appears because each interior point is shared by two adjacent trapezoids)
The factor of 2 for interior points arises because each interior point is shared by two adjacent trapezoids. The area of a single trapezoid with parallel sides and is ; summing all trapezoids and collecting terms yields the formula above. The endpoints appear only once (each is the edge of only one trapezoid), while interior points appear twice (as the right edge of one trapezoid and the left edge of the next).
The trapezoidal rule has error . Doubling the number of points reduces the error by a factor of four. This relationship emerges from Taylor series analysis: the trapezoidal rule is exact for linear functions and makes errors proportional to the second derivative of the function, which determines how much the curve deviates from linearity.
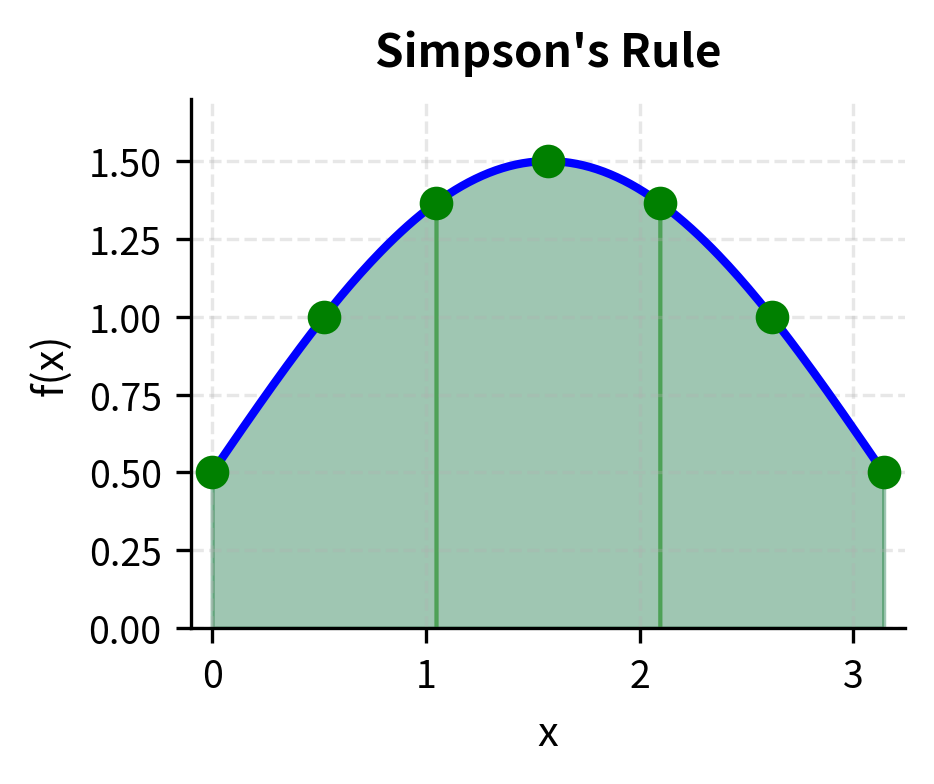
Simpson's Rule
Simpson's rule achieves higher accuracy by fitting parabolas through groups of three points. Rather than approximating the curve with straight line segments, Simpson's rule uses quadratic polynomials that can capture curvature. Since any three points uniquely determine a parabola, we divide the interval into pairs of subintervals and fit a parabola to each trio of consecutive points.
For intervals (where must be even):
where:
- Odd-indexed points (): weighted by 4 (midpoints of parabolic segments)
- Even-indexed points (): weighted by 2 (shared endpoints between segments)
- Endpoints and : weighted by 1
The 1-4-2-4-2-...-4-1 weighting pattern comes from integrating quadratic polynomials exactly. The coefficient 4 for odd-indexed points arises because these are the midpoints of each parabolic segment where the parabola contributes most. The coefficient 2 for even-indexed interior points reflects that these endpoints are shared by adjacent parabolic segments.
To understand why Simpson's rule uses these specific weights, consider integrating a parabola over an interval centered at the origin. The exact integral equals , which is precisely the Simpson's rule formula applied to three points. By choosing weights that make the formula exact for parabolas, we ensure high accuracy for any function that is approximately quadratic over each pair of sub-intervals.
Simpson's rule has error . This makes it much more accurate than the trapezoidal rule for smooth functions. The fourth-order convergence means that halving the step size reduces the error by a factor of 16, an improvement over the factor of 4 achieved by the trapezoidal rule. This increased accuracy comes at at no extra cost: Simpson's rule requires the same function evaluations as the trapezoidal rule, just combined with different weights.
Gaussian Quadrature
Gaussian quadrature achieves remarkable accuracy by choosing both the evaluation points and weights optimally. Rather than using equally-spaced points, it selects points (called nodes or abscissas) that maximize accuracy for polynomial functions. The key insight is that if you're free to choose where to evaluate the function, some choices are much better than others.
Consider the constraints. With function evaluations, we have degrees of freedom to optimize (n node positions and n weights). If we want the formula to be exact for polynomials, we should use these degrees of freedom to handle the highest-degree polynomials possible. For equally-spaced points (where positions are fixed), we can only optimize the weights, which in general lets us enforce exactness for polynomials up to degree (sometimes higher due to symmetry). But by optimizing both positions and weights, Gaussian quadrature achieves exactness for polynomials up to degree .nearly twice as good.
For Gauss-Legendre quadrature on :
where:
- : number of quadrature points
- : nodes (abscissas), roots of the -th degree Legendre polynomial
- : weights, computed to make the formula exact for polynomials up to degree
Example values:
- For : nodes at , weights
- For : nodes at , weights
The nodes are not equally spaced. They cluster toward the interval endpoints to control error near the boundaries where polynomial interpolation typically has the largest errors. This clustering is not arbitrary; it emerges from the mathematical requirement of exactness for high-degree polynomials, which forces the nodes to be roots of orthogonal polynomials (Legendre polynomials for the interval ). The mathematics underlying Gaussian quadrature connects to the theory of orthogonal polynomials and approximation theory.
This formula is exact for polynomials of degree up to , which is highly efficient. With just function evaluations, we achieve the same accuracy as a -degree polynomial approximation. For smooth functions that are well-approximated by polynomials, this translates to high accuracy with very few evaluations.
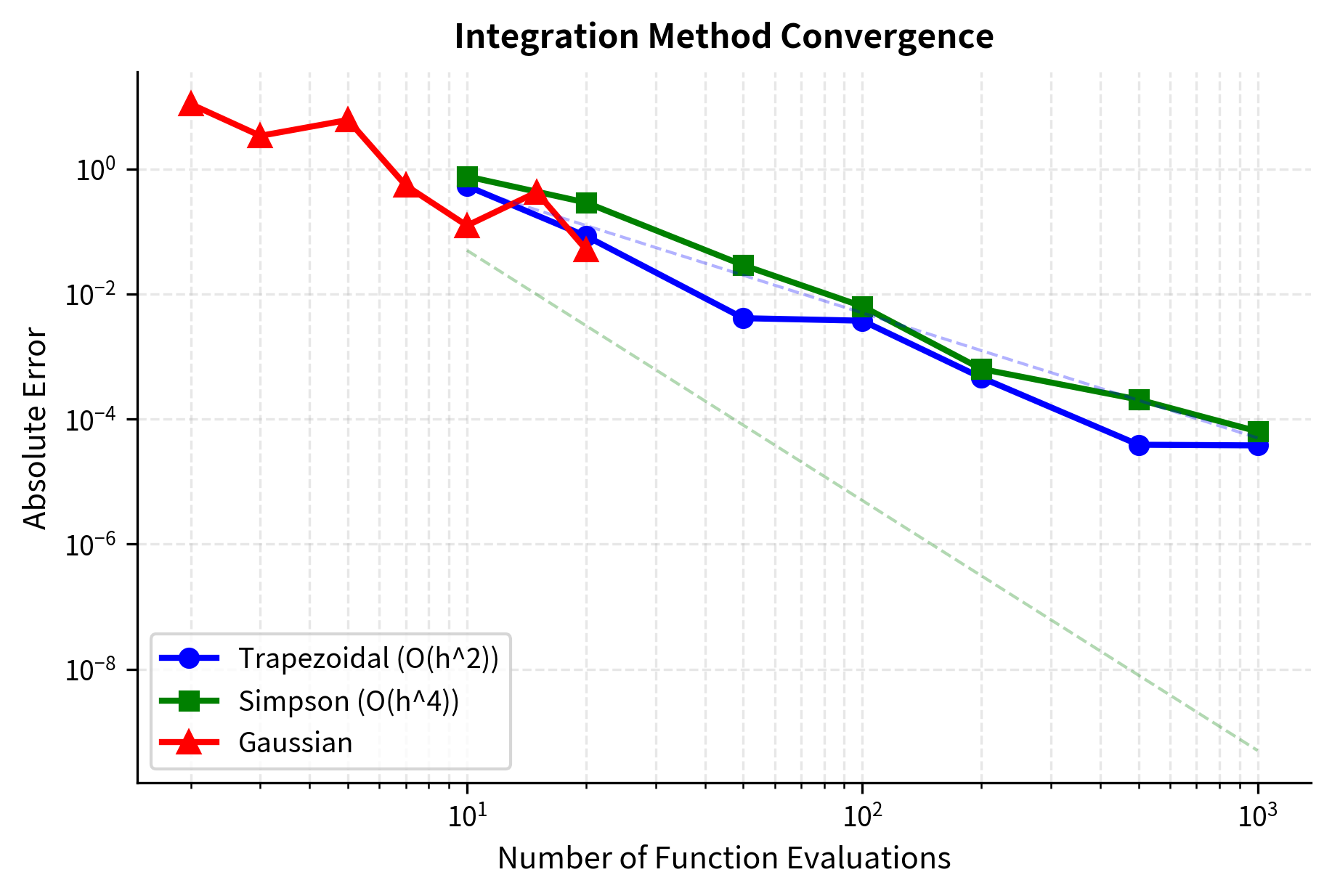
Let's compare these methods on a financial example: computing the expected payoff of a call option under a normal distribution of returns.
The results reveal the efficiency differences between methods. The trapezoidal rule requires 1000 points to achieve reasonable accuracy, while Simpson's rule reaches similar precision with just 100 points due to its O(h⁴) error convergence. Gaussian quadrature with just 20 points achieves accuracy comparable to Simpson's rule with 1000 points. This efficiency makes Gaussian quadrature the method of choice when function evaluations are expensive.
Practical Integration in Finance
Integration arises throughout quantitative finance in several key areas:
Risk-neutral pricing expresses derivatives prices as discounted expected payoffs:
where:
- : current value of the derivative
- : discount factor from expiration to today
- : expectation under the risk-neutral probability measure
- : derivative's payoff at expiration, typically a function of the underlying asset price
When payoffs are complex or the risk-neutral distribution doesn't yield closed forms, numerical integration computes these expectations.
Value at Risk (VaR) requires integrating the tail of a loss distribution:
where:
- : Value at Risk at confidence level
- : portfolio loss (positive values = losses)
- : confidence level (typically 95% or 99%)
- : infimum (smallest value satisfying the condition)
This definition says VaR is the smallest loss threshold such that the probability of exceeding it is at most .
While often computed via simulation, analytical approaches use numerical integration to evaluate the cumulative distribution function.
Probability transforms in copula models and risk aggregation require integrating joint densities to compute marginal distributions or dependence measures.
Worked Example: Building a Complete Pricing System
Let's combine these numerical methods to build a system that prices a bond with an embedded call option. The issuer can call (redeem) the bond before maturity if interest rates fall, making the yield calculation more complex.
First, we'll establish the market environment by constructing a yield curve from market data:
Now let's price a callable bond. The bond has a 6% coupon, 10-year maturity, and can be called at par after year 5:
The straight bond price exceeds par because the 6% coupon is higher than current market rates (around 5%). However, the embedded call option reduces the bond's value to investors because the issuer will likely call the bond if rates fall further, depriving investors of the above-market coupon payments. This call option value of approximately $25-30 represents the compensation investors implicitly give up for the call risk.
Now let's use root-finding to calculate the option-adjusted spread (OAS), which is the constant spread over the yield curve that equates the model price to a market price:
The OAS represents the credit spread component of the bond's yield after stripping out the value of the embedded option. A positive OAS indicates the bond offers compensation beyond the option-adjusted risk-free rate, typically reflecting credit risk or liquidity premium. A negative OAS indicates the bond is trading rich relative to the option-adjusted curve under the assumed model inputs. This metric allows fair comparison between callable and non-callable bonds from the same issuer.
This example demonstrates how root-finding, interpolation, and integration work together in a realistic pricing application.
The OAS of approximately -56 basis points indicates that this callable bond is trading rich relative to the option-adjusted risk-free curve in this simplified model. Investors use OAS to compare relative value across bonds with different embedded options.
Limitations and Practical Impact
Numerical methods are essential tools, but they have limitations that practitioners must understand.
Convergence is not guaranteed for many algorithms. Newton-Raphson can diverge if started far from the root or if the function has flat regions. Implied volatility calculation is difficult for deep out-of-the-money options where vega approaches zero. Production systems need careful handling of edge cases, fallback to robust methods like bisection when Newton-Raphson fails, and reasonable bounds on iterations and results.
Interpolation can produce artifacts that affect downstream calculations. Cubic splines, while smooth, can overshoot or oscillate between data points, occasionally producing negative forward rates in yield curves. Practitioners often use monotone-preserving or tension splines specifically designed for financial curves. Extrapolation beyond the data range is dangerous: a spline fit to 1-10 year rates may produce nonsensical values at 30 years.
Numerical integration error can accumulate in complex calculations. When pricing exotic derivatives that require nested integrations or when aggregating risks across many positions, small errors compound. Practitioners validate numerical results against closed-form solutions where available and use convergence analysis by repeating calculations with finer grids to assess reliability.
Despite these limitations, numerical methods have transformed quantitative finance. Before electronic computing, yield-to-maturity calculations required published tables and interpolation by hand. Implied volatility simply could not be computed in real-time. Today, these calculations happen millions of times per second across global markets.
The Black-Scholes revolution in the 1970s was enabled partly by the availability of numerical root-finding and normal distribution approximations. Modern high-frequency trading depends on implied volatility calculations fast enough to respond to quote updates within microseconds. Risk management systems that analyze portfolios of millions of positions rely entirely on numerical methods for integration and interpolation.
Summary
This chapter introduced three fundamental categories of numerical methods that form the computational foundation of quantitative finance.
Root-finding algorithms solve equations that cannot be inverted analytically. The bisection method guarantees convergence through interval halving but converges slowly. Newton-Raphson achieves quadratic convergence by using derivative information, but it can fail without good initial guesses. Hybrid methods combine robustness with speed for production applications like real-time implied volatility calculation.
Interpolation techniques construct continuous functions from discrete market data. Linear interpolation is fast and simple but produces non-smooth curves. Cubic splines provide the smoothness needed for computing derivatives and hedging ratios. Two-dimensional interpolation enables construction of volatility surfaces and multi-factor models.
Numerical integration approximates definite integrals for pricing and risk calculations. The trapezoidal rule and Simpson's rule are intuitive methods based on polynomial approximation. Gaussian quadrature achieves high accuracy with few function evaluations by optimally selecting evaluation points.
These techniques appear throughout the remaining chapters. Option pricing uses root-finding for implied volatility and Greeks calculation. Term structure models require interpolation for discount curve construction. Monte Carlo methods combine with numerical integration for path-dependent derivative pricing. Understanding these foundational algorithms enables you to implement, debug, and optimize the quantitative systems that power modern finance.
Key Parameters
The key parameters for the numerical methods covered in this chapter are:
- tol (tolerance): Convergence threshold for root-finding algorithms. Smaller values yield more precise results but require more iterations. Typical values range from 1e-6 to 1e-10.
- max_iter: Maximum number of iterations before algorithms terminate. Prevents infinite loops when convergence fails. Usually set between 50-100.
- a, b (interval bounds): Initial bracketing interval for bisection method. Must satisfy f(a) × f(b) < 0 to guarantee a root exists between them.
- x0 (initial guess): Starting point for Newton-Raphson. Convergence depends heavily on choosing a value reasonably close to the true root.
- n (number of points): Controls accuracy in numerical integration. Higher values improve precision but increase computation time. The relationship between n and error varies by method: O(1/n²) for trapezoidal, O(1/n⁴) for Simpson's.
- vol (volatility): Rate volatility parameter in bond pricing models. Higher volatility increases the value of embedded options.
- oas (option-adjusted spread): Constant spread over the risk-free curve that accounts for embedded option risk in callable bonds.
Quiz
Ready to test your understanding? Take this quick quiz to reinforce what you've learned about numerical methods and algorithms in finance.

Comments